Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Profile oceniania służą do zwiększania klasyfikacji pasujących dokumentów na podstawie kryteriów. W tym artykule dowiesz się, jak określić i przypisać profil oceniania, który zwiększa ocenę wyszukiwania na podstawie podanych parametrów. Profile oceniania można tworzyć w oparciu o:
Pola ważone, w których zwiększenie jest oparte na dopasowaniu znalezionym w określonym polu ciągu. Jeśli na przykład dopasowania znalezione w polu "Temat" powinny być bardziej istotne niż to samo dopasowanie znalezione w polu "Opis".
Funkcje dla danych liczbowych, w tym dat, zakresów i współrzędnych geograficznych. Istnieje również funkcja Tags, która działa na polu zapewniającym dowolną kolekcję ciągów. Możesz wybrać to podejście względem pól ważonych, jeśli chcesz zwiększyć wynik na podstawie tego, czy dopasowanie znajduje się w polu tagów.
Profil oceniania można dodać do indeksu, edytując jego definicję JSON w portalu Azure lub programowo za pomocą interfejsów API, takich jak Utwórz lub zaktualizuj indeks REST lub równoważnych interfejsów API w dowolnym zestawie Azure SDK.
Wymagania wstępne
Do oceniania profilów w wyszukiwaniu słów kluczowych można użyć dowolnej wersji interfejsu API lub pakietu ZESTAWU SDK. W przypadku wyszukiwania wektorowego i hybrydowego użyj interfejsów API REST 2024-05-01-preview i 2024-07-01 lub pakietów Azure SDK, które zapewniają równoważność funkcji. Aby zapewnić integrację między profilami oceniania a semantycznym rankerem, użyj wersji 2025-05-01-preview lub późniejszej.
Reguły oceniania profilów
Musisz mieć nowy lub istniejący indeks wyszukiwania z polami tekstowymi lub liczbowymi.
Profile oceniania można używać w wyszukiwaniu słów kluczowych, wyszukiwaniu wektorów i wyszukiwaniu hybrydowym. Jednak profile oceniania mają zastosowanie tylko do pól niewektorów, więc upewnij się, że indeks zawiera pola tekstowe lub liczbowe, które można zwiększyć lub zważyć.
W indeksie może być maksymalnie 100 profilów oceniania (zobacz limity usług), ale w danym zapytaniu można określić tylko jeden profil.
Z profilami oceniania można używać klasyfikatora semantycznego. Gdy wiele funkcji klasyfikacji lub istotności jest w grze, semantyczny ranking jest ostatnim krokiem. Sposób działania oceniania wyszukiwania zawiera ilustrację.
Uwaga
Nieznane pojęcia dotyczące istotności? Odwiedź stronę Istotność i ocenianie w usłudze Azure AI Search w tle. Możesz również obejrzeć ten segment wideo w serwisie YouTube na potrzeby oceniania profilów w wynikach rankingowych BM25.
Definicja profilu oceniania
Profil oceniania ma nazwę obiektu zdefiniowanego w schemacie indeksu. Profil oceniania składa się z ważonych pól, funkcji i parametrów.
Poniższa definicja przedstawia prosty profil o nazwie "geo". Ten przykład zwiększa wyniki z terminem wyszukiwania w polu hotelName. Używa distance również funkcji , aby faworyzować wyniki znajdujące się w odległości 10 kilometrów od bieżącej lokalizacji. Jeśli ktoś wyszukuje termin "inn", a "inn" jest częścią nazwy hotelu, dokumenty zawierające hotele z "inn" w promieniu 10 KM bieżącej lokalizacji będą wyświetlane wyżej w wynikach wyszukiwania.
"scoringProfiles": [
{
"name":"geo",
"text": {
"weights": {
"hotelName": 5
}
},
"functions": [
{
"type": "distance",
"boost": 5,
"fieldName": "location",
"interpolation": "logarithmic",
"distance": {
"referencePointParameter": "currentLocation",
"boostingDistance": 10
}
}
]
}
]
Aby użyć tego profilu oceniania, zapytanie jest formułowane w celu określenia scoringProfile parametru w żądaniu. Jeśli używasz interfejsu API REST, zapytania są określane za pośrednictwem żądań GET i POST. W poniższym przykładzie parametr "currentLocation" ma ogranicznik pojedynczej kreski (-). Następuje po nim współrzędnych długości i szerokości geograficznej, gdzie długość geograficzna jest wartością ujemną.
POST /indexes/hotels/docs&api-version=2024-07-01
{
"search": "inn",
"scoringProfile": "geo",
"scoringParameters": ["currentLocation--122.123,44.77233"]
}
To zapytanie wyszukuje termin "inn" i przekazuje je w bieżącej lokalizacji. Zwróć uwagę, że to zapytanie zawiera inne parametry, takie jak scoringParameter. Parametry zapytania, w tym "scoringParameter", są opisane w artykule Search Documents (INTERFEJS API REST).
Zobacz rozszerzony przykład wyszukiwania wektorowego i hybrydowego oraz rozszerzonego przykładu wyszukiwania słów kluczowych, aby uzyskać więcej scenariuszy.
Jak działa ocenianie wyszukiwania w usłudze Azure AI Search
Profile oceniania uzupełniają domyślny algorytm oceniania, zwiększając wyniki dopasowań spełniających kryteria profilu. Funkcje oceniania mają zastosowanie do:
- Wyszukiwanie tekstu (słowa kluczowego)
- Zapytania czystego wektora
- Zapytania hybrydowe z zapytaniami tekstowymi i wektorowymi są wykonywane równolegle
W przypadku autonomicznych zapytań tekstowych profile oceniania identyfikują maksymalnie 1000 dopasowań w wyszukiwaniu w rankingu BM25, a 50 pierwszych jest zwracanych w wynikach.
W przypadku czystych wektorów zapytanie jest tylko wektorem, ale jeśli dokumenty pasujące do k zawierają pola niewektorowe z zawartością czytelną dla człowieka, można zastosować profil oceniania. Profil oceniania zmienia zestaw wyników, zwiększając dokumenty zgodne z kryteriami w profilu.
W przypadku zapytań tekstowych w zapytaniu hybrydowym profile oceniania identyfikują maksymalnie 1000 dopasowań w wyszukiwaniu w rankingu BM25. Jednak po zidentyfikowaniu tych 1000 wyników zostaną przywrócone do ich oryginalnej kolejności BM25, aby można było je ponownie podkreślić wraz z wektorami powoduje kolejność końcowej funkcji klasyfikacji wzajemnej (RRF ), gdzie profil oceniania (zidentyfikowany jako "ostateczna korekta zwiększania dokumentu" na ilustracji) jest stosowany do scalonych wyników, wraz z wagą wektorową i klasyfikacją semantyczną jako ostatni krok.
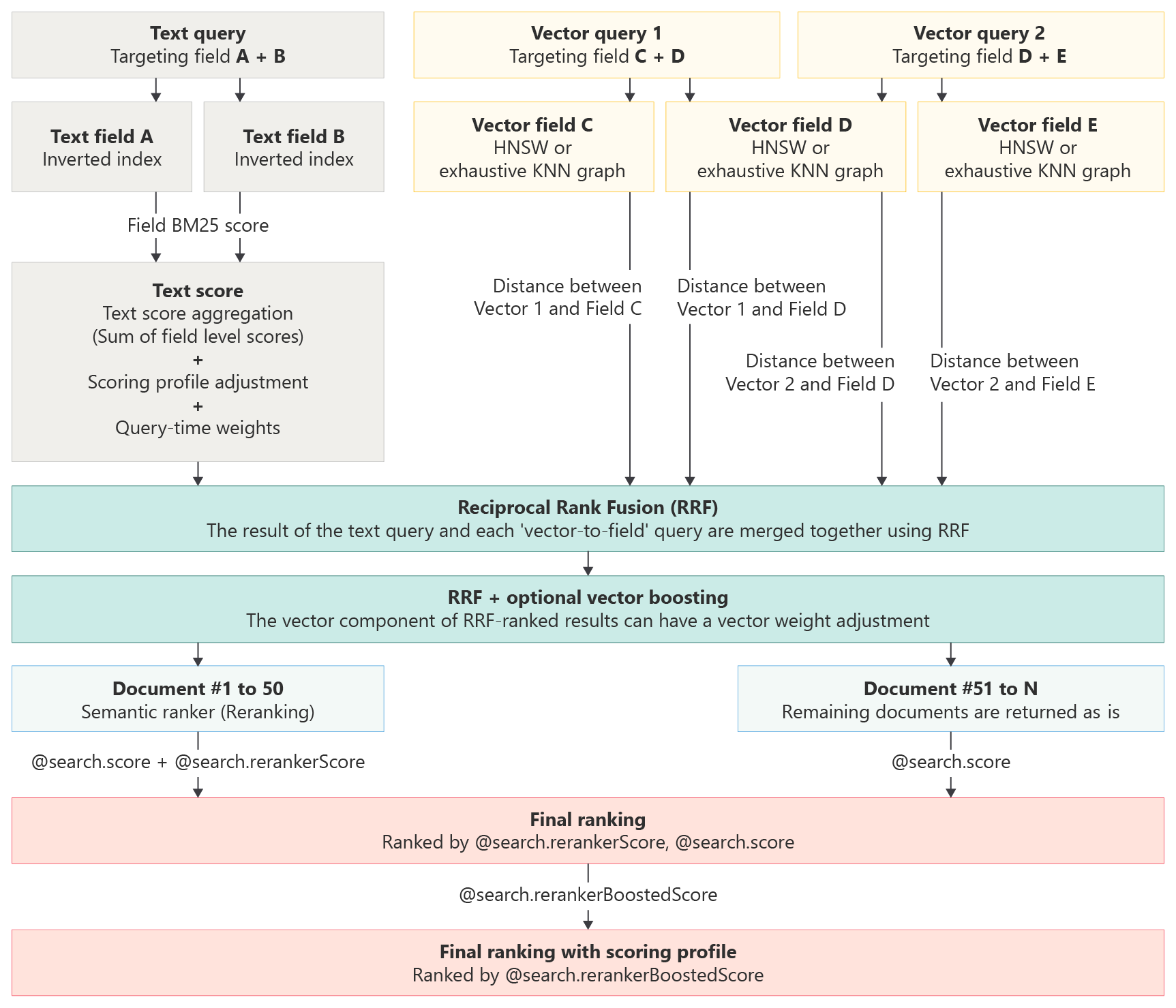
Dodawanie profilu oceniania do indeksu wyszukiwania
Zacznij od definicji indeksu. Profile oceniania można dodawać i aktualizować w istniejącym indeksie bez konieczności ponownego kompilowania. Użyj żądania tworzenia lub aktualizowania indeksu, aby opublikować poprawkę.
Wklej szablon podany w tym artykule.
Podaj nazwę zgodną z konwencjami nazewnictwa usługi Azure AI Search.
Określ kryteria zwiększania. Pojedynczy profil może zawierać pola, funkcje lub oba pola ważone tekstem.
Należy pracować iteracyjnie przy użyciu zestawu danych, który pomoże Ci udowodnić lub obalić skuteczność danego profilu.
Profile oceniania można zdefiniować w witrynie Azure Portal, jak pokazano na poniższym zrzucie ekranu lub programowo za pomocą interfejsów API REST lub w zestawach SDK platformy Azure, takich jak klasa ScoringProfile w zestawie Azure SDK dla platformy .NET.

Używanie pól ważonych tekstem
Użyj pól tekstowych, gdy kontekst pola jest ważny, a zapytania zawierają searchable pola ciągów. Jeśli na przykład zapytanie zawiera termin "airport", możesz chcieć "lotnisko" w polu Opis mieć większą wagę niż w polu HotelName.
Pola ważone to pary nazwa-wartość składające się z searchable pola i liczby dodatniej, która jest używana jako mnożnik. Jeśli oryginalny wynik pola HotelName wynosi 3, wzmocniony wynik dla tego pola staje się 6, przyczyniając się do wyższego ogólnego wyniku dla samego dokumentu nadrzędnego.
"scoringProfiles": [
{
"name": "boostSearchTerms",
"text": {
"weights": {
"HotelName": 2,
"Description": 5
}
}
}
]
Korzystanie z funkcji
Używaj funkcji, gdy proste wagi względne są niewystarczające lub nie mają zastosowania, podobnie jak w przypadku odległości i świeżości, które są obliczeniami na danych liczbowych. Można określić wiele funkcji na profil oceniania. Aby uzyskać więcej informacji na temat typów danych EDM używanych w usłudze Azure AI Search, zobacz Obsługiwane typy danych.
| Funkcja | opis | Przypadki użycia |
|---|---|---|
| odległość | Zwiększ bliskość lub lokalizację geograficzną. Tej funkcji można używać tylko z polami Edm.GeographyPoint . |
Służy do scenariuszy "znajdź w pobliżu mnie". |
| świeżość | Zwiększ według wartości w polu data/godzina (Edm.DateTimeOffset).
Ustaw parametr boostingDuration , aby określić wartość reprezentującą przedział czasu, w którym występuje zwiększenie. |
Użyj polecenia , jeśli chcesz zwiększyć według nowszych lub starszych dat. Klasyfikuj elementy, takie jak zdarzenia kalendarza z przyszłymi datami, tak aby elementy bliżej teraźniejszości mogły zostać sklasyfikowane wyżej niż elementy w przyszłości. Jeden koniec zakresu jest stały do bieżącego czasu. Aby zwiększyć zakres czasów w przeszłości, użyj pozytywnego wzmocnieniaDuration. Aby zwiększyć zakres czasów w przyszłości, użyj negatywnego wzmocnieniaDuration. |
| wielkość | Zmień klasyfikacje na podstawie zakresu wartości dla pola liczbowego. Wartość musi być liczbą całkowitą lub zmiennoprzecinkową. W przypadku ocen gwiazdek od 1 do 4 będzie to 1. W przypadku marginesów powyżej 50%, będzie to 50. Tej funkcji można używać tylko z polami Edm.Double i .Edm.Int W przypadku funkcji wielkości można odwrócić zakres, wysoki do niski, jeśli chcesz, aby wzorzec odwrotny (na przykład zwiększyć niższe ceny elementów więcej niż wyższej ceny elementów). Biorąc pod uwagę zakres cen od $100 do $1, można ustawić boostingRangeStart na 100 i boostingRangeEnd na 1, aby zwiększyć niższe ceny przedmiotów. |
Użyj, gdy chcesz zwiększyć marżę zysku, oceny, liczby kliknięć, liczbę pobrań, najwyższą cenę, najniższą cenę lub liczbę pobrań. Gdy dwa elementy są istotne, element o wyższej ocenie zostanie wyświetlony jako pierwszy. |
| etykieta | Zwiększ liczbę tagów, które są wspólne zarówno dla wyszukiwanych dokumentów, jak i ciągów zapytań. Tagi są udostępniane w elemecie tagsParameter. Tej funkcji można używać tylko z polami wyszukiwania typu Edm.String i Collection(Edm.String). |
Użyj polecenia , jeśli masz pola tagów. Jeśli dany tag na liście jest samą listą rozdzielaną przecinkami, możesz użyć normalizatora tekstu w polu, aby usunąć przecinki w czasie zapytania (mapować przecinek na spację). To podejście spowoduje "spłaszczenie" listy, tak aby wszystkie terminy były pojedynczym, długim ciągiem terminów rozdzielanych przecinkami. |
Reguły korzystania z funkcji
- Funkcje można stosować tylko do pól, które są przypisywane jako
filterable. - Typ funkcji ("świeżość", "wielkość", "odległość", "tag") musi mieć małe litery.
- Funkcje nie mogą zawierać wartości null ani pustych.
- Funkcje mogą mieć tylko jedno pole na definicję funkcji. Aby użyć wielkości dwa razy w tym samym profilu, podaj dwie definicje wielkości, jedną dla każdego pola.
Szablon
W tej sekcji przedstawiono składnię i szablon profilów oceniania. Opis właściwości można znaleźć w dokumentacji interfejsu API REST.
"scoringProfiles": [
{
"name": "name of scoring profile",
"text": (optional, only applies to searchable fields) {
"weights": {
"searchable_field_name": relative_weight_value (positive #'s),
...
}
},
"functions": (optional) [
{
"type": "magnitude | freshness | distance | tag",
"boost": # (positive number used as multiplier for raw score != 1),
"fieldName": "(...)",
"interpolation": "constant | linear (default) | quadratic | logarithmic",
"magnitude": {
"boostingRangeStart": #,
"boostingRangeEnd": #,
"constantBoostBeyondRange": true | false (default)
}
// ( - or -)
"freshness": {
"boostingDuration": "..." (value representing timespan over which boosting occurs)
}
// ( - or -)
"distance": {
"referencePointParameter": "...", (parameter to be passed in queries to use as reference location)
"boostingDistance": # (the distance in kilometers from the reference location where the boosting range ends)
}
// ( - or -)
"tag": {
"tagsParameter": "..."(parameter to be passed in queries to specify a list of tags to compare against target field)
}
}
],
"functionAggregation": (optional, applies only when functions are specified) "sum (default) | average | minimum | maximum | firstMatching"
}
],
"defaultScoringProfile": (optional) "...",
Ustawianie interpolacji
Interpolacje ustawiają kształt nachylenia używanego do oceniania. Ponieważ ocenianie jest wysokie do niskich, nachylenie jest zawsze malejące, ale interpolacja określa krzywą nachylenia w dół. Można użyć następujących interpolacji:
| Interpolacja | opis |
|---|---|
linear |
W przypadku elementów, które znajdują się w zakresie maksymalnym i minimalnym, zwiększenie jest stosowane w stale malejącej ilości. Linear to domyślna interpolacja profilu oceniania. |
constant |
W przypadku elementów znajdujących się w zakresie początkowym i końcowym do wyników klasyfikacji jest stosowany stały impuls. |
quadratic |
W porównaniu z interpolacją liniową, która ma stale malejący wzrost, ćwiartka początkowo zmniejsza się w mniejszym tempie, a następnie zbliża się do zakresu końcowego, zmniejsza się w znacznie wyższym interwale. Ta opcja interpolacji nie jest dozwolona w funkcjach oceniania tagów. |
logarithmic |
W porównaniu z interpolacją liniową, która ma stale malejący wzrost, logarytmiczna początkowo spada w wyższym tempie, a następnie zbliża się do zakresu końcowego, zmniejsza się w znacznie mniejszym interwale. Ta opcja interpolacji nie jest dozwolona w funkcjach oceniania tagów. |

Ustawianie funkcji boostingDuration dla funkcji świeżości
boostingDuration jest atrybutem freshness funkcji. Służy do ustawiania okresu wygaśnięcia, po którym zwiększenie spowoduje zatrzymanie dla określonego dokumentu. Na przykład, aby zwiększyć linię produktu lub markę dla 10-dniowego okresu promocyjnego, należy określić 10-dniowy okres jako "P10D" dla tych dokumentów.
boostingDuration musi być sformatowana jako wartość XSD "dayTimeDuration" (ograniczony podzestaw wartości czasu trwania ISO 8601). Wzorzec tego jest następujący: "P[nD][T[nH][nM][nS]]".
Poniższa tabela zawiera kilka przykładów.
| Czas trwania | czasWzmacniania |
|---|---|
| 1 dzień | "P1D" |
| 2 dni i 12 godzin | "P2DT12H" |
| 15 min | "PT15M" |
| 30 dni, 5 godzin, 10 minut i 6,334 sekundy | "P30DT5H10M6.334S" |
Aby uzyskać więcej przykładów, zobacz Schemat XML: Typy danych (W3.org witrynie internetowej).
Rozszerzony przykład wyszukiwania wektorowego i hybrydowego
Zobacz ten wpis w blogu i notes , aby zapoznać się z pokazem użycia profilów oceniania i dokumentem zwiększającym wektor i generowanie scenariuszy sztucznej inteligencji.
Rozszerzony przykład wyszukiwania słów kluczowych
Poniższy przykład przedstawia schemat indeksu z dwoma profilami oceniania (boostGenre, newAndHighlyRated). Każde zapytanie względem tego indeksu, które zawiera dowolny profil jako parametr zapytania, użyje profilu do oceny zestawu wyników.
Profil boostGenre używa ważonych pól tekstowych, zwiększając dopasowania znalezione w polach albumTitle, gatunek i artistName. Pola są odpowiednio zwiększane o 1,5, 5 i 2. Dlaczego gatunek jest wzmocniony o wiele wyżej niż inni? Jeśli wyszukiwanie jest przeprowadzane na danych, które są nieco homogeniczne (tak jak w przypadku "gatunku" w indeksie sklepu muzycznego), może być konieczna większa wariancja w względnych wagach. Na przykład w pliku musicstoreindex "rock" jest wyświetlany zarówno jako gatunek, jak i w identycznych opisach gatunku. Jeśli chcesz, aby gatunek przewyższał opis gatunku, pole gatunku będzie potrzebować znacznie większej wagi względnej.
{
"name": "musicstoreindex",
"fields": [
{ "name": "key", "type": "Edm.String", "key": true },
{ "name": "albumTitle", "type": "Edm.String" },
{ "name": "albumUrl", "type": "Edm.String", "filterable": false },
{ "name": "genre", "type": "Edm.String" },
{ "name": "genreDescription", "type": "Edm.String", "filterable": false },
{ "name": "artistName", "type": "Edm.String" },
{ "name": "orderableOnline", "type": "Edm.Boolean" },
{ "name": "rating", "type": "Edm.Int32" },
{ "name": "tags", "type": "Collection(Edm.String)" },
{ "name": "price", "type": "Edm.Double", "filterable": false },
{ "name": "margin", "type": "Edm.Int32", "retrievable": false },
{ "name": "inventory", "type": "Edm.Int32" },
{ "name": "lastUpdated", "type": "Edm.DateTimeOffset" }
],
"scoringProfiles": [
{
"name": "boostGenre",
"text": {
"weights": {
"albumTitle": 1.5,
"genre": 5,
"artistName": 2
}
}
},
{
"name": "newAndHighlyRated",
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": 10,
"interpolation": "quadratic",
"freshness": {
"boostingDuration": "P365D"
}
},
{
"type": "magnitude",
"fieldName": "rating",
"boost": 10,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 1,
"boostingRangeEnd": 5,
"constantBoostBeyondRange": false
}
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [ "albumTitle", "artistName" ]
}
]
}