Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Organizacje często muszą przetwarzać duże ilości danych przed ich udostępnieniem kluczowym uczestnikom biznesowym. Z tego samouczka dowiesz się, jak wykorzystać zintegrowane środowiska w usłudze Azure Synapse Analytics do przetwarzania danych przy użyciu platformy Apache Spark, a później udostępniać dane użytkownikom końcowym za pośrednictwem usługi Power BI i bezserwerowego języka SQL.
Zanim rozpoczniesz
- Obszar roboczy usługi Azure Synapse Analytics z kontem magazynu usługi ADLS Gen2 ustawionym jako magazyn domyślny.
- Obszar roboczy usługi Power BI i program Power BI Desktop umożliwiają wizualizowanie danych. Aby uzyskać szczegółowe informacje, zobacz Tworzenie obszaru roboczego usługi Power BI i instalowanie programu Power BI Desktop
- Połączona usługa łącząca obszary robocze usługi Azure Synapse Analytics i Power BI. Aby uzyskać szczegółowe informacje, zobacz link do obszaru roboczego usługi Power BI
- Bezserwerowa pula platformy Apache Spark w obszarze roboczym usługi Synapse Analytics. Aby uzyskać szczegółowe informacje, zobacz tworzenie bezserwerowej puli platformy Apache Spark
Pobieranie i przygotowywanie danych
W tym przykładzie użyjesz platformy Apache Spark do przeprowadzenia analizy danych dotyczących napiwków za przejazdy taksówką z Nowego Jorku. Dane są dostępne za pośrednictwem usługi Azure Open Datasets. Ten podzestaw zestawu danych zawiera informacje o żółtych przejazdach taksówek, w tym informacje o każdej podróży, godzinie rozpoczęcia i godzinie zakończenia oraz lokalizacjach, kosztach i innych interesujących atrybutach.
Uruchom następujące wiersze, aby utworzyć ramkę danych platformy Spark, wklejając kod do nowej komórki. Spowoduje to pobranie danych za pośrednictwem interfejsu API Open Datasets. Pobieranie wszystkich danych generuje około 1,5 miliarda wierszy. W poniższym przykładzie kodu użyto start_date i end_date do zastosowania filtru zwracającego jeden miesiąc danych.
from azureml.opendatasets import NycTlcYellow from dateutil import parser from datetime import datetime end_date = parser.parse('2018-06-06') start_date = parser.parse('2018-05-01') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())Korzystając z bazy danych Apache Spark SQL, utworzymy bazę danych o nazwie NycTlcTutorial. Użyjemy tej bazy danych do przechowywania wyników przetwarzania danych.
%%pyspark spark.sql("CREATE DATABASE IF NOT EXISTS NycTlcTutorial")Następnie użyjemy operacji ramki danych Platformy Spark do przetwarzania danych. W poniższym kodzie wykonamy następujące przekształcenia:
- Usunięcie kolumn, które nie są potrzebne.
- Usunięcie wartości odstających/nieprawidłowych przez filtrowanie.
- Tworzenie nowych funkcji, takich jak
tripTimeSecsitippedna potrzeby dodatkowej analizy.
from pyspark.sql.functions import unix_timestamp, date_format, col, when taxi_df = filtered_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\ , 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\ , date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\ , date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\ , (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\ , (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped') )\ .filter((filtered_df.passengerCount > 0) & (filtered_df.passengerCount < 8)\ & (filtered_df.tipAmount >= 0) & (filtered_df.tipAmount <= 25)\ & (filtered_df.fareAmount >= 1) & (filtered_df.fareAmount <= 250)\ & (filtered_df.tipAmount < filtered_df.fareAmount)\ & (filtered_df.tripDistance > 0) & (filtered_df.tripDistance <= 100)\ & (filtered_df.rateCodeId <= 5) & (filtered_df.paymentType.isin({"1", "2"})))Na koniec zapiszemy ramkę danych przy użyciu metody Apache Spark
saveAsTable. Umożliwi to późniejsze wykonywanie zapytań i łączenie się z tą samą tabelą przy użyciu bezserwerowych pul SQL.taxi_df.write.mode("overwrite").saveAsTable("NycTlcTutorial.nyctaxi")
Wykonywanie zapytań dotyczących danych przy użyciu bezserwerowych pul SQL
Usługa Azure Synapse Analytics umożliwia różnym aparatom obliczeniowym obszaru roboczego udostępnianie baz danych i tabel między bezserwerowymi pulami platformy Apache Spark i bezserwerową pulą SQL. Jest to obsługiwane za pośrednictwem funkcji zarządzania udostępnionymi metadanymi usługi Synapse. W związku z tym bazy danych utworzone przez platformę Spark oraz ich tabele oparte na formacie Parquet stają się widoczne w serwerlessowej puli SQL obszaru roboczego.
Aby wysłać zapytanie do tabeli platformy Apache Spark przy użyciu bezserwerowej puli SQL:
Po zapisaniu tabeli platformy Apache Spark przejdź do karty danych .
W sekcji Obszary robocze znajdź właśnie utworzoną tabelę Apache Spark i kliknij Nowy skrypt SQL, a następnie kliknij Wybierz 100 pierwszych wierszy.
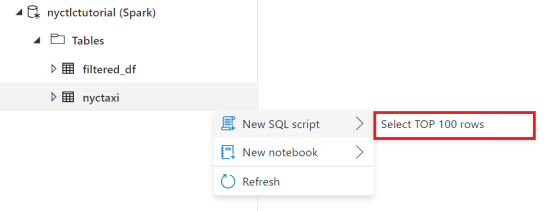
Możesz nadal uściślić zapytanie, a nawet wizualizować wyniki przy użyciu opcji tworzenia wykresów SQL.
Nawiązywanie połączenia z usługą Power BI
Następnie połączymy bezserwerową pulę SQL z obszarem roboczym usługi Power BI. Po połączeniu obszaru roboczego będzie można tworzyć raporty usługi Power BI zarówno bezpośrednio z usługi Azure Synapse Analytics, jak i z poziomu programu Power BI Desktop.
Uwaga
Przed rozpoczęciem należy skonfigurować połączoną usługę w obszarze roboczym usługi Power BI i pobrać program Power BI Desktop.
Aby połączyć naszą bezserwerową pulę SQL z obszarem roboczym usługi Power BI:
Przejdź do karty Zestawy danych usługi Power BI i wybierz opcję + Nowy zestaw danych. Po wyświetleniu monitu pobierz plik pbids z bazy danych usługi SQL Analytics, której chcesz użyć jako źródła danych.
Otwórz plik w programie Power BI Desktop, aby utworzyć zestaw danych. Po otwarciu pliku połącz się z bazą danych programu SQL Server przy użyciu konta Microsoft i opcji Importuj .
Tworzenie raportu usługi Power BI
W programie Power BI Desktop możesz teraz dodać do raportu wykres kluczowych elementów mających wpływ .
Przeciągnij kolumnę średnią tipAmount na oś Analizuj.
Przeciągnij kolumny weekdayString, średni dystansPodróży i średni czasPodróżyWSekundach na oś Wyjaśnienia według.
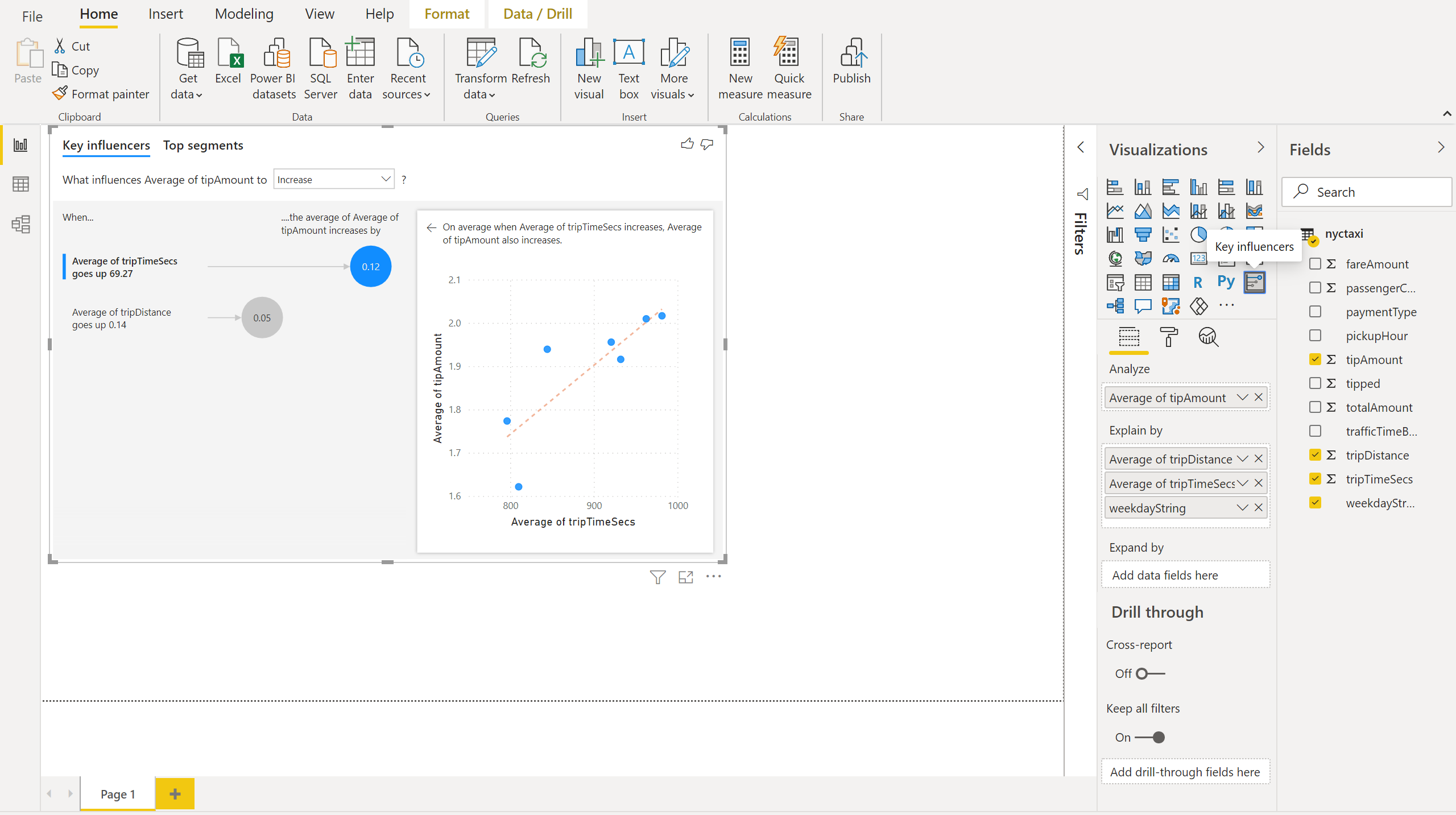
Na karcie Narzędzia główne programu Power BI Desktop wybierz pozycję Publikuj i Zapisz zmiany. Wprowadź nazwę pliku i zapisz ten raport w obszarze roboczym NycTaxiTutorial.
Ponadto można również tworzyć wizualizacje usługi Power BI z poziomu obszaru roboczego usługi Azure Synapse Analytics. W tym celu przejdź do karty Programowanie w obszarze roboczym usługi Azure Synapse i otwórz kartę Power BI. W tym miejscu możesz wybrać raport i kontynuować tworzenie kolejnych wizualizacji.
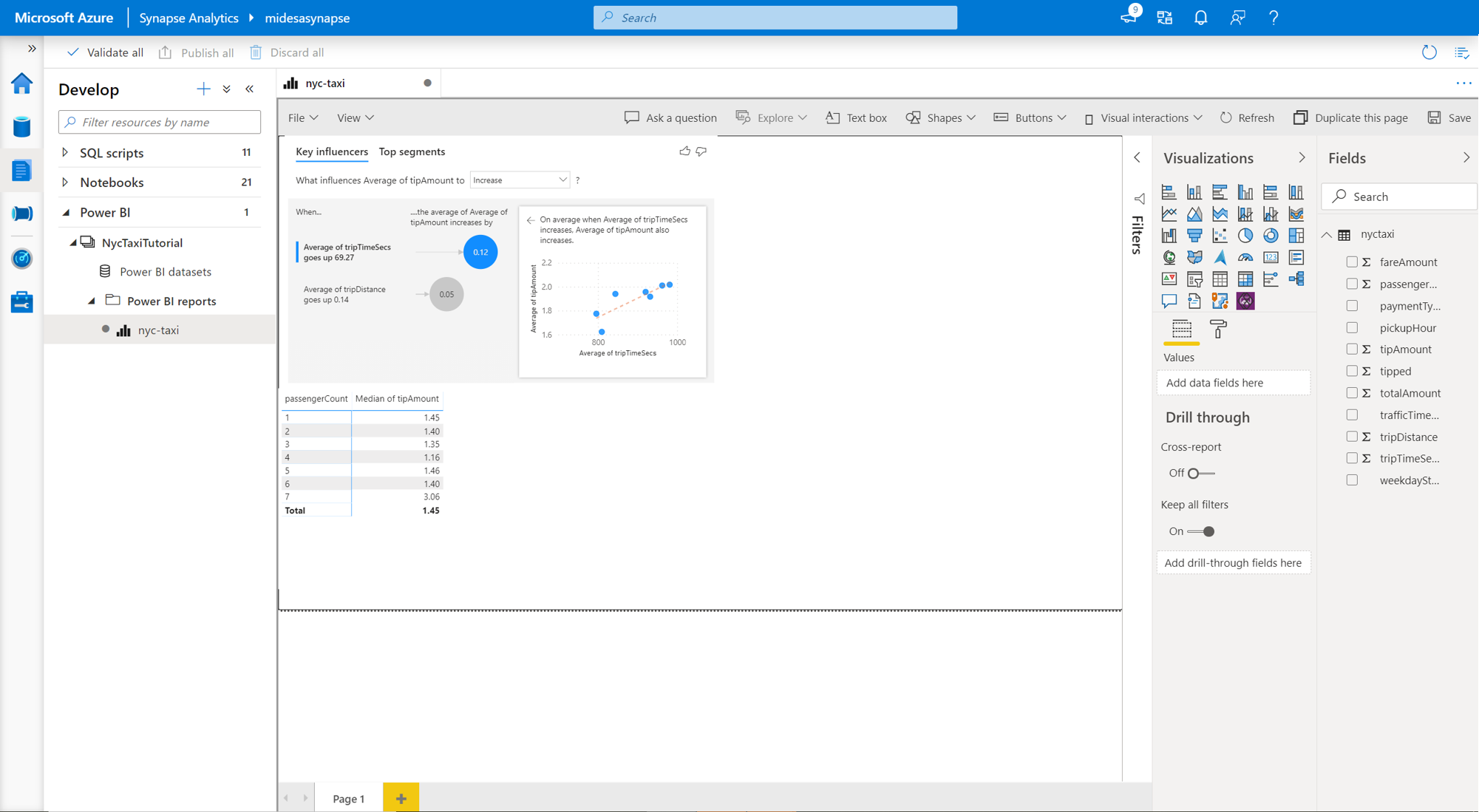
Aby uzyskać więcej informacji na temat tworzenia zestawu danych za pomocą bezserwerowego języka SQL i nawiązywania połączenia z usługą Power BI, zapoznaj się z tym samouczkiem dotyczącym nawiązywania połączenia z programem Power BI Desktop
Następne kroki
Aby dowiedzieć się więcej na temat możliwości wizualizacji danych w usłudze Azure Synapse Analytics, zapoznaj się z następującymi dokumentami i samouczkami: