Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Podsumowanie:Usługa Azure Synapse Analytics to platforma analizy bez ograniczeń firmy Microsoft, która integruje magazynowanie danych przedsiębiorstwa i przetwarzanie danych big data w jednym środowisku zarządzanym bez konieczności integracji z systemem. Usługa Azure Synapse udostępnia kompleksowe narzędzia do cyklu życia analitycznego za pomocą następujących funkcji:
- Pipelines for data integration.
- Pula obliczeniowa Apache Spark do przetwarzania danych big data.
- Eksplorator danych na potrzeby analizy dzienników i szeregów czasowych.
- Pula SQL bez serwera do eksploracji danych w usłudze Azure Data Lake.
- Dedicated SQL pool (formerly SQL DW) for enterprise data warehousing.
- Głęboka integracja z usługami Power BI, Azure Cosmos DB i Azure Machine Learning.
Zabezpieczenia i prywatność danych usługi Azure Synapse nie są negocjowane. Celem tej białej księgi jest przedstawienie kompleksowego przeglądu funkcji zabezpieczeń usługi Azure Synapse, które są klasy korporacyjnej i wiodące w branży. Oficjalny dokument składa się z serii artykułów, które obejmują następujące pięć warstw zabezpieczeń:
- Ochrona danych
- Kontrola dostępu
- Uwierzytelnianie
- Bezpieczeństwo sieci
- Ochrona przed zagrożeniami
Ten oficjalny dokument dotyczy wszystkich uczestników projektu zabezpieczeń przedsiębiorstwa. Obejmują one administratorów zabezpieczeń, administracji sieci, administratorów platformy Azure, administratorów obszarów roboczych i administratorów baz danych.
Pisarze: Vengatesh Parasuraman, Fretz Nuson, Ron Dunn, Khendr'a Reid, John Hoang, Nithesh Msdppa, Mykola Kovalenko, Brad Schacht, Pedro Martinez, Mark Pryce-Maher i Arshad Ali.
Recenzenci techniczni: Nandita Valsan, Rony Thomas, Abhishek Narain, Daniel Crawford i Tammy Richter Jones.
Dotyczy: Azure Synapse Analytics, dedykowana pula SQL (dawniej SQL DW), bezserwerowa pula SQL i pula Apache Spark.
Ważne
Ten oficjalny dokument nie dotyczy usług Azure SQL Database, Azure SQL Managed Instance, Azure Machine Learning ani Azure Databricks.
Wprowadzenie
Częste nagłówki naruszeń danych, infekcje złośliwym oprogramowaniem i wstrzyknięcie złośliwego kodu należą do szerokiej listy problemów z zabezpieczeniami firm, które chcą modernizacji chmury. Klient korporacyjny wymaga dostawcy usług chmurowych lub rozwiązania, które może sprostać ich wymaganiom, ponieważ nie mogą sobie pozwolić na błędne rozwiązanie.
Oto niektóre typowe pytania dotyczące zabezpieczeń:
- Jak mogę kontrolować, kto może wyświetlać jakie dane?
- Jakie są opcje weryfikowania tożsamości użytkownika?
- Jak są chronione moje dane?
- Jakiej technologii zabezpieczeń sieci można użyć do ochrony integralności, poufności i dostępu do moich sieci i danych?
- Jakie narzędzia wykrywają i powiadamiają mnie o zagrożeniach?
Celem tej białej księgi jest zapewnienie odpowiedzi na te typowe pytania dotyczące zabezpieczeń i wiele innych.
Architektura składników
Azure Synapse to usługa analizy typu platforma jako usługa (PaaS), która łączy wiele niezależnych składników, takich jak dedykowane pule SQL, bezserwerowe pule SQL, pule platformy Apache Spark i potoki integracji danych. Te składniki są przeznaczone do współpracy w celu zapewnienia bezproblemowego środowiska platformy analitycznej.
Dedykowane pule SQL to konfigurowalne klastry, które zapewniają funkcje hurtowni danych na poziomie przedsiębiorstwa dla obciążeń związanych z SQL. Dane są pozyskiwane do magazynu zarządzanego obsługiwanego przez usługę Azure Storage, która jest również usługą PaaS. Obliczenia są odizolowane od magazynu, dzięki czemu klienci mogą skalować obliczenia niezależnie od swoich danych. Dedykowane pule SQL umożliwiają również wykonywanie zapytań dotyczących plików danych bezpośrednio za pośrednictwem kont usługi Azure Storage zarządzanych przez klienta przy użyciu tabel zewnętrznych.
Bezserwerowe pule SQL to klastry na żądanie, które zapewniają interfejs SQL do wykonywania zapytań i analizowania danych bezpośrednio za pośrednictwem kont usługi Azure Storage zarządzanych przez klienta. Ponieważ są one bezserwerowe, nie ma zarządzanego magazynu, a węzły obliczeniowe są skalowane automatycznie w odpowiedzi na obciążenie zapytania.
Platforma Apache Spark w usłudze Azure Synapse jest jedną z implementacji platformy Apache Spark typu open source firmy Microsoft w chmurze. Instancje Spark są udostępniane na żądanie na podstawie konfiguracji metadanych określonych w pulach Spark. Każdy użytkownik otrzymuje własną dedykowaną instancję Spark do uruchamiania swoich zadań. Pliki danych przetwarzane przez wystąpienia platformy Spark są zarządzane przez klienta na własnych kontach usługi Azure Storage.
Pipelines to logiczne grupowanie działań, które wykonują przenoszenie i przetwarzanie danych na dużą skalę. Data flow is a transformation activity in a pipeline that's developed by using a low-code user interface. Może wykonywać przekształcenia danych na dużą skalę. Za kulisami przepływy danych wykorzystują klastry Apache Spark usługi Azure Synapse do wykonywania automatycznie generowanego kodu. Pipelines and data flows are compute-only services, and they don't have any managed storage associated with them.
Pipelines use the Integration Runtime (IR) as the scalable compute infrastructure for performing data movement and dispatch activities. Data movement activities run on the IR whereas the dispatch activities run on variety of other compute engines, including Azure SQL Database, Azure HDInsight, Azure Databricks, Apache Spark clusters of Azure Synapse, and others. Usługa Azure Synapse obsługuje dwa typy środowiska IR: Środowisko Azure Integration Runtime i własne środowisko Integration Runtime. Środowisko Azure IR zapewnia w pełni zarządzaną, skalowalną i na żądanie infrastrukturę obliczeniową. Własne środowisko IR jest instalowane i konfigurowane przez klienta w własnej sieci na maszynach lokalnych lub na maszynach wirtualnych w chmurze platformy Azure.
Klienci mogą skojarzyć swój obszar roboczy usługi Synapse z zarządzaną siecią wirtualną obszaru roboczego. When associated with a managed workspace virtual network, Azure IRs and Apache Spark clusters that are used by pipelines, data flows, and the Apache Spark pools are deployed inside the managed workspace virtual network. This setup ensures network isolation between the workspaces for pipelines and Apache Spark workloads.
Na poniższym diagramie przedstawiono różne składniki usługi Azure Synapse.
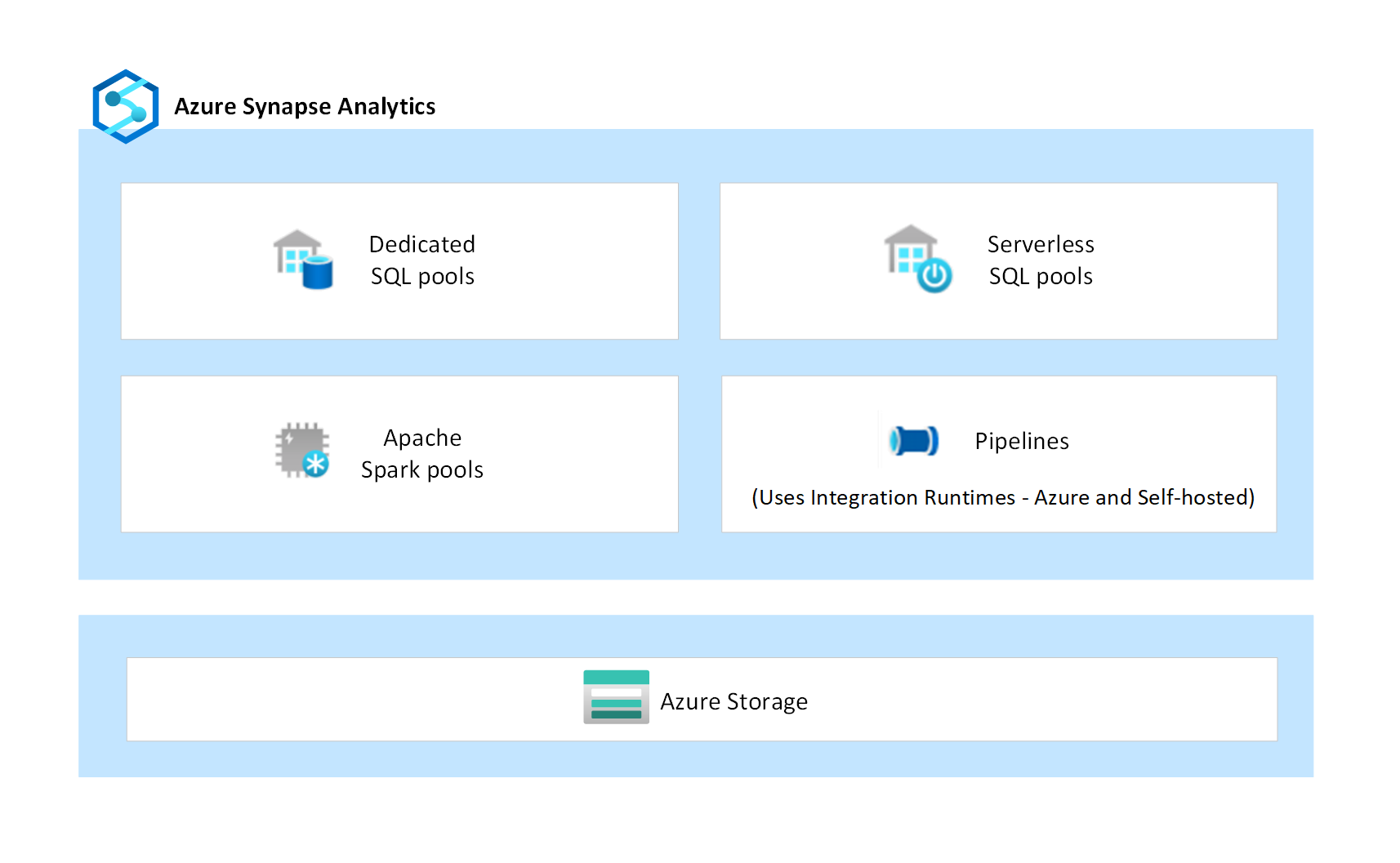
Izolacja składników
Każdy pojedynczy składnik usługi Azure Synapse przedstawiony na diagramie zapewnia własne funkcje zabezpieczeń. Funkcje zabezpieczeń zapewniają ochronę danych, kontrolę dostępu, uwierzytelnianie, zabezpieczenia sieci i ochronę przed zagrożeniami na potrzeby zabezpieczania zasobów obliczeniowych i skojarzonych danych, które są przetwarzane. Ponadto usługa Azure Storage, będąca usługą PaaS, zapewnia dodatkowe zabezpieczenia, które są konfigurowane i zarządzane przez klienta na własnych kontach magazynowych. Ten poziom izolacji składników ogranicza i minimalizuje narażenie, jeśli wystąpiła luka w zabezpieczeniach w jednym z jego składników.
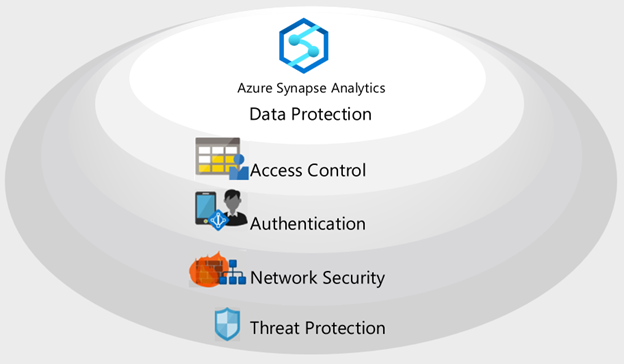
Warstwy zabezpieczeń
Usługa Azure Synapse implementuje wielowarstwową architekturę zabezpieczeń na potrzeby kompleksowej ochrony danych. Istnieją pięć warstw:
- Ochrona danych w celu identyfikowania i klasyfikowania poufnych danych oraz szyfrowania danych magazynowanych i przesyłanych.
- Kontrola dostępu w celu określenia prawa użytkownika do interakcji z danymi.
- Uwierzytelnianie w celu potwierdzenia tożsamości użytkowników i aplikacji.
- Zabezpieczenia sieci w celu odizolowania ruchu sieciowego z prywatnymi punktami końcowymi i wirtualnymi sieciami prywatnymi.
- Ochrona przed zagrożeniami w celu identyfikowania potencjalnych zagrożeń bezpieczeństwa, takich jak nietypowe lokalizacje dostępu, ataki iniekcyjne SQL, ataki uwierzytelniania i inne.
Następne kroki
W następnym artykule z tej serii dokumentów dowiesz się więcej o ochronie danych.