Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Machine Learning Studio (wersja klasyczna)
Machine Learning Studio (wersja klasyczna)  Azure Machine Learning
Azure Machine Learning
Ważne
Obsługa programu Machine Learning Studio (wersja klasyczna) zakończy się 31 sierpnia 2024 r. Zalecamy przejście do usługi Azure Machine Learning przed tym terminem.
Od 1 grudnia 2021 r. nie będzie można tworzyć nowych zasobów programu Machine Learning Studio (wersja klasyczna). Do 31 sierpnia 2024 r. można będzie nadal korzystać z istniejących zasobów programu Machine Learning Studio (wersja klasyczna).
- Zobacz informacje na temat przenoszenia projektów uczenia maszynowego z usługi ML Studio (klasycznej) do usługi Azure Machine Learning.
- Dowiedz się więcej o usłudze Azure Machine Learning
Dokumentacja programu ML Studio (wersja klasyczna) jest wycofywana i może nie być aktualizowana w przyszłości.
W tym artykule przedstawiono metryki, których można użyć do monitorowania wydajności modelu w usłudze Machine Learning Studio (wersja klasyczna). Ocena wydajności modelu jest jednym z podstawowych etapów procesu nauki o danych. Wskazuje ona, jak pomyślne jest ocenianie (przewidywania) zestawu danych przez wytrenowany model. Usługa Machine Learning Studio (klasyczna) obsługuje ocenę modelu za pomocą dwóch głównych modułów uczenia maszynowego:
Te moduły umożliwiają sprawdzenie, jak model działa pod względem wielu metryk, które są często używane w uczeniu maszynowym i statystykach.
Ocenianie modeli należy wziąć pod uwagę wraz z:
Przedstawiono trzy typowe scenariusze uczenia nadzorowanych:
- regresja
- klasyfikacja binarna
- klasyfikacja wieloklasowa
Ocena a krzyżowa walidacja
Ocena i krzyżowa walidacja to standardowe sposoby mierzenia wydajności modelu. Oba generują metryki oceny, które można sprawdzić lub porównać z metrykami innych modeli.
Ocena modelu oczekuje ocenionego zestawu danych jako danych wejściowych (lub dwóch w przypadku, gdy chcesz porównać wydajność dwóch różnych modeli). W związku z tym należy wytrenować model przy użyciu modułu Train Model (Trenowanie modelu ) i przewidywać niektóre zestawy danych przy użyciu modułu Score Model (Generowanie wyników dla modelu ), aby móc ocenić wyniki. Ocena jest oparta na ocenianych etykietach/prawdopodobieństwach wraz z rzeczywistymi etykietami, z których wszystkie są danymi wyjściowymi modułu Score Model (Generowanie wyników dla modelu ).
Alternatywnie można użyć walidacji krzyżowej, aby przeprowadzić wiele operacji trenowania, oceniania i ewaluacji (10 przekrojów) automatycznie na różnych podzestawach danych wejściowych. Dane wejściowe są podzielone na 10 części, w których jedna jest zarezerwowana do testowania, a druga 9 na potrzeby trenowania. Ten proces jest powtarzany 10 razy, a metryki oceny są uśrednione. Pomaga to określić, jak dobrze model uogólniłby nowe zestawy danych. Moduł Cross-Validate Model przyjmuje nieprzeszkolony model oraz jakiś oznaczony zbiór danych i generuje wyniki oceny każdego z 10 podzbiorów oraz wyniki uśrednione.
W poniższych sekcjach utworzymy proste modele regresji i klasyfikacji oraz ocenimy ich wydajność przy użyciu modułów Evaluate Model (Ocena modelu ) i Cross-Validate Model (Krzyżowe weryfikowanie modelu ).
Ocenianie modelu regresji
Załóżmy, że chcemy przewidzieć cenę samochodu przy użyciu funkcji, takich jak wymiary, koni mechanicznych, specyfikacje silnika itd. Jest to typowy problem regresji, w którym zmienna docelowa (cena) jest wartością liczbową ciągłą. Możemy dopasować model regresji liniowej, który, biorąc pod uwagę wartości cech określonego samochodu, może przewidzieć cenę tego samochodu. Ten model regresji może służyć do oceniania tego samego zestawu danych, na podstawie którego wytrenowaliśmy. Gdy mamy przewidywane ceny samochodów, możemy ocenić wydajność modelu, sprawdzając, ile przewidywań odbiega od rzeczywistych cen średnio. Aby to zilustrować, użyjemy zestawu danych Automobile price data (Raw) dostępnego w sekcji Saved Datasets w usłudze Machine Learning Studio (wersja klasyczna).
Tworzenie eksperymentu
Dodaj następujące moduły do obszaru roboczego w usłudze Machine Learning Studio (wersja klasyczna):
- Dane dotyczące cen samochodów (nieprzetworzone)
- Regresja liniowa
- Train Model (Trenuj model)
- Model punktowy
- Ocena modelu
Połącz porty, jak pokazano poniżej na rysunku 1, a następnie ustaw kolumnę Etykieta modułu Train Model (Trenowanie modelu) na cenę.

Rysunek 1. Ocenianie modelu regresji.
Sprawdzanie wyników oceny
Po uruchomieniu eksperymentu możesz kliknąć port wyjściowy modułu Evaluate Model (Ocena modelu ) i wybrać pozycję Visualize (Wizualizacja ), aby wyświetlić wyniki oceny. Metryki oceny dostępne dla modeli regresji to: Średni błąd bezwzględny, Pierwiastek średniego błędu bezwzględnego, Względny błąd bezwzględny, Względny błąd kwadratowy i Współczynnik determinacji.
Termin "błąd" w tym miejscu reprezentuje różnicę między przewidywaną wartością a wartością true. Wartość bezwzględna lub kwadrat tej różnicy jest zwykle obliczany w celu przechwycenia całkowitej wielkości błędu we wszystkich wystąpieniach, ponieważ różnica między przewidywaną i rzeczywistą wartością może być ujemna w niektórych przypadkach. Metryki błędów mierzą wydajność predykcyjną modelu regresji pod względem odchylenia średniego przewidywania z rzeczywistych wartości. Niższe wartości błędów oznaczają, że model jest dokładniejszy w tworzeniu przewidywań. Ogólna metryka błędu zero oznacza, że model idealnie pasuje do danych.
Współczynnik determinacji, znany również jako R kwadrat, jest również standardowym sposobem mierzenia, jak dobrze model pasuje do danych. Można go interpretować jako proporcję odmiany wyjaśnionej przez model. Wyższy odsetek jest lepszy w tym przypadku, gdzie 1 wskazuje idealne dopasowanie.
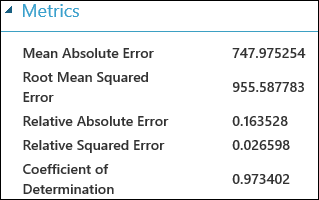
Rysunek 2. Metryki oceny regresji liniowej.
Korzystanie z krzyżowego sprawdzania poprawności
Jak wspomniano wcześniej, można wykonywać powtarzające się szkolenie, ocenianie i ewaluacje automatycznie za pomocą modułu Cross-Validate Model. W tym przypadku potrzebny jest zestaw danych, nietrenowany model i moduł Cross-Validate Model (patrz rysunek poniżej). Należy ustawić kolumnę etykiety na cenę w atrybutach modułu Cross-Validate Model.
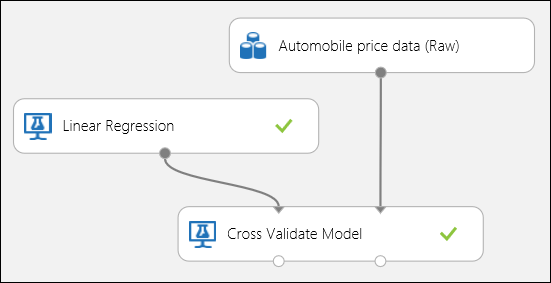
Rysunek 3. Krzyżowe weryfikowanie modelu regresji.
Po uruchomieniu eksperymentu możesz sprawdzić wyniki oceny, klikając odpowiedni port wyjściowy modułu Cross-Validate Model (Model krzyżowego sprawdzania poprawności). Zapewni to szczegółowy widok metryk dla każdej iteracji (składania) oraz średnie wyniki każdej z metryk (Rysunek 4).
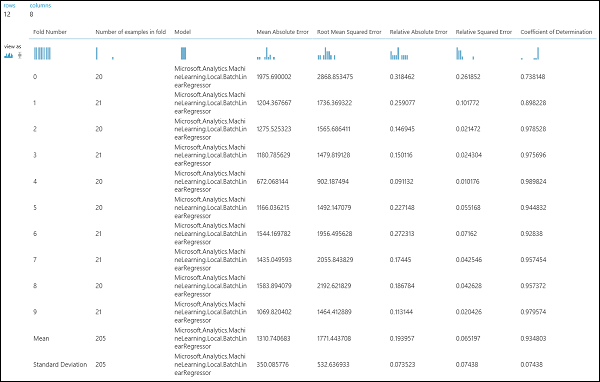
Rysunek 4. Wyniki krzyżowego sprawdzania poprawności modelu regresji.
Ocenianie modelu klasyfikacji binarnej
W scenariuszu klasyfikacji binarnej zmienna docelowa ma tylko dwa możliwe wyniki, na przykład: {0, 1} lub {false, true}, {ujemne, dodatnie}. Załóżmy, że otrzymujesz zestaw danych dla dorosłych pracowników z niektórymi zmiennymi demograficznymi i zatrudnienia oraz że poproszono Cię o przewidywanie poziomu dochodu, zmiennej binarnej o wartościach {"<=50 K", ">50 K"}. Innymi słowy, klasa ujemna reprezentuje pracowników, którzy zarabiają mniej niż lub równe 50 K rocznie, a klasa dodatnia reprezentuje wszystkich innych pracowników. Podobnie jak w scenariuszu regresji, wytrenujemy model, ocenimy niektóre dane i ocenimy wyniki. Główna różnica polega na wyborze metryk, które Machine Learning Studio (classic) oblicza i zwraca. Aby zilustrować scenariusz przewidywania na poziomie dochodów, użyjemy zestawu danych Dla dorosłych do utworzenia eksperymentu studio (klasycznego) i oceny wydajności modelu regresji logistycznej dwuklasowej, powszechnie używanego klasyfikatora binarnego.
Tworzenie eksperymentu
Dodaj następujące moduły do obszaru roboczego w usłudze Machine Learning Studio (wersja klasyczna):
- Zestaw danych spisowych do binarnej klasyfikacji dochodów dorosłych
- Regresja logistyczna dwuklasowa
- Train Model (Trenuj model)
- Model oceny
- Ocena modelu
Połącz porty, jak pokazano poniżej na rysunku 5, a następnie ustaw kolumnę Etykieta w module Train Model na dochód.
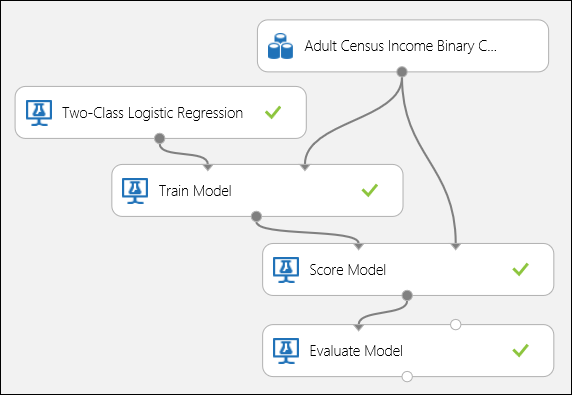
Rysunek 5. Ocenianie modelu klasyfikacji binarnej.
Sprawdzanie wyników oceny
Po uruchomieniu eksperymentu możesz kliknąć port wyjściowy modułu Evaluate Model (Ocena modelu ) i wybrać pozycję Visualize (Wizualizacja ), aby wyświetlić wyniki oceny (Rysunek 7). pl-PL: Metryki oceny dostępne dla modeli klasyfikacji binarnej to: Dokładność, Precyzja, Czułość, F1 Score i AUC. Ponadto moduł generuje macierz pomyłek pokazującą liczbę prawdziwie dodatnich, fałszywie ujemnych, fałszywie dodatnich i prawdziwie ujemnych wyników, a także krzywe ROC, Precyzja/Kompletność oraz Lift.
Dokładność jest po prostu proporcją poprawnie sklasyfikowanych wystąpień. Zazwyczaj jest to pierwsza metryka, na którą zwracasz uwagę podczas oceniania klasyfikatora. Jednak gdy dane testowe są niezrównoważone (gdzie większość wystąpień należy do jednej z klas) lub bardziej interesuje Cię wydajność jednej z klas, dokładność nie przechwytuje skuteczności klasyfikatora. W scenariuszu klasyfikacji na poziomie dochodów załóżmy, że testujesz dane, w których 99% wystąpień reprezentuje osoby, które zarabiają mniej niż lub równe 50 tys. rocznie. Można osiągnąć dokładność 0,99, przewidując klasę "<=50K" dla wszystkich wystąpień. Klasyfikator w tym przypadku wydaje się robić dobrą robotę ogólnie, ale w rzeczywistości nie klasyfikuje żadnego z osób o wysokich dochodach (1%) poprawnie.
Z tego powodu warto obliczyć dodatkowe metryki, które przechwytują bardziej szczegółowe aspekty oceny. Zanim przejdziemy do szczegółów takich metryk, ważne jest zrozumienie macierzy pomyłek w ocenie klasyfikacji binarnej. Etykiety klas w zestawie treningowym mogą przyjmować tylko dwie możliwe wartości, które zwykle nazywamy dodatnimi lub ujemną. Wystąpienia dodatnie i ujemne, które klasyfikator przewiduje poprawnie, są nazywane wartościami prawdziwie dodatnimi (TP) i prawdziwie ujemnymi (TN), odpowiednio. Podobnie niepoprawnie sklasyfikowane wystąpienia są nazywane fałszywie dodatnimi (FP) i fałszywie ujemnymi (FN). Macierz pomyłek to po prostu tabela przedstawiająca liczbę wystąpień, które należą do każdej z tych czterech kategorii. Usługa Machine Learning Studio (klasyczna) automatycznie decyduje, która z dwóch klas w zestawie danych jest klasą dodatnią. Jeśli etykiety klas są boolowskie lub liczbami całkowitymi, to wystąpienia oznaczone etykietą "true" lub "1" są przypisane do klasy dodatniej. Jeśli etykiety są ciągami, takimi jak zestaw danych dochodów, etykiety są sortowane alfabetycznie, a pierwszy poziom jest wybierany jako klasa ujemna, podczas gdy drugi poziom jest klasą dodatnią.
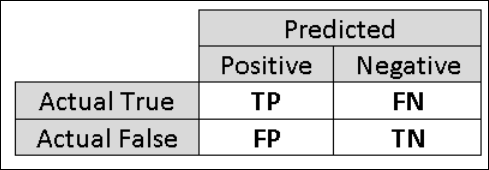
Rysunek 6. Tabela pomyłek klasyfikacji binarnej.
Wracając do problemu klasyfikacji dochodów, chcielibyśmy zadać kilka pytań ewaluacyjnych, które pomogą nam zrozumieć wydajność używanego klasyfikatora. Naturalne pytanie brzmi: "Z osób, których model przewidział, że zarabiają >50 K (TP+FP), ile zostało sklasyfikowanych poprawnie (TP)?" To pytanie można odpowiedzieć, patrząc na precyzję modelu, która jest proporcją dodatnich, które są klasyfikowane poprawnie: TP/(TP+FP). Innym typowym pytaniem jest "Ze wszystkich wysoko zarabiających pracowników o dochodach >50 tys. (TP+FN), ile klasyfikator poprawnie sklasyfikował (TP)". Jest to rzeczywiście kompletność lub prawdziwie dodatni współczynnik: TP/(TP+FN) klasyfikatora. Można zauważyć, że istnieje oczywisty kompromis między precyzją a czułością. Na przykład, biorąc pod uwagę stosunkowo zrównoważony zestaw danych, klasyfikator, który przewiduje głównie pozytywne wystąpienia miałby wysoką czułość, ale raczej niską precyzję, ponieważ wiele wystąpień ujemnych byłoby błędnie sklasyfikowanych, co spowodowałoby dużą liczbę fałszywie pozytywnych. Aby wyświetlić wykres różnic między tymi dwiema metrykami, możesz kliknąć krzywą PRECISION/RECALL na stronie danych wyjściowych wyniku oceny (lewa górna część rysunku 7).
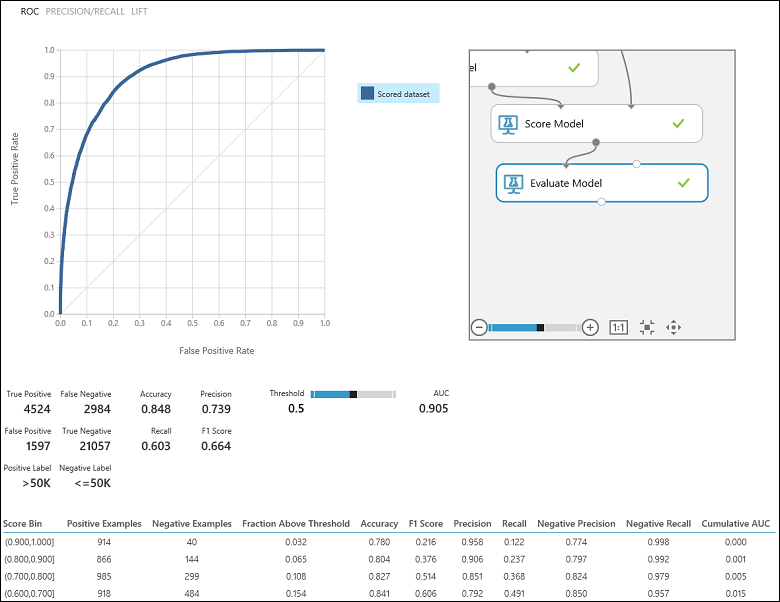
Rysunek 7. Wyniki oceny klasyfikacji binarnej.
Inna powiązana metryka, która jest często używana, to Wynik F1, który uwzględnia zarówno precyzję, jak i kompletność. Jest to średnia harmoniczna tych dwóch metryk i jest obliczana w następujący sposób: F1 = 2 (precyzja x przypomnienie) / (precyzja + przypomnienie). Wynik F1 jest dobrym sposobem podsumowania oceny w jednej liczbie, ale zawsze dobrym rozwiązaniem jest przyjrzenie się zarówno precyzji, jak i przypomnieniu razem, aby lepiej zrozumieć, jak zachowuje się klasyfikator.
Ponadto można sprawdzić rzeczywistą dodatnią stopę w porównaniu z fałszywie dodatnią częstotliwością w krzywej Właściwości operacyjnej odbiornika (ROC) i odpowiednią wartością Area Under the Curve (AUC). Im bliżej krzywa znajduje się lewego górnego rogu, tym lepsza jest skuteczność klasyfikatora (tzn. maksymalizowanie współczynnika prawdziwie dodatnich przy jednoczesnym minimalizowaniu współczynnika fałszywie dodatnich). Krzywe zbliżone do przekątnej wykresu są wynikiem działania klasyfikatorów, które mają tendencję do przewidywań bliskich losowemu zgadywaniu.
Korzystanie z krzyżowego sprawdzania poprawności
Podobnie jak w przykładzie regresji, możemy przeprowadzić krzyżową walidację, aby wielokrotnie trenować, oceniać i ewaluować różne podzestawy danych automatycznie. Podobnie możemy użyć modułu Cross-Validate Model, nietrenowanego modelu regresji logistycznej oraz zbioru danych. Kolumna etykiety musi być ustawiona na dochód we właściwościach modułu Cross-Validate Model . Po uruchomieniu eksperymentu i kliknięciu prawego portu wyjściowego modułu Cross-Validate Model (Krzyżowe weryfikowanie modelu), zobaczymy wartości metryk klasyfikacji binarnej dla każdego fałdu, wraz ze średnią i odchyleniem standardowym każdego z nich.
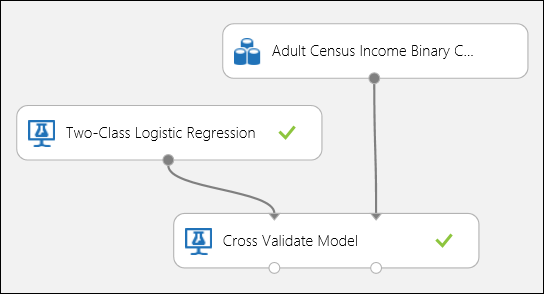
Rysunek 8. Krzyżowe weryfikowanie modelu klasyfikacji binarnej.
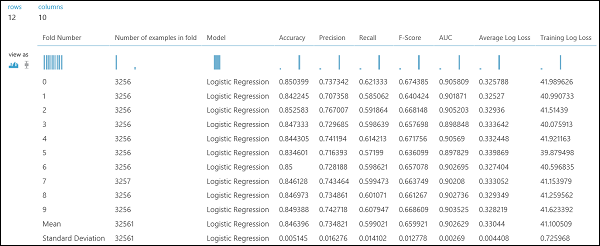
Rysunek 9. Wyniki krzyżowego sprawdzania poprawności klasyfikatora binarnego.
Ocenianie modelu klasyfikacji wieloklasowej
W tym eksperymencie użyjemy popularnego zestawu danych, który zawiera wystąpienia trzech różnych typów (klas) rośliny irys. Dla każdego wystąpienia istnieją cztery wartości cech (długość/szerokość i szerokość i długość płatka). W poprzednich eksperymentach wyszkoliliśmy i przetestowaliśmy modele przy użyciu tych samych zestawów danych. Tutaj użyjemy modułu Podział danych, aby utworzyć dwa podzestawy danych, przeprowadzić trenowanie na pierwszym oraz dokonać pomiaru i oceny na drugim. Zestaw danych Iris jest publicznie dostępny w repozytorium UCI Machine Learning i można go pobrać przy użyciu modułu Importuj dane .
Tworzenie eksperymentu
Dodaj następujące moduły do obszaru roboczego w usłudze Machine Learning Studio (wersja klasyczna):
- Importowanie danych
- Wieloklasowy las decyzyjny
- Podziel dane
- Train Model (Trenuj model)
- Model punktacji
- Ocena modelu
Połącz porty, jak pokazano poniżej na rysunku 10.
Ustaw indeks kolumny Etykieta w module Train Model na 5. Zestaw danych nie ma wiersza nagłówka, ale wiemy, że etykiety klas znajdują się w piątej kolumnie.
Kliknij moduł Importuj dane i ustaw właściwość Źródło danych na URL sieci Web przez HTTP, a adres URL na http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data.
Ustaw ułamek wystąpień, które mają być używane do trenowania w module Split Data (na przykład 0.7).
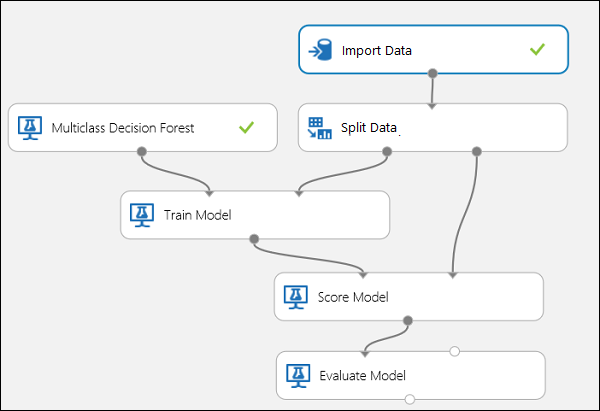
Rysunek 10. Ocenianie klasyfikatora wieloklasowego
Sprawdzanie wyników oceny
Uruchom eksperyment i kliknij port wyjściowy Evaluate Model. W tym przypadku wyniki oceny są prezentowane w postaci macierzy pomyłek. Macierz przedstawia rzeczywiste i przewidywane przypadki dla wszystkich trzech klas.
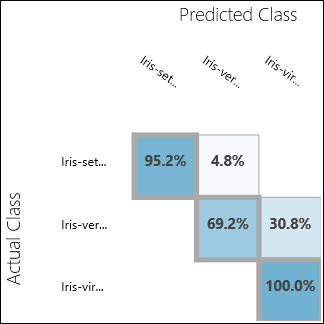
Rysunek 11. Wyniki oceny klasyfikacji wieloklasowej.
Korzystanie z krzyżowego sprawdzania poprawności
Jak wspomniano wcześniej, można automatycznie wykonywać wielokrotne trenowanie, ocenianie i oceny przy użyciu modułu Cross-Validate Model. Potrzebny jest zestaw danych, nietrenowany model i moduł Cross-Validate Model (patrz rysunek poniżej). Ponownie należy ustawić kolumnę etykiety modułu Cross-Validate Model (indeks kolumny 5 w tym przypadku). Po uruchomieniu eksperymentu i kliknięciu prawego portu wyjściowego Cross-Validate Model, można sprawdzić wartości metryk dla każdej składy, a także średnią i odchylenie standardowe. Wyświetlane tutaj metryki są podobne do tych omówionych w przypadku klasyfikacji binarnej. Jednak w klasyfikacji wieloklasowej obliczanie wyników prawdziwie dodatnich/ujemnych i wyników fałszywie dodatnich/ujemnych odbywa się przez liczenie na podstawie klasy, ponieważ nie ma ogólnej klasy dodatniej ani ujemnej. Na przykład podczas obliczania precyzji lub czułości klasy "Iris-setosa" zakłada się, że jest to dodatnia klasa, a wszystkie inne jako ujemne klasy.
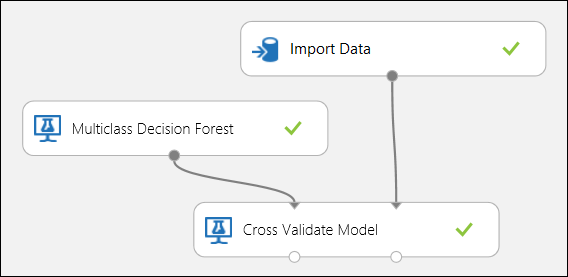
Rysunek 12. Krzyżowe weryfikowanie modelu klasyfikacji wieloklasowej.
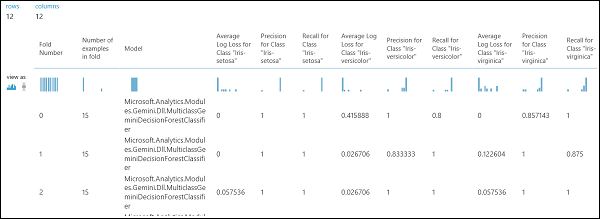
Rysunek 13. Wyniki krzyżowego sprawdzania poprawności modelu klasyfikacji wieloklasowej.