Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Configure um banco de dados no SQL Database e o aplicativo cliente para realizar o failover para uma região remota e teste um plano de failover. Você aprenderá como:
- Criar um grupo de contingência
- Executar um aplicativo Java para consultar um banco de dados no Banco de Dados SQL
- Teste de Failover
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
Observação
Este artigo usa o módulo do PowerShell Azure Az, que é o módulo do PowerShell recomendado para interagir com o Azure. Para começar a usar o módulo do Az PowerShell, confira Instalar o Azure PowerShell. Para saber como migrar para o módulo Az PowerShell, confira Migrar o Azure PowerShell do AzureRM para o Az.
Importante
O módulo AzureRM (Azure Resource Manager) do PowerShell foi preterido em 29 de fevereiro de 2024. Todo o desenvolvimento futuro deve usar o módulo Az.Sql. Os usuários são aconselhados a migrar do AzureRM para o módulo do Az PowerShell para garantir o suporte e as atualizações contínuas. O módulo AzureRM não é mais mantido ou tem suporte. Os argumentos para os comandos no módulo do Az PowerShell e nos módulos do AzureRM são substancialmente idênticos. Para obter mais informações sobre sua compatibilidade, consulte Apresentando o novo módulo do Az PowerShell.
Para concluir o tutorial, verifique se você instalou os seguintes itens:
- PowerShell do Azure
- Um banco de dados individual no Banco de Dados SQL do Azure. Para criar um, use,
- O tutorial usa o
AdventureWorksLTbanco de dados de exemplo, que é o banco de dados de exemplo opcional carregado quando você cria um novo Banco de Dados SQL do Azure.
Importante
Não se esqueça de configurar regras de firewall para usar o endereço IP público do computador em que você está executando as etapas nesse tutorial. As regras de firewall no nível do banco de dados serão replicadas automaticamente para o servidor secundário.
Para obter informações, consulte Criar uma regra de firewall no nível do banco de dados ou para determinar o endereço IP usado para a regra de firewall no nível do servidor para seu computador , consulte Início Rápido: Criar uma regra de firewall no nível do servidor no portal do Azure.
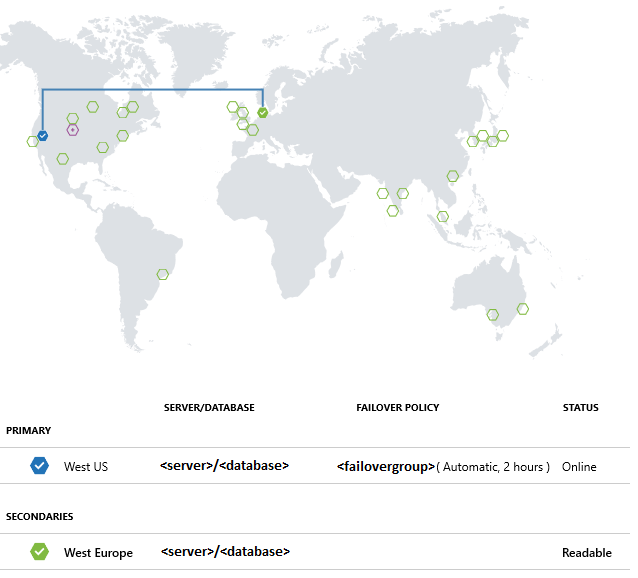
Criar o grupo de contingência
Usando o Azure PowerShell, crie grupos de failover entre um servidor existente e um servidor novo em outra região. Em seguida, adicione o banco de dados de exemplo ao grupo de failover.
Importante
Este exemplo exige o Azure PowerShell Az 1.0 ou posterior. Execute Get-Module -ListAvailable Az para ver quais versões estão instaladas.
Se é preciso instalar, consulte Instalar o módulo do Azure PowerShell.
Execute Connect-AzAccount para entrar no Azure.
Para criar um grupo de failover, execute o seguinte script:
$admin = "<adminName>"
$password = "<password>"
$resourceGroup = "<resourceGroupName>"
$location = "<resourceGroupLocation>"
$server = "<serverName>"
$database = "<databaseName>"
$drLocation = "<disasterRecoveryLocation>"
$drServer = "<disasterRecoveryServerName>"
$failoverGroup = "<globallyUniqueFailoverGroupName>"
# create a backup server in the failover region
New-AzSqlServer -ResourceGroupName $resourceGroup -ServerName $drServer `
-Location $drLocation -SqlAdministratorCredentials $(New-Object -TypeName System.Management.Automation.PSCredential `
-ArgumentList $admin, $(ConvertTo-SecureString -String $password -AsPlainText -Force))
# create a failover group between the servers
New-AzSqlDatabaseFailoverGroup –ResourceGroupName $resourceGroup -ServerName $server `
-PartnerServerName $drServer –FailoverGroupName $failoverGroup –FailoverPolicy Automatic -GracePeriodWithDataLossHours 2
# add the database to the failover group
Get-AzSqlDatabase -ResourceGroupName $resourceGroup -ServerName $server -DatabaseName $database | `
Add-AzSqlDatabaseToFailoverGroup -ResourceGroupName $resourceGroup -ServerName $server -FailoverGroupName $failoverGroup
As configurações de replicação geográfica também podem ser alteradas no portal do Azure selecionando seu banco de dados, em seguida Configurações>Replicação geográfica.
Executar o projeto de exemplo
No console, crie um projeto do Maven com o seguinte comando:
mvn archetype:generate "-DgroupId=com.sqldbsamples" "-DartifactId=SqlDbSample" "-DarchetypeArtifactId=maven-archetype-quickstart" "-Dversion=1.0.0"Digite Y e pressione Enter.
Altere os diretórios para o novo projeto.
cd SqlDbSampleUsando seu editor favorito, abra o arquivo pom.xml na pasta do projeto.
Adicione a dependência do Microsoft JDBC Driver para SQL Server adicionando a seção
dependencya seguir. A dependência deve ser colada dentro da seçãodependenciesmaior.<dependency> <groupId>com.microsoft.sqlserver</groupId> <artifactId>mssql-jdbc</artifactId> <version>6.1.0.jre8</version> </dependency>Especifique a versão de Java adicionando a seção
propertiesapós a seçãodependencies:<properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> </properties>Dê suporte a arquivos de manifesto adicionando a seção
buildapós a seçãoproperties:<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <version>3.0.0</version> <configuration> <archive> <manifest> <mainClass>com.sqldbsamples.App</mainClass> </manifest> </archive> </configuration> </plugin> </plugins> </build>Salve e feche o arquivo pom.xml.
Abra o arquivo de App.java localizado
..\SqlDbSample\src\main\java\com\sqldbsamplese substitua o conteúdo pelo seguinte código:package com.sqldbsamples; import java.sql.Connection; import java.sql.Statement; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.Timestamp; import java.sql.DriverManager; import java.util.Date; import java.util.concurrent.TimeUnit; public class App { private static final String FAILOVER_GROUP_NAME = "<your failover group name>"; // add failover group name private static final String DB_NAME = "<your database>"; // add database name private static final String USER = "<your admin>"; // add database user private static final String PASSWORD = "<password>"; // add database password private static final String READ_WRITE_URL = String.format("jdbc:" + "sqlserver://%s.database.windows.net:1433;database=%s;user=%s;password=%s;encrypt=true;" + "hostNameInCertificate=*.database.windows.net;loginTimeout=30;", FAILOVER_GROUP_NAME, DB_NAME, USER, PASSWORD); private static final String READ_ONLY_URL = String.format("jdbc:" + "sqlserver://%s.secondary.database.windows.net:1433;database=%s;user=%s;password=%s;encrypt=true;" + "hostNameInCertificate=*.database.windows.net;loginTimeout=30;", FAILOVER_GROUP_NAME, DB_NAME, USER, PASSWORD); public static void main(String[] args) { System.out.println("#######################################"); System.out.println("## GEO DISTRIBUTED DATABASE TUTORIAL ##"); System.out.println("#######################################"); System.out.println(""); int highWaterMark = getHighWaterMarkId(); try { for(int i = 1; i < 1000; i++) { // loop will run for about 1 hour System.out.print(i + ": insert on primary " + (insertData((highWaterMark + i)) ? "successful" : "failed")); TimeUnit.SECONDS.sleep(1); System.out.print(", read from secondary " + (selectData((highWaterMark + i)) ? "successful" : "failed") + "\n"); TimeUnit.SECONDS.sleep(3); } } catch(Exception e) { e.printStackTrace(); } } private static boolean insertData(int id) { // Insert data into the product table with a unique product name so we can find the product again String sql = "INSERT INTO SalesLT.Product " + "(Name, ProductNumber, Color, StandardCost, ListPrice, SellStartDate) VALUES (?,?,?,?,?,?);"; try (Connection connection = DriverManager.getConnection(READ_WRITE_URL); PreparedStatement pstmt = connection.prepareStatement(sql)) { pstmt.setString(1, "BrandNewProduct" + id); pstmt.setInt(2, 200989 + id + 10000); pstmt.setString(3, "Blue"); pstmt.setDouble(4, 75.00); pstmt.setDouble(5, 89.99); pstmt.setTimestamp(6, new Timestamp(new Date().getTime())); return (1 == pstmt.executeUpdate()); } catch (Exception e) { return false; } } private static boolean selectData(int id) { // Query the data previously inserted into the primary database from the geo replicated database String sql = "SELECT Name, Color, ListPrice FROM SalesLT.Product WHERE Name = ?"; try (Connection connection = DriverManager.getConnection(READ_ONLY_URL); PreparedStatement pstmt = connection.prepareStatement(sql)) { pstmt.setString(1, "BrandNewProduct" + id); try (ResultSet resultSet = pstmt.executeQuery()) { return resultSet.next(); } } catch (Exception e) { return false; } } private static int getHighWaterMarkId() { // Query the high water mark id stored in the table to be able to make unique inserts String sql = "SELECT MAX(ProductId) FROM SalesLT.Product"; int result = 1; try (Connection connection = DriverManager.getConnection(READ_WRITE_URL); Statement stmt = connection.createStatement(); ResultSet resultSet = stmt.executeQuery(sql)) { if (resultSet.next()) { result = resultSet.getInt(1); } } catch (Exception e) { e.printStackTrace(); } return result; } }Salve e feche o arquivo App.java.
No console de comando, execute o seguinte comando:
mvn packageInicie o aplicativo que será executado por cerca de 1 hora até ser interrompido manualmente, permitindo que você tenha tempo para executar o teste de failover.
mvn -q -e exec:java "-Dexec.mainClass=com.sqldbsamples.App"####################################### ## GEO DISTRIBUTED DATABASE TUTORIAL ## ####################################### 1. insert on primary successful, read from secondary successful 2. insert on primary successful, read from secondary successful 3. insert on primary successful, read from secondary successful ...
Teste de Failover
Execute os scripts a seguir para simular um failover e observe os resultados do aplicativo. Observe como algumas inserções e seleções falharão durante a migração do banco de dados.
É possível verificar a função do servidor de recuperação de desastre durante o teste com o seguinte comando:
(Get-AzSqlDatabaseFailoverGroup -FailoverGroupName $failoverGroup `
-ResourceGroupName $resourceGroup -ServerName $drServer).ReplicationRole
Para testar um failover:
Inicie um failover manual do grupo de failover:
Switch-AzSqlDatabaseFailoverGroup -ResourceGroupName $resourceGroup ` -ServerName $drServer -FailoverGroupName $failoverGroupReverta o grupo de failover de volta para o servidor primário:
Switch-AzSqlDatabaseFailoverGroup -ResourceGroupName $resourceGroup ` -ServerName $server -FailoverGroupName $failoverGroup
Conteúdo relacionado
- Lista de verificação de alta disponibilidade e recuperação de desastre
- Continuidade dos negócios no Banco de Dados SQL do Azure
- Disponibilidade por meio de redundância – Banco de Dados SQL do Azure
- Melhores práticas e visão geral dos grupos de failover (Banco de Dados SQL do Azure)
- Replicação geográfica ativa