Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dublowanie w sieci szkieletowej oferuje prosty sposób uniknięcia złożonych procesów ETL (wyodrębnianie, przekształcanie, ładowanie) i bezproblemową integrację istniejących danych magazynu Google BigQuery z resztą danych w sieci szkieletowej. Dane Google BigQuery można stale replikować bezpośrednio do usługi OneLake Fabric. W usłudze Fabric możesz korzystać z zaawansowanych funkcji analizy biznesowej, sztucznej inteligencji, inżynierii danych, nauki o danych i udostępniania danych.
Aby zapoznać się z samouczkiem dotyczącym konfigurowania bazy danych Google BigQuery do tworzenia kopii lustrzanych w Fabric, zobacz Tutorial: Konfigurowanie baz danych do tworzenia kopii lustrzanych w Microsoft Fabric z usługi Google BigQuery.
Ważne
Dublowanie w usłudze Google BigQuery jest teraz dostępne w wersji zapoznawczej. Obciążenia produkcyjne nie są obsługiwane w wersji zapoznawczej.
Dlaczego warto używać mirrorowania w Fabric?
Dublowanie w Microsoft Fabric eliminuje złożoność łączenia narzędzi od różnych dostawców. Nie trzeba migrować danych. Połącz się z danymi Google BigQuery niemal w czasie rzeczywistym, aby korzystać z zestawu narzędzi analitycznych Fabric. Fabric współpracuje również bezproblemowo z produktami firmy Microsoft, Google BigQuery i szeroką gamą technologii, które obsługują format tabeli Delta Lake typu open source.
Jakie doświadczenia analityczne są wbudowane?
Dublowanie tworzy dublowaną bazę danych i punkt końcowy analizy SQL w obszarze roboczym Fabric. Dublowana baza danych zarządza replikacją danych do usługi OneLake i konwersją na Parquet, umożliwiając scenariusze podrzędne, takie jak inżynieria danych, nauka o danych i nie tylko.
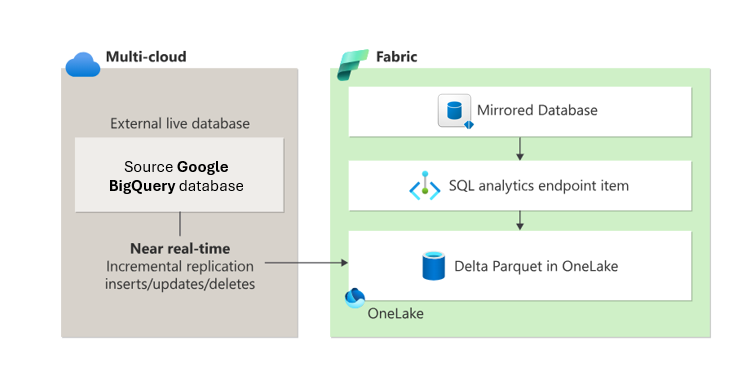
Punkt końcowy analizy SQL zapewnia środowisko analityczne tylko do odczytu na podstawie tabel delty utworzonych podczas dublowania. Możesz przeglądać tabele dublowane, tworzyć zapytania i widoki bez kodu, tworzyć widoki SQL i procedury składowane oraz wykonywać zapytania o dane między magazynami i magazynami typu lakehouse w tym samym obszarze roboczym.
Aby uzyskać więcej informacji na temat możliwości analizy i zgodnych narzędzi, zobacz Dublowanie obiektów.
Zagadnienia dotyczące zabezpieczeń
Istnieją określone wymagania dotyczące uprawnień użytkownika umożliwiające włączenie dublowania sieci szkieletowej.
Fabric udostępnia funkcje ochrony danych umożliwiające zarządzanie dostępem w ramach Microsoft Fabric. Aby uzyskać więcej informacji, zobacz dokumentację funkcji ochrony danych.
Zagadnienia dotyczące kosztów odwzorowywania w BigQuery
Zasoby obliczeniowe Fabric używane do replikowania danych do usługi Fabric OneLake są bezpłatne. Koszt przechowywania w trybie dublowania jest bezpłatny do pewnego limitu, ustalonego na podstawie pojemności. Moc obliczeniowa na potrzeby wykonywania zapytań dotyczących danych przy użyciu języka SQL, narzędzia Power BI lub platformy Spark jest naliczana według regularnych stawek.
Fabric nie nalicza opłat za ruch przychodzący danych sieciowych do usługi OneLake na potrzeby Mirroring.
Podczas dublowania danych są naliczane koszty obliczeniowe BigQuery i zapytań w chmurze Google: BigQuery Change Data Capture (CDC) wykorzystuje obliczenia BigQuery do modyfikacji wierszy, API zapisu Storage Write API do pozyskiwania danych oraz magazyn BigQuery do przechowywania danych, co wiąże się z kosztami.
Aby uzyskać więcej informacji na temat kosztów dublowania Google BigQuery, zobacz objaśnienie cennika.