O que há de novo na IA do Azure para Informação de Documentos
Este conteúdo se aplica a:![]() v4.0 (versão prévia)
v4.0 (versão prévia)![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
O serviço Informação de Documentos é atualizado continuamente. Adicione esta página aos favoritos para manter-se atualizado com as notas de versão, os aprimoramentos de recursos e a documentação mais recente.
Importante
As versões prévias da API são desativadas quando a API GA é lançada. A versão da API 2023-02-28-preview está sendo desativada. Se ainda estiver usando a versão prévia da API ou as versões do SDK associadas, atualize seu código para usar a versão 2023-07-31 (GA).
Fevereiro de 2024
A API REST 2024-02-29-preview do Document Intelligence já está disponível. A API versão prévia apresenta recursos novos e atualizados:
Atualmente, a versão prévia pública 2024-02-29-preview está disponível apenas nas seguintes regiões do Azure:
- Leste dos EUA
- Oeste dos EUA 2
- Oeste da Europa
O Modelo de layout agora dá suporte a detecção de figura e análise hierárquica de estrutura de documentos (seções e subseções). A qualidade da IA da ordem de leitura e da detecção de funções lógicas também é aprimorada.
Modelos de extração personalizados
- Os modelos de extração personalizados agora dão suporte a pontuações de confiança de célula, linha e nível de tabela. Saiba mais sobre a confiança de tabela, linha e célula.
- Os modelos de extração personalizados têm melhorias na qualidade da IA para a extração de campos.
- O exemplo de extração de modelo personalizado agora dá suporte à extração de campos sobrepostos. Saiba mais sobre os campos sobrepostos e como usá-los.
Modelo de classificação personalizada
- O modelo de classificação personalizado agora dá suporte ao treinamento incremental para cenários em que você precisa atualizar o modelo de classificador com exemplos ou classes adicionais. Saiba mais sobre backups incrementais.
- O modelo de classificação personalizado adiciona suporte para tipos de documentos do Office (.docx, .pptx e .xls). Saiba mais sobre o suporte do tipo de documento expandido.
-
- Suporte para novos locais:
Localidade Código Árabe ( ar)Búlgaro ( bg)Grego ( el)Hebraico ( he)Macedônio ( mk)Russo ( ru)Sérvio cirílico ( sr-cyrl)Ucraniano ( uk)Tailandês ( th)Turco ( tr)Vietnamita ( vi)- Suporte para novos códigos de moeda:
Moeda Localidade Código BAM Marca conversível bósnia ( ba)BGN Lev búlgaro ( bg)ILS Novo shekel israelense ( il)MKD Dinar macedônio ( mk)RUB Rublo russo ( ru)THB Thai Baht ( th)TRY Lira Turca ( tr)UAH Hryvnia ucraniana ( ua)VND Dong vietnamita ( vn)- Os itens fiscais dão suporte à expansão para Alemanha (
de), Espanha (es), Portugal (pt), Canadá inglêsen-CA.
-
- Suporte de campo expandido para IDs da União Europeia e carteira de motorista.
-
- Extraia informações do Aplicativo de Empréstimo Residencial Uniforme (Formulário 1003).
- Extraia informações do Resumo de Subscrição Uniforme e Transmissão ou Formulário 1008.
- Extraia informações da divulgação do fechamento da hipoteca.
🆕 Modelo de cartão de crédito/débito
- Extraia informações dos cartões bancários.
-
- Nova predefinição para extrair informações das certidões de casamento.
Dezembro de 2023
As bibliotecas de clientes da Informação de Documentos destinados à API REST 2023-10-31-preview já estão disponíveis para uso.
novembrod e 2023
A API REST do serviço 2023-10-31-preview da Informação de Documentos já está disponível. A API versão prévia apresenta recursos novos e atualizados:
Atualmente, a versão prévia pública 2023-10-31-preview só está disponível nas seguintes regiões do Azure:
- Leste dos EUA
- Oeste dos EUA 2
- Oeste da Europa
-
- Expansão do idioma para manuscrito: Russo (
ru), Árabe (ar), Tailandês (th). - Conformidade de EO (Ordem Executiva) Cibernética.
- Expansão do idioma para manuscrito: Russo (
-
- Suporte a arquivos HTML e do Office.
- Suporte à saída do Markdown.
- Melhorias de extração de tabela, ordem de leitura e detecção de título de seção.
- Com o Informação de Documentos 2023-10-31-preview, o modelo geral de documentos (documento predefinido) foi preterido. Daqui para frente, para extrair pares chave-valor de documentos, use o modelo
prebuilt-layoutcom o parâmetro de cadeia de caracteres de consulta opcionalfeatures=keyValuePairshabilitado.
-
- Agora extrai a moeda para todos os campos relacionados ao preço.
Modelo de Cartão de Seguro Saúde
- Novo campo de suporte para informações do Medicare e do Medicaid.
Modelos de Documentos de Impostos dos EUA
- Novo modelo fiscal 1099. Dá suporte ao formulário base 1099 e às seguintes variações: A, B, C, CAP, DIV, G, H, INT, K, LS, LTC, MISC, NEC, OID, PATR, Q, QA, R, S, SA, SB.
-
- Suporte para o campo
KVK. - Suporte para o campo
BPAY. - Diversos refinamentos de campo.
- Suporte para o campo
-
- Suporte para documentos de vários idiomas.
- Novas opções de divisão da página: divisão automática, sempre dividido por página, sem divisão.
Funcionalidades de complemento
- Os campos de consulta estão disponíveis na versão
2023-10-31-preview. - As funcionalidades de suplemento estão disponíveis em todos os modelos, exceto o modelo Leitura.
- Os campos de consulta estão disponíveis na versão
Observação
Com a versão de disponibilidade geral (GA) da API 31-08-2022, as APIs de pré-visualização associadas estão sendo descontinuadas. Se você estiver usando as versões da API 30-09-2021-versão prévia, 30-01-2022-versão prévia ou 30-06-2022-versão prévia, atualize seus aplicativos para direcionar a versão da API 31-08-2022. Há algumas pequenas alterações envolvidas. Para obter mais informações, consulte o guia de migração.
Julho de 2023
Observação
O Reconhecimento de Formulários passou a se chamar IA do Azure para Informação de Documentos!
- Os serviços de IA do Azure, documento, abrangem tudo o que antes era conhecido como Serviços Cognitivos e Serviços de IA Aplicada do Azure.
- Não houve alterações nos preços.
- Os nomes Serviços Cognitivos e IA Aplicada do Azure continuam a ser usados nas APIs de cobrança, análises de custo, listas de preços e preço do Azure.
- Não houve alterações interruptivas nas interfaces de programação de aplicativo (APIs) ou bibliotecas de clientes.
- Algumas plataformas ainda estão aguardando a atualização de renomeação. Todas as menções ao Reconhecimento de Formulários ou à Informação de Documentos na nossa documentação se referem ao mesmo serviço do Azure.
Informação de Documentos v3.1 (GA)
A API da versão 3.1 da Informação de Documentos agora está em disponibilidade geral (GA)! A versão da API corresponde a 2023-07-31.
A API v3.1 apresenta recursos novos e atualizados:
- As APIs da Informação de Documentos agora são mais modulares e com suporte para recursos opcionais. Agora você pode personalizar a saída para incluir especificamente os recursos necessários. Saiba mais sobre os parâmetros opcionais.
- API de classificação de documentos para dividir um único arquivo em documentos individuais. Saiba mais sobre classificação de documentos.
- Modelo de contrato predefinido.
- Modelo de formulário fiscal 1098 predefinido dos EUA.
- Suporte para tipos de arquivos do Office com a API de Leitura.
- Reconhecimento de código de barras em documentos.
- Recurso complementar de reconhecimento de fórmula.
- Recurso complementar de reconhecimento de fonte.
- Suporte para documentos de alta resolução.
- Os modelos neurais personalizados agora exigem uma única amostra rotulada para treinar.
- Expansão de linguagem de modelos neurais personalizados. Treine um modelo neural para documentos em 30 idiomas. Veja o suporte a idiomas para obter a lista completa de idiomas com suporte.
- 🆕 Modelo de cartão de seguro de saúde predefinido.
- Expansão de localidade do modelo de fatura predefinido.
- Linguagem de modelo de recibo predefinida e expansão de localidade com mais de 100 idiomas com suporte.
- O modelo de ID predefinido agora dá suporte a IDs europeias.
Atualizações da UX do Document Intelligence Studio
✔️ Analisar Opções
A Informação de Documentos agora é compatível com recursos de análise mais sofisticados e o Estúdio permite um ponto de entrada (botão Analisar opções) para configurar os recursos de complemento com facilidade.
Dependendo do cenário de extração de documentos, configure o intervalo de análises, o intervalo de páginas de documentos, a detecção opcional e os recursos de detecção premium.
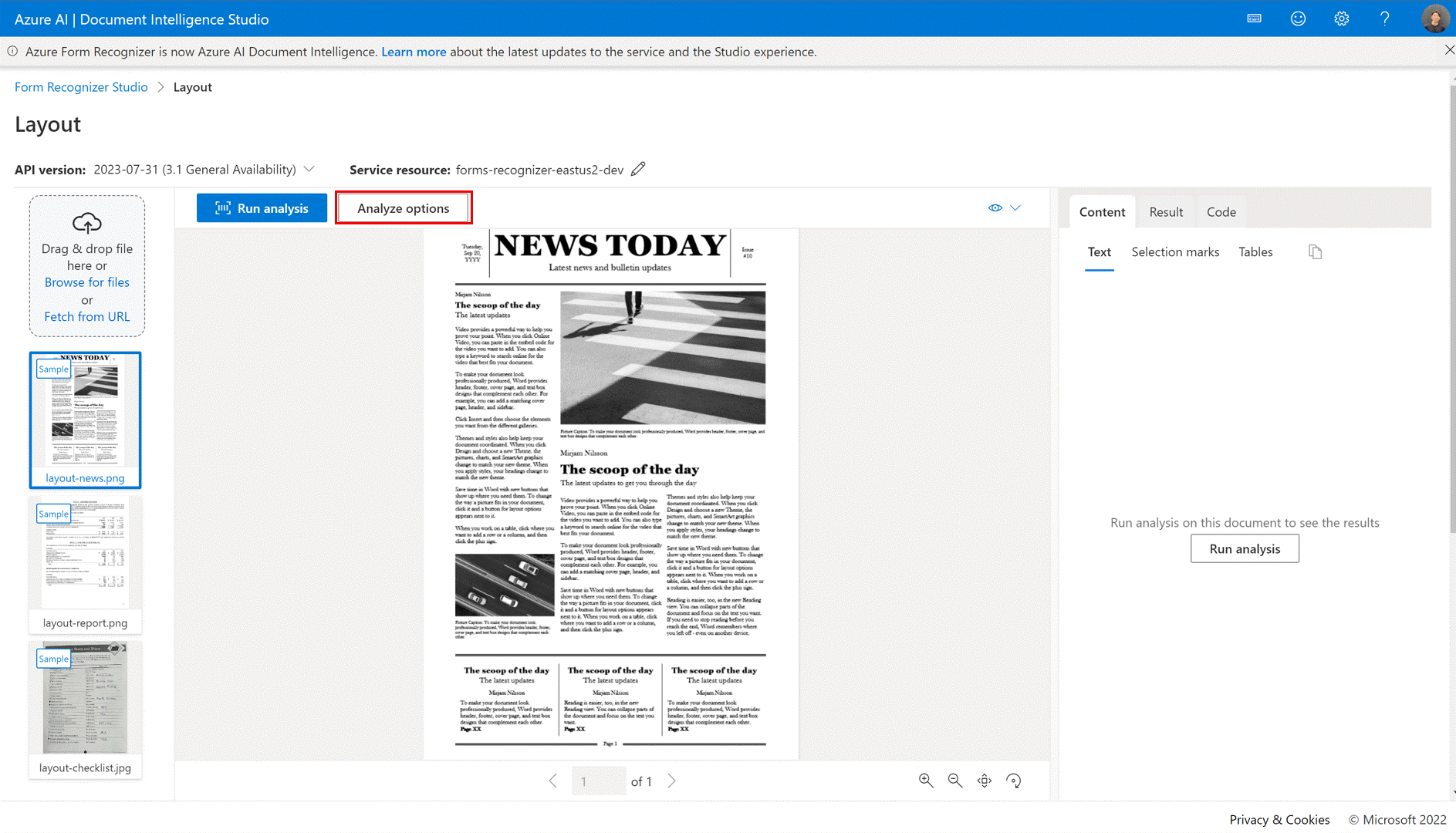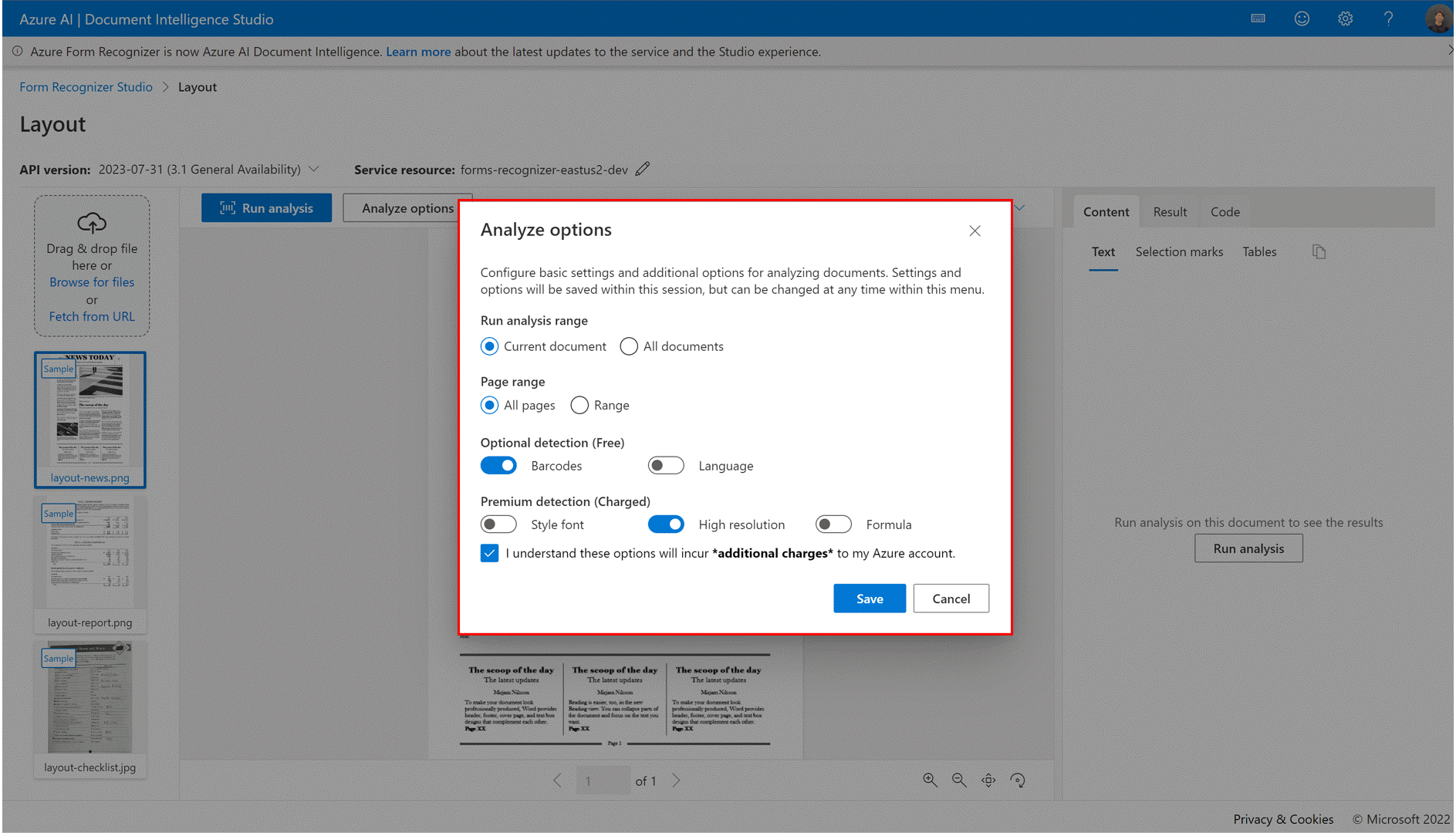
Observação
A extração de fontes não é visualizada no Estúdio da Informação de Documentos. No entanto, é possível marcar a seção de estilos da saída JSON para obter os resultados de detecção de fonte.
✔️ Rotulagem automática de documentos com modelos predefinidos ou um de seus próprios modelos
Na página de rotulagem do modelo de extração personalizado, agora você pode rotular automaticamente seus documentos usando um dos modelos predefinidos do Serviço de Informação de Documentos ou modelos treinados anteriormente.
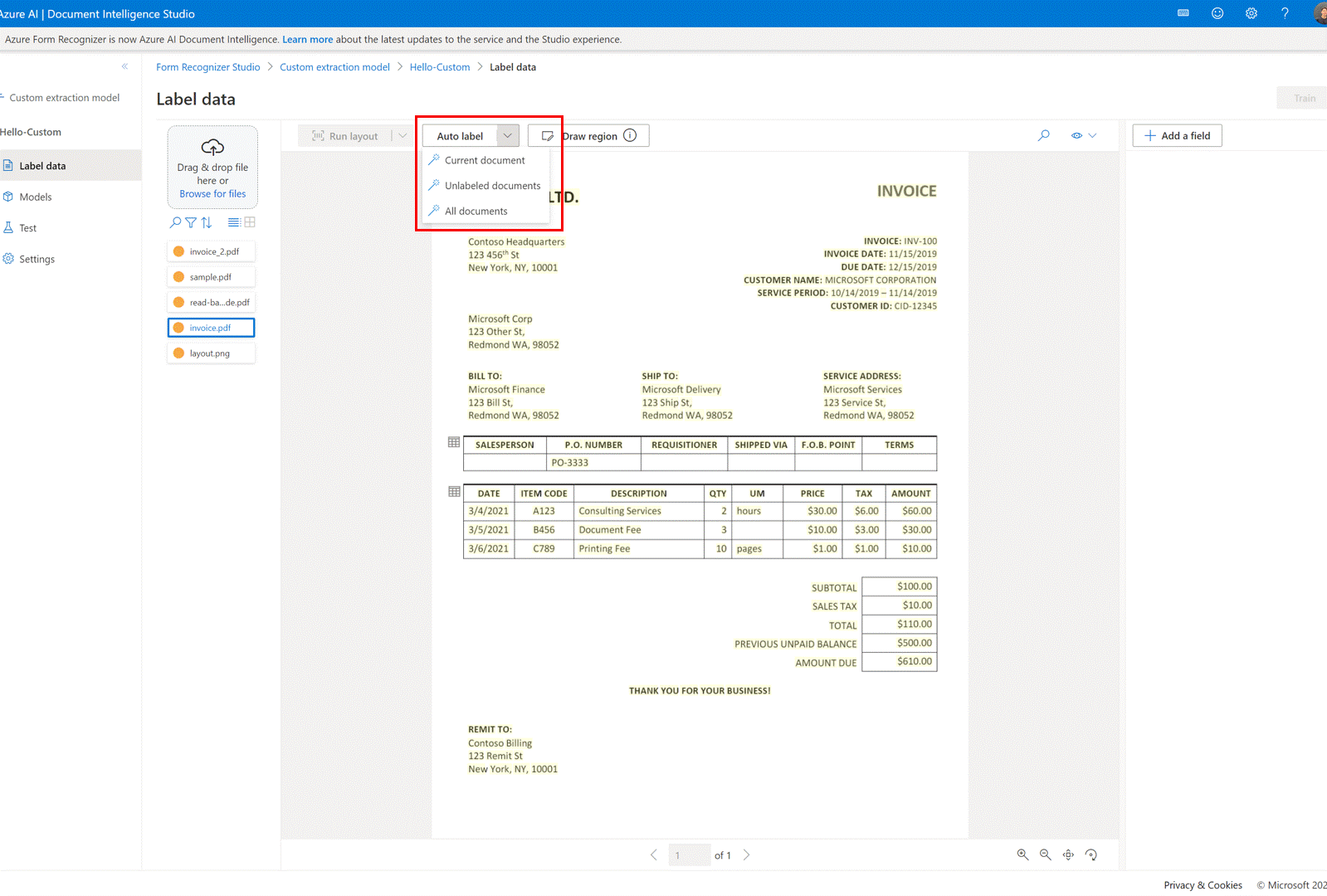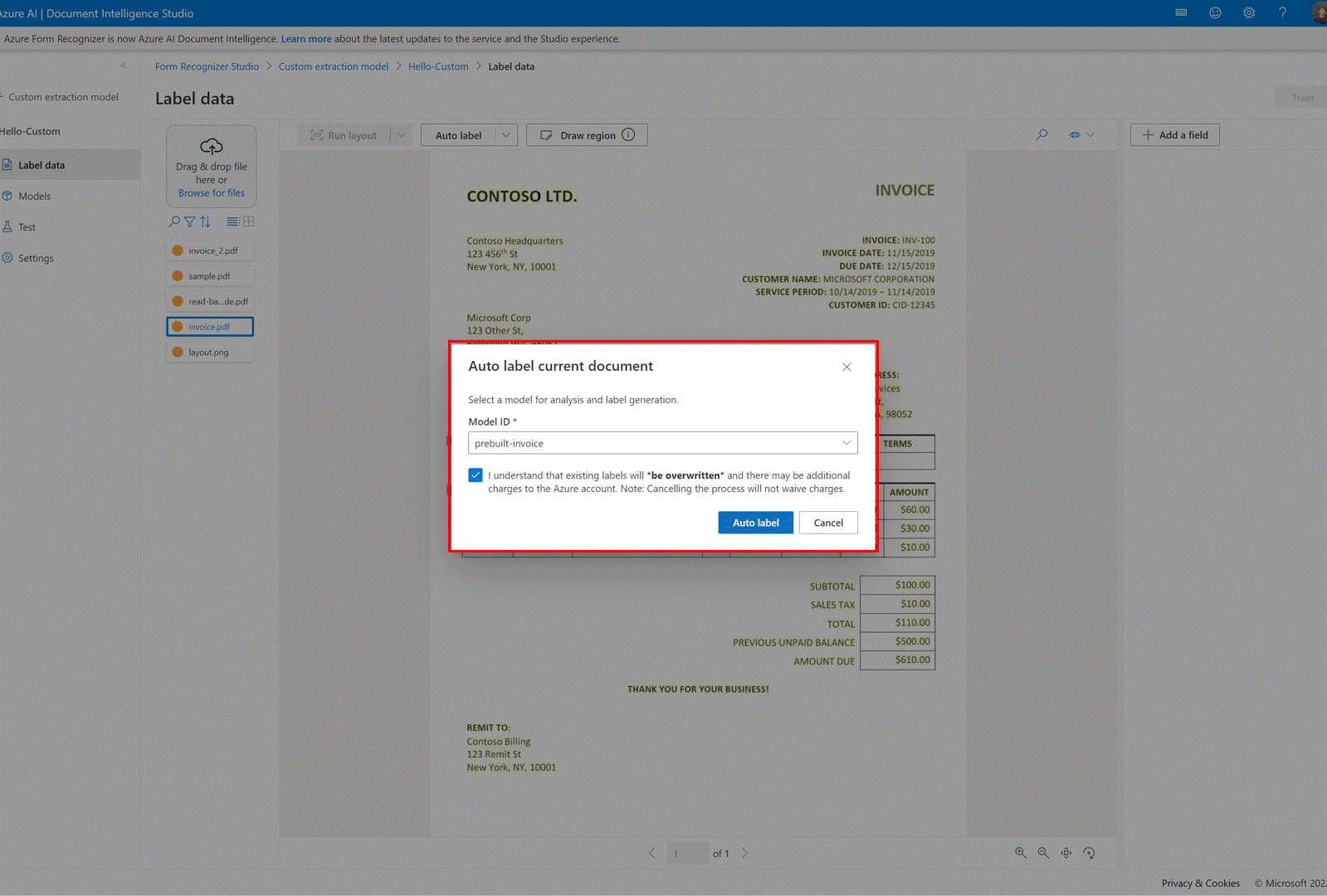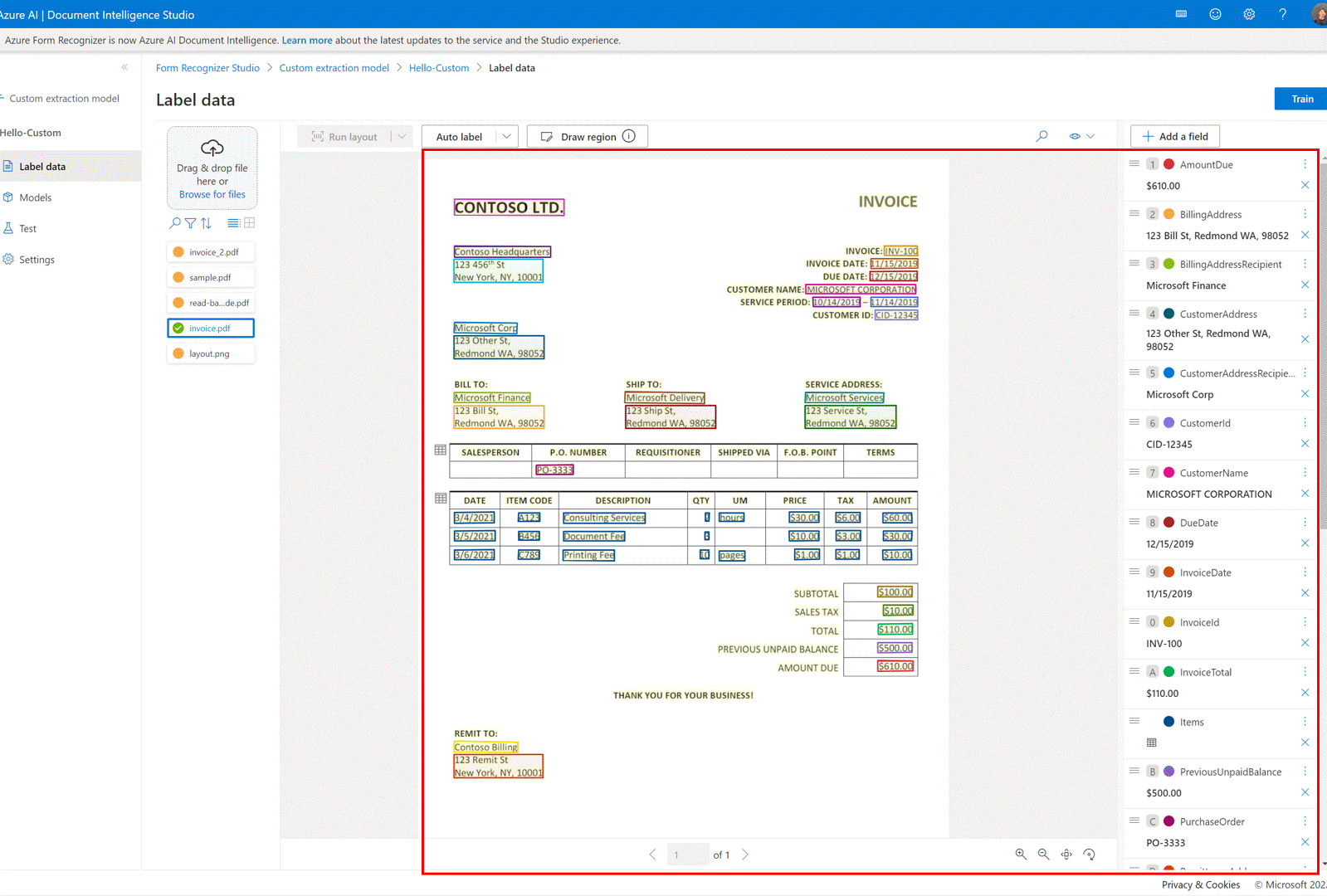
Para alguns documentos, podem existir rótulos duplicados após a execução da rotulagem automática. Modifique os rótulos para que não haja rótulos duplicados na página de rotulagem posteriormente.
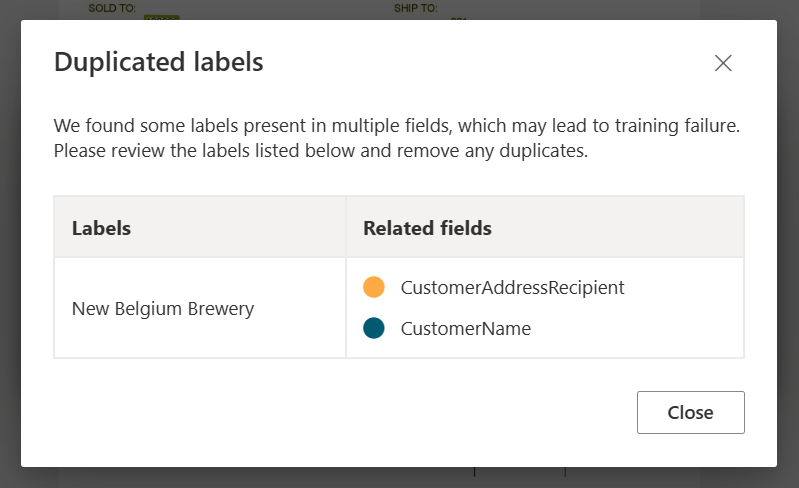
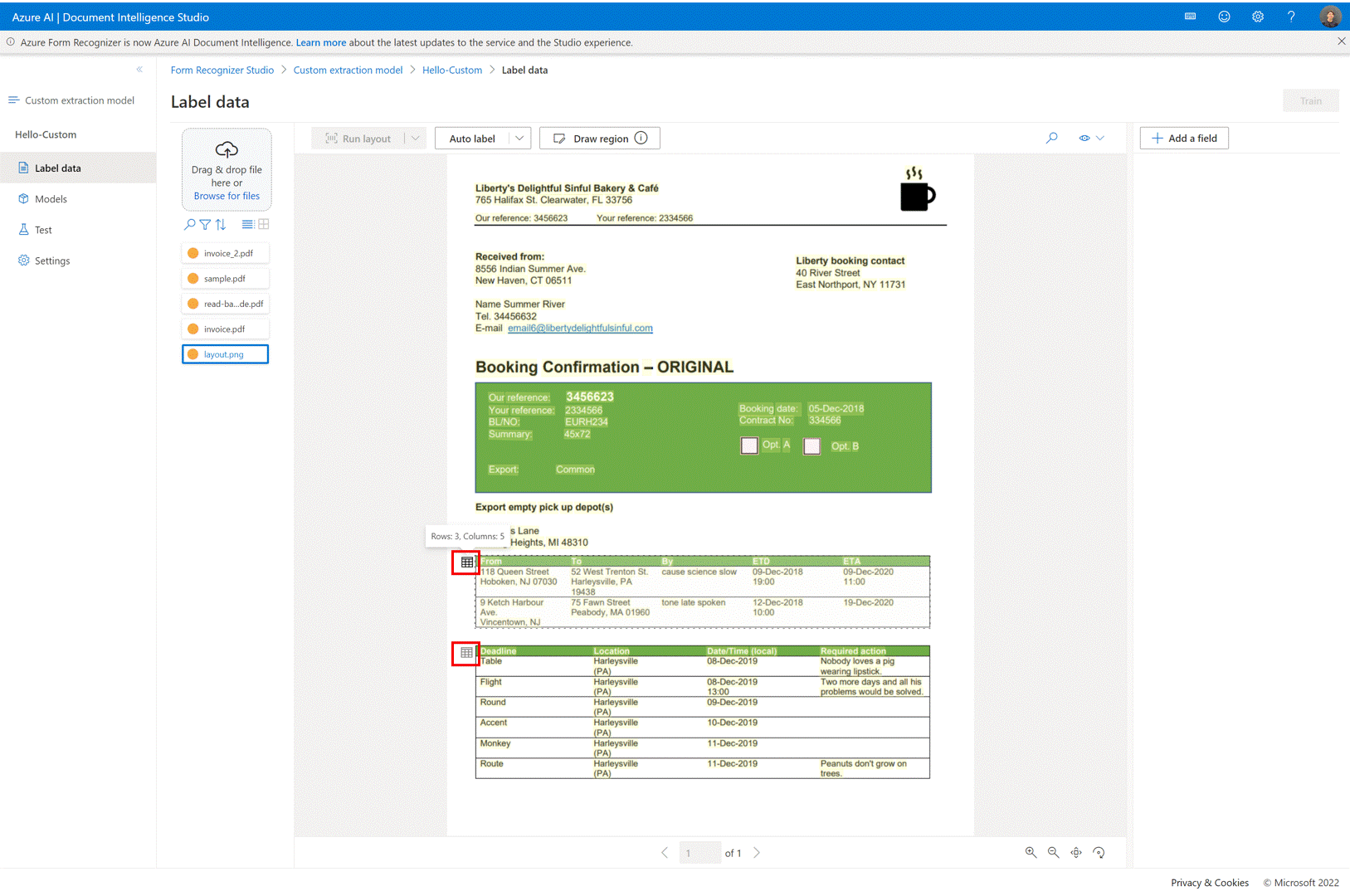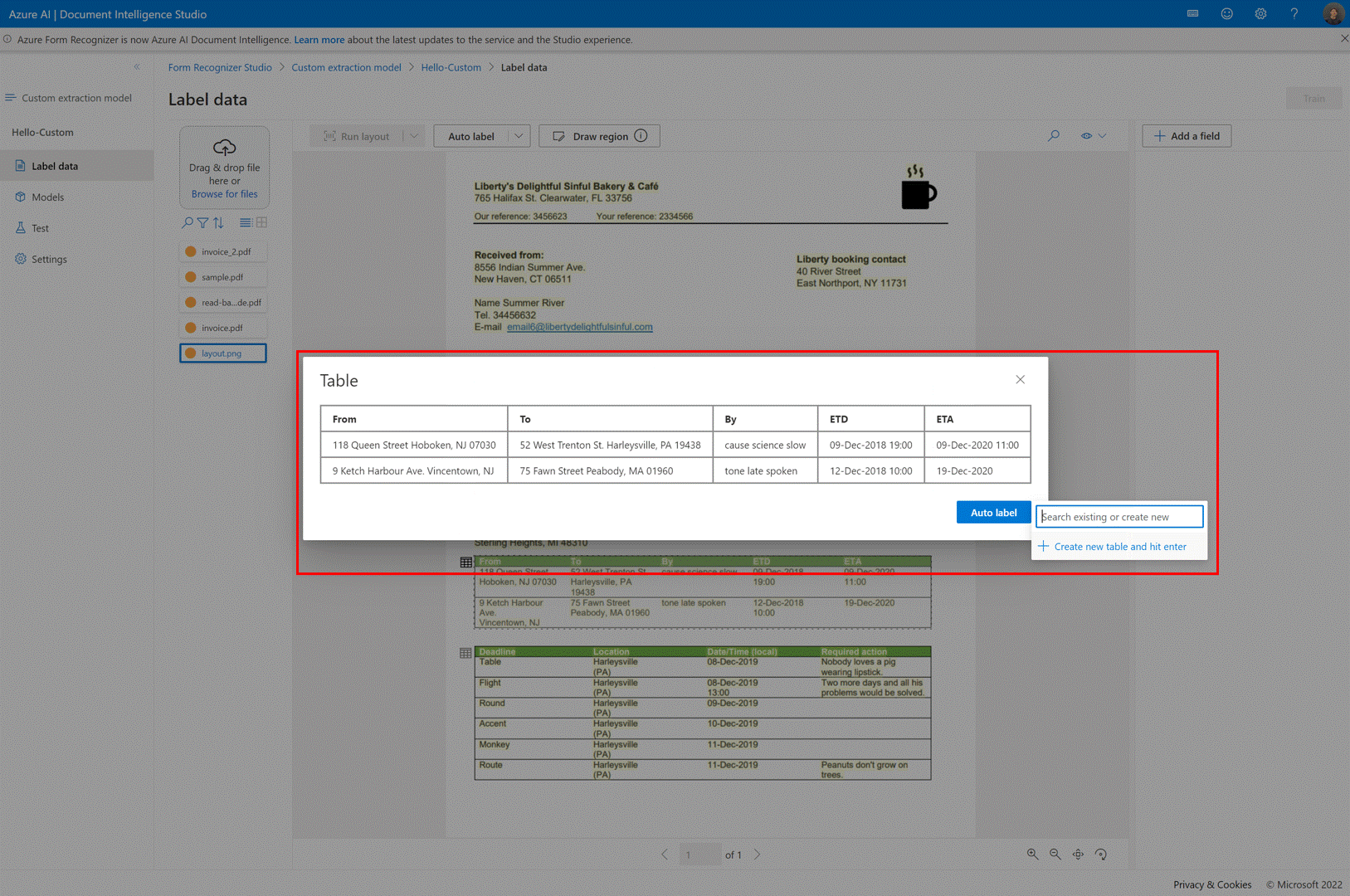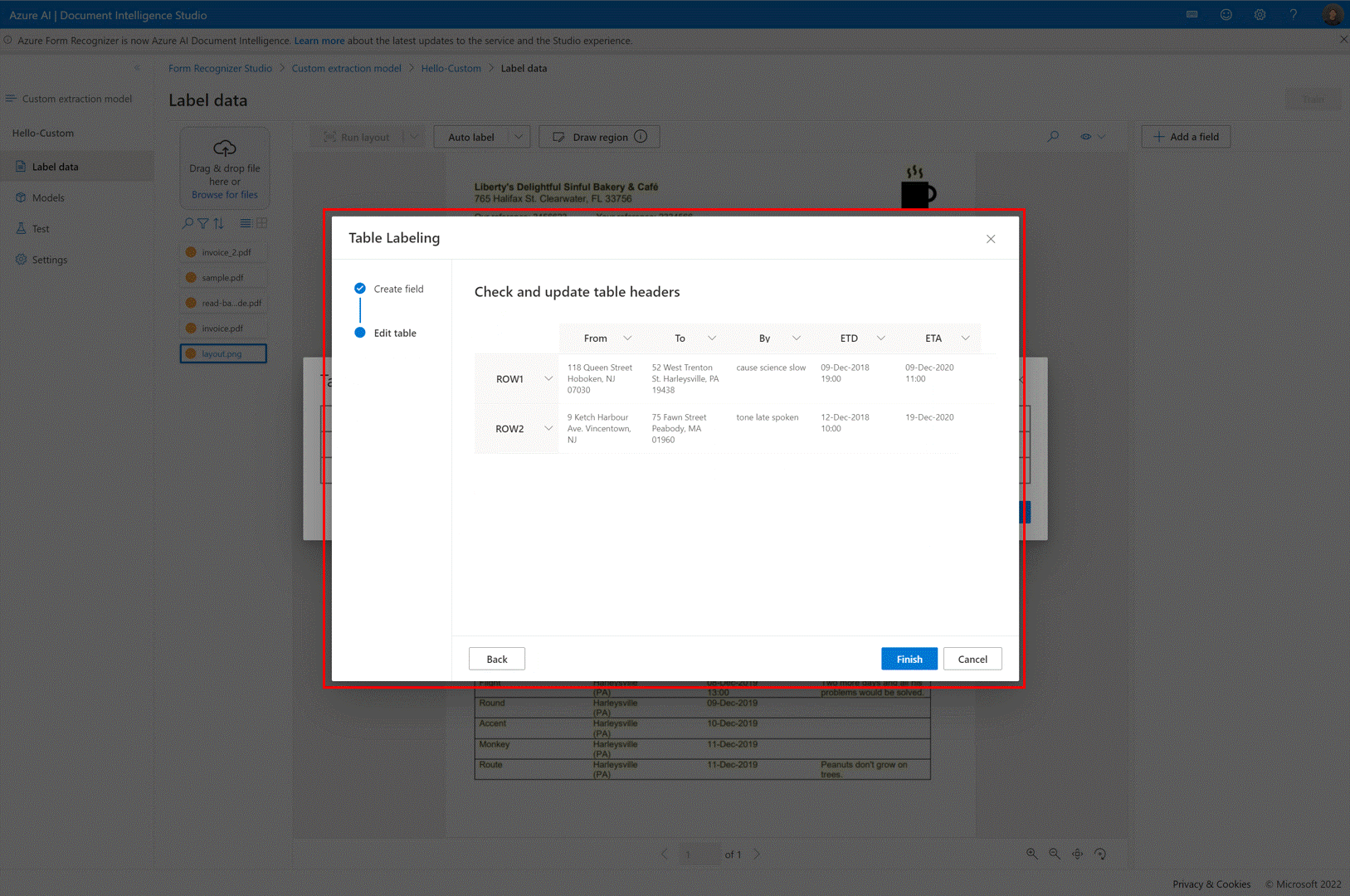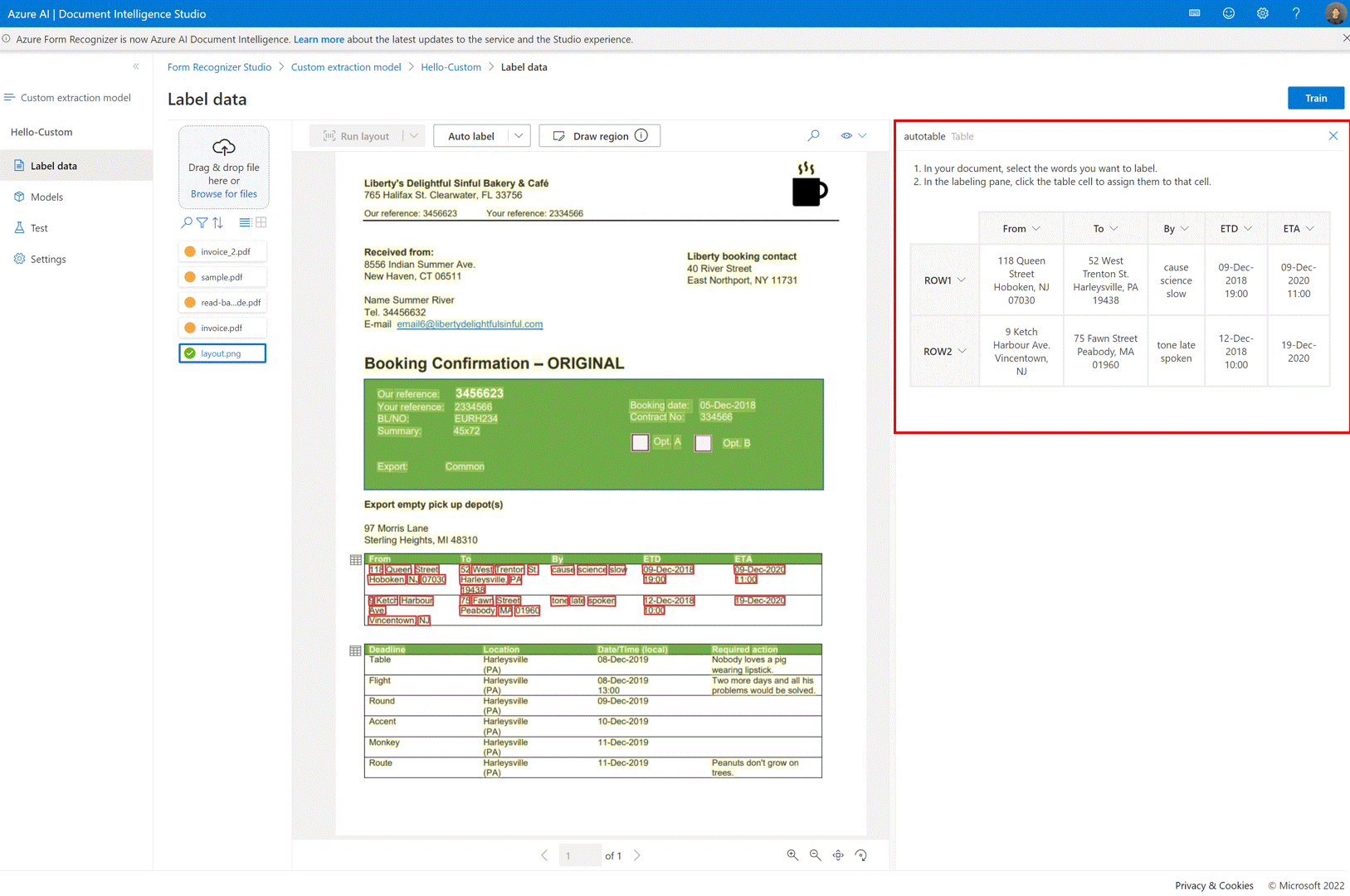
✔️ Tabelas de rotulagem automática
Na página de rotulagem de modelo de extração personalizada, agora você pode rotular automaticamente as tabelas no documento sem precisar rotular as tabelas manualmente.
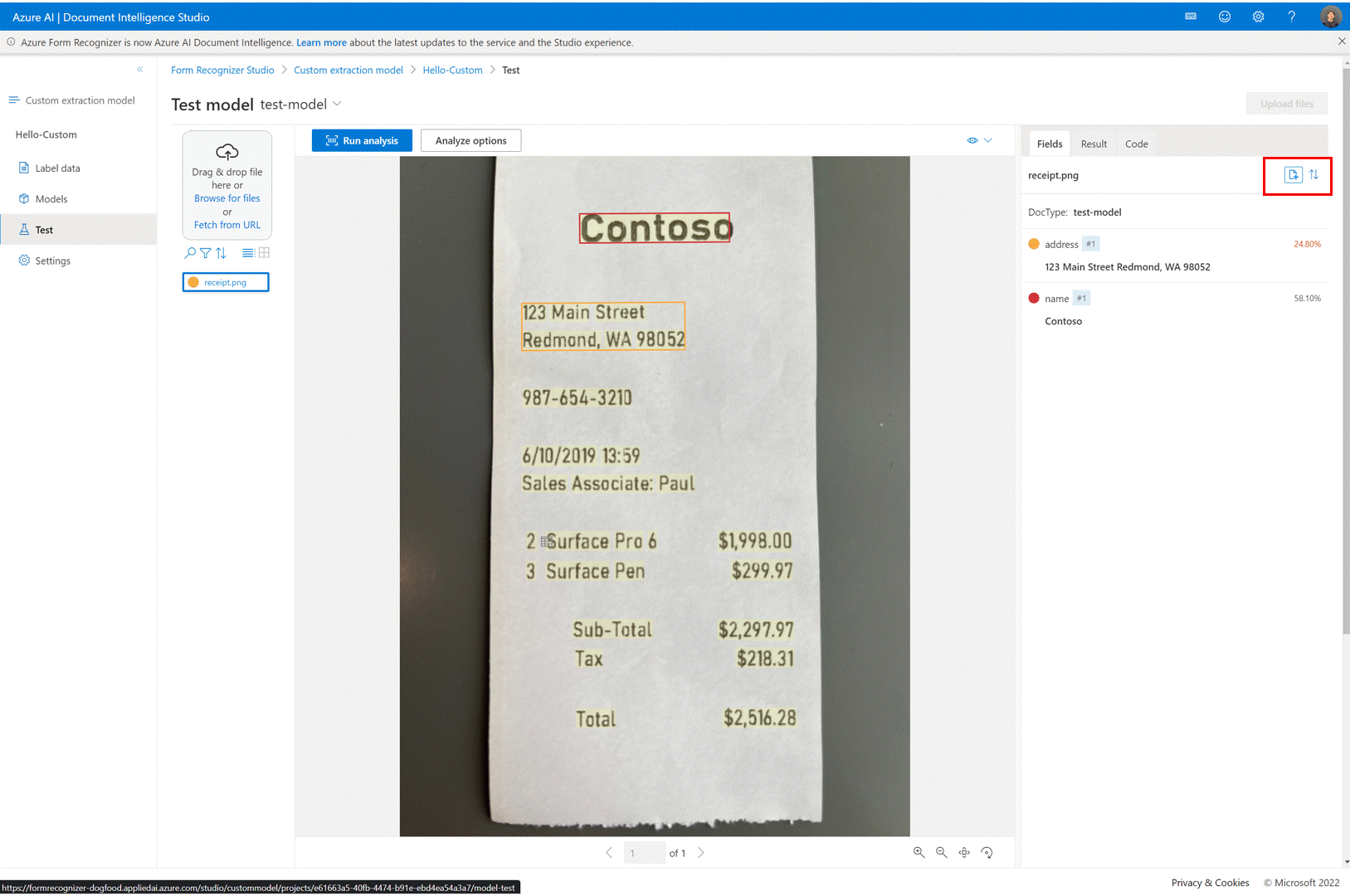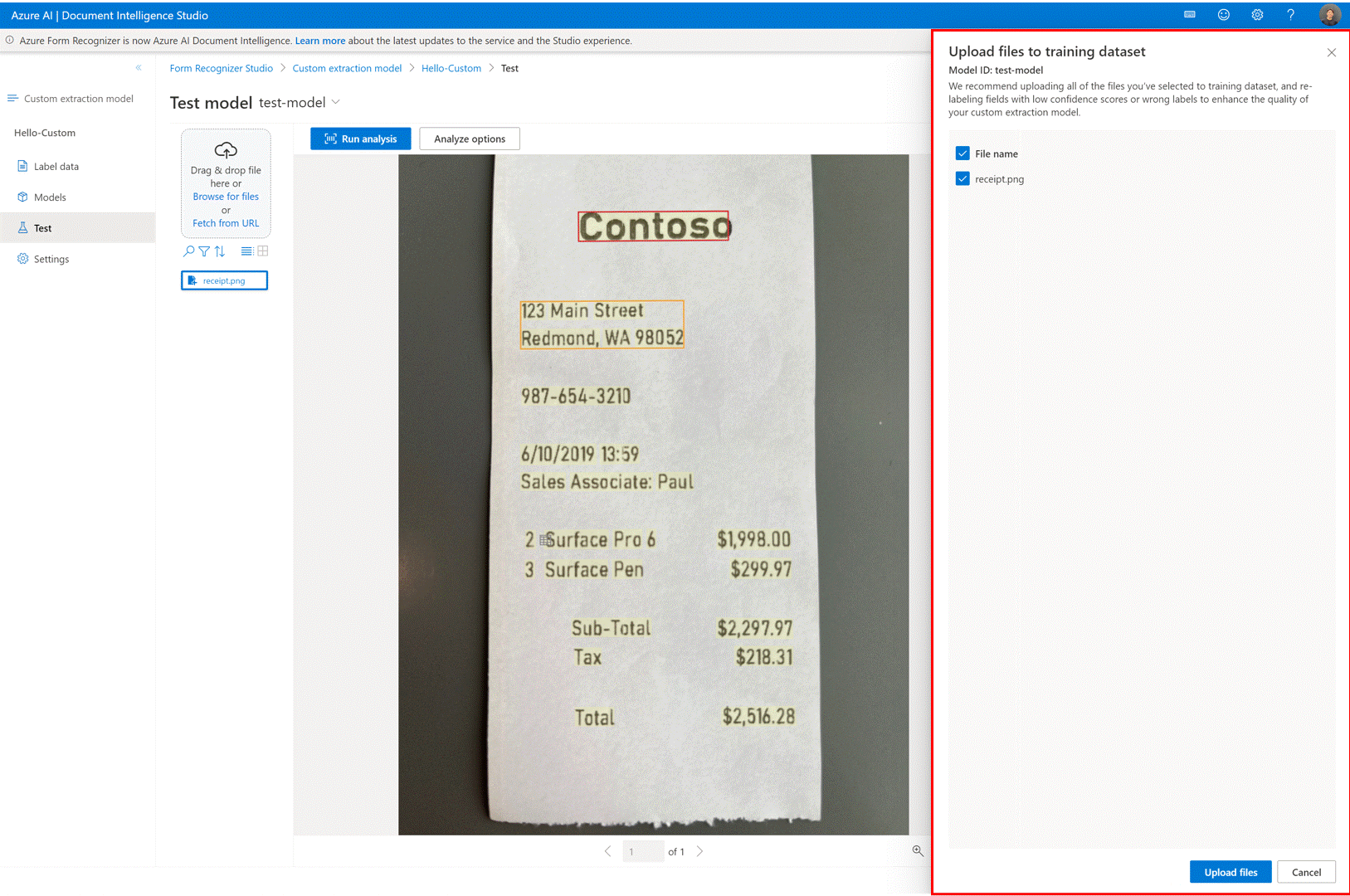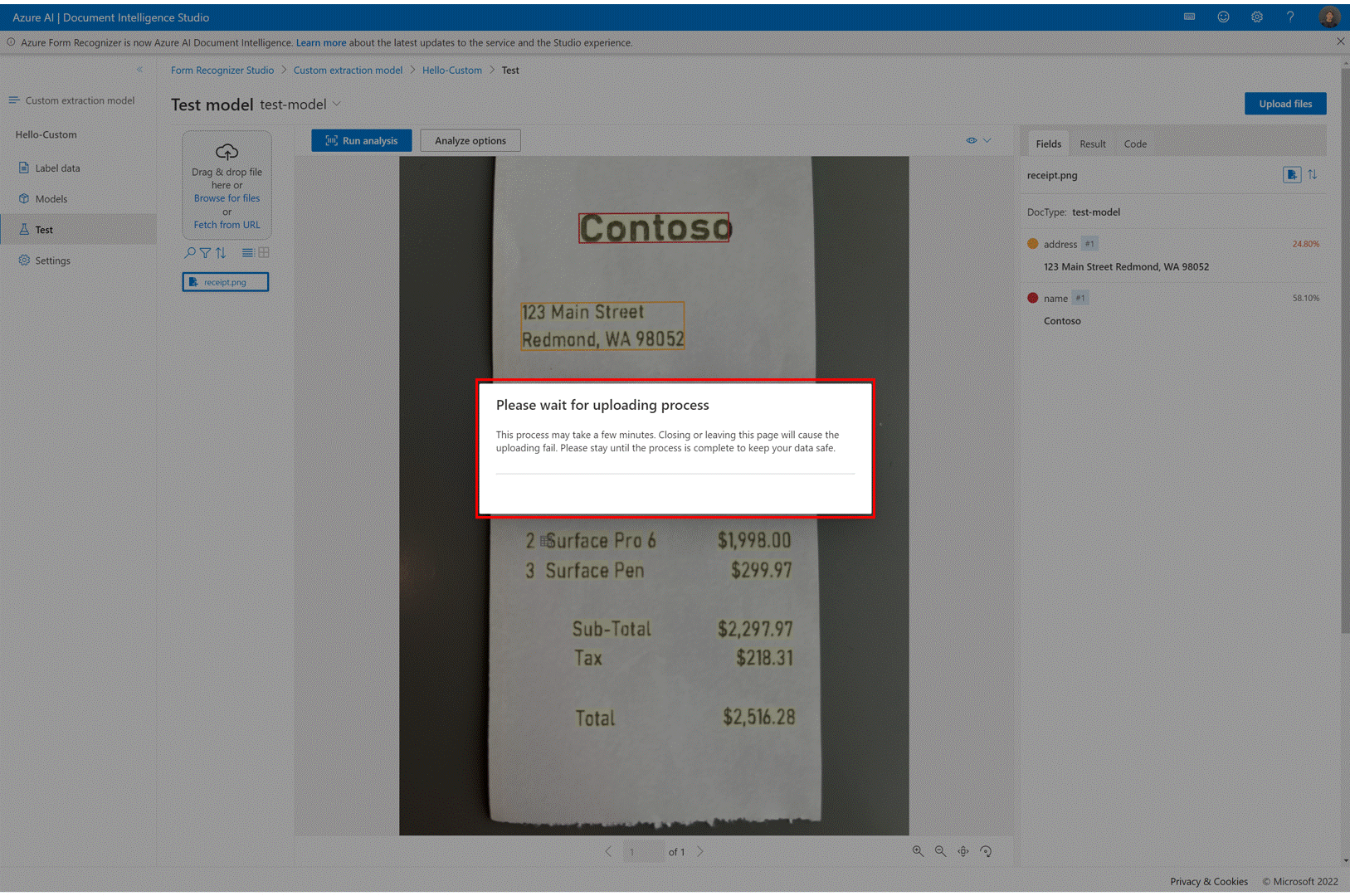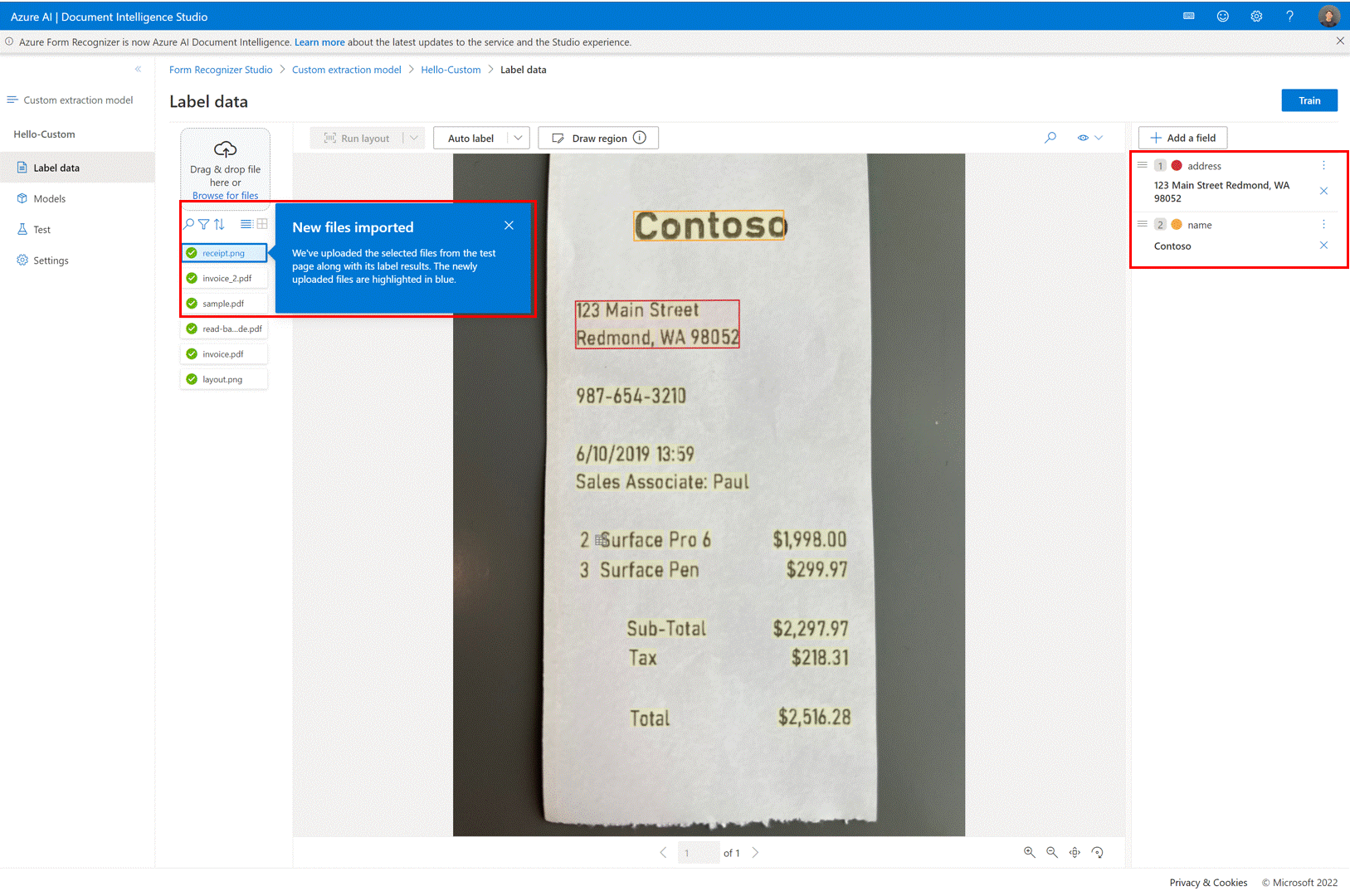
✔️ Adicionar arquivos de teste diretamente ao conjunto de dados de treinamento
Uma vez treinado um modelo de extração personalizado, use a página de teste para melhorar a qualidade do modelo, carregando documentos de teste para o conjunto de dados de treinamento, se necessário.
Se uma pontuação de baixa confiança for retornada para alguns rótulos, verifique se eles estão corretamente rotulados. Caso contrário, adicione-os ao conjunto de dados de treinamento e re-rótulo para melhorar a qualidade do modelo.
✔️ Faça uso das opções e filtros da lista de documentos em projetos personalizados
Use a página de rotulagem do modelo de extração personalizada. Agora você pode navegar pelos documentos de treinamento com facilidade usando a pesquisa, o filtro e a classificação por recurso.
Utilize o modo de exibição de grade para visualizar documentos ou use a exibição de lista para percorrer os documentos com mais facilidade.
✔️ Compartilhamento de projetos
- Compartilhe projetos de extração personalizados com facilidade. Para obter mais informações, consulte Compartilhamento de projetos com modelos personalizados.
Maio de 2023
Apresentação da documentação atualizada para o Build 2023
🆕 Visão geral do Informação de Documentos navegação aprimorada, pontos de acesso estruturados e imagens enriquecidas.
🆕 Escolher um modelo da Informação de Documentos fornece orientação para escolher a melhor solução da Informação de Documentos para seus projetos e fluxos de trabalho.
Abril de 2022
Anunciando o lançamento de pré-visualização pública mais recente da biblioteca de cliente da Informação de Documentos
A versão 28-02-2023-versão prévia da API REST da Informação de Documentos dá suporte às bibliotecas de clientes de versão de visualização pública. Esta versão inclui os seguintes novos recursos e capacidades disponíveis para bibliotecas de clientes de .NET/C# (4.1.0-beta-1), Java (4.1.0-beta-1), JavaScript (4.1.0-beta-1) e Python (3.3.0b.1):
Para obter mais informações, confiraSDK da Informação de Documentos (versão prévia pública) e Notas de versão de março de 2023
Março de 2023
Importante
As funcionalidades de 2023-02-28-preview só estão disponíveis nas seguintes regiões:
- Europa Ocidental
- Oeste dos EUA 2
- Leste dos EUA
- O modelo de classificação personalizado é um novo recurso da Informação de Documentos começando com a API
2023-02-28-preview. Experimente o recurso de classificação de documentos usando o Document Intelligence Studio ou a API REST. - Recursos de campos de consulta foram adicionados ao modelo de documento geral; use modelos de OpenAI do Azure para extrair campos específicos de documentos. Experimente o recurso Documentos gerais com campos de consulta usando o Document Intelligence Studio. No momento, os campos de consulta estão ativos apenas para recursos na região
East US. - Funcionalidades de complemento:
- A extração de fonte agora é reconhecida com a API
2023-02-28-preview. - A extração de fórmulas agora é reconhecida com a API
2023-02-28-preview. - A extração de alta resolução agora é reconhecida com a API
2023-02-28-preview.
- A extração de fonte agora é reconhecida com a API
- Atualizações personalizadas do modelo de extração:
- O modelo neural personalizado agora dá suporte a novos idiomas para treinamento e análise. Treine modelos neurais em holandês, francês, alemão, italiano e espanhol.
- O modelo personalizado agora tem uma funcionalidade de detecção de assinatura aprimorada.
- Atualizações do Document Intelligence Studio:
- Além de dar suporte a todos os novos recursos, como classificação e campos de consulta, o Estúdio agora permite o compartilhamento de projetos de modelo personalizado.
- Acréscimo de novos modelo em versão prévia restrita: Cartões de vacinação, Contratos, Formulário US Tax 1098, Formulário US Tax 1098-E e Formulário US Tax 1098-T. Para solicitar acesso a modelos de visualização fechados, preencha e envie o formulário de solicitação de versão prévia privada da Informação de Documentos.
- Atualizações do modelo de recibo:
- O modelo de recibo adiciona suporte para recibos térmicos.
- O modelo de recibo agora adiciona suporte a 18 idiomas e três idiomas regionais (inglês, francês e português).
- O modelo de recibo agora dá suporte à extração de
TaxDetails.
- O modelo de layout agora melhora o reconhecimento de tabelas.
- O modelo de leitura agora adiciona melhorias no reconhecimento de caracteres de um único dígito.
Fevereiro de 2023
Alguns contêineres da Informação de Documentos para v3.0 já estão disponíveis para uso!
No momento, os contêineres Leitura v3.0 e Layout v3.0 estão disponíveis.
Para obter mais informações, confiraInstalar e executar contêineres da Informação de Documentos.
Janeiro de 2023
Modelo de recibo predefinido – Idiomas com suporte adicionados. O modelo de recibo agora dá suporte a estes novos idiomas e localidades
- Japonês – Japão (ja-JP)
- Francês – Canadá (fr-CA)
- Neerlandês – Países Baixos (nl-NL)
- Inglês – Emirados Árabes Unidos (en-AE)
- Português – Brasil (pt-BR)
Modelo de fatura predefinido – Idiomas com suporte adicionados. O modelo de fatura agora dá suporte a estes novos idiomas e localidades
- Inglês: Estados Unidos (en-US), Austrália (en-AU), Canadá (en-CA), Reino Unido (en-GB), Índia (en-IN)
- Espanhol – Espanha (es-ES)
- Francês – França (fr-FR)
- Italiano – Itália (it-IT)
- Português – Portugal (pt-PT)
- Neerlandês – Países Baixos (nl-NL)
Modelo de fatura predefinido – Campos reconhecidos adicionados. O modelo de fatura agora reconhece estes novos campos
- Código de moeda
- Opções de pagamento
- Desconto total
- Itens tributários (somente para en-IN)
Modelo de ID predefinido – Tipos de documento com suporte adicionados. O modelo de ID agora dá suporte a estes tipos de documento adicionados
- ID militar dos EUA
Dica
Todas as atualizações de janeiro de 2023 estão disponíveis com a API REST versão 2022-08-31 (Disponibilidade geral).
Modelo de recebimento predefinido – suporte para idiomas adicionais:
O modelo de recibo prefinido adiciona suporte para os seguintes idiomas:
- Inglês – Emirados Árabes Unidos (en-AE)
- Neerlandês – Países Baixos (nl-NL)
- Francês – Canadá (fr-CA)
- Alemão (de-DE)
- Italiano (it-IT)
- Japonês – Japão (ja-JP)
- Português – Brasil (pt-BR)
Modelo de fatura predefinido—suporte para idiomas adicionais e extrações de campo
O modelo de fatura predefinida adiciona suporte para os seguintes idiomas:
- Inglês: Austrália (en-AU), Canadá (en-CA), Reino Unido (en-UK), Índia (en-IN)
- Português – Brasil (pt-BR)
O modelo de fatura prefinida agora adiciona suporte para as seguintes extrações de campo:
- Código de moeda
- Opções de pagamento
- Desconto total
- Itens tributários (somente para en-IN)
Modelo de documento de ID predefinido—suporte a tipos de documento adicionais
O modelo de documento de ID prefinida agora adiciona suporte para os seguintes tipos de documentos:
- Expansão da carteira de motorista com suporte para Índia, Canadá, Reino Unido e Austrália
- Cartões de identidade e de documentos militares dos EUA
- Documentos e carteiras de identidade da Índia (PAN e Aadhaar)
- Documentos e carteiras de identidade da Austrália (carteira com foto, ID com senha)
- Documentos e carteiras de identidade do Canadá (carteira de identidade, cartão Maple)
- Documentos e carteiras de identidade do Reino Unido (carteira de identidade nacional ou regional)
Dezembro de 2022
Atualizações do Document Intelligence Studio
A versão de dezembro do Document Intelligence Studio inclui as atualizações mais recentes do Document Intelligence Studio. Há melhorias significativas na experiência do usuário, principalmente com suporte à rotulagem de modelo personalizado.
Intervalo de páginas. Agora, o estúdio dá suporte à análise de páginas especificadas de um documento.
Rotulagem de modelo personalizado:
Executar a API de layout automaticamente. Você pode optar por executar a API de Layout para todos os documentos automaticamente no armazenamento de blobs durante o processo de instalação do modelo personalizado.
Pesquisa. Agora, o estúdio inclui a funcionalidade de pesquisa para localizar palavras em um documento. Essa melhoria permite uma navegação mais fácil durante a rotulagem.
Navegação. Você pode selecionar rótulos para direcionar palavras rotuladas em um documento.
Rotulagem de tabela automática. Depois de selecionar o ícone de tabela em um documento, você poderá optar por rotular automaticamente a tabela extraída no modo de exibição de rotulagem.
Subtipos de rótulo e subtipos de segundo nível Agora, o estúdio dá suporte a subtipos para colunas de tabela, linhas de tabela e subtipos de segundo nível para tipos como datas e números.
Agora há suporte para a criação de modelos neurais personalizados na região US Gov - Virgínia.
As versões prévias da API
2022-01-30-previewe2021-09-30-previewserão desativadas em 31 de janeiro de 2023. Atualize para a versão2022-08-31da API para evitar interrupções de serviço.
Novembro de 2022
- Anunciando a última versão estável das bibliotecas da IA do Azure para Informação de Documentos
- Esta versão inclui alterações e atualizações importantes para bibliotecas de clientes do .NET, Java, JavaScript e Python. Para obter mais informações, confiraDevBlog do SDK do Azure.
- Os aprimoramentos mais significativos são a introdução de dois novos clientes, o
DocumentAnalysisCliente oDocumentModelAdministrationClient.
Outubro de 2022
Conteúdo versionado da Informação de Documentos
A documentação do Informação de Documentos foi atualizada para apresentar uma experiência com controle de versão. Agora, você pode optar por visualizar o conteúdo direcionado à experiência
v3.0 GAou à experiênciav2.1 GA. A experiência v3.0 é a padrão.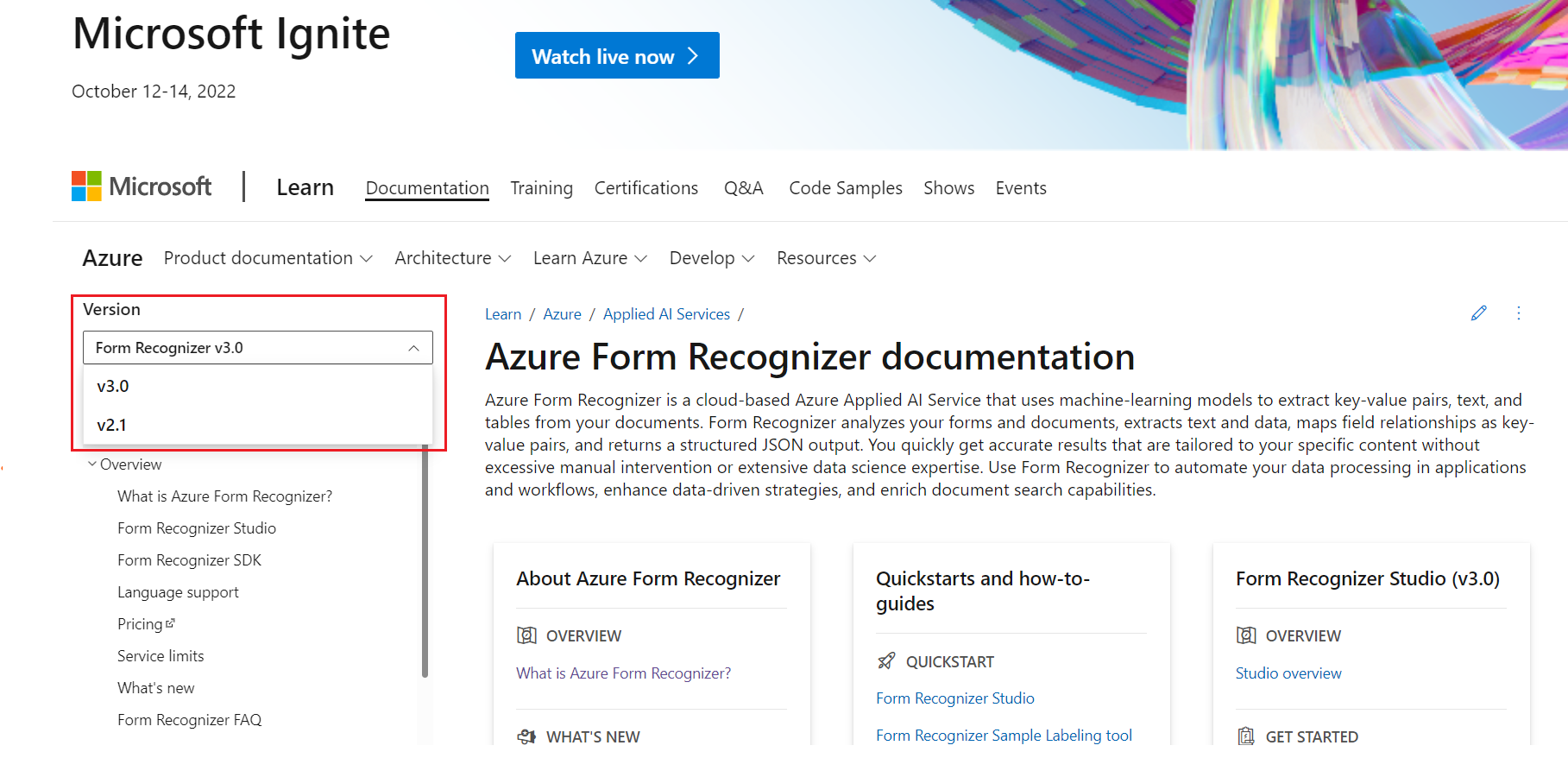
Código de amostra do Document Intelligence Studio
- O código de amostra para a experiência de rotulagem do Document Intelligence Studio agora está disponível no GitHub. Os clientes podem desenvolver e integrar a Informação de Documentos em sua própria UX ou construir sua própria nova UX usando o código de exemplo do Document Intelligence Studio.
Expansão de idioma
- Com a versão prévia mais recente, os modelos Leitura (OCR), Layout e Personalizado da Informação de Documentos dão suporte a 134 novos idiomas. Essas adições incluem grego, letão, sérvio, tailandês, ucraniano e vietnamita, juntamente com várias línguas latinas e que utilizam o alfabeto cirílico. A Informação de Documentos agora tem um total de 299 idiomas com suporte na versão em disponibilidade geral mais recente e nas novas versões prévias. Consulte a página de idiomas suportados para ver todos os idiomas suportados.
- Use o parâmetro da API REST
api-version=2022-06-30-previewao usar a API ou o SDK correspondente para oferecer suporte aos novos idiomas em seus aplicativos.
Novo modelo de contrato predefinido
- Um novo modelo de contrato predefinido que extrai informações de contratos como partes, título, ID do contrato, data de execução e muito mais. Atualmente, o modelo de contratos está em versão prévia, solicite acesso aqui.
Expansão de região para treinamento de modelos neurais personalizados
- Agora há suporte para o treinamento de modelos neurais personalizados em regiões adicionadas.
- Leste dos EUA
- Leste dos EUA 2
- Governo dos EUA do Arizona
- Agora há suporte para o treinamento de modelos neurais personalizados em regiões adicionadas.
Setembro de 2022
Observação
A partir da versão 4.0.0, um novo conjunto de clientes foi introduzido para aproveitar os recursos mais recentes do serviço Informação de Documentos.
A versão de GA 4.0.0 de SDK inclui as seguintes atualizações:
- Versão 4.0.0 GA (2022-09-08)
- Dá suporte a clientes da API REST v3.0 e v2.0
Agora há suporte para a expansão de região do treinamento de modelos neurais personalizados em seis regiões novas
- Leste da Austrália
- Centro dos EUA
- Leste da Ásia
- França Central
- Sul do Reino Unido
- Oeste dos EUA 2
Para obter uma lista completa de regiões em que há suporte para treinamento, confira Modelos neurais personalizados.
Lançamento da versão
4.0.0 GAdo SDK da Informação de Documentos:- Bibliotecas de clientes da Informação de Documentos versão 4.0.0 (.NET/C#, Java, JavaScript) e a versão 3.2.0 (Python) estão geralmente disponíveis e prontos para uso em aplicativos de produção.
- Para obter mais informações sobre bibliotecas de clientes da Informação de Documentos, confira a visão geral do SDK.
- Atualize seus aplicativos usando o guia de migração da linguagem de programação.
Agosto de 2022
A versão de visualização beta do SDK da Informação de Documentos de agosto de 2022 inclui as seguintes atualizações:
Versão 4.0.0-beta.5 (09-08-2022)
Informação de Documentos v3.0 em disponibilidade geral
- A API REST da Informação de Documentos v3.0 agora está com disponibilidade geral e pronta para uso em aplicativos de produção! Atualize os aplicativos com a API REST versão 31/08/2022.
Atualizações do Document Intelligence Studio
- Próximas etapas. Em cada página de modelo, o Studio agora tem uma próxima seção de etapas. Os usuários podem referenciar rapidamente o código de exemplo, as diretrizes de solução de problemas e as informações de preços.
- Modelos personalizados. O Estúdio agora inclui a capacidade de reordenar rótulos em projetos de modelo personalizados para melhorar a eficiência da rotulagem.
- Copiar modelos Modelos personalizados podem ser copiados nos serviços da Informação de Documentos a partir do Estúdio. A operação permite a promoção de um modelo treinado para outros ambientes e regiões.
- Excluir documentos. O Estúdio agora dá suporte à exclusão de documentos do conjunto de dados rotulado em projetos personalizados.
Atualizações de serviço da Informação de Documentos
- prebuilt-read. O modelo de Leitura OCR agora também está disponível na Informação de Documentos com parágrafos e detecção de idioma como os dois novos recursos. A Leitura da Informação de Documentos tem como alvo cenários avançados de documentos alinhados com os recursos mais amplos de inteligência de documentos na Informação de Documentos.
- prebuilt-layout. O modelo de Layout extrai parágrafos e se o texto extraído é um parágrafo, título, cabeçalho da seção, nota de rodapé, cabeçalho de página, rodapé de página ou número de página.
- prebuilt-invoice. Os campos TotalVAT e Line/VAT agora corrigem os campos TotalTax e Line/Tax existentes, respectivamente.
- prebuilt-idDocument. Suporte à extração de dados para ID de estado dos EUA, seguro social e green cards. Suporte para informações de visto de passaporte.
- prebuilt-receipt. Apoio de localidade expandido para francês (fr-FR), espanhol (es-ES), português (pt-PT), italiano (it-IT) e alemão (de-DE).
- prebuilt-businessCard. Suporte à análise de endereços para extrair subcampos de componentes do endereço, como endereço, cidade, estado, país/região e CEP.
Aprimoramentos de qualidade de IA
- prebuilt-read. Suporte aprimorado para caracteres únicos, datas manuscritas, valores, nomes, outros dados importantes comumente encontradas em recibos e faturas, bem como processamento aprimorado de documentos PDF digitais.
- prebuilt-layout. Suporte para melhor detecção de tabelas cortadas, tabelas sem bordas e reconhecimento aprimorado de células de longa abrangência.
- prebuilt-document. Melhor valor e detecção de caixa de seleção.
- custom-neural. Precisão aprimorada para detecção e extração de tabelas.
Junho de 2022
- A versão de visualização beta do SDK da Informação de Documentos de junho de 2022 inclui as seguintes atualizações:
Versão 4.0.0-beta.4 (2022-06-08)
A versão de junho do Document Intelligence Studio é a atualização mais recente do Document Intelligence Studio. Há melhorias consideráveis de experiência do usuário e acessibilidade abordadas nesta atualização:
- Exemplo de código para JavaScript e C#. A guia de código do Estúdio agora adiciona exemplos de código JavaScript e C#, além do Python existente.
- Interface do usuário de upload de documento. O Studio agora dá suporte ao upload de documentos com a opção "arrastar e soltar" na nova interface do usuário para upload.
- Novo recurso para projetos personalizados. Os projetos personalizados agora dão suporte à criação de contas de armazenamento e blobs ao serem configurados. Além disso, o projeto personalizado agora dá suporte ao carregamento de arquivos de treinamento diretamente no Studio e à cópia do modelo personalizado existente.
A versão da Informação de Documentos v3.0 30-06-2022-versão prévia apresenta atualizações abrangentes nas APIs de recursos:
- O layout estende a extração de estrutura. O layout agora inclui elementos de estrutura adicionados, como seções, cabeçalhos de seção e parágrafos. Essa atualização permite cenários de segmentação de documentos mais refinada. Para obter uma lista completa de elementos de estrutura identificados, confiraEstrutura aprimorada.
- Suporte a campos tabulares de modelo neural personalizado. Os modelos de documento personalizados agora dão suporte a campos tabulares. Por padrão, os campos tabulares também têm várias páginas. Para saber mais sobre campos tabulares em modelos neurais personalizados, confiraCampos tabulares.
- Suporte a campos tabulares de modelo personalizado para tabelas entre páginas. Os modelos de formulário personalizados agora dão suporte a campos tabulares entre páginas. Para saber mais sobre campos tabulares em modelos personalizados, confiraCampos tabulares.
- A saída do modelo de fatura agora inclui pares chave-valor do documento geral. Quando as faturas contêm campos necessários além dos campos incluídos no modelo predefinido, o modelo de documento geral complementa a saída com pares chave-valor. ConfiraPares chave-valor.
- Expansão do idioma da fatura. O modelo de fatura inclui suporte a idioma expandido. ConfiraIdiomas com suporte.
- O cartão de visita predefinido agora inclui suporte ao idioma japonês. ConfiraIdiomas com suporte.
- Modelo de documento de ID predefinido. O modelo de documento de ID agora extrai DateOfIssue, Height, Weight, EyeColor, HairColor e DocumentDiscriminator das carteiras de motorista dos EUA. ConfiraExtração de campo.
- O modelo de leitura agora dá suporte a tipos comuns de documentos do Microsoft Office. Agora há suporte para tipos de documentos como Word (docx), Excel (xlsx) e PowerPoint (pptx) com a API de Leitura. Confira Extração de dados de leitura.
Fevereiro de 2022
Versão 4.0.0-beta.3 (2022-02-10)
A versão prévia da Informação de Documentos v3.0 apresenta vários novos recursos, capacidades e melhorias:
- O Modelo neural personalizado ou modelo de documento personalizado é um novo modelo personalizado para extração de texto e marcas de seleção de formulários estruturados, documentos semiestruturados e não estruturados.
- O modelo predefinido W-2 é um novo modelo predefinido para extração de campos de formulários W-2 em cenários de relatórios de impostos e verificação de renda.
- A API de Leitura extrai linhas de texto impressas, palavras, localizações de texto, idiomas detectados e texto manuscrito, se detectado.
- O modelo pré-treinado de documento geral já está atualizado para dar suporte a marcas de seleção, além de texto de API, tabelas, estrutura e pares chave-valor em formulários e documentos.
- API de Fatura O modelo predefinido de fatura expande o suporte para faturas em espanhol.
- O Document Intelligence Studio adiciona novas demonstrações para leitura, W2, amostras de recibos de hotel e suporte para treinamento de novos modelos neurais personalizados.
- Expansão de idiomas os modelos Leitura, Layout e Formulários Personalizados da Informação de Documentos ganharam suporte para 42 novos idiomas, incluindo árabe, hindi e outros idiomas, usando scripts de árabe e Devanagari para expandir a cobertura para 164 idiomas. O suporte à linguagem manuscrita foi expandido para japonês e coreano.
Comece a usar a nova API REST, o Python ou o SDK do .NET para a API da versão prévia v3.0.
Extração de dados de modelo da Informação de Documentos:
Modelo Extração de texto Pares chave-valor Marcas de seleção Tabelas Assinaturas Ler ✓ Documentação Geral ✓ ✓ ✓ ✓ Layout ✓ ✓ ✓ Fatura ✓ ✓ ✓ ✓ Receipt ✓ ✓ ✓ Documento de identificação ✓ ✓ Cartão de visita ✓ ✓ Template personalizado ✓ ✓ ✓ ✓ ✓ Neural personalizado ✓ ✓ ✓ ✓ A versão prévia beta do SDK da Informação de Documentos inclui as seguintes atualizações:
Modos e modelos de documento personalizados:
- Modelo personalizado (formulário personalizado anteriormente).
- Neural personalizado.
- Modelo personalizado – modo de build.
Modelo predefinido W-2 (prebuilt-tax.us.w2).
Modelo predefinido de leitura (prebuilt-read).
Modelo predefinido de fatura (espanhol) (prebuilt-invoice).
Novembro de 2021
Versão 4.0.0-beta.2 (2021-11-09)
| Pacote (NuGet) | Histórico de log de alterações/versão | Documentação de referência da API
- A atualização (beta.2) da versão prévia do SDK da Inteligência de Documentos v3.0 incorpora correções de bugs e atualizações secundárias de recursos.
Outubro de 2021
A versão prévia 4.0.0-beta.1 (2021-10-07) da Inteligência de Documentos v3.0 apresenta diversos recursos e funcionalidades novos:
O modelo Documento geral é uma nova API que usa um modelo pré-treinado para extrair texto, tabelas, estrutura e pares chave-valor de formulários e documentos.
Modelo de recibo do Hotel adicionado ao processamento de recibos predefinido.
Campos expandidos para Documentação de Identidade O modelo de ID dá suporte à extração de endossos, restrições e classificação de veículos a partir de carteiras de habilitação dos EUA.
O Campo de assinatura é um novo tipo de campo em formulários personalizados para detectar a presença de uma assinatura em um campo de formulário.
Expansão de idioma Suporte para 122 idiomas (impresso) e 7 idiomas (manuscritos). O Layout da Informação de Documentos e o Formulário personalizado expandem o número de idiomas com suporte para 122 em sua versão prévia mais recente. Essa versão prévia inclui extração de texto para textos impressos em 49 novos idiomas, incluindo russo, búlgaro e outros idiomas em alfabeto cirílico, além de mais idiomas em alfabeto latino. Além disso, a extração de texto manuscrito agora dá suporte a sete idiomas que incluem o inglês e novas versões prévias do chinês simplificado, francês, alemão, italiano, português e espanhol.
Aprimoramentos da extração de texto e tabelas O layout agora dá suporte à extração de tabelas de linha única, também chamadas de tabelas chave-valor. Os aprimoramentos da extração de texto incluem um melhor processamento de PDFs digitais e texto de MRZ (zona legível por máquina) em documentos de identidade, juntamente com o desempenho geral.
Document Intelligence Studio Para simplificar o uso do serviço, agora você pode acessar o Document Intelligence Studio para testar os diferentes modelos predefinidos ou rotular e treinar um modelo personalizado.
Comece a usar a nova API REST, o Python ou o SDK do .NET para a API da versão prévia v3.0.
Extração de dados de modelo da Informação de Documentos
Modelo Extração de texto Pares chave-valor Marcas de seleção Tabelas Documentação Geral ✓ ✓ ✓ ✓ Layout ✓ ✓ ✓ Fatura ✓ ✓ ✓ ✓ Receipt ✓ ✓ Documento de identificação ✓ ✓ Cartão de visita ✓ ✓ Personalizado ✓ ✓ ✓ ✓
Setembro de 2021
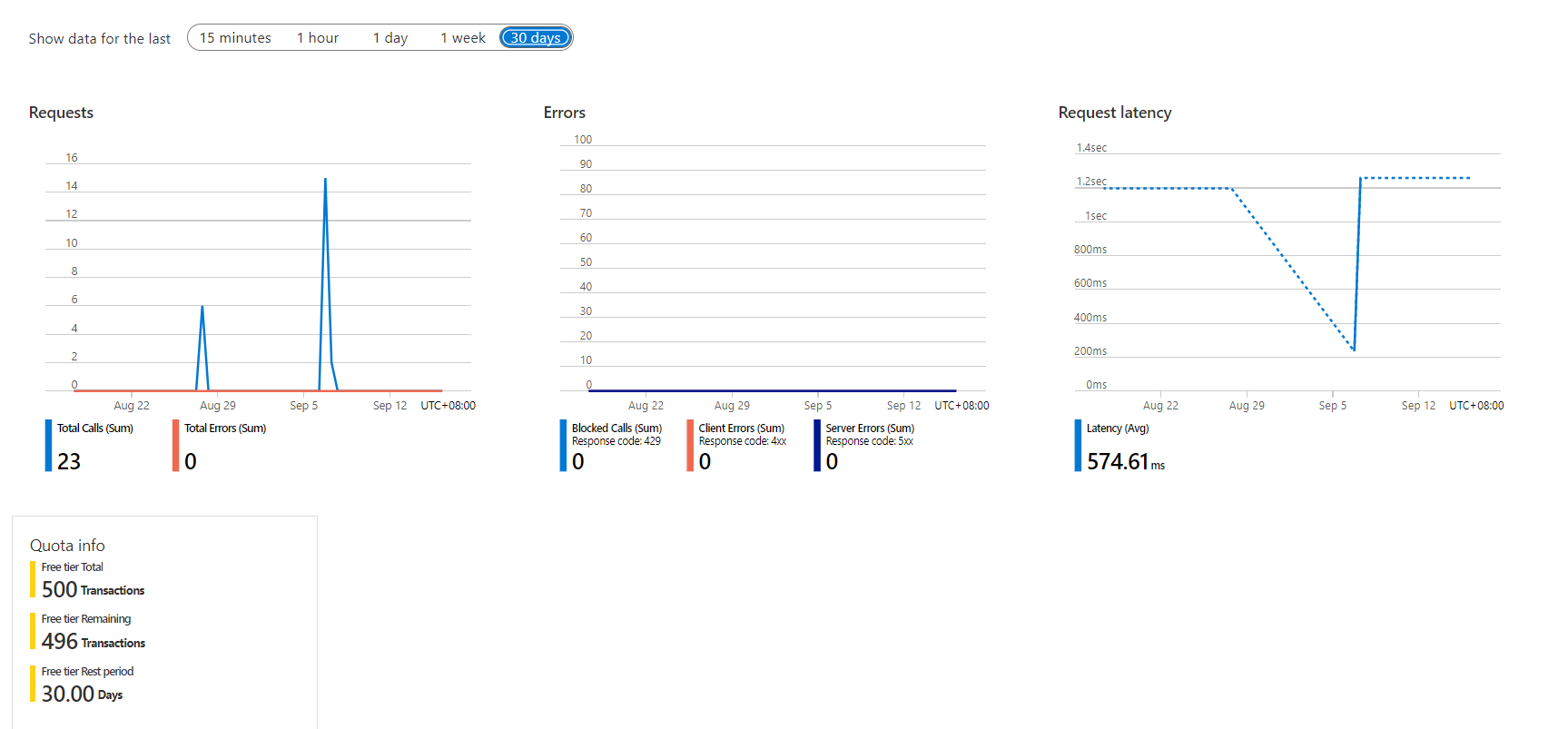
Recursos avançados do explorador de métricas do Azure estão disponíveis na página de visão geral do recurso Informação de Documentos no portal do Azure.
Menu Monitoramento:
Gráficos:
Atualização do modelo de documento de identificação: nomes fornecidos, incluindo um sufixo, com ou sem ponto (ponto final), processo com êxito:
Texto de entrada Resultado com atualização William Isaac Kirby Jr. Nome: William Isaac
Sobrenome: Kirby Jr.Henry Caleb Ross Sr Nome: Henry Caleb
Sobrenome: Ross Sr.
Julho de 2021
- Suporte à identidade gerenciada atribuída pelo sistema: agora você pode habilitar uma identidade gerenciada atribuída pelo sistema para conceder à Informação de Documentos acesso limitado a contas de armazenamento privado, incluindo contas protegidas por uma Rede Virtual, firewall ou traga seu próprio armazenamento (BYOS) habilitadas. ConfiraCriar e utilizar a identidade gerenciada para o seu recurso da Informação de Documentos para saber mais.
Junho de 2021
Agora, os contêineres v2.1 da Informação de Documentos lançados em versão prévia restrita são compatíveis com seis contêineres de recursos — Layout, Cartão de visita, Documento de identidade, Recibo, Fatura e Personalizado. Para usá-los, você deve enviar uma solicitação online e obter aprovação.
Conector da Informação de Documentos lançado em versão prévia: o conector da Informação de Documentos integra-se aos Aplicativos Lógicos do Azure, ao Microsoft Power Automate e ao Microsoft Power Apps. O conector permite ações e gatilhos de fluxo de trabalho para extrair e analisar dados e estrutura de documentos de formulários personalizados e predefinidos, faturas, recibos, cartões de visita e documentos de identidade.
SDK v3.1.0 da Informação de Documentos corrigido para v3.1.1 para C#, Java e Python. O patch aborda as faturas que não têm campos de subitens detectados, como um
FormFieldcomText, mas nenhuma informação deBoundingBoxou dePage.
Maio de 2021
- Versão 3.1.0 (26/05/2021)
Histórico de log de alterações/versão| Documentação de referência | Pacote NuGet versão 3.0.1 |
A Informação de Documentos 2.1 está em disponibilidade geral. A versão de GA marca a estabilidade das alterações introduzidas nas versões anteriores do pacote de versão prévia 2.1. Esta versão permite que você detecte e extraia informações e dados do seguintes tipos de documento:
Para começar, experimente a Ferramenta de exemplo da Inteligência de Documentos e siga o início rápido.
O recurso API de Layout de tabela atualizado adiciona o reconhecimento de cabeçalho com cabeçalhos de coluna que podem abranger várias linhas. Cada célula da tabela tem um atributo que indica se ele faz parte de um cabeçalho ou não. Essa atualização pode ser usada para identificar as linhas que compõem o cabeçalho da tabela.
Abril de 2021
Pacote NuGet versão 3.1.0-beta.4
Novos métodos para analisar dados de documentos de identidade:
StartRecognizeIdDocumentsFromUriAsync
StartRecognizeIdDocumentsAsync
Para obter uma lista de valores de campos, confiraCampos extraídos em nossa documentação da Inteligência de Documentos.
Expandido o conjunto de idiomas de documentação que pode ser fornecido para o método StartRecognizeContent .
Nova propriedade
Pagescom suporte nas seguintes classes:RecognizeBusinessCardsOptions
RecognizeCustomFormsOptions
RecognizeInvoicesOptions
RecognizeReceiptsOptionsA
Pagespropriedade permite selecionar individualmente ou um intervalo de páginas para documentos PDF e TIFF de várias páginas. Para páginas individuais, insira o número da página, por exemplo,3. Para um intervalo de páginas (como a página 2 e as páginas de 5 a 7), insira os números de página e os intervalos separados por vírgulas:2, 5-7.Nova propriedade
ReadingOrdercom suporte para a seguinte classe:A
ReadingOrderpropriedade é um parâmetro opcional que permite especificar qual algoritmo de ordem de leitura –basicounatural– deve ser aplicado para ordenar a extração de elementos de texto. Se esse campo não for especificado, o valor padrão serábasic.
- As atualizações de versão prévia do SDK para a versão da API
2.1-preview.3apresentam atualizações e aprimoramentos de recursos.
Março de 2021
A versão prévia pública da Informação de Documentos v2.1 v2.1-preview.3 foi lançada e inclui os seguintes recursos:
Novo modelo de ID predefinido O novo modelo de ID predefinido permite que os clientes obtenham IDs e retornem dados estruturados para automatizar o processamento. Ele combina nossas funcionalidades avançadas de OCR (reconhecimento óptico de caracteres) com modelos de reconhecimento de ID para extrair informações importantes de passaportes e carteiras de motorista dos EUA.
Saiba mais sobre o modelo de ID predefinido

Extração de item de linha para modelo de fatura – O modelo de fatura predefinido agora dá suporte à extração de item de linha; agora é possível extrair itens completos e suas partes: descrição, valor, quantidade, ID do produto, data e muito mais. Com uma simples chamada à API/ao SDK, é possível extrair dados úteis de suas faturas – texto, tabela, pares chave-valor e itens de linha.
Rotulagem e treinamento de tabelas supervisionados, rotulagem de valores vazios – além dos recursos de última geração de extração automática de tabelas de aprendizado profundo da Informação de Documentos, ela agora permite que os clientes rotulem e treinem em tabelas. Essa nova versão inclui a capacidade de fazer um treinamento usando itens de linha/tabelas (dinâmicos e fixos) e rotulá-los, além de treinar um modelo personalizado para extrair pares chave-valor e itens de linha. Após treinado, o modelo é capaz de extrair itens de linha como parte da saída JSON na seção documentResults.

Além de rotular tabelas, agora você pode rotular valores e regiões vazias. Quando alguns documentos no conjunto de treinamento não têm valores para determinados campos, é possível rotulá-los para que o modelo saiba como extrair valores dos documentos analisados de maneira correta.
Suporte para 66 novos idiomas – a API Layout e os Modelos Personalizados para Informação de Documentos agora dão suporte a 73 idiomas.
Saiba mais sobre o suporte a idiomas do Document Intelligence.
Ordem de leitura natural, classificação de manuscrito e seleção de página – Com essa atualização, é possível optar por obter as saídas de linha de texto na ordem de leitura natural, em vez da ordenação padrão da esquerda para a direita e de cima para baixo. Use o novo parâmetro de consulta readingOrder e defina-o como valor "natural" para uma saída de ordem de leitura mais amigável. Além disso, para línguas latinas, a Informação de Documentos classifica as linhas de texto como escritas à mão ou não e fornece uma pontuação de confiança.
Aprimoramentos de qualidade do modelo de Recibo predefinido Essa atualização inclui muitas melhorias de qualidade para o modelo de Recibo predefinido, especialmente relativo à extração de itens de linha.


Novembro de 2020
A Informação de Documentos v2.1-preview.2 foi lançada e inclui os seguintes recursos:
Novo modelo de fatura predefinido – O novo modelo de fatura predefinido permite que os clientes obtenham faturas em vários formatos e retornem dados estruturados para automatizar o processamento das faturas. Ele combina nossos poderosos recursos de OCR (reconhecimento óptico de caracteres) com modelos de aprendizado profundo de reconhecimento de faturas para extrair informações importantes das faturas em inglês. Ele extrai o texto, as tabelas e as informações importantes, como cliente, fornecedor, ID da fatura, data de vencimento da fatura, total, valor devido, valor do imposto, destinatário da remessa e recebedor da fatura.

Extração aprimorada de tabelas – a Informação de Documentos agora fornece extração aprimorada de tabelas, que combina nossos poderosos recursos de OCR (reconhecimento óptico de caracteres) com um modelo de extração de tabela de aprendizado profundo. A Inteligência de Documentos pode extrair dados de tabelas, incluindo tabelas complexas com colunas mescladas, linhas, sem bordas e muito mais.

Atualização da biblioteca do cliente – as versões mais recentes das bibliotecas cliente para .NET, Python, Java e JavaScript têm suporte para a API Informação de Documentos 2.1.
Novo idioma com suporte: japonês – Os novos idiomas a seguir agora têm suporte: para
AnalyzeLayouteAnalyzeCustomForm: Japonês (ja). Suporte ao idioma.Indicação de estilo de linha de texto (manuscrito/outro) (somente para idiomas latinos) – a Informação de Documentos agora gera um objeto
appearanceque classifica se cada linha de texto está no estilo manuscrito ou não, juntamente com uma pontuação de confiança. Esse recurso é compatível apenas com idiomas latinos.Aprimoramentos de qualidade – Aprimoramentos de extração, incluindo melhorias de extração de dígito único.
Novo recurso de teste na Ferramenta de Rotulagem de Exemplo da Informação de Documentos – capacidade de testar modelos predefinidos de Fatura, Recibo e Cartão de Visita, e uso da Ferramenta de Rotulagem de Exemplo da Informação de Documentos pela API de Layout. Veja como os dados são extraídos sem escrever nenhum código.
Experimente a ferramenta de Rotulagem de Exemplo da Informação de Documentos
- Loop de comentários – Ao analisar arquivos por meio da ferramenta de Rotulagem de Exemplos, agora você também pode adicioná-los ao conjunto de treinamento, ajustar os rótulos, se necessário, e treinar para aprimorar o modelo.
- Rotulagem automática de documentos – Rotula automaticamente os documentos adicionados, com base em documentos rotulados anteriormente no projeto.


Agosto de 2020
**O Informação de Documentos
v2.1-preview.1inclui os seguintes recursos:- A referência da API REST está disponível – Veja
v2.1-preview.1 reference. - Novos idiomas com suporte. Além do inglês, agora há suporte para os seguintes idiomas: para
LayouteTrain Custom Model: inglês (en), chinês (simplificado) (zh-Hans), holandês (nl), francês (fr), alemão (de), italiano (it), português (pt) e espanhol (es). - Detecção de caixa de seleção/marca de seleção – a Informação de Documentos oferece suporte à detecção e extração de marcas de seleção, como caixas de seleção e botões de opção. As marcas de seleção são extraídas no
Layout, e a rotulagem e o treinamento já podem ser feitos emTrain Custom Model-Layoutpara extrair pares chave-valor para marcas de seleção. - Composição de modelo – permite que vários modelos sejam compostos e chamados com uma única ID de modelo. Quando você envia um documento para ser analisado com uma ID de modelo composto, uma etapa de classificação é executada primeiro para encaminhá-lo para o modelo personalizado correto. A Composição de modelo está disponível para
Train Custom Model-Train Custom Model. - Nome do modelo – adicione um nome amigável a seus modelos personalizados para facilitar o gerenciamento e o acompanhamento.
- Novo modelo predefinido para cartões de visita para extrair campos comuns em cartões de visita no idioma inglês.
- Novos locais para os Recibos predefinidos, além de EN-US, agora também há suporte para EN-AU, EN-CA, EN-GB, EN-IN.
- Aprimoramentos de qualidade para
Layout,Train Custom Model- Treinar sem Rótulos e Treinar com Rótulos.
- A referência da API REST está disponível – Veja
A v2.0 inclui a seguinte atualização:
- As bibliotecas de clientes para .NET, Python, Java e JavaScript estão em disponibilidade geral.
Há novas amostras disponíveis no GitHub.
- A ferramenta Receitas de extração de conhecimento – guia estratégico de formulários coleta as melhores práticas de compromissos reais de clientes da Informação de Documentos e fornece exemplos de código utilizáveis, listas de verificação e pipelines de amostra usados no desenvolvimento desses projetos.
- A ferramenta de rotulagem de exemplo foi atualizada para dar suporte à nova funcionalidade da v2.1. Consulte este início rápido para começar a usar a ferramenta.
- O exemplo do Quiosque Inteligente da Informação de Documentos mostra como integrar
Analyze ReceipteTrain Custom Model- treinar sem rótulos.
Julho de 2020
- Referência da Informação de Documentos v2.0 disponível – veja a referência da API v2.0 e as bibliotecas de clientes atualizadas para .NET, Python, Java e JavaScript.
Aprimoramentos de tabela e aprimoramentos de extração – inclui aprimoramentos de precisão e aprimoramentos de extrações de tabela, especificamente a capacidade de aprender cabeçalhos e estruturas de tabelas em treinamento personalizado sem rótulos.
Suporte a moedas – Detecção e extração de símbolos de moeda globais.
Azure Gov – a Informação de Documentos agora também está disponível no Azure Governamental.
Recursos de segurança aprimorados:
- Bring Your Own Key – a Informação de Documentos criptografa automaticamente seus dados quando persistidos na nuvem para protegê-los e ajudá-lo a alcançar os compromissos de segurança e conformidade da organização. Por padrão, sua assinatura usa chaves de criptografia gerenciadas pela Microsoft. Agora você também pode gerenciar sua assinatura com suas próprias chaves de criptografia. As chaves gerenciadas pelo cliente, também conhecidas como Bring Your Own Key (BYOK), oferecem maior flexibilidade para criar, alternar, desabilitar e revogar controles de acesso. Você também pode auditar as chaves de criptografia usadas para proteger seus dados.
- Pontos de extremidade privados – Permitem acessar dados com segurança por meio de um Link Privado.
Junho de 2020
- API CopyModel adicionada às bibliotecas de clientes – Agora você pode usar as bibliotecas de clientes para copiar modelos de uma assinatura para outra. Confira Fazer backup e recuperar modelos para obter informações gerais sobre esse recurso.
- Integração do Azure Active Directory – agora você pode usar suas credenciais do Azure AD para autenticar seus objetos de cliente da Informação de Documentos nas bibliotecas de clientes.
- Alterações específicas do SDK – Essa alteração inclui adições de recursos menores e alterações de rompimento. Para obter mais informações, confira os logs de alterações do SDK.
Abril de 2020
- Versão prévia do suporte do SDK para a API da Informação de Documentos v2.0 – este mês expandimos nosso suporte de serviço para incluir uma versão prévia do SDK para a Informação de Documentos v2.0. Use estes links para começar com o idioma de sua escolha:
- SDK .NET
- Java SDK
- SDK do Python
- SDK do JavaScript
O novo SDK é compatível com todos os recursos da API REST v2.0 para a Informação de Documentos. Você pode compartilhar seus comentários sobre as bibliotecas de clientes por meio do formulário de comentários do SDK.
Copiar Modelo Personalizado Agora você pode copiar modelos entre regiões e assinaturas usando o novo recurso Copiar Modelo Personalizado. Antes de invocar a API Copiar Modelo Personalizado, obtenha autorização para copiar dados no recurso de destino. Essa autorização é protegida chamando a operação Autorização de Cópia no ponto de extremidade do recurso de destino.
API REST.Gerar uma autorização de cópia.
API REST Copiar um modelo personalizado.
Aprimoramentos de segurança.
As chaves gerenciadas pelo cliente já estão disponíveis para o FormRecognizer. Para obter mais informações, confira Criptografia de dados em repouso para a Informação de Documentos.
Use identidades gerenciadas para acessar recursos do Azure com o Azure Active Directory. Para obter mais informações, consulte Autorizar o acesso a identidades gerenciadas.
Março de 2020
- Tipos de valores para rotulagem Agora você pode especificar os tipos de valores que você está rotulando com a ferramenta Rotulagem de Exemplo da Informação de Documentos. Os tipos de valor e as variações a seguir são compatíveis no momento:
string- padrão,
no-whitespaces,alphanumeric
- padrão,
number- padrão,
currency
- padrão,
date- padrão,
dmy,mdy,ymd
- padrão,
timeinteger
Confira o guia da ferramenta de Rotulagem de Exemplos para saber como usar esse recurso.
Visualização de tabela A ferramenta de Rotulagem de Exemplos agora exibe tabelas que foram reconhecidas no documento. Esse recurso permite exibir as tabelas reconhecidas e extraídas do documento, antes de rotular e analisar. Esse recurso pode ser ativado/desativado usando a opção de camadas.
A imagem a seguir é um exemplo de como as tabelas são reconhecidas e extraídas:
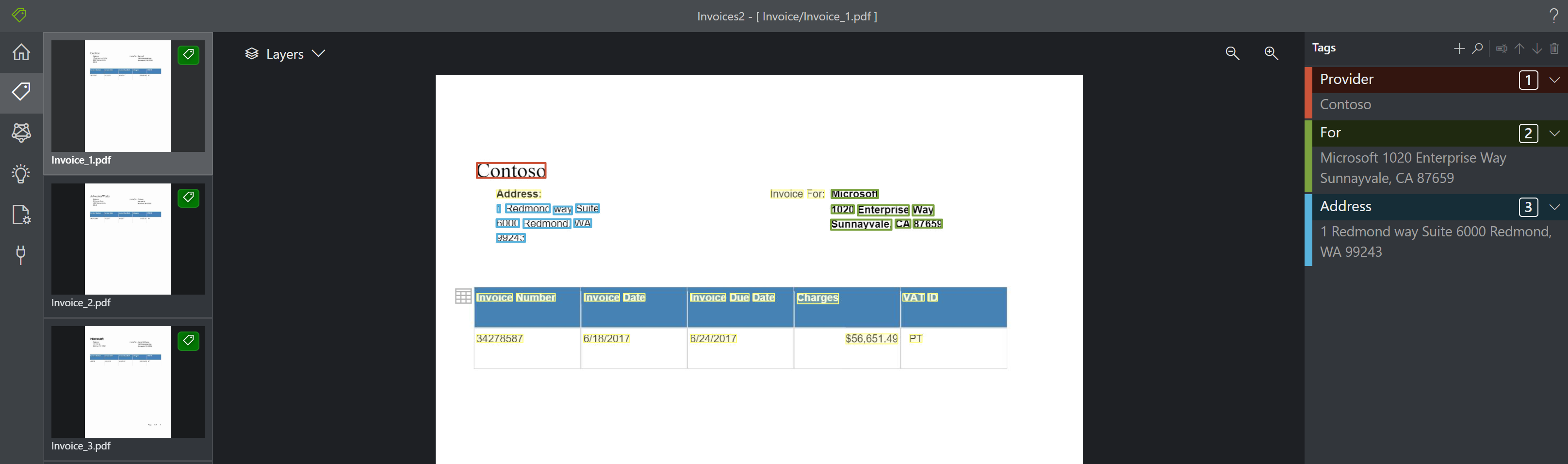
As tabelas extraídas estão disponíveis na saída JSON em
"pageResults".Importante
Não há suporte para rotular tabelas. Se as tabelas não forem reconhecidas nem extraídas automaticamente, você só poderá rotulá-las como pares chave/valor. Ao rotular tabelas como pares chave/valor, rotule cada célula como um valor exclusivo.
Aprimoramentos de extração.
Esta versão inclui aprimoramentos de extração e melhorias de precisão, especificamente, a capacidade de rotular e extrair vários pares chave/valor na mesma linha de texto.
A ferramenta de rotulagem de amostra agora é de código aberto.
A ferramenta Rotulagem de Exemplo da Informação de Documentos agora está disponível como um projeto de código aberto. Você pode integrá-la em suas soluções e fazer alterações específicas do cliente para atender às suas necessidades.
Para obter mais informações sobre a Ferramenta de Rotulagem de Exemplo da Informação de Documentos, revise a documentação disponível no GitHub.
TLSImposição de 1.2.Agora o
TLS1.2 é obrigatório para todas as solicitações HTTP a este serviço. Para obter mais informações, consulte a segurança dos serviços de IA do Azure.
Janeiro de 2020
Esta versão apresenta a Informação de Documentos 2.0. Nas próximas seções, você encontrará mais informações sobre novos recursos, aprimoramentos e alterações.
Novos recursos
Modelo personalizado
- Treinar com rótulos Agora você pode treinar um modelo personalizado usando dados rotulados manualmente. Esse método resulta em modelos de melhor desempenho e pode produzir modelos que funcionam com formulários complexos ou formulários que contêm valores sem chaves.
- API Assíncrona Você pode usar chamadas à API assíncronas para treinar e analisar grandes conjuntos de dados e arquivos.
- Suporte a arquivos TIFF Agora você pode treinar e extrair dados de documentos TIFF.
- Aprimoramentos na precisão da extração.
Modelo de recibo predefinido
- Valores de gorjeta Agora você pode extrair valores de gorjeta e outros valores manuscritos.
- Extração de item de linha Você pode extrair valores de item de linha de recibos.
- Valores de confiança Você pode exibir a confiança do modelo para cada valor extraído.
- Aprimoramentos na precisão da extração.
- Extração de layout Agora você pode usar a API de Layout para extrair dados de texto e dados de tabela em seus formulários.
Alterações da API de modelo personalizado
Todas as APIs para treinamento e uso de modelos personalizados foram renomeadas, e alguns métodos síncronos agora são assíncronos. A seguir estão as alterações mais significativas:
- O processo de treinamento de um modelo agora é assíncrono. Você inicia o treinamento por meio da chamada à API /custom/models. Essa chamada retorna uma ID de operação, que pode ser passada em custom/models/{modelID} para retornar os resultados de treinamento.
- A extração de chave/valor agora é iniciada pela chamada à API /custom/models/{modelID}/analyze. Essa chamada retorna uma ID de operação, que pode ser passada em custom/models/{modelID}/analyzeResults/{resultID} para retornar os resultados de extração.
- As IDs de operação para a operação de treinamento agora estão localizadas no cabeçalho Location das respostas HTTP, não no cabeçalho Operation-Location.
Alterações da API de recibo
As APIs para leitura recibos de vendas foram renomeadas.
A extração de dados de recibos agora é iniciada pela chamada à API /prebuilt/receipt/analyze. Essa chamada retorna uma ID de operação, que pode ser passada em /prebuilt/receipt/analyzeResults/{resultID} para retornar os resultados de extração.
Alterações do formato de saída
- As respostas JSON para todas as chamadas à API têm novos formatos. Algumas chaves e valores foram adicionadas, removidas ou renomeadas. Consulte os guias de início rápido para obter exemplos dos formatos JSON atuais.
Próximas etapas
Experimente processar seus próprios formulários e documentos com o Estúdio da Informação de Documentos.
Execute um início rápido do serviço Informação de Documentos e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.
Tente processar seus próprios formulários e documentos com a ferramenta Rotulagem de Amostra da Informação de Documentos.
Execute um início rápido do serviço Informação de Documentos e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.