Kompleksowe scenariusze usługi Lakehouse: omówienie i architektura
Microsoft Fabric to rozwiązanie analityczne typu "wszystko w jednym" dla przedsiębiorstw, które obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym i analizy biznesowej. Oferuje kompleksowy pakiet usług, w tym usług typu data lake, inżynierii danych i integracji danych, w jednym miejscu. Aby uzyskać więcej informacji, zobacz Co to jest usługa Microsoft Fabric?
Ten samouczek przeprowadzi Cię przez kompleksowe scenariusze pozyskiwania danych do użycia danych. Pomaga to w tworzeniu podstawowego zrozumienia usługi Fabric, w tym różnych środowisk i sposobu ich integracji, a także profesjonalnych i obywatelskich środowisk deweloperskich, które są dostarczane z pracą na tej platformie. Ten samouczek nie jest przeznaczony do stosowania architektury referencyjnej, wyczerpującej listy funkcji i funkcji ani rekomendacji dotyczących konkretnych najlepszych rozwiązań.
Scenariusz end-to-end usługi Lakehouse
Tradycyjnie organizacje budowały nowoczesne magazyny danych na potrzeby transakcyjnej i ustrukturyzowanej analizy danych. Usługa Data Lakehouses na potrzeby analizy danych big data (częściowo/bez struktury). Te dwa systemy działały równolegle, tworząc silosy, duplikowanie danych i zwiększając całkowity koszt posiadania.
Sieć szkieletowa ze zjednoczeniem magazynu danych i standaryzacji w formacie usługi Delta Lake pozwala wyeliminować silosy, usunąć duplikowanie danych i znacząco zmniejszyć całkowity koszt posiadania.
Dzięki elastyczności oferowanej przez usługę Fabric można zaimplementować architektury typu lakehouse lub magazynu danych lub połączyć je razem, aby uzyskać najlepsze wyniki zarówno z prostą implementacją. W tym samouczku przyjrzysz się przykładowi organizacji handlu detalicznego i utworzysz jej lakehouse od początku do końca. Używa architektury medalonu, w której warstwa z brązu ma nieprzetworzone dane, warstwa srebra ma zweryfikowane i deduplikowane dane, a warstwa złota ma wysoce wyrafinowane dane. Możesz podjąć to samo podejście, aby zaimplementować magazyn lakehouse dla dowolnej organizacji z dowolnej branży.
W tym samouczku wyjaśniono, jak deweloper w fikcyjnej firmie Wide World Importers z domeny detalicznej wykonuje następujące kroki:
Zaloguj się do swojego konta usługi Power BI i zarejestruj się, aby skorzystać z bezpłatnej wersji próbnej usługi Microsoft Fabric. Jeśli nie masz licencji usługi Power BI, zarejestruj się w celu uzyskania bezpłatnej licencji usługi Power BI, a następnie możesz rozpocząć wersję próbną usługi Fabric.
Tworzenie i implementowanie kompleksowej bazy danych typu lakehouse dla organizacji:
- Utwórz obszar roboczy Sieć szkieletowa.
- Utwórz jezioro.
- Pozyskiwanie danych, przekształcanie danych i ładowanie ich do magazynu lakehouse. Możesz również eksplorować usługę OneLake, jedną kopię danych w trybie lakehouse i tryb punktu końcowego analizy SQL.
- Połącz się z usługą Lakehouse przy użyciu punktu końcowego analizy SQL i utwórz raport usługi Power BI przy użyciu usługi DirectLake , aby analizować dane sprzedaży w różnych wymiarach.
- Opcjonalnie można organizować i planować przepływ pozyskiwania i przekształcania danych za pomocą potoku.
Wyczyść zasoby , usuwając obszar roboczy i inne elementy.
Architektura
Na poniższej ilustracji przedstawiono kompleksową architekturę typu lakehouse. Składniki, które są zaangażowane, zostały opisane na poniższej liście.
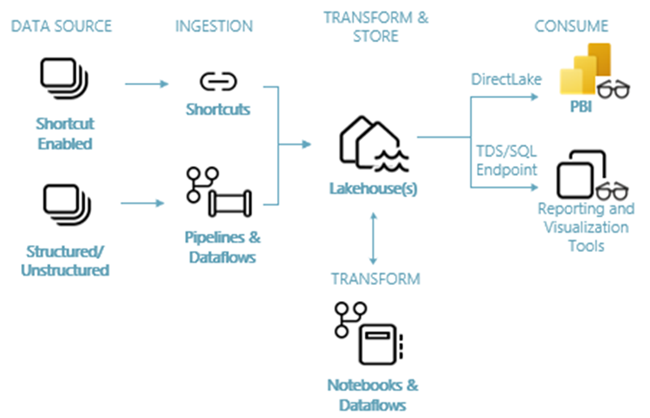
Źródła danych: sieć szkieletowa umożliwia szybkie i łatwe łączenie się z usługami Azure Data Services, a także z innymi platformami opartymi na chmurze i lokalnymi źródłami danych w celu usprawnienia pozyskiwania danych.
Pozyskiwanie: możesz szybko tworzyć szczegółowe informacje dla organizacji przy użyciu ponad 200 łączników natywnych. Te łączniki są zintegrowane z potokiem sieci szkieletowej i korzystają z przyjaznego dla użytkownika przekształcenia danych przeciągania i upuszczania za pomocą przepływu danych. Ponadto za pomocą funkcji Skrót w sieci szkieletowej można nawiązać połączenie z istniejącymi danymi bez konieczności kopiowania ani przenoszenia.
Przekształcanie i przechowywanie: Sieć szkieletowa standandaryzuje format usługi Delta Lake. Oznacza to, że wszystkie aparaty sieci szkieletowej mogą uzyskiwać dostęp do tego samego zestawu danych przechowywanego w usłudze OneLake i manipulować nim bez duplikowania danych. Ten system magazynowania zapewnia elastyczność tworzenia magazynów typu lakehouse przy użyciu architektury medalionu lub siatki danych, w zależności od wymagań organizacji. Możesz wybrać środowisko przekształcania danych z małą ilością kodu lub bez kodu, korzystając z potoków/przepływów danych lub notesu/platformy Spark w celu uzyskania środowiska opartego na kodzie.
Korzystanie: usługa Power BI może korzystać z danych z usługi Lakehouse na potrzeby raportowania i wizualizacji. Każda usługa Lakehouse ma wbudowany punkt końcowy TDS nazywany punktem końcowym analizy SQL, który umożliwia łatwą łączność i wykonywanie zapytań dotyczących danych w tabelach usługi Lakehouse z innych narzędzi raportowania. Punkt końcowy analizy SQL zapewnia użytkownikom funkcjonalność połączenia SQL.
Przykładowy zestaw danych
W tym samouczku użyto przykładowej bazy danych Wide World Importers (WWI). W przypadku kompleksowego scenariusza usługi Lakehouse wygenerowaliśmy wystarczające dane, aby poznać możliwości skalowania i wydajności platformy Fabric.
Wide World Importers (WWI) to hurtowy importer towarów nowości i dystrybutor działający z obszaru Zatoki San Francisco. Jako hurtownik klienci WWI głównie obejmują firmy, które odsprzedają się osobom fizycznym. WWI sprzedaje klientom detalicznym w Stany Zjednoczone, w tym sklepy specjalne, supermarkety, sklepy obliczeniowe, sklepy turystyczne i niektóre osoby. WWI sprzedaje również innym hurtowniom za pośrednictwem sieci agentów, którzy promują produkty w imieniu WWI. Aby dowiedzieć się więcej na temat profilu i operacji firmy, zobacz Przykładowe bazy danych Wide World Importers dla usługi Microsoft SQL.
Ogólnie rzecz biorąc, dane są przesyłane z systemów transakcyjnych lub aplikacji biznesowych do lakehouse. Jednak ze względu na prostotę w tym samouczku używamy modelu wymiarowego dostarczonego przez WWI jako początkowego źródła danych. Używamy go jako źródła do pozyskiwania danych w lakehouse i przekształcania ich na różnych etapach (Brązowe, Srebrne i Złote) architektury medalonu.
Model danych
Chociaż model wymiarowy WWI zawiera wiele tabel faktów, w tym samouczku używamy tabeli faktów Sprzedaż i skorelowanych wymiarów. Poniższy przykład ilustruje model danych WWI:
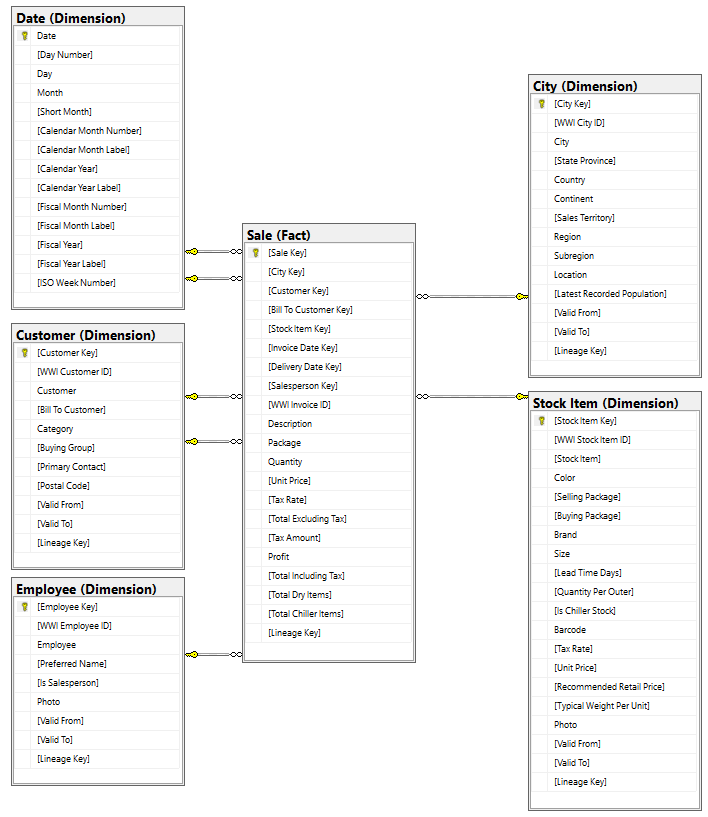
Przepływ danych i transformacji
Jak opisano wcześniej, używamy przykładowych danych z przykładowych danych wide world importers (WWI) w celu utworzenia tej kompleksowej bazy danych typu lakehouse. W tej implementacji przykładowe dane są przechowywane na koncie usługi Azure Data Storage w formacie pliku Parquet dla wszystkich tabel. Jednak w rzeczywistych scenariuszach dane zazwyczaj pochodzą z różnych źródeł i w różnych formatach.
Na poniższej ilustracji przedstawiono przekształcenie źródła, miejsca docelowego i danych:
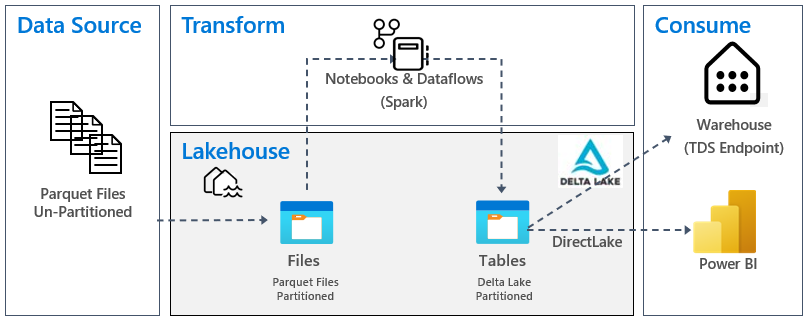
Źródło danych: dane źródłowe są w formacie pliku Parquet i w strukturze niepartycyjnej. Jest on przechowywany w folderze dla każdej tabeli. W tym samouczku skonfigurujemy potok w celu pozyskiwania pełnych danych historycznych lub jednorazowych do usługi Lakehouse.
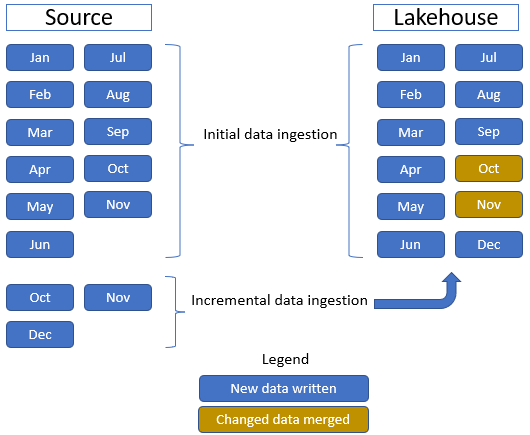
W tym samouczku używamy tabeli faktów Sprzedaż , która zawiera jeden folder nadrzędny z danymi historycznymi przez 11 miesięcy (z jednym podfolderem dla każdego miesiąca) i innym folderem zawierającym dane przyrostowe przez trzy miesiące (jeden podfolder dla każdego miesiąca). Podczas początkowego pozyskiwania danych dane są pozyskiwane do tabeli lakehouse przez 11 miesięcy. Jednak po nadejściu danych przyrostowych zawiera zaktualizowane dane dla października i listopada, a nowe dane z grudnia i listopada są scalane z istniejącymi danymi, a nowe dane z grudnia są zapisywane w tabeli lakehouse, jak pokazano na poniższej ilustracji:
Lakehouse: w tym samouczku utworzysz jezioro, pozyskujesz dane w sekcji plików lakehouse, a następnie utworzysz tabele delty lake w sekcji Tabele lakehouse.
Przekształcanie: w przypadku przygotowywania i przekształcania danych są widoczne dwa różne podejścia. Demonstrujemy użycie notesów/platformy Spark dla użytkowników, którzy preferują środowisko oparte na kodzie i używają potoków/przepływu danych dla użytkowników, którzy preferują środowisko z małą ilością kodu lub bez kodu.
Użycie: aby zademonstrować użycie danych, zobaczysz, jak za pomocą funkcji DirectLake usługi Power BI tworzyć raporty, pulpity nawigacyjne i bezpośrednio wykonywać zapytania o dane z usługi Lakehouse. Ponadto pokazano, jak udostępnić dane narzędziom raportowania innych firm przy użyciu punktu końcowego analizy TDS/SQL. Ten punkt końcowy umożliwia nawiązywanie połączenia z magazynem i uruchamianie zapytań SQL na potrzeby analizy.
Następny krok
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla