Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
This article is part five of a seven-part series that provides guidance on how to migrate from Oracle to Azure Synapse Analytics. The focus of this article is best practices for minimizing SQL issues.
Overview
Characteristics of Oracle environments
Oracle's initial database product, released in 1979, was a commercial SQL relational database for on-line transaction processing (OLTP) applications—with much lower transaction rates than today. Since that initial release, the Oracle environment has evolved to become far more complex and encompasses numerous features. The features include client-server architectures, distributed databases, parallel processing, data analytics, high availability, data warehousing, data in-memory techniques, and support for cloud-based instances.
Tip
Oracle pioneered the "data warehouse appliance" concept in the early 2000's.
Due to the cost and complexity of maintaining and upgrading legacy on-premises Oracle environments, many existing Oracle users want to take advantage of the innovations provided by cloud environments. Modern cloud environments, such as cloud, IaaS, and PaaS, let you delegate tasks like infrastructure maintenance and platform development to the cloud provider.
Many data warehouses that support complex analytic SQL queries on large data volumes use Oracle technologies. These data warehouses commonly have a dimensional data model, such as star or snowflake schemas, and use data marts for individual departments.
Tip
Many existing Oracle installations are data warehouses that use a dimensional data model.
The combination of SQL and dimensional data models in Oracle simplifies migration to Azure Synapse because the SQL and basic data model concepts are transferable. Microsoft recommends moving your existing data model as-is to Azure to reduce risk, effort, and migration time. Although your migration plan might include a change in the underlying data model, such as a move from an Inmon model to a data vault, it makes sense to initially perform an as-is migration. After the initial migration, you can then make changes within the Azure cloud environment to take advantage of its performance, elastic scalability, built-in features, and cost benefits.
Although the SQL language is standardized, individual vendors sometimes implement proprietary extensions. As a result, you might find SQL differences during your migration that require workarounds in Azure Synapse.
Use Azure facilities to implement a metadata-driven migration
You can automate and orchestrate the migration process by using the capabilities of the Azure environment. This approach minimizes the performance hit on the existing Oracle environment, which may already be running close to capacity.
Azure Data Factory is a cloud-based data integration service that supports creating data-driven workflows in the cloud to orchestrate and automate data movement and data transformation. You can use Data Factory to create and schedule data-driven workflows (pipelines) that ingest data from disparate data stores. Data Factory can process and transform data by using compute services such as Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics, and Azure Machine Learning.
Azure also includes Azure Database Migration Services to help you plan and perform a migration from environments such as Oracle. SQL Server Migration Assistant (SSMA) for Oracle can automate migration of Oracle databases, including in some cases functions and procedural code.
Tip
Automate the migration process by using Azure Data Factory capabilities.
When you're planning to use Azure facilities, such as Data Factory, to manage the migration process, first create metadata that lists all the data tables that need to be migrated and their location.
SQL DDL differences between Oracle and Azure Synapse
The ANSI SQL standard defines the basic syntax for Data Definition Language (DDL) commands. Some DDL commands, like CREATE TABLE and CREATE VIEW, are common to both Oracle and Azure Synapse, but have been extended to provide implementation-specific features such as indexing, table distribution, and partitioning options.
Tip
SQL DDL commands CREATE TABLE and CREATE VIEW have standard core elements but are also used to define implementation-specific options.
The following sections discuss the Oracle-specific options that need to be considered during a migration to Azure Synapse.
Table/view considerations
When you migrate tables between different environments, typically only the raw data and the metadata that describes it physically migrate. Other database elements from the source system, such as indexes and log files, usually aren't migrated because they might be unnecessary or implemented differently in the new environment. For example, the TEMPORARY option within Oracle's CREATE TABLE syntax is equivalent to prefixing a table name with the # character in Azure Synapse.
Performance optimizations in the source environment, such as indexes, indicate where you might add performance optimization in the new target environment. For example, if bit-mapped indexes are frequently used in queries within the source Oracle environment, that suggests that a non-clustered index should be created within Azure Synapse. Other native performance optimization techniques such as table replication may be more applicable than straight like-for-like index creation. SSMA for Oracle can provide migration recommendations for table distribution and indexing.
Tip
Existing indexes indicate candidates for indexing in the migrated warehouse.
SQL view definitions contain SQL Data Manipulation Language (DML) statements that define the view, typically with one or more SELECT statements. When you migrate CREATE VIEW statements, take into account the DML differences between Oracle and Azure Synapse.
Unsupported Oracle database object types
Oracle-specific features can often be replaced by Azure Synapse features. However, some Oracle database objects aren't directly supported in Azure Synapse. The following list of unsupported Oracle database objects describes how you can achieve equivalent functionality in Azure Synapse:
Indexing options: in Oracle, several indexing options, such as bit-mapped indexes, function-based indexes, and domain indexes, have no direct equivalent in Azure Synapse. Although Azure Synapse doesn't support those index types, you can achieve a similar reduction in disk I/O by using user-defined index types and/or partitioning Reducing disk I/O improves query performance.
You can find out which columns are indexed and their index type by querying system catalog tables and views, such as
ALL_INDEXES,DBA_INDEXES,USER_INDEXES, andDBA_IND_COL. Or, you can query thedba_index_usageorv$object_usageviews when monitoring is enabled.Azure Synapse features, such as parallel query processing and in-memory caching of data and results, make it likely that fewer indexes are required for data warehouse applications to achieve excellent performance goals.
Clustered tables: Oracle tables can be organized so that table rows that are frequently accessed together (based on a common value) are physically stored together. This strategy reduces disk I/O when data is retrieved. Oracle also has a hash-cluster option for individual tables, which applies a hash value to the cluster key and physically stores rows with the same hash value together.
In Azure Synapse, you can achieve a similar result by partitioning and/or using other indexes.
Materialized views: Oracle supports materialized views and recommends one or more of them for large tables with many columns where only a few columns are regularly used in queries. Materialized views are automatically refreshed by the system when data in the base table is updated.
In 2019, Microsoft announced that Azure Synapse will support materialized views with the same functionality as in Oracle. Materialized views are now a preview feature in Azure Synapse.
In-database triggers: in Oracle, a trigger can be configured to automatically run when a triggering event occurs. Triggering events can be:
A DML statement, such as
INSERT,UPDATE, orDELETE, runs. If you defined a trigger that fires before anINSERTstatement on a customer table, the trigger will fire once before a new row is inserted into the customer table.A DDL statement, such as
CREATEorALTER, runs. This triggering event is often used to record schema changes for auditing purposes.A system event such as startup or shutdown of the Oracle database.
A user event such as login or logout.
Azure Synapse doesn't support Oracle database triggers. However, you can achieve equivalent functionality by using Data Factory, although doing so will require you to refactor the processes that use triggers.
Synonyms: Oracle supports defining synonyms as alternative names for several database object types. Those types include tables, views, sequences, procedures, stored functions, packages, materialized views, Java class schema objects, user-defined objects, or other synonyms.
Azure Synapse doesn't currently support defining synonyms, although if a synonym in Oracle refers to a table or view, then you can define a view in Azure Synapse to match the alternative name. If a synonym in Oracle refers to a function or stored procedure, then you can replace the synonym in Azure Synapse with another function or stored procedure that calls the target.
User-defined types: Oracle supports user-defined objects that can contain a series of individual fields, each with their own definition and default values. Those objects can then be referenced within a table definition in the same way as built-in data types like
NUMBERorVARCHAR.Azure Synapse doesn't currently support user-defined types. If the data you need to migrate includes user-defined data types, either "flatten" them into a conventional table definition, or if they're arrays of data, normalize them in a separate table.
SQL DDL generation
You can edit existing Oracle CREATE TABLE and CREATE VIEW scripts to achieve equivalent definitions in Azure Synapse. To do so, you might need to use modified data types and remove or modify Oracle-specific clauses, such as TABLESPACE.
Tip
Use existing Oracle metadata to automate the generation of CREATE TABLE and CREATE VIEW DDL for Azure Synapse.
Within the Oracle environment, system catalog tables specify the current table/view definition. Unlike user-maintained documentation, system catalog information is always complete and in sync with current table definitions. You can access system catalog information by using utilities such as Oracle SQL Developer. Oracle SQL Developer can generate CREATE TABLE DDL statements that you can edit to apply to equivalent tables in Azure Synapse, as shown in the next screenshot.

Oracle SQL Developer outputs the following CREATE TABLE statement, which contains Oracle-specific clauses that you should remove. Map any unsupported data types before running your modified CREATE TABLE statement on Azure Synapse.
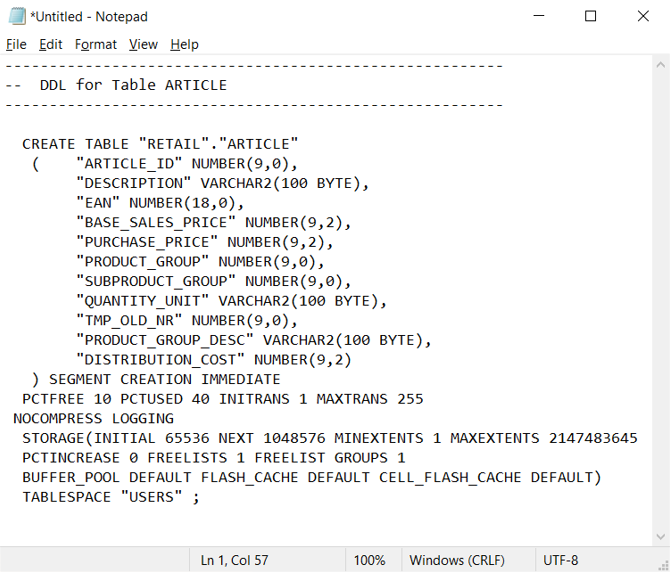
Alternatively, you can automatically generate CREATE TABLE statements from the information within Oracle catalog tables by using SQL queries, SSMA, or third-party migration tools. This approach is the fastest, most consistent way to generate CREATE TABLE statements for many tables.
Tip
Third-party tools and services can automate data mapping tasks.
Third-party vendors offer tools and services to automate migration, including the mapping of data types. If a third-party ETL tool is already in use in the Oracle environment, use that tool to implement any required data transformations.
SQL DML differences between Oracle and Azure Synapse
The ANSI SQL standard defines the basic syntax for DML commands, such as SELECT, INSERT, UPDATE, and DELETE. Although Oracle and Azure Synapse both support DDL commands, in some cases they implement the same command differently.
Tip
The standard SQL DML commands SELECT, INSERT, and UPDATE can have additional syntax options in different database environments.
The following sections discuss the Oracle-specific DML commands that need to be considered during a migration to Azure Synapse.
SQL DML syntax differences
There are some SQL DML syntax differences between Oracle SQL and Azure Synapse T-SQL:
DUALtable: Oracle has a system table namedDUALthat consists of exactly one column nameddummyand one record with the valueX. TheDUALsystem table is used when a query requires a table name for syntax reasons, but the table content isn't needed.An example Oracle query that uses the
DUALtable isSELECT sysdate from dual;. The Azure Synapse equivalent isSELECT GETDATE();. To simplify migration of DML, you could create an equivalentDUALtable in Azure Synapse using the following DDL.CREATE TABLE DUAL ( DUMMY VARCHAR(1) ) GO INSERT INTO DUAL (DUMMY) VALUES ('X') GONULLvalues: aNULLvalue in Oracle is an empty string, represented by aCHARorVARCHARstring type of length0. In Azure Synapse and most other databases,NULLmeans something else. Be careful when migrating data, or when migrating processes that handle or store data, to ensure thatNULLvalues are handled consistently.Oracle outer join syntax: although more recent versions of Oracle support ANSI outer join syntax, older Oracle systems use a proprietary syntax for outer joins that uses a plus sign (
+) within the SQL statement. If you're migrating an older Oracle environment, you might encounter the older syntax. For example:SELECT d.deptno, e.job FROM dept d, emp e WHERE d.deptno = e.deptno (+) AND e.job (+) = 'CLERK' GROUP BY d.deptno, e.job;The equivalent ANSI standard syntax is:
SELECT d.deptno, e.job FROM dept d LEFT OUTER JOIN emp e ON d.deptno = e.deptno and e.job = 'CLERK' GROUP BY d.deptno, e.job ORDER BY d.deptno, e.job;DATEdata: in Oracle, theDATEdata type can store both date and time. Azure Synapse stores date and time in separateDATE,TIME, andDATETIMEdata types. When you're migrating OracleDATEcolumns, check whether they store both date and time or just a date. If they only store a date, then map the column toDATE, otherwise toDATETIME.DATEarithmetic: Oracle supports subtracting one date from another, for exampleSELECT date '2018-12-31' - date '2018-1201' from dual;. In Azure Synapse, you can subtract dates by using theDATEDIFF()function, for exampleSELECT DATEDIFF(day, '2018-12-01', '2018-12-31');.Oracle can subtract integers from dates, for example
SELECT hire_date, (hire_date-1) FROM employees;. In Azure Synapse, you can add or subtract integers from dates by using theDATEADD()function.Updates via views: in Oracle you can run insert, update, and delete operations against a view to update the underlying table. In Azure Synapse, you run those operations against a base table—not a view. You might have to re-engineer ETL processing if an Oracle table is updated through a view.
Built-in functions: the following table shows the differences in the syntax and usage of some built-in functions.
| Oracle Function | Description | Synapse equivalent |
|---|---|---|
| ADD_MONTHS | Add a specified number of months | DATEADD |
| CAST | Convert one built-in data type into another | CAST |
| DECODE | Evaluate a list of conditions | CASE expression |
| EMPTY_BLOB | Create an empty BLOB value |
0x constant (empty binary string) |
| EMPTY_CLOB | Create an empty CLOB or NCLOB value |
'' (empty string) |
| INITCAP | Capitalize the first letter of each word | User-defined function |
| INSTR | Find position of a substring in a string | CHARINDEX |
| LAST_DAY | Get the last date of month | EOMONTH |
| LENGTH | Get string length in characters | LEN |
| LPAD | Left-pad string to the specified length | Expression using REPLICATE, RIGHT, and LEFT |
| MOD | Get the remainder of a division of one number by another |
% operator |
| MONTHS_BETWEEN | Get the number of months between two dates | DATEDIFF |
| NVL | Replace NULL with expression |
ISNULL |
| SUBSTR | Return a substring from a string | SUBSTRING |
| TO_CHAR for datetime | Convert datetime to string | CONVERT |
| TO_DATE | Convert a string to datetime | CONVERT |
| TRANSLATE | One-to-one single character substitution | Expressions using REPLACE or a user-defined function |
| TRIM | Trim leading or trailing characters | LTRIM and RTRIM |
| TRUNC for datetime | Truncate datetime | Expressions using CONVERT |
| UNISTR | Convert Unicode code points to characters | Expressions using NCHAR |
Functions, stored procedures, and sequences
When migrating a data warehouse from a mature environment like Oracle, you probably need to migrate elements other than simple tables and views. For functions, stored procedures, and sequences, check whether tools within the Azure environment can replace their functionality because it's usually more efficient to use built-in Azure tools than to recode the Oracle functions.
As part of your preparation phase, create an inventory of objects that need to be migrated, define a method for handling them, and allocate appropriate resources in your migration plan.
Microsoft tools like SSMA for Oracle and Azure Database Migration Services, or third-party migration products and services, can automate the migration of functions, stored procedures, and sequences.
Tip
Third-party products and services can automate migration of non-data elements.
The following sections discuss the migration of functions, stored procedures, and sequences.
Functions
As with most database products, Oracle supports system and user-defined functions within a SQL implementation. When you migrate a legacy database platform to Azure Synapse, you can usually migrate common system functions without change. Some system functions might have a slightly different syntax, but you can automate any required changes.
For Oracle system functions or arbitrary user-defined functions that have no equivalent in Azure Synapse, recode those functions using the target environment language. Oracle user-defined functions are coded in PL/SQL, Java, or C. Azure Synapse uses the Transact-SQL language to implement user-defined functions.
Stored procedures
Most modern database products support storing procedures within the database. Oracle provides the PL/SQL language for this purpose. A stored procedure typically contains both SQL statements and procedural logic, and returns data or a status.
Azure Synapse supports stored procedures using T-SQL, so you'll need to recode any migrated stored procedures in T-SQL.
Sequences
In Oracle, a sequence is a named database object, created using CREATE SEQUENCE. A sequence provides unique numeric values via the CURRVAL and NEXTVAL methods. You can use the generated unique numbers as surrogate key values for primary keys. Azure Synapse doesn't implement CREATE SEQUENCE, but you can implement sequences using IDENTITY columns or SQL code that generates the next sequence number in a series.
Use EXPLAIN to validate legacy SQL
Tip
Use real queries from the existing system query logs to find potential migration issues.
Assuming a like-for-like migrated data model in Azure Synapse with the same table and column names, one way to test legacy Oracle SQL for compatibility with Azure Synapse is:
- Capture some representative SQL statements from the legacy system query history logs.
- Prefix those queries with the
EXPLAINstatement. - Run the
EXPLAINstatements in Azure Synapse.
Any incompatible SQL will generate an error, and the error information can be used to determine the scale of the recoding task. This approach doesn't require you to load any data into the Azure environment, you only need to create the relevant tables and views.
Summary
Existing legacy Oracle installations are typically implemented in a way that makes migration to Azure Synapse relatively straightforward. Both environments use SQL for analytical queries on large data volumes, and generally use some form of dimensional data model. These factors make Oracle installations a good candidate for migration to Azure Synapse.
To summarize, our recommendations for minimizing the task of migrating SQL code from Oracle to Azure Synapse are:
Migrate your existing data model as-is to minimize risk, effort, and migration time, even if a different data model is planned, such as a data vault.
Understand the differences between the Oracle SQL implementation and the Azure Synapse implementation.
Use the metadata and query logs from the existing Oracle implementation to assess the impact of changing the environment. Plan an approach to mitigate the differences.
Automate the migration process to minimize risk, effort, and migration time. You can use Microsoft tools such as Azure Database Migration Services and SSMA.
Consider using specialist third-party tools and services to streamline the migration.
Next steps
To learn more about Microsoft and third-party tools, see the next article in this series: Tools for Oracle data warehouse migration to Azure Synapse Analytics.