Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten samouczek przedstawia pełny przykład przepływu pracy analizy danych usługi Synapse w usłudze Microsoft Fabric. Używa on zarówno zasobu danych nycflights13 , jak i R, aby przewidzieć, czy samolot przybywa ponad 30 minut później. Następnie użyje wyników przewidywania do utworzenia interaktywnego pulpitu nawigacyjnego usługi Power BI.
Z tego samouczka dowiesz się, jak wykonywać następujące działania:
Użyj pakietów tidymodels
- Przepisy
- pasternak
- rsample
- przepływy pracy do przetwarzania danych i trenowania modelu uczenia maszynowego
Zapisz dane wyjściowe do Lakehouse jako tabelę różnicową.
Utwórz raport wizualny Power BI do bezpośredniego dostępu do danych w tym lakehouse
Warunki wstępne
Pobierz subskrypcję usługi Microsoft Fabric . Możesz też utworzyć bezpłatne konto wersji próbnej usługi Microsoft Fabric.
Zaloguj się do usługi Microsoft Fabric.
Przełącz się na Fabric, używając przełącznika nawigacji w lewej dolnej części strony głównej.

Otwórz lub utwórz notatnik. Aby dowiedzieć się, jak to zrobić, zobacz Jak używać notesów usługi Microsoft Fabric.
Ustaw opcję języka na SparkR (R), aby zmienić język podstawowy.
Dołącz notatnik do lakehouse. Po lewej stronie wybierz opcję Dodaj, aby dodać istniejący lakehouse lub utworzyć nowy lakehouse.
Instalowanie pakietów
Zainstaluj pakiet nycflights13, aby użyć kodu w tym samouczku.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Eksplorowanie danych
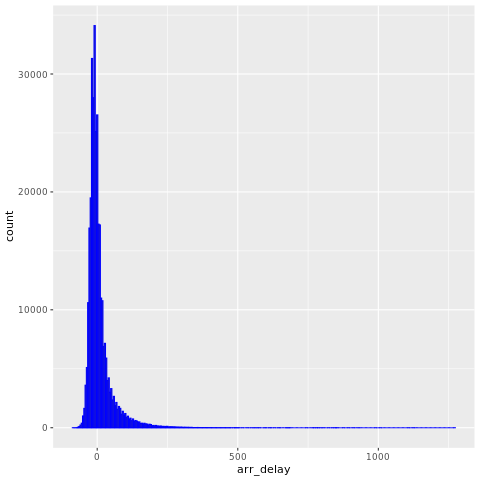
Dane nycflights13 zawierają informacje o 325 819 lotach, które przybyły w pobliżu Nowego Jorku w 2013 roku. Najpierw sprawdź rozkład opóźnień lotów. Poniższa komórka kodu generuje wykres, który pokazuje, że rozkład opóźnienia przylotu ma prawostronną asymetrię.
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
Ma długi ogon przy wysokich wartościach, jak pokazano na poniższej ilustracji.
Załaduj dane i wprowadź kilka zmian w zmiennych:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Przed utworzeniem modelu należy wziąć pod uwagę kilka określonych zmiennych, które mają znaczenie zarówno w przypadku przetwarzania wstępnego, jak i modelowania.
Zmienna arr_delay jest zmienną współczynnikową. W przypadku trenowania modelu regresji logistycznej ważne jest, aby zmienna wynikowa była zmienną czynnikową.
glimpse(flight_data)
Około 16% procent lotów z tego zestawu danych przyleciało z ponad 30-minutowym opóźnieniem.
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
Ta dest funkcja ma 104 miejsca docelowe lotów:
unique(flight_data$dest)
Istnieje 16 odrębnych przewoźników:
unique(flight_data$carrier)
Dzielenie danych
Podziel pojedynczy zestaw danych na dwa zestawy: zestaw treningowy i zestaw testowy. Zachowaj większość wierszy oryginalnego zestawu danych (jako losowo wybrany podzestaw) w obrębie zestawu danych treningowego. Użyj zestawu danych trenowania, aby dopasować model i użyć zestawu danych testowego do mierzenia wydajności modelu.
Użyj pakietu rsample, aby utworzyć obiekt zawierający informacje o sposobie dzielenia danych. Następnie użyj dwóch kolejnych funkcji rsample, aby utworzyć ramki danych dla zestawów trenowania i testowania:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Utwórz przepis i role
Utwórz przepis na prosty model regresji logistycznej. Przed rozpoczęciem trenowania modelu użyj przepisu, aby utworzyć nowe czynniki prognostyczne i przeprowadzić wstępne przetwarzanie wymagane przez model.
update_role() Użyj funkcji z rolą niestandardową o nazwie ID, aby przepisy wiedziały, że flight i time_hour są zmiennymi. Rola może mieć dowolną wartość znakową. Formuła zawiera wszystkie zmienne w zestawie treningowym jako predyktory, z wyjątkiem arr_delay. Przepis zachowuje te dwie zmienne identyfikacyjne, ale nie używa ich ani jako celów, ani jako predyktorów.
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Aby wyświetlić bieżący zestaw zmiennych i ról, użyj funkcji summary():
summary(flights_rec)
Tworzenie funkcji
Tworzenie cech może poprawić Twój model. Data lotu może mieć rozsądny wpływ na prawdopodobieństwo późnego przyjazdu:
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Może to pomóc w dodaniu terminów modelu pochodzących z daty, które mają potencjalne znaczenie dla modelu. Wyprowadź następujące istotne cechy z pojedynczej zmiennej daty.
- Dzień tygodnia
- Miesiąc
- Czy data odpowiada świętu czy nie
Dodaj trzy kroki do swojego przepisu:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Dopasuj model za pomocą schematu
Użyj regresji logistycznej, aby modelować dane lotu. Najpierw utwórz specyfikację modelu przy użyciu pakietu parsnip:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
Użyj pakietu workflows, aby powiązać model parsnip (lr_mod) z przepisem (flights_rec):
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Trenowanie modelu
Ta funkcja może przygotować przepis i wytrenować model z wynikowych predyktorów:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Użyj funkcji pomocnika xtract_fit_parsnip() i extract_recipe(), aby wyodrębnić obiekty modelu lub przepisu z przepływu pracy. W tym przykładzie pobierz dopasowany obiekt modelu, a następnie użyj funkcji broom::tidy(), aby uzyskać uporządkowaną tibble współczynników modelu.
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Przewidywanie wyników
Pojedyncze wywołanie do predict() używa wytrenowanego przepływu pracy (flights_fit), by dokonywać przewidywań z niewidocznymi danymi testowymi. Metoda predict() stosuje przepis do nowych danych, a następnie przekazuje wyniki do dopasowanego modelu.
predict(flights_fit, test_data)
Pobierz dane wyjściowe z predict(), aby otrzymać przewidywaną klasę: late w porównaniu do on_time. Jednak aby zapisać razem przewidywane prawdopodobieństwa klasy dla każdego lotu, użyj augment() z modelem w połączeniu z danymi testowymi.
flights_aug <-
augment(flights_fit, test_data)
Przejrzyj dane:
glimpse(flights_aug)
Ocena modelu
Mamy teraz tibble z przewidywanymi prawdopodobieństwami klas. W pierwszych kilku rzędach model prawidłowo przewidział pięć punktualnych lotów (wartości .pred_on_time są p > 0.50). Jednak potrzebujemy przewidywań dla łącznie 81 455 wierszy.
Potrzebujemy metryki, która informuje, jak dobrze model przewidział późne przybycie, w porównaniu z rzeczywistym stanem zmiennej arr_delay wyniku.
Użyj pola pod krzywą charakterystyki pracy odbiornika (AUC-ROC) jako wskaźnika. Oblicz go przy użyciu roc_curve() i roc_auc()z pakietu yardstick:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Tworzenie raportu usługi Power BI
Wynik modelu wygląda dobrze. Użyj wyników przewidywania opóźnienia lotu, aby utworzyć interaktywny pulpit nawigacyjny usługi Power BI. Na pulpicie nawigacyjnym jest wyświetlana liczba lotów według przewoźnika oraz liczba lotów według miejsca docelowego. Pulpit nawigacyjny może filtrować według wyników przewidywania opóźnień.

Uwzględnij nazwę przewoźnika i nazwę lotniska w zestawie danych wyników przewidywania:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Przejrzyj dane:
glimpse(flights_clean)
Przekonwertuj dane na ramkę danych platformy Spark:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Zapisz dane w tabeli Delta w Lakehouse.
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Użyj tabeli różnicowej, aby utworzyć model semantyczny.
W lewym okienku nawigacyjnym wybierz swój obszar roboczy, a w polu tekstowym w prawym górnym rogu wpisz nazwę lakehouse, który dołączyłeś do notesu. Poniższy zrzut ekranu przedstawia wybranie opcji Mój obszar roboczy:
Wprowadź nazwę lakehouse dołączoną do notesu. Wprowadzamy test_lakehouse1, jak pokazano na poniższym zrzucie ekranu:
W obszarze filtrowanych wyników wybierz Lakehouse, jak pokazano na poniższym zrzucie ekranu.
Wybierz pozycję Nowy model semantyczny , jak pokazano na poniższym zrzucie ekranu:
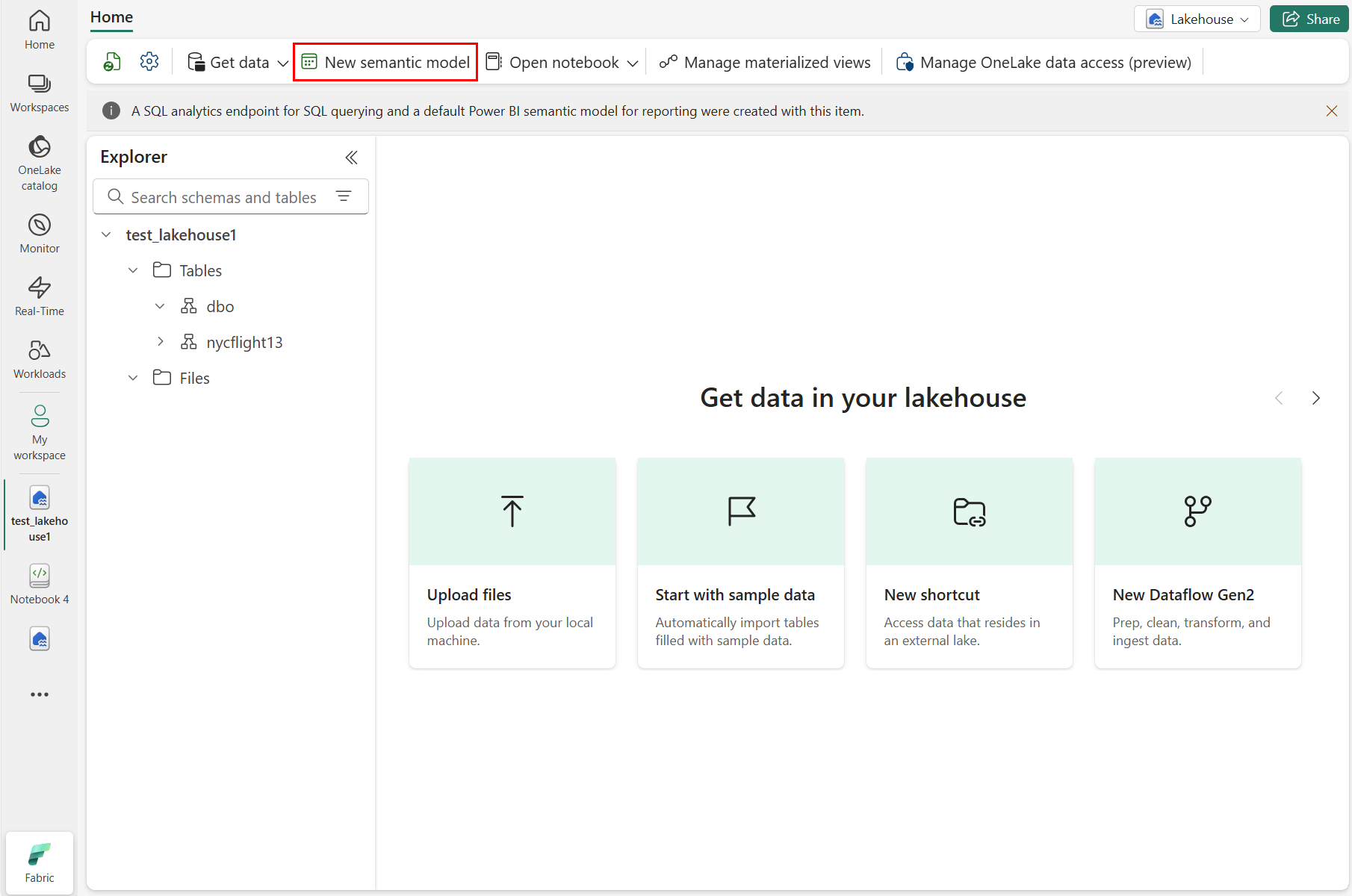
W okienku Nowy model semantyczny wprowadź nazwę nowego modelu semantycznego, wybierz obszar roboczy i wybierz tabele do użycia dla tego nowego modelu, a następnie wybierz pozycję Potwierdź, jak pokazano na poniższym zrzucie ekranu:
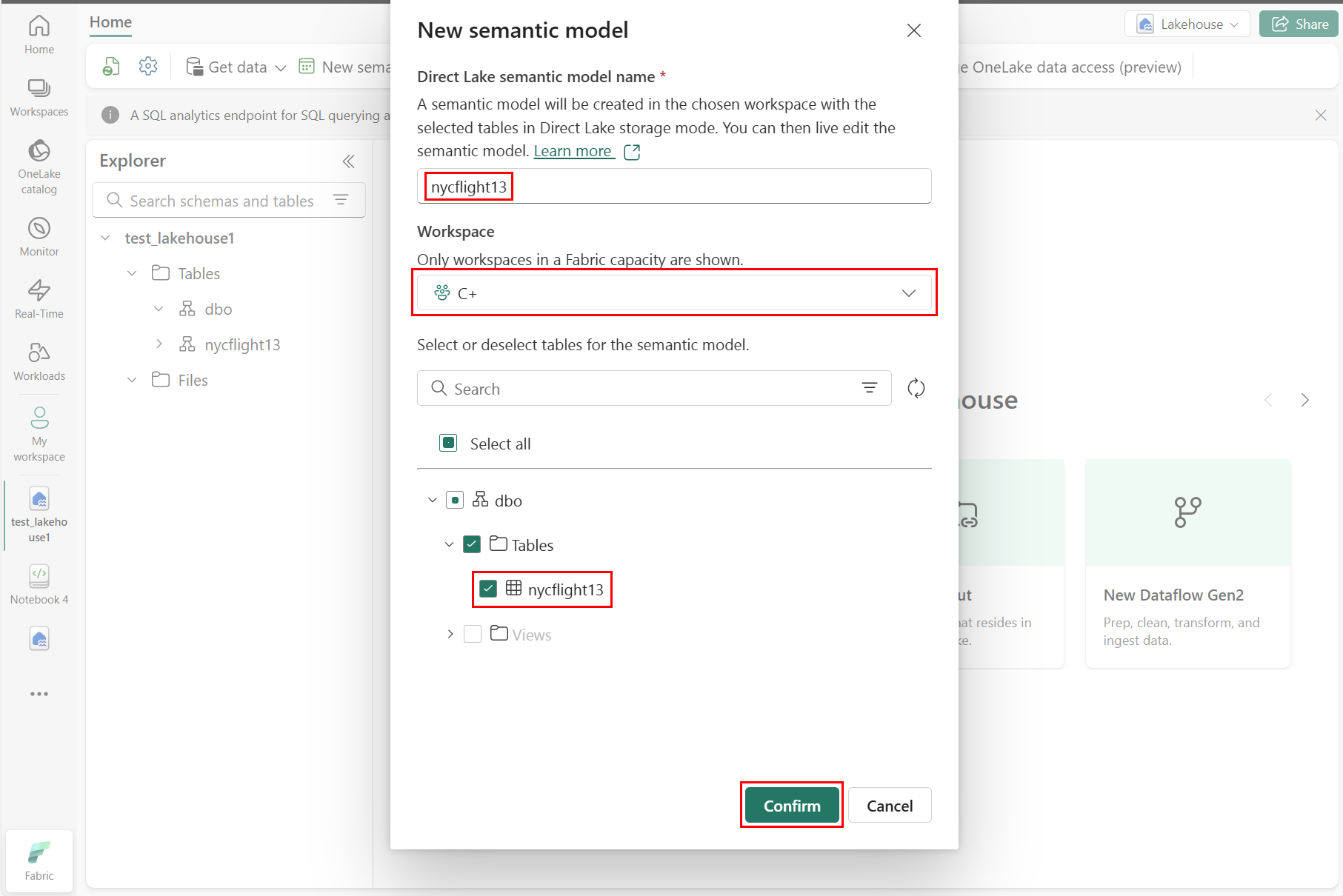
Aby utworzyć nowy raport, wybierz pozycję Utwórz nowy raport, jak pokazano na poniższym zrzucie ekranu:
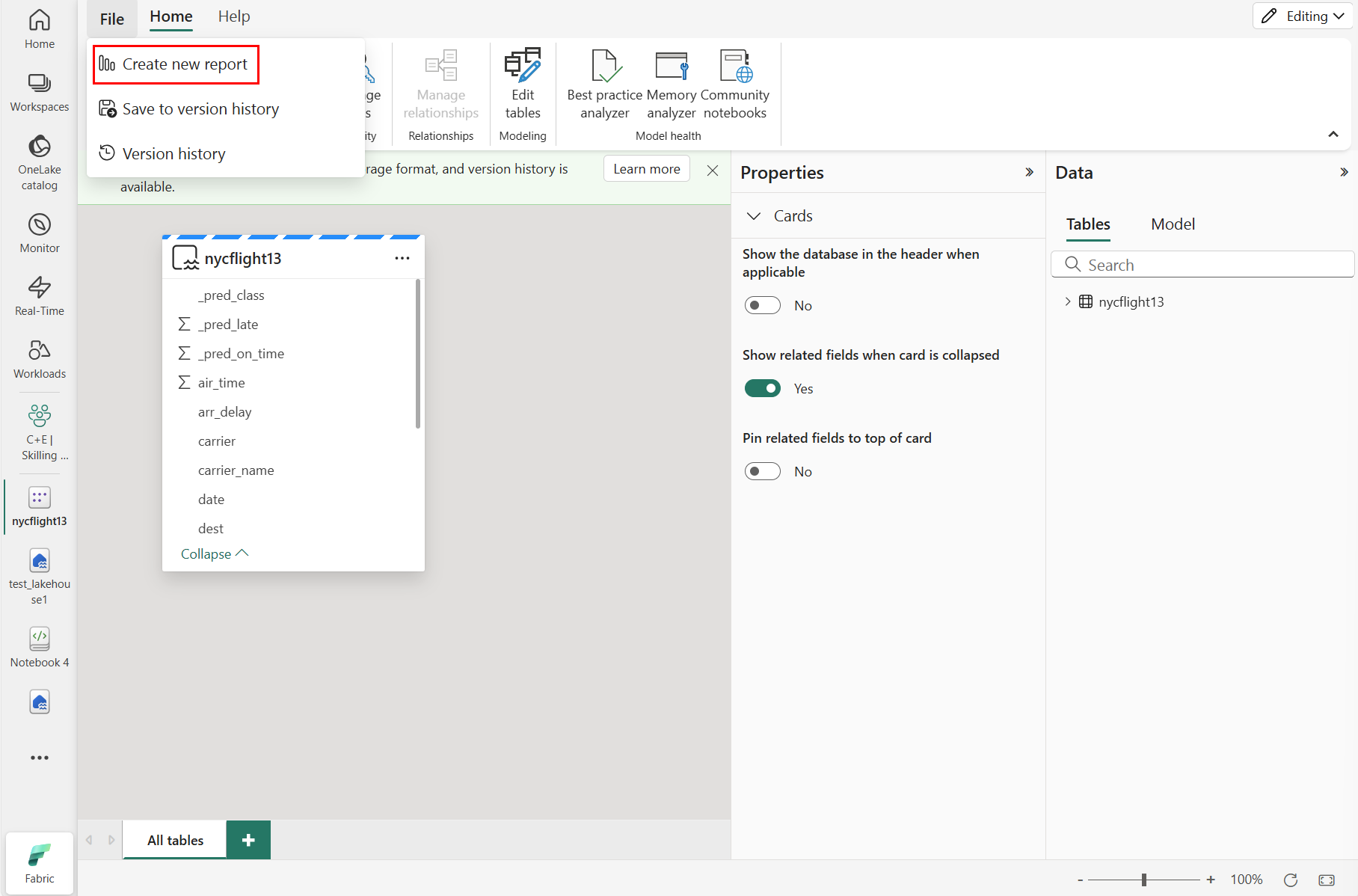
Wybierz lub przeciągnij pola z okienek Dane i Wizualizacje na kanwę raportu, aby zbudować raport.
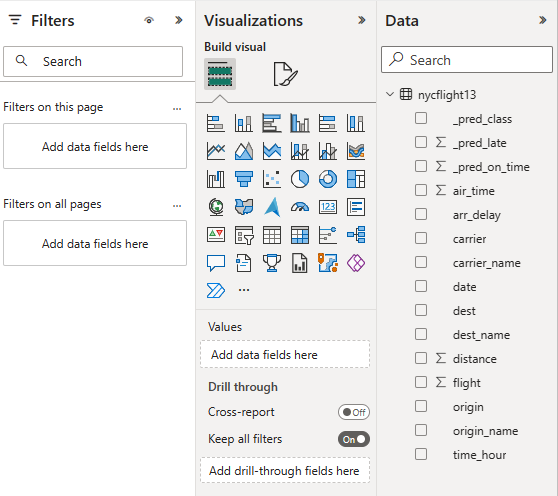






Aby utworzyć raport pokazany na początku tej sekcji, użyj tych wizualizacji i danych:
-
 Skumulowany wykres słupkowy z:
Skumulowany wykres słupkowy z: - Oś Y: carrier_name
- Oś X: flight. Wybierz liczbę do agregacji
- Legenda: origin_name
-
Skumulowany wykres słupkowy z:
- Oś Y: dest_name
- Oś X: flight. Wybierz liczbę do agregacji
- Legenda: origin_name
-
 krajalnica z:
krajalnica z: - Pole: _pred_class
-
krajalnica z:
- Pole: _pred_late
Powiązana zawartość
- Jak używać SparkR
- Jak używać interfejsu sparklyr
- Jak używać Tidyverse
- zarządzanie bibliotekami R
- Wizualizowanie danych w usłudze R
- samouczek : przewidywanie cen awokado za pomocą języka R