Tworzenie zestawów danych usługi Azure Machine Learning na podstawie zestawów danych usługi Azure Open
Z tego artykułu dowiesz się, jak przenieść wyselekcjonowane dane wzbogacania do lokalnych lub zdalnych eksperymentów uczenia maszynowego przy użyciu zestawów danych usługi Azure Machine Learning i zestawów danych usługi Azure Open Datasets.
Zestaw danych usługi Azure Machine Learning umożliwia utworzenie odwołania do lokalizacji źródła danych wraz z kopią jego metadanych. Ponieważ zestawy danych są lazily oceniane i ponieważ dane pozostają w istniejącej lokalizacji, ty
- Nie ryzykuj niezamierzonych zmian w oryginalnych źródłach danych
- Poniesienie dodatkowych kosztów magazynowania
- Zwiększanie szybkości przepływów pracy uczenia maszynowego
Aby uzyskać więcej informacji na temat tego, gdzie zestawy danych mieszczą się w ogólnym przepływie pracy dostępu do danych usługi Azure Machine Learning, odwiedź artykuł Bezpieczny dostęp do danych .
Zestawy danych Platformy Azure Open to wyselekcjonowane publiczne zestawy danych, które dodają funkcje specyficzne dla scenariusza, aby wzbogacić rozwiązania predykcyjne i zwiększyć dokładność tych rozwiązań. Odwiedź zasób katalogu Open Datasets dla danych domeny publicznej, które mogą pomóc w trenowaniu modeli uczenia maszynowego — na przykład:
- Kondycja i genomiki
- Praca i ekonomia
- Populacja i bezpieczeństwo
- Dodatkowe i typowe zestawy danych
- Transport
Otwarte zestawy danych są hostowane w chmurze na platformie Microsoft Azure. Obejmuje to zarówno zestaw SDK języka Python usługi Azure Machine Learning, jak i usługę Azure Machine Learning Studio .
Wymagania wstępne
Należy wykonać:
Subskrypcja Azure. Jeśli nie masz subskrypcji, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Learning.
Obszar roboczy usługi Azure Machine Learning.
Zainstalowany zestaw SDK usługi Azure Machine Learning dla języka Python, który zawiera
azureml-datasetspakiet.- Tworzenie wystąpienia obliczeniowego usługi Azure Machine Learning — w pełni skonfigurowane i zarządzane środowisko programistyczne obejmujące zintegrowane notesy i zestaw SDK już zainstalowany.
OR
- Współpracuj we własnym środowisku języka Python i zainstaluj zestaw SDK samodzielnie, korzystając z tych instrukcji.
Uwaga
Niektóre klasy zestawów danych mają zależności od pakietu azureml-dataprep . Ten pakiet jest zgodny tylko z 64-bitowym językiem Python. W przypadku użytkowników systemu Linux te klasy są obsługiwane tylko w następujących dystrybucjach systemu Linux:
- Debian (8, 9)
- Fedora (27, 28)
- Red Hat Enterprise Linux (7, 8)
- Ubuntu (14.04, 16.04, 18.04)
Tworzenie zestawów danych przy użyciu zestawu SDK
Aby utworzyć zestawy danych usługi Azure Machine Learning za pomocą klas Azure Open Datasets, w zestawie SDK języka Python upewnij się, że pakiet został zainstalowany za pomocą polecenia pip install azureml-opendatasets. W zestawie SDK klasa każdego odrębnego zestawu danych reprezentuje klasę, a niektóre klasy są dostępne jako typ danych usługi Azure Machine Learning FileDataset , typ danych usługi Azure Machine Learning TabularDataset lub oba te typy. Zapoznaj się z dokumentacją referencyjną, aby uzyskać pełną listę opendatasets klas.
Niektóre klasy można pobrać opendatasets jako TabularDataset zasoby lub FileDataset . Następnie można manipulować plikami i/lub pobierać je bezpośrednio. Inne klasy mogą pobierać zestaw danych tylko z użyciem get_tabular_dataset() funkcji lub get_file_dataset() z Datasetklasy w zestawie SDK języka Python.
Ten kod pokazuje, że klasa MNIST opendatasets może zwrócić wartość a TabularDataset lub FileDataset:
from azureml.core import Dataset
from azureml.opendatasets import MNIST
# MNIST class can return either TabularDataset or FileDataset
tabular_dataset = MNIST.get_tabular_dataset()
file_dataset = MNIST.get_file_dataset()
W tym przykładzie klasa Diabetes opendatasets jest dostępna tylko jako TabularDataset. Wymaga to użycia polecenia get_tabular_dataset().
from azureml.opendatasets import Diabetes
from azureml.core import Dataset
# Diabetes class can return ONLY TabularDataset and must be called from the static function
diabetes_tabular = Diabetes.get_tabular_dataset()
Rejestrowanie zestawów danych
Zarejestruj zestaw danych usługi Azure Machine Learning w obszarze roboczym, aby udostępnić zestaw danych innym osobom i użyć go ponownie w eksperymentach w obszarze roboczym. Po zarejestrowaniu zestawu danych usługi Azure Machine Learning utworzonego na podstawie otwartych zestawów danych żadne dane nie są natychmiast pobierane, ale dane staną się dostępne później (na przykład podczas trenowania) po zażądaniu z centralnej lokalizacji magazynu.
Aby zarejestrować zestawy danych w obszarze roboczym, użyj register() metody .
titanic_ds = titanic_ds.register(workspace=workspace,
name='titanic_ds',
description='titanic training data')
Tworzenie zestawów danych za pomocą programu Studio
Zestawy danych usługi Azure Machine Learning można również tworzyć z poziomu usługi Azure Open Datasets za pomocą usługi Azure Machine Learning Studio. Ten skonsolidowany interfejs internetowy obejmuje narzędzia uczenia maszynowego do wykonywania scenariuszy nauki o danych dla praktyków nauki o danych na wszystkich poziomach umiejętności.
Uwaga
Zestawy danych utworzone za pośrednictwem usługi Azure Machine Learning Studio są automatycznie rejestrowane w obszarze roboczym.
W obszarze roboczym wybierz pozycję Dane w lewym okienku nawigacyjnym. Na karcie Zasoby danych wybierz pozycję Utwórz, jak pokazano na tym zrzucie ekranu:

Na następnym ekranie dodaj nazwę i opcjonalny opis nowego zasobu danych. Następnie wybierz pozycję Tabelaryczny na liście rozwijanej Typ , jak pokazano na poniższym zrzucie ekranu:

Na następnym ekranie wybierz pozycję Z usługi Azure Open Datasets, a następnie wybierz pozycję Dalej, jak pokazano na poniższym zrzucie ekranu:

Na następnym ekranie wybierz dostępny zestaw danych Azure Open. Na tym zrzucie ekranu wybrano zestaw danych dotyczących bezpieczeństwa w San Francisco:

W razie potrzeby przewiń w dół i wybierz pozycję Dalej, jak pokazano na poniższym zrzucie ekranu:

Opcjonalnie przefiltruj dane za pomocą dostępnych filtrów odpowiednich dla wybranego zestawu danych. W przypadku zestawu danych dotyczących bezpieczeństwa w San Francisco ustawiliśmy filtrowany zakres dat między datą początkową 1 lipca 2024 r. a 17 lipca 2024 r. Wybierz pozycję Dalej, jak pokazano na tym zrzucie ekranu:
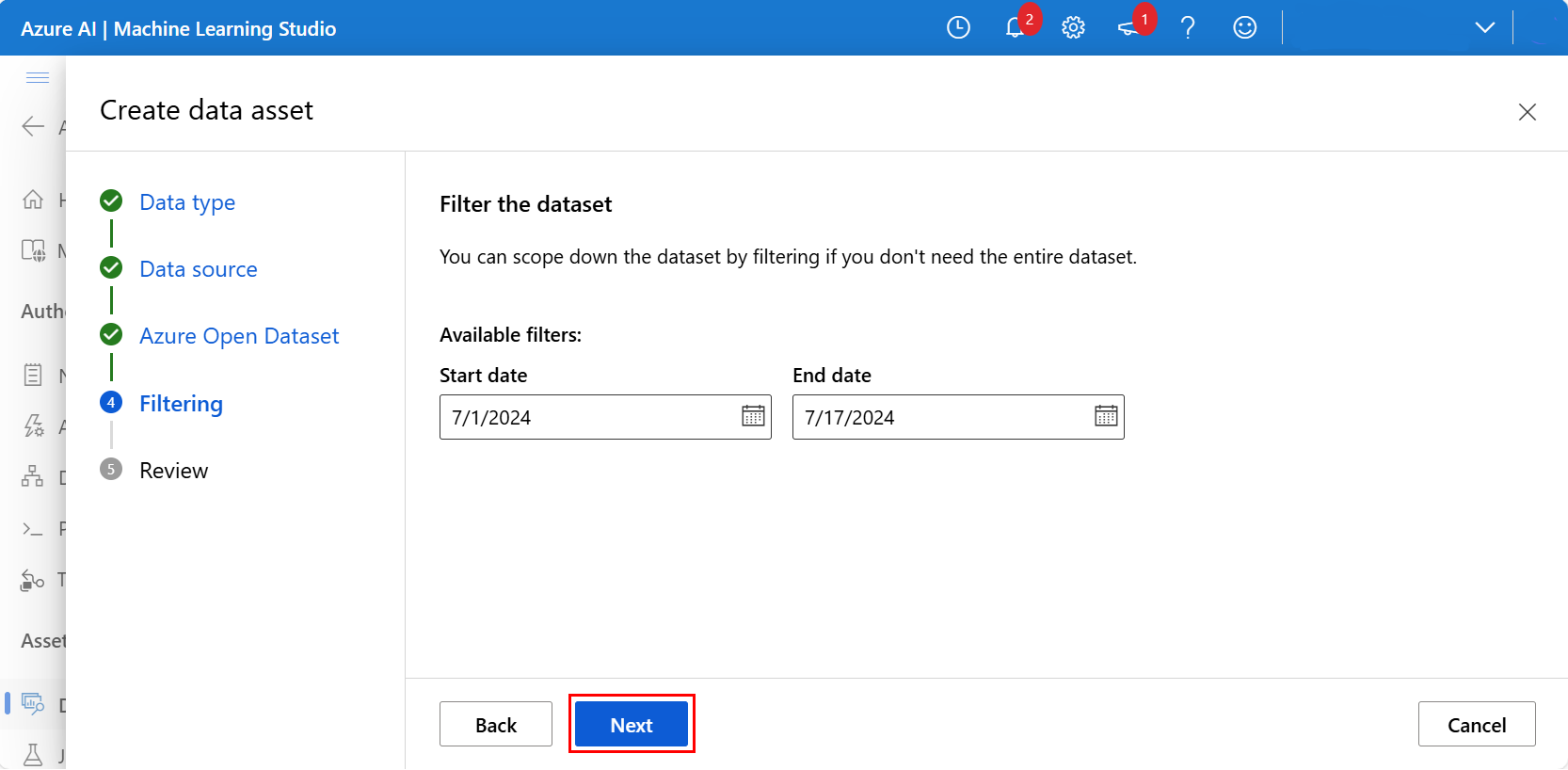
Na następnym ekranie przejrzyj ustawienia nowego zasobu danych i wprowadź wszelkie niezbędne zmiany. Gdy wygląda to dobrze, wybierz pozycję Utwórz , jak pokazano na poniższym zrzucie ekranu:

Aby uzyskać więcej informacji na temat opisów pól i zakresów dat dla zestawu danych danych dotyczących bezpieczeństwa w San Francisco, odwiedź zasób danych dotyczących bezpieczeństwa w San Francisco. Aby uzyskać więcej informacji na temat innych zestawów danych, odwiedź zasób katalogu azure Open Datasets.







Zestaw danych jest teraz dostępny w obszarze Roboczym w obszarze Zestawy danych. Można go używać w taki sam sposób, jak w przypadku innych utworzonych zestawów danych.
Uzyskiwanie dostępu do zestawów danych dla eksperymentów
Użyj zestawów danych w eksperymentach uczenia maszynowego na potrzeby trenowania modeli uczenia maszynowego. Aby uzyskać więcej informacji, odwiedź stronę Dowiedz się więcej na temat trenowania za pomocą zestawów danych.
Przykładowe notesy
Aby zapoznać się z przykładami i pokazami funkcji Open Datasets, zapoznaj się z tymi przykładowymi notesami.
Następne kroki
- Trenowanie pierwszego modelu uczenia maszynowego.
- Trenowanie przy użyciu zestawów danych.
- Tworzenie zestawu danych usługi Azure Machine Learning.