Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Uwaga / Notatka
Magazyny wiedzy to magazyn pomocniczy, który istnieje w usłudze Azure Storage i zawiera dane wyjściowe zestawów umiejętności usługi Azure AI Search. Są one oddzielone od źródeł wiedzy i baz wiedzy, które są używane w przepływach pracy agentowego pobierania danych.
Projekcje definiują tabele fizyczne, obiekty i pliki w magazynie wiedzy, które odbierają zawartość z potoku wzbogacania danych w usłudze Azure AI Search. Podczas tworzenia magazynu wiedzy większość pracy skupia się na definiowaniu i kształtowaniu projekcji.
W tym artykule przedstawiono koncepcje projekcji i przepływ pracy, dzięki czemu przed rozpoczęciem kodowania masz pewne doświadczenie.
Projekcje są definiowane w zestawach umiejętności usługi Azure AI Search, ale wyniki końcowe to projekcje plików tabel, obiektów i obrazów w usłudze Azure Storage.
Typy projekcji i użycia
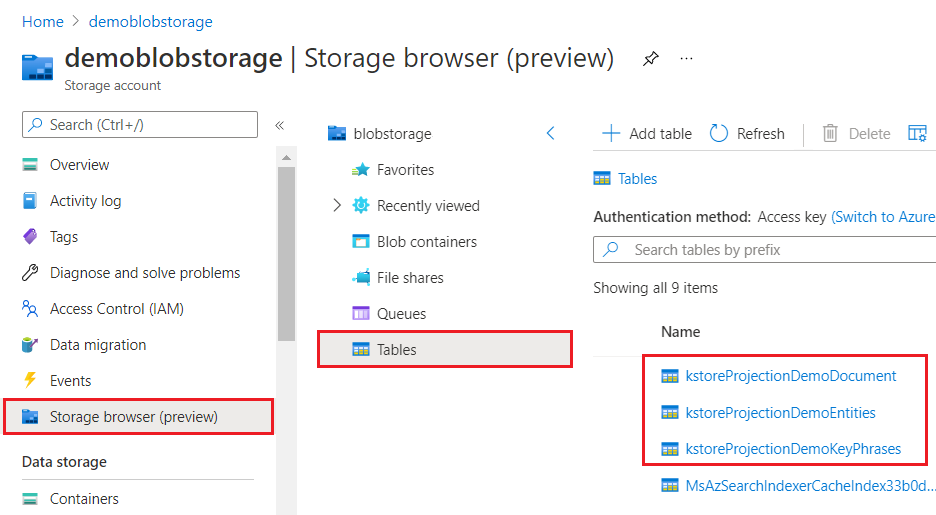
Magazyn wiedzy to konstrukcja logiczna, która jest fizycznie wyrażana jako luźna kolekcja tabel, obiektów JSON lub plików obrazów binarnych w usłudze Azure Storage.
| Projection | Magazyn | Usage |
|---|---|---|
| Tables | Azure Table Storage (usługa przechowywania danych w tabelach) | Służy do danych najlepiej reprezentowanych jako wiersze i kolumny lub zawsze, gdy potrzebujesz szczegółowych reprezentacji danych (na przykład jako ramek danych). Projekcje tabel umożliwiają definiowanie schematu kształtu przy użyciu umiejętności kształtowania lub używania wbudowanych kształtów do określania kolumn i wierszy. Zawartość można organizować w wiele tabel na podstawie znanych zasad normalizacji. Tabele, które znajdują się w tej samej grupie, są automatycznie powiązane. |
| Objects | Azure Blob Storage | Używany, gdy potrzebujesz pełnej reprezentacji JSON danych i ulepszeń w jednym dokumencie JSON. Podobnie jak w przypadku projekcji tabel, tylko prawidłowe obiekty JSON mogą być projektowane jako obiekty, a kształtowanie może pomóc w tym celu. |
| Files | Azure Blob Storage | Służy do zapisywania znormalizowanych plików obrazów binarnych. |
Definicja projekcji
Projekcje są określane w ramach właściwości "knowledgeStore" w zestawie umiejętności. Definicje projekcji są używane podczas wywołania indeksatora do tworzenia i ładowania obiektów w usłudze Azure Storage z wzbogaconą zawartością. Jeśli nie znasz tych pojęć, zacznij od wzbogacania sztucznej inteligencji, aby zapoznać się z wprowadzeniem.
Poniższy przykład ilustruje umieszczanie projekcji w bazie knowledgeStore i podstawową konstrukcję. Nazwa, typ i źródło zawartości tworzą definicję projekcji.
"knowledgeStore" : {
"storageConnectionString": "DefaultEndpointsProtocol=https;AccountName=<Acct Name>;AccountKey=<Acct Key>;",
"projections": [
{
"tables": [
{ "tableName": "ks-museums-main", "generatedKeyName": "ID", "source": "/document/tableprojection" },
{ "tableName": "ks-museumEntities", "generatedKeyName": "ID","source": "/document/tableprojection/Entities/*" }
],
"objects": [
{ "storageContainer": "ks-museums", "generatedKeyName": "ID", "source": "/document/objectprojection" }
],
"files": [ ]
}
]
Grupy projekcji
Projekcje to zbiór złożonych kolekcji, co oznacza, że można określić wiele zestawów dla każdego typu. Często używa się tylko jednej grupy projekcji, ale można użyć wielu, jeśli wymagania dotyczące przechowywania danych obejmują obsługę różnych narzędzi i scenariuszy. Na przykład można użyć jednej grupy do projektowania i debugowania zestawu umiejętności, podczas gdy drugi zestaw zbiera dane wyjściowe używane dla aplikacji online, a trzeci dla obciążeń nauki o danych.
Te same dane wyjściowe zestawu umiejętności służą do wypełniania wszystkich grup w ramach projekcji. Poniższy przykład przedstawia dwa.
"knowledgeStore" : {
"storageConnectionString": "DefaultEndpointsProtocol=https;AccountName=<Acct Name>;AccountKey=<Acct Key>;",
"projections": [
{
"tables": [],
"objects": [],
"files": []
},
{
"tables": [],
"objects": [],
"files": []
}
]
}
Grupy projekcji mają następujące kluczowe cechy wzajemnej wyłączności i powiązań.
| Principle | Description |
|---|---|
| Wzajemna wyłączność | Każda grupa jest w pełni odizolowana od innych grup, aby obsługiwać różne scenariusze kształtowania danych. Jeśli na przykład testujesz różne struktury i kombinacje tabel, każdy zestaw zostanie umieszczony w innej grupie projekcji na potrzeby testowania AB. Każda grupa pozyskuje dane z tego samego źródła (drzewa wzbogacania), ale jest całkowicie odizolowana od kombinacji tabeli-obiektu-pliku dowolnych grup projekcyjnych równorzędnych. |
| Relatedness | W grupie projekcji zawartość w tabelach, obiektach i plikach są powiązane. Repozytorium wiedzy używa wygenerowanych kluczy jako punktów odniesienia do wspólnego węzła nadrzędnego. Rozważmy na przykład scenariusz, w którym masz dokument zawierający obrazy i tekst. Można rzutować tekst do tabel i obrazów do plików binarnych, a zarówno tabele, jak i obiekty mają kolumnę/właściwość zawierającą adres URL pliku. |
Projekcja „źródło”
Parametr źródłowy jest trzecim składnikiem definicji projekcji. Ponieważ projekcje przechowują dane z potoku wzbogacania sztucznej inteligencji, źródłem projekcji jest zawsze dane wyjściowe umiejętności. W związku z tym dane wyjściowe mogą być pojedynczym polem (na przykład polem przetłumaczonego tekstu), ale często jest to odwołanie do kształtu danych.
Formy danych wynikają z twojego zestawu umiejętności. Wśród wszystkich wbudowanych umiejętności dostępnych w usłudze Azure AI Search istnieje umiejętność narzędziowa nazywana umiejętnością kształtowania używaną do tworzenia kształtów danych. Możesz uwzględnić umiejętności kształtowania (w dowolnej liczbie), aby obsługiwać projekcje w repozytorium wiedzy.
Kształty są często używane z projekcjami tabel, gdzie kształt nie tylko określa, które wiersze trafiają do tabeli, ale również które kolumny są tworzone (kształt można także przekazać do projekcji obiektu).
Kształty mogą być złożone i są poza zakresem, aby szczegółowo omówić je tutaj, ale poniższy przykład krótko ilustruje podstawowy kształt. Dane wyjściowe Shaper skill są określane jako źródło projekcji tabeli. W projekcji tabeli będą kolumny "metadata-storage_path", "reviews_text", "reviews_title" i tak dalej, jak określono w schemacie.
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "ShaperForTables",
"description": null,
"context": "/document",
"inputs": [
{
"name": "metadata_storage_path",
"source": "/document/metadata_storage_path",
"sourceContext": null,
"inputs": []
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "reviews_username",
"source": "/document/reviews_username"
},
],
"outputs": [
{
"name": "output",
"targetName": "mytableprojection"
}
]
}
Cykl życia projekcji
Projekcje mają cykl życia powiązany z danymi źródłowymi w źródle danych. W miarę aktualizowania i ponownego indeksowania danych źródłowych projekcje są aktualizowane z wynikami wzbogacenia, dzięki czemu projekcje są ostatecznie zgodne z danymi w źródle danych. Jednak projekcje są również przechowywane niezależnie w usłudze Azure Storage. Nie zostaną usunięte, gdy indeksator lub sama usługa wyszukiwania zostanie usunięta.
Konsumuj w aplikacjach
Po uruchomieniu indeksatora połącz się z projekcjami i zużyj dane w innych aplikacjach i obciążeniach.
Użyj witryny Azure Portal, aby zweryfikować tworzenie obiektów i zawartość w usłudze Azure Storage.
Użyj usługi Power BI do eksploracji danych. To narzędzie działa najlepiej, gdy dane są w usłudze Azure Table Storage. W usłudze Power BI można manipulować danymi w nowych tabelach, które są łatwiejsze do wykonywania zapytań i analizowania.
Użyj wzbogaconych danych w kontenerze obiektów blob w potoku nauki o danych. Można na przykład załadować dane z blobów do ramki danych Pandas.
Jeśli na koniec musisz wyeksportować dane z magazynu wiedzy, usługa Azure Data Factory ma łączniki do eksportowania danych i wylądowania ich w wybranej bazie danych.
Lista kontrolna dotycząca rozpoczynania pracy
Pamiętaj, że projekcje są przeznaczone wyłącznie dla magazynów wiedzy i nie są używane do tworzenia struktury indeksu wyszukiwania.
W usłudze Azure Storage uzyskaj ciąg połączenia z kluczy dostępu i sprawdź, czy konto to StorageV2 (wersja ogólnego przeznaczenia 2).
Będąc w usłudze Azure Storage, zapoznaj się z istniejącą zawartością kontenerów i tabel, aby wybrać nazwy niekonfliktujące dla projekcji. Magazyn wiedzy to luźna kolekcja tabel i kontenerów. Rozważ wdrożenie konwencji nazewnictwa, aby śledzić powiązane obiekty.
W usłudze Azure AI Search włącz buforowanie wzbogacania (wersja zapoznawcza) w indeksatorze, a następnie uruchom indeksator, aby wykonać zestaw umiejętności i wypełnić pamięć podręczną. Jest to funkcja w wersji zapoznawczej, dlatego należy użyć interfejsu API REST w wersji zapoznawczej w żądaniu indeksatora. Po wypełnieniu pamięci podręcznej, można bezpłatnie modyfikować definicje projekcji w magazynie wiedzy, pod warunkiem, że same umiejętności nie zostaną zmodyfikowane.
W kodzie wszystkie projekcje są definiowane wyłącznie w zestawie umiejętności. Brak właściwości indeksatora (takich jak mapowania pól lub mapowania pól wyjściowych), które mają zastosowanie do projekcji. W ramach definicji zestawu umiejętności skupisz się na dwóch obszarach: właściwości knowledgeStore i tablicy umiejętności.
W obszarze knowledgeStore określ tabelę, obiekt, projekcje plików w
projectionssekcji . Typ obiektu, nazwa obiektu i ilość (na liczbę zdefiniowanych projekcji) są określane w tej sekcji.Z tablicy umiejętności określ, do których wyników umiejętności należy odwoływać się w
sourcekażdej projekcji. Wszystkie projekcje mają źródło. Źródłem mogą być dane wyjściowe umiejętności nadrzędnej, ale często są to dane wyjściowe umiejętności Shaper. Kompozycja projekcji jest określana na podstawie kształtów.
Jeśli dodasz projekcje do istniejącego zestawu umiejętności, zaktualizuj zestaw umiejętności i uruchom indeksator.
Sprawdź wyniki w usłudze Azure Storage. W kolejnych przebiegach unikaj kolizji nazewnictwa, usuwając obiekty w usłudze Azure Storage lub zmieniając nazwy projektów w zestawie umiejętności.
Jeśli używasz projekcji tabel, zobacz Opis modelu danych usługi Table Service oraz cele dotyczące skalowalności i wydajności dla usługi Table Storage, aby upewnić się, że wymagania dotyczące danych znajdują się w udokumentowanych limitach usługi Table Storage.
Dalsze kroki
Przejrzyj składnię i przykłady dla każdego typu projekcji.