Format tekstu rozdzielanego w usłudze Data Factory w usłudze Microsoft Fabric
W tym artykule opisano sposób konfigurowania rozdzielanego formatu tekstu w potoku danych usługi Data Factory w usłudze Microsoft Fabric.
Obsługiwane możliwości
Format tekstu rozdzielanego jest obsługiwany w przypadku następujących działań i łączników jako źródła i miejsca docelowego.
| Kategoria | Łącznik/działanie |
|---|---|
| Obsługiwany łącznik | Amazon S3 |
| Zgodność z usługą Amazon S3 | |
| Azure Blob Storage | |
| Usługa Azure Data Lake Storage 1. generacji | |
| Azure Data Lake Storage Gen2 | |
| Azure Files | |
| System plików | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Pliki lakehouse | |
| Oracle Cloud Storage | |
| SFTP | |
| Obsługiwane działanie | działanie Kopiuj (źródło/miejsce docelowe) |
| Działanie Lookup | |
| Działanie GetMetadata | |
| Działanie usuwania |
Rozdzielany format tekstu w działaniu kopiowania
Aby skonfigurować format tekstu rozdzielanego, wybierz połączenie w źródle lub miejscu docelowym działania kopiowania potoku danych, a następnie wybierz pozycję RozdzielanyTekst na liście rozwijanej Format pliku. Wybierz pozycję Ustawienia , aby uzyskać dalszą konfigurację tego formatu.
Rozdzielany format tekstu jako źródło
Po wybraniu pozycji Ustawienia w sekcji Format pliku w oknie dialogowym Ustawienia formatu pliku zostaną wyświetlone następujące właściwości.
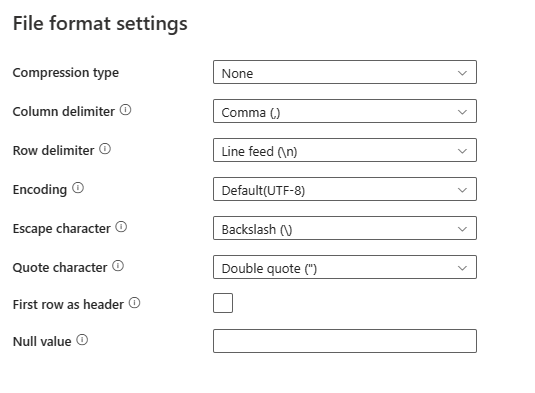
Typ kompresji: koder koder kompresji używany do odczytywania rozdzielonych plików tekstowych. Możesz wybrać typ Brak, bzip2, gzip, deflate, ZipDeflate, TarGzip lub tar na liście rozwijanej.
Jeśli wybierzesz opcję ZipDeflate jako typ kompresji, zachowaj nazwę pliku zip jako folder będzie wyświetlany w obszarze Ustawienia zaawansowane na karcie Źródło .
- Zachowaj nazwę pliku zip jako folder: wskazuje, czy podczas kopiowania zachować nazwę źródłowego pliku zip jako strukturę folderów.
- Jeśli to pole jest zaznaczone (ustawienie domyślne), usługa zapisuje rozpakowane pliki na .
<specified file path>/<folder named as source zip file>/ - Jeśli to pole jest niezaznaczone, usługa zapisuje rozpakowane pliki bezpośrednio do
<specified file path>. Upewnij się, że nie masz zduplikowanych nazw plików w różnych źródłowych plikach zip, aby uniknąć wyścigów ani nieoczekiwanych zachowań.
- Jeśli to pole jest zaznaczone (ustawienie domyślne), usługa zapisuje rozpakowane pliki na .
W przypadku wybrania opcji TarGzip/tar jako typu kompresji zachowaj nazwę pliku kompresji jako folder zostanie wyświetlona w obszarze Ustawienia zaawansowane na karcie Źródło .
- Zachowaj nazwę pliku kompresji jako folder: wskazuje, czy podczas kopiowania zachować nazwę skompresowanego pliku źródłowego jako strukturę folderów.
- Jeśli to pole jest zaznaczone (ustawienie domyślne), usługa zapisuje dekompresowane pliki do
<specified file path>/<folder named as source compressed file>/. - Jeśli to pole jest niezaznaczone, usługa zapisuje dekompresowane pliki bezpośrednio do
<specified file path>. Upewnij się, że nie masz zduplikowanych nazw plików w różnych źródłowych plikach zip, aby uniknąć wyścigów ani nieoczekiwanych zachowań.
- Jeśli to pole jest zaznaczone (ustawienie domyślne), usługa zapisuje dekompresowane pliki do
- Zachowaj nazwę pliku zip jako folder: wskazuje, czy podczas kopiowania zachować nazwę źródłowego pliku zip jako strukturę folderów.
Poziom kompresji: określ współczynnik kompresji po wybraniu typu kompresji. Możesz wybrać jedną z opcji Optymalna lub Najszybsza.
- Najszybsza: operacja kompresji powinna zostać ukończona tak szybko, jak to możliwe, nawet jeśli wynikowy plik nie jest optymalnie skompresowany.
- Optymalna: operacja kompresji powinna być optymalnie skompresowana, nawet jeśli operacja trwa dłużej. Aby uzyskać więcej informacji, zobacz Temat Poziom kompresji.
Ogranicznik kolumn: znaki używane do oddzielania kolumn w pliku. Wartość domyślna to przecinek (
,).Ogranicznik wierszy: określ znak używany do oddzielania wierszy w pliku. Dozwolony jest tylko jeden znak. Wartość domyślna to źródło danych
\nwiersza .Kodowanie: typ kodowania używany do odczytu/zapisu plików testowych. Wartość domyślna to UTF-8.
Znak ucieczki: pojedynczy znak ucieczki cudzysłowów wewnątrz wartości cudzysłowu. Wartość domyślna to ukośnik
\odwrotny. Gdy znak ucieczki jest zdefiniowany jako pusty ciąg, znak cudzysłowu musi być również ustawiony jako pusty ciąg, w tym przypadku upewnij się, że wszystkie wartości kolumn nie zawierają ograniczników.Znak cudzysłowu: pojedynczy znak cudzysłowu wartości kolumn, jeśli zawiera ogranicznik kolumn. Wartość domyślna to podwójne cudzysłowy
". Gdy znak cudzysłowu jest zdefiniowany jako pusty ciąg, oznacza to, że nie ma cudzysłowu, a wartość kolumny nie jest cytowana, a znak ucieczki jest używany do ucieczki ogranicznika kolumny i samego siebie.Pierwszy wiersz jako nagłówek: określa, czy należy traktować/tworzyć pierwszy wiersz jako wiersz nagłówka z nazwami kolumn. Dozwolone wartości są zaznaczone i niezaznaczone (ustawienie domyślne). Gdy pierwszy wiersz jako nagłówek jest niezaznaczony, zwróć uwagę na podgląd danych interfejsu użytkownika i dane wyjściowe działania wyszukiwania automatycznie generują nazwy kolumn jako Prop_{n} (począwszy od 0), działanie kopiowania wymaga jawnego mapowania ze źródła do miejsca docelowego i lokalizuje kolumny według porządkowych (począwszy od 1).
Wartość null: określa ciąg reprezentujący wartość null. Wartość domyślna to pusty ciąg.
W obszarze Ustawienia zaawansowane na karcie Źródło uwidocznione są inne właściwości powiązane z formatem tekstu rozdzielanego.
Rozdzielany format tekstu jako miejsce docelowe
Po wybraniu pozycji Ustawienia w sekcji Format pliku w oknie dialogowym Ustawienia formatu pliku zostaną wyświetlone następujące właściwości.
Typ kompresji: koder koder kompresji używany do pisania rozdzielonych plików tekstowych. Możesz wybrać typ Brak, bzip2, gzip, deflate, ZipDeflate, TarGzip lub tar na liście rozwijanej.
Poziom kompresji: określ współczynnik kompresji po wybraniu typu kompresji. Możesz wybrać jedną z opcji Optymalna lub Najszybsza.
- Najszybsza: operacja kompresji powinna zostać ukończona tak szybko, jak to możliwe, nawet jeśli wynikowy plik nie jest optymalnie skompresowany.
- Optymalna: operacja kompresji powinna być optymalnie skompresowana, nawet jeśli operacja trwa dłużej. Aby uzyskać więcej informacji, zobacz Temat Poziom kompresji.
Ogranicznik kolumn: znaki używane do oddzielania kolumn w pliku. Wartość domyślna to przecinek (
,).Ogranicznik wierszy: znak używany do oddzielania wierszy w pliku. Dozwolony jest tylko jeden znak. Wartość domyślna to źródło danych
\nwiersza .Kodowanie: typ kodowania używany do pisania plików testowych. Wartość domyślna to UTF-8.
Znak ucieczki: pojedynczy znak ucieczki cudzysłowów wewnątrz wartości cudzysłowu. Wartość domyślna to ukośnik
\odwrotny. Gdy znak ucieczki jest zdefiniowany jako pusty ciąg, znak cudzysłowu musi być również ustawiony jako pusty ciąg, w tym przypadku upewnij się, że wszystkie wartości kolumn nie zawierają ograniczników.Znak cudzysłowu: pojedynczy znak cudzysłowu wartości kolumn, jeśli zawiera ogranicznik kolumn. Wartość domyślna to podwójne cudzysłowy
". Gdy znak cudzysłowu jest zdefiniowany jako pusty ciąg, oznacza to, że nie ma cudzysłowu, a wartość kolumny nie jest cytowana, a znak ucieczki jest używany do ucieczki ogranicznika kolumny i samego siebie.Pierwszy wiersz jako nagłówek: określa, czy należy traktować/tworzyć pierwszy wiersz jako wiersz nagłówka z nazwami kolumn. Dozwolone wartości są zaznaczone i niezaznaczone (ustawienie domyślne). Gdy pierwszy wiersz jako nagłówek jest niezaznaczony, zwróć uwagę na podgląd danych interfejsu użytkownika i dane wyjściowe działania wyszukiwania automatycznie generują nazwy kolumn jako Prop_{n} (począwszy od 0), działanie kopiowania wymaga jawnego mapowania ze źródła do miejsca docelowego i lokalizuje kolumny według porządkowych (począwszy od 1).
Wartość null: określa ciąg reprezentujący wartość null. Wartość domyślna to pusty ciąg.
W obszarze Ustawienia zaawansowane na karcie Miejsce docelowe są wyświetlane dalsze właściwości powiązane z formatem tekstu rozdzielanego.
Zacytuj cały tekst: Ujęć wszystkie wartości w cudzysłowie.
Rozszerzenie pliku: rozszerzenie pliku używane do nazywania plików wyjściowych, na przykład
.csv,.txt.Maksymalna liczba wierszy na plik: podczas zapisywania danych w folderze można zapisać w wielu plikach i określić maksymalną liczbę wierszy na plik.
Prefiks nazwy pliku: ma zastosowanie, gdy skonfigurowano maksymalną liczbę wierszy na plik . Określ prefiks nazwy pliku podczas zapisywania danych w wielu plikach, co spowodowało następujący wzorzec:
<fileNamePrefix>_00000.<fileExtension>. Jeśli nie zostanie określony, prefiks nazwy pliku zostanie wygenerowany automatycznie. Ta właściwość nie ma zastosowania, gdy źródło jest magazynem opartym na plikach lub włączoną opcją partycji magazynu danych.
Podsumowanie tabeli
Rozdzielany tekst jako źródło
Poniższe właściwości są obsługiwane w sekcji Źródło działania kopiowania w przypadku używania formatu tekstu rozdzielanego.
| Nazwa | Opis | Wartość | Wymagane | Właściwość skryptu JSON |
|---|---|---|---|---|
| Format pliku | Format pliku, którego chcesz użyć. | Rozdzielany tekst | Tak | type (w obszarze datasetSettings):Rozdzielany tekst |
| Typ kompresji | Koder koder kompresji używany do odczytywania rozdzielonych plików tekstowych. | Wybierz spośród następujących: Brak bzip2 gzip Deflate ZipDeflate TarGzip smoła |
Nie. | type (w obszarze compression): bzip2 gzip Deflate ZipDeflate TarGzip smoła |
| Zachowaj nazwę pliku zip jako folder | Wskazuje, czy podczas kopiowania zachować nazwę źródłowego pliku zip jako strukturę folderów. Ma zastosowanie po wybraniu opcji Kompresja ZipDeflate . | Zaznaczone lub usuń zaznaczenie | Nie | preserveZipFileNameAsFolder (pod compressionProperties->type jako ZipDeflateReadSettings) |
| Zachowaj nazwę pliku kompresji jako folder | Wskazuje, czy podczas kopiowania zachować nazwę skompresowanego pliku źródłowego jako strukturę folderów. Ma zastosowanie podczas wybierania kompresji TarGzip/tar . | Zaznaczone lub usuń zaznaczenie | Nie. | preserveCompressionFileNameAsFolder (w obszarze compressionProperties->type jako TarGZipReadSettings lub TarReadSettings) |
| Poziom kompresji | Współczynnik kompresji. Dozwolone wartości są optymalne lub najszybsze. | Optymalna lub najszybsza | Nie | poziom (w obszarze compression): Najszybszy Optymalny |
| Ogranicznik kolumn | Znaki używane do oddzielania kolumn w pliku. | < ogranicznik wybranej kolumny > przecinek , (domyślnie) |
Nie. | columnDelimiter |
| Ogranicznik wierszy | Znak używany do rozdzielania wierszy w pliku. | < ogranicznik zaznaczonego wiersza > \r,\n (domyślnie) lub r\n |
Nie | rowDelimiter |
| Kodowanie | Typ kodowania używany do odczytu/zapisu plików testowych. | "UTF-8" (domyślnie),"UTF-8 bez BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM869", "IBM869"70", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1252", "WINDOWS-1252"1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | Nie | encodingName |
| Znak ucieczki | Pojedynczy znak ucieczki cudzysłowów wewnątrz cytowanej wartości. Gdy znak ucieczki jest zdefiniowany jako pusty ciąg, znak cudzysłowu musi być również ustawiony jako pusty ciąg, w tym przypadku upewnij się, że wszystkie wartości kolumn nie zawierają ograniczników. | < wybrany znak ucieczki > ukośnik \ odwrotny (domyślnie) |
Nie. | escapeChar |
| Znak cudzysłowu | Pojedynczy znak cudzysłowu wartości kolumn, jeśli zawiera ogranicznik kolumn. Gdy znak cudzysłowu jest zdefiniowany jako pusty ciąg, oznacza to, że nie ma cudzysłowu, a wartość kolumny nie jest cytowana, a znak ucieczki jest używany do ucieczki ogranicznika kolumny i samego siebie. | < wybrany znak cudzysłowu > cudzysłowy " (domyślnie) |
Nie. | quoteChar |
| Pierwszy wiersz jako nagłówek | Określa, czy pierwszy wiersz w danym arkuszu/zakresie ma być traktowany jako wiersz nagłówka z nazwami kolumn. | Wybrane lub niezaznaczone | Nie. | firstRowAsHeader: true lub false (wartość domyślna) |
| Wartość null | Określa ciąg reprezentujący wartość null. Wartość domyślna to pusty ciąg. | < reprezentacja ciągu wartości null > pusty ciąg (domyślnie) |
Nie. | nullValue |
Rozdzielany tekst jako miejsce docelowe
Następujące właściwości są obsługiwane w sekcji Miejsce docelowe działania kopiowania w przypadku używania formatu tekstu rozdzielanego.
| Nazwa | Opis | Wartość | Wymagane | Właściwość skryptu JSON |
|---|---|---|---|---|
| Format pliku | Format pliku, którego chcesz użyć. | Rozdzielany tekst | Tak | type (w obszarze datasetSettings):Rozdzielany tekst |
| Typ kompresji | Koder koder kompresji używany do pisania rozdzielonych plików tekstowych. | Wybierz spośród następujących: Brak bzip2 gzip Deflate ZipDeflate TarGzip smoła |
Nie. | type (w obszarze compression): bzip2 gzip Deflate ZipDeflate TarGzip smoła |
| Zachowaj nazwę pliku zip jako folder | Wskazuje, czy podczas kopiowania zachować nazwę źródłowego pliku zip jako strukturę folderów. | Zaznaczone lub usuń zaznaczenie | Nie | preserveZipFileNameAsFolder (pod compressionProperties->type jako ZipDeflateReadSettings) |
| Zachowaj nazwę pliku kompresji jako folder | Wskazuje, czy podczas kopiowania zachować nazwę skompresowanego pliku źródłowego jako strukturę folderów. | Zaznaczone lub usuń zaznaczenie | Nie. | preserveCompressionFileNameAsFolder (w obszarze compressionProperties->type jako TarGZipReadSettings lub TarReadSettings) |
| Poziom kompresji | Współczynnik kompresji. Dozwolone wartości są optymalne lub najszybsze. | Optymalna lub najszybsza | Nie | poziom (w obszarze compression): Najszybszy Optymalny |
| Ogranicznik kolumn | Znaki używane do oddzielania kolumn w pliku. | < ogranicznik wybranej kolumny > przecinek , (domyślnie) |
Nie. | columnDelimiter |
| Ogranicznik wierszy | Znak używany do rozdzielania wierszy w pliku. | < ogranicznik zaznaczonego wiersza > \r,\n (domyślnie) lub r\n |
Nie | rowDelimiter |
| Kodowanie | Typ kodowania używany do odczytu/zapisu plików testowych. | "UTF-8" (domyślnie),"UTF-8 bez BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM869", "IBM869"70", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1252", "WINDOWS-1252"1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | Nie | encodingName |
| Znak ucieczki | Pojedynczy znak ucieczki cudzysłowów wewnątrz cytowanej wartości. Gdy znak ucieczki jest zdefiniowany jako pusty ciąg, znak cudzysłowu musi być również ustawiony jako pusty ciąg, w tym przypadku upewnij się, że wszystkie wartości kolumn nie zawierają ograniczników. | < wybrany znak ucieczki > ukośnik \ odwrotny (domyślnie) |
Nie. | escapeChar |
| Znak cudzysłowu | Pojedynczy znak cudzysłowu wartości kolumn, jeśli zawiera ogranicznik kolumn. Gdy znak cudzysłowu jest zdefiniowany jako pusty ciąg, oznacza to, że nie ma cudzysłowu, a wartość kolumny nie jest cytowana, a znak ucieczki jest używany do ucieczki ogranicznika kolumny i samego siebie. | < wybrany znak cudzysłowu > cudzysłowy " (domyślnie) |
Nie. | quoteChar |
| Pierwszy wiersz jako nagłówek | Określa, czy pierwszy wiersz w danym arkuszu/zakresie ma być traktowany jako wiersz nagłówka z nazwami kolumn. | Wybrane lub niezaznaczone | Nie. | firstRowAsHeader: true lub false (wartość domyślna) |
| Cudzysłowuj cały tekst | Ujęć wszystkie wartości w cudzysłowie. | Wybrane (domyślne) lub niezaznaczone | Nie. | quoteAllText: true (wartość domyślna) lub fałsz |
| Formatem | Rozszerzenie pliku używane do nazywania plików wyjściowych. | < rozszerzenie pliku > .txt (domyślnie) |
Nie. | fileExtension |
| Maksymalna liczba wierszy na plik | Podczas zapisywania danych w folderze można wybrać zapisywanie w wielu plikach i określić maksymalną liczbę wierszy na plik. | < maksymalna liczba wierszy na plik > | Nie. | maxRowsPerFile |
| Prefiks nazwy pliku | Ma zastosowanie w przypadku skonfigurowania maksymalnej liczby wierszy na plik . Określ prefiks nazwy pliku podczas zapisywania danych w wielu plikach, co spowodowało następujący wzorzec: <fileNamePrefix>_00000.<fileExtension>. Jeśli nie zostanie określony, prefiks nazwy pliku zostanie wygenerowany automatycznie. Ta właściwość nie ma zastosowania, gdy źródło jest magazynem opartym na plikach lub włączoną opcją partycji magazynu danych. |
< prefiks nazwy pliku > | Nie. | fileNamePrefix |
Powiązana zawartość
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla