język zapytań Kusto w usłudze Microsoft Sentinel
język zapytań Kusto jest językiem używanym do pracy z danymi w usłudze Microsoft Sentinel i manipulowania nimi. Dzienniki, które są wprowadzane do obszaru roboczego, nie są warte dużej ilości, jeśli nie możesz ich analizować i uzyskiwać ważne informacje ukryte we wszystkich tych danych. język zapytań Kusto ma nie tylko moc i elastyczność uzyskiwania tych informacji, ale także prostotę ułatwiającą szybkie rozpoczęcie pracy. Jeśli masz doświadczenie w skryptach lub pracy z bazami danych, wiele treści tego artykułu będzie bardzo znane. Jeśli nie, nie martw się, ponieważ intuicyjny charakter języka szybko umożliwia rozpoczęcie pisania własnych zapytań i wspieranie wartości dla organizacji.
W tym artykule przedstawiono podstawowe informacje na temat język zapytań Kusto, obejmujące niektóre z najczęściej używanych funkcji i operatorów, które powinny obejmować od 75 do 80 procent zapytań, które będziesz pisać dziennie. Jeśli potrzebujesz bardziej szczegółowej lub bardziej zaawansowanych zapytań, możesz skorzystać z nowego skoroszytu Advanced KQL for Microsoft Sentinel (zobacz ten wpis w blogu wprowadzającym). Zapoznaj się również z oficjalną dokumentacją język zapytań Kusto oraz różnymi kursami online (takimi jak pluralsight).
Tło — dlaczego język zapytań Kusto?
Usługa Microsoft Sentinel jest oparta na usłudze Azure Monitor i używa obszarów roboczych usługi Log Analytics usługi Azure Monitor do przechowywania wszystkich danych. Te dane obejmują dowolne z następujących elementów:
- dane pozyskiwane ze źródeł zewnętrznych do wstępnie zdefiniowanych tabel przy użyciu łączników danych usługi Microsoft Sentinel.
- dane pozyskiwane ze źródeł zewnętrznych do tabel niestandardowych zdefiniowanych przez użytkownika przy użyciu niestandardowych łączników danych, a także niektórych typów wbudowanych łączników.
- dane utworzone przez samą usługę Microsoft Sentinel, wynikające z analiz tworzonych i realizowanych — na przykład alertów, zdarzeń i informacji związanych z UEBA.
- dane przekazane do usługi Microsoft Sentinel w celu ułatwienia wykrywania i analizy — na przykład źródeł danych analizy zagrożeń i list obserwowanych.
język zapytań Kusto został opracowany w ramach usługi Azure Data Explorer i dlatego jest zoptymalizowany pod kątem wyszukiwania magazynów danych big data w środowisku chmury. Zainspirowany słynnym odkrywcą Undersea Jacques Cousteau (i wymawiany odpowiednio "koo-STOH"), został zaprojektowany, aby ułatwić zagłębienie się w oceany danych i eksplorowanie ukrytych skarbów.
język zapytań Kusto jest również używana w usłudze Azure Monitor (i w związku z tym w usłudze Microsoft Sentinel), w tym niektóre dodatkowe funkcje usługi Azure Monitor, które umożliwiają pobieranie, wizualizowanie, analizowanie i analizowanie danych w magazynach danych usługi Log Analytics. W usłudze Microsoft Sentinel używasz narzędzi opartych na język zapytań Kusto za każdym razem, gdy wizualizujesz i analizujesz dane i wyszukiwanie zagrożeń, niezależnie od tego, czy w istniejących regułach i skoroszytach, czy w tworzeniu własnych.
Ponieważ język zapytań Kusto jest częścią niemal wszystkiego, co robisz w usłudze Microsoft Sentinel, jasne zrozumienie sposobu jej działania pomaga uzyskać znacznie więcej z rozwiązania SIEM.
Co to jest zapytanie?
Zapytanie język zapytań Kusto to żądanie tylko do odczytu do przetwarzania danych i zwracania wyników — nie zapisuje żadnych danych. Zapytania działają na danych zorganizowanych w hierarchię baz danych, tabel i kolumn, podobnie jak w przypadku języka SQL.
Żądania są deklarowane w języku prostym i używają modelu przepływu danych zaprojektowanego w celu ułatwienia odczytywania, zapisywania i automatyzowania składni. Zobaczymy to szczegółowo.
język zapytań Kusto zapytania składają się z instrukcji rozdzielonych średnikami. Istnieje wiele rodzajów instrukcji, ale tylko dwa powszechnie używane typy, które omówimy tutaj:
Instrukcje wyrażeń tabelarycznych są zwykle oznaczane, gdy mówimy o zapytaniach — są to rzeczywiste treści zapytania. Ważne jest, aby wiedzieć o instrukcjach wyrażenia tabelarycznego, że akceptują dane wejściowe tabelaryczne (tabelę lub inne wyrażenie tabelaryczne) i generują dane wyjściowe tabelaryczne. Co najmniej jeden z nich jest wymagany. Większość pozostałej części tego artykułu omówi tego rodzaju oświadczenie.
instrukcje let umożliwiają tworzenie i definiowanie zmiennych i stałych poza treścią zapytania, co ułatwia czytelność i wszechstronność. Są one opcjonalne i zależą od konkretnych potrzeb. Na końcu artykułu zajmiemy się tego rodzaju oświadczeniem.
Środowisko demonstracyjne
Możesz przećwiczyć instrukcje język zapytań Kusto — w tym te w tym artykule — w środowisku demonstracyjnym usługi Log Analytics w witrynie Azure Portal. Korzystanie z tego środowiska praktycznego nie wiąże się z żadnymi opłatami, ale do uzyskania do niego dostępu jest potrzebne konto platformy Azure.
Zapoznaj się ze środowiskiem demonstracyjnym. Podobnie jak usługa Log Analytics w środowisku produkcyjnym, może być używana na wiele sposobów:
Wybierz tabelę, w której chcesz utworzyć zapytanie. Na domyślnej karcie Tabele (widocznej w czerwonym prostokątie w lewym górnym rogu) wybierz tabelę z listy tabel pogrupowanych według tematów (pokazanych w lewym dolnym rogu). Rozwiń tematy, aby wyświetlić poszczególne tabele, a następnie możesz dodatkowo rozwinąć każdą tabelę, aby wyświetlić wszystkie jej pola (kolumny). Dwukrotne kliknięcie tabeli lub nazwy pola spowoduje umieszczenie go w punkcie kursora w oknie zapytania. Wpisz resztę zapytania zgodnie z nazwą tabeli, jak pokazano poniżej.
Znajdź istniejące zapytanie do zbadania lub zmodyfikowania. Wybierz kartę Zapytania (pokazaną w czerwonym prostokątze w lewym górnym rogu), aby wyświetlić listę dostępnych zapytań poza polem. Możesz też wybrać pozycję Zapytania na pasku przycisków w prawym górnym rogu. Możesz eksplorować gotowe zapytania dostarczane z usługą Microsoft Sentinel. Dwukrotne kliknięcie zapytania spowoduje umieszczenie całego zapytania w oknie zapytania w punkcie kursora.
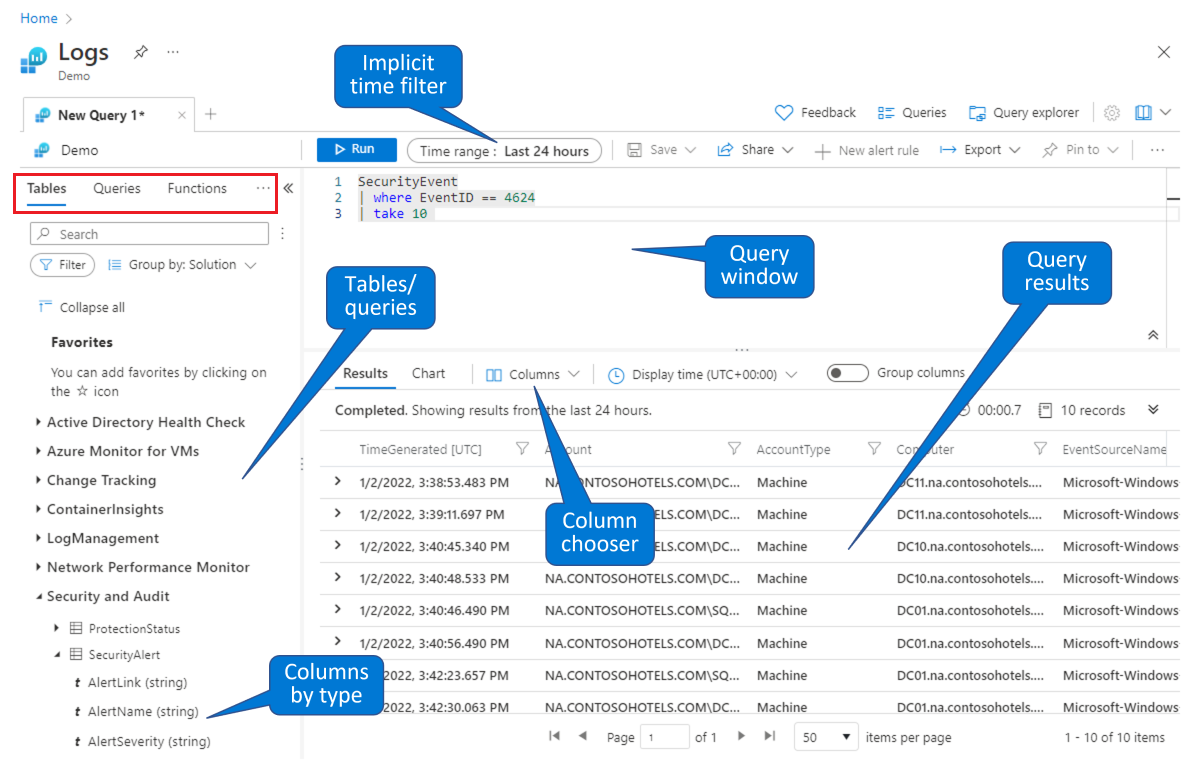
Podobnie jak w tym środowisku demonstracyjnym, możesz wykonywać zapytania i filtrować dane na stronie Dzienniki usługi Microsoft Sentinel. Możesz wybrać tabelę i przejść do szczegółów, aby wyświetlić kolumny. Możesz zmodyfikować domyślne kolumny wyświetlane przy użyciu wybierania kolumn i ustawić domyślny zakres czasu dla zapytań. Jeśli zakres czasu jest jawnie zdefiniowany w zapytaniu, filtr czasu będzie niedostępny (wyszarydzony).
Struktura zapytań
Dobrym miejscem do rozpoczęcia nauki język zapytań Kusto jest zrozumienie ogólnej struktury zapytań. Pierwszą rzeczą, którą zauważysz podczas przeglądania zapytania Kusto, jest użycie symbolu potoku (|). Struktura zapytania Kusto zaczyna się od pobierania danych ze źródła danych, a następnie przekazywania danych przez "potok", a każdy krok zapewnia pewien poziom przetwarzania, a następnie przekazuje dane do następnego kroku. Na końcu potoku otrzymasz końcowy wynik. W efekcie jest to nasz potok:
Get Data | Filter | Summarize | Sort | Select
Ta koncepcja przekazywania danych w dół potoku zapewnia bardzo intuicyjną strukturę, ponieważ łatwo jest utworzyć obraz mentalny danych na każdym kroku.
Aby to zilustrować, przyjrzyjmy się następującemu zapytaniu, które analizuje dzienniki logowania firmy Microsoft Entra. Podczas odczytywania poszczególnych wierszy można zobaczyć słowa kluczowe wskazujące, co dzieje się z danymi. W potoku uwzględniliśmy odpowiedni etap jako komentarz w każdym wierszu.
Uwaga
Komentarze można dodawać do dowolnego wiersza w zapytaniu, poprzedzając je podwójnym ukośnikiem (//).
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
Ponieważ dane wyjściowe każdego kroku służą jako dane wejściowe dla poniższego kroku, kolejność kroków może określać wyniki zapytania i wpływać na jego wydajność. Ważne jest, aby uporządkować kroki zgodnie z tym, co chcesz wydostać się z zapytania.
Napiwek
- Dobrą regułą jest wczesne filtrowanie danych, więc przekazujesz tylko odpowiednie dane w dół potoku. Znacznie zwiększy to wydajność i zapewni przypadkowe uwzględnienie nieistotnych danych w krokach podsumowania.
- W tym artykule przedstawiono inne najlepsze rozwiązania, które należy wziąć pod uwagę. Aby uzyskać bardziej pełną listę, zobacz najlepsze rozwiązania dotyczące zapytań.
Mam nadzieję, że masz teraz uznanie dla ogólnej struktury zapytania w język zapytań Kusto. Teraz przyjrzyjmy się rzeczywistym operatorom zapytań, które są używane do tworzenia zapytania.
Typy danych
Zanim przejdziemy do operatorów zapytań, najpierw przyjrzyjmy się typom danych. Podobnie jak w większości języków, typ danych określa, jakie obliczenia i manipulacje mogą być uruchamiane względem wartości. Jeśli na przykład masz wartość typu ciąg, nie będzie można wykonać na niej obliczeń arytmetycznych.
W język zapytań Kusto większość typów danych jest zgodne ze standardowymi konwencjami i prawdopodobnie wcześniej znasz nazwy. W poniższej tabeli przedstawiono pełną listę:
Tabela typów danych
| Type | Dodatkowe nazwy | Równoważny typ platformy .NET |
|---|---|---|
bool |
Boolean |
System.Boolean |
datetime |
Date |
System.DateTime |
dynamic |
System.Object |
|
guid |
uuid, uniqueid |
System.Guid |
int |
System.Int32 |
|
long |
System.Int64 |
|
real |
Double |
System.Double |
string |
System.String |
|
timespan |
Time |
System.TimeSpan |
decimal |
System.Data.SqlTypes.SqlDecimal |
Chociaż większość typów danych jest standardowa, możesz poznać mniej znanych typów, takich jak dynamiczny, przedział czasu i identyfikator GUID.
Funkcja Dynamic ma strukturę bardzo podobną do formatu JSON, ale z jedną kluczową różnicą: może przechowywać język zapytań Kusto typów danych specyficznych dla tradycyjnych danych JSON, takich jak zagnieżdżona wartość dynamiczna lub przedział czasu. Oto przykład typu dynamicznego:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Przedział czasu to typ danych, który odnosi się do miary czasu, takiego jak godziny, dni lub sekundy. Nie należy mylić przedziału czasu z datą /godziną, która oblicza rzeczywistą datę i godzinę, a nie miarę godziny. W poniższej tabeli przedstawiono listę sufiksów przedziału czasu .
Sufiksy przedziału czasu
| Function | opis |
|---|---|
D |
dniach |
H |
godziny |
M |
minutes |
S |
s |
Ms |
milisekundy |
Microsecond |
Mikrosekundach |
Tick |
Nanosekundach |
Guid to typ danych reprezentujący 128-bitowy, globalnie unikatowy identyfikator, który jest zgodny ze standardowym formatem [8]-[4]-[4]-[4]-[4]-[12], gdzie każdy [liczba] reprezentuje liczbę znaków, a każdy znak może wahać się od 0 do 9 lub f.
Uwaga
język zapytań Kusto ma zarówno operatory tabelaryczne, jak i skalarne. W pozostałej części tego artykułu, jeśli po prostu widzisz słowo "operator", możesz założyć, że oznacza to operator tabelaryczny, chyba że w przeciwnym razie zostanie zanotowany.
Pobieranie, ograniczanie, sortowanie i filtrowanie danych
Podstawowe słownictwo język zapytań Kusto — podstawy, które umożliwią osiągnięcie przeważającej większości zadań — to zbiór operatorów do filtrowania, sortowania i wybierania danych. Pozostałe zadania, które należy wykonać, będą wymagały rozciągnięcia wiedzy o języku w celu spełnienia bardziej zaawansowanych potrzeb. Rozwińmy nieco niektóre polecenia użyte w powyższym przykładzie i przyjrzyjmy takesię metodom , sorti where.
Dla każdego z tych operatorów przeanalizujemy jego użycie w poprzednim przykładzie SigninLogs i poznamy przydatną wskazówkę lub najlepsze rozwiązanie.
Pobieranie danych
Pierwszy wiersz dowolnego podstawowego zapytania określa tabelę, z którą chcesz pracować. W przypadku usługi Microsoft Sentinel prawdopodobnie będzie to nazwa typu dziennika w obszarze roboczym, na przykład SigninLogs, SecurityAlert lub CommonSecurityLog. Przykład:
SigninLogs
Należy pamiętać, że w język zapytań Kusto w nazwach dzienników jest rozróżniana wielkość liter, więc SigninLogs będą signinLogs interpretowane inaczej. Należy zachować ostrożność podczas wybierania nazw dzienników niestandardowych, aby były łatwe do zidentyfikowania i nie są zbyt podobne do innego dziennika.
Ograniczanie danych: limit /
Operator take (i identyczny operator limitu ) służy do ograniczania wyników przez zwrócenie tylko określonej liczby wierszy. Następuje po niej liczba całkowita określająca liczbę wierszy do zwrócenia. Zazwyczaj jest ona używana na końcu zapytania po określeniu kolejności sortowania, a w takim przypadku zwróci ona daną liczbę wierszy w górnej części posortowanej kolejności.
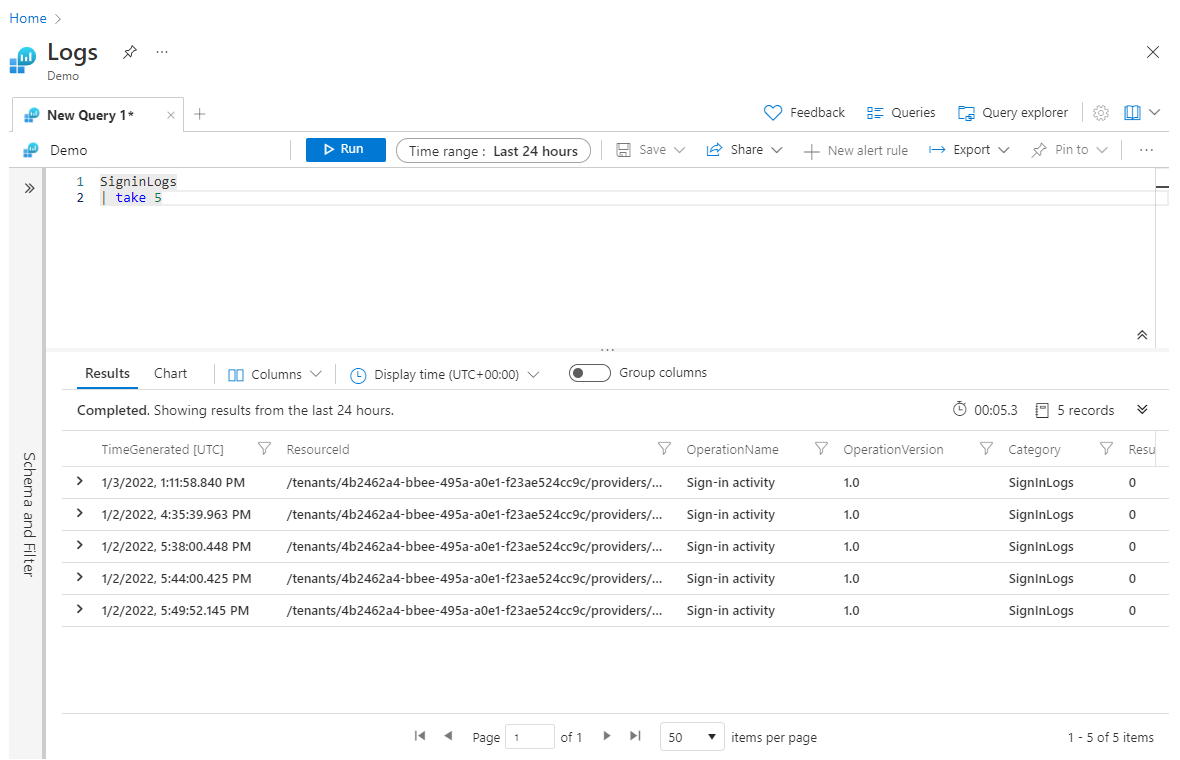
Użycie take wcześniejszej części zapytania może być przydatne podczas testowania zapytania, gdy nie chcesz zwracać dużych zestawów danych. Jeśli jednak umieścisz operację take przed dowolnymi sort operacjami, take zwróci wiersze wybrane losowo — i prawdopodobnie inny zestaw wierszy za każdym razem, gdy zapytanie zostanie uruchomione. Oto przykład użycia metody take:
SigninLogs
| take 5
Napiwek
Podczas pracy nad zupełnie nowym zapytaniem, w którym możesz nie wiedzieć, jak będzie wyglądać zapytanie, warto umieścić instrukcję take na początku, aby sztucznie ograniczyć zestaw danych w celu szybszego przetwarzania i eksperymentowania. Gdy będziesz zadowolony z pełnego zapytania, możesz usunąć początkowy take krok.
Sortowanie danych: kolejność sortowania /
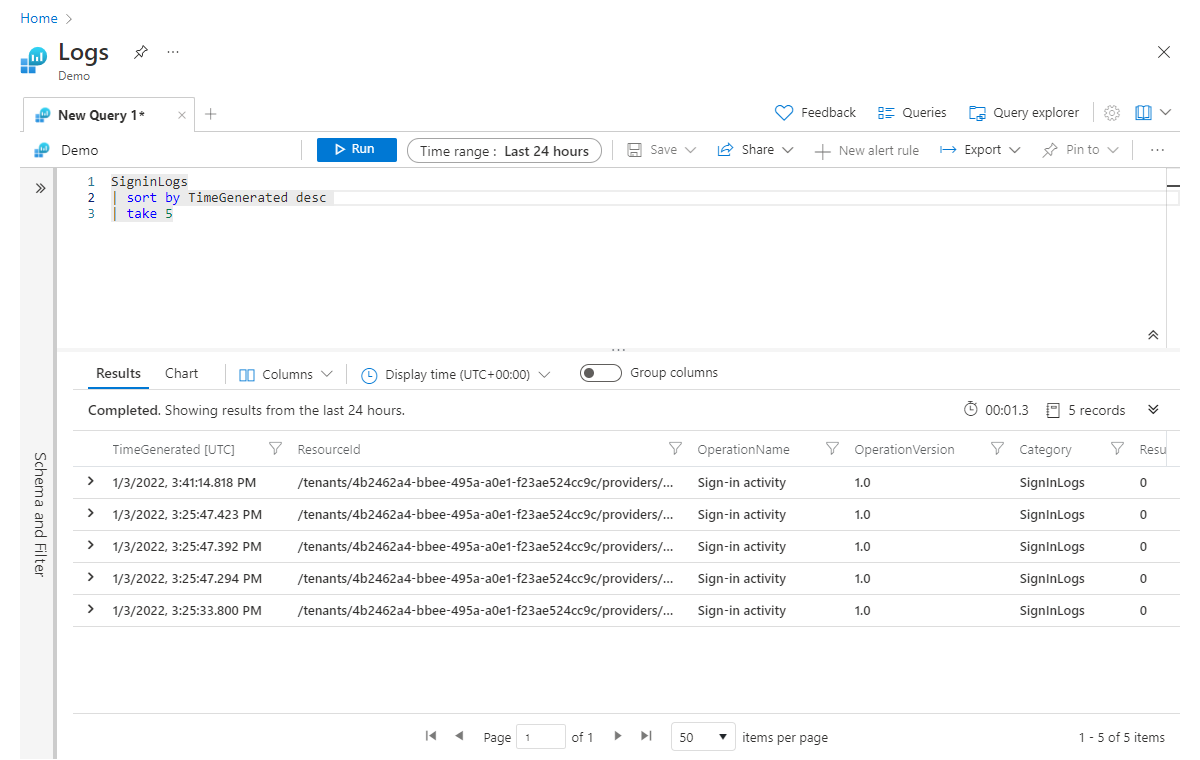
Operator sortowania (i identyczny operator kolejności) służy do sortowania danych według określonej kolumny. W poniższym przykładzie zamówiliśmy wyniki według wartości TimeGenerated i ustawiliśmy kierunek kolejności na malejąco przy użyciu parametru desc, umieszczając najpierw najwyższe wartości. W przypadku kolejności rosnącej użyjemy asc.
Uwaga
Domyślny kierunek sortowania jest malejący, więc technicznie trzeba określić tylko, czy chcesz sortować w kolejności rosnącej. Jednak określenie kierunku sortowania w każdym przypadku sprawi, że zapytanie będzie bardziej czytelne.
SigninLogs
| sort by TimeGenerated desc
| take 5
Jak wspomnieliśmy, umieszczamy sort operator przed operatorem take . Najpierw musimy posortować, aby upewnić się, że otrzymamy odpowiednie pięć rekordów.
Top
Górny operator umożliwia łączenie sort operacji i take w jeden operator:
SigninLogs
| top 5 by TimeGenerated desc
W przypadkach, gdy co najmniej dwa rekordy mają tę samą wartość w kolumnie, według której sortujesz, można dodać więcej kolumn do sortowania. Dodaj dodatkowe kolumny sortowania na liście rozdzielanej przecinkami znajdujące się po pierwszej kolumnie sortowania, ale przed słowem kluczowym kolejność sortowania. Przykład:
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
Teraz, jeśli funkcja TimeGenerated jest taka sama między wieloma rekordami, spróbuje posortować według wartości w kolumnie Tożsamość .
Uwaga
Kiedy należy używać i sort take, i kiedy należy używać top
Jeśli sortujesz tylko jedno pole, użyj metody
top, ponieważ zapewnia lepszą wydajność niż kombinacja elementówsortitake.Jeśli musisz posortować więcej niż jedno pole (na przykład w poprzednim przykładzie powyżej),
topnie można tego zrobić, więc musisz użyć poleceniasortitake.
Filtrowanie danych: gdzie
Operator where jest prawdopodobnie najważniejszym operatorem, ponieważ jest to klucz do upewnienia się, że pracujesz tylko z podzbiorem danych, które są istotne dla danego scenariusza. Należy jak najlepiej filtrować dane tak szybko, jak to możliwe, ponieważ spowoduje to zwiększenie wydajności zapytań przez zmniejszenie ilości danych, które należy przetworzyć w kolejnych krokach; gwarantuje również, że wykonujesz tylko obliczenia na żądanych danych. Zobacz ten przykład:
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
Operator where określa zmienną, operator porównania (skalarny) i wartość. W naszym przypadku użyliśmy >= określenia, że wartość w kolumnie TimeGenerated musi być większa niż (czyli późniejsza niż) lub równa siedmiu dni temu.
Istnieją dwa typy operatorów porównania w język zapytań Kusto: ciąg i liczbowy. W poniższej tabeli przedstawiono pełną listę operatorów liczbowych:
Operatory liczbowe
| Operator | opis |
|---|---|
+ |
Dodatek |
- |
Odejmowanie |
* |
Mnożenie |
/ |
Wydział |
% |
Modulo |
< |
Mniejsze niż |
> |
Większe niż |
== |
Równa się |
!= |
Nierówne |
<= |
Mniejsze niż lub równe |
>= |
Większe niż lub równe |
in |
Równe jednemu z elementów |
!in |
Nie równa się żadnej z elementów |
Lista operatorów ciągów jest znacznie dłuższą listą, ponieważ zawiera permutacje dla wielkości liter, lokalizacji podciągów, prefiksów, sufiksów i wiele innych. Operator == jest zarówno operatorem liczbowym, jak i ciągowym, co oznacza, że może być używany zarówno dla liczb, jak i tekstu. Na przykład obie następujące instrukcje będą prawidłowe, gdzie instrukcje:
| where ResultType == 0| where Category == 'SignInLogs'
Napiwek
Najlepsze rozwiązanie: w większości przypadków prawdopodobnie chcesz filtrować dane według więcej niż jednej kolumny lub filtrować tę samą kolumnę w więcej niż jeden sposób. W tych przypadkach istnieją dwa najlepsze rozwiązania, które należy wziąć pod uwagę.
Można połączyć wiele where instrukcji w jeden krok przy użyciu słowa kluczowego i . Przykład:
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
Jeśli masz wiele filtrów połączonych w jedną where instrukcję przy użyciu słowa kluczowego i , podobnie jak powyżej, uzyskasz lepszą wydajność, umieszczając filtry odwołujące się tylko do jednej kolumny. Dlatego lepszym sposobem na napisanie powyższego zapytania jest:
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
W tym przykładzie pierwszy filtr wymienia jedną kolumnę (TimeGenerated), podczas gdy drugi odwołuje się do dwóch kolumn (Resource and ResourceGroup).
Podsumowanie danych
Summarize jest jednym z najważniejszych operatorów tabelarycznych w język zapytań Kusto, ale jest to również jeden z bardziej złożonych operatorów, aby dowiedzieć się, czy dopiero zaczynasz wykonywać zapytania w językach ogólnie. Zadaniem polecenia summarize jest utworzenie tabeli danych i wyprowadzenie nowej tabeli , która jest agregowana przez co najmniej jedną kolumnę.
Struktura instrukcji summarize
Podstawowa struktura instrukcji summarize jest następująca:
| summarize <aggregation> by <column>
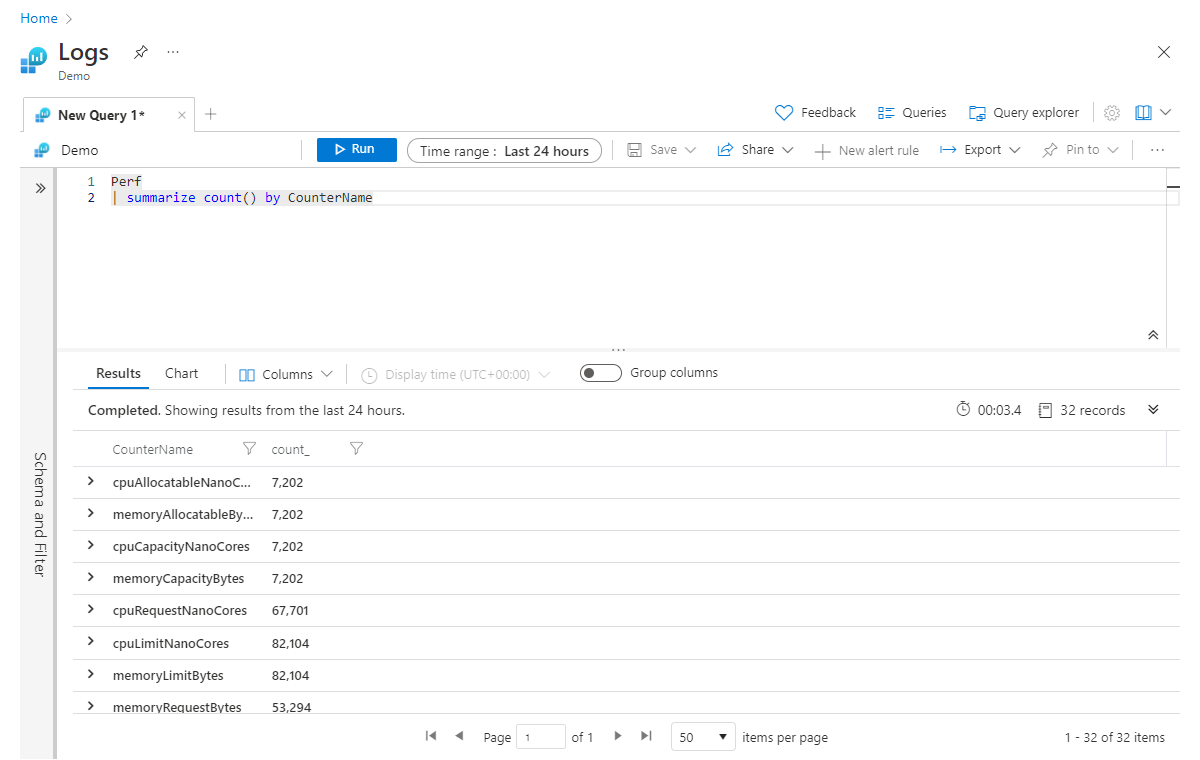
Na przykład następujące polecenie zwróci liczbę rekordów dla każdej wartości CounterName w tabeli Wydajności :
Perf
| summarize count() by CounterName
Ponieważ dane wyjściowe elementu summarize to nowa tabela, wszystkie kolumny, które nie zostały jawnie określone w summarize instrukcji, nie zostaną przekazane potokowi. Aby zilustrować tę koncepcję, rozważmy następujący przykład:
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
W drugim wierszu określamy, że zależy nam tylko na kolumnach ObjectName, CounterValue i CounterName. Następnie podsumowaliśmy, aby uzyskać liczbę rekordów według counterName , a na koniec próbujemy posortować dane w kolejności rosnącej na podstawie kolumny ObjectName . Niestety, to zapytanie zakończy się niepowodzeniem z powodu błędu (wskazującego, że wartość ObjectName jest nieznana), ponieważ po podsumowaniu dołączyliśmy tylko kolumny Count i CounterName w nowej tabeli. Aby uniknąć tego błędu, możemy po prostu dodać obiekt ObjectName na końcu naszego summarize kroku, w następujący sposób:
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
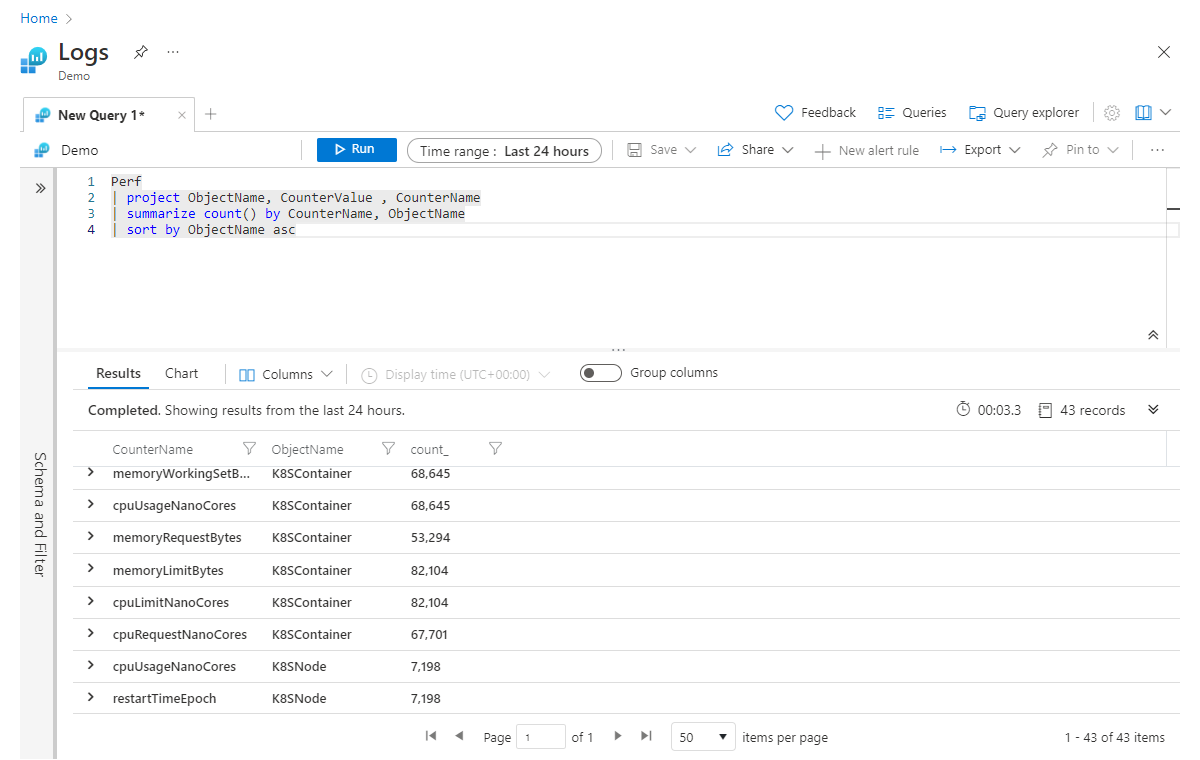
| sort by ObjectName asc
Sposobem odczytania summarize wiersza w głowie będzie: "podsumowywanie liczby rekordów według CounterName i grupowanie według ObjectName". Możesz kontynuować dodawanie kolumn rozdzielonych przecinkami na końcu instrukcji summarize .
Korzystając z poprzedniego przykładu, jeśli chcemy agregować wiele kolumn jednocześnie, możemy to osiągnąć, dodając agregacje do summarize operatora oddzielone przecinkami. W poniższym przykładzie otrzymujemy nie tylko liczbę wszystkich rekordów, ale także sumę wartości w kolumnie CounterValue we wszystkich rekordach (które pasują do wszystkich filtrów w zapytaniu):
Perf
| project ObjectName, CounterValue , CounterName
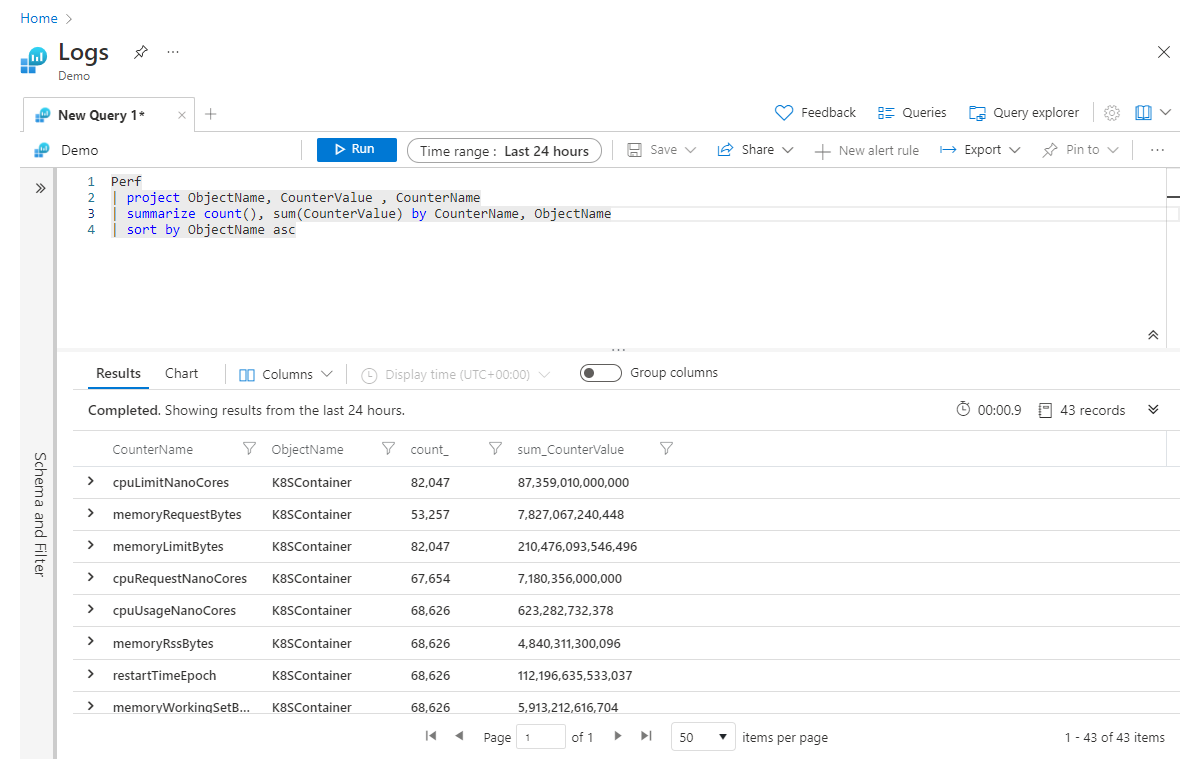
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Zmienianie nazw kolumn zagregowanych
Wygląda to na dobry moment, aby mówić o nazwach kolumn dla tych zagregowanych kolumn. Na początku tej sekcji stwierdziliśmy, że summarize operator przyjmuje tabelę danych i tworzy nową tabelę, a tylko kolumny określone w summarize instrukcji będą kontynuowane w dół potoku. W związku z tym, jeśli chcesz uruchomić powyższy przykład, wynikowe kolumny dla naszej agregacji będą count_ i sum_CounterValue.
Aparat Kusto automatycznie utworzy nazwę kolumny bez konieczności jawnego, ale często okaże się, że nowa kolumna będzie bardziej przyjazna. Możesz łatwo zmienić nazwę kolumny w instrukcji summarize , określając nową nazwę, a następnie = agregację, w następujący sposób:
Perf
| project ObjectName, CounterValue , CounterName
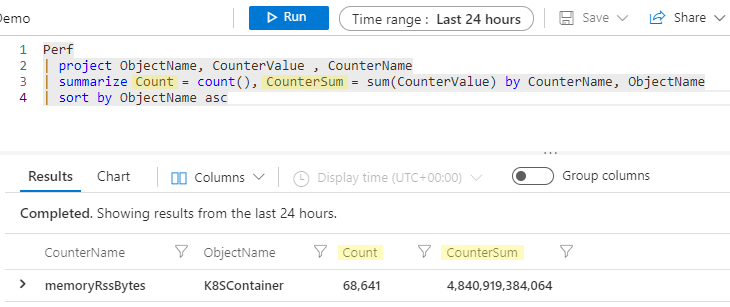
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Teraz nasze podsumowane kolumny będą mieć nazwę Count (Liczba) i CounterSum (Liczniki).
Operator ma o wiele więcej summarize informacji, niż omówimy tutaj, ale należy zainwestować czas, aby go nauczyć, ponieważ jest to kluczowy składnik dowolnej analizy danych, którą planujesz wykonać na danych usługi Microsoft Sentinel.
Dokumentacja agregacji
To wiele funkcji agregacji, ale niektóre z najczęściej używanych funkcji to sum(), count()i avg(). Oto lista częściowa (zobacz pełną listę):
Funkcje agregacji
| Function | opis |
|---|---|
arg_max() |
Zwraca co najmniej jedno wyrażenie, gdy argument jest zmaksymalizowany |
arg_min() |
Zwraca co najmniej jedno wyrażenie, gdy argument jest zminimalizowany |
avg() |
Zwraca średnią wartość w grupie |
buildschema() |
Zwraca minimalny schemat, który przyznaje wszystkie wartości danych wejściowych dynamicznych |
count() |
Zwraca liczbę grup |
countif() |
Zwraca liczbę z predykatem grupy |
dcount() |
Zwraca przybliżoną liczbę unikatowych elementów grupy |
make_bag() |
Zwraca worek właściwości wartości dynamicznych w grupie |
make_list() |
Zwraca listę wszystkich wartości w grupie |
make_set() |
Zwraca zestaw unikatowych wartości w grupie |
max() |
Zwraca maksymalną wartość w grupie |
min() |
Zwraca minimalną wartość w grupie |
percentiles() |
Zwraca przybliżony percentyl grupy |
stdev() |
Zwraca odchylenie standardowe w grupie |
sum() |
Zwraca sumę elementów w grupie |
take_any() |
Zwraca losową wartość niepustą dla grupy |
variance() |
Zwraca wariancję w grupie |
Wybieranie: dodawanie i usuwanie kolumn
W miarę rozpoczynania pracy z zapytaniami może się okazać, że masz więcej informacji niż potrzebujesz w swoich tematach (czyli zbyt wiele kolumn w tabeli). Możesz też potrzebować więcej informacji niż masz (czyli musisz dodać nową kolumnę, która będzie zawierać wyniki analizy innych kolumn). Przyjrzyjmy się kilku operatorom kluczy na potrzeby manipulowania kolumnami.
Projekt i odejście od projektu
Program Project jest w przybliżeniu odpowiednikiem instrukcji select w wielu językach. Umożliwia wybranie kolumn, które mają być zachowywane. Kolejność zwracanych kolumn będzie zgodna z kolejnością kolumn wyświetlanych w instrukcji project , jak pokazano w tym przykładzie:
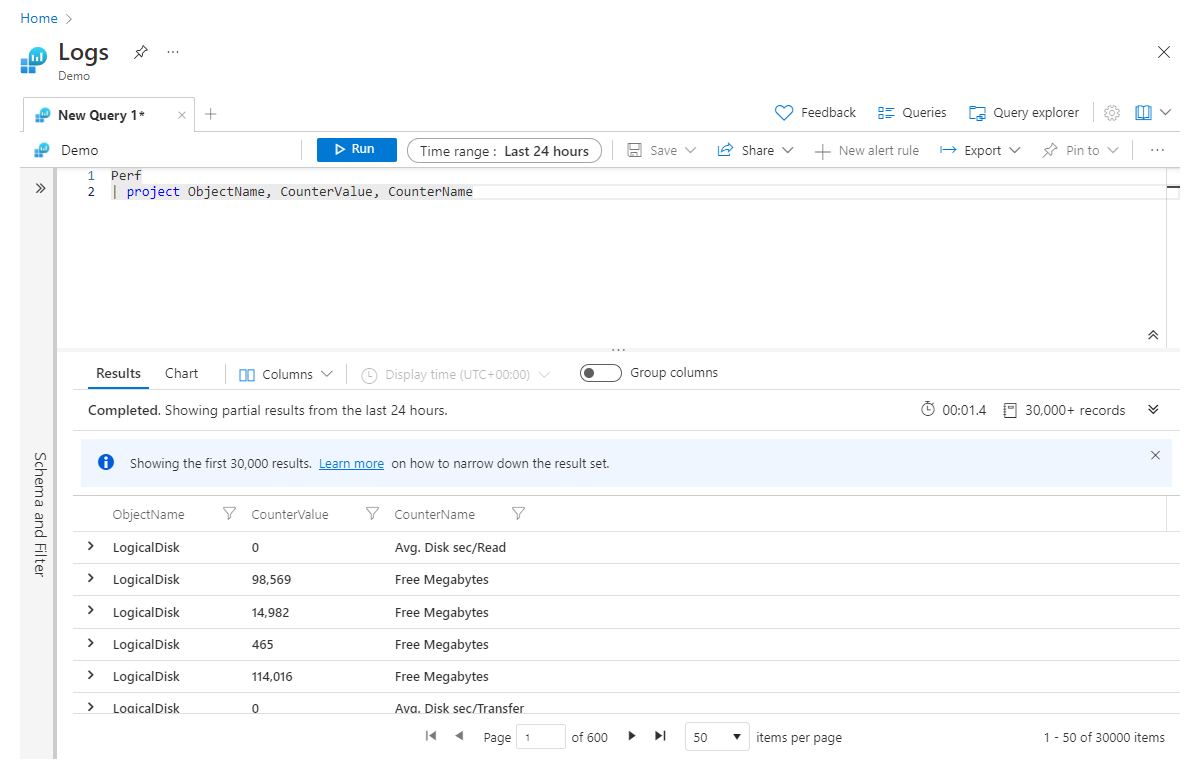
Perf
| project ObjectName, CounterValue, CounterName
Jak można sobie wyobrazić, podczas pracy z bardzo szerokimi zestawami danych może istnieć wiele kolumn, które chcesz zachować, i określenie ich wszystkich według nazwy wymagałoby dużo pisania. W takich przypadkach masz projekt z dala od projektu, co pozwala określić kolumny do usunięcia, a nie te, które mają być zachowywane, w następujący sposób:
Perf
| project-away MG, _ResourceId, Type
Napiwek
Przydatne może być użycie project w dwóch lokalizacjach zapytań na początku i na końcu. Użycie project na wczesnym etapie zapytania może pomóc zwiększyć wydajność, usuwając duże fragmenty danych, których nie trzeba przekazywać w potoku. Użycie go ponownie na końcu umożliwia pozbycie się wszystkich kolumn, które mogły zostać utworzone w poprzednich krokach i nie są potrzebne w końcowych danych wyjściowych.
Rozszerz
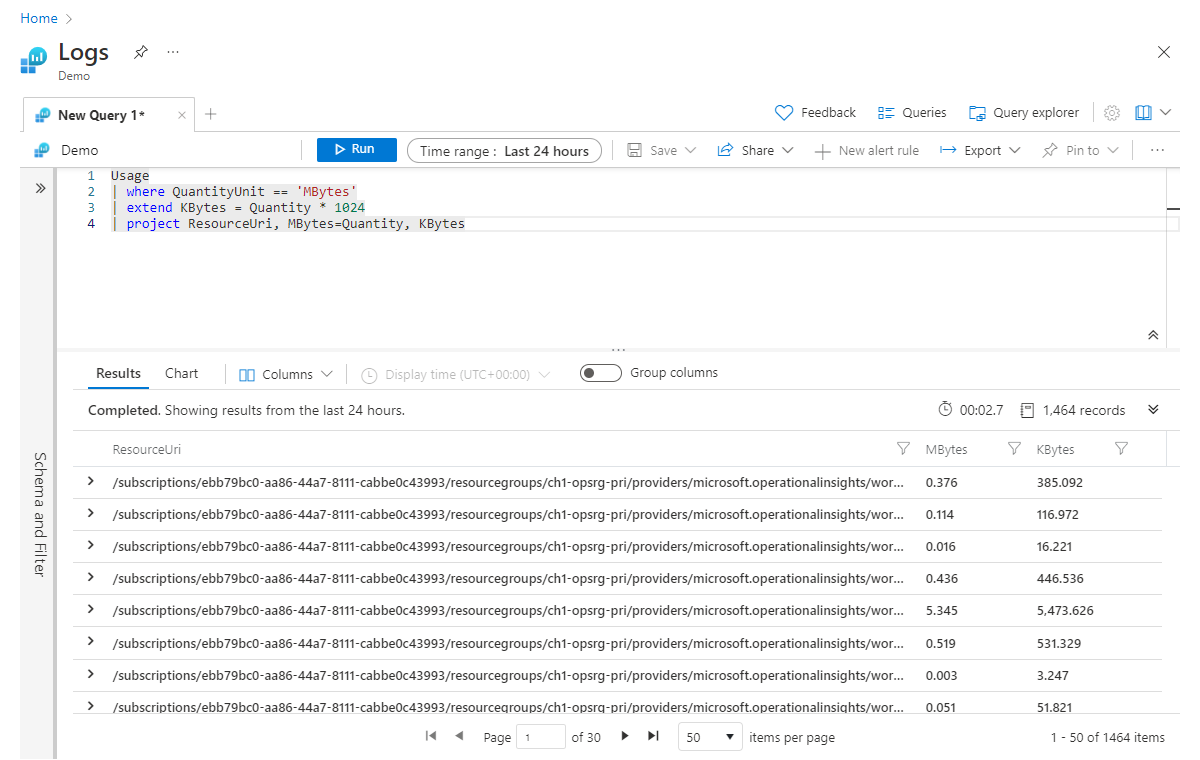
Rozszerzenie służy do tworzenia nowej kolumny obliczeniowej. Może to być przydatne, gdy chcesz wykonać obliczenia względem istniejących kolumn i wyświetlić dane wyjściowe dla każdego wiersza. Przyjrzyjmy się prostego przykładowi, w którym obliczamy nową kolumnę o nazwie Kbytes, którą możemy obliczyć, mnożąc wartość MB (w istniejącej kolumnie Quantity ) o 1024.
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project ResourceUri, MBytes=Quantity, KBytes
W ostatnim wierszu w naszej project instrukcji zmieniliśmy nazwę kolumny Quantity na Mbytes, abyśmy mogli łatwo określić, która jednostka miary jest odpowiednia dla każdej kolumny.
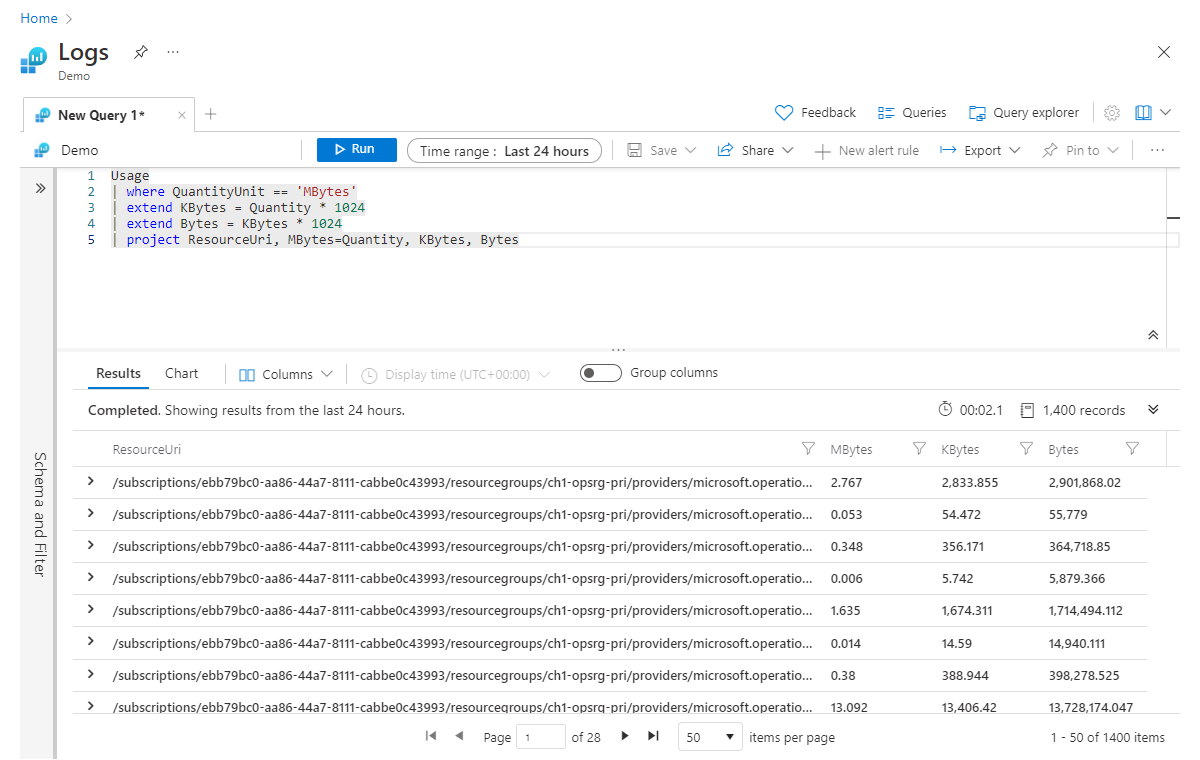
Warto zauważyć, że extend działa również z już kolumnami obliczeniowymi. Możemy na przykład dodać jeszcze jedną kolumnę o nazwie Bajty obliczaną na podstawie kbytów:
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project ResourceUri, MBytes=Quantity, KBytes, Bytes
Przyłączanie tabel
Większość pracy w usłudze Microsoft Sentinel można wykonać przy użyciu jednego typu dziennika, ale czasami chcesz skorelować dane razem lub wykonać wyszukiwanie względem innego zestawu danych. Podobnie jak większość języków zapytań, język zapytań Kusto oferuje kilka operatorów używanych do wykonywania różnych typów sprzężeń. W tej sekcji przyjrzymy się najczęściej używanym operatorom union i join.
Unii
Unia po prostu przyjmuje co najmniej dwie tabele i zwraca wszystkie wiersze. Przykład:
OfficeActivity
| union SecurityEvent
Spowoduje to zwrócenie wszystkich wierszy z tabel OfficeActivity i SecurityEvent . Union oferuje kilka parametrów, których można użyć do dostosowania zachowania unii. Dwa z najbardziej przydatnych elementów to źródło i rodzaj:
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
Parametr withsource umożliwia określenie nazwy nowej kolumny, której wartość w danym wierszu będzie nazwą tabeli, z której pochodzi wiersz. W powyższym przykładzie nazwaliśmy kolumnę SourceTable, a w zależności od wiersza wartość to OfficeActivity lub SecurityEvent.
Drugi określony parametr był rodzaj, który ma dwie opcje: wewnętrzny lub zewnętrzny. W powyższym przykładzie określono wewnętrzne, co oznacza, że jedynymi kolumnami, które będą przechowywane podczas unii, są te, które istnieją w obu tabelach. Alternatywnie, jeśli określono zewnętrzne (czyli wartość domyślna), zostaną zwrócone wszystkie kolumny z obu tabel.
Dołącz
Sprzężenie działa podobnie do union, z wyjątkiem zamiast łączenia tabel w celu utworzenia nowej tabeli, łączymy wiersze w celu utworzenia nowej tabeli. Podobnie jak w przypadku większości języków bazy danych, istnieje wiele typów sprzężeń, które można wykonać. Ogólna składnia elementu to join :
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
Po operatorze join określamy rodzaj sprzężenia, po którym chcemy wykonać nawias otwarty. W nawiasach określasz tabelę, którą chcesz sprzężć, a także inne instrukcje zapytania w tej tabeli, które chcesz dodać. Po nawiasie zamykającym użyjemy słowa kluczowego on , po którym następuje lewa ($left.<columnName> — słowo kluczowe) i prawo ($right.<kolumny columnName>) oddzielone operatorem ==. Oto przykład sprzężenia wewnętrznego:
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
Uwaga
Jeśli obie tabele mają taką samą nazwę dla kolumn, na których wykonujesz sprzężenie, nie musisz używać $left i $right. Zamiast tego możesz po prostu określić nazwę kolumny. Jednak użycie $left i $right jest bardziej wyraźne i ogólnie uważane za dobrą praktykę.
W poniższej tabeli przedstawiono listę dostępnych typów sprzężeń.
Typy sprzężeń
| Typ sprzężenia | opis |
|---|---|
inner |
Zwraca pojedynczą dla każdej kombinacji pasujących wierszy z obu tabel. |
innerunique |
Zwraca wiersze z lewej tabeli z unikatowymi wartościami w polu połączonym, które mają dopasowanie w prawej tabeli. Jest to domyślny nieokreślony typ sprzężenia. |
leftsemi |
Zwraca wszystkie rekordy z lewej tabeli, które mają dopasowanie w prawej tabeli. Zostaną zwrócone tylko kolumny z lewej tabeli. |
rightsemi |
Zwraca wszystkie rekordy z prawej tabeli, które mają dopasowanie w tabeli po lewej stronie. Zostaną zwrócone tylko kolumny z prawej tabeli. |
leftanti/leftantisemi |
Zwraca wszystkie rekordy z lewej tabeli, które nie mają dopasowania w prawej tabeli. Zostaną zwrócone tylko kolumny z lewej tabeli. |
rightanti/rightantisemi |
Zwraca wszystkie rekordy z prawej tabeli, które nie mają dopasowania w lewej tabeli. Zostaną zwrócone tylko kolumny z prawej tabeli. |
leftouter |
Zwraca wszystkie rekordy z lewej tabeli. W przypadku rekordów, które nie mają dopasowania w prawej tabeli, wartości komórek będą miały wartość null. |
rightouter |
Zwraca wszystkie rekordy z prawej tabeli. W przypadku rekordów, które nie mają dopasowania w lewej tabeli, wartości komórek będą miały wartość null. |
fullouter |
Zwraca wszystkie rekordy z obu tabel po lewej i prawej, pasujące lub nie. Niedopasowane wartości będą mieć wartość null. |
Napiwek
Najlepszym rozwiązaniem jest posiadanie najmniejszej tabeli po lewej stronie. W niektórych przypadkach wykonanie tej reguły może dać ogromne korzyści z wydajności, w zależności od typów sprzężeń, które wykonujesz, oraz rozmiar tabel.
Evaluate
Możesz pamiętać, że z powrotem w pierwszym przykładzie zobaczyliśmy operator evaluate na jednym z wierszy. Operator evaluate jest rzadziej używany niż te, których wcześniej dotknęliśmy. Jednak wiedza o tym, jak evaluate działa operator, jest dobrze warta twojego czasu. Po raz kolejny jest to pierwsze zapytanie, w którym zobaczysz evaluate w drugim wierszu.
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
Ten operator umożliwia wywoływanie dostępnych wtyczek (w zasadzie wbudowanych funkcji). Wiele z tych wtyczek koncentruje się na nauce o danych, takich jak autoklastrowanie, różnice i sequence_detect, co pozwala na przeprowadzanie zaawansowanej analizy i odnajdywanie anomalii statystycznych i wartości odstających.
Wtyczka użyta w powyższym przykładzie została wywołana bag_unpack i ułatwia wykonywanie fragmentu danych dynamicznych i konwertowanie ich na kolumny. Pamiętaj, że dane dynamiczne to typ danych, który wygląda bardzo podobnie do formatu JSON, jak pokazano w tym przykładzie:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
W tym przypadku chcieliśmy podsumować dane według miasta, ale miasto jest zawarte jako właściwość w kolumnie LocationDetails . Aby użyć właściwości miasta w zapytaniu, musieliśmy najpierw przekonwertować ją na kolumnę przy użyciu bag_unpack.
Wracając do naszych oryginalnych kroków potoku, widzieliśmy następujące elementy:
Get Data | Filter | Summarize | Sort | Select
Teraz, gdy rozważaliśmy evaluate operator, możemy zobaczyć, że reprezentuje nowy etap w potoku, który teraz wygląda następująco:
Get Data | Parse | Filter | Summarize | Sort | Select
Istnieje wiele innych przykładów operatorów i funkcji, które mogą służyć do analizowania źródeł danych w bardziej czytelny i możliwy do manipulowania formatem. Możesz dowiedzieć się więcej o nich — i pozostałej części język zapytań Kusto — w pełnej dokumentacji i w skoroszycie.
Instrukcje Let
Teraz, gdy omówiliśmy wiele głównych operatorów i typów danych, podsumujmy się instrukcją let, która jest doskonałym sposobem na ułatwienie odczytywania, edytowania i obsługi zapytań.
Umożliwia utworzenie i ustawienie zmiennej lub przypisanie nazwy do wyrażenia. To wyrażenie może być pojedynczą wartością, ale może to być również całe zapytanie. Oto prosty przykład:
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
W tym miejscu określiliśmy nazwę aWeekAgo i ustawiliśmy ją tak, aby była równa danych wyjściowych funkcji przedziału czasu , która zwraca wartość typu data/godzina . Następnie kończymy instrukcję let średnikiem. Teraz mamy nową zmienną o nazwie aWeekAgo , która może być używana w dowolnym miejscu w zapytaniu.
Jak już wspomniano, możesz użyć instrukcji let , aby wykonać całe zapytanie i nadać wynik nazwę. Ponieważ wyniki zapytania, będące wyrażeniami tabelarycznymi, mogą być używane jako dane wejściowe zapytań, można traktować ten nazwany wynik jako tabelę na potrzeby uruchamiania innego zapytania w nim. Oto niewielka modyfikacja poprzedniego przykładu:
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
W tym przypadku utworzyliśmy drugą instrukcję let , w której opakowaliśmy całe zapytanie w nową zmienną o nazwie getSignins. Podobnie jak wcześniej, kończymy drugą instrukcję let średnikiem. Następnie wywołujemy zmienną w ostatnim wierszu, co spowoduje uruchomienie zapytania. Zwróć uwagę, że byliśmy w stanie użyć aWeekAgo w drugiej instrukcji let . Jest to spowodowane tym, że określono go w poprzednim wierszu; Jeśli mieliśmy zamienić instrukcje let , aby getSignins przyszedł pierwszy, wystąpi błąd.
Teraz możemy użyć polecenia getSignins jako podstawy innego zapytania (w tym samym oknie):
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
Instrukcje let zapewniają większą moc i elastyczność w ułatwianiu organizowania zapytań. Umożliwia definiowanie wartości skalarnych i tabelarycznych oraz tworzenie funkcji zdefiniowanych przez użytkownika. Naprawdę przydają się podczas organizowania bardziej złożonych zapytań, które mogą wykonywać wiele sprzężeń.
Następne kroki
Chociaż ten artykuł ledwo zadrapał powierzchnię, masz teraz niezbędne podstawy i omówiliśmy części, których będziesz używać najczęściej, aby wykonać swoją pracę w usłudze Microsoft Sentinel.
Zaawansowany skoroszyt KQL dla usługi Microsoft Sentinel
Skorzystaj z język zapytań Kusto skoroszytu bezpośrednio w usłudze Microsoft Sentinel — skoroszyt Advanced KQL for Microsoft Sentinel. Zapewnia on pomoc krok po kroku i przykłady dla wielu sytuacji, które prawdopodobnie napotkasz podczas codziennych operacji zabezpieczeń, a także wskazuje na wiele gotowych, gotowych, gotowych przykładów reguł analizy, skoroszytów, reguł wyszukiwania zagrożeń i innych elementów korzystających z zapytań Kusto. Uruchom ten skoroszyt z bloku Skoroszyty w usłudze Microsoft Sentinel.
Zaawansowany skoroszyt platformy KQL — umożliwienie ci stosowania języka KQL-savvy to doskonały wpis w blogu, który pokazuje, jak używać tego skoroszytu.
Więcej zasobów
Zapoznaj się z tą kolekcją zasobów uczenia się, szkolenia i umiejętności, aby poszerzyć i pogłębić swoją wiedzę na temat język zapytań Kusto.