Compreender e ajustar as unidades de streaming do Stream Analytics
Compreender a unidade de streaming e o nó de streaming
As SUs (Unidades de Streaming) representam recursos de computação alocados para executar um trabalho no Stream Analytics. Quanto maior o número de SUs, mais recursos de CPU e memória são alocados para o trabalho. Esta capacidade permite que você se concentre na lógica de consulta e abstrai a necessidade de gerenciar o hardware para executar o trabalho do Stream Analytics de maneira oportuna.
O Azure Stream Analytics dá suporte a duas estruturas de unidade de streaming: SU V1 (a ser preterida) e SU V2 (recomendada).
O modelo de SU V1 é a oferta original do ASA em que cada 6 SUs correspondem a um único nó de streaming para um trabalho. Os trabalhos também podem ser executados com 1 e 3 SUs e eles correspondem a nós de streaming fracionários. A colocação em escala ocorre em incrementos de 6 além de 6 trabalhos de SU, para 12, 18, 24 e mais, adicionando mais nós de streaming que fornecem recursos de computação distribuídos.
O modelo de SU V2 (recomendado) é uma estrutura simplificada com preços favoráveis para os mesmos recursos de computação. No modelo de SU V2, 1 SU V2 corresponde a um nó de streaming para o seu trabalho. 2 SUs V2 correspondem a 2, 3 a 3, e assim por diante. Trabalhos com 1/3 e 2/3 de SUs V2 também estão disponíveis com um nó de streaming, mas uma fração dos recursos de computação. Os trabalhos com 1/3 e 2/3 de SUs V2 oferecem uma opção econômica para cargas de trabalho que exigem escala menor.
O poder de computação subjacente para as unidades de streaming V1 e V2 é o seguinte:
Para obter informações sobre preços de SU, visite a Página de Preços do Azure Stream Analytics.
Entenda as conversões de unidades de streaming e onde elas se aplicam
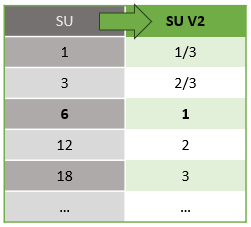
Há uma conversão automática de Unidades de Streaming que ocorre da camada de API REST para a interface do usuário (Portal do Azure e Visual Studio Code). Você notará essa conversão no log de atividades, bem como onde os valores SU aparecem diferentes dos valores na interface do usuário. Isso ocorre por design e a razão para isso é porque os campos da API REST são limitados a valores inteiros e os trabalhos ASA oferecem suporte a nós fracionários (unidades de streaming 1/3 e 2/3). A interface do usuário do ASA exibe valores de nó 1/3, 2/3, 1, 2, 3, ... etc, enquanto o back-end (logs de atividade, camada de API REST) exibe os mesmos valores multiplicados por 10 como 3, 7, 10, 20, 30, respectivamente.
| Standard | Standard V2 (UI) | Standard V2 (Back-end como logs, API Rest, etc.) |
|---|---|---|
| 1 | 1/3 | 3 |
| 3 | 2/3 | 7 |
| 6 | 1 | 10 |
| 12 | 2 | 20 |
| 18 | 3 | 30 |
| ... | ... | ... |
Isso nos permite transmitir a mesma granularidade e eliminar o ponto decimal na camada de API para SKUs V2. Essa conversão é automática e não tem impacto no desempenho do trabalho.
Noções básicas sobre o consumo e a utilização de memória
Para obter o processamento de streaming de baixa latência, os trabalhos do Azure Stream Analytics executam todo o processamento na memória. Quando a memória está acabando, o trabalho de streaming falha. Como resultado, em um trabalho de produção, é importante monitorar o uso de recursos de um trabalho de streaming e verificar se há recursos suficientes alocados para manter os trabalhos em execução 24 horas por dia.
A métrica de utilização % SU, que varia de 0% a 100%, descreve o consumo de memória da carga de trabalho. Para um trabalho de streaming com volume mínimo, a métrica costuma ficar entre 10 a 20%. Se a % de utilização de SUs for alta (acima de 80%) ou se os eventos de entrada tiverem uma lista de pendências (mesmo com uma baixa % de utilização de SUd, já que não mostra o uso da CPU), sua carga de trabalho provavelmente exigirá mais recursos de computação, o que exige que você aumente o número de unidades de streaming. É melhor manter a métrica de SU abaixo de 80% para levar em conta os picos ocasionais. Para reagir a cargas de trabalho aumentadas e aumentar as unidades de streaming, considere definir um alerta de 80% na métrica utilização da SU. Além disso, você pode usar métricas de eventos com atraso de marca-d'água e com lista de pendências para ver se há um impacto.
Configurar as SUs (unidades de streaming) do Stream Analytics
Entre no portal do Azure.
Na lista de recursos, localize o trabalho do Stream Analytics que você deseja escalar e abra-o.
Na página do trabalho, no título Configurar, selecione Escalar. O número padrão de SUs ao criar um trabalho é 1.
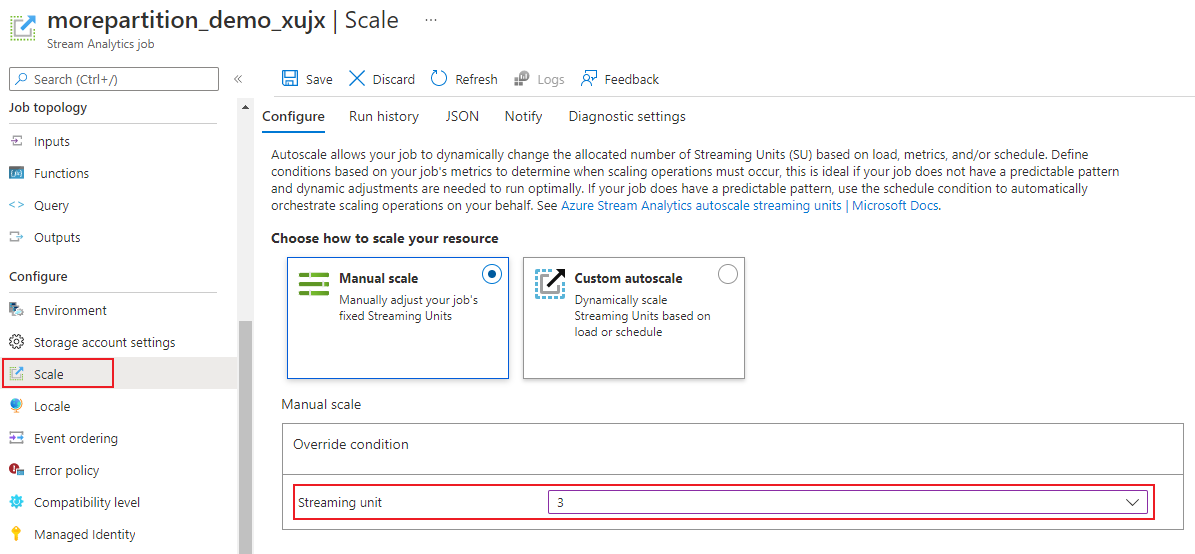
Escolha a opção SU na lista suspensa para definir as SUs do trabalho. Observe que você está limitado a configurações específicas de SU.
Você pode alterar o número de SUs atribuídas ao seu trabalho enquanto ele estiver em execução. Você pode ficar restrito à escolha de um conjunto de valores de SU quando o trabalho estiver em execução se o trabalho usar uma saída não particionada ou tiver uma consulta de várias etapas com valores PARTITION BY diferentes.
Monitorar o desempenho do trabalho
Usando o portal do Azure, você pode acompanhar as métricas relacionadas ao desempenho de um trabalho. Para saber mais sobre a definição de métricas, confira Métricas de trabalho do Azure Stream Analytics. Para saber mais sobre o monitoramento de métricas no portal, confira Monitorar trabalho do Stream Analytics com o portal do Azure.
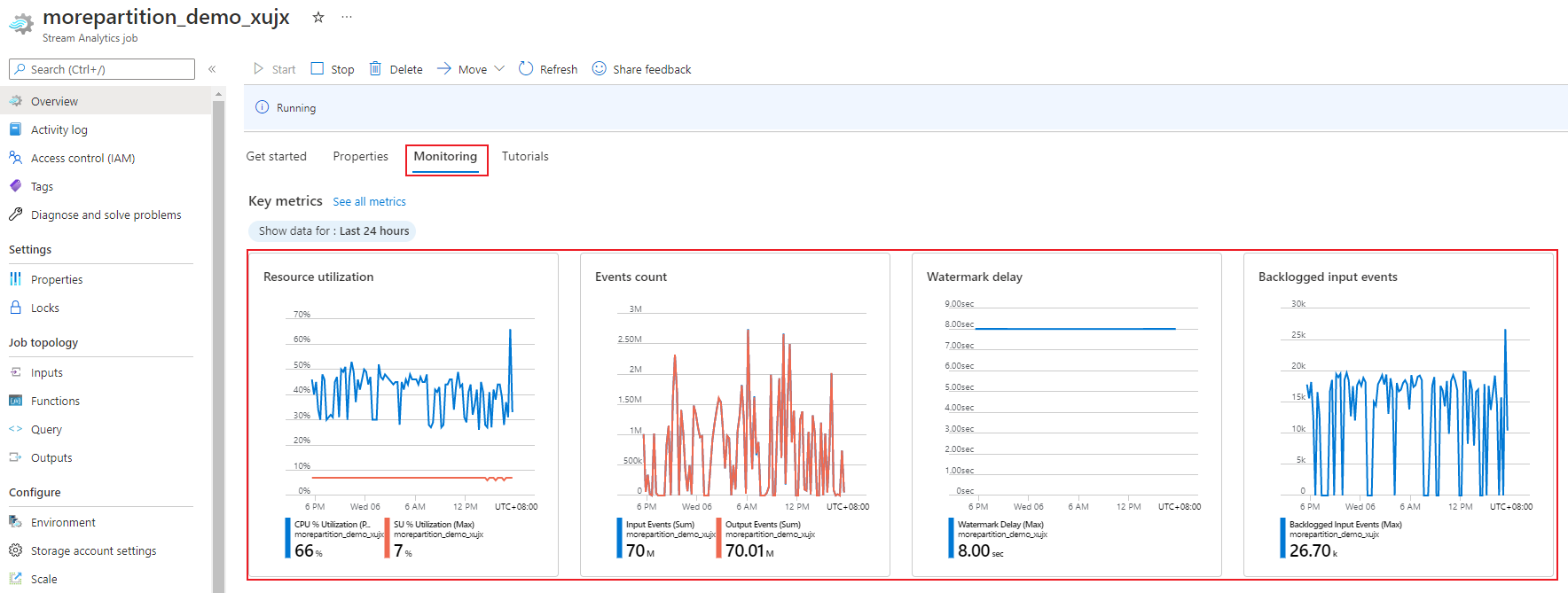
Calcule a taxa de transferência esperada da carga de trabalho. Caso a taxa de transferência seja menor do que o esperado, ajuste a partição de entrada e a consulta e adicione unidades de streaming ao seu trabalho.
Quantas SUs são necessárias para um trabalho?
A escolha do número de SUs necessárias para um trabalho específico depende da configuração da partição para as entradas e da consulta que é definida dentro do trabalho. A página Escala permite que você defina o número correto de SUs. Trata-se de uma prática recomendada para alocar mais SUs do que o necessário. O mecanismo de processamento do Stream Analytics foi otimizado para latência e taxa de transferência ao custo da alocação de memória adicional.
Em geral, a prática recomendada é iniciar com 1 SU V2 para consultas que não usam PARTITION BY. Em seguida, determine o ponto ideal usando um método de tentativa e erro no qual você modifica o número de SUs depois de passar volumes representativos de dados, e examine a métrica % de Utilização de SU. O número total de unidades de streaming que pode ser usado por um trabalho do Stream Analytics depende do número de etapas na consulta definida para o trabalho e do número de partições em cada etapa. Saiba mais sobre os limites aqui.
Para saber mais sobre como escolher o número correto de SUs, consulte esta página: Escalar trabalhos do Azure Stream Analytics para aumentar a taxa de transferência.
Observação
A escolha de quantas SUs são necessárias para um trabalho específico depende da configuração de partição das entradas e da consulta definida para o trabalho. Você pode selecionar até sua cota de SUs para um trabalho. Para obter informações sobre a cota de assinatura do Azure Stream Analytics, visite Limites do Stream Analytics. Para aumentar as SUs para suas assinaturas, entre em contato com o Suporte da Microsoft. Os valores válidos para SUs por trabalho são 1/3, 2/3, 1, 2, 3 e assim por diante.
Fatores que aumentam a utilização de SU%
Elementos de consulta temporal (orientados ao tempo) são o conjunto principal de operadores com monitoração de estado fornecido por Stream Analytics. O Stream Analytics gerencia o estado dessas operações internamente em nome de usuário, ao gerenciar o consumo de memória, pontos de verificação para a resiliência e a recuperação de estado durante as atualizações de serviço. Embora o Stream Analytics gerencie os estados completamente, existem muitas recomendações de melhor prática que os usuários devem considerar.
Observe que um trabalho com lógica de consulta complexa pode ter alta utilização de % de SU mesmo quando não estiver recebendo eventos de entrada continuamente. Isso pode acontecer após um aumento repentino nos eventos de entrada e saída. Se a consulta for complexa, o trabalho poderá continuar a manter o estado na memória.
A utilização percentual da UA pode cair repentinamente para 0 por um curto período antes de voltar aos níveis esperados. Isso ocorre devido a erros transitórios ou atualizações iniciadas pelo sistema. Aumentar o número de unidades de streaming para um trabalho poderá não reduzir a % de Utilização de SU se a consulta não for totalmente paralela.
Ao comparar a utilização em um período de tempo, use métricas de taxa de eventos. As métricas InputEvents e OutputEvents mostram quantos eventos foram lidos e processados. Há métricas que também indicam o número de eventos de erro, como erros de desserialização. Quando o número de eventos por unidade de tempo aumentar, a % de SU aumenta na maioria dos casos.
Lógica de consulta com estado em elementos temporais
Um dos recursos exclusivos do trabalho do Azure Stream Analytics é a execução do processamento com estado, como funções de análise temporal, de junções temporais e de agregações em janela. Cada um desses operadores mantém as informações de estados. O tamanho máximo da janela para esses elementos de consulta é de sete dias.
O conceito de janela temporal é exibido em vários elementos de consulta do Stream Analytics:
Agregações em janela: GROUP BY Em cascata, Salto e Janelas deslizantes
Junções temporais: JOIN à função DATEDIFF
Funções analíticas temporais: ISFIRST, LAST e a LAG com LIMIT DURATION
Os seguintes fatores influenciam a memória usada (parte da métrica de unidades de streaming) por trabalhos do Stream Analytics:
Agregações em janelas
A memória consumida (tamanho do estado) para uma agregação em janelas nem sempre é diretamente proporcional ao tamanho da janela. Em vez disso, a memória consumida é proporcional à cardinalidade de dados ou o número de grupos em cada janela de tempo.
Por exemplo, na consulta a seguir, o número associado a clusterid é a cardinalidade da consulta.
SELECT count(*)
FROM input
GROUP BY clusterid, tumblingwindow (minutes, 5)
Para mitigar quaisquer problemas causados pela alta cardinalidade na consulta anterior, você pode enviar eventos aos Hubs de Eventos particionados por clusterid, e escalar horizontalmente a consulta permitindo que o sistema processe cada partição de entrada separadamente usando PARTITION BY, conforme mostra o exemplo a seguir:
SELECT count(*)
FROM input PARTITION BY PartitionId
GROUP BY PartitionId, clusterid, tumblingwindow (minutes, 5)
Depois que a consulta é particionada horizontalmente, ela é espalhada em vários nós. Como resultado, o número de valores de clusterid em cada nó é reduzido, diminuindo assim a cardinalidade do grupo por operador.
As partições dos Hubs de Eventos devem ser particionadas pela chave de agrupamento para evitar a necessidade de uma etapa de redução. Para obter mais informações, confira Visão Geral dos Hubs de Eventos.
Junções temporais
A memória consumida (tamanho do estado) de uma junção temporal é proporcional ao número de eventos no espaço de manobra temporal da junção, que é a taxa de entrada de eventos multiplicada pelo tamanho do espaço de manobra. Em outras palavras, a memória consumida por junções é proporcional ao intervalo de tempo DateDiff multiplicado por taxa média de eventos.
O número de eventos sem correspondência na junção afeta a utilização da memória para a consulta. A consulta a seguir está tentando localizar as impressões de anúncio que geram cliques:
SELECT clicks.id
FROM clicks
INNER JOIN impressions ON impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10.
Neste exemplo, é possível que vários anúncios sejam exibidos e algumas pessoas cliquem neles, e é necessário manter todos os eventos em uma janela do tempo. A memória consumida é proporcional ao tamanho da janela e à taxa de eventos.
Para corrigir isso, envie eventos aos Hubs de Eventos particionados por chaves de junção (ID neste caso), e escale horizontalmente a consulta permitindo que o sistema processe cada partição de entrada separadamente usando PARTITION BY, conforme mostrado:
SELECT clicks.id
FROM clicks PARTITION BY PartitionId
INNER JOIN impressions PARTITION BY PartitionId
ON impression.PartitionId = clicks.PartitionId AND impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10
Depois que a consulta é particionada horizontalmente, ela é espalhada em vários nós. Como resultado, o número de eventos em cada nó é reduzido, diminuindo o tamanho do estado mantido na janela de junção.
Funções de análise temporal
A memória consumida (tamanho do estado) de uma função de análise temporal é proporcional à taxa de eventos multiplicada pela duração. A memória consumida por funções analíticas não é proporcional ao tamanho da janela, mas em vez disso, a contagem de partição em cada janela de tempo.
A correção é semelhante à junção temporal. Você pode escalar horizontalmente a consulta usando PARTITION BY.
Buffer fora de ordem
Usuário pode configurar o tamanho do buffer fora de ordem no painel de configuração de Ordenação de Eventos. O buffer é usado para armazenar as entradas durante o período e, depois, reordená-las. O tamanho do buffer é proporcional à taxa de entrada de evento multiplicada pelo tamanho da janela fora de ordem. O tamanho da janela padrão é 0.
Para corrigir o estouro de buffer de fora de ordem, expanda a consulta usando PARTITION BY. Depois que a consulta é particionada horizontalmente, ela é espalhada em vários nós. Como resultado, o número de eventos em cada nó é reduzido, diminuindo o número de eventos em cada buffer de reordenação.
Contagem de partição de entrada
Cada partição de entrada de um trabalho de entrada tem um buffer. Quanto maior o número de partições de entrada, mais recursos o trabalho consumirá. Em cada unidade de streaming, o Azure Stream Analytics pode processar aproximadamente 7 MB/s de entrada. Portanto, você pode otimizar correspondendo o número de unidades de streaming do Stream Analytics com o número de partições no seu hub de eventos.
Normalmente, um trabalho configurado com 1/3 de unidade de streaming é suficiente para um hub de eventos com duas partições (que é o requisito mínimo para o hub de eventos). Se o hub de eventos tem mais partições, seu trabalho do Stream Analytics consumirá mais recursos, mas não necessariamente usará a taxa de transferência adicional fornecida pelos Hubs de Eventos.
Para um trabalho com 1 unidade de streaming V2, talvez sejam necessárias quatro ou oito partições do hub de eventos. No entanto, evite muitas partições desnecessárias uma vez que provoca o uso excessivo de recursos. Por exemplo, um hub de eventos com 16 partições ou mais em um trabalho do Stream Analytics que tem 1 unidade de streaming.
Dados de referência
Os dados de referência no ASA são carregados na memória para uma pesquisa rápida. Com a implementação atual, cada operação de junção com dados de referência mantém uma cópia dos dados de referência na memória, mesmo se você ingressar com os mesmos dados de referência várias vezes. Para consultas com PARTITION BY, cada partição tem uma cópia dos dados de referência, para que as partições fiquem completamente separadas. Com o efeito multiplicador, o uso da memória pode ficar muito alto rapidamente se você ingressar com dados de referência várias vezes e com várias partições.
Uso de funções UDF
Quando você adiciona uma função UDF, o Azure Stream Analytics carrega o runtime do JavaScript na memória. Isso afetará a % de SU.
Próximas etapas
- Criar consultas paralelizáveis no Azure Stream Analytics
- Dimensionar trabalhos do Azure Stream Analytics para aumentar a produtividade
- Métricas de trabalho do Azure Stream Analytics
- Dimensões de métricas de trabalho do Azure Stream Analytics
- Monitorar o trabalho do Stream Analytics com portal do Azure
- Analise o desempenho do trabalho do Stream Analytics com dimensões de métricas
- Compreender e ajustar as Unidades de Streaming