Diagnozowanie typowych scenariuszy za pomocą usługi Service Fabric
W tym artykule przedstawiono typowe scenariusze napotykane przez użytkowników w obszarze monitorowania i diagnostyki za pomocą usługi Service Fabric. Przedstawione scenariusze obejmują wszystkie trzy warstwy usługi Service Fabric: aplikacja, klaster i infrastruktura. Każde rozwiązanie używa dzienników usługi Application Insights i usługi Azure Monitor, narzędzi do monitorowania platformy Azure, aby ukończyć każdy scenariusz. Kroki w każdym rozwiązaniu dają użytkownikom wprowadzenie do korzystania z dzienników usługi Application Insights i usługi Azure Monitor w kontekście usługi Service Fabric.
Wymagania wstępne i zalecenia
Rozwiązania w tym artykule korzystają z następujących narzędzi. Zalecamy skonfigurowanie i skonfigurowanie następujących ustawień:
- Usługa Application Insights z usługą Service Fabric
- Włączanie Diagnostyka Azure w klastrze
- Konfigurowanie obszaru roboczego usługi Log Analytics
- Agent usługi Log Analytics do śledzenia liczników wydajności
Jak mogę zobaczyć nieobsługiwane wyjątki w mojej aplikacji?
Przejdź do zasobu usługi Application Insights, za pomocą którego skonfigurowano aplikację.
Wybierz pozycję Wyszukaj w lewym górnym rogu. Następnie wybierz filtr na następnym panelu.
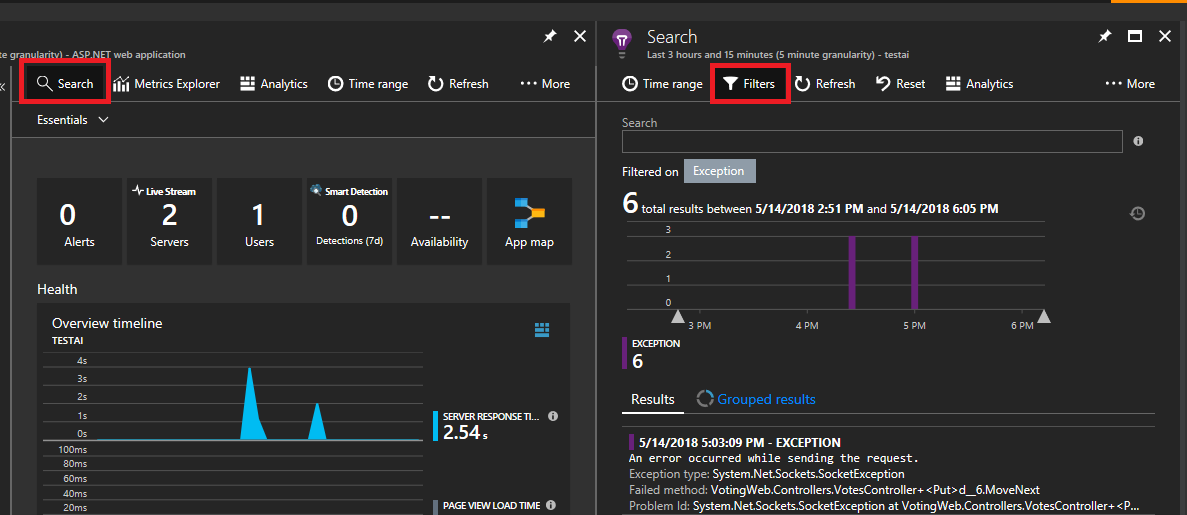
Zobaczysz wiele typów zdarzeń (ślady, żądania, zdarzenia niestandardowe). Wybierz pozycję "Wyjątek" jako filtr.
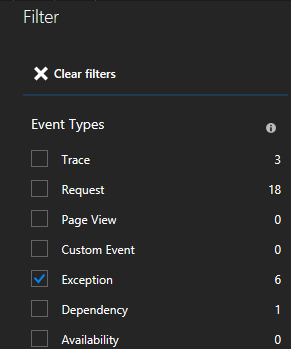
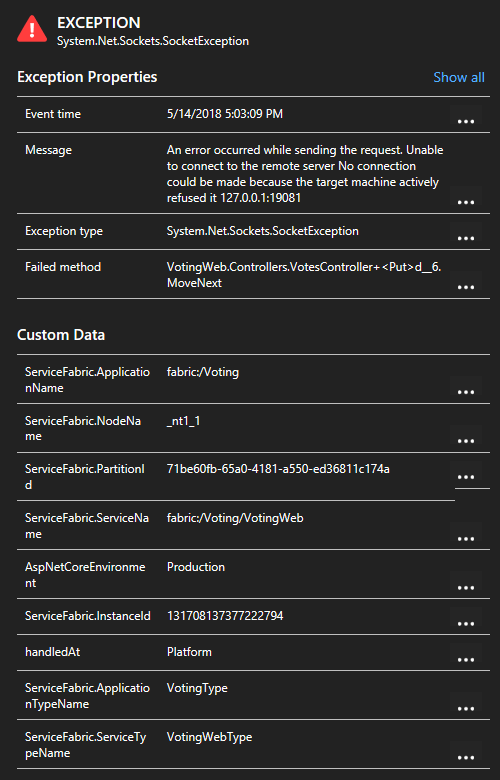
Klikając wyjątek na liście, możesz zapoznać się z bardziej szczegółowymi informacjami, w tym kontekstem usługi, jeśli używasz zestawu SDK usługi Application Insights usługi Service Fabric.
Jak mogę wyświetlić, które wywołania HTTP są używane w moich usługach?
W tym samym zasobie usługi Application Insights można filtrować według "żądań" zamiast wyjątków i wyświetlać wszystkie wykonane żądania
Jeśli używasz zestawu SDK usługi Service Fabric Application Insights, możesz zobaczyć wizualną reprezentację usług połączonych ze sobą oraz liczbę żądań zakończonych powodzeniem i niepowodzeniem. Po lewej stronie wybierz pozycję "Mapa aplikacji"
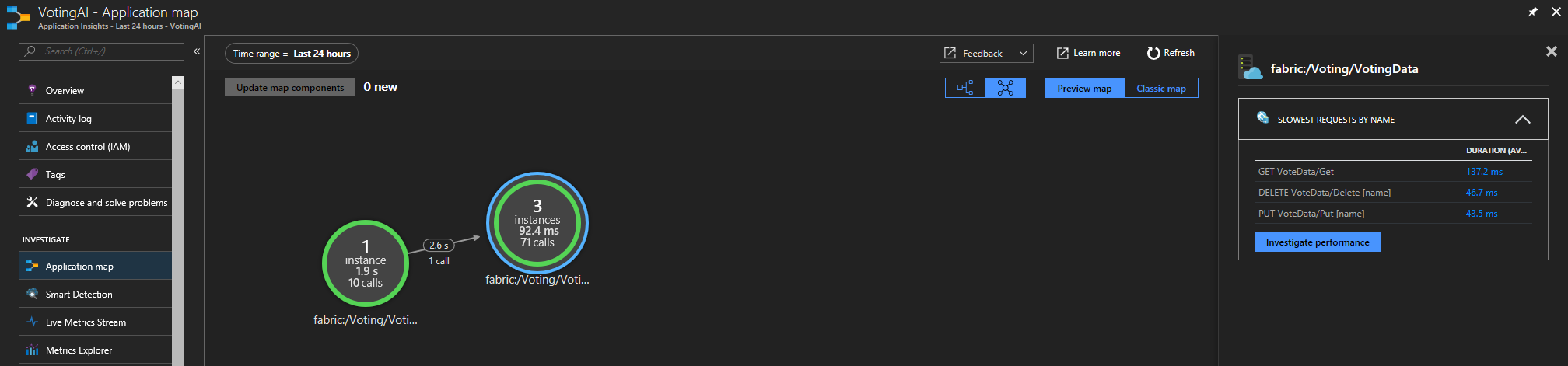
Aby uzyskać więcej informacji na mapie aplikacji, odwiedź dokumentację mapy aplikacji
Jak mogę utworzyć alert, gdy węzeł ulegnie awarii
Zdarzenia węzła są śledzone przez klaster usługi Service Fabric. Przejdź do zasobu rozwiązania Service Fabric Analytics o nazwie ServiceFabric(NameofResourceGroup)
Wybierz wykres w dolnej części bloku zatytułowanego "Podsumowanie"
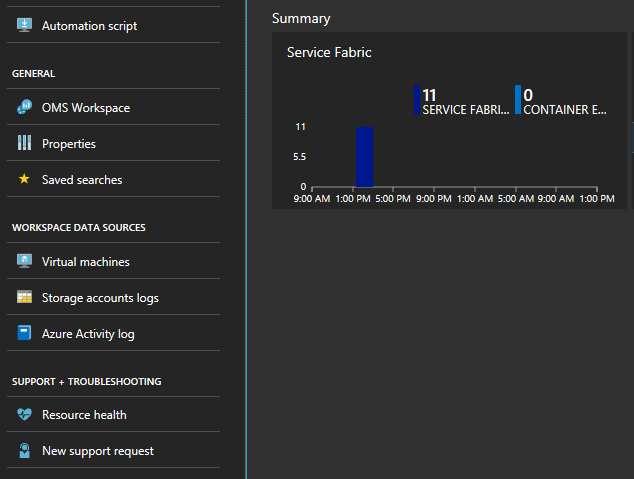
W tym miejscu masz wiele grafów i kafelków wyświetlających różne metryki. Wybierz jeden z grafów i nastąpi przejście do przeszukiwania dzienników. W tym miejscu można wykonywać zapytania dotyczące dowolnych zdarzeń klastra lub liczników wydajności.
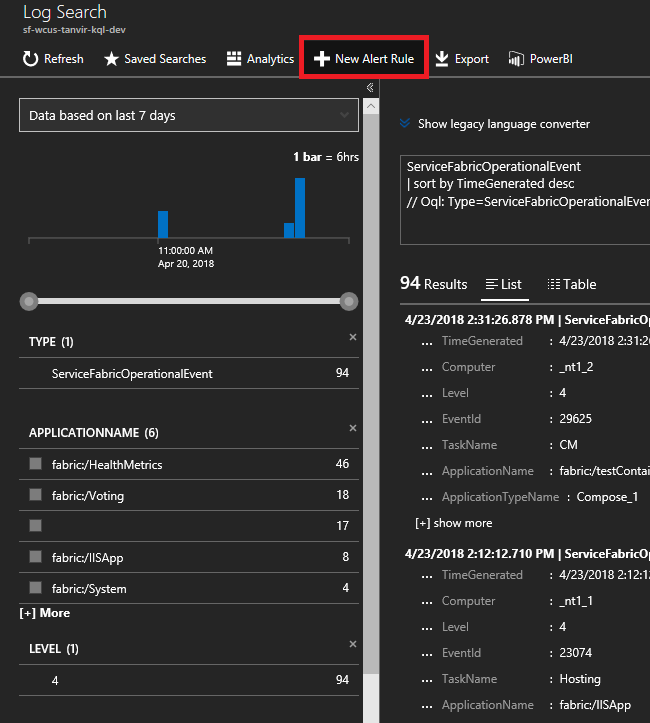
Wprowadź następujące zapytanie. Te identyfikatory zdarzeń znajdują się w dokumentacji zdarzeń węzła
ServiceFabricOperationalEvent | where EventID >= 25622 and EventID <= 25626Wybierz pozycję "Nowa reguła alertu" u góry, a teraz po nadejściu zdarzenia na podstawie tego zapytania otrzymasz alert w wybranej metodzie komunikacji.
Jak można otrzymywać alerty dotyczące wycofywania uaktualnienia aplikacji?
W tym samym oknie przeszukiwania dzienników, co poprzednio, wprowadź następujące zapytanie dotyczące wycofywania uaktualnień. Te identyfikatory zdarzeń znajdują się w obszarze Dokumentacja zdarzeń aplikacji
ServiceFabricOperationalEvent | where EventID == 29623 or EventID == 29624Wybierz pozycję "Nowa reguła alertu" u góry, a teraz po nadejściu zdarzenia na podstawie tego zapytania otrzymasz alert.
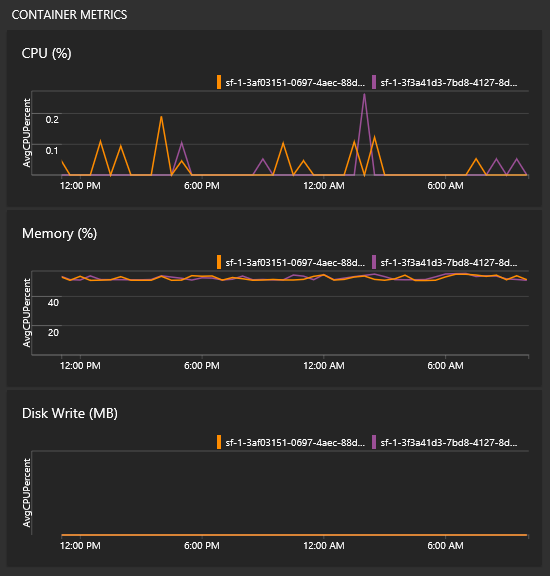
Jak mogę zobaczyć metryki kontenera?
W tym samym widoku ze wszystkimi wykresami zobaczysz niektóre kafelki wydajności kontenerów. Aby wypełnić te kafelki, potrzebny jest agent usługi Log Analytics i rozwiązanie do monitorowania kontenerów.
Uwaga
Aby instrumentować dane telemetryczne z wewnątrz kontenera, należy dodać pakiet nuget usługi Application Insights dla kontenerów.
Jak monitorować liczniki wydajności?
Po dodaniu agenta usługi Log Analytics do klastra należy dodać określone liczniki wydajności, które chcesz śledzić. Przejdź do strony obszaru roboczego usługi Log Analytics w portalu — na stronie rozwiązania karta obszaru roboczego znajduje się w menu po lewej stronie.
Po przejściu na stronę obszaru roboczego wybierz pozycję "Ustawienia zaawansowane" w tym samym menu po lewej stronie.
Wybierz pozycję Dane > Liczniki wydajności systemu Windows (dane > liczniki wydajności systemu Linux dla maszyn z systemem Linux), aby rozpocząć zbieranie określonych liczników z węzłów za pośrednictwem agenta usługi Log Analytics. Oto przykłady formatu liczników do dodania
.NET CLR Memory(<ProcessNameHere>)\\# Total committed BytesProcessor(_Total)\\% Processor TimeW przewodniku Szybki start używane są nazwy procesów VotingData i VotingWeb, więc śledzenie tych liczników wyglądałoby następująco:
.NET CLR Memory(VotingData)\\# Total committed Bytes.NET CLR Memory(VotingWeb)\\# Total committed Bytes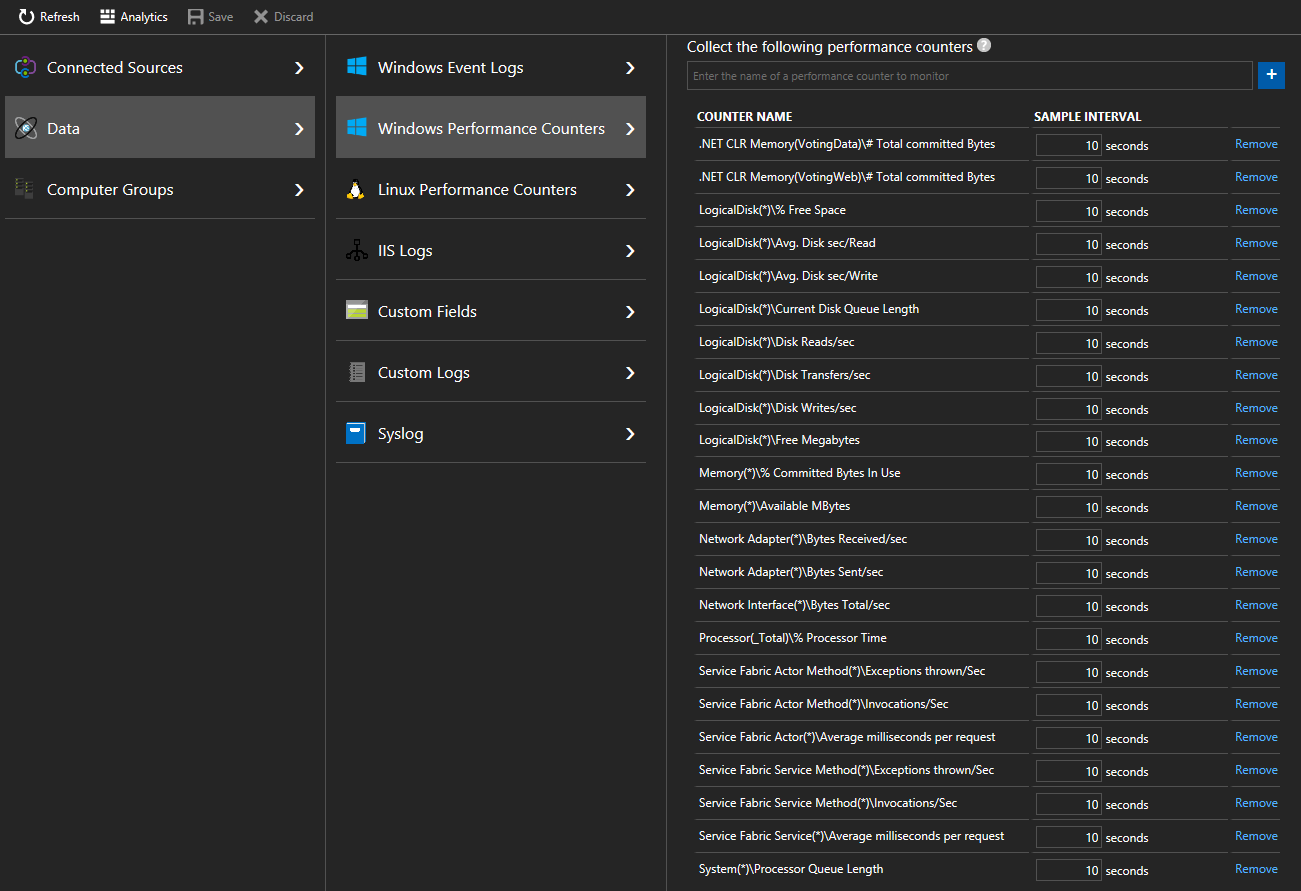
Dzięki temu możesz zobaczyć, jak infrastruktura obsługuje obciążenia, i ustawiać odpowiednie alerty na podstawie wykorzystania zasobów. Na przykład — możesz ustawić alert, jeśli całkowite użycie procesora przekroczy 90% lub poniżej 5%. Nazwa licznika używana w tym celu to "% czasu procesora". Można to zrobić, tworząc regułę alertu dla następującego zapytania:
Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | where CounterValue >= 90 or CounterValue <= 5.
Jak mogę śledzić wydajność moich usług Reliable Services i Aktorów?
Aby śledzić wydajność usług Reliable Services lub Actors w aplikacjach, należy również zbierać liczniki aktora usługi Service Fabric, metody aktora, usługi i metody usługi. Oto przykłady niezawodnych liczników wydajności usług i aktorów do zbierania
Uwaga
Obecnie nie można zbierać liczników wydajności usługi Service Fabric przez agenta usługi Log Analytics, ale mogą być zbierane przez inne rozwiązania diagnostyczne
Service Fabric Service(*)\\Average milliseconds per requestService Fabric Service Method(*)\\Invocations/SecService Fabric Actor(*)\\Average milliseconds per requestService Fabric Actor Method(*)\\Invocations/Sec
Sprawdź te linki, aby uzyskać pełną listę liczników wydajności w usługach Reliable Services i Actors
Następne kroki
- Wyszukiwanie typowych błędów aktywacji pakietów kodu
- Konfigurowanie alertów w sztucznej inteligencji w celu powiadamiania o zmianach wydajności lub użycia
- Funkcja wykrywania inteligentnego w usłudze Application Insights przeprowadza proaktywną analizę danych telemetrycznych wysyłanych do sztucznej inteligencji w celu ostrzeżenia o potencjalnych problemach z wydajnością
- Dowiedz się więcej o alertach dzienników usługi Azure Monitor, aby ułatwić wykrywanie i diagnostykę.
- W przypadku klastrów lokalnych dzienniki usługi Azure Monitor oferują bramę (serwer proxy przekazywania HTTP), która może służyć do wysyłania danych do dzienników usługi Azure Monitor. Dowiedz się więcej o tym w temacie Łączenie komputerów bez dostępu do Internetu do dzienników usługi Azure Monitor przy użyciu bramy usługi Log Analytics
- Zapoznaj się z funkcjami przeszukiwania dzienników i wykonywania zapytań oferowanych w ramach dzienników usługi Azure Monitor
- Aby zapoznać się ze szczegółowym omówieniem dzienników usługi Azure Monitor i ofertami, przeczytaj co to są dzienniki usługi Azure Monitor?