Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:✅ punktu końcowego analizy SQL i magazynu danych w usłudze Microsoft Fabric
Usługa Fabric Data Warehouse to relacyjny magazyn w skali przedsiębiorstwa oparty na fundamencie data lake.
- Idealne przypadki użycia magazynu danych Fabric to schematy gwiazdy lub płatka śniegu, wyselekcjonowane składnice danych firmowych, zarządzane modele semantyczne do inteligencji biznesowej.
- Dane magazynu danych Fabric, podobnie jak wszystkie dane Fabric, są przechowywane w tabelach Delta, które są plikami Parquet z transakcyjnym dziennikiem w oparciu o pliki. Oparty na formacie otwartych danych Fabric magazyn umożliwia udostępnianie i współpracę między inżynierami danych a użytkownikami biznesowymi bez naruszania zabezpieczeń lub zarządzania.
- Usługa Fabric Data Warehouse jest opracowywana głównie przy użyciu języka T-SQL i udostępnia duży obszar powierzchni oparty na aparacie bazy danych SQL, z pełną obsługą transakcji ACID w wielu tabelach, zmaterializowanymi widokami, funkcjami i procedurami składowanymi.
- Zbiorcze ładowanie Fabric Data Warehouse można przeprowadzić za pośrednictwem połączeń T-SQL i TDS lub platformy Spark, a dane będą zapisywane zbiorczo bezpośrednio w tabelach Delta.
- Łatwe w użyciu środowisko SaaS jest również ściśle zintegrowane z usługą Power BI w celu łatwej analizy i raportowania.
Klienci magazynu danych korzystają z następujących korzyści:
- Zapytania obejmujące wiele baz danych mogą używać wielu źródeł danych do szybkiego wglądu w szczegółowe dane z zerowymi duplikacjami danych.
-
Łatwe pozyskiwanie, ładowanie i przekształcanie danych na dużą skalę za pośrednictwem potoków, przepływów danych, zapytań między bazami danych lub
COPY INTOpolecenia T-SQL. - Autonomiczne zarządzanie obciążeniami z wiodącym w branży aparatem przetwarzania zapytań rozproszonych nie oznacza, że żadne pokrętła nie zwracają się do osiągnięcia najlepszej wydajności klasy.
- Skalowanie niemal natychmiast w celu spełnienia wymagań biznesowych. Przechowywanie zasobów i obliczenia są oddzielone.
- Dane są automatycznie replikowane do plików OneLake w celu uzyskania dostępu zewnętrznego.
- Utworzony dla dowolnego poziomu umiejętności od dewelopera obywatela do administratora bazy danych lub inżyniera danych.
Elementy magazynowania danych
Usługa Fabric Data Warehouse nie jest tradycyjną hurtownią danych przedsiębiorstwa, jest hurtownią lake, która obsługuje dwa odrębne elementy hurtowni: element hurtowni Fabric i element punktu końcowego analityki SQL. Oba są zaprojektowane specjalnie w celu zaspokojenia potrzeb biznesowych klientów, zapewniając jednocześnie najlepszą wydajność klasy, minimalizując koszty i zmniejszając nakład pracy administracyjnej.
Magazyn danych sieci szkieletowej
W obszarze roboczym usługi Microsoft Fabric magazyn sieci szkieletowej jest oznaczony jako Magazyn w kolumnie Typ . Jeśli potrzebujesz pełnej mocy i możliwości transakcyjnych (obsługa zapytań DDL i DML) magazynu danych, jest to szybkie i proste rozwiązanie.

Magazyn może być wypełniany przez jedną z obsługiwanych metod pozyskiwania danych, takich jak COPY INTO, Pipelines, Dataflows lub cross database ingestion options, np. CREATE TABLE AS SELECT (CTAS), INSERT.. WYBIERZ LUB WYBIERZ DO.
Aby rozpocząć pracę z magazynem, zobacz:
Punkt końcowy analizy SQL usługi Lakehouse
W obszarze roboczym Microsoft Fabric każdy Lakehouse ma automatycznie wygenerowany "punkt końcowy analizy SQL", który może służyć do przejścia z widoku "Lake" Lakehouse (obsługującego inżynierię danych i platformę Apache Spark) do widoku "SQL" tego samego Lakehouse w celu tworzenia widoków, funkcji, procedur składowanych i stosowania zabezpieczeń SQL.
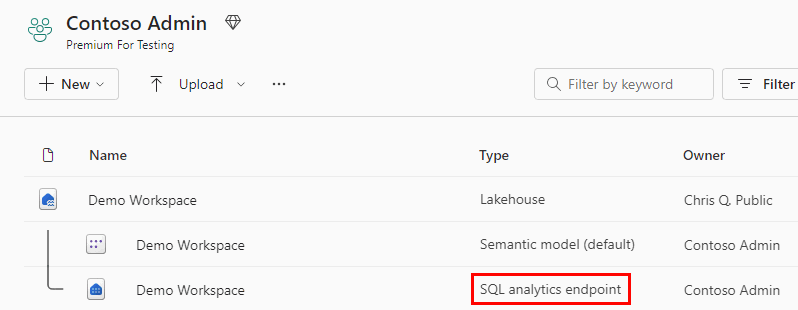
Korzystając z podobnej technologii, zarówno magazyn, baza danych SQL, jak i usługa Fabric OneLake, wszystkie automatycznie aprowizują punkt końcowy analizy SQL podczas tworzenia.
Za pomocą punktu końcowego analizy SQL polecenia języka T-SQL mogą definiować i wykonywać zapytania o obiekty danych, ale nie manipulować ani modyfikować danych. Następujące akcje można wykonać w punkcie końcowym analizy SQL:
- Wykonywanie zapytań względem tabel odwołujących się do danych w folderach usługi Delta Lake w usłudze Lake.
- Tworzenie widoków, wbudowanych funkcji TVF i procedur w celu hermetyzacji semantyki i logiki biznesowej w języku T-SQL.
- Zarządzanie uprawnieniami do obiektów. Aby uzyskać więcej informacji na temat zabezpieczeń w punkcie końcowym analizy SQL, zobacz Zabezpieczenia usługi OneLake dla punktów końcowych analizy SQL.
Aby rozpocząć pracę z punktem końcowym analizy SQL, zobacz:
- Lepsze w połączeniu: połączenie magazynu danych i jeziora danych w usłudze Microsoft Fabric
- Zagadnienia dotyczące wydajności punktu końcowego analizy SQL
- Wykonywanie zapytań względem punktu końcowego analizy SQL lub magazynu w usłudze Microsoft Fabric
Magazyn lub jezioro
Podczas podejmowania decyzji dotyczących korzystania z magazynu lub magazynu typu lakehouse należy wziąć pod uwagę konkretne potrzeby i kontekst wymagań związanych z zarządzaniem danymi i analizą.
Wybierz magazyn danych, gdy potrzebujesz rozwiązania w skali przedsiębiorstwa z otwartym standardowym formatem, bez wydajności pokrętła i minimalnej konfiguracji. Najlepiej nadaje się do obsługi częściowo ustrukturyzowanych i ustrukturyzowanych formatów danych, magazyn danych jest odpowiedni zarówno dla początkujących, jak i doświadczonych specjalistów ds. danych, oferując proste i intuicyjne środowiska.
Wybierz usługę Lakehouse , gdy potrzebujesz dużego repozytorium wysoce nieustrukturyzowanych danych ze źródeł heterogenicznych i chcesz użyć platformy Spark jako podstawowego narzędzia programistycznego. Działając jako "lekki" magazyn danych, zawsze masz możliwość używania punktu końcowego analizy SQL i narzędzi T-SQL do dostarczania scenariuszy raportowania i analizy danych w usłudze Lakehouse.
Zawsze masz możliwość dodania jednego lub drugiego w późniejszym momencie, jeśli potrzeby biznesowe zmienią się i niezależnie od tego, gdzie się rozpoczniesz, zarówno magazyn, jak i lakehouse używają tego samego zaawansowanego aparatu SQL dla wszystkich zapytań T-SQL.
Aby uzyskać bardziej szczegółowe wskazówki dotyczące podejmowania decyzji, zobacz Przewodnik po decyzjach usługi Microsoft Fabric: Wybieranie między magazynem i usługą Lakehouse.
Migration
Użyj Fabric Migration Assistant for Data Warehouse, aby przeprowadzić migrację z platform Azure Synapse Analytics, SQL Server i innych platform baz danych SQL. Zapoznaj się z artykułem Metody planowania migracji i migracji dla dedykowanych pul SQL usługi Azure Synapse Analytics w usłudze Fabric Data Warehouse.
Aby uzyskać wskazówki dotyczące migracji w usłudze Microsoft Fabric, zapoznaj się z narzędziami i linkami w temacie Omówienie migracji usługi Microsoft Fabric.
Powiązana zawartość
- Lepsze razem: jezioro i magazyn
- Tworzenie magazynu w usłudze Microsoft Fabric
- Utwórz lakehouse w usłudze Microsoft Fabric
- Tworzenie raportów dotyczących magazynowania danych w usłudze Microsoft Fabric
- Kontrola wersji za pomocą Warehouse (wersja próbna)
- Zabezpieczenia usługi OneLake dla punktów końcowych analizy SQL