Samouczek: trenowanie pierwszego modelu uczenia maszynowego (zestaw SDK w wersji 1, część 2 z 3)
DOTYCZY: Zestaw SDK języka Python w wersji 1
Zestaw SDK języka Python w wersji 1
W tym samouczku pokazano, jak wytrenować model uczenia maszynowego w usłudze Azure Machine Learning. Ten samouczek jest częścią 2 trzyczęściowej serii samouczków.
W części 1. Uruchamianie serii "Hello world!" przedstawiono sposób uruchamiania zadania w chmurze za pomocą skryptu sterującego.
W tym samouczku wykonasz następny krok, przesyłając skrypt, który szkoli model uczenia maszynowego. Ten przykład pomoże Ci zrozumieć, w jaki sposób usługa Azure Machine Learning ułatwia spójne zachowanie między debugowaniem lokalnym a przebiegami zdalnymi.
W tym samouczku zostały wykonane następujące czynności:
- Tworzenie skryptu uczenia.
- Definiowanie środowiska usługi Azure Machine Learning za pomocą środowiska Conda.
- Utwórz skrypt sterujący.
- Omówienie klas usługi Azure Machine Learning (
Environment,Run,Metrics). - Prześlij i uruchom skrypt szkoleniowy.
- Wyświetlanie danych wyjściowych kodu w chmurze.
- Rejestrowanie metryk w usłudze Azure Machine Learning.
- Wyświetlanie metryk w chmurze.
Wymagania wstępne
- Ukończenie części 1 serii.
Tworzenie skryptów szkoleniowych
Najpierw należy zdefiniować architekturę sieci neuronowej w pliku model.py . Cały kod trenowania zostanie skierowany do podkatalogu src , w tym model.py.
Kod szkoleniowy jest pobierany z tego przykładu wprowadzającego z biblioteki PyTorch. Należy pamiętać, że pojęcia związane z usługą Azure Machine Learning dotyczą dowolnego kodu uczenia maszynowego, a nie tylko rozwiązania PyTorch.
Utwórz plik model.py w podfolderze src . Skopiuj ten kod do pliku:
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xNa pasku narzędzi wybierz pozycję Zapisz , aby zapisać plik. Jeśli chcesz, zamknij kartę.
Następnie zdefiniuj skrypt trenowania również w podfolderze src . Ten skrypt pobiera zestaw danych CIFAR10 przy użyciu interfejsów API PyTorch
torchvision.dataset, konfiguruje sieć zdefiniowaną w model.py i trenuje go w dwóch epokach przy użyciu standardowej utraty SGD i utraty między entropiami.Utwórz skrypt train.py w podfolderze src :
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")Masz teraz następującą strukturę folderów:
Testowanie lokalne
Wybierz pozycję Zapisz i uruchom skrypt w terminalu , aby uruchomić skrypt train.py bezpośrednio w wystąpieniu obliczeniowym.
Po zakończeniu działania skryptu wybierz pozycję Odśwież nad folderami plików. Zobaczysz nowy folder danych o nazwie get-started/data Rozwiń ten folder, aby wyświetlić pobrane dane.
Tworzenie środowiska języka Python
Usługa Azure Machine Learning udostępnia koncepcję środowiska reprezentującego powtarzalne, wersjonowane środowisko języka Python do uruchamiania eksperymentów. Tworzenie środowiska z lokalnego środowiska Conda lub pip jest łatwe.
Najpierw utworzysz plik z zależnościami pakietu.
Utwórz nowy plik w folderze get-started o nazwie
pytorch-env.yml:name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvisionNa pasku narzędzi wybierz pozycję Zapisz , aby zapisać plik. Jeśli chcesz, zamknij kartę.
Tworzenie skryptu sterującego
Różnica między następującym skryptem sterującym a tym, który został użyty do przesłania komunikatu "Hello world!", jest dodanie kilku dodatkowych wierszy w celu ustawienia środowiska.
Utwórz nowy plik języka Python w folderze get-started o nazwie run-pytorch.py:
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
Porada
Jeśli podczas tworzenia klastra obliczeniowego użyto innej nazwy, pamiętaj o dostosowaniu nazwy w kodzie compute_target='cpu-cluster' .
Omówienie zmian w kodzie
env = ...
Odwołuje się do utworzonego powyżej pliku zależności.
config.run_config.environment = env
Dodaje środowisko do skryptuRunConfig.
Przesyłanie przebiegu do usługi Azure Machine Learning
Wybierz pozycję Zapisz i uruchom skrypt w terminalu, aby uruchomić skrypt run-pytorch.py .
Zostanie wyświetlony link w wyświetlonym oknie terminalu. Wybierz link, aby wyświetlić zadanie.
Uwaga
Podczas ładowania azureml_run_type_providers... mogą pojawić się pewne ostrzeżenia rozpoczynające się od błędu. Możesz zignorować te ostrzeżenia. Użyj linku u dołu tych ostrzeżeń, aby wyświetlić dane wyjściowe.
Wyświetlanie danych wyjściowych
- Na wyświetlonej stronie zostanie wyświetlony stan zadania. Przy pierwszym uruchomieniu tego skryptu usługa Azure Machine Learning utworzy nowy obraz platformy Docker ze środowiska PyTorch. Ukończenie całego zadania może potrwać około 10 minut. Ten obraz zostanie ponownie użyty w przyszłych zadaniach, aby działały znacznie szybciej.
- W Azure Machine Learning studio można wyświetlić dzienniki kompilacji platformy Docker. Wybierz kartę Dane wyjściowe i dzienniki , a następnie wybierz pozycję20_image_build_log.txt.
- Gdy stan zadania ma wartość Ukończono, wybierz pozycję Dane wyjściowe i dzienniki.
- Wybierz std_log.txt , aby wyświetlić dane wyjściowe zadania.
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
Jeśli zostanie wyświetlony błąd Your total snapshot size exceeds the limit, folder danych znajduje się w wartości użytej source_directory w ScriptRunConfigpliku .
Wybierz pozycję ... na końcu folderu, a następnie wybierz pozycję Przenieś , aby przenieść dane do folderu get-started .
Rejestrowanie metryk trenowania
Teraz, gdy masz już trenowanie modelu w usłudze Azure Machine Learning, zacznij śledzić niektóre metryki wydajności.
Bieżący skrypt trenowania wyświetla metryki w terminalu. Usługa Azure Machine Learning udostępnia mechanizm rejestrowania metryk z większą funkcjonalnością. Dodając kilka wierszy kodu, zyskujesz możliwość wizualizowania metryk w studio i porównywania metryk między wieloma zadaniami.
Modyfikowanie train.py w celu uwzględnienia rejestrowania
Zmodyfikuj skrypt train.py , aby zawierał dwa kolejne wiersze kodu:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')Zapisz ten plik, a następnie zamknij kartę, jeśli chcesz.
Omówienie dwóch dodatkowych wierszy kodu
W train.py uzyskujesz dostęp do obiektu run z poziomu samego skryptu trenowania przy użyciu Run.get_context() metody i używasz go do rejestrowania metryk:
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
Metryki w usłudze Azure Machine Learning to:
- Zorganizowane według eksperymentu i przebiegu, dzięki czemu można łatwo śledzić i porównywać metryki.
- Wyposażony w interfejs użytkownika, dzięki czemu można wizualizować wydajność trenowania w studio.
- Zaprojektowano pod kątem skalowania, aby zachować te korzyści nawet wtedy, gdy uruchamiasz setki eksperymentów.
Aktualizowanie pliku środowiska Conda
Skrypt train.py właśnie wziął nową zależność od azureml.core. Zaktualizuj pytorch-env.yml , aby odzwierciedlić tę zmianę:
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
Przed przesłaniem przebiegu upewnij się, że ten plik został zapisany.
Przesyłanie przebiegu do usługi Azure Machine Learning
Wybierz kartę skryptu run-pytorch.py , a następnie wybierz pozycję Zapisz i uruchom skrypt w terminalu, aby ponownie uruchomić skrypt run-pytorch.py . Upewnij się, że zmiany pytorch-env.yml zostały zapisane jako pierwsze.
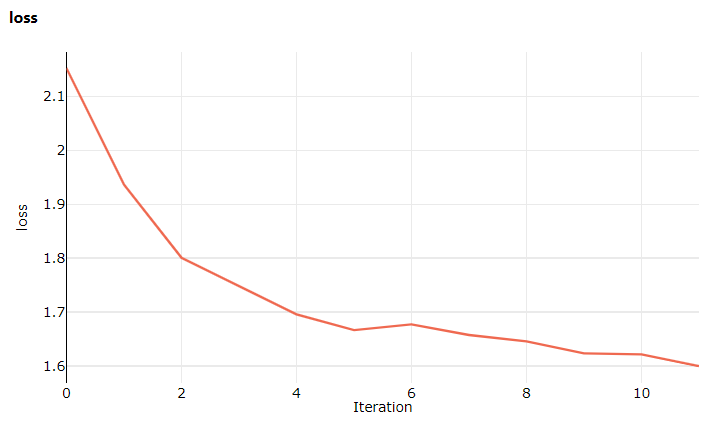
Tym razem po wizycie w studio przejdź do karty Metryki , na której można teraz zobaczyć aktualizacje na żywo dotyczące utraty trenowania modelu. Rozpoczęcie trenowania może potrwać od 1 do 2 minut.
Następne kroki
W tej sesji uaktualniono podstawowy skrypt "Hello world!" do bardziej realistycznego skryptu szkoleniowego, który wymagał uruchomienia określonego środowiska języka Python. Pokazano, jak używać wyselekcjonowanych środowisk usługi Azure Machine Learning. Na koniec pokazano, jak w kilku wierszach kodu można rejestrować metryki w usłudze Azure Machine Learning.
Istnieją inne sposoby tworzenia środowisk usługi Azure Machine Learning, w tym z pliku pip requirements.txt lub z istniejącego lokalnego środowiska Conda.
W następnej sesji zobaczysz, jak pracować z danymi w usłudze Azure Machine Learning, przekazując zestaw danych CIFAR10 na platformę Azure.
Uwaga
Jeśli chcesz ukończyć serię samouczków w tym miejscu i nie przejść do następnego kroku, pamiętaj, aby wyczyścić zasoby.