Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Um data lake é um repositório de armazenamento que contém uma grande quantidade de dados em seu formato nativo e bruto. Os repositórios Data lake são otimizados para dimensionar seu tamanho para terabytes e petabytes de dados. Normalmente, os dados vêm de várias fontes e podem incluir dados estruturados, semiestruturados ou não estruturados. O data lake ajuda você a armazenar tudo em seu estado original, não transformado. Esse método é diferente de um data warehouse tradicional, que transforma e processa os dados no momento da ingestão.

Os principais casos de uso do data lake incluem:
- Movimentação de dados na nuvem e na Internet das Coisas (IoT).
- Processamento de Big Data.
- Análise.
- Relatório.
- Movimentação de dados no local.
Considere as seguintes vantagens de um data lake:
Um data lake nunca exclui dados porque os armazena em seu formato bruto. Esse recurso é especialmente útil em um ambiente de Big Data porque talvez você não saiba com antecedência quais informações pode obter com os dados.
Os usuários podem explorar os dados e criar suas próprias consultas.
Um data lake pode ser mais rápido do que as ferramentas tradicionais de extração, transformação e carregamento (ETL).
Um data lake é mais flexível do que um data warehouse porque ele pode armazenar dados não estruturados e semiestruturados.
Uma solução de data lake completa consiste no processamento e armazenamento. O armazenamento do data lake é projetado para tolerância a falhas, escalabilidade infinita e ingestão com alta velocidade de dados em vários formatos e tamanhos. O processamento do data lake envolve um ou mais mecanismos de processamento que podem incorporar essas metas e operar em dados armazenados em um data lake em grande escala.
Quando você deve usar um data lake
Recomendamos que você use um data lake para exploração de dados, análise de dados e aprendizado de máquina.
Um data lake pode agir como a fonte de dados para um data warehouse. Quando você usa esse método, o data lake ingere dados brutos e os transforma em um formato estruturado consultável. Normalmente, essa transformação usa um pipeline de ELT (extrair, carregar, transformar) no qual os dados são incluídos e transformados no local. Os dados de origem relacional podem ir diretamente para o data warehouse por meio de um processo ETL e ignorar o data lake.
Você pode usar Data Lake Stores em cenários de streaming de eventos ou de IoT porque os data lakes podem persistir grandes quantidades de dados relacionais e não relacionais sem transformação nem definição de esquema. Os data lakes podem lidar com grandes volumes de pequenas gravações em baixa latência e são otimizados para alta taxa de transferência.
A tabela a seguir compara data lakes e data warehouses.
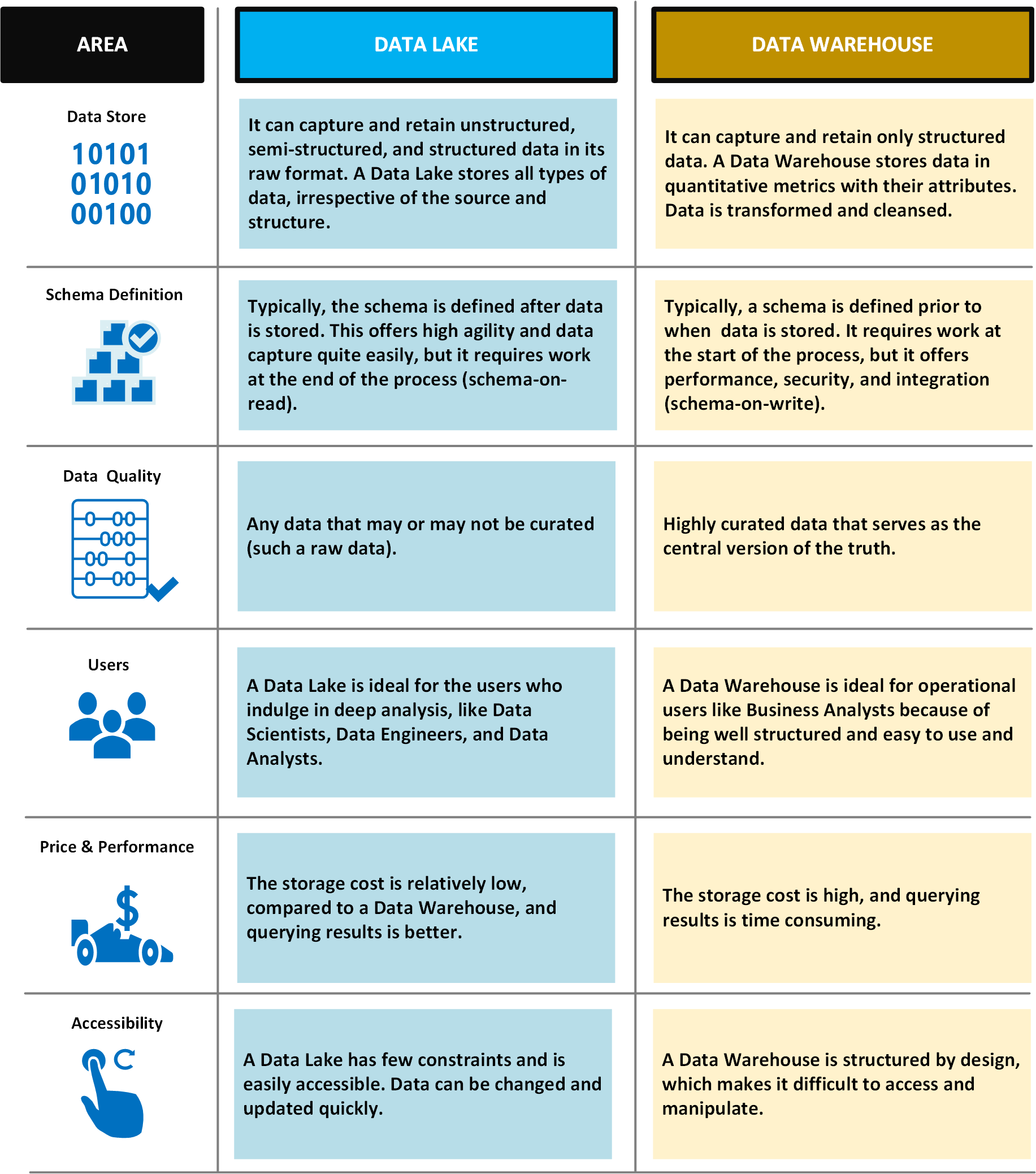
Desafios
Grandes volumes de dados: o gerenciamento de grandes quantidades de dados brutos e não estruturados pode ser complexo e consome muitos recursos, portanto, você precisa de infraestrutura e ferramentas robustas.
Gargalos potenciais: o processamento de dados pode introduzir atrasos e ineficiências, especialmente quando você tem grandes volumes e diversos tipos de dados.
Riscos de corrupção de dados: a validação e o monitoramento inadequados dos dados apresentam um risco de corrupção deles, o que pode comprometer a integridade do data lake.
Problemas de controle de qualidade: a qualidade adequada dos dados é um desafio devido à variedade de fontes e formatos de dados. Você deve implementar práticas rigorosas de governança de dados.
Problemas de desempenho: o desempenho da consulta pode diminuir à medida que o data lake cresce, portanto, você deve otimizar as estratégias de armazenamento e processamento.
Opções de tecnologia
Ao criar uma solução abrangente de data lake no Azure, considere as seguintes tecnologias:
O Azure Data Lake Storage combina o Armazenamento de Blobs do Azure com recursos de data lake, que fornecem acesso compatível com o Apache Hadoop, recursos de namespace hierárquico e segurança aprimorada para análise eficiente de Big Data.
O Azure Databricks é uma plataforma unificada que você pode usar para processar, armazenar, analisar e monetizar dados. Ele oferece suporte a processos ETL, painéis, segurança, exploração de dados, aprendizado de máquina e IA generativa.
O Azure Synapse Analytics é um serviço unificado que você pode usar para ingerir, explorar, preparar, gerenciar e fornecer dados para as necessidades imediatas de business intelligence e aprendizado de máquina. Ele se integra profundamente aos data lakes do Azure para que você possa consultar e analisar grandes conjuntos de dados com eficiência.
O Azure Data Factory é um serviço de integração de dados baseado em nuvem que você pode usar para criar fluxos de trabalho controlados por dados para orquestrar e automatizar a movimentação e a transformação de dados.
O Microsoft Fabric é uma plataforma de dados abrangente que unifica engenharia de dados, ciência de dados, armazenamento de dados, análise em tempo real e business intelligence em uma única solução.
Colaboradores
Esse artigo é mantido pela Microsoft. Ele foi originalmente escrito pelos colaboradores a seguir.
Autor principal:
- Avijit Prasad | Consultor de nuvem
Para ver perfis não públicos do LinkedIn, entre no LinkedIn.
Próximas etapas
- o que é OneLake?
- Introdução ao Data Lake Storage
- Documentação do Azure Data Lake Analytics
- Treinamento: Introdução ao Data Lake Storage
- Integração do Hadoop e do Azure Data Lake Storage
- Conectar ao Data Lake Storage e ao Blob Storage
- Carregar dados no Data Lake Storage com o Azure Data Factory