Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano obsługę niezawodności w usłudze Azure HDInsight oraz omówiono strefy dostępnościoraz odzyskiwanie między regionami i ciągłość działalności biznesowej. Aby uzyskać bardziej szczegółowe omówienie niezawodności na platformie Azure, zobacz Niezawodność platformy Azure.
Obsługa strefy dostępności
Strefy dostępności są fizycznie oddzielnymi grupami centrów danych w regionie świadczenia usługi Azure. Gdy jedna strefa ulegnie awarii, usługi mogą przejść w tryb failover do jednej z pozostałych stref.
Usługa Azure HDInsight obsługuje konfigurację wdrożenia strefowego. Węzły klastra usługi Azure HDInsight są umieszczane w jednej strefie wybranej w wybranym regionie. Strefowy klaster usługi HDInsight jest odizolowany od wszelkich awarii występujących w innych strefach. Jeśli jednak awaria wpłynie na konkretną strefę wybraną dla klastra usługi HDInsight, klaster nie będzie dostępny. Ten model wdrożenia zapewnia niedrogą łączność sieciową o niskiej latencji w klastrze. Replikowanie tego modelu wdrażania do wielu stref dostępności może zapewnić wyższy poziom dostępności w celu ochrony przed awariami sprzętowymi.
Ważna
W przypadku wdrożeń, w których użytkownicy nie określają określonej strefy, typy węzłów nie są odporne na strefy i mogą wystąpić przestoje podczas przestoju w dowolnej strefie w tym regionie.
Wymagania wstępne
Strefy dostępności są obsługiwane tylko w przypadku klastrów utworzonych po 15 czerwca 2023 r. Nie można zaktualizować ustawień strefy dostępności po utworzeniu klastra. Nie można również zaktualizować istniejącego klastra bez stref dostępności w celu korzystania ze stref dostępności.
Klastry muszą być tworzone w ramach niestandardowej sieci VNet.
Musisz zapewnić własną bazę danych SQL dla Ambari oraz zewnętrzny magazyn metadanych, taki jak metastore Hive, aby móc skonfigurować te bazy danych w tej samej strefie dostępności.
Klastry usługi HDInsight należy utworzyć z opcją strefy dostępności w jednym z następujących regionów:
- Australia Wschodnia
- Brazylia Południowa
- Kanada Środkowa
- Środkowe stany USA
- Wschodnie stany USA
- Wschodnie stany USA 2
- Francja Środkowa
- Niemcy Środkowo-Zachodnie
- Japonia Wschodnia
- Korea Środkowa
- Europa Północna
- Katar Środkowy
- Azja Południowo-Wschodnia
- Południowo-środkowe stany USA
- Południowe Zjednoczone Królestwo
- US Gov Wirginia
- Europa Zachodnia
- Zachodnie stany USA 2
Tworzenie klastra usługi HDInsight przy użyciu strefy dostępności
Szablon usługi Azure Resource Manager (ARM) umożliwia uruchomienie klastra usługi HDInsight w określonej strefie dostępności.
W sekcji resources (zasoby) należy dodać sekcję "zones" (strefy) i określić strefę dostępności, do której ma zostać wdrożony ten klaster.
"resources": [
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('cluster name')]",
"location": "East US 2",
"zones": [
"1"
],
}
]
Weryfikowanie węzłów w jednej strefie dostępności oraz w różnych strefach.
Gdy klaster usługi HDInsight jest gotowy, możesz sprawdzić lokalizację, aby sprawdzić, w której strefie dostępności są one wdrażane.
Uzyskiwanie odpowiedzi z API:
[
{
"location": "East US 2",
"zones": [
"1"
],
}
]
Zwiększyć rozmiar klastra
Klaster usługi HDInsight można skalować w górę przy użyciu większej liczby węzłów roboczych. Nowo dodane węzły robocze zostaną umieszczone w tej samej strefie dostępności tego klastra.
Migracja strefy dostępności
Klastry usługi Azure HDInsight obecnie nie obsługują migracji bezpośredniej istniejących instancji do obsługi stref dostępności. Można jednak ponownie utworzyć klaster i wybrać inną strefę dostępności lub region podczas tworzenia klastra. Pomocniczy klaster rezerwowy w innym regionie i innej strefie dostępności można wykorzystać w scenariuszach odzyskiwania po awarii.
Doświadczenie redukcji strefy
Gdy strefa dostępności ulegnie awarii:
- Nie można połączyć się z tym klastrem za pomocą protokołu SSH.
- Nie można usunąć ani skalować w górę ani skalować w dół tego klastra.
- Nie można przesyłać zadań ani wyświetlać historii zadań.
- Nadal możesz przesłać nowe żądanie utworzenia klastra w innym regionie.
Odzyskiwanie po awarii między regionami i ciągłość działania
Odzyskiwanie po awarii (DR) odnosi się do praktyk używanych przez organizacje do odzyskiwania po wystąpieniu zdarzeń o dużym wpływie, takich jak klęski żywiołowe lub nieudane wdrożenia, które powodują przestoje i utratę danych. Niezależnie od przyczyny najlepszym rozwiązaniem dla awarii jest dobrze zdefiniowany i przetestowany plan odzyskiwania po awarii oraz projekt aplikacji, który aktywnie obsługuje odzyskiwanie po awarii. Przed rozpoczęciem tworzenia planu odzyskiwania po awarii zobacz Zalecenia dotyczące projektowania strategii odzyskiwania po awarii.
W przypadku DR firma Microsoft używa modelu wspólnej odpowiedzialności . W tym modelu firma Microsoft zapewnia dostępność podstawowej infrastruktury i usług platformy. Jednak wiele usług platformy Azure nie replikuje automatycznie danych ani nie wraca z regionu, w którym wystąpił błąd, aby przeprowadzić replikację krzyżową do innego włączonego regionu. W przypadku tych usług odpowiadasz za skonfigurowanie planu odzyskiwania danych po awarii, który jest dostosowany do Twojego obciążenia. Większość usług oferty platformy Azure jako usługa (PaaS) udostępnia funkcje i wskazówki wspierające DR. Możesz użyć funkcji specyficznych dla usługi, aby wspierać szybkie odzyskiwanie i ułatwić opracowanie planu odzyskiwania po awarii.
Klastry usługi Azure HDInsight zależą od wielu usług platformy Azure, takich jak magazyn, bazy danych, usługi Active Directory, usługi Active Directory Domain Services, sieć i usługa Key Vault. Dobrze zaprojektowana, wysoce dostępna i odporna na uszkodzenia aplikacja analityczna powinna być zaprojektowana z wystarczającą nadmiarowością, aby wytrzymać regionalne lub lokalne zakłócenia w co najmniej jednej z tych usług. Ta sekcja zawiera omówienie najlepszych rozwiązań, dostępności pojedynczego i wielu regionów oraz opcji optymalizacji planowania ciągłości działania.
Odzyskiwanie po awarii w lokalizacji geograficznej obejmującej wiele regionów
Zwiększenie ciągłości biznesowej poprzez międzyregionalny plan odzyskiwania awaryjnego o wysokiej dostępności wymaga projektów architektonicznych o większej złożoności i wyższych kosztach. W poniższych tabelach opisano niektóre obszary techniczne, które mogą zwiększyć całkowity koszt posiadania.
Optymalizacje kosztów
| Obszar | Przyczyna eskalacji kosztów | Strategie optymalizacji |
|---|---|---|
| Magazyn danych | Duplikowanie podstawowych danych/tabel w regionie pomocniczym | Replikowanie tylko wyselekcjonowanych danych |
| Wypływ danych | Transfery danych wychodzących między regionami wiążą się z kosztami. Zapoznaj się z wytycznymi dotyczącymi cen przepustowości | Replikowanie tylko wyselekcjonowanych danych w celu zmniejszenia wychodzącego ruchu danych z regionu. |
| Obliczenia klastra | Dodatkowy klaster usługi HDInsight w regionie drugorzędnym | Użyj zautomatyzowanych skryptów, aby wdrożyć pomocnicze zasoby obliczeniowe po awarii podstawowej. Użyj skalowania automatycznego, aby zachować minimalny rozmiar klastra pomocniczego. Użyj tańszych SKU dla maszyn wirtualnych. Utwórz pomocnicze w regionach, w których jednostki SKU maszyn wirtualnych mogą być dyskontowane. |
| Authentication | Scenariusze z wieloma użytkownikami w regionie pomocniczym powodują dodatkowe konfiguracje usług Microsoft Entra Domain Services | Unikaj konfiguracji wielu użytkowników w regionie pomocniczym. |
Optymalizacje złożoności
| Obszar | Przyczyna eskalacji złożoności | Strategie optymalizacji |
|---|---|---|
| Schematy odczytu i zapisu | Wymaganie włączenia odczytu i zapisu zarówno podstawowego, jak i pomocniczego | Zaprojektuj element wtórny jako tylko do odczytu |
| Zero RPO (Zerowy Cel Punktu Odzyskiwania) i RTO (Zerowy Cel Czasu Odzyskiwania) | Wymaganie zerowej utraty danych (RPO=0) i zerowego przestoju (RTO=0) | Zaprojektuj RPO i RTO w sposób, aby zmniejszyć liczbę składników, które wymagają failover. Aby uzyskać więcej informacji na temat RTO (Cel Czasu Odzyskiwania) i RPO (Cel Punktu Odzyskiwania), zobacz Azure HDInsight architektury ciągłości biznesowej. |
| Funkcje biznesowe | Wymaganie pełnej funkcjonalności biznesowej podstawowej w pomocniczej wersji | Oceń, czy można uruchomić z absolutnie minimalnym krytycznym podzbiorem funkcjonalności biznesowej w środowisku zapasowym. |
| Łączność | Wymaganie, aby wszystkie systemy nadrzędne i podrzędne z głównego były podłączone do dodatkowego. | Ogranicz łączność pomocniczą do absolutnie niezbędnego krytycznego podzestawu. |
Podczas tworzenia planu odzyskiwania po awarii w wielu regionach należy wziąć pod uwagę następujące zalecenia:
Określ minimalną funkcjonalność biznesową, której potrzebujesz, jeśli wystąpi awaria i dlaczego. Na przykład oceń, czy potrzebujesz możliwości trybu failover dla warstwy przekształcania danych (pokazanej na żółtym) i warstwie obsługującej dane (pokazanej na niebiesko) lub jeśli potrzebujesz tylko trybu failover dla warstwy usługi danych.
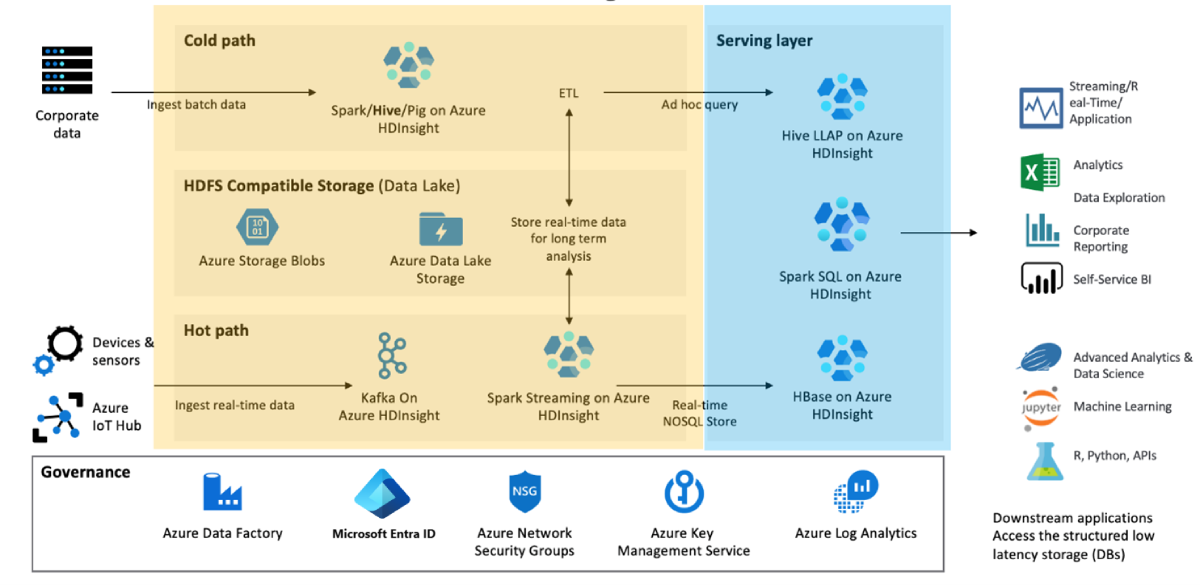
Segmentuj klastry na podstawie obciążenia, cyklu projektowania i działów. Posiadanie większej liczby klastrów zmniejsza prawdopodobieństwo wystąpienia pojedynczego dużego błędu wpływającego na wiele różnych procesów biznesowych.
Przełącz swoje regiony pomocnicze na tryb tylko do odczytu. Regiony trybu failover z możliwościami odczytu i zapisu mogą prowadzić do złożonych architektur.
Klastry przejściowe są łatwiejsze do zarządzania w przypadku awarii. Zaprojektuj obciążenia w taki sposób, aby klastry mogły być rotowane i żaden stan nie był w nich utrzymywany.
Często zadania robocze pozostają niedokończone w przypadku katastrofy, wymagając ponownego uruchomienia w nowym regionie. Zaprojektuj obciążenia jako idempotentne w naturze.
Używaj automatyzacji podczas wdrożeń klastrów i upewnij się, że ustawienia konfiguracji klastrów są skryptowane w miarę możliwości, aby zapewnić szybkie i w pełni zautomatyzowane wdrażanie w razie awarii.
Wykrywanie, powiadamianie i zarządzanie awariami
Użyj narzędzi do monitorowania platformy Azure w usłudze HDInsight, aby wykryć nietypowe zachowanie w klastrze i ustawić odpowiednie powiadomienia o alertach. Możesz wdrożyć wstępnie skonfigurowane rozwiązania do zarządzania specyficzne dla klastra usługi HDInsight, które zbierają ważne metryki wydajności określonego typu klastra. Aby uzyskać więcej informacji, zobacz Azure Monitoring for HDInsight (Monitorowanie platformy Azure dla usługi HDInsight).
Subskrybuj alerty dotyczące stanu platformy Azure, aby otrzymywać powiadomienia o problemach z usługą, planowanym utrzymaniu, stanie i zaleceniach dotyczących bezpieczeństwa dla subskrypcji, usługi lub regionu. Powiadomienia zdrowotne, które obejmują przyczynę problemu i przewidywany czas rozwiązania, pomagają lepiej wykonywać przełączanie awaryjne i powroty do działania. Aby uzyskać więcej informacji, zobacz dokumentację usługi Azure Service Health.
Odzyskiwanie po awarii w lokalizacji geograficznej z jednym regionem
Każdy składnik w podstawowym systemie usługi HDInsight ma własne mechanizmy odporności na uszkodzenia w jednym regionie. Należy pamiętać, że nie zawsze potrzeba katastrofalnego zdarzenia, aby wpłynąć na funkcjonalność biznesu. Incydenty serwisowe w jednej lub więcej z następujących usług w jednym regionie mogą również prowadzić do utraty oczekiwanej funkcjonalności biznesowej.
Obliczenia (maszyny wirtualne): klaster usługi Azure HDInsight. HDInsight oferuje dostępność na poziomie SLA 99,9%%. Aby zapewnić wysoką dostępność w jednym wdrożeniu, usługa HDInsight jest domyślnie dołączona do wielu usług, które są w trybie wysokiej dostępności. Mechanizmy tolerancji błędów w HDInsight są zapewniane zarówno przez usługi wysokiej dostępności firmy Microsoft, jak i przez ekosystem Apache OSS.
Następujące składniki infrastruktury zostały zaprojektowane pod kątem wysokiej dostępności:
- Aktywne i rezerwowe węzły główne
- Wiele węzłów bramy sieciowej
- Trzy węzły kworum Zookeepera
- Węzły robocze przydzielane według domen błędów i aktualizacji
Następujące usługi są również zaprojektowane pod kątem wysokiej dostępności:
- Apache Ambari Serwer
- Serwer osi czasu aplikacji dla usługi YARN
- Serwer historii zadań dla usługi Hadoop MapReduce
- Apache Livy
- HDFS
- Menadżer Zasobów YARN
- HBase Master
Aby dowiedzieć się więcej, zobacz usługi wysokiej dostępności obsługiwane przez usługę Azure HDInsight.
Magazyny metadanych: Azure SQL Database. Usługa HDInsight używa usługi Azure SQL Database jako metabazy danych, która zapewnia dostępność na poziomie umowy SLA 99,99%. Trzy repliki danych są utrwalane w centrum danych z replikacją synchroniczną. Jeśli wystąpi utrata repliki, replika alternatywna jest obsługiwana bezproblemowo. Aktywna georeplikacja jest obsługiwana domyślnie z maksymalnie czterema centrami danych. W przypadku przełączenia, czy to ręcznego, czy awarii centrum danych, pierwsza replika w hierarchii automatycznie uzyskuje możliwość odczytu i zapisu. Aby uzyskać więcej informacji, zobacz Ciągłość działalności biznesowej usługi Azure SQL Database.
Magazyn: Azure Data Lake Gen2 lub Blob Storage. HDInsight poleca Azure Data Lake Storage Gen2 jako podstawową warstwę pamięci. Usługa Azure Storage, w tym Azure Data Lake Storage Gen2, zapewnia SLA na poziomie 99,9%. Usługa HDInsight używa usługi LRS, w której trzy repliki danych są utrwalane w centrum danych, a replikacja jest synchroniczna. W przypadku utraty repliki, obsługa repliki odbywa się bez zakłóceń.
Uwierzytelnianie: Microsoft Entra ID, Microsoft Entra Domain Services, Enterprise Security Package.
- Microsoft Entra ID zapewnia SLA na poziomie 99,9%. Active Directory to usługa globalna z wieloma poziomami nadmiarowości wewnętrznej i automatycznej możliwości odzyskiwania. Aby uzyskać więcej informacji, zobacz, jak firma Microsoft stale poprawia niezawodność identyfikatora Entra firmy Microsoft.
- Microsoft Entra Domain Services zapewnia dostępność zgodną z SLA na poziomie 99,9%. Microsoft Entra Domain Services to usługa o wysokiej dostępności hostowana w globalnie rozproszonych centrach danych. Zestawy replik to funkcja w wersji zapoznawczej w usługach Microsoft Entra Domain Services, która umożliwia geograficzne odzyskiwanie po awarii, jeśli region świadczenia usługi Azure przejdzie w tryb offline. Aby uzyskać więcej informacji, zobacz pojęcia i funkcje zestawów replik dla usług Microsoft Entra Domain Services.
- Usługa Azure DNS zapewnia umowę dotyczącą SLA na poziomie 100%. Usługa HDInsight używa usługi Azure DNS w różnych miejscach do rozpoznawania nazw domen.
Opcjonalne usługi, takie jak Azure Key Vault i Azure Data Factory.
