Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Na platformie Azure niezawodność oznacza odporność i dostępność w przypadku awarii lub obniżenia wydajności usługi. W usłudze Azure AI Search niezawodność można osiągnąć w ramach jednej usługi lub za pośrednictwem wielu usług wyszukiwania w oddzielnych regionach.
Wdróż pojedynczą usługę wyszukiwania i skaluj w górę w celu zapewnienia wysokiej dostępności. Możesz dodać wiele replik, aby obsługiwać wyższe obciążenia indeksowania i wykonywania zapytań. Jeśli usługa wyszukiwania obsługuje strefy dostępności, repliki są automatycznie dystrybuowane w różnych fizycznych centrach danych dla dodatkowej odporności.
Wdrażanie wielu usług wyszukiwania w różnych regionach geograficznych. Wszystkie obciążenia wyszukiwania są w pełni zawarte w jednej usłudze, która działa w jednym regionie geograficznym, ale w scenariuszu obejmującym wiele usług masz opcje synchronizowania zawartości, aby była taka sama we wszystkich usługach. Możesz również skonfigurować rozwiązanie do równoważenia obciążenia w celu ponownego dystrybuowania żądań lub przełączania w tryb failover w przypadku awarii usługi.
Aby zapewnić ciągłość działania i odzyskiwanie po awariach na poziomie regionalnym, zaplanuj topologię między regionami składającą się z wielu usług wyszukiwania o identycznej konfiguracji i zawartości. Twoje niestandardowe skrypty lub kod udostępniają mechanizm awaryjnego przełączania dla alternatywnej usługi wyszukiwania, jeśli jedna z nich nagle stanie się niedostępna.
Wysoka dostępność
W usłudze Azure AI Search repliki są kopiami indeksu. Usługa wyszukiwania jest zlecona z co najmniej jedną repliką i może mieć maksymalnie 12 replik. Dodawanie replik umożliwia usłudze Azure AI Search ponowne uruchomienie maszyny i konserwację jednej repliki, podczas gdy wykonywanie zapytań jest kontynuowane w innych replikach.
W przypadku każdej indywidualnej usługi wyszukiwania firma Microsoft gwarantuje dostępność na poziomie co najmniej 99,9% dla konfiguracji spełniających następujące kryteria:
Dwie repliki w celu zapewnienia wysokiej dostępności obciążeń tylko do odczytu (zapytań)
Co najmniej trzy repliki w celu zapewnienia wysokiej dostępności obciążeń odczytu i zapisu (zapytań i indeksowania)
System ma wewnętrzne mechanizmy monitorowania kondycji repliki i integralności partycji. Jeśli aprowizujesz określoną kombinację replik i partycji, system zapewnia ten poziom pojemności usługi.
Dla warstwy Bezpłatna nie jest dostępna żadna umowa dotycząca poziomu usług (SLA). Aby uzyskać więcej informacji, zobacz umowa SLA dla usługi Azure AI Search.
Obsługa strefy dostępności
Strefy dostępności to funkcja platformy Azure, która dzieli centra danych regionu na odrębne grupy lokalizacji fizycznej w celu zapewnienia wysokiej dostępności w tym samym regionie. W usłudze Azure AI Search poszczególne repliki są jednostkami przypisania strefy. Usługa wyszukiwania działa w jednym regionie; jego repliki działają w różnych fizycznych centrach danych (lub strefach) w tym regionie.
Strefy dostępności są używane podczas dodawania co najmniej dwóch replik do usługi wyszukiwania. Każda replika jest umieszczana w innej strefie dostępności w regionie. Jeśli masz więcej replik niż dostępne strefy w regionie usługi wyszukiwania, repliki są dystrybuowane w strefach tak równomiernie, jak to możliwe. Nie ma żadnej konkretnej akcji ze swojej strony, z wyjątkiem tworzenia usługi wyszukiwania w regionie, który udostępnia strefy dostępności, a następnie skonfigurowania usługi pod kątem używania wielu replik.
Wymagania wstępne
- Warstwa usługi musi być Standardowa lub wyższa
- Region usługi musi znajdować się w regionie, w którym są dostępne strefy (wymienione w poniższej sekcji)
- Konfiguracja musi zawierać wiele replik: dwa dla obciążeń zapytań tylko do odczytu, trzy dla obciążeń odczytu i zapisu, które obejmują indeksowanie
Obsługiwane regiony
Obsługa stref dostępności zależy od infrastruktury i magazynu. Obecnie następująca strefa ma niewystarczający magazyn i nie zapewnia strefy dostępności dla usługi Azure AI Search:
- Japonia Zachodnia
W przeciwnym razie strefy dostępności usługi Azure AI Search są obsługiwane w następujących regionach:
| Region | Data wdrożenia |
|---|---|
| Australia Wschodnia | 30 stycznia 2021 r. lub nowszego |
| Brazylia Południowa | 2 maja 2021 r. lub nowszy |
| Kanada Środkowa | 30 stycznia 2021 r. lub nowszego |
| Indie Centralne | 20 stycznia 2022 r. lub nowszego |
| Środkowe stany USA | 4 grudnia 2020 r. lub nowszy |
| Chiny Północne 3 | 7 września 2022 r. lub nowsze |
| Azja Wschodnia | 13 stycznia 2022 r. lub nowszego |
| Wschodnie stany USA | 27 stycznia 2021 r. lub nowszy |
| Wschodnie stany USA 2 | 30 stycznia 2021 r. lub nowszego |
| Francja Środkowa | 23 października 2020 r. lub nowszy |
| Niemcy Środkowo-Zachodnie | 3 maja 2021 r. lub nowsza |
| Izrael Środkowy | 1 kwietnia 2024 r. lub nowszy |
| Włochy Północne | 1 kwietnia 2024 r. lub nowszy |
| Japonia Wschodnia | 30 stycznia 2021 r. lub nowszego |
| Korea Środkowa | 20 stycznia 2022 r. lub nowszego |
| Europa Północna | 28 stycznia 2021 r. lub nowszy |
| Norwegia Wschodnia | 20 stycznia 2022 r. lub nowszego |
| Katar Środkowy | 25 sierpnia 2022 r. lub nowszego |
| Północ Południowej Afryki | 7 września 2022 r. lub nowsze |
| Południowo-Centralne USA | 30 kwietnia 2021 r. lub nowszego |
| Azja Południowo-Wschodnia | 31 stycznia 2021 r. lub nowszy |
| Szwecja Środkowa | 21 stycznia 2022 r. lub nowszy |
| Szwajcaria Północna | 7 września 2022 r. lub nowsze |
| Północne Zjednoczone Emiraty Arabskie | 9 września 2022 r. lub nowszy |
| Południowe Zjednoczone Królestwo | 30 stycznia 2021 r. lub nowszego |
| Rząd USA Wirginia | 30 kwietnia 2021 r. lub nowszego |
| Europa Zachodnia | 29 stycznia 2021 r. lub nowszego |
| Zachodnie stany USA 2 | 30 stycznia 2021 r. lub nowszego |
| Zachodnie stany USA 3 | 2 czerwca 2021 r. lub nowszy |
Uwaga
Strefy dostępności nie zmieniają warunków umowy SLA. Nadal potrzebujesz co najmniej trzech replik, aby zapewnić wysoką dostępność obsługi zapytań.
Wiele usług w oddzielnych regionach geograficznych
Nadmiarowość usługi jest niezbędna, jeśli wymagania operacyjne obejmują:
Wymagania dotyczące ciągłości działania i odzyskiwania po awarii (BCDR). Usługa Azure AI Search nie zapewnia natychmiastowego przejścia w tryb failover, jeśli wystąpi awaria.
Szybka wydajność aplikacji rozproszonej globalnie. Jeśli żądania zapytań i indeksowania pochodzą z całego świata, użytkownicy, którzy znajdują się najbliżej centrum danych hosta, będą korzystać z szybszej wydajności. Tworzenie większej liczby usług w regionach z bliskim sąsiedztwem tych użytkowników może wyrównać wydajność dla wszystkich użytkowników.
Jeśli potrzebujesz co najmniej dwóch usług wyszukiwania, tworzenie ich w różnych regionach może spełniać wymagania aplikacji dotyczące ciągłości i odzyskiwania oraz szybsze czasy odpowiedzi dla globalnej bazy użytkowników.
Usługa Azure AI Search nie zapewnia zautomatyzowanej metody replikowania indeksów wyszukiwania w różnych regionach geograficznych, ale istnieją pewne techniki, które mogą ułatwić ten proces implementowania i zarządzania nimi. Te techniki opisano w kilku następnych sekcjach.
Celem rozproszonego geograficznie zestawu usług wyszukiwania jest posiadanie co najmniej dwóch indeksów dostępnych w co najmniej dwóch regionach, gdzie użytkownik jest kierowany do usługi Azure AI Wyszukiwania, która zapewnia najmniejsze opóźnienie.
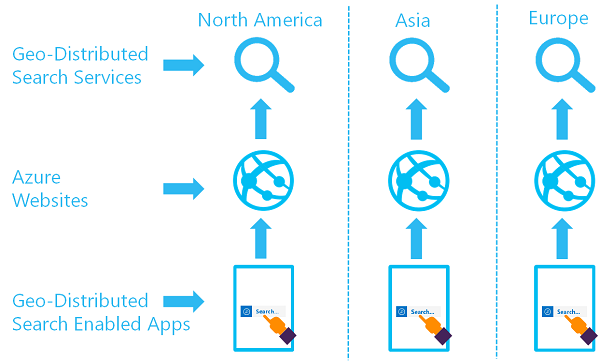
Tę architekturę można zaimplementować, tworząc wiele usług i projektując strategię synchronizacji danych. Opcjonalnie możesz uwzględnić zasób, taki jak usługa Azure Traffic Manager na potrzeby routingu żądań.
Napiwek
Aby uzyskać pomoc dotyczącą wdrażania wielu usług wyszukiwania w wielu regionach, zobacz ten przykład Bicep w usłudze GitHub , który wdraża w pełni skonfigurowane rozwiązanie do wyszukiwania w wielu regionach. W przykładzie przedstawiono dwie opcje synchronizacji indeksów i przekierowywanie żądań przy użyciu usługi Traffic Manager.
Synchronizowanie danych między wieloma usługami
Istnieją dwie opcje synchronizowania co najmniej dwóch odrębnych usług wyszukiwania:
- Ściąganie aktualizacji zawartości do indeksu wyszukiwania przy użyciu indeksatora.
- Umieść zawartość w indeksie za pomocą interfejsu API dodawania lub aktualizowania dokumentów (REST) lub równoważnego interfejsu API zestawu Azure SDK.
Aby skonfigurować każdą z tych opcji, zalecamy użycie przykładowego skryptu Bicep w repozytorium azure-search-multiple-region, zmodyfikowanego dla Twoich regionów i strategii indeksowania.
Opcja 1. Używanie indeksatorów do aktualizowania zawartości w wielu usługach
Jeśli już używasz indeksatora w jednej usłudze, możesz skonfigurować drugi indeksator w drugiej usłudze tak, aby używał tego samego obiektu źródła danych, ściągając dane z tej samej lokalizacji. Każda usługa w każdym regionie ma własny indeksator i indeks docelowy (indeks wyszukiwania nie jest udostępniany, co oznacza, że każdy indeks ma własną kopię danych), ale każdy indeksator odwołuje się do tego samego źródła danych.
Poniżej przedstawiono ogólną wizualizację tego, jak wyglądałaby ta architektura.
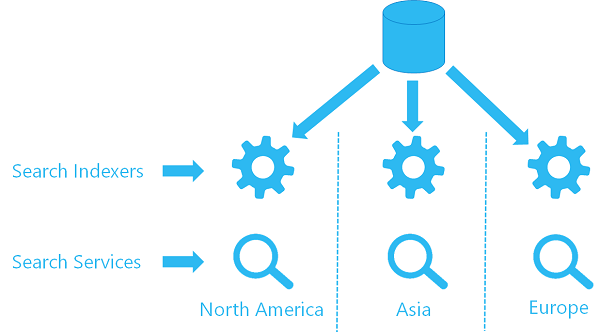
Opcja 2. Używanie interfejsów API REST do wypychania aktualizacji zawartości do wielu usług
Jeśli używasz interfejsu API REST usługi Azure AI Search do wypychania zawartości do indeksu wyszukiwania, możesz zachować synchronizację różnych usług wyszukiwania, wypychając zmiany do wszystkich usług wyszukiwania za każdym razem, gdy jest wymagana aktualizacja. W swoim kodzie upewnij się, że obsługujesz sytuacje, w których aktualizacja jednej usługi wyszukiwania kończy się niepowodzeniem, ale powodzi się dla innych usług wyszukiwania.
Przełączanie w tryb failover lub przekierowywanie żądań zapytań
Jeśli potrzebujesz nadmiarowości na poziomie żądania, platforma Azure oferuje kilka opcji równoważenia obciążenia:
- Usługa Azure Traffic Manager służy do kierowania żądań do wielu witryn internetowych zlokalizowanych geograficznie, które są następnie wspierane przez wiele usług wyszukiwania.
- Usługa Application Gateway służy do równoważenia obciążenia między serwerami w regionie w warstwie aplikacji.
- Usługa Azure Front Door służy do optymalizowania globalnego routingu ruchu internetowego i zapewniania globalnego trybu failover.
- Usługa Azure Load Balancer używana do równoważenia obciążenia między usługami w puli zaplecza.
Niektóre kwestie, o których należy pamiętać podczas oceniania opcji równoważenia obciążenia:
Wyszukiwanie to usługa zaplecza, która akceptuje żądania zapytań i indeksowania od klienta.
Żądania od klienta do usługi wyszukiwania muszą być uwierzytelnione. Aby uzyskać dostęp do operacji wyszukiwania, obiekt wywołujący musi mieć uprawnienia oparte na rolach lub podać klucz interfejsu API w żądaniu.
Punkty końcowe usługi są domyślnie dostępne za pośrednictwem publicznego połączenia internetowego. Jeśli skonfigurujesz prywatny punkt końcowy dla połączeń klienckich pochodzących z sieci wirtualnej, użyj usługi Application Gateway.
Usługa Azure AI Search akceptuje żądania skierowane do punktu końcowego
<your-search-service-name>.search.windows.net. Jeśli osiągniesz ten sam punkt końcowy przy użyciu innej nazwy DNS w nagłówku hosta, na przykład CNAME, żądanie zostanie odrzucone.
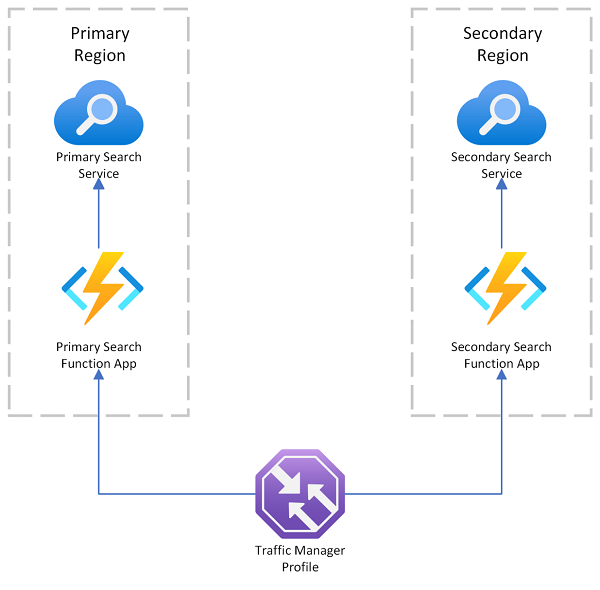
Usługa Azure AI Search udostępnia przykład wdrożenia w wielu regionach, który używa usługi Azure Traffic Manager do przekierowywania żądań, jeśli podstawowy punkt końcowy zakończy się niepowodzeniem. To rozwiązanie jest przydatne, gdy kierujesz do klienta z funkcją wyszukiwania, który wywołuje usługę wyszukiwania jedynie w tym samym regionie.
Usługa Azure Traffic Manager jest używana głównie do routingu ruchu sieciowego między różnymi punktami końcowymi na podstawie określonych metod routingu (takich jak priorytet, wydajność lub lokalizacja geograficzna). Działa na poziomie DNS w celu kierowania żądań przychodzących do odpowiedniego punktu końcowego. Jeśli punkt końcowy obsługujący usługę Traffic Manager rozpoczyna odrzucanie żądań, ruch jest kierowany do innego punktu końcowego.
Usługa Traffic Manager nie zapewnia punktu końcowego dla bezpośredniego połączenia z usługą Azure AI Search, co oznacza, że nie można umieścić usługi wyszukiwania bezpośrednio za usługą Traffic Manager. Zamiast tego założeniem jest to, że żądania przepływają do usługi Traffic Manager, a następnie do klienta internetowego obsługującego wyszukiwanie, a na koniec do usługi wyszukiwania w zapleczu. Klient i usługa znajdują się w tym samym regionie. Jeśli jedna usługa wyszukiwania ulegnie awarii, klient wyszukiwania zaczyna nie działać poprawnie, a Traffic Manager przekierowuje ruch do pozostałej usługi.
Uwaga
Jeśli używasz sond kondycji usługi Azure Load Balancer w usłudze wyszukiwania, musisz użyć sondy HTTPS z /ping jako ścieżką.
Miejsce przechowywania danych we wdrożeniu w wielu regionach
Podczas wdrażania wielu usług wyszukiwania w różnych regionach geograficznych zawartość jest przechowywana w regionie wybrany dla każdej usługi wyszukiwania.
Usługa Azure AI Search nie przechowuje danych poza określonym regionem bez autoryzacji. Autoryzacja jest niejawna, gdy używasz funkcji zapisywanych w zasobie usługi Azure Storage: pamięci podręcznej wzbogacania, sesji debugowania, magazynu wiedzy. We wszystkich przypadkach konto magazynowe jest takie, które zapewniasz, w regionie, który wybierzesz.
Uwaga
Jeśli zarówno konto przechowywania, jak i usługa wyszukiwania znajdują się w tym samym regionie, ruch sieciowy między wyszukiwaniem a przechowywaniem używa prywatnego adresu IP i występuje w wewnętrznym łączu firmy Microsoft. Ponieważ są używane prywatne adresy IP, nie można skonfigurować zapór ip ani prywatnego punktu końcowego na potrzeby zabezpieczeń sieci. Zamiast tego użyj wyjątku zaufanej usługi jako alternatywy, gdy obie usługi znajdują się w tym samym regionie.
Informacje o awariach usług i katastroficznych zdarzeniach
Zgodnie z umową SLA firma Microsoft gwarantuje wysoki poziom dostępności żądań zapytań dotyczących indeksu, gdy wystąpienie usługi Azure AI usługa wyszukiwania jest skonfigurowane z co najmniej dwiema replikami, a żądania aktualizacji indeksu, gdy wystąpienie usługi Azure AI usługa wyszukiwania jest skonfigurowane z co najmniej trzema replikami. Nie ma jednak wbudowanego mechanizmu odzyskiwania po awarii. Jeśli usługa ciągła jest wymagana w przypadku awarii katastrofanej poza kontrolą firmy Microsoft, zalecamy aprowizowanie drugiej usługi w innym regionie i wdrożenie strategii replikacji geograficznej w celu zapewnienia, że indeksy są w pełni nadmiarowe we wszystkich usługach.
Klienci, którzy używają indeksatorów do wypełniania i odświeżania indeksów, mogą obsługiwać odzyskiwanie po awarii za pośrednictwem indeksatorów specyficznych dla obszaru geograficznego, które pobierają dane z tego samego źródła danych. Dwie usługi w różnych regionach, z których każda uruchamia indeksator, mogą indeksować to samo źródło danych, aby osiągnąć nadmiarowość geograficzną. Jeśli indeksujesz ze źródeł danych, które są również geograficznie redundantne, pamiętaj, że indeksatory usługi Azure AI Search mogą wykonywać indeksowanie przyrostowe (tj. scalanie aktualizacji z nowych, zmodyfikowanych lub usuniętych dokumentów) tylko z replik podstawowych. W przypadku awarii systemu pamiętaj, aby przekierować indeksator do nowej repliki podstawowej.
Jeśli nie używasz indeksatorów, użyj kodu aplikacji do wypychania obiektów i danych do różnych usług wyszukiwania równolegle. Aby uzyskać więcej informacji, zobacz Synchronizowanie danych między wieloma usługami.
Tworzenie kopii zapasowej i przywracanie alternatyw
Strategia ciągłości działania dla warstwy danych zwykle obejmuje krok przywracania z kopii zapasowej. Ponieważ usługa Azure AI Search nie jest podstawowym rozwiązaniem magazynu danych, firma Microsoft nie udostępnia formalnego mechanizmu samoobsługowego tworzenia kopii zapasowych i przywracania. Możesz jednak użyć przykładowego kodu index-backup-restore w tym przykładowym repozytorium .NET usługi Azure AI Search lub w tym przykładowym repozytorium języka Python , aby utworzyć kopię zapasową definicji indeksu i migawki do serii plików JSON, a następnie użyć tych plików do przywrócenia indeksu, jeśli jest to konieczne. To narzędzie może również przenosić indeksy między warstwami usług.
W przeciwnym razie kod aplikacji używany do tworzenia i wypełniania indeksu jest de facto opcją przywracania w przypadku usunięcia indeksu przez pomyłkę. Aby ponownie skompilować indeks, należy go usunąć (zakładając, że istnieje), ponownie utworzyć indeks w usłudze i ponownie załadować, pobierając dane z podstawowego magazynu danych.
Powiązana zawartość
- Zapoznaj się z limitami usług, aby dowiedzieć się więcej na temat warstw cenowych i limitów usług.
- Zapoznaj się z tematem Planowanie pojemności , aby dowiedzieć się więcej na temat kombinacji partycji i repliki.
- Zapoznaj się z analizą przypadku: Używanie wyszukiwania poznawczego do obsługi złożonych scenariuszy sztucznej inteligencji , aby uzyskać więcej wskazówek dotyczących konfiguracji.