Samouczek: rozpoczynanie pracy ze skryptem języka Python w usłudze Azure Machine Learning (zestaw SDK w wersji 1, część 1 z 3)
DOTYCZY: Zestaw SDK języka Python w wersji 1
Zestaw SDK języka Python w wersji 1
W tym samouczku uruchomisz swój pierwszy skrypt języka Python w chmurze przy użyciu usługi Azure Machine Learning. Ten samouczek jest częścią 1 trzyczęściowej serii samouczków.
Ten samouczek pozwala uniknąć złożoności trenowania modelu uczenia maszynowego. Uruchomisz skrypt języka Python "Hello world" w chmurze. Dowiesz się, jak skrypt sterowania jest używany do konfigurowania i tworzenia przebiegu w usłudze Azure Machine Learning.
W tym samouczku wykonasz następujące czynności:
- Tworzenie i uruchamianie "Hello world!" Skrypt języka Python.
- Utwórz skrypt sterujący języka Python, aby przesłać tekst "Hello world!" do usługi Azure Machine Learning.
- Omówienie pojęć związanych z usługą Azure Machine Learning w skrycie sterowania.
- Prześlij i uruchom skrypt "Hello world!".
- Wyświetl dane wyjściowe kodu w chmurze.
Wymagania wstępne
- Ukończ tworzenie zasobów, których musisz rozpocząć , aby utworzyć obszar roboczy i wystąpienie obliczeniowe do użycia w tej serii samouczków.
-
- Utwórz klaster obliczeniowy oparty na chmurze. Nadaj mu nazwę "cpu-cluster", aby dopasować kod w tym samouczku.
Tworzenie i uruchamianie skryptu języka Python
Ten samouczek będzie używać wystąpienia obliczeniowego jako komputera programistycznego. Najpierw utwórz kilka folderów i skryptu:
- Zaloguj się do Azure Machine Learning studio i wybierz obszar roboczy, jeśli zostanie wyświetlony monit.
- Po lewej stronie wybierz pozycję Notesy
- Na pasku narzędzi Pliki wybierz pozycję +, a następnie wybierz pozycję Utwórz nowy folder.
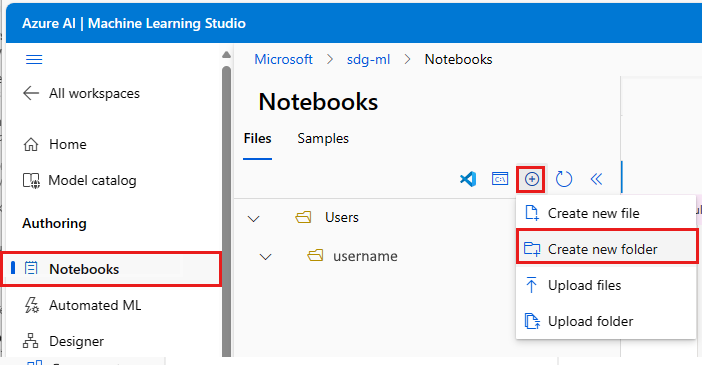
- Nadaj folderowi nazwę get-started.
- Po prawej stronie nazwy folderu użyj folderu ... , aby utworzyć inny folder w obszarze rozpoczynania pracy.
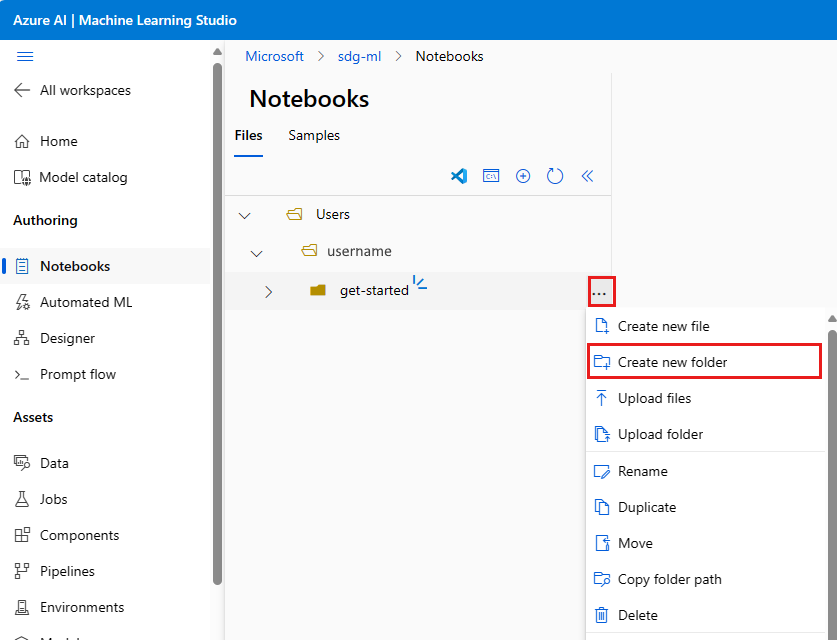
- Nazwij nowy folder src. Użyj linku Edytuj lokalizację, jeśli lokalizacja pliku jest nieprawidłowa.
- Po prawej stronie folderu src użyj ... do utworzenia nowego pliku w folderze src .
- Nadaj plikowi nazwę hello.py. Przełącz typ pliku na python (py)*.
Skopiuj ten kod do pliku:
# src/hello.py
print("Hello world!")
Struktura folderów projektu będzie teraz wyglądać następująco:
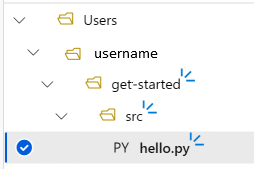
Testowanie skryptu
Możesz uruchomić kod lokalnie, co w tym przypadku oznacza wystąpienie obliczeniowe. Uruchamianie kodu lokalnie ma korzyść z interaktywnego debugowania kodu.
Jeśli wystąpienie obliczeniowe zostało wcześniej zatrzymane, uruchom je teraz za pomocą narzędzia Uruchom obliczenia po prawej stronie listy rozwijanej obliczeniowej. Poczekaj około minuty, aż stan zmieni się na Uruchomiono.

Wybierz pozycję Zapisz i uruchom skrypt w terminalu, aby uruchomić skrypt.
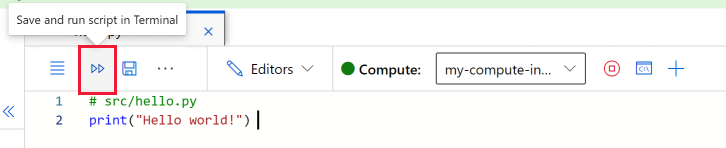
Dane wyjściowe skryptu zostaną wyświetlone w wyświetlonym oknie terminalu. Zamknij kartę i wybierz pozycję Zakończ , aby zamknąć sesję.
Tworzenie skryptu sterującego
Skrypt sterowania umożliwia uruchamianie hello.py skryptu w różnych zasobach obliczeniowych. Skrypt sterowania służy do kontrolowania sposobu i miejsca uruchamiania kodu uczenia maszynowego.
Wybierz folder ... na końcu folderu get-started , aby utworzyć nowy plik. Utwórz plik w języku Python o nazwie run-hello.py i skopiuj/wklej następujący kod do tego pliku:
# get-started/run-hello.py
from azureml.core import Workspace, Experiment, Environment, ScriptRunConfig
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-hello')
config = ScriptRunConfig(source_directory='./src', script='hello.py', compute_target='cpu-cluster')
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
Porada
Jeśli podczas tworzenia klastra obliczeniowego użyto innej nazwy, pamiętaj o dostosowaniu nazwy w kodzie compute_target='cpu-cluster' .
Zrozumienie kodu
Oto opis działania skryptu sterującego:
ws = Workspace.from_config()
Obszar roboczy łączy się z obszarem roboczym usługi Azure Machine Learning, dzięki czemu można komunikować się z zasobami usługi Azure Machine Learning.
experiment = Experiment( ... )
Eksperyment zapewnia prosty sposób organizowania wielu zadań pod pojedynczą nazwą. Później zobaczysz, jak eksperymenty ułatwiają porównywanie metryk między dziesiątkami zadań.
config = ScriptRunConfig( ... )
ScriptRunConfig opakowuje hello.py kod i przekazuje go do obszaru roboczego. Jak sugeruje nazwa, możesz użyć tej klasy do skonfigurowania sposobu uruchamianiaskryptu w usłudze Azure Machine Learning. Określa również, na jakim obiekcie obliczeniowym będzie uruchamiany skrypt. W tym kodzie docelowy jest klaster obliczeniowy utworzony w samouczku dotyczącym konfiguracji.
run = experiment.submit(config)
Przesyła skrypt. To przesłanie jest nazywane uruchomieniem. W wersji 2 zmieniono jej nazwę na zadanie. Uruchomienie/zadanie hermetyzuje pojedyncze wykonanie kodu. Użyj zadania, aby monitorować postęp skryptu, przechwytywać dane wyjściowe, analizować wyniki, wizualizować metryki i nie tylko.
aml_url = run.get_portal_url()
Obiekt run zapewnia dojście do wykonania kodu. Monitoruj postęp Azure Machine Learning studio przy użyciu adresu URL wydrukowanego ze skryptu języka Python.
Przesyłanie i uruchamianie kodu w chmurze
Wybierz pozycję Zapisz i uruchom skrypt w terminalu, aby uruchomić skrypt sterowania, który z kolei działa
hello.pyw klastrze obliczeniowym utworzonym w samouczku konfiguracji.W terminalu może zostać wyświetlony monit o zalogowanie się w celu uwierzytelnienia. Skopiuj kod i postępuj zgodnie z linkiem, aby ukończyć ten krok.
Po uwierzytelnieniu w terminalu zostanie wyświetlony link. Wybierz link, aby wyświetlić zadanie.
Uwaga
Podczas ładowania azureml_run_type_providers..., mogą pojawić się ostrzeżenia rozpoczynające się od błędu. Możesz zignorować te ostrzeżenia. Użyj linku w dolnej części tych ostrzeżeń, aby wyświetlić dane wyjściowe.
Wyświetlanie danych wyjściowych
- Na wyświetlonej stronie zostanie wyświetlony stan zadania.
- Po zakończeniu zadania wybierz pozycję Dane wyjściowe i dzienniki w górnej części strony.
- Wybierz pozycjęstd_log.txt , aby wyświetlić dane wyjściowe zadania.
Monitorowanie kodu w chmurze w programie Studio
Dane wyjściowe skryptu będą zawierać link do programu Studio, który wygląda mniej więcej tak: https://ml.azure.com/experiments/hello-world/runs/<run-id>?wsid=/subscriptions/<subscription-id>/resourcegroups/<resource-group>/workspaces/<workspace-name>.
Postępuj zgodnie z linkiem. Na początku zobaczysz stan Kolejkowane lub Przygotowywanie. Ukończenie pierwszego przebiegu potrwa od 5 do 10 minut. Dzieje się tak, ponieważ występują następujące kwestie:
- Obraz platformy Docker jest wbudowany w chmurę
- Rozmiar klastra obliczeniowego jest zmieniany z zakresu od 0 do 1 węzła
- Obraz platformy Docker jest pobierany do obliczeń.
Kolejne zadania są znacznie szybsze (~15 sekund), ponieważ obraz platformy Docker jest buforowany na obliczeniach. Możesz to przetestować, przesyłając ponownie poniższy kod po zakończeniu pierwszego zadania.
Poczekaj około 10 minut. Zostanie wyświetlony komunikat informujący o zakończeniu zadania. Następnie użyj opcji Odśwież , aby wyświetlić zmianę stanu na Ukończono. Po zakończeniu zadania przejdź do karty Dane wyjściowe i dzienniki . W tym miejscu można zobaczyć std_log.txt plik, który wygląda następująco:
1: [2020-08-04T22:15:44.407305] Entering context manager injector.
2: [context_manager_injector.py] Command line Options: Namespace(inject=['ProjectPythonPath:context_managers.ProjectPythonPath', 'RunHistory:context_managers.RunHistory', 'TrackUserError:context_managers.TrackUserError', 'UserExceptions:context_managers.UserExceptions'], invocation=['hello.py'])
3: Starting the daemon thread to refresh tokens in background for process with pid = 31263
4: Entering Job History Context Manager.
5: Preparing to call script [ hello.py ] with arguments: []
6: After variable expansion, calling script [ hello.py ] with arguments: []
7:
8: Hello world!
9: Starting the daemon thread to refresh tokens in background for process with pid = 31263
10:
11:
12: The experiment completed successfully. Finalizing job...
13: Logging experiment finalizing status in history service.
14: [2020-08-04T22:15:46.541334] TimeoutHandler __init__
15: [2020-08-04T22:15:46.541396] TimeoutHandler __enter__
16: Cleaning up all outstanding Job operations, waiting 300.0 seconds
17: 1 items cleaning up...
18: Cleanup took 0.1812913417816162 seconds
19: [2020-08-04T22:15:47.040203] TimeoutHandler __exit__
W wierszu 8 są wyświetlane dane wyjściowe "Hello world!".
Plik 70_driver_log.txt zawiera standardowe dane wyjściowe zadania. Ten plik może być przydatny podczas debugowania zadań zdalnych w chmurze.
Następne kroki
W tym samouczku wykonaliśmy prosty skrypt "Hello world!" i uruchomiliśmy go na platformie Azure. Pokazano, jak nawiązać połączenie z obszarem roboczym usługi Azure Machine Learning, utworzyć eksperyment i przesłać hello.py kod do chmury.
W następnym samouczku utworzysz te informacje, uruchamiając coś bardziej interesującego niż print("Hello world!").
Tutorial: Train a model (Samouczek: uczenie modelu)
Uwaga
Jeśli chcesz ukończyć serię samouczków w tym miejscu i nie przejść do następnego kroku, pamiętaj, aby wyczyścić zasoby.