Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Notesy Jupyter zapewniają interaktywne środowisko do eksplorowania, analizowania i wizualizowania danych w Microsoft Sentinel danych i tabel federacyjnych. Notesy umożliwiają pisanie i wykonywanie kodu, dokumentowanie przepływu pracy i wyświetlanie wyników — wszystko w jednym miejscu. Dzięki temu można łatwo eksplorować dane, tworzyć zaawansowane rozwiązania analityczne i udostępniać szczegółowe informacje innym osobom. Dzięki wykorzystaniu języka Python i platformy Apache Spark w ramach Visual Studio Code notesy ułatwiają przekształcanie nieprzetworzonych danych zabezpieczeń w analizę z możliwością działania.
W tym artykule przedstawiono sposób eksplorowania danych usługi Data Lake i interakcji z nimi przy użyciu notesów Jupyter w Visual Studio Code.
Wymagania wstępne
Dołączanie do Microsoft Sentinel data lake
Aby korzystać z notesów w Microsoft Sentinel data lake, należy najpierw dołączyć do usługi Data Lake. Jeśli nie dołączyć do Sentinel data lake, zobacz Dołączanie do Microsoft Sentinel data lake. Jeśli ostatnio dołączono do usługi data lake, pozyskanie wystarczającej ilości danych może zająć trochę czasu, zanim będzie można utworzyć znaczące analizy przy użyciu notesów.
Uprawnienia
Microsoft Entra ID role zapewniają szeroki dostęp do wszystkich obszarów roboczych w usłudze Data Lake. Alternatywnie można udzielić dostępu do poszczególnych obszarów roboczych przy użyciu Azure ról RBAC. Użytkownicy z uprawnieniami Azure RBAC do Microsoft Sentinel obszarów roboczych mogą uruchamiać notesy względem tych obszarów roboczych w warstwie usługi Data Lake. Aby uzyskać więcej informacji, zobacz Role i uprawnienia w Microsoft Sentinel.
Opcjonalnie można skonfigurować Microsoft Sentinel określania zakresu lub kontroli dostępu opartej na rolach na poziomie wiersza w celu dalszego ograniczania dostępu do danych w obszarze roboczym. Po włączeniu określanie zakresu na poziomie wiersza ogranicza dane zwracane przez zapytania na podstawie przypisanego zakresu użytkownika. Jeśli określanie zakresu na poziomie wiersza nie jest skonfigurowane, istniejący model uprawnień na poziomie obszaru roboczego ma zastosowanie bez zmian. Aby uzyskać więcej informacji, zobacz Konfigurowanie Microsoft Sentinel określania zakresu (rbac na poziomie wiersza) (wersja zapoznawcza).
Aby utworzyć nowe tabele niestandardowe w warstwie analizy, tożsamość zarządzana usługi Data Lake musi mieć przypisaną rolę Współautor usługi Log Analytics w obszarze roboczym usługi Log Analytics.
Aby przypisać rolę, wykonaj poniższe kroki:
- W Azure Portal przejdź do obszaru roboczego usługi Log Analytics, do których chcesz przypisać rolę.
- Wybierz pozycję Kontrola dostępu (IAM) w okienku nawigacji po lewej stronie.
- Wybierz pozycję Dodaj przypisanie roli.
- W tabeli Role (Rola ) wybierz pozycję Współautor usługi Log Analytics, a następnie wybierz pozycję Dalej.
- Wybierz pozycję Tożsamość zarządzana, a następnie wybierz pozycję Wybierz członków.
- Tożsamość zarządzana usługi Data Lake to tożsamość zarządzana przypisana przez system o nazwie
msg-resources-<guid>. Wybierz tożsamość zarządzana, a następnie wybierz pozycję Wybierz. - Wybierz pozycję Przejrzyj i przypisz.
Aby uzyskać więcej informacji na temat przypisywania ról do tożsamości zarządzanych, zobacz Przypisywanie ról Azure przy użyciu Azure Portal.
Instalowanie Visual Studio Code i rozszerzenia Microsoft Sentinel
Jeśli nie masz jeszcze Visual Studio Code, pobierz i zainstaluj Visual Studio Code dla komputerów Mac, Linux lub Windows.
Rozszerzenie Microsoft Sentinel dla programu Visual Studio Code (VS Code) jest instalowane z poziomu platformy handlowej rozszerzeń. Aby zainstalować rozszerzenie, wykonaj następujące kroki:
- Wybierz witrynę Extensions Marketplace na lewym pasku narzędzi.
- Wyszukaj Sentinel.
- Wybierz rozszerzenie Microsoft Sentinel i wybierz pozycję Zainstaluj.
- Po zainstalowaniu rozszerzenia ikona osłony Microsoft Sentinel zostanie wyświetlona na lewym pasku narzędzi.

Zainstaluj rozszerzenie GitHub Copilot dla Visual Studio Code, aby włączyć uzupełnianie kodu i sugestie w notesach.
- Wyszukaj GitHub Copilot w witrynie Extensions Marketplace i zainstaluj ją.
- Po instalacji zaloguj się do GitHub Copilot przy użyciu konta usługi GitHub.
Eksplorowanie tabel warstwy usługi Data Lake
Po zainstalowaniu rozszerzenia Microsoft Sentinel możesz rozpocząć eksplorowanie tabel warstwy usługi Data Lake i tworzenie notesów Jupyter w celu analizowania danych.
Zaloguj się do rozszerzenia Microsoft Sentinel
Wybierz ikonę osłony Microsoft Sentinel na lewym pasku narzędzi.
Zostanie wyświetlone okno dialogowe z następującym tekstem Rozszerzenie "Microsoft Sentinel" chce się zalogować przy użyciu firmy Microsoft. Wybierz pozycję Zezwalaj.
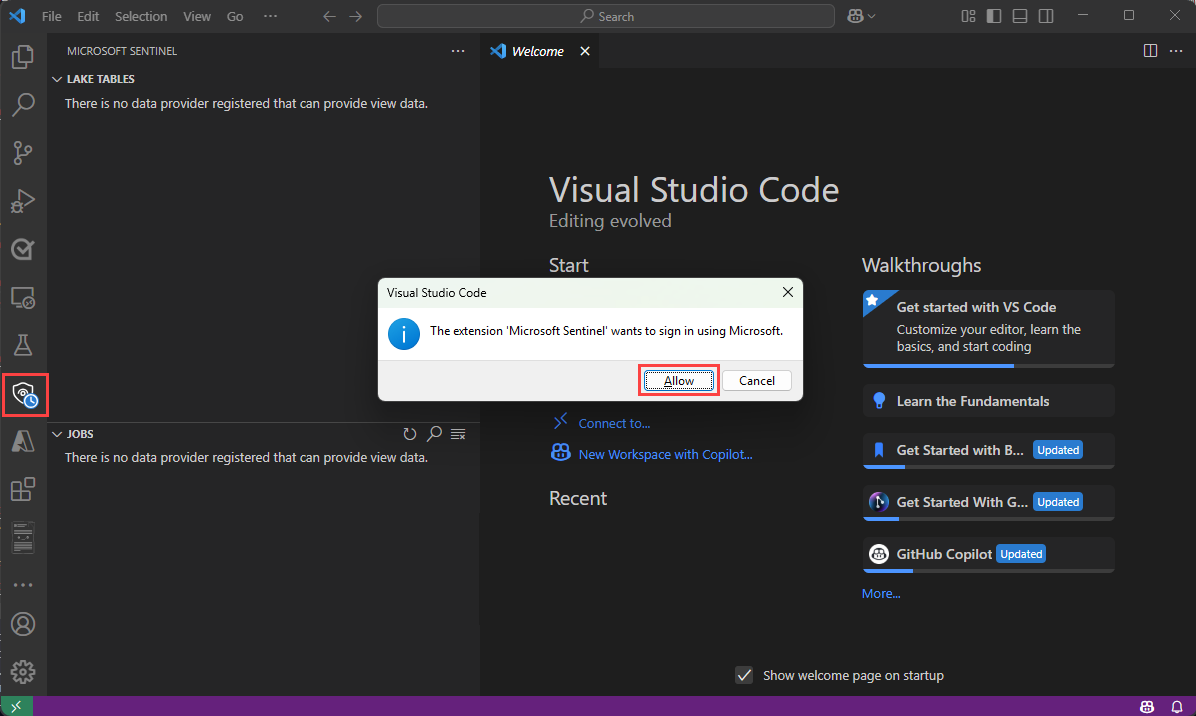
Wybierz nazwę konta, aby ukończyć logowanie.
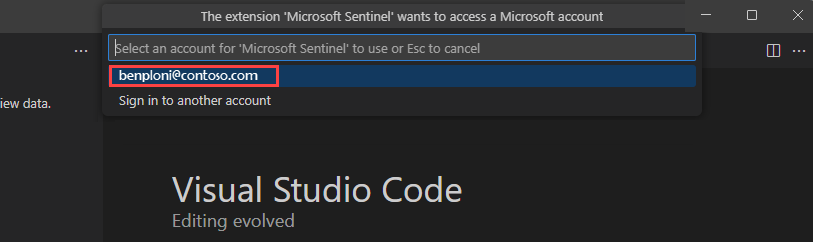
Jeśli masz wiele kont gości skojarzonych z logowaniem, możesz bezproblemowo przełączać się między kontami. Aby przełączać się między kontami, wybierz nazwę konta w lewym dolnym rogu okna Visual Studio Code. Jednocześnie można wybrać tylko jedno konto.
Ważna
Przełączanie między kontami rozłącza wszystkie aktywne sesje pyspark.



Wyświetlanie tabel i zadań usługi Data Lake
Po zalogowaniu rozszerzenie Sentinel wyświetla listę tabel usługi Lake i zadań w okienku po lewej stronie. Tabele są pogrupowane według bazy danych i kategorii. Tabele federacyjne są wyświetlane w kategorii Tabele federacyjne w obszarze Tabele systemowe. Wybierz tabelę, aby wyświetlić definicje kolumn.
Aby uzyskać informacje na temat zadań, zobacz Zadania i planowanie. Aby uzyskać więcej informacji na temat tabel federacyjnych, zobacz Using federated tables in the Microsoft Sentinel data lake (Używanie tabel federacyjnych w Microsoft Sentinel data lake).

Tworzenie nowego notesu
Aby utworzyć nowy notes, użyj jednej z następujących metod.
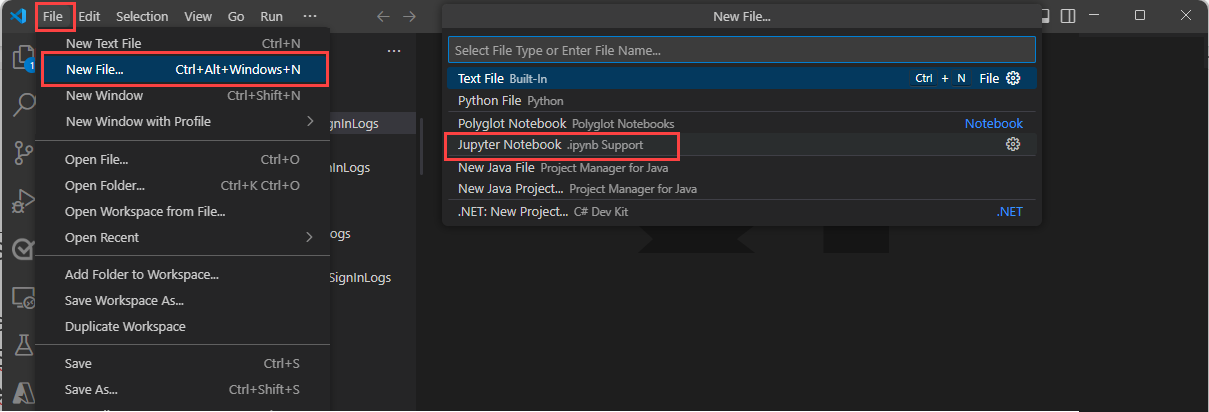
Wprowadź > ciąg w polu wyszukiwania lub naciśnij klawisze Ctrl+Shift+P, a następnie wprowadź polecenie Utwórz nową Jupyter Notebook.

Wybierz pozycję Plik > nowy plik, a następnie wybierz pozycję Jupyter Notebook z listy rozwijanej.
W nowym notesie wklej następujący kod do pierwszej komórki.
from sentinel_lake.providers import MicrosoftSentinelProvider data_provider = MicrosoftSentinelProvider(spark) table_name = "EntraGroups" df = data_provider.read_table(table_name) df.select("displayName", "groupTypes", "mail", "mailNickname", "description", "tenantId").show(100, truncate=False)


Edytor udostępnia uzupełnianie kodu intellisense dla MicrosoftSentinelProvider klas i nazw tabel w usłudze Data Lake.
Wybierz trójkąt Uruchom , aby wykonać kod w notesie. Wyniki są wyświetlane w okienku danych wyjściowych poniżej komórki kodu.
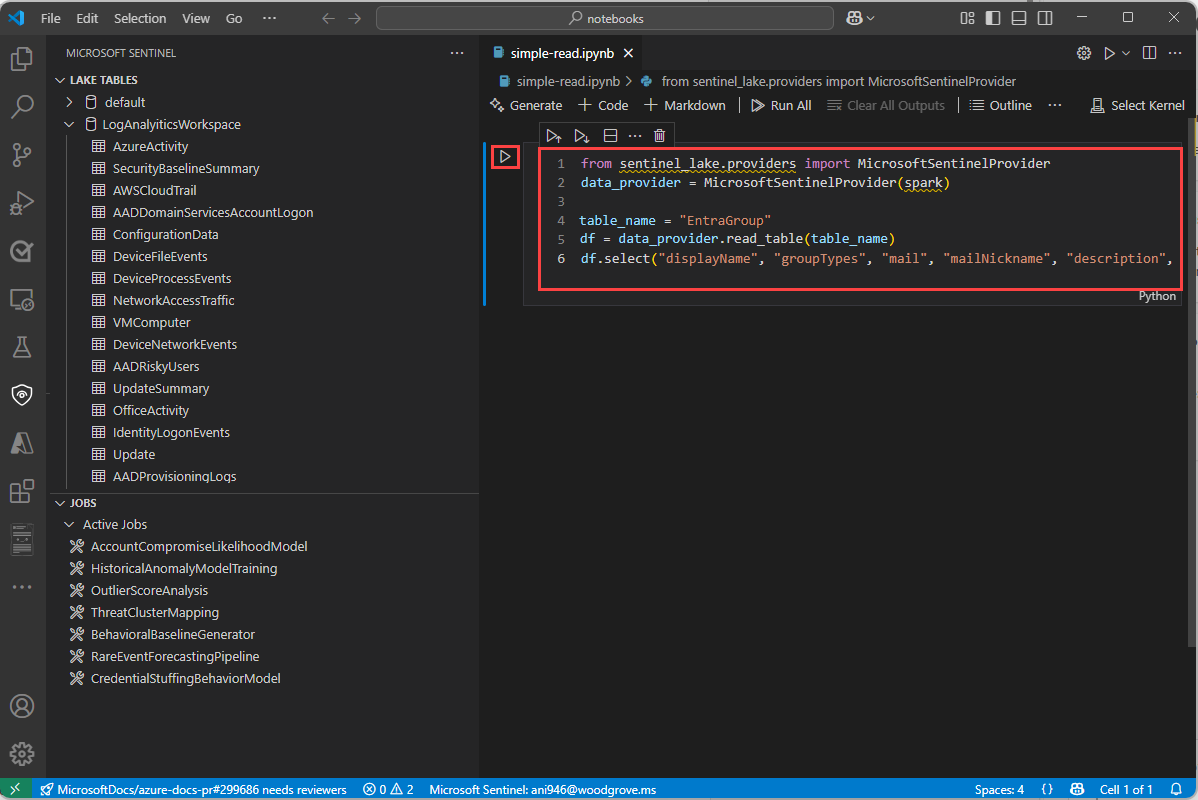
Wybierz pozycję Microsoft Sentinel z listy, aby wyświetlić listę pul środowiska uruchomieniowego.
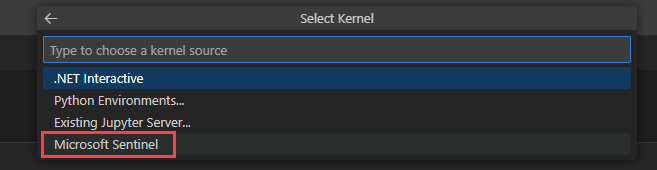
Wybierz pozycję Średni , aby uruchomić notes w średniej wielkości puli środowiska uruchomieniowego. Aby uzyskać więcej informacji na temat różnych środowisk uruchomieniowych, zobacz Wybieranie odpowiedniego Microsoft Sentinel środowiska uruchomieniowego.



Uwaga
Wybranie jądra powoduje uruchomienie sesji platformy Spark i uruchomienie kodu w notesie. Po wybraniu puli uruchomienie sesji może potrwać od 3 do 5 minut. Kolejne uruchomienia są uruchamiane szybciej, ponieważ sesja jest już aktywna.
Po rozpoczęciu sesji kod w notesie zostanie uruchomiony, a wyniki zostaną wyświetlone w okienku danych wyjściowych poniżej komórki kodu, na przykład: 
Przykładowe notesy demonstrujące sposób interakcji z usługą Microsoft Sentinel data lake można znaleźć w temacie Przykładowe notesy Microsoft Sentinel data lake.
Pasek stanu
Pasek stanu w dolnej części notesu zawiera informacje o bieżącym stanie notesu i sesji platformy Spark. Pasek stanu zawiera następujące informacje:
Procent wykorzystania rdzeni wirtualnych dla wybranej puli platformy Spark. Umieść kursor na wartości procentowej, aby wyświetlić liczbę używanych rdzeni wirtualnych i łączną liczbę rdzeni wirtualnych dostępnych w puli. Wartości procentowe reprezentują bieżące użycie obciążeń interaktywnych i zadań dla zalogowanego konta.
Stan połączenia sesji platformy Spark, na przykład
Connecting,ConnectedlubNot Connected.

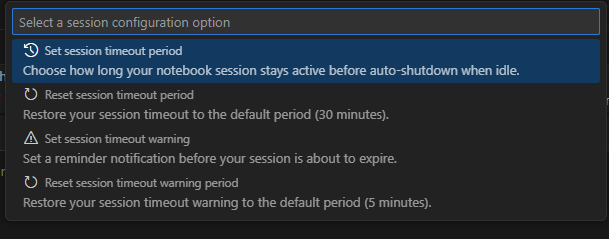
Ustawianie limitów czasu sesji
Możesz ustawić limit czasu sesji i ostrzeżenia dotyczące limitu czasu dla notesów interakcyjnych. Aby zmienić limit czasu, wybierz stan połączenia na pasku stanu w dolnej części notesu. Wybierz jedną z następujących opcji:
Ustaw limit czasu sesji: ustawia czas w minutach przed przekroczeniem limitu czasu sesji. Wartość domyślna to 30 minut.
Okres limitu czasu sesji resetowania: resetuje limit czasu sesji do wartości domyślnej wynoszącej 30 minut.
Ustaw okres ostrzeżenia o przekroczeniu limitu czasu sesji: ustawia czas w minutach przed przekroczeniem limitu czasu, przez który zostanie wyświetlone ostrzeżenie informujące o przekroczeniu limitu czasu sesji. Wartość domyślna to 5 minut.
Okres ostrzeżenia o przekroczeniu limitu czasu sesji resetowania: resetuje ostrzeżenie limitu czasu sesji do wartości domyślnej wynoszącej 5 minut.

Używanie GitHub Copilot w notesach
Użyj GitHub Copilot, aby ułatwić pisanie kodu w notesach. GitHub Copilot udostępnia sugestie dotyczące kodu i autouzupełnianie na podstawie kontekstu kodu. Aby użyć GitHub Copilot, upewnij się, że masz zainstalowane rozszerzenie GitHub Copilot w Visual Studio Code.
Skopiuj kod z przykładowych notesów Microsoft Sentinel data lake i zapisz go w folderze notesów, aby zapewnić kontekst dla GitHub Copilot. GitHub Copilot będą mogli sugerować uzupełnianie kodu na podstawie kontekstu notesu.
Poniższy przykład przedstawia GitHub Copilot generowania przeglądu kodu.

Microsoft Sentinel Provider, klasa
Aby nawiązać połączenie z Microsoft Sentinel data lake, użyj SentinelLakeProvider klasy .
Ta klasa jest częścią modułu access_module.data_loader i udostępnia metody interakcji z usługą Data Lake. Aby użyć tej klasy, zaimportuj ją i utwórz wystąpienie klasy przy użyciu spark sesji.
from sentinel_lake.providers import MicrosoftSentinelProvider
data_provider = MicrosoftSentinelProvider(spark)
Aby uzyskać więcej informacji na temat dostępnych metod, zobacz Microsoft Sentinel Informacje o klasach dostawcy.
Wybierz odpowiednią pulę środowiska uruchomieniowego
Dostępne są trzy pule środowiska uruchomieniowego do uruchamiania notesów Jupyter w rozszerzeniu Microsoft Sentinel. Każda pula jest przeznaczona dla różnych obciążeń i wymagań dotyczących wydajności. Wybór puli środowiska uruchomieniowego ma wpływ na wydajność, koszt i czas wykonywania zadań platformy Spark.
| Pula środowiska uruchomieniowego | Zalecane przypadki użycia | Cechy |
|---|---|---|
| Mała | Opracowywanie, testowanie i uproszczona analiza eksploracyjna. Małe obciążenia z prostymi przekształceniami. Efektywność kosztowa została określona priorytetowo. |
Nadaje się do małych obciążeń Proste przekształcenia. Niższy koszt, dłuższy czas wykonywania. |
| Średnie | Zadania ETL z sprzężeniami, agregacjami i trenowaniem modelu uczenia maszynowego. Umiarkowane obciążenia ze złożonymi przekształceniami. |
Lepsza wydajność w stosunku do małych. Obsługuje równoległość i umiarkowane operacje intensywnie korzystające z pamięci. |
| Duża | Obciążenia uczenia głębokiego i uczenia maszynowego. Rozległe tasowanie danych, duże sprzężenia lub przetwarzanie w czasie rzeczywistym. Krytyczny czas wykonywania. |
Duża ilość pamięci i mocy obliczeniowej. Minimalne opóźnienia. Najlepiej w przypadku dużych, złożonych lub zależnych od czasu obciążeń. |
Uwaga
Po pierwszym uzyskaniu dostępu ładowanie opcji jądra może potrwać około 30 sekund.
Po wybraniu puli środowiska uruchomieniowego rozpoczęcie sesji może potrwać od 3 do 5 minut.
Wyświetlanie komunikatów, dzienników i błędów
Dzienniki komunikatów i komunikaty o błędach są wyświetlane w trzech obszarach w Visual Studio Code.
Okienko Dane wyjściowe .
- W okienku Dane wyjściowe wybierz pozycję Microsoft Sentinel z listy rozwijanej.
- Wybierz pozycję Debuguj, aby uwzględnić szczegółowe wpisy dziennika.
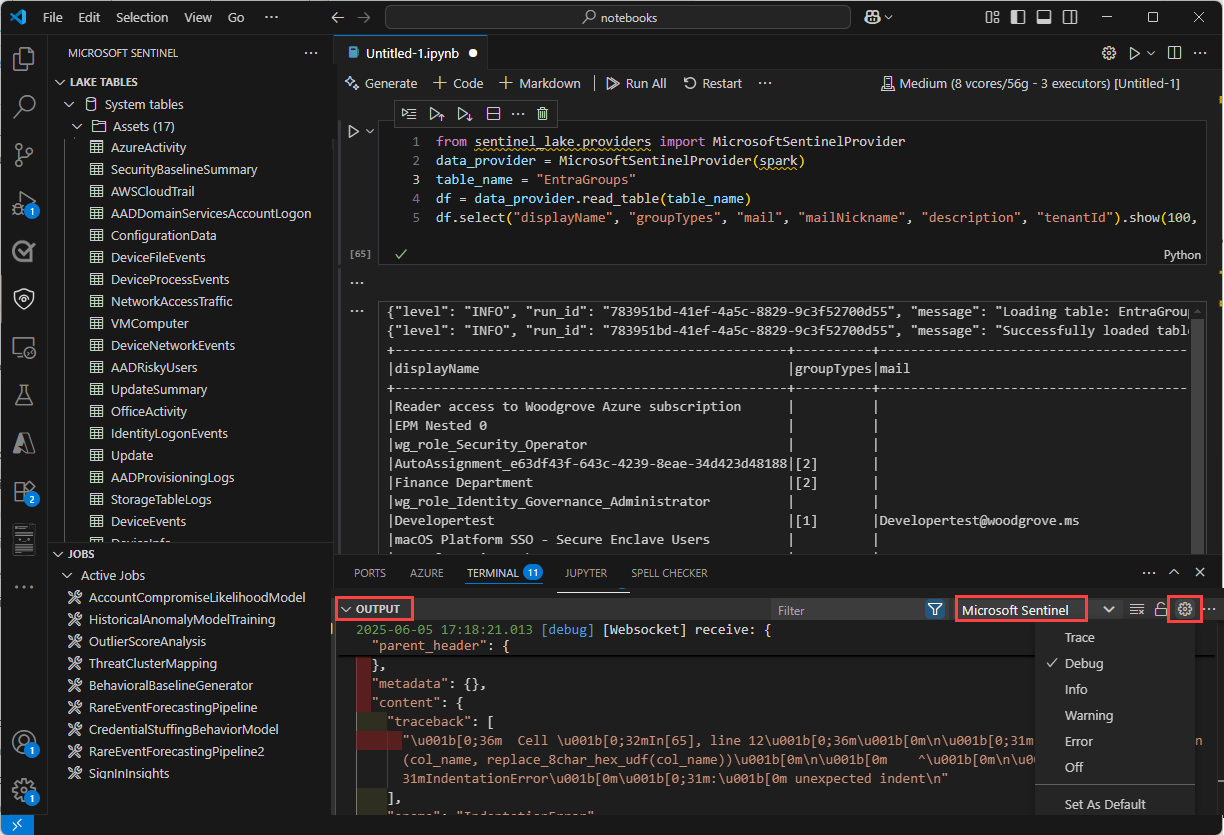
Komunikaty w wierszu w notesie dostarczają opinii i informacji na temat wykonywania komórek kodu. Komunikaty te obejmują aktualizacje stanu wykonywania, wskaźniki postępu i powiadomienia o błędach związane z kodem w poprzedniej komórce
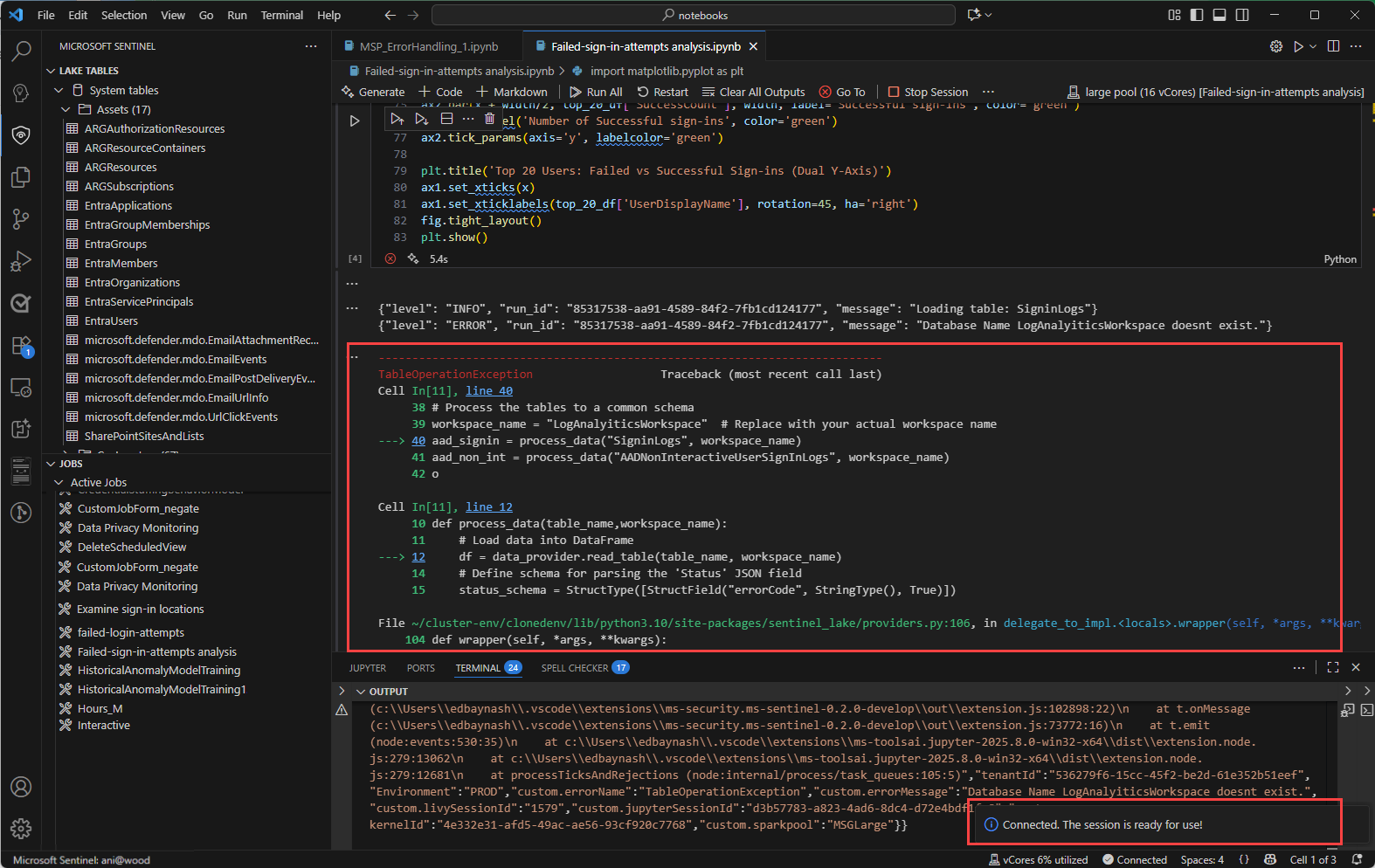
Wyskakujące powiadomienie w prawym dolnym rogu Visual Studio Code, znane również jako wyskakujące komunikaty, udostępnia alerty i aktualizacje w czasie rzeczywistym dotyczące stanu operacji w notesie i sesji platformy Spark. Powiadomienia te obejmują komunikaty, ostrzeżenia i alerty o błędach, takie jak pomyślne połączenie z sesją platformy Spark i ostrzeżenia o przekroczeniu limitu czasu.


Zadania i planowanie
Zadania można zaplanować w określonych godzinach lub interwałach przy użyciu rozszerzenia Microsoft Sentinel dla Visual Studio Code. Zadania umożliwiają automatyzację zadań przetwarzania danych w celu podsumowania, przekształcenia lub analizowania danych w Microsoft Sentinel data lake. Zadania są również używane do przetwarzania danych i zapisywania wyników w tabelach niestandardowych w warstwie usługi Data Lake lub warstwie analizy. Aby uzyskać więcej informacji na temat tworzenia zadań i zarządzania nimi, zobacz Tworzenie zadań notesu Jupyter i zarządzanie nimi.
Parametry i limity usługi dla notesów programu VS Code
W poniższej sekcji wymieniono parametry usługi i limity dotyczące usługi Microsoft Sentinel data lake podczas korzystania z notesów programu VS Code.
| Kategoria | Parametr/limit |
|---|---|
| Tabela niestandardowa w warstwie analizy | Nie można usunąć tabel niestandardowych w warstwie analizy z notesu. Użyj usługi Log Analytics, aby usunąć te tabele. Aby uzyskać więcej informacji, zobacz Dodawanie lub usuwanie tabel i kolumn w Azure Monitorowanie dzienników |
| Limit czasu gniazd internetowych bramy | 2 godziny |
| Przekroczenie limitu czasu zapytania interakcyjnego | 2 godziny |
| Limit czasu braku aktywności sesji interakcyjnej | 20 minut |
| Język | Python |
| Limit czasu zadania notesu | 8 godzin |
| Maksymalna liczba współbieżnych zadań notesu | 3. Kolejne zadania są umieszczane w kolejce |
| Maksymalna liczba równoczesnych użytkowników podczas interakcyjnego wykonywania zapytań | 8–10 w dużej puli |
| Czas rozpoczęcia sesji | Rozpoczęcie sesji obliczeniowej platformy Spark trwa około 5–6 minut. Stan sesji można wyświetlić w dolnej części notesu programu VS Code. |
| Obsługiwane biblioteki | Tylko biblioteki Azure Synapse 3.4 i biblioteka dostawcy Microsoft Sentinel dla funkcji abstrakcyjnych są obsługiwane do wykonywania zapytań w usłudze data lake. Instalacje pip lub biblioteki niestandardowe nie są obsługiwane. |
| Limit środowiska użytkownika programu VS Code do wyświetlania rekordów | 100 000 wierszy |
Rozwiązywanie problemów
W poniższej tabeli wymieniono typowe błędy, które mogą wystąpić podczas pracy z notesami, ich główne przyczyny i sugerowane akcje w celu ich rozwiązania.
| Kategoria błędu | Nazwa błędu | Kod błędu | Komunikat o błędzie | Sugerowana akcja |
|---|---|---|---|---|
| DatabaseError | DatabaseNotFound | 2001 | Nie można odnaleźć bazy danych {DatabaseName}. | Sprawdź, czy baza danych istnieje. Jeśli baza danych jest nowa, poczekaj na odświeżenie metadanych. |
| DatabaseError | AmbiguousDatabaseName | 2002 | Kilka baz danych (identyfikatory: {DatabaseID1}, {DatabaseID2}, ...) ma nazwę {DatabaseName}. Podaj określony identyfikator bazy danych. | Określ identyfikator bazy danych, gdy wiele baz danych ma taką samą nazwę. |
| DatabaseError | DatabaseIdMismatch | 2003 | Nie można odnaleźć bazy danych ({DatabaseName}, identyfikator {DatabaseID}). | Sprawdź zarówno nazwę bazy danych, jak i identyfikator. Aby uzyskać identyfikatory bazy danych, wyświetl listę wszystkich baz danych. |
| DatabaseError | ListDatabasesFailure | 2004 | Nie można pobrać baz danych. Uruchom ponownie sesję i spróbuj ponownie. | Uruchom ponownie sesję i ponów próbę wykonania operacji po kilku minutach. |
| TableError | TableDoesNotExist | 2100 | Nie można odnaleźć tabeli {TableName} w bazie danych {DatabaseName}. | Sprawdź, czy tabela istnieje w bazie danych. Jeśli tabela lub baza danych jest nowa, poczekaj kilka minut i spróbuj ponownie. |
| TableError | ProvisioningIncomplete | 2101 | Tabela {TableName} nie jest gotowa. Poczekaj kilka minut, zanim spróbujesz ponownie. | Tabela jest aprowizowana. Poczekaj kilka minut, zanim spróbujesz ponownie. |
| TableError | DeltaTableMissing | 2102 | Tabela {TableName} jest pusta. Przygotowanie nowych tabel może potrwać do kilku godzin. | Pełne zsynchronizowanie tabeli analitycznej z usługą Data Lake może potrwać kilka godzin. W przypadku tabel znajdujących się tylko w usłudze Data Lake sprawdź, czy dane muszą zostać załadowane lub przywrócone. |
| TableError | TableDoesNotExistForDelete | 2103 | Nie można usunąć tabeli. Nie można odnaleźć tabeli {TableName}. | Sprawdź, czy tabela istnieje w bazie danych. Jeśli tabela lub baza danych jest nowa, poczekaj kilka minut i spróbuj ponownie. |
| AuthorizationFailure | MissingSASToken | 2201 | Nie można uzyskać dostępu do tabeli. Uruchom ponownie sesję i spróbuj ponownie. | Autoryzacja nie powiodła się podczas próby pobrania tokenu dostępu dla tabeli. Uruchom ponownie sesję i spróbuj ponownie. |
| AuthorizationFailure | InvalidSASToken | 2202 | Nie można uzyskać dostępu do tabeli. Uruchom ponownie sesję i spróbuj ponownie. | Autoryzacja nie powiodła się podczas próby pobrania tokenu dostępu dla tabeli. Uruchom ponownie sesję i spróbuj ponownie. |
| AuthorizationFailure | TokenExpired | 2203 | Nie można uzyskać dostępu do tabeli. Uruchom ponownie sesję i spróbuj ponownie. | Autoryzacja nie powiodła się podczas próby pobrania tokenu dostępu dla tabeli. Uruchom ponownie sesję i spróbuj ponownie. |
| AuthorizationFailure | TableInsufficientPermissions | 2204 | Wymagany jest dostęp do tabeli {TableName} w bazie danych {DatabaseName}. | Skontaktuj się z administratorem, aby zażądać dostępu do tabeli lub bazy danych (obszaru roboczego). |
| AuthorizationFailure | InternalTableAccessDenied | 2205 | Dostęp do tabeli {TableName} jest ograniczony. | Tylko tabele systemowe lub zdefiniowane przez użytkownika mogą być dostępne z notesu. |
| AuthorizationFailure | TableAuthFailure | 2206 | Nie można zapisać danych w tabeli. Uruchom ponownie sesję i spróbuj ponownie. | Autoryzacja nie powiodła się podczas próby zapisania danych w tabeli. Uruchom ponownie sesję i spróbuj ponownie. |
| ConfigurationError | HadoopConfigFailure | 2301 | Nie można zaktualizować konfiguracji sesji. Uruchom ponownie sesję i spróbuj ponownie. | Ten problem jest przejściowy i można go rozwiązać, uruchamiając ponownie sesję i próbując ponownie. Jeśli ten problem będzie się powtarzać, skontaktuj się z pomocą techniczną. |
| Dataerror | JsonParsingFailure | 2302 | Metadane tabeli zostały uszkodzone. Skontaktuj się z pomocą techniczną w celu uzyskania pomocy. | Skontaktuj się z pomocą techniczną w celu uzyskania pomocy. Podaj identyfikator dzierżawy, nazwę tabeli i nazwę bazy danych. |
| TableSchemaError | TableSchemaMismatch | 2401 | Nie można odnaleźć kolumny w tabeli docelowej. Wyrównaj schemat ramki danych i tabelę docelową lub użyj trybu zastępowania. | Zaktualizuj schemat ramki danych, aby był zgodny z tabelą w docelowej bazie danych. Tabelę można również zastąpić całkowicie w trybie zastępowania. |
| TableSchemaError | MissingRequiredColumns | 2402 | W ramce danych brakuje kolumny {ColumnName}. Sprawdź schemat ramki danych i wyrównaj go do tabeli docelowej. | Zaktualizuj schemat ramki danych, aby był zgodny z tabelą w docelowej bazie danych. Tabelę można również zastąpić całkowicie w trybie zastępowania. |
| TableSchemaError | ColumnTypeChangeNotAllowed | 2403 | Nie można zmienić typu danych kolumny {ColumnName}. | Zmiana typu danych nie jest dozwolona dla kolumny. Sprawdź istniejące kolumny w tabeli docelowej i wyrównaj wszystkie typy danych w ramce danych. |
| TableSchemaError | ColumnNullabilityChangeNotAllowed | 2404 | Nie można zmienić wartości null kolumny {ColumnName}. | Nie można zaktualizować ustawień wartości null kolumny. Sprawdź tabelę docelową i wyrównaj ustawienia do ramki danych. |
| PozyskiwanieError | FolderCreationFailure | 2501 | Nie można utworzyć magazynu dla tabeli {TableName}. | Ten problem jest przejściowy i można go rozwiązać, uruchamiając ponownie sesję i próbując ponownie. Jeśli ten problem będzie się powtarzać, skontaktuj się z pomocą techniczną. |
| PozyskiwanieError | SubJobRequestFailure | 2502 | Nie można utworzyć zadania pozyskiwania dla tabeli {TableName}. | Ten problem jest przejściowy i można go rozwiązać, uruchamiając ponownie sesję i próbując ponownie. Jeśli ten problem będzie się powtarzać, skontaktuj się z pomocą techniczną. |
| PozyskiwanieError | SubJobCreationFailure | 2503 | Nie można utworzyć zadania pozyskiwania dla tabeli {TableName}. | Ten problem jest przejściowy i można go rozwiązać, uruchamiając ponownie sesję i próbując ponownie. Jeśli ten problem będzie się powtarzać, skontaktuj się z pomocą techniczną. |
| InputError | InvalidWriteMode | 2601 | Nieprawidłowy tryb zapisu. Użyj dołączania lub zastępowania. | Przed zapisaniem ramki danych określ prawidłowy tryb zapisu (dołączanie lub zastępowanie). |
| InputError | PartitioningNotAllowed | 2602 | Nie można partycjonować tabel analizy. | Usuń partycjonowanie wszystkich kolumn w tabelach analitycznych. |
| InputError | MissingTableSuffixLake | 2603 | Nieprawidłowa nazwa tabeli niestandardowej. Wszystkie nazwy tabel niestandardowych w usłudze Data Lake muszą kończyć się _SPRK. | Dodaj _SPRK jako sufiks do nazwy tabeli przed zapisaniem jej w usłudze data lake. |
| InputError | MissingTableSuffixLA | 2604 | Nieprawidłowa nazwa tabeli niestandardowej. Wszystkie nazwy niestandardowych tabel analizy muszą kończyć się _SPRK_CL. | Dodaj _SPRK_CL jako sufiks do nazwy tabeli przed zapisaniem jej w magazynie analizy. |
| UnknownError | InternalServerError | 2901 | Wystąpił problem. Uruchom ponownie sesję i spróbuj ponownie. | Ten problem jest przejściowy i można go rozwiązać, uruchamiając ponownie sesję i próbując ponownie. Jeśli ten problem będzie się powtarzać, skontaktuj się z pomocą techniczną. |
Uwaga
Wykonywanie zapytań dotyczących starszych tabel, takich jak AzureDiagnostics, nie jest obsługiwane.