Samouczek: konfigurowanie dublowanych baz danych usługi Microsoft Fabric z usługi Azure Cosmos DB (wersja zapoznawcza)
W tym samouczku skonfigurujesz dublowaną bazę danych usługi Fabric z poziomu konta usługi Azure Cosmos DB for NoSQL.
Ważne
Dublowanie dla usługi Azure Cosmos DB jest obecnie dostępne w wersji zapoznawczej. Obciążenia produkcyjne nie są obsługiwane w wersji zapoznawczej. Obecnie obsługiwane są tylko konta usługi Azure Cosmos DB for NoSQL.
Wymagania wstępne
- Istniejące konto usługi Azure Cosmos DB for NoSQL.
- Jeśli nie masz subskrypcji platformy Azure, wypróbuj bezpłatnie usługę Azure Cosmos DB dla noSQL.
- Jeśli masz istniejącą subskrypcję platformy Azure, utwórz nowe konto usługi Azure Cosmos DB for NoSQL.
- Istniejąca pojemność sieci szkieletowej. Jeśli nie masz istniejącej pojemności, uruchom wersję próbną usługi Fabric. Dublowanie może nie być dostępne w niektórych regionach sieci szkieletowej. Aby uzyskać więcej informacji, zobacz obsługiwane regiony.
- Włącz dublowanie w dzierżawie sieci szkieletowej lub obszarze roboczym. Jeśli ta funkcja nie jest jeszcze włączona, włącz dublowanie w dzierżawie sieci szkieletowej.
- Jeśli nie widzisz funkcji dublowania w obszarze roboczym lub dzierżawie sieci szkieletowej, administrator organizacji musi włączyć w ustawieniach administratora.
Napiwek
W publicznej wersji zapoznawczej zaleca się użycie kopii testowej lub deweloperskiej istniejących danych usługi Azure Cosmos DB, które można szybko odzyskać z kopii zapasowej.
Konfigurowanie konta usługi Azure Cosmos DB
Najpierw upewnij się, że źródłowe konto usługi Azure Cosmos DB jest poprawnie skonfigurowane do użycia z dublowaniem sieci szkieletowej.
Przejdź do konta usługi Azure Cosmos DB w witrynie Azure Portal.
Upewnij się, że włączono ciągłą kopię zapasową. Jeśli nie jest włączona, postępuj zgodnie z przewodnikiem migracji istniejącego konta usługi Azure Cosmos DB do ciągłej kopii zapasowej, aby włączyć ciągłą kopię zapasową . Ta funkcja może nie być dostępna w niektórych scenariuszach. Aby uzyskać więcej informacji, zobacz ograniczenia bazy danych i konta.
Upewnij się, że opcje sieci są ustawione na dostęp do sieci publicznej dla wszystkich sieci. Jeśli nie, postępuj zgodnie z przewodnikiem konfigurowania dostępu sieciowego do konta usługi Azure Cosmos DB.
Tworzenie dublowanej bazy danych
Teraz utwórz dublowaną bazę danych, która jest obiektem docelowym replikowanych danych. Aby uzyskać więcej informacji, zobacz Czego można oczekiwać od dublowania.
Przejdź do strony głównej portalu sieci szkieletowej.
Otwórz istniejący obszar roboczy lub utwórz nowy obszar roboczy.
W menu nawigacji wybierz Utwórz.
Wybierz pozycję Utwórz, znajdź sekcję Magazyn danych, a następnie wybierz pozycję Dublowana usługa Azure Cosmos DB (wersja zapoznawcza).
Podaj nazwę dublowanej bazy danych, a następnie wybierz pozycję Utwórz.
Połączenie do źródłowej bazy danych
Następnie połącz źródłową bazę danych z dublowaną bazą danych.
W sekcji Nowe połączenie wybierz pozycję Azure Cosmos DB for NoSQL.
Podaj poświadczenia dla konta usługi Azure Cosmos DB for NoSQL, w tym następujące elementy:
Wartość Punkt końcowy usługi Azure Cosmos DB Punkt końcowy adresu URL dla konta źródłowego. Nazwa połączenia Unikatowa nazwa połączenia. Rodzaj uwierzytelniania Wybierz pozycję Klucz konta. Klucz konta Klucz odczytu i zapisu dla konta źródłowego. 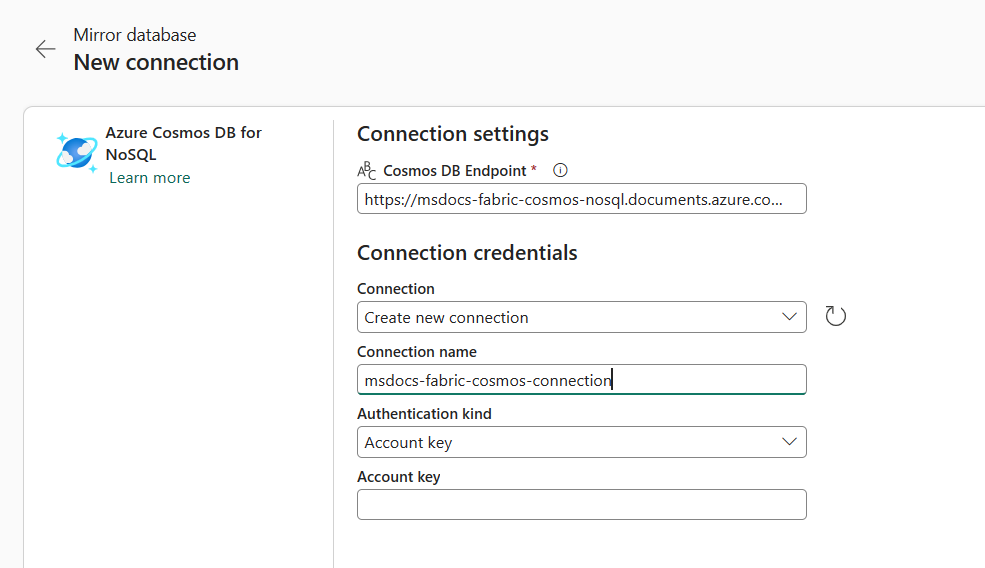
Wybierz pozycję Połącz. Następnie wybierz bazę danych do dublowania.
Uwaga
Wszystkie kontenery w bazie danych są dublowane.

Rozpoczynanie procesu dublowania
Wybierz pozycję Dublowanie bazy danych. Dublowanie zaczyna się teraz.
Poczekaj od dwóch do pięciu minut. Następnie wybierz pozycję Monitoruj replikację , aby wyświetlić stan akcji replikacji.
Po kilku minutach stan powinien ulec zmianie na Uruchomiono, co oznacza, że kontenery są synchronizowane.
Napiwek
Jeśli nie możesz znaleźć kontenerów i odpowiedniego stanu replikacji, zaczekaj kilka sekund, a następnie odśwież okienko. W rzadkich przypadkach mogą pojawić się komunikaty o błędach przejściowych. Można je bezpiecznie zignorować i kontynuować odświeżanie.
Po zakończeniu dublowania początkowej kopii kontenerów data zostanie wyświetlona w kolumnie ostatniego odświeżania . Jeśli dane zostały pomyślnie zreplikowane, łączna kolumna wierszy będzie zawierać liczbę replikowanych elementów.
Monitorowanie dublowania sieci szkieletowej
Teraz, gdy dane są uruchomione, istnieją różne scenariusze analityczne dostępne we wszystkich sieciach szkieletowych.
Po skonfigurowaniu dublowania sieci szkieletowej nastąpi automatyczne przejście do okienka Stan replikacji.
W tym miejscu monitoruj bieżący stan replikacji. Aby uzyskać więcej informacji i szczegółowe informacje na temat stanów replikacji, zobacz Monitorowanie replikacji dublowania sieci szkieletowej.
Wykonywanie zapytań względem źródłowej bazy danych z sieci szkieletowej
Użyj portalu sieci szkieletowej, aby eksplorować dane, które już istnieją na koncie usługi Azure Cosmos DB, odpytując źródłową bazę danych Cosmos DB.
Przejdź do dublowanej bazy danych w portalu sieci szkieletowej.
Wybierz pozycję Widok, a następnie źródłową bazę danych. Ta akcja powoduje otwarcie eksploratora danych usługi Azure Cosmos DB z widokiem tylko do odczytu źródłowej bazy danych.
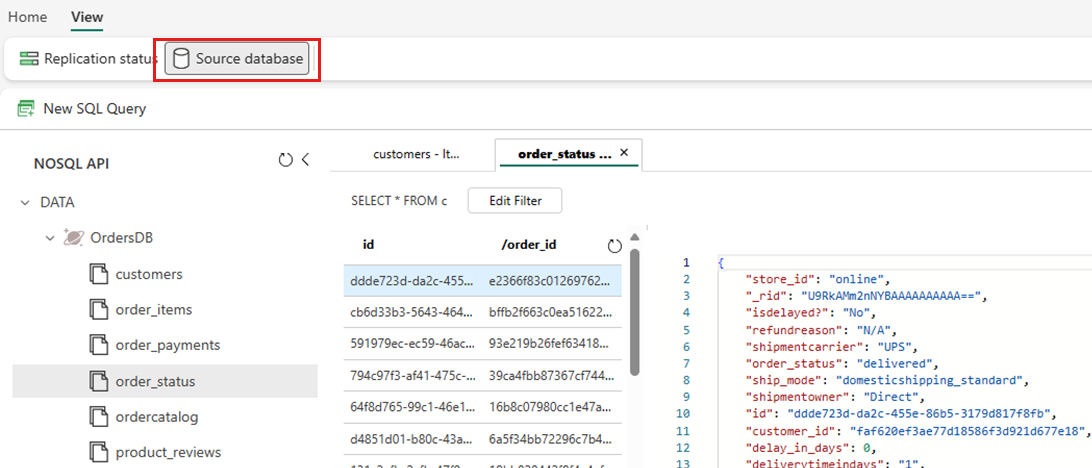
Wybierz kontener, a następnie otwórz menu kontekstowe i wybierz pozycję Nowe zapytanie SQL.
Uruchom dowolne zapytanie. Na przykład użyj polecenia
SELECT COUNT(1) FROM container, aby zliczyć liczbę elementów w kontenerze.Uwaga
Wszystkie operacje odczytu w źródłowej bazie danych są kierowane do platformy Azure i będą zużywać jednostki żądań przydzielone na koncie.

Analizowanie docelowej dublowanej bazy danych
Teraz użyj języka T-SQL, aby wysłać zapytanie do danych NoSQL, które są teraz przechowywane w usłudze Fabric OneLake.
Przejdź do dublowanej bazy danych w portalu sieci szkieletowej.
Przełącz się z dublowanej usługi Azure Cosmos DB do punktu końcowego analizy SQL.
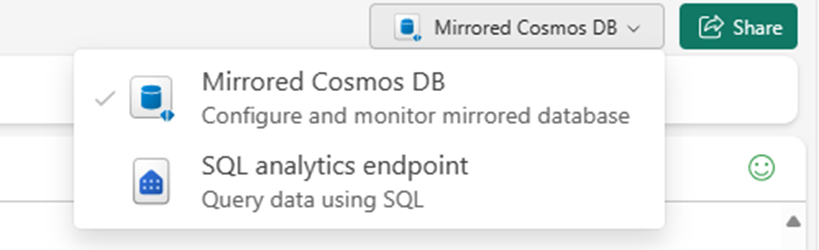
Każdy kontener w źródłowej bazie danych powinien być reprezentowany w punkcie końcowym analizy SQL jako tabeli magazynu.
Wybierz dowolną tabelę, otwórz menu kontekstowe, a następnie wybierz pozycję Nowe zapytanie SQL, a na koniec wybierz pozycję Wybierz 100 pierwszych.
Zapytanie wykonuje i zwraca 100 rekordów w wybranej tabeli.
Otwórz menu kontekstowe dla tej samej tabeli i wybierz pozycję Nowe zapytanie SQL. Napisz przykładowe zapytanie, które używa agregacji, takich jak
SUM,COUNT,MINlubMAX. Połącz wiele tabel w magazynie, aby wykonać zapytanie w wielu kontenerach.Uwaga
Na przykład to zapytanie będzie wykonywane w wielu kontenerach:
SELECT d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type], sum(o.[price]) as price, sum(o.[freight_value]) freight_value FROM [dbo].[products] p INNER JOIN [dbo].[OrdersDB_order_payments] p on o.[order_id] = p.[order_id] INNER JOIN [dbo].[OrdersDB_order_status] t ON o.[order_id] = t.[order_id] INNER JOIN [dbo].[OrdersDB_customers] c on t.[customer_id] = c.[customer_id] INNER JOIN [dbo].[OrdersDB_productdirectory] d ON o.product_id = d.product_id INNER JOIN [dbo].[OrdersDB_sellers] s on o.seller_id = s.seller_id GROUP BY d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type]W tym przykładzie przyjęto założenie, że nazwa tabeli i kolumn. Użyj własnej tabeli i kolumn podczas pisania zapytania SQL.
Wybierz zapytanie, a następnie wybierz pozycję Zapisz jako widok. Nadaj widokowi unikatową nazwę. Dostęp do tego widoku można uzyskać w dowolnym momencie w portalu sieci szkieletowej.
Wybierz zapytanie, a następnie wybierz pozycję Eksploruj te dane (wersja zapoznawcza). Ta akcja eksploruje zapytanie w usłudze Power BI bezpośrednio przy użyciu usługi Direct Lake w danych dublowanych w usłudze OneLake.
Napiwek
Opcjonalnie możesz również użyć Copilot lub innych ulepszeń do tworzenia pulpitów nawigacyjnych i raportów bez dalszego przenoszenia danych.
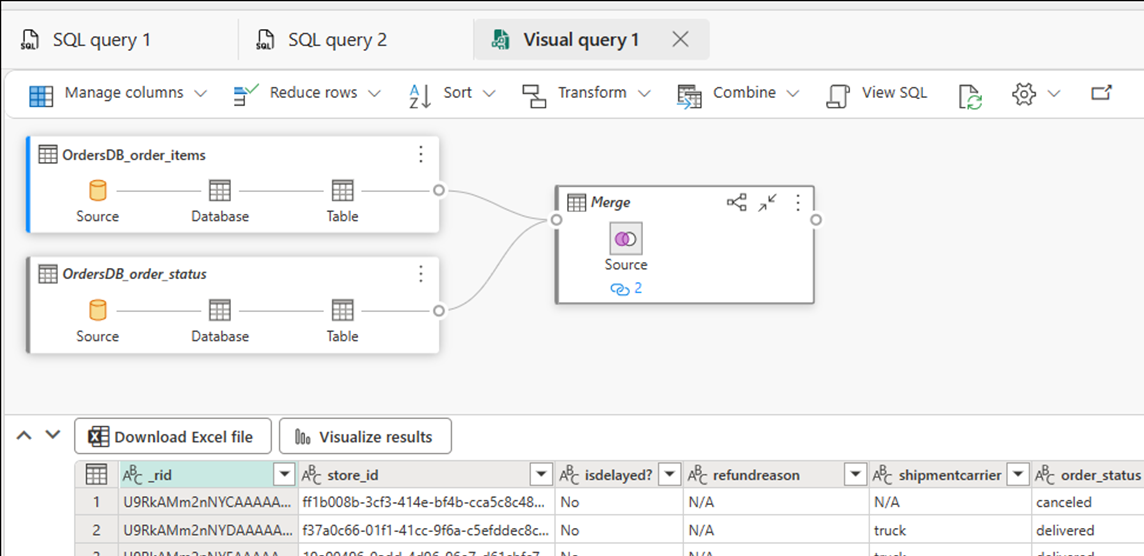
Wróć do dublowanej bazy danych w portalu sieci szkieletowej.
Wybierz pozycję Nowe zapytanie wizualne. Użyj edytora zapytań, aby tworzyć złożone zapytania.


Więcej przykładów
Dowiedz się więcej na temat uzyskiwania dostępu do danych usługi Azure Cosmos DB z dublowaniem i wykonywania zapytań w sieci szkieletowej:
- Instrukcje: wykonywanie zapytań dotyczących zagnieżdżonych danych w dublowanych bazach danych usługi Microsoft Fabric z usługi Azure Cosmos DB
- Instrukcje: uzyskiwanie dostępu do dublowanych danych usługi Azure Cosmos DB w usłudze Lakehouse i notesów z usługi Microsoft Fabric (wersja zapoznawcza)
- Instrukcje: łączenie dublowanych danych usługi Azure Cosmos DB z innymi dublowanych bazami danych w usłudze Microsoft Fabric
Powiązana zawartość
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla