Kreatory importu w usłudze Azure AI Search
Usługa Azure AI Search ma dwóch kreatorów importu, które automatyzują indeksowanie i definicje obiektów, dzięki czemu można natychmiast rozpocząć wykonywanie zapytań. Jeśli dopiero zaczynasz korzystać z usługi Azure AI Search, te kreatory są jedną z najbardziej zaawansowanych funkcji. Przy minimalnym nakładzie pracy można utworzyć potok indeksowania lub wzbogacania, który wykonuje większość funkcji usługi Azure AI Search.
Kreator importu danych obsługuje przepływy pracy niewektorów. Możesz wyodrębnić tekst alfanumeryczny z nieprzetworzonych dokumentów. Możesz również skonfigurować zastosowane sztuczną inteligencję i wbudowane umiejętności, które wywnioskowały strukturę i wygenerowały zawartość z możliwością przeszukiwania tekstu na podstawie plików obrazów i danych bez struktury.
Kreator importowania i wektoryzacji danych obsługuje wektoryzację. Musisz określić istniejące wdrożenie modelu osadzania, ale kreator nawiązuje połączenie, formułuje żądanie i obsługuje odpowiedź. Generuje zawartość wektorów na podstawie zawartości tekstu lub obrazu.
Jeśli używasz kreatora do testowania weryfikacji koncepcji, w tym artykule opisano wewnętrzne działania kreatorów, dzięki czemu można ich efektywniej używać.
Ten artykuł nie jest krok po kroku. Aby uzyskać pomoc dotyczącą korzystania z kreatora z wbudowanymi przykładowymi danymi, zobacz:
- Szybki start: tworzenie indeksu wyszukiwania
- Szybki start: tworzenie zestawu umiejętności dotyczących tłumaczenia tekstu i jednostki
- Szybki start: tworzenie indeksu wektorów
- Szybki start: wyszukiwanie obrazów (wektory)
Uruchamianie kreatorów
W witrynie Azure Portal otwórz stronę usługi wyszukiwania z pulpitu nawigacyjnego lub znajdź swoją usługę na liście usług.
Na stronie Przegląd usługi w górnej części wybierz pozycję Importuj dane lub Importuj i wektoryzuj dane.
Kreatory otwierają w pełni rozwinięte okno przeglądarki, aby mieć więcej miejsca do pracy.
W przypadku wybrania opcji Importuj dane możesz wybrać opcję Przykłady , aby użyć wstępnie utworzonej próbki danych z obsługiwanego źródła danych.

Wykonaj pozostałe kroki kreatora, aby utworzyć indeks i indeksator.
Możesz również uruchomić polecenie Importuj dane z innych usług platformy Azure, w tym usług Azure Cosmos DB, Azure SQL Database, SQL Managed Instance i Azure Blob Storage. Wyszukaj pozycję Dodaj usługę Azure AI Search w okienku nawigacji po lewej stronie na stronie przeglądu usługi.
Obiekty utworzone przez kreatora
Kreator zwraca obiekty w poniższej tabeli. Po utworzeniu obiektów możesz przejrzeć ich definicje JSON w portalu lub wywołać je z kodu.
| Obiekt | opis |
|---|---|
| Indeksator | Obiekt konfiguracji określający źródło danych, indeks docelowy, opcjonalny zestaw umiejętności, opcjonalny harmonogram i opcjonalne ustawienia konfiguracji służące do przekazywania błędów i kodowania base-64. |
| Źródło danych | Utrwala informacje o połączeniu z obsługiwanym źródłem danych na platformie Azure. Obiekt źródła danych jest używany wyłącznie z indeksatorami. |
| Indeks | Fizyczna struktura danych używana do wyszukiwania pełnotekstowego i innych zapytań. |
| Zestaw umiejętności | Opcjonalny. Kompletny zestaw instrukcji dotyczących manipulowania, przekształcania i kształtowania zawartości, w tym analizowania i wyodrębniania informacji z plików obrazów. Zestawy umiejętności są również używane do zintegrowanej wektoryzacji. O ile ilość pracy nie mieści się w limicie 20 transakcji na indeksator dziennie, zestaw umiejętności musi zawierać odwołanie do zasobu wielousług usługi Azure AI, który zapewnia wzbogacanie. W przypadku zintegrowanej wektoryzacji można użyć usługi Azure AI Vision lub modelu osadzania w katalogu modeli usługi Azure AI Studio. |
| Magazyn wiedzy | Opcjonalny. Przechowuje dane wyjściowe z tabel i obiektów blob w usłudze Azure Storage na potrzeby niezależnej analizy lub przetwarzania podrzędnego w scenariuszach bez wyszukiwania. |
Świadczenia
Przed napisaniem jakiegokolwiek kodu można użyć kreatorów do tworzenia prototypów i testowania koncepcji weryfikacji koncepcji. Kreatory łączą się z zewnętrznymi źródłami danych, próbkują dane w celu utworzenia indeksu początkowego, a następnie importują i opcjonalnie wektoryzują dane jako dokumenty JSON do indeksu w usłudze Azure AI Search.
Jeśli oceniasz zestawy umiejętności, kreator obsługuje mapowania pól wyjściowych i dodaje funkcje pomocnicze do tworzenia obiektów do użycia. Podział tekstu jest dodawany, jeśli określisz tryb analizowania. Scalanie tekstu jest dodawane w przypadku wybrania analizy obrazów, aby kreator mógł ponownie połączyć opisy tekstu z zawartością obrazu. Umiejętności kształtatora dodane do obsługi prawidłowych projekcji, jeśli wybrano opcję magazynu wiedzy. Wszystkie powyższe zadania mają krzywą szkoleniową. Jeśli dopiero zaczynasz wzbogacać, możliwość obsługi tych kroków pozwala zmierzyć wartość umiejętności bez konieczności inwestowania dużo czasu i wysiłku.
Próbkowanie to proces, za pomocą którego schemat indeksu jest wnioskowany i ma pewne ograniczenia. Po utworzeniu źródła danych kreator wybiera losową próbkę dokumentów, aby zdecydować, które kolumny są częścią źródła danych. Nie wszystkie pliki są odczytywane, ponieważ potencjalnie może to potrwać wiele godzin w przypadku bardzo dużych źródeł danych. Biorąc pod uwagę wybór dokumentów, metadanych źródłowych, takich jak nazwa pola lub typ, służy do tworzenia kolekcji pól w schemacie indeksu. W zależności od złożoności danych źródłowych może być konieczne zmodyfikowanie początkowego schematu pod kątem dokładności lub rozszerzenie go pod kątem kompletności. Zmiany można wprowadzić w tekście na stronie definicji indeksu.
Ogólnie rzecz biorąc, zalety korzystania z kreatora są jasne: o ile wymagania są spełnione, można utworzyć indeks z możliwością wykonywania zapytań w ciągu kilku minut. Niektóre złożoności indeksowania, takie jak serializowanie danych jako dokumenty JSON, są obsługiwane przez kreatora.
Ograniczenia
Kreator nie jest bez ograniczeń. Ograniczenia są sumowane w następujący sposób:
Kreator nie obsługuje iteracji ani ponownego użycia. Każdy przepływ pracy kreatora tworzy nowy indeks, zestaw umiejętności i konfigurację indeksatora. Tylko źródła danych można utrwalać i używać ponownie w kreatorze. Aby edytować lub uściślić inne obiekty, usuń obiekty i zacznij od nowa albo użyj interfejsów API REST lub zestawu SDK platformy .NET, aby zmodyfikować struktury.
Zawartość źródłowa musi znajdować się w obsługiwanym źródle danych.
Próbkowanie znajduje się w podzestawie danych źródłowych. W przypadku dużych źródeł danych kreator może przegapić pola. Może być konieczne rozszerzenie schematu lub poprawienie wywnioskowanych typów danych, jeśli próbkowanie jest niewystarczające.
Wzbogacanie sztucznej inteligencji, jak pokazano w portalu, jest ograniczone do podzbioru wbudowanych umiejętności.
Magazyn wiedzy, który można utworzyć przez kreatora, jest ograniczony do kilku domyślnych projekcji i używa domyślnej konwencji nazewnictwa. Jeśli chcesz dostosować nazwy lub projekcje, musisz utworzyć magazyn wiedzy za pomocą interfejsu API REST lub zestawów SDK.
Bezpieczne połączenia
Kreatory importu tworzą połączenia wychodzące przy użyciu kontrolera portalu i publicznych punktów końcowych. Nie można używać kreatorów, jeśli zasoby platformy Azure są dostępne za pośrednictwem połączenia prywatnego lub za pośrednictwem udostępnionego łącza prywatnego.
Kreatorów można używać za pośrednictwem ograniczonych połączeń publicznych, ale nie wszystkie funkcje są dostępne.
W usłudze wyszukiwania importowanie wbudowanych przykładowych danych wymaga publicznego punktu końcowego i brak reguł zapory.
Przykładowe dane są hostowane przez firmę Microsoft w określonych zasobach platformy Azure. Kontroler portalu łączy się z tymi zasobami za pośrednictwem publicznego punktu końcowego. Jeśli umieścisz usługę wyszukiwania za zaporą, ten błąd występuje podczas próby pobrania wbudowanych przykładowych danych:
Import configuration failed, error creating Data Source, a następnie ."An error has occured."W przypadku obsługiwanych źródeł danych platformy Azure chronionych przez zapory możesz pobrać dane, jeśli masz odpowiednie reguły zapory.
Zasób platformy Azure musi przyznać żądania sieciowe z adresu IP urządzenia używanego w połączeniu. Należy również wyświetlić usługę Azure AI Search jako zaufaną usługę w konfiguracji sieci zasobu. Na przykład w usłudze Azure Storage możesz wyświetlić listę
Microsoft.Search/searchServicesjako zaufaną usługę.W przypadku połączeń z określonym kontem wielousługowym usługi Azure AI lub na połączeniach z osadzaniem modeli wdrożonych w usłudze Azure AI Studio lub Azure OpenAI należy włączyć publiczny dostęp do Internetu. Te zasoby platformy Azure są wywoływane w przypadku korzystania z wbudowanych umiejętności kreatora importu danych lub zintegrowanej wektoryzacji w kreatorze importowania i wektoryzacji danych .
W kreatorze importowania i wektoryzacji danych błąd to
"Access denied due to Virtual Network/Firewall rules."W kreatorze importowania danych nie ma błędu, ale zestaw umiejętności nie zostanie utworzony.
Jeśli ustawienia zapory uniemożliwiają pomyślne działanie przepływów pracy kreatora, rozważ zamiast tego podejścia skryptowe lub programowe.
Przepływ pracy
Kreator jest podzielony na cztery główne kroki:
Nawiązywanie połączenia z obsługiwanym źródłem danych platformy Azure.
Utwórz schemat indeksu, wywnioskowany przez dane źródła próbkowania.
Opcjonalnie dodaj zastosowaną sztuczną inteligencję, aby wyodrębnić lub wygenerować zawartość i strukturę. Dane wejściowe do tworzenia magazynu wiedzy są zbierane w tym kroku.
Uruchom kreatora, aby utworzyć obiekty, opcjonalnie wektoryzować dane, załadować dane do indeksu, ustawić harmonogram i inne opcje konfiguracji.
Przepływ pracy jest potokiem, więc jest jednym ze sposobów. Nie można użyć kreatora do edytowania żadnych utworzonych obiektów, ale możesz użyć innych narzędzi portalu, takich jak indeks lub projektant indeksatora lub edytorów JSON, w celu uzyskania dozwolonych aktualizacji.
Konfiguracja źródła danych w kreatorze
Kreatorzy łączą się z zewnętrznym obsługiwanym źródłem danych przy użyciu wewnętrznej logiki dostarczonej przez indeksatory usługi Azure AI Search, które są wyposażone w próbkowanie źródła, odczytywania metadanych, łamania dokumentów w celu odczytywania zawartości i struktury oraz serializowania zawartości jako kodu JSON w celu późniejszego zaimportowania do usługi Azure AI Search.
Możesz wkleić połączenie z obsługiwanym źródłem danych w innej subskrypcji lub regionie, ale selektor Wybierz istniejące połączenie ma zakres aktywnej subskrypcji.
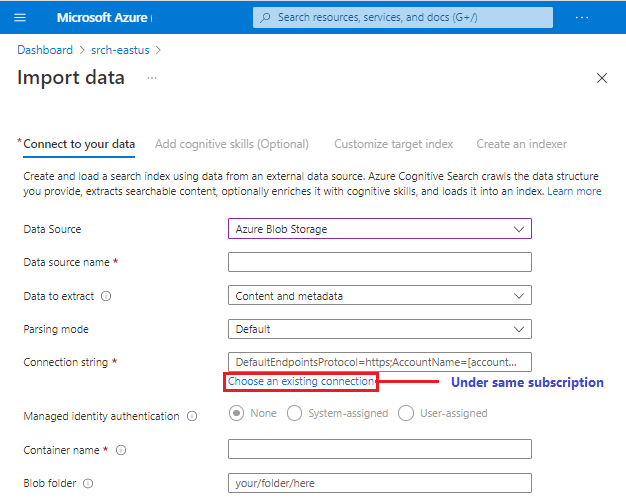
Nie wszystkie źródła danych w wersji zapoznawczej mają gwarancję dostępności w kreatorze. Ponieważ każde źródło danych może wprowadzać inne zmiany podrzędne, źródło danych w wersji zapoznawczej zostanie dodane tylko do listy źródeł danych, jeśli w pełni obsługuje wszystkie środowiska kreatora, takie jak definicja zestawu umiejętności i wnioskowanie schematu indeksu.
Można importować tylko z jednej tabeli, widoku bazy danych lub równoważnej struktury danych, jednak struktura może zawierać hierarchiczne lub zagnieżdżone podstruktury. Aby uzyskać więcej informacji, zobacz How to model complex types (Jak modelować złożone typy).
Konfiguracja zestawu umiejętności w kreatorze
Konfiguracja zestawu umiejętności występuje po definicji źródła danych, ponieważ typ źródła danych informuje o dostępności określonych wbudowanych umiejętności. W szczególności, jeśli indeksujesz pliki z usługi Blob Storage, wybór trybu analizowania tych plików określa, czy analiza tonacji jest dostępna.
Kreator dodaje wybrane umiejętności. Dodaje również inne umiejętności, które są niezbędne do osiągnięcia pomyślnego wyniku. Jeśli na przykład określisz magazyn wiedzy, kreator doda umiejętności kształtowania do obsługi projekcji (lub struktur danych fizycznych).
Zestawy umiejętności są opcjonalne i w dolnej części strony znajduje się przycisk, który można pominąć, jeśli nie chcesz wzbogacania sztucznej inteligencji.
Konfiguracja schematu indeksu w kreatorze
Kreatorzy przykładowe źródło danych wykrywa pola i typ pola. W zależności od źródła danych może również oferować pola do indeksowania metadanych.
Ponieważ próbkowanie jest nieprecyzyjnym ćwiczeniem, zapoznaj się z indeksem, aby zapoznać się z następującymi zagadnieniami:
Czy lista pól jest dokładna? Jeśli źródło danych zawiera pola, które nie zostały pobrane w próbkowaniu, możesz ręcznie dodać wszystkie nowe pola, które próbkowanie nie zostały pobrane, i usunąć wszystkie, które nie dodają wartości do środowiska wyszukiwania lub które nie będą używane w wyrażeniu filtru lub profilu oceniania.
Czy typ danych jest odpowiedni dla danych przychodzących? Usługa Azure AI Search obsługuje typy danych modelu danych jednostki (EDM). W przypadku danych usługi Azure SQL istnieje wykres mapowania, który zawiera równoważne wartości. Aby uzyskać więcej informacji, zobacz Mapowania pól i przekształcenia.
Czy masz jedno pole, które może służyć jako klucz? To pole musi być ciągiem Edm.string i musi jednoznacznie zidentyfikować dokument. W przypadku danych relacyjnych może zostać zamapowany na klucz podstawowy. W przypadku obiektów blob może to być .
metadata-storage-pathJeśli wartości pól zawierają spacje lub kreski, należy ustawić opcję Klucz kodowania Base-64 w kroku Tworzenie indeksatora w obszarze Opcje zaawansowane, aby pominąć sprawdzanie poprawności tych znaków.Ustaw atrybuty, aby określić sposób użycia tego pola w indeksie.
Pośmiń czas na wykonanie tego kroku, ponieważ atrybuty określają fizyczne wyrażenie pól w indeksie. Jeśli chcesz zmienić atrybuty później, nawet programowo, prawie zawsze musisz usunąć i ponownie skompilować indeks. Podstawowe atrybuty, takie jak Wyszukiwanie i Pobieranie, mają niewielki wpływ na magazyn. Włączanie filtrów i używanie sugestorów zwiększa wymagania dotyczące magazynu.
Funkcja wyszukiwania umożliwia wyszukiwanie pełnotekstowe. Każde pole używane w zapytaniach wolnych formularzy lub w wyrażeniach zapytań musi mieć ten atrybut. Odwrócone indeksy są tworzone dla każdego pola oznaczonego jako Wyszukiwanie.
Funkcja pobierania zwraca pole w wynikach wyszukiwania. Każde pole, które udostępnia zawartość do wyników wyszukiwania, musi mieć ten atrybut. Ustawienie tego pola nie ma znacznie wpływu na rozmiar indeksu.
Filtrowalne umożliwia odwołowanie się do pola w wyrażeniach filtru. Każde pole używane w wyrażeniu $filter musi mieć ten atrybut. Wyrażenia filtru są przeznaczone dla dokładnych dopasowań. Ponieważ ciągi tekstowe pozostają nienaruszone, do obsługi zawartości dosłownej jest wymagana większa ilość miejsca do magazynowania.
Funkcja facetable umożliwia korzystanie z pola nawigacji aspektowej. Jako możliwe do filtrowania można oznaczyć tylko pola jako możliwe do filtrowania.
Możliwość sortowania umożliwia użycie pola w sortowaniu. Każde pole używane w wyrażeniu $Orderby musi mieć ten atrybut.
Czy potrzebujesz analizy leksykalnej? W przypadku pól Edm.string, które można wyszukiwać, możesz ustawić analizator, jeśli chcesz indeksować i wykonywać zapytania w języku.
Wartość domyślna to Standard Lucene , ale możesz wybrać język angielski firmy Microsoft, jeśli chcesz użyć analizatora firmy Microsoft do zaawansowanego przetwarzania leksyktycznego, takiego jak rozpoznawanie nieregularnych form rzeczowników i czasowników. W portalu można określić tylko analizatory języków. Jeśli używasz analizatora niestandardowego lub analizatora niejęzycznego, takiego jak słowo kluczowe, wzorzec itd., musisz utworzyć go programowo. Aby uzyskać więcej informacji na temat analizatorów, zobacz Dodawanie analizatorów języka.
Czy potrzebujesz funkcji typeahead w postaci autouzupełniania lub sugerowanych wyników? Zaznacz pole wyboru Sugestor, aby włączyć sugestie dotyczące zapytań typowych i autouzupełnianie w wybranych polach. Sugestory dodają do indeksu liczbę tokenizowanych terminów, a tym samym zużywają więcej miejsca do magazynowania.
Konfiguracja indeksatora w kreatorze
Ostatnia strona kreatora zbiera dane wejściowe użytkownika dla konfiguracji indeksatora. Możesz określić harmonogram i ustawić inne opcje, które będą się różnić w zależności od typu źródła danych.
Wewnętrznie kreator konfiguruje również następujące definicje, które nie są widoczne w indeksatorze do momentu jego utworzenia:
- mapowania pól między źródłem danych a indeksem
- mapowania pól wyjściowych między danymi wyjściowymi umiejętności a indeksem
Następne kroki
Najlepszym sposobem zrozumienia korzyści i ograniczeń kreatora jest przejście przez niego. Oto przewodnik Szybki start, który objaśnia każdy krok.