Monitorowanie usługi Azure Service Fabric
W tym artykule opisano:
- Typy danych monitorowania, które można zbierać dla tej usługi.
- Sposoby analizowania tych danych.
Uwaga
Jeśli znasz już tę usługę i/lub usługę Azure Monitor i chcesz wiedzieć, jak analizować dane monitorowania, zobacz sekcję Analizowanie pod koniec tego artykułu.
Jeśli masz krytyczne aplikacje i procesy biznesowe korzystające z zasobów platformy Azure, musisz monitorować i otrzymywać alerty dla systemu. Usługa Azure Monitor zbiera i agreguje metryki i dzienniki z każdego składnika systemu. Usługa Azure Monitor zapewnia wgląd w dostępność, wydajność i odporność oraz powiadamia o problemach. Do konfigurowania i wyświetlania danych monitorowania można użyć witryny Azure Portal, programu PowerShell, interfejsu wiersza polecenia platformy Azure, interfejsu API REST lub bibliotek klienckich.
- Aby uzyskać więcej informacji na temat usługi Azure Monitor, zobacz Omówienie usługi Azure Monitor.
- Aby uzyskać więcej informacji na temat ogólnego monitorowania zasobów platformy Azure, zobacz Monitorowanie zasobów platformy Azure za pomocą usługi Azure Monitor.
Monitorowanie usługi Azure Service Fabric
Usługa Azure Service Fabric ma następujące warstwy, które można monitorować:
- Monitorowanie aplikacji: aplikacje uruchamiane w węzłach. Aplikacje można monitorować za pomocą klucza usługi Application Insights lub zestawu SDK, magazynu zdarzeń lub rejestrowania podstawowego ASP.NET.
- Monitorowanie platformy (klastra): metryki klienta, dzienniki i zdarzenia dla platformy lub węzłów klastra, w tym metryki kontenera . Metryki i dzienniki różnią się w przypadku węzłów systemu Linux lub Windows.
- Monitorowanie infrastruktury (wydajności): Kondycja usługi i liczniki wydajności dla infrastruktury usług.
Możesz monitorować sposób używania aplikacji, akcje wykonywane przez platformę usługi Service Fabric, wykorzystanie zasobów z licznikami wydajności oraz ogólną kondycję klastra. Dzienniki usługi Azure Monitor i usługa Application Insights oferują wbudowaną integrację z usługą Service Fabric.
- Aby dowiedzieć się więcej o najlepszych rozwiązaniach, zobacz Monitorowanie i najlepsze rozwiązania diagnostyczne dotyczące usługi Azure Service Fabric.
- Aby zapoznać się z samouczkiem przedstawiającym wyświetlanie zdarzeń i raportów kondycji usługi Service Fabric, wykonywanie zapytań o interfejsy API magazynu zdarzeń i monitorowanie liczników wydajności, zobacz Samouczek: monitorowanie klastra usługi Service Fabric na platformie Azure.
- Aby dowiedzieć się, jak skonfigurować dzienniki usługi Azure Monitor w celu monitorowania kontenerów systemu Windows zorganizowanych w usłudze Service Fabric, zobacz Samouczek: monitorowanie kontenerów systemu Windows w usłudze Service Fabric przy użyciu dzienników usługi Azure Monitor.
Service Fabric Explorer
Service Fabric Explorer, aplikacja klasyczna dla systemów Windows, macOS i Linux, to narzędzie typu open source do sprawdzania klastrów usługi Azure Service Fabric i zarządzania nimi. Aby włączyć automatyzację, każda akcja, którą można wykonać za pomocą narzędzia Service Fabric Explorer, można również wykonać za pomocą programu PowerShell lub interfejsu API REST.
Monitorowanie aplikacji
Monitorowanie aplikacji śledzi sposób użycia funkcji i składników aplikacji. Chcesz monitorować aplikacje, aby upewnić się, że problemy wpływające na użytkowników są przechwytywane. Odpowiedzialność za monitorowanie aplikacji zależy od użytkowników tworzących aplikację i jej usługi, ponieważ jest ona unikatowa dla logiki biznesowej aplikacji. Monitorowanie aplikacji może być przydatne w następujących scenariuszach:
- Ile ruchu doświadcza moja aplikacja? — Czy musisz skalować usługi, aby zaspokoić wymagania użytkowników lub rozwiązać potencjalne wąskie gardło w aplikacji?
- Czy moje wywołania typu service-to-service są pomyślne i śledzone?
- Jakie działania są podejmowane przez użytkowników mojej aplikacji? - Zbieranie danych telemetrycznych może prowadzić przyszłe opracowywanie funkcji i lepszą diagnostykę błędów aplikacji
- Czy moja aplikacja zgłasza nieobsługiwane wyjątki?
- Co się dzieje w ramach usług uruchomionych wewnątrz moich kontenerów?
Doskonałym rozwiązaniem w zakresie monitorowania aplikacji jest to, że deweloperzy mogą używać dowolnych narzędzi i struktur, ponieważ znajduje się ona w kontekście aplikacji. Więcej informacji na temat rozwiązania platformy Azure do monitorowania aplikacji za pomocą usługi Azure Monitor Application Insights można dowiedzieć się w analizie zdarzeń za pomocą usługi Application Insights.
Mamy również samouczek dotyczący konfigurowania tej konfiguracji dla aplikacji platformy .NET. W tym samouczku omówiono sposób instalowania odpowiednich narzędzi, przykładu pisania niestandardowych danych telemetrycznych w aplikacji oraz wyświetlania diagnostyki aplikacji i telemetrii w witrynie Azure Portal.
Rejestrowanie aplikacji
Instrumentacja kodu to nie tylko sposób uzyskiwania szczegółowych informacji o użytkownikach, ale także jedyny sposób, w jaki możesz wiedzieć, czy coś jest nie tak w aplikacji, oraz do diagnozowania tego, co należy naprawić. Chociaż technicznie można połączyć debuger z usługą produkcyjną, nie jest to powszechna praktyka. Dlatego posiadanie szczegółowych danych instrumentacji jest ważne.
Niektóre produkty automatycznie instrumentację kodu. Chociaż te rozwiązania mogą działać dobrze, instrumentacja ręczna jest prawie zawsze wymagana do konkretnej logiki biznesowej. W końcu musisz mieć wystarczającą ilość informacji, aby śledczo debugować aplikację. Aplikacje usługi Service Fabric można instrumentować przy użyciu dowolnej platformy rejestrowania. W tej sekcji opisano kilka różnych podejść do instrumentacji kodu, a kiedy wybrać jedno podejście.
Zestaw SDK usługi Application Insights: usługa Application Insights oferuje zaawansowaną integrację z usługą Service Fabric. Użytkownicy mogą dodawać pakiety nuget usługi AI Service Fabric i odbierać dane oraz dzienniki utworzone i zebrane w witrynie Azure Portal. Ponadto zachęcamy użytkowników do dodawania własnych danych telemetrycznych w celu diagnozowania i debugowania aplikacji oraz śledzenia najczęściej używanych usług i części aplikacji. Klasa TelemetryClient w zestawie SDK udostępnia wiele sposobów śledzenia danych telemetrycznych w aplikacjach. Aby uzyskać więcej informacji, zobacz Analiza zdarzeń i wizualizacja za pomocą usługi Application Insights.
Zapoznaj się z przykładem instrumentowania i dodawania usługi Application Insights do aplikacji w naszym samouczku na potrzeby monitorowania i diagnozowania aplikacji platformy .NET.
EventSource: Podczas tworzenia rozwiązania usługi Service Fabric na podstawie szablonu w programie Visual Studio jest generowana klasa pochodna EventSource (ServiceEventSource lub ActorEventSource). Zostanie utworzony szablon, w którym można dodawać zdarzenia dla aplikacji lub usługi. Nazwa źródła zdarzeń musi być unikatowa i powinna zostać zmieniona z domyślnego ciągu szablonu MyCompany-solution-project<<>>. Posiadanie wielu definicji źródła zdarzeń , które używają tej samej nazwy, powoduje problem w czasie wykonywania. Każde zdefiniowane zdarzenie musi mieć unikatowy identyfikator. Jeśli identyfikator nie jest unikatowy, wystąpi błąd środowiska uruchomieniowego. Niektóre organizacje wstępnie przypisz zakresy wartości dla identyfikatorów, aby uniknąć konfliktów między oddzielnymi zespołami deweloperów. Aby uzyskać więcej informacji, zobacz blog Vance lub dokumentację MSDN.
ASP.NET Podstawowe rejestrowanie: ważne jest, aby dokładnie zaplanować instrumentację kodu. Odpowiedni plan instrumentacji może pomóc uniknąć potencjalnie destabilizacji bazy kodu, a następnie konieczne jest ponowne wprowadzenie kodu. Aby zmniejszyć ryzyko, możesz wybrać bibliotekę instrumentacji, na przykład Microsoft.Extensions.Logging, która jest częścią platformy Microsoft ASP.NET Core. ASP.NET Core ma interfejs ILogger , którego można używać z wybranym dostawcą, jednocześnie minimalizując wpływ na istniejący kod. Możesz użyć kodu w programie ASP.NET Core w systemach Windows i Linux oraz w pełnym programie .NET Framework, aby kod instrumentacji był ustandaryzowany.
Aby zapoznać się z przykładami dotyczącymi używania tych sugestii, zobacz Dodawanie rejestrowania do aplikacji usługi Service Fabric.
Monitorowanie platformy (klastra)
Użytkownik ma kontrolę nad tym, jakie dane telemetryczne pochodzą z aplikacji, ponieważ użytkownik pisze sam kod, ale co z diagnostyką z platformy Service Fabric? Jednym z celów usługi Service Fabric jest zapewnienie odporności aplikacji na awarie sprzętowe. Ten cel jest osiągany dzięki możliwości wykrywania problemów z infrastrukturą i szybkiego przełączania obciążeń w tryb failover do innych węzłów w klastrze. Ale w tym konkretnym przypadku co zrobić, jeśli same usługi systemowe mają problemy? A jeśli próbujesz wdrożyć lub przenieść obciążenie, naruszono reguły umieszczania usług? Usługa Service Fabric udostępnia diagnostykę tych funkcji i nie tylko, aby upewnić się, że masz informacje o aktywności wykonywanej w klastrze. Oto przykładowe scenariusze monitorowania klastra:
Aby uzyskać więcej informacji na temat monitorowania platformy (klastra), zobacz Monitorowanie klastra.
Zdarzenia usługi Service Fabric
Usługa Service Fabric udostępnia kompleksowy zestaw zdarzeń diagnostycznych, do których można uzyskać dostęp za pośrednictwem magazynu zdarzeń lub kanału zdarzeń operacyjnych udostępnianych przez platformę. Te zdarzenia usługi Service Fabric ilustrują akcje wykonywane przez platformę w różnych jednostkach, takich jak węzły, aplikacje, usługi i partycje. Te same zdarzenia są dostępne w klastrach systemów Windows i Linux.
Kanały zdarzeń usługi Service Fabric: w systemie Windows zdarzenia usługi Service Fabric są dostępne od jednego dostawcy ETW z zestawem odpowiednich
logLevelKeywordFilterselementów używanych do wybierania między kanałami operacyjnymi i danymi i wiadomościami. Jest to sposób oddzielania wychodzących zdarzeń usługi Service Fabric do filtrowania zgodnie z potrzebami. W systemie Linux zdarzenia usługi Service Fabric przechodzą przez narzędzie LTTng i są umieszczane w jednej tabeli usługi Storage, z której można je filtrować zgodnie z potrzebami. Te kanały zawierają wyselekcjonowane zdarzenia ustrukturyzowane, które mogą służyć do lepszego zrozumienia stanu klastra. Diagnostyka jest domyślnie włączona w czasie tworzenia klastra, która tworzy tabelę usługi Azure Storage, w której zdarzenia z tych kanałów są wysyłane do Ciebie w celu wykonywania zapytań w przyszłości.EventStore to funkcja, która pokazuje zdarzenia platformy usługi Service Fabric w narzędziu Service Fabric Explorer i programowo za pośrednictwem interfejsu API REST biblioteki klienta usługi Service Fabric. Możesz zobaczyć widok migawki tego, co dzieje się w klastrze dla każdego węzła, usługi i aplikacji, oraz zapytania na podstawie czasu zdarzenia. Interfejsy API magazynu zdarzeń są dostępne tylko dla klastrów systemu Windows działających na platformie Azure. Na maszynach z systemem Windows te zdarzenia są przekazywane do dziennika zdarzeń, aby zobaczyć zdarzenia usługi Service Fabric w Podgląd zdarzeń.
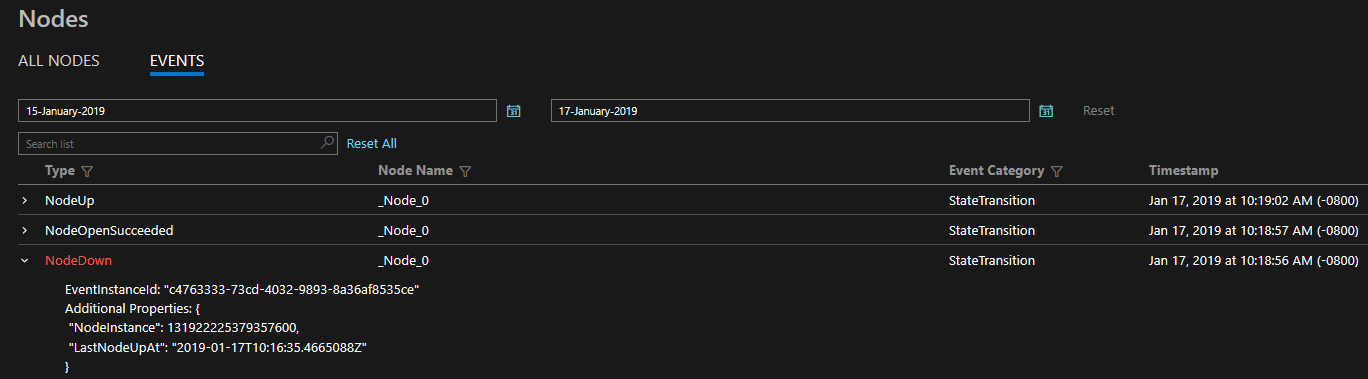
Udostępniona diagnostyka jest w formie kompleksowego zestawu zdarzeń. Te zdarzenia usługi Service Fabric ilustrują akcje wykonywane przez platformę w różnych jednostkach, takich jak węzły, aplikacje, usługi, partycje itp. W ostatnim scenariuszu powyżej, jeśli węzeł miał zostać wyłączony, platforma będzie emitować NodeDown zdarzenie i można je natychmiast powiadomić za pomocą wybranego narzędzia do monitorowania. Inne typowe przykłady obejmują ApplicationUpgradeRollbackStarted lub PartitionReconfigured podczas pracy w trybie failover. Te same zdarzenia są dostępne w klastrach systemów Windows i Linux.
Zdarzenia są wysyłane za pośrednictwem kanałów standardowych w systemach Windows i Linux i mogą być odczytywane przez dowolne narzędzie do monitorowania, które je obsługuje. Rozwiązanie usługi Azure Monitor to dzienniki usługi Azure Monitor. Możesz przeczytać więcej na temat integracji dzienników usługi Azure Monitor, która zawiera niestandardowy pulpit nawigacyjny operacyjny dla klastra i kilka przykładowych zapytań, z których można tworzyć alerty. Więcej pojęć związanych z monitorowaniem klastra jest dostępnych na poziomie platformy zdarzenia i generowania dzienników.
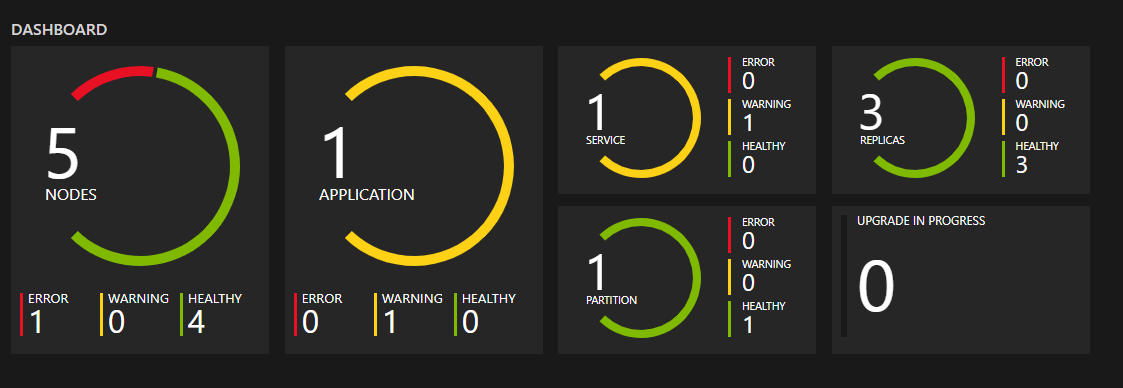
Monitorowanie kondycji
Platforma Service Fabric zawiera model kondycji, który zapewnia rozszerzone raportowanie kondycji dla stanu jednostek w klastrze. Każdy węzeł, aplikacja, usługa, partycja, replika lub wystąpienie ma stale aktualizowalny stan kondycji. Stan kondycji może mieć wartość "OK", "Ostrzeżenie" lub "Błąd". Zdarzenia usługi Service Fabric można traktować jako czasowniki wykonywane przez klaster w różnych jednostkach i kondycji jako przymiotniki dla każdej jednostki. Za każdym razem, gdy kondycja określonej jednostki przechodzi, zdarzenie będzie również emitowane. Dzięki temu możesz skonfigurować zapytania i alerty dotyczące zdarzeń kondycji w wybranym narzędziu do monitorowania, podobnie jak w przypadku każdego innego zdarzenia.
Ponadto umożliwiamy nawet użytkownikom zastępowanie kondycji jednostek. Jeśli aplikacja przechodzi uaktualnienie i testy weryfikacyjne kończą się niepowodzeniem, możesz zapisać w usłudze Service Fabric Health przy użyciu interfejsu API kondycji, aby wskazać, że aplikacja nie jest już w dobrej kondycji, a usługa Service Fabric automatycznie wycofa uaktualnienie. Aby uzyskać więcej informacji na temat modelu kondycji, zapoznaj się z wprowadzeniem do monitorowania kondycji usługi Service Fabric
Watchdogs
Ogólnie rzecz biorąc, watchdog to oddzielna usługa, która monitoruje kondycję i obciążenie usług, wysyła polecenia ping do punktów końcowych i zgłasza nieoczekiwane zdarzenia kondycji w klastrze. Może to pomóc w zapobieganiu błędom, które mogą nie być wykrywane tylko na podstawie wydajności pojedynczej usługi. Watchdogs to również dobre miejsce do hostowania kodu, który wykonuje akcje naprawcze, które nie wymagają interakcji użytkownika, takie jak czyszczenie plików dziennika w magazynie w określonych odstępach czasu. Jeśli chcesz w pełni zaimplementować usługę watchdog sf typu open source, która zawiera łatwy w użyciu model rozszerzalności watchdog i działa zarówno w klastrach systemu Windows, jak i Linux, zobacz projekt FabricObserver . FabricObserver to oprogramowanie gotowe do produkcji. Zachęcamy do wdrożenia serwera FabricObserver w klastrach testowych i produkcyjnych i rozszerzania go w celu zaspokojenia Twoich potrzeb za pomocą modelu wtyczek lub rozwidlania go i pisania własnych wbudowanych obserwatorów. Poprzednie (wtyczki) jest zalecanym podejściem.
Monitorowanie infrastruktury (wydajności)
Po omówieniu diagnostyki w aplikacji i na platformie jak wiemy, że sprzęt działa zgodnie z oczekiwaniami? Monitorowanie podstawowej infrastruktury jest kluczowym elementem zrozumienia stanu klastra i wykorzystania zasobów. Mierzenie wydajności systemu zależy od wielu czynników, które mogą być subiektywne w zależności od obciążeń. Te czynniki są zwykle mierzone za pomocą liczników wydajności. Te liczniki wydajności mogą pochodzić z różnych źródeł, w tym systemu operacyjnego, platformy .NET Framework lub samej platformy Usługi Service Fabric. Niektóre scenariusze, w których byłyby przydatne, to
- Czy wydajnie używam sprzętu? Czy chcesz używać sprzętu na poziomie 90% procesora CPU lub 10%. Jest to przydatne podczas skalowania klastra lub optymalizowania procesów aplikacji.
- Czy mogę proaktywnie przewidywać problemy z infrastrukturą? — wiele problemów jest poprzedzonych nagłymi zmianami (spadkami) wydajności, dzięki czemu można używać liczników wydajności, takich jak użycie operacji we/wy sieci i procesora CPU w celu proaktywnego przewidywania i diagnozowania problemów.
Listę liczników wydajności, które powinny być zbierane na poziomie infrastruktury, można znaleźć w sekcji Metryki wydajności.
Dzienniki usługi Azure Monitor są zalecane do monitorowania zdarzeń na poziomie klastra. Po skonfigurowaniu agenta usługi Log Analytics w obszarze roboczym można zbierać następujące elementy:
- Metryki wydajności, takie jak wykorzystanie procesora CPU.
- Liczniki wydajności platformy .NET, takie jak wykorzystanie procesora CPU na poziomie procesu.
- Liczniki wydajności usługi Service Fabric, takie jak liczba wyjątków od niezawodnej usługi.
- Metryki kontenera, takie jak użycie procesora CPU.
Typy zasobów
Platforma Azure używa koncepcji typów zasobów i identyfikatorów, aby zidentyfikować wszystko w subskrypcji. Typy zasobów są również częścią identyfikatorów zasobów dla każdego zasobu uruchomionego na platformie Azure. Na przykład jeden typ zasobu dla maszyny wirtualnej to Microsoft.Compute/virtualMachines. Aby uzyskać listę usług i skojarzonych z nimi typów zasobów, zobacz Dostawcy zasobów.
Usługa Azure Monitor podobnie organizuje podstawowe dane monitorowania w metryki i dzienniki na podstawie typów zasobów, nazywanych również przestrzeniami nazw. Różne metryki i dzienniki są dostępne dla różnych typów zasobów. Usługa może być skojarzona z więcej niż jednym typem zasobu.
Aby uzyskać więcej informacji na temat typów zasobów dla usługi Azure Service Fabric, zobacz Dokumentacja danych monitorowania usługi Service Fabric.
Magazyn danych
W przypadku usługi Azure Monitor:
- Dane metryk są przechowywane w bazie danych metryk usługi Azure Monitor.
- Dane dziennika są przechowywane w magazynie dzienników usługi Azure Monitor. Log Analytics to narzędzie w witrynie Azure Portal, które może wykonywać zapytania dotyczące tego magazynu.
- Dziennik aktywności platformy Azure to oddzielny magazyn z własnym interfejsem w witrynie Azure Portal.
Opcjonalnie możesz kierować dane metryki i dziennika aktywności do magazynu dzienników usługi Azure Monitor. Następnie możesz użyć usługi Log Analytics, aby wykonać zapytanie o dane i skorelować je z innymi danymi dziennika.
Wiele usług może używać ustawień diagnostycznych do wysyłania danych metryk i dzienników do innych lokalizacji przechowywania poza usługą Azure Monitor. Przykłady obejmują usługę Azure Storage, hostowane systemy partnerskie i systemy partnerskie spoza platformy Azure przy użyciu usługi Event Hubs.
Aby uzyskać szczegółowe informacje na temat sposobu przechowywania danych przez usługę Azure Monitor, zobacz Azure Monitor data platformy.
Metryki platformy usługi Azure Monitor
Usługa Azure Monitor udostępnia metryki platformy dla wielu usług. Aby uzyskać listę wszystkich metryk, które można zebrać dla wszystkich zasobów w usłudze Azure Monitor, zobacz Obsługiwane metryki w usłudze Azure Monitor.
Ta usługa nie zbiera metryk platformy.
Metryki oparte na usłudze Azure Monitor
Ta usługa udostępnia inne metryki, które nie są uwzględnione w bazie danych metryk usługi Azure Monitor.
Metryki systemu operacyjnego gościa
Metryki systemu operacyjnego gościa działającego w węzłach klastra usługi Service Fabric muszą być zbierane za pośrednictwem co najmniej jednego agenta działającego w systemie operacyjnym gościa. Metryki systemu operacyjnego gościa obejmują liczniki wydajności, które śledzą procent użycia procesora CPU gościa lub użycie pamięci, z których oba są często używane do skalowania automatycznego lub alertów.
Najlepszym rozwiązaniem jest użycie i skonfigurowanie agenta usługi Azure Monitor w celu wysyłania metryk wydajności systemu operacyjnego gościa za pośrednictwem niestandardowego interfejsu API metryk do bazy danych metryk usługi Azure Monitor. Metryki systemu operacyjnego gościa można wysyłać do dzienników usługi Azure Monitor przy użyciu tego samego agenta. Następnie możesz wykonywać zapytania dotyczące tych metryk i dzienników przy użyciu usługi Log Analytics.
Uwaga
Agent usługi Azure Monitor zastępuje rozszerzenie Diagnostyka Azure i agenta usługi Log Analytics na potrzeby routingu systemu operacyjnego gościa. Aby uzyskać więcej informacji, zobacz Omówienie agentów usługi Azure Monitor.
Dzienniki zasobów usługi Azure Monitor
Dzienniki zasobów zapewniają wgląd w operacje wykonywane przez zasób platformy Azure. Dzienniki są generowane automatycznie, ale należy skierować je do dzienników usługi Azure Monitor, aby je zapisać lub wysłać do nich zapytanie. Dzienniki są zorganizowane w kategorie. Dana przestrzeń nazw może mieć wiele kategorii dzienników zasobów, które można zebrać.
Ta usługa nie zbiera dzienników zasobów, ale można je znaleźć w temacie Monitorowanie danych z zasobów platformy Azure.
Dzienniki i zdarzenia usługi Service Fabric
Usługa Service Fabric może zbierać następujące dzienniki:
- W przypadku klastrów systemu Windows można skonfigurować monitorowanie klastra za pomocą agenta diagnostyki i dzienników usługi Azure Monitor.
- W przypadku klastrów systemu Linux dzienniki usługi Azure Monitor są również zalecanym narzędziem do monitorowania platformy Azure i infrastruktury. Diagnostyka platformy systemu Linux wymaga innej konfiguracji. Aby uzyskać więcej informacji, zobacz Service Fabric Linux cluster events in Syslog (Zdarzenia klastra systemu Linux w usłudze Service Fabric w dzienniku systemowym).
- Agent usługi Azure Monitor można skonfigurować tak, aby wysyłał dzienniki systemu operacyjnego gościa do dzienników usługi Azure Monitor, w których można wykonywać zapytania za pomocą usługi Log Analytics.
- Dzienniki kontenera usługi Service Fabric można zapisywać w pliku stdout lub stderr , aby były dostępne w dziennikach usługi Azure Monitor.
- Możesz skonfigurować rozwiązanie do monitorowania kontenerów dla dzienników usługi Azure Monitor, aby wyświetlić zdarzenia kontenera.
Inne rozwiązania do rejestrowania
Mimo że dwa zalecane rozwiązania, dzienniki usługi Azure Monitor i usługa Application Insights mają wbudowaną integrację z usługą Service Fabric, wiele zdarzeń jest zapisywanych za pośrednictwem dostawców ETW i rozszerzalne z innymi rozwiązaniami rejestrowania. Należy również przyjrzeć się elastycznemu stosowi (zwłaszcza jeśli rozważasz uruchomienie klastra w środowisku offline), Dynatrace lub innej platformie preferencji. Aby uzyskać listę zintegrowanych partnerów, zobacz Azure Service Fabric Monitoring Partners (Partnerzy monitorowania usługi Azure Service Fabric).
Kluczowe kwestie dla dowolnej wybranej platformy powinny obejmować, jak wygodne jest korzystanie z interfejsu użytkownika, możliwości wykonywania zapytań, dostępnych wizualizacji niestandardowych i pulpitów nawigacyjnych oraz dodatkowych narzędzi, które zapewniają w celu ulepszenia środowiska monitorowania.
Dziennik aktywności platformy Azure
Dziennik aktywności zawiera zdarzenia na poziomie subskrypcji, które śledzą operacje dla każdego zasobu platformy Azure widoczne spoza tego zasobu; na przykład utworzenie nowego zasobu lub uruchomienie maszyny wirtualnej.
Kolekcja: zdarzenia dziennika aktywności są generowane automatycznie i zbierane w osobnym magazynie do wyświetlania w witrynie Azure Portal.
Routing: możesz wysyłać dane dziennika aktywności do dzienników usługi Azure Monitor, aby móc analizować je wraz z innymi danymi dziennika. Dostępne są również inne lokalizacje, takie jak Azure Storage, Azure Event Hubs i niektórzy partnerzy monitorowania firmy Microsoft. Aby uzyskać więcej informacji na temat kierowania dziennika aktywności, zobacz Omówienie dziennika aktywności platformy Azure.
Analizowanie danych monitorowania
Istnieje wiele narzędzi do analizowania danych monitorowania.
Narzędzia usługi Azure Monitor
Usługa Azure Monitor obsługuje następujące podstawowe narzędzia:
Eksplorator metryk — narzędzie w witrynie Azure Portal, które umożliwia wyświetlanie i analizowanie metryk dla zasobów platformy Azure. Aby uzyskać więcej informacji, zobacz Analizowanie metryk za pomocą Eksploratora metryk usługi Azure Monitor.
Log Analytics — narzędzie w witrynie Azure Portal, które umożliwia wykonywanie zapytań i analizowanie danych dzienników przy użyciu języka zapytań Kusto (KQL). Aby uzyskać więcej informacji, zobacz Rozpoczynanie pracy z zapytaniami dzienników w usłudze Azure Monitor.
Dziennik aktywności, który zawiera interfejs użytkownika w witrynie Azure Portal do wyświetlania i podstawowych wyszukiwań. Aby przeprowadzić bardziej szczegółową analizę, musisz kierować dane do dzienników usługi Azure Monitor i uruchamiać bardziej złożone zapytania w usłudze Log Analytics.
Narzędzia, które umożliwiają bardziej złożoną wizualizację, obejmują:
- Pulpity nawigacyjne, które umożliwiają łączenie różnych rodzajów danych w jednym okienku w witrynie Azure Portal.
- Skoroszyty, dostosowywalne raporty, które można utworzyć w witrynie Azure Portal. Skoroszyty mogą zawierać tekst, metryki i zapytania dziennika.
- Grafana to otwarte narzędzie platformy, które wyróżnia się na operacyjnych pulpitach nawigacyjnych. Za pomocą narzędzia Grafana można tworzyć pulpity nawigacyjne zawierające dane z wielu źródeł innych niż usługa Azure Monitor.
- Power BI, usługa analizy biznesowej, która udostępnia interaktywne wizualizacje w różnych źródłach danych. Usługę Power BI można skonfigurować tak, aby automatycznie importować dane dziennika z usługi Azure Monitor, aby korzystać z tych wizualizacji.
Aby zapoznać się z omówieniem typowych scenariuszy analizy monitorowania usługi Service Fabric, zobacz Diagnozowanie typowych scenariuszy za pomocą usługi Service Fabric.
Narzędzia eksportu usługi Azure Monitor
Dane z usługi Azure Monitor można pobrać do innych narzędzi przy użyciu następujących metod:
Metryki: użyj interfejsu API REST dla metryk , aby wyodrębnić dane metryk z bazy danych metryk usługi Azure Monitor. Interfejs API obsługuje wyrażenia filtrów w celu uściślinia pobranych danych. Aby uzyskać więcej informacji, zobacz Dokumentacja interfejsu API REST usługi Azure Monitor.
Dzienniki: użyj interfejsu API REST lub skojarzonych bibliotek klienckich.
Aby rozpocząć pracę z interfejsem API REST dla usługi Azure Monitor, zobacz Przewodnik po interfejsie API REST monitorowania platformy Azure.
Zapytania usługi Kusto
Dane monitorowania można analizować w magazynie dzienników usługi Azure Monitor /Log Analytics przy użyciu języka zapytań Kusto (KQL).
Ważne
Po wybraniu pozycji Dzienniki z menu usługi w portalu usługa Log Analytics zostanie otwarta z zakresem zapytania ustawionym na bieżącą usługę. Ten zakres oznacza, że zapytania dziennika będą zawierać tylko dane z tego typu zasobu. Jeśli chcesz uruchomić zapytanie zawierające dane z innych usług platformy Azure, wybierz pozycję Dzienniki z menu usługi Azure Monitor . Aby uzyskać szczegółowe informacje, zobacz Zakres zapytań dzienników i zakres czasu w usłudze Azure Monitor Log Analytics .
Aby uzyskać listę typowych zapytań dotyczących dowolnej usługi, zobacz interfejs zapytań usługi Log Analytics.
Przykładowe zapytania
Następujące zapytania zwracają zdarzenia usługi Service Fabric, w tym akcje w węzłach. Aby uzyskać informacje o innych przydatnych zapytaniach, zobacz Service Fabric Events (Zdarzenia usługi Service Fabric).
Zwracanie zdarzeń operacyjnych zarejestrowanych w ostatniej godzinie:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Return Health Reports with HealthState == 3 (Error) i wyodrębnij więcej właściwości z EventMessage pola:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Pobierz zdarzenia operacyjne usługi Service Fabric zagregowane przy użyciu określonej usługi i węzła:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Alerty
Alerty usługi Azure Monitor proaktywnie powiadamiają o znalezieniu określonych warunków w danych monitorowania. Alerty umożliwiają identyfikowanie i rozwiązywanie problemów w systemie przed ich zauważeniem przez klientów. Aby uzyskać więcej informacji, zobacz Alerty usługi Azure Monitor.
Istnieje wiele źródeł typowych alertów dotyczących zasobów platformy Azure. Przykłady typowych alertów dotyczących zasobów platformy Azure można znaleźć w temacie Przykładowe zapytania alertów dziennika. Witryna Alerty bazowe usługi Azure Monitor (AMBA) udostępnia częściowo zautomatyzowaną metodę implementowania ważnych alertów metryk platformy, pulpitów nawigacyjnych i wytycznych. Witryna ma zastosowanie do stale powiększającego się podzestawu usług platformy Azure, w tym wszystkich usług, które są częścią strefy docelowej platformy Azure (ALZ).
Typowy schemat alertu standandaryzuje użycie powiadomień o alertach usługi Azure Monitor. Aby uzyskać więcej informacji, zobacz Wspólny schemat alertów.
Typy alertów
Możesz otrzymywać alerty dotyczące dowolnej metryki lub źródła danych dziennika na platformie danych usługi Azure Monitor. Istnieje wiele różnych typów alertów w zależności od usług, które monitorujesz i zbieranych danych monitorowania. Różne typy alertów mają różne zalety i wady. Aby uzyskać więcej informacji, zobacz Wybieranie odpowiedniego typu alertu monitorowania.
Poniższa lista zawiera opis typów alertów usługi Azure Monitor, które można utworzyć:
- Alerty metryk oceniają metryki zasobów w regularnych odstępach czasu. Metryki mogą być metrykami platformy, metrykami niestandardowymi, dziennikami z usługi Azure Monitor przekonwertowanym na metryki lub metrykami usługi Application Insights. Alerty metryk mogą również stosować wiele warunków i progów dynamicznych.
- Alerty dzienników umożliwiają użytkownikom używanie zapytania usługi Log Analytics do oceny dzienników zasobów z wstępnie zdefiniowaną częstotliwością.
- Alerty dziennika aktywności są wyzwalane, gdy wystąpi nowe zdarzenie dziennika aktywności zgodne ze zdefiniowanymi warunkami. Alerty usługi Resource Health i alerty usługi Service Health to alerty dziennika aktywności, które zgłaszają kondycję usługi i zasobów.
Niektóre usługi platformy Azure obsługują również alerty wykrywania inteligentnego, alerty Prometheus lub zalecane reguły alertów.
W przypadku niektórych usług można monitorować na dużą skalę, stosując tę samą regułę alertu metryki do wielu zasobów tego samego typu, które istnieją w tym samym regionie świadczenia usługi Azure. Poszczególne powiadomienia są wysyłane dla każdego monitorowanego zasobu. Aby uzyskać informacje o obsługiwanych usługach i chmurach platformy Azure, zobacz Monitorowanie wielu zasobów przy użyciu jednej reguły alertu.
Reguły alertów usługi Service Fabric
W poniższej tabeli wymieniono niektóre reguły alertów dla usługi Service Fabric. Te alerty są tylko przykładami. Alerty można ustawić dla dowolnej metryki, wpisu dziennika lub wpisu dziennika aktywności wymienionego w dokumentacji danych monitorowania usługi Service Fabric lub listy zdarzeń usługi Service Fabric.
| Typ alertu | Warunek | opis |
|---|---|---|
| Zdarzenie węzła | Węzeł ulegnie awarii | ServiceFabricOperationalEvent, gdzie EventID >= 25622 i EventID <= 25626. Te identyfikatory zdarzeń znajdują się w dokumentacji zdarzeń węzła. |
| Zdarzenie aplikacji | Wycofywanie uaktualnienia aplikacji | ServiceFabricOperationalEvent, gdzie EventID == 29623 lub EventID == 29624. Te identyfikatory zdarzeń znajdują się w dokumentacji zdarzeń aplikacji. |
| Kondycja zasobów | Uaktualnianie usługi nieosiągalne/niedostępne | Klaster przechodzi do stanu UpgradeServiceUnreachable. |
Zalecenia doradcy
W przypadku niektórych usług, jeśli podczas operacji zasobów wystąpią krytyczne warunki lub nieuchronne zmiany, na stronie Przegląd usługi w portalu zostanie wyświetlony alert. Więcej informacji i zalecanych poprawek alertu można znaleźć w temacie Zalecenia usługi Advisor w obszarze Monitorowanie w menu po lewej stronie. Podczas normalnych operacji nie są wyświetlane żadne zalecenia doradcy.
Aby uzyskać więcej informacji na temat usługi Azure Advisor, zobacz Omówienie usługi Azure Advisor.
Zalecana konfiguracja
Teraz, po przejściu do każdego obszaru monitorowania i przykładowych scenariuszy, poniżej przedstawiono podsumowanie narzędzi do monitorowania platformy Azure i skonfigurowanie potrzebne do monitorowania wszystkich powyższych obszarów.
- Monitorowanie aplikacji za pomocą usługi Application Insights
- Monitorowanie klastra za pomocą agenta diagnostyki i dzienników usługi Azure Monitor
- Monitorowanie infrastruktury za pomocą dzienników usługi Azure Monitor
Możesz również użyć i zmodyfikować przykładowy szablon usługi ARM, aby zautomatyzować wdrażanie wszystkich niezbędnych zasobów i agentów.
Powiązana zawartość
- Zobacz Dokumentację danych monitorowania usługi Service Fabric, aby zapoznać się z dokumentacją metryk, dzienników i innych ważnych wartości utworzonych dla usługi Service Fabric.
- Zobacz Monitorowanie zasobów platformy Azure za pomocą usługi Azure Monitor , aby uzyskać ogólne informacje na temat monitorowania zasobów platformy Azure.
- Zobacz listę zdarzeń usługi Service Fabric.