Wskazówki dotyczące modelu złożonego w programie Power BI Desktop
W tym artykule elementy docelowe są modelami danych tworzącymi modele złożone usługi Power BI. Opisuje przypadki użycia modelu złożonego i zawiera wskazówki dotyczące projektowania. W szczególności wskazówki mogą pomóc w ustaleniu, czy model złożony jest odpowiedni dla danego rozwiązania. Jeśli tak jest, ten artykuł pomoże ci również zaprojektować optymalne modele złożone i raporty.
Uwaga
Wprowadzenie do modeli złożonych nie zostało omówione w tym artykule. Jeśli nie znasz całkowicie modeli złożonych, zalecamy przeczytanie artykułu Korzystanie z modeli złożonych w programie Power BI Desktop .
Ponieważ modele złożone składają się z co najmniej jednego źródła DirectQuery, ważne jest również, aby dokładnie zrozumieć relacje modelu, modele DirectQuery i wskazówki dotyczące projektowania modelu DirectQuery.
Przypadki użycia modelu złożonego
Z definicji model złożony łączy wiele grup źródłowych. Grupa źródłowa może reprezentować zaimportowane dane lub połączenie ze źródłem zapytania bezpośredniego. Źródłem zapytania bezpośredniego może być relacyjna baza danych lub inny model tabelaryczny, który może być modelem semantycznym usługi Power BI (wcześniej znanym jako zestaw danych) lub modelem tabelarycznym usług Analysis Services. Gdy model tabelaryczny łączy się z innym modelem tabelarycznym, jest znany jako łańcuch. Aby uzyskać więcej informacji, zobacz Using DirectQuery for Power BI semantic models and Analysis Services (Używanie trybu DirectQuery dla modeli semantycznych usługi Power BI i usług Analysis Services).
Uwaga
Gdy model łączy się z modelem tabelarycznym, ale nie rozszerza go dodatkowymi danymi, nie jest to model złożony. W takim przypadku jest to model DirectQuery, który łączy się z modelem zdalnym — dlatego składa się tylko z jednej grupy źródłowej. Możesz utworzyć ten typ modelu, aby zmodyfikować właściwości obiektu modelu źródłowego, takie jak nazwa tabeli, kolejność sortowania kolumn lub ciąg formatu.
Połączenie modeli tabelarycznych jest szczególnie istotne podczas rozszerzania modelu semantycznego przedsiębiorstwa (gdy jest to model semantyczny usługi Power BI lub model usług Analysis Services). Semantyczny model przedsiębiorstwa ma podstawowe znaczenie dla opracowywania i działania magazynu danych. Zapewnia warstwę abstrakcji danych w magazynie danych, aby przedstawić definicje biznesowe i terminologię. Jest on często używany jako związek między fizycznymi modelami danych i narzędziami raportowania, takimi jak usługa Power BI. W większości organizacji jest ona zarządzana przez centralny zespół i dlatego jest opisana jako przedsiębiorstwo. Aby uzyskać więcej informacji, zobacz scenariusz użycia analizy biznesowej przedsiębiorstwa.
W poniższych sytuacjach można rozważyć utworzenie modelu złożonego.
- Model może być modelem DirectQuery i chcesz zwiększyć wydajność. W modelu złożonym można zwiększyć wydajność, konfigurując odpowiedni magazyn dla każdej tabeli. Można również dodać agregacje zdefiniowane przez użytkownika. Obie te optymalizacje zostały opisane w dalszej części tego artykułu.
- Chcesz połączyć model DirectQuery z większą ilością danych, które należy zaimportować do modelu. Zaimportowane dane można załadować z innego źródła danych lub z tabel obliczeniowych.
- Chcesz połączyć co najmniej dwa źródła danych DirectQuery w jeden model. Te źródła mogą być relacyjnymi bazami danych lub innymi modelami tabelarycznymi.
Uwaga
Modele złożone nie mogą zawierać połączeń z niektórymi zewnętrznymi bazami danych analitycznych. Te bazy danych obejmują oprogramowanie SAP Business Warehouse i SAP HANA podczas traktowania platformy SAP HANA jako źródła wielowymiarowego.
Ocena innych opcji projektowania modelu
Modele złożone usługi Power BI mogą rozwiązywać konkretne wyzwania projektowe, ale mogą przyczynić się do spowolnienia wydajności. Ponadto w niektórych sytuacjach mogą wystąpić nieoczekiwane wyniki obliczeń (opisane w dalszej części tego artykułu). Z tych powodów należy ocenić inne opcje projektowania modelu, gdy istnieją.
Jeśli to możliwe, najlepiej jest opracować model w trybie importu. Ten tryb zapewnia największą elastyczność projektowania i najlepszą wydajność.
Jednak wyzwania związane z dużymi ilościami danych lub raportowanie danych niemal w czasie rzeczywistym nie zawsze mogą być rozwiązywane przez modele importu. W jednym z tych przypadków można rozważyć model DirectQuery, zapewniając, że dane są przechowywane w jednym źródle danych obsługiwanym przez tryb DirectQuery. Aby uzyskać więcej informacji, zobacz Modele DirectQuery w programie Power BI Desktop.
Napiwek
Jeśli twoim celem jest rozszerzenie istniejącego modelu tabelarycznego na więcej danych, jeśli to możliwe, dodaj te dane do istniejącego źródła danych.
Tryb przechowywania tabel
W modelu złożonym można ustawić tryb przechowywania dla każdej tabeli (z wyjątkiem tabel obliczeniowych).
- Zapytanie bezpośrednie: zalecamy ustawienie tego trybu dla tabel reprezentujących duże woluminy danych lub które muszą dostarczać wyniki niemal w czasie rzeczywistym. Dane nigdy nie zostaną zaimportowane do tych tabel. Zazwyczaj te tabele będą tabelami faktów, które są tabelami podsumowania.
- Importowanie: zalecamy ustawienie tego trybu dla tabel, które nie są używane do filtrowania i grupowania tabel faktów w trybie DirectQuery lub trybie hybrydowym. Jest to również jedyna opcja dla tabel opartych na źródłach, które nie są obsługiwane przez tryb DirectQuery. Tabele obliczeniowe są zawsze importowane.
- Podwójne: zalecamy ustawienie tego trybu dla tabel wymiarów, jeśli istnieje możliwość, że będą one odpytywane razem z tabelami faktów trybu DirectQuery z tego samego źródła.
- Hybrydowe: zalecamy ustawienie tego trybu przez dodanie partycji importu i jednej partycji DirectQuery do tabeli faktów, jeśli chcesz uwzględnić najnowsze zmiany danych w czasie rzeczywistym lub gdy chcesz zapewnić szybki dostęp do najczęściej używanych danych za pośrednictwem partycji importu, pozostawiając większość najczęściej używanych danych w magazynie danych.
Istnieje kilka możliwych scenariuszy, gdy usługa Power BI wysyła zapytanie do modelu złożonego.
- Zapytania importuje tylko tabele lub tabele podwójne: usługa Power BI pobiera wszystkie dane z pamięci podręcznej modelu. Zapewni to najszybszą możliwą wydajność. Ten scenariusz jest typowy w przypadku tabel wymiarów, których dotyczy zapytanie według filtrów lub wizualizacji fragmentatora.
- Wykonuje zapytania dotyczące tabel podwójnych lub tabel DirectQuery z tego samego źródła: usługa Power BI pobiera wszystkie dane, wysyłając co najmniej jedno zapytanie natywne do źródła zapytania bezpośredniego. Zapewni to dobrą wydajność, zwłaszcza gdy odpowiednie indeksy istnieją w tabelach źródłowych. Ten scenariusz jest typowy w przypadku zapytań, które odnoszą tabele podwójnych wymiarów i tabele faktów trybu DirectQuery. Te zapytania są wewnątrz grupy źródłowej, dlatego wszystkie relacje jeden do jednego lub jednego do wielu są oceniane jako zwykłe relacje.
- Wykonuje zapytania dotyczące tabel podwójnych lub tabel hybrydowych z tego samego źródła: ten scenariusz jest kombinacją dwóch poprzednich scenariuszy. Usługa Power BI pobiera dane z pamięci podręcznej modelu, gdy jest dostępna w partycjach importu, w przeciwnym razie wysyła jedno lub więcej natywnych zapytań do źródła zapytania bezpośredniego. Zapewni to najszybszą możliwą wydajność, ponieważ w magazynie danych jest odpytywane tylko fragment danych, zwłaszcza gdy istnieją odpowiednie indeksy w tabelach źródłowych. Jeśli chodzi o tabele dwóch wymiarów i tabele faktów trybu DirectQuery, te zapytania są wewnątrz grupy źródłowej, dlatego wszystkie relacje jeden do jednego lub jednego do wielu są oceniane jako zwykłe relacje.
- Wszystkie inne zapytania: te zapytania obejmują relacje między grupami źródłowymi. Jest to spowodowane tym, że tabela importu odnosi się do tabeli DirectQuery lub tabela podwójna odnosi się do tabeli DirectQuery z innego źródła — w tym przypadku zachowuje się jako tabela importu. Wszystkie relacje są oceniane jako ograniczone relacje. Oznacza to również, że grupy stosowane do tabel innych niż DirectQuery muszą być wysyłane do źródła DirectQuery jako zmaterializowane podzapytania (tabele wirtualne). W takim przypadku zapytanie natywne może być nieefektywne, zwłaszcza w przypadku dużych zestawów grupowania.
Podsumowując, zalecamy:
- Należy dokładnie rozważyć, że model złożony jest właściwym rozwiązaniem — chociaż umożliwia integrację na poziomie modelu z różnymi źródłami danych, wprowadza również złożoność projektu z możliwymi konsekwencjami (opisanymi w dalszej części tego artykułu).
- Ustaw tryb przechowywania na Zapytanie bezpośrednie , gdy tabela jest tabelą faktów przechowującą duże woluminy danych lub gdy musi dostarczać wyniki niemal w czasie rzeczywistym.
- Rozważ użycie trybu hybrydowego, definiując zasady odświeżania przyrostowego i dane w czasie rzeczywistym lub partycjonując tabelę faktów przy użyciu narzędzia TOM, TMSL lub innej firmy. Aby uzyskać więcej informacji, zobacz Odświeżanie przyrostowe i dane w czasie rzeczywistym dla modeli semantycznych oraz Scenariusz użycia zaawansowanego zarządzania modelami danych.
- Ustaw tryb przechowywania na Podwójne , gdy tabela jest tabelą wymiarów i będzie odpytywane wraz z zapytaniami DirectQuery lub hybrydowymi tabelami faktów, które znajdują się w tej samej grupie źródłowej.
- Ustaw odpowiednie częstotliwości odświeżania, aby zachować pamięć podręczną modelu dla tabel podwójnych i hybrydowych (oraz wszystkich zależnych tabel obliczeniowych) zsynchronizowanych ze źródłowymi bazami danych.
- Staraj się zapewnić integralność danych między grupami źródłowymi (w tym pamięcią podręczną modelu), ponieważ ograniczone relacje spowodują wyeliminowanie wierszy w wynikach zapytania, gdy powiązane wartości kolumn nie są zgodne.
- Zawsze, gdy jest to możliwe, zoptymalizuj źródła danych DirectQuery przy użyciu odpowiednich indeksów, aby uzyskać wydajne sprzężenia, filtrowanie i grupowanie.
Agregacje zdefiniowane przez użytkownika
Agregacje zdefiniowane przez użytkownika można dodawać do tabel DirectQuery. Ich celem jest zwiększenie wydajności zapytań o wyższym stopniu szczegółowość .
Gdy agregacje są buforowane w modelu, zachowują się jako tabele importu (chociaż nie mogą być używane jak tabela modelu). Dodanie agregacji importu do modelu DirectQuery spowoduje utworzenie modelu złożonego.
Uwaga
Tabele hybrydowe nie obsługują agregacji, ponieważ niektóre partycje działają w trybie importu. Nie można dodawać agregacji na poziomie pojedynczej partycji DirectQuery.
Zalecamy, aby agregacja jest zgodna z podstawową regułą: jego liczba wierszy powinna być co najmniej 10 mniejsza niż tabela bazowa. Jeśli na przykład tabela bazowa przechowuje 1 miliard wierszy, tabela agregacji nie powinna przekraczać 100 milionów wierszy. Ta reguła gwarantuje, że istnieje odpowiedni wzrost wydajności w stosunku do kosztów tworzenia i konserwacji agregacji.
Relacje między grupami źródłowymi
Gdy relacja modelu obejmuje grupy źródłowe, jest znana jako relacja między grupami źródłowymi. Relacje między grupami źródłowymi są również ograniczone , ponieważ nie ma gwarantowanej strony "jeden". Aby uzyskać więcej informacji, zobacz Ocena relacji.
Uwaga
W niektórych sytuacjach można uniknąć tworzenia relacji między grupami źródłowymi. Zobacz temat Używanie fragmentatorów synchronizacji w dalszej części tego artykułu.
Podczas definiowania relacji między grupami źródłowymi należy wziąć pod uwagę następujące zalecenia.
- Użyj kolumn relacji o niskiej kardynalności: aby uzyskać najlepszą wydajność, zalecamy, aby kolumny relacji były niskiej kardynalności, co oznacza, że powinny przechowywać mniej niż 50 000 unikatowych wartości. To zalecenie jest szczególnie prawdziwe podczas łączenia modeli tabelarycznych i w przypadku kolumn innych niż tekst.
- Unikaj używania dużych kolumn relacji tekstowych: jeśli musisz użyć kolumn tekstowych w relacji, oblicz oczekiwaną długość tekstu filtru, mnożąc kardynalność przez średnią długość kolumny tekstowej. Możliwa długość tekstu nie powinna przekraczać 1000 000 znaków.
- Podnieś stopień szczegółowości relacji: jeśli to możliwe, utwórz relacje na wyższym poziomie szczegółowości. Na przykład zamiast odnosić tabelę dat w kluczu daty, należy zamiast tego użyć klucza miesiąca. Takie podejście projektowe wymaga, aby powiązana tabela zawierała kolumnę klucza miesiąca, a raporty nie będą mogły wyświetlać codziennych faktów.
- Staraj się osiągnąć prosty projekt relacji: utwórz relację między grupami źródłowymi tylko wtedy, gdy jest potrzebna, i spróbuj ograniczyć liczbę tabel w ścieżce relacji. Takie podejście projektowe pomoże zwiększyć wydajność i uniknąć niejednoznacznych ścieżek relacji.
Ostrzeżenie
Ponieważ program Power BI Desktop nie weryfikuje dokładnie relacji między grupami źródłowymi, istnieje możliwość utworzenia niejednoznacznych relacji.
Scenariusz relacji między grupami źródłowymi 1
Rozważmy scenariusz złożonego projektu relacji i sposób, w jaki może on generować różne , ale prawidłowe wyniki.
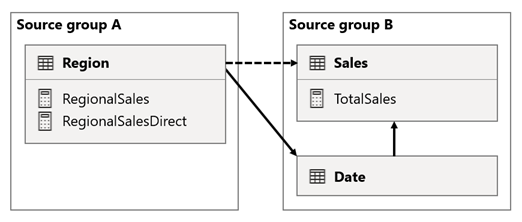
W tym scenariuszu tabela Region w grupie źródłowej A ma relację z tabelą Date i tabelą Sales w grupie źródłowej B. Relacja między tabelą Region a tabelą Date jest aktywna, a relacja między tabelą Region a tabelą Sales jest nieaktywna. Istnieje również aktywna relacja między tabelą Region a tabelą Sales , z których obie znajdują się w grupie źródłowej B. Tabela Sales zawiera miarę o nazwie TotalSales, a tabela Region zawiera dwie miary o nazwach RegionalSales i RegionalSalesDirect.
Poniżej przedstawiono definicje miar.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Zwróć uwagę, że miara RegionalSales odwołuje się do miary TotalSales , a miara RegionalSalesDirect nie. Zamiast tego miara RegionalSalesDirect używa wyrażenia SUM(Sales[Sales]), które jest wyrażeniem miary TotalSales .
Różnica w wyniku jest subtelna. Gdy usługa Power BI ocenia miarę RegionalSales , stosuje filtr z tabeli Region do tabeli Sales i tabeli Date . W związku z tym filtr jest również propagowany z tabeli Date do tabeli Sales . Natomiast gdy usługa Power BI oblicza miarę RegionalSalesDirect , propaguje filtr tylko z tabeli Region do tabeli Sales . Wyniki zwrócone przez miarę RegionalSales i miarę RegionalSalesDirect mogą się różnić, mimo że wyrażenia są semantycznie równoważne.
Ważne
Za każdym razem, gdy używasz CALCULATE funkcji z wyrażeniem, które jest miarą w zdalnej grupie źródłowej, dokładnie przetestuj wyniki obliczeń.
Scenariusz relacji między grupami źródłowymi 2
Rozważmy scenariusz, w przypadku gdy relacja między grupami źródłowymi ma kolumny relacji o wysokiej kardynalności.
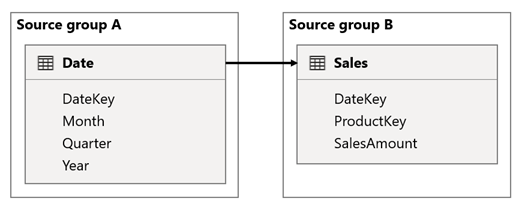
W tym scenariuszu tabela Date jest powiązana z tabelą Sales w kolumnach DateKey . Typ danych kolumn DateKey jest liczbą całkowitą, przechowując liczby całkowite, które używają formatu yyyymmdd. Tabele należą do różnych grup źródłowych. Ponadto jest to relacja o wysokiej kardynalności, ponieważ najwcześniejsza data w tabeli Date to 1 stycznia 1900 r., a najnowsza data to 31 grudnia 2100 r., więc w tabeli znajduje się łącznie 73 414 wierszy (jeden wiersz dla każdej daty w okresie 1900–2100).
Istnieją dwa przypadki niepokoju.
Po pierwsze, gdy użyjesz kolumn tabeli Date jako filtrów, propagacja filtru będzie filtrować kolumnę DateKey tabeli Sales w celu oceny miar. Podczas filtrowania według jednego roku, na przykład 2022, zapytanie języka DAX będzie zawierać wyrażenie filtru, takie jak Sales[DateKey] IN { 20220101, 20220102, …20221231 }. Rozmiar tekstu zapytania może stać się bardzo duży, gdy liczba wartości w wyrażeniu filtru jest duża lub gdy wartości filtru są długimi ciągami. Usługa Power BI jest kosztowna, aby wygenerować długie zapytanie i źródło danych w celu uruchomienia zapytania.
Po drugie, gdy używasz kolumn tabeli Date ( takich jak Rok, Kwartał lub Miesiąc) — jako kolumn grupujących, wyniki są filtrami zawierającymi wszystkie unikatowe kombinacje lat, kwartału lub miesiąca oraz wartości kolumny DateKey . Rozmiar ciągu zapytania, który zawiera filtry w kolumnach grupowania i kolumnie relacji, może stać się bardzo duży. Jest to szczególnie istotne, gdy liczba kolumn grupowania i/lub kardynalność kolumny sprzężenia (kolumna DateKey ) jest duża.
Aby rozwiązać wszelkie problemy z wydajnością, możesz:
- Dodaj tabelę Date (Data) do źródła danych, co spowoduje utworzenie pojedynczego modelu grupy źródłowej (co oznacza, że nie jest to już model złożony).
- Podnieś stopień szczegółowości relacji. Możesz na przykład dodać kolumnę MonthKey do obu tabel i utworzyć relację w tych kolumnach. Jednak podnosząc stopień szczegółowości relacji, utracisz możliwość raportowania dziennej aktywności sprzedaży (chyba że używasz kolumny DateKey z tabeli Sales ).
Scenariusz relacji między grupami źródłowymi 3
Rozważmy scenariusz, w przypadku gdy nie ma pasujących wartości między tabelami w relacji między grupami źródłowymi.
W tym scenariuszu tabela Date w grupie źródłowej B ma relację z tabelą Sales w tej grupie źródłowej, a także z tabelą Target w grupie źródłowej A. Wszystkie relacje to jeden do wielu z tabeli Date odnoszące się do kolumn Year. Tabela Sales zawiera kolumnę SalesAmount , która przechowuje kwoty sprzedaży, podczas gdy tabela Target zawiera kolumnę TargetAmount , która przechowuje kwoty docelowe.
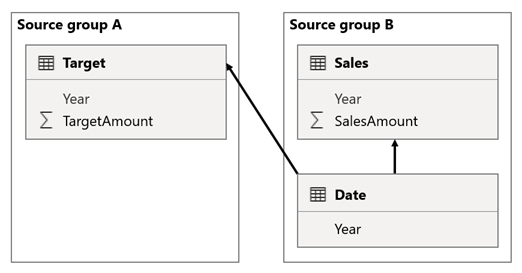
Tabela Date (Data ) przechowuje lata 2021 i 2022. Tabela Sales przechowuje kwoty sprzedaży dla lat 2021 (100) i 2022 (200), podczas gdy tabela Target przechowuje kwoty docelowe dla roku 2021 (100), 2022 (200) i 2023 (300) — w przyszłym roku.
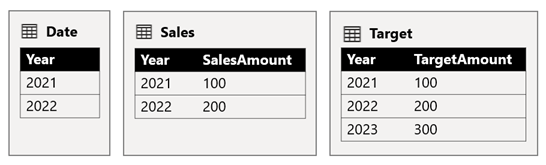
Gdy wizualizacja tabeli usługi Power BI wysyła zapytanie do modelu złożonego, grupując kolumnę Year z tabeli Date i sumując kolumny SalesAmount i TargetAmount, nie będzie pokazywać wartości docelowej dla 2023 roku. Dzieje się tak, ponieważ relacja między grupami źródłowymi jest ograniczoną relacją, dlatego używa INNER JOIN semantyki, co eliminuje wiersze, w których nie ma pasującej wartości po obu stronach. Spowoduje to jednak wygenerowanie prawidłowej kwoty docelowej (600), ponieważ filtr tabeli Date nie ma zastosowania do jego oceny.
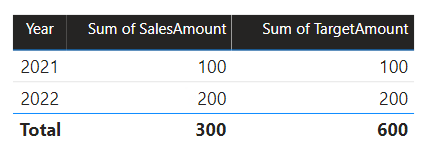
Jeśli relacja między tabelą Date a tabelą Target jest relacją wewnątrz grupy źródłowej (przy założeniu, że tabela Target należy do grupy źródłowej B), wizualizacja będzie zawierać rok (pusty) pokazujący wartość docelową 2023 (i inne niezgodne lata).
Ważne
Aby uniknąć błędnego raportowania, upewnij się, że w kolumnach relacji istnieją pasujące wartości, gdy tabele wymiarów i faktów znajdują się w różnych grupach źródłowych.
Aby uzyskać więcej informacji na temat ograniczonych relacji, zobacz Ocena relacji.
Obliczenia
Podczas dodawania kolumn obliczeniowych i grup obliczeniowych do modelu złożonego należy wziąć pod uwagę określone ograniczenia.
Kolumny obliczeniowe
Kolumny obliczeniowe dodane do tabeli DirectQuery, która źródło danych z relacyjnej bazy danych, takiej jak Program Microsoft SQL Server, są ograniczone do wyrażeń działających jednocześnie w jednym wierszu. Te wyrażenia nie mogą używać funkcji iteracyjnych języka DAX, takich jak , ani funkcji modyfikacji kontekstu filtru, takich jak SUMXCALCULATE.
Uwaga
Nie można dodać kolumn obliczeniowych ani tabel obliczeniowych, które zależą od łańcuchowych modeli tabelarycznych.
Wyrażenie kolumny obliczeniowej w zdalnej tabeli DirectQuery jest ograniczone tylko do oceny wewnątrz wiersza. Można jednak utworzyć takie wyrażenie, ale spowoduje to błąd, gdy jest on używany w wizualizacji. Jeśli na przykład dodasz kolumnę obliczeniową do zdalnej tabeli DirectQuery o nazwie DimProduct przy użyciu wyrażenia [Product Sales] / SUM (DimProduct[ProductSales]), będzie można pomyślnie zapisać wyrażenie w modelu. Jednak spowoduje to błąd, gdy jest używany w wizualizacji, ponieważ narusza ograniczenie oceny wewnątrz wiersza.
Natomiast kolumny obliczeniowe dodane do zdalnej tabeli DirectQuery, która jest modelem tabelarycznym, który jest modelem semantycznym usługi Power BI lub modelem usług Analysis Services, są bardziej elastyczne. W takim przypadku wszystkie funkcje języka DAX są dozwolone, ponieważ wyrażenie zostanie ocenione w źródłowym modelu tabelarycznym.
Wiele wyrażeń wymaga, aby usługa Power BI zmaterializować kolumnę obliczeniową przed użyciem jej jako grupy lub filtru albo agregacji. Gdy kolumna obliczeniowa jest zmaterializowana w dużej tabeli, może być kosztowna pod względem procesora CPU i pamięci, w zależności od kardynalności kolumn, od których zależy kolumna obliczeniowa. W takim przypadku zalecamy dodanie tych kolumn obliczeniowych do modelu źródłowego.
Uwaga
Podczas dodawania kolumn obliczeniowych do modelu złożonego należy przetestować wszystkie obliczenia modelu. Obliczenia nadrzędne mogą nie działać poprawnie, ponieważ nie uwzględniały wpływu na kontekst filtru.
Grupy obliczania
Jeśli grupy obliczeń istnieją w grupie źródłowej, która łączy się z semantycznym modelem usługi Power BI lub modelem usług Analysis Services, usługa Power BI może zwrócić nieoczekiwane wyniki. Aby uzyskać więcej informacji, zobacz Grupy obliczeń, zapytanie i ocena miar.
Projekt modelu
Zawsze należy zoptymalizować model usługi Power BI, przyjmując projekt schematu gwiazdy.
Napiwek
Aby uzyskać więcej informacji, zobacz Omówienie schematu gwiazdy i znaczenia usługi Power BI.
Pamiętaj, aby utworzyć tabele wymiarów oddzielone od tabel faktów, aby usługa Power BI mogła poprawnie interpretować sprzężenia i tworzyć wydajne plany zapytań. Chociaż te wskazówki dotyczą dowolnego modelu usługi Power BI, jest to szczególnie prawdziwe w przypadku rozpoznawanych modeli, które staną się grupą źródłową modelu złożonego. Pozwoli to na prostszą i wydajniejszą integrację innych tabel w modelach podrzędnych.
Jeśli to możliwe, unikaj tworzenia tabel wymiarów w jednej grupie źródłowej, które odnoszą się do tabeli faktów w innej grupie źródłowej. Jest to spowodowane tym, że lepiej jest mieć relacje wewnątrz grupy źródłowej niż relacje między grupami źródłowymi, zwłaszcza w przypadku kolumn relacji o wysokiej kardynalności. Jak opisano wcześniej, relacje między grupami źródłowymi polegają na dopasowywaniu wartości w kolumnach relacji. W przeciwnym razie w wizualizacjach raportu mogą być wyświetlane nieoczekiwane wyniki.
Zabezpieczenia na poziomie wiersza
Jeśli model zawiera agregacje zdefiniowane przez użytkownika, kolumny obliczeniowe w tabelach importu lub tabele obliczeniowe, upewnij się, że zabezpieczenia na poziomie wiersza są prawidłowo skonfigurowane i przetestowane.
Jeśli model złożony łączy się z innymi modelami tabelarycznymi, reguły zabezpieczeń na poziomie wiersza są stosowane tylko w grupie źródłowej (modelu lokalnym), w której są zdefiniowane. Nie będą one stosowane do innych grup źródłowych (modeli zdalnych). Ponadto nie można zdefiniować reguł zabezpieczeń na poziomie wiersza w tabeli z innej grupy źródłowej ani zdefiniować reguł zabezpieczeń na poziomie wiersza w tabeli lokalnej, która ma relację z inną grupą źródłową.
Projekt raportu
W niektórych sytuacjach można zwiększyć wydajność modelu złożonego, projektując zoptymalizowany układ raportu.
Wizualizacje z pojedynczą grupą źródłową
Jeśli to możliwe, utwórz wizualizacje używające pól z jednej grupy źródłowej. Dzieje się tak, ponieważ zapytania generowane przez wizualizacje będą działać lepiej, gdy wynik zostanie pobrany z pojedynczej grupy źródłowej. Rozważ utworzenie dwóch wizualizacji umieszczonych obok siebie, które pobierają dane z dwóch różnych grup źródłowych.
Używanie fragmentatorów synchronizacji
W niektórych sytuacjach można skonfigurować fragmentatory synchronizacji, aby uniknąć tworzenia relacji między grupami źródłowymi w modelu. Może to umożliwić wizualne łączenie grup źródłowych, które mogą działać lepiej.
Rozważmy scenariusz, w przypadku gdy model ma dwie grupy źródłowe. Każda grupa źródłowa ma tabelę wymiarów produktu używaną do filtrowania odsprzedawcy i sprzedaży internetowej.
W tym scenariuszu grupa źródłowa A zawiera tabelę Product powiązaną z tabelą ResellerSales. Grupa źródłowa B zawiera tabelę Product2 powiązaną z tabelą InternetSales . Nie ma żadnych relacji między grupami źródłowymi.
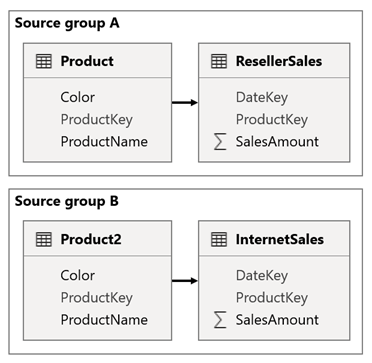
W raporcie dodasz fragmentator, który filtruje stronę przy użyciu kolumny Kolor tabeli Product. Domyślnie fragmentator filtruje tabelę ResellerSales , ale nie tabelę InternetSales . Następnie dodasz ukryty fragmentator przy użyciu kolumny Color tabeli Product2. Ustawiając identyczną nazwę grupy (znajdującą się w opcjach zaawansowanych fragmentatorów synchronizacji), filtry stosowane do widocznego fragmentatora są automatycznie propagowane do ukrytego fragmentatora.
Uwaga
Podczas korzystania z fragmentatorów synchronizacji można uniknąć konieczności utworzenia relacji między grupami źródłowymi, zwiększa złożoność projektu modelu. Pamiętaj, aby edukować innych użytkowników na temat tego, dlaczego model został zaprojektowany ze zduplikowanymi tabelami wymiarów. Unikaj pomyłek, ukrywając tabele wymiarów, których nie chcesz używać przez innych użytkowników. Możesz również dodać tekst opisu do ukrytych tabel, aby udokumentować ich przeznaczenie.
Aby uzyskać więcej informacji, zobacz Synchronizowanie oddzielnych fragmentatorów.
Inne wskazówki
Oto kilka innych wskazówek, które ułatwiają projektowanie i konserwację modeli złożonych.
- Wydajność i skala: jeśli raporty były wcześniej połączone z semantycznym modelem usługi Power BI lub modelem usług Analysis Services, usługa Power BI może ponownie używać pamięci podręcznych wizualizacji między raportami. Po przekonwertowaniu połączenia na żywo w celu utworzenia lokalnego modelu DirectQuery raporty nie będą już korzystać z tych pamięci podręcznych. W związku z tym może wystąpić niższa wydajność, a nawet błędy odświeżania. Ponadto obciążenie dla usługa Power BI zwiększy się, co może wymagać skalowania pojemności w górę lub rozłożenia obciążenia między inne pojemności. Aby uzyskać więcej informacji na temat odświeżania i buforowania danych, zobacz Odświeżanie danych w usłudze Power BI.
- Zmiana nazwy: nie zalecamy zmieniania nazw semantycznych modeli używanych przez modele złożone ani zmieniania nazw ich obszarów roboczych. Dzieje się tak, ponieważ modele złożone łączą się z semantycznymi modelami usługi Power BI przy użyciu nazw obszarów roboczych i semantycznych modeli (a nie ich wewnętrznych unikatowych identyfikatorów). Zmiana nazwy modelu semantycznego lub obszaru roboczego może spowodować przerwanie połączeń używanych przez model złożony.
- Ład: nie zalecamy, aby pojedyncza wersja modelu prawdy to model złożony. Dzieje się tak, ponieważ będzie to zależne od innych źródeł danych lub modeli, które w przypadku aktualizacji mogą spowodować przerwanie modelu złożonego. Zamiast tego zalecamy opublikowanie modelu semantycznego przedsiębiorstwa jako pojedynczej wersji prawdy. Rozważmy ten model, aby był niezawodnym fundamentem. Inni modelujący dane mogą następnie tworzyć modele złożone, które rozszerzają model podstawowy w celu tworzenia wyspecjalizowanych modeli.
- Pochodzenie danych: użyj funkcji analizy wpływu modelu danych i semantycznego modelu przed opublikowaniem zmian modelu złożonego. Te funkcje są dostępne w usługa Power BI i mogą pomóc w zrozumieniu, w jaki sposób modele semantyczne są powiązane i używane. Ważne jest, aby zrozumieć, że nie można przeprowadzić analizy wpływu na zewnętrzne modele semantyczne wyświetlane w widoku pochodzenia, ale w rzeczywistości znajdują się w innym obszarze roboczym. Aby przeprowadzić analizę wpływu na zewnętrzny model semantyczny, musisz przejść do źródłowego obszaru roboczego.
- Aktualizacje schematu: należy odświeżyć model złożony w programie Power BI Desktop, gdy zmiany schematu zostaną wprowadzone w nadrzędnych źródłach danych. Następnie należy ponownie opublikować model w usługa Power BI. Pamiętaj, aby dokładnie przetestować obliczenia i raporty zależne.
Powiązana zawartość
Aby uzyskać więcej informacji związanych z tym artykułem, zapoznaj się z następującymi zasobami.
- Używanie modeli złożonych w usłudze Power BI Desktop
- Relacje modelu w programie Power BI Desktop
- Modele trybu DirectQuery w programie Power BI Desktop
- Używanie trybu DirectQuery w programie Power BI Desktop
- Używanie trybu DirectQuery dla modeli semantycznych usługi Power BI i usług Analysis Services
- Tryb przechowywania w programie Power BI Desktop
- Agregacje zdefiniowane przez użytkownika
- Pytania? Spróbuj zadać Społeczność usługi Power BI
- Sugestie? Współtworzenie pomysłów na ulepszanie usługi Power BI
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla