Co to jest platforma Apache Spark w usłudze Azure Synapse Analytics?
Apache Spark to platforma przetwarzania równoległego, która obsługuje przetwarzanie w pamięci w celu zwiększania wydajności aplikacji do analizy danych big data. Platforma Apache Spark w usłudze Azure Synapse Analytics to jedna z implementacji platformy Apache Spark oferowanych przez firmę Microsoft w chmurze. Usługa Azure Synapse ułatwia tworzenie i konfigurowanie bezserwerowej puli zadań platformy Apache Spark na platformie Azure. Pule zadań platformy Spark w usłudze Azure Synapse są zgodne z usługami Azure Storage i Azure Data Lake Generation 2 Storage. Można więc używać pul zadań platformy Spark do przetwarzania danych przechowywanych na platformie Azure.
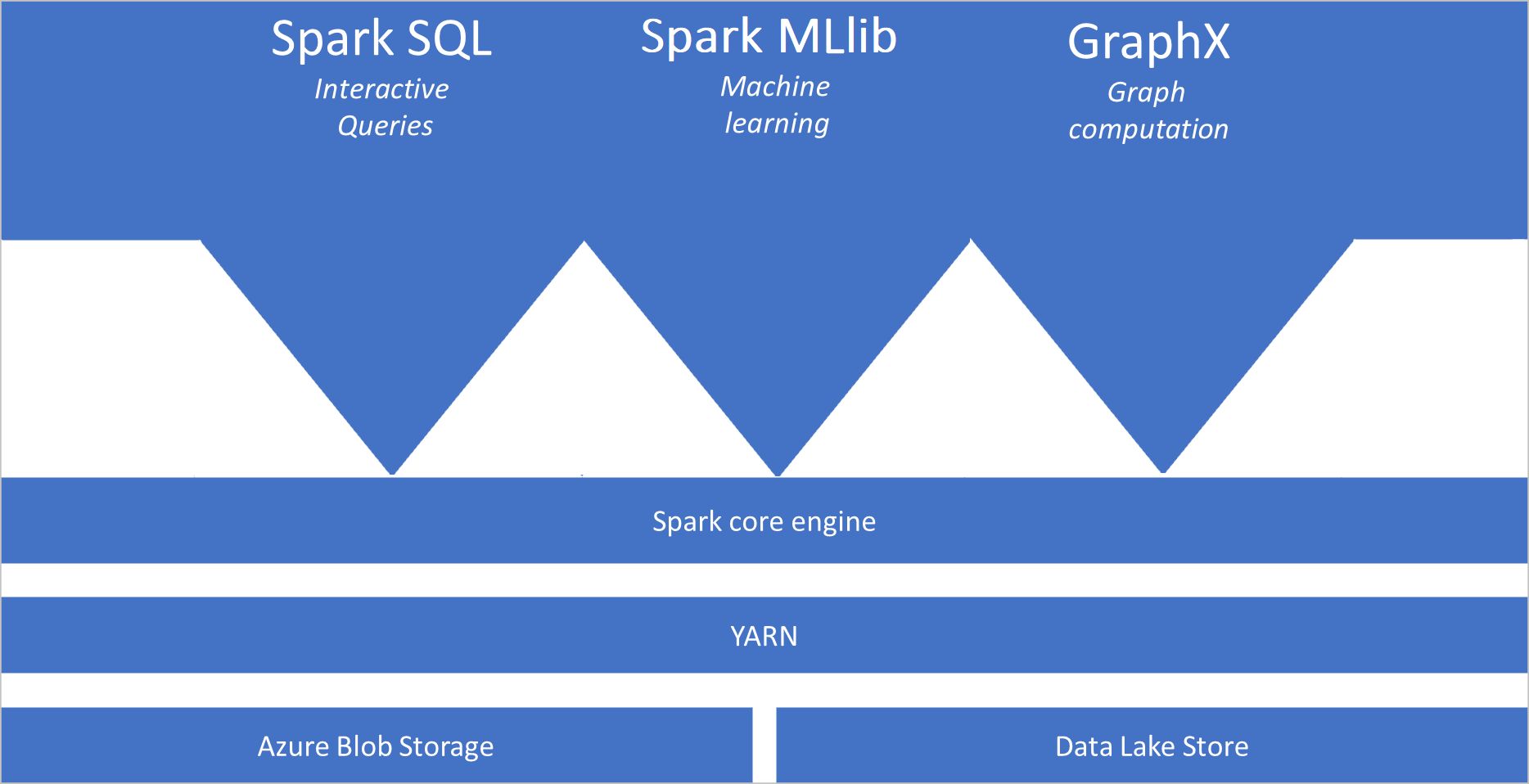
Co to jest platforma Apache Spark
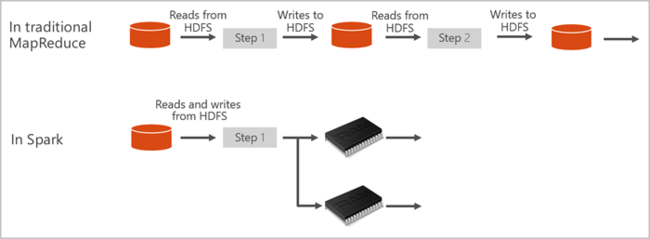
Platforma Apache Spark udostępnia typy pierwotne umożliwiające używanie klastrów obliczeniowych korzystających z funkcji przetwarzania w pamięci. Zadanie Spark może ładować i buforować dane w pamięci, a następnie wielokrotnie wykonywać zapytania względem tych danych. Przetwarzanie w pamięci jest szybsze niż aplikacje oparte na dyskach. Platforma Spark obsługuje również integrację z wieloma językami programowania, co pozwala manipulować rozproszonymi zestawami danych jak kolekcjami lokalnymi. Nie ma potrzeby, aby wszystkie elementy były obejmowane strukturami operacji mapowania i redukcji. Więcej informacji można dowiedzieć się z wideo platformy Apache Spark for Synapse.
Pule platformy Spark w usłudze Azure Synapse oferują w pełni zarządzaną usługę Spark. Poniżej wymieniono korzyści wynikające z tworzenia puli spark w usłudze Azure Synapse Analytics.
| Funkcja | opis |
|---|---|
| Szybkość i wydajność | Wystąpienia platformy Spark są uruchamiane w ciągu około 2 minut przez mniej niż 60 węzłów i około 5 minut przez więcej niż 60 węzłów. Wystąpienie jest domyślnie zamykane 5 minut po uruchomieniu ostatniego zadania, chyba że jest ono aktywne przez połączenie notesu. |
| Łatwość tworzenia | Nową pulę Spark można utworzyć w usłudze Azure Synapse w ciągu kilku minut przy użyciu witryny Azure Portal, programu Azure PowerShell lub zestawu SDK platformy .NET usługi Synapse Analytics. Zobacz Rozpoczynanie pracy z pulami platformy Spark w usłudze Azure Synapse Analytics. |
| Łatwość użycia | Usługa Synapse Analytics zawiera notes niestandardowy pochodzący z nteract. Można ich używać do interakcyjnego przetwarzania danych i wizualizacji. |
| Interfejsy API REST | Platforma Spark w usłudze Azure Synapse Analytics obejmuje usługę Apache Livy, serwer zadań Spark oparty na interfejsie API REST do zdalnego przesyłania i monitorowania zadań. |
| Obsługa usługi Azure Data Lake Storage Generation 2 | Pule platformy Spark w usłudze Azure Synapse mogą używać usługi Azure Data Lake Storage Generation 2 i magazynu obiektów blob. Aby uzyskać więcej informacji na temat usługi Data Lake Storage, zobacz Omówienie usługi Azure Data Lake Storage |
| Integracja ze zintegrowanymi środowiskami projektowymi innych firm | Usługa Azure Synapse udostępnia wtyczkę IDE dla środowiska IntelliJ IDEA firmy JetBrains, która jest przydatna do tworzenia i przesyłania aplikacji do puli Spark. |
| Wstępnie załadowane biblioteki Anaconda | Pule platformy Spark w usłudze Azure Synapse są dostarczane ze wstępnie zainstalowanymi bibliotekami Anaconda. Platforma Anaconda udostępnia blisko 200 bibliotek do uczenia maszynowego, analizy danych, wizualizacji i innych technologii. |
| Skalowalność | Platforma Apache Spark w pulach usługi Azure Synapse może mieć włączoną funkcję automatycznego skalowania, dzięki czemu pule można skalować, dodając lub usuwając węzły zgodnie z potrzebami. Ponadto pule platformy Spark można wyłączyć bez utraty danych, ponieważ wszystkie dane są przechowywane w usłudze Azure Storage lub Data Lake Storage. |
Pule platformy Spark w usłudze Azure Synapse obejmują następujące składniki, które są domyślnie dostępne w pulach:
- Spark Core. Obejmuje takie składniki jak Spark Core, Spark SQL, GraphX oraz MLlib.
- Anaconda
- Apache Livy
- notes nteract
Architektura puli platformy Spark
Aplikacje platformy Spark działają jako niezależne zestawy procesów w puli, koordynowane przez SparkContext obiekt w głównym programie nazywanym programem sterowników.
Program SparkContext może łączyć się z menedżerem klastra, który przydziela zasoby między aplikacjami. Menedżer klastra to Apache Hadoop YARN. Po nawiązaniu połączenia platforma Spark uzyskuje funkcje wykonawcze w węzłach w puli, które są procesami, które uruchamiają obliczenia i przechowują dane dla aplikacji. Następnie wysyła kod aplikacji zdefiniowany przez pliki JAR lub Python przekazane do SparkContextfunkcji wykonawczej. SparkContext Na koniec wysyła zadania do funkcji wykonawczych do uruchomienia.
Polecenie SparkContext uruchamia funkcję główną użytkownika i wykonuje różne operacje równoległe w węzłach. Następnie program SparkContext zbiera wyniki operacji. Węzły odczytują i zapisują dane z i do systemu plików. Węzły buforują również przekształcone dane w pamięci jako odporne rozproszone zestawy danych (RDD).
Narzędzie SparkContext łączy się z pulą Spark i jest odpowiedzialne za konwertowanie aplikacji na skierowany graf acykliczny (DAG). Wykres składa się z poszczególnych zadań uruchamianych w ramach procesu wykonawczego w węzłach. Każda aplikacja pobiera własne procesy wykonawcze, które pozostają w trakcie całej aplikacji i uruchamiają zadania w wielu wątkach.
Apache Spark w przypadkach użycia usługi Azure Synapse Analytics
Pule platformy Spark w usłudze Azure Synapse Analytics umożliwiają wykonanie następujących kluczowych scenariuszy:
- inżynierowie danych/przygotowywanie danych
Platforma Apache Spark zawiera wiele funkcji językowych do obsługi przygotowywania i przetwarzania dużych ilości danych, dzięki czemu może być bardziej cenna, a następnie zużywana przez inne usługi w usłudze Azure Synapse Analytics. Jest to włączone za pośrednictwem wielu języków (C#, Scala, PySpark, Spark SQL) i dostarczonych bibliotek na potrzeby przetwarzania i łączności.
- Usługa Machine Learning
Platforma Apache Spark zawiera bibliotekę MLlib, bibliotekę uczenia maszynowego utworzoną na platformie Spark, której można używać z puli Spark w usłudze Azure Synapse Analytics. Pule platformy Spark w usłudze Azure Synapse Analytics obejmują również platformę Anaconda, dystrybucję języka Python z różnymi pakietami do nauki o danych, w tym uczenia maszynowego. W połączeniu z wbudowaną obsługą notesów zyskujesz środowisko do tworzenia aplikacji do uczenia maszynowego.
- Przesyłanie strumieniowe danych
Usługa Synapse Spark obsługuje przesyłanie strumieniowe ze strukturą platformy Spark, o ile korzystasz z obsługiwanej wersji środowiska uruchomieniowego usługi Azure Synapse Spark. Wszystkie zadania są obsługiwane przez siedem dni. Dotyczy to zarówno zadań wsadowych, jak i przesyłania strumieniowego, a ogólnie klienci automatyzują proces ponownego uruchamiania przy użyciu usługi Azure Functions.
Powiązana zawartość
Skorzystaj z następujących artykułów, aby dowiedzieć się więcej na temat platformy Apache Spark w usłudze Azure Synapse Analytics:
- Szybki start: tworzenie puli Spark w usłudze Azure Synapse
- Szybki start: tworzenie notesu platformy Apache Spark
- Samouczek: uczenie maszynowe przy użyciu platformy Apache Spark
Uwaga
Niektóre z oficjalnych dokumentacji platformy Apache Spark korzystają z konsoli Spark, która nie jest dostępna w usłudze Azure Synapse Spark. Zamiast tego skorzystaj z notesu lub środowiska IntelliJ.