Instrukcje: uzyskiwanie dostępu do dublowanych danych usługi Azure Cosmos DB w usłudze Lakehouse i notesów z usługi Microsoft Fabric (wersja zapoznawcza)
Z tego przewodnika dowiesz się, jak uzyskać dostęp do dublowanych danych usługi Azure Cosmos DB w usłudze Lakehouse i notesach z usługi Microsoft Fabric (wersja zapoznawcza).
Ważne
Dublowanie dla usługi Azure Cosmos DB jest obecnie dostępne w wersji zapoznawczej. Obciążenia produkcyjne nie są obsługiwane w wersji zapoznawczej. Obecnie obsługiwane są tylko konta usługi Azure Cosmos DB for NoSQL.
Wymagania wstępne
- Istniejące konto usługi Azure Cosmos DB for NoSQL.
- Jeśli nie masz subskrypcji platformy Azure, wypróbuj bezpłatnie usługę Azure Cosmos DB dla noSQL.
- Jeśli masz istniejącą subskrypcję platformy Azure, utwórz nowe konto usługi Azure Cosmos DB for NoSQL.
- Istniejąca pojemność sieci szkieletowej. Jeśli nie masz istniejącej pojemności, uruchom wersję próbną usługi Fabric.
- Włącz dublowanie w dzierżawie sieci szkieletowej lub obszarze roboczym. Jeśli ta funkcja nie jest jeszcze włączona, włącz dublowanie w dzierżawie sieci szkieletowej.
- Konto usługi Azure Cosmos DB for NoSQL musi być skonfigurowane pod kątem dublowania sieci szkieletowej. Aby uzyskać więcej informacji, zobacz wymagania dotyczące konta.
Napiwek
W publicznej wersji zapoznawczej zaleca się użycie kopii testowej lub deweloperskiej istniejących danych usługi Azure Cosmos DB, które można szybko odzyskać z kopii zapasowej.
Konfigurowanie dublowania i wymagań wstępnych
Konfigurowanie dublowania dla bazy danych Azure Cosmos DB for NoSQL. Jeśli nie masz pewności, jak skonfigurować dublowanie, zapoznaj się z samouczkiem dotyczącym konfigurowania dublowanej bazy danych.
Przejdź do portalu sieci szkieletowej.
Utwórz nowe połączenie i dublowaną bazę danych przy użyciu poświadczeń konta usługi Azure Cosmos DB.
Poczekaj, aż replikacja zakończy początkową migawkę danych.
Dostęp do danych dublowanych w usłudze Lakehouse i notesach
Użyj usługi Lakehouse, aby jeszcze bardziej rozszerzyć liczbę narzędzi, których można użyć do analizowania danych dublowanych w usłudze Azure Cosmos DB for NoSQL. W tym miejscu użyjesz usługi Lakehouse do utworzenia notesu platformy Spark w celu wykonywania zapytań dotyczących danych.
Przejdź ponownie do strony głównej portalu sieci szkieletowej.
W menu nawigacji wybierz Utwórz.
Wybierz pozycję Utwórz, znajdź sekcję inżynierowie danych ing, a następnie wybierz pozycję Lakehouse.
Podaj nazwę usługi Lakehouse, a następnie wybierz pozycję Utwórz.
Teraz wybierz pozycję Pobierz dane, a następnie pozycję Nowy skrót. Z listy opcji skrótów wybierz pozycję Microsoft OneLake.
Wybierz dublowaną bazę danych Azure Cosmos DB for NoSQL z listy dublowanych baz danych w obszarze roboczym Sieć szkieletowa. Wybierz tabele do użycia z usługą Lakehouse, wybierz pozycję Dalej, a następnie wybierz pozycję Utwórz.
Otwórz menu kontekstowe tabeli w usłudze Lakehouse i wybierz pozycję Nowy lub istniejący notes.
Zostanie automatycznie otwarty nowy notes i ładuje ramkę danych przy użyciu polecenia
SELECT LIMIT 1000.Uruchamianie zapytań, takich jak
SELECT *przy użyciu platformy Spark.df = spark.sql("SELECT * FROM Lakehouse.OrdersDB_customers LIMIT 1000") display(df)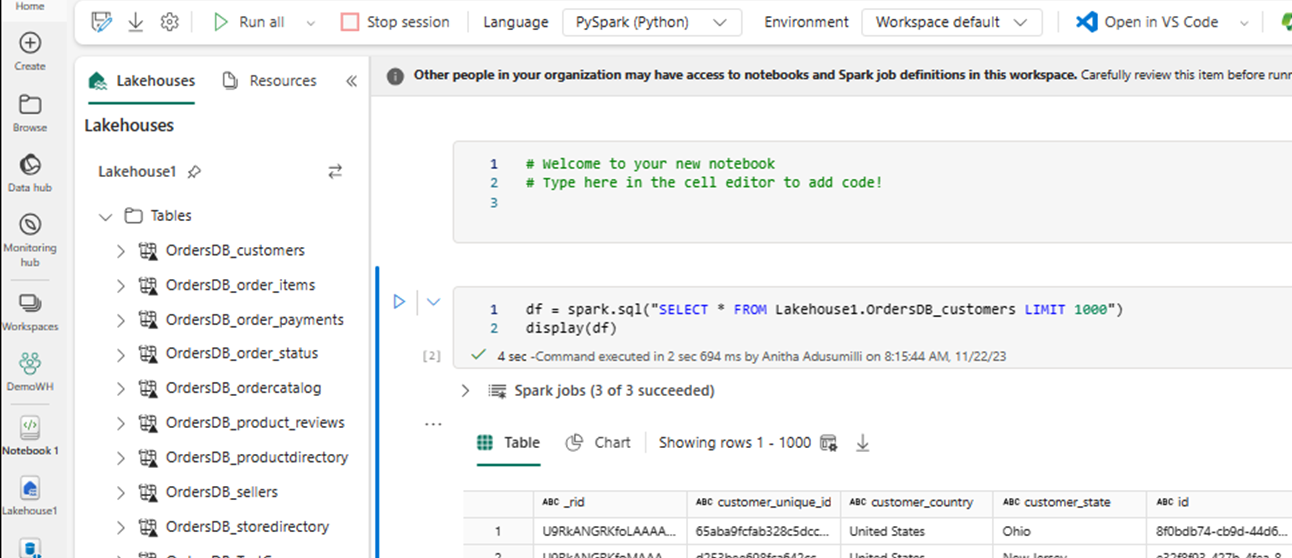
Uwaga
W tym przykładzie przyjęto założenie, że nazwa tabeli. Użyj własnej tabeli podczas pisania zapytania platformy Spark.

Zapisywanie zwrotne przy użyciu platformy Spark
Na koniec możesz użyć kodu Spark i Python, aby zapisywać dane z powrotem na źródłowym koncie usługi Azure Cosmos DB z notesów w sieci szkieletowej. Możesz to zrobić, aby zapisać wyniki analityczne w usłudze Cosmos DB, które następnie mogą być używane jako płaszczyzna obsługi dla aplikacji OLTP.
Utwórz cztery komórki kodu w notesie.
Najpierw wykonaj zapytanie dotyczące danych dublowanych.
fMirror = spark.sql("SELECT * FROM Lakehouse1.OrdersDB_ordercatalog")Napiwek
Nazwy tabel w tych przykładowych blokach kodu zakładają określony schemat danych. Możesz zastąpić to własnymi nazwami tabel i kolumn.
Teraz przekształcaj i agreguj dane.
dfCDB = dfMirror.filter(dfMirror.categoryId.isNotNull()).groupBy("categoryId").agg(max("price").alias("max_price"), max("id").alias("id"))Następnie skonfiguruj platformę Spark do zapisywania zwrotnego na koncie usługi Azure Cosmos DB for NoSQL przy użyciu poświadczeń, nazwy bazy danych i nazwy kontenera.
writeConfig = { "spark.cosmos.accountEndpoint" : "https://xxxx.documents.azure.com:443/", "spark.cosmos.accountKey" : "xxxx", "spark.cosmos.database" : "xxxx", "spark.cosmos.container" : "xxxx" }Na koniec użyj platformy Spark, aby zapisać z powrotem do źródłowej bazy danych.
dfCDB.write.mode("APPEND").format("cosmos.oltp").options(**writeConfig).save()Uruchom wszystkie komórki kodu.
Ważne
Operacje zapisu w usłudze Azure Cosmos DB będą zużywać jednostki żądań (RU).
Powiązana zawartość
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla