Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure![]() Banco de dados SQL no Fabric
Banco de dados SQL no Fabric
Este artigo descreve a arquitetura do Banco de Dados SQL do Azure e do Banco de Dados SQL no Fabric, que alcançam disponibilidade por meio de redundância local e alta disponibilidade por meio de redundância de zona.
Overview
O Banco de Dados SQL do Azure e o Banco de Dados SQL no Fabric são executados na versão estável mais recente do Mecanismo de Banco de Dados do SQL Server no sistema operacional Windows com todos os patches aplicáveis. O Banco de Dados SQL cuida automaticamente de tarefas de manutenção críticas, como aplicação de patch, backups, atualizações do SQL do Azure e do Windows, bem como eventos não planejados, como hardware subjacente, software ou falhas de rede. Quando um banco de dados ou pool elástico no Banco de Dados SQL é corrigido ou falha, o tempo de inatividade não é perceptível se você empregar a lógica de repetição no seu aplicativo. O Banco de Dados SQL pode se recuperar rapidamente, até nas circunstâncias mais críticas, garantindo que seus dados estejam sempre disponíveis. A maioria dos usuários não percebe que as atualizações são executadas de modo contínuo.
Por padrão, o Banco de Dados SQL do Azure obtém disponibilidade por meio da redundância local, certificando-se de que seu banco de dados lida com interrupções como:
- Operações de gerenciamento iniciadas pelo cliente que resultam em um curto tempo de inatividade
- Operações de manutenção de serviços
- Problemas com:
- rack em que os computadores que alimentam seu serviço estão em execução
- o computador físico que hospeda o mecanismo de banco de dados de SQL
- Outros problemas com o mecanismo de banco de dados de SQL
- Outras possíveis interrupções locais não planejadas
A solução de disponibilidade padrão foi projetada para garantir que os dados confirmados nunca sejam perdidos devido a falhas, que as operações de manutenção tenham impactos mínimos na carga de trabalho e que o banco de dados não seja um único ponto de falha em sua arquitetura de software.
No entanto, para minimizar o impacto em seus dados no caso de uma interrupção em uma zona inteira, você pode alcançar alta disponibilidade habilitando a redundância de zona. Sem redundância de zona, os failovers ocorrem localmente no mesmo data center, o que pode resultar na não disponibilidade do banco de dados até que a interrupção seja resolvida. A única maneira de recuperar é por meio de uma solução de recuperação de desastre, como failover geográfico por meio da replicação geográfica ativa, grupos de failover ou uma restauração geográfica de um backup com redundância geográfica. Para saber mais, revise a visão geral da continuidade dos negócios.
Há três modelos de arquitetura de alta disponibilidade:
- Modelo de armazenamento remoto que se baseia em uma separação de computação e armazenamento. O modelo de armazenamento remoto depende da disponibilidade e confiabilidade da camada de armazenamento remoto. Essa arquitetura destina-se a aplicativos de negócios orientados para o orçamento que podem tolerar alguma degradação de desempenho durante atividades de manutenção.
- Modelo de armazenamento local que se baseia em um cluster de processos do mecanismo de banco de dados. O modelo de armazenamento local depende do fato de que sempre há um quorum de nós disponíveis do mecanismo de banco de dados. Essa arquitetura destina-se a aplicativos de missão crítica com alto desempenho de E/S, alta taxa de transações, e garante o impacto mínimo no desempenho da carga de trabalho durante as atividades de manutenção.
- Modelo de hiperescala que usa um sistema distribuído de componentes altamente disponíveis, como nós de computação, servidores de página, serviço de log e armazenamento persistente. Cada componente que dá suporte a um banco de dados de Hiperescala fornece sua redundância e resiliência a falhas. Os nós de computação, servidores de página e serviço de log são executados no Azure Service Fabric, que controla a integridade de cada componente e executa failovers para nós íntegros disponíveis, conforme necessário. O armazenamento persistente usa o Armazenamento do Azure com seus recursos de alta disponibilidade e redundância nativos. Para obter mais informações, confira Arquitetura de Hiperescala.
Em cada um dos três modelos de disponibilidade, o Banco de Dados SQL dá suporte a opções de redundância local e redundância de zona. A redundância local fornece resiliência em um datacenter, enquanto a redundância de zona melhora ainda mais a resiliência, protegendo-se contra interrupções de uma zona de disponibilidade dentro de uma região.
A seguinte tabela mostra as opções de disponibilidade com base nas camadas de serviço:
| Nível de serviço | Modelo de alta disponibilidade | Disponibilidade com redundância local | Disponibilidade com redundância de zona |
|---|---|---|---|
| Uso Geral (vCore) | Armazenamento remoto | Yes | Yes |
| Comercialmente Crítico (vCore) | Armazenamento local | Yes | Yes |
| Hiperescala (vCore) | Hiperescala | Yes | Yes |
| Básico (DTU) | Armazenamento remoto | Yes | No |
| Padrão (DTU) | Armazenamento remoto | Yes | No |
| Premium (DTU) | Armazenamento local | Yes | Yes |
Para obter mais informações sobre SLAs específicos para diferentes camadas de serviço, confira SLA para Banco de Dados SQL do Azure.
Disponibilidade por meio de redundância local
A disponibilidade com redundância local baseia-se no armazenamento do banco de dados no LRS (armazenamento com redundância local), que copia seus dados três vezes em um único datacenter na região primária e protege os dados em caso de falha local, como uma falha na rede de pequena escala ou de energia. O LRS é a opção de redundância de menor custo e oferece a menor durabilidade em comparação com outras opções. Caso ocorra um desastre em larga escala na região, como um incêndio ou uma inundação, todas as réplicas da conta de armazenamento que use o LRS poderão ser perdidas ou se tornarem irrecuperáveis. Dessa forma, para proteger ainda mais seus dados ao usar a opção de disponibilidade com redundância local, considere usar uma opção de armazenamento mais resiliente para os backups de banco de dados. Isso não se aplica a bancos de dados de hiperescala, em que o mesmo armazenamento é usado para arquivos de dados e backups.
A disponibilidade localmente redundante está disponível para todos os bancos de dados em todas as camadas de serviço e RPO (RPO, Objetivo de Ponto de Recuperação), que indica que a quantidade de perda de dados é zero.
Camadas de serviço Básico, Standard e Uso Geral
As camadas de serviço Basic e Standard da visão geral do modelo de compra baseado em DTU e a camada de serviço uso geral do modelo de compra baseado em vCore usam o modelo de disponibilidade de armazenamento remoto para computação sem servidor e provisionada. O diagrama a seguir mostra nós com as camadas de computação e armazenamento separadas.
O modelo de disponibilidade de armazenamento remoto inclui duas camadas:
Uma camada de computação sem estado que executa o processo do mecanismo de banco de dados e contém apenas dados transitórios e em cache, como os bancos de dado
tempdbemodelno SSD anexado e cache de planos, pool de buffer e pool columnstore na memória. Este nó sem estado é operado pelo Microsoft Azure Service Fabric, que inicializa o mecanismo de banco de dados, controla a integridade do nó e executa o failover para outro nó, se necessário.Uma camada de dados com estado, com arquivos de banco de dados (
.mdfe.ldf) que são armazenados no Armazenamento de Blobs do Azure. O Armazenamento de Blobs do Azure possui recursos internos de redundância e disponibilidade de dados. Ele garante que todos os registros no arquivo de log ou na página do arquivo de dados serão preservados mesmo se o processo do mecanismo de banco de dados falhar.
Sempre que o mecanismo de banco de dados ou o sistema operacional é atualizado ou uma falha é detectada, o Azure Service Fabric move o processo do mecanismo de banco de dados sem estado para outro nó de computação sem estado com capacidade livre suficiente. Os dados no Armazenamento de Blobs do Azure não são afetados pela movimentação, e os arquivos de dados/log são anexados ao processo do mecanismo de banco de dados recém-inicializado. Esse processo garante a alta disponibilidade, mas uma carga de trabalho pesada pode enfrentar degradação do desempenho durante a transição, uma vez que o novo processo do mecanismo de banco de dados começa com o cache frio.
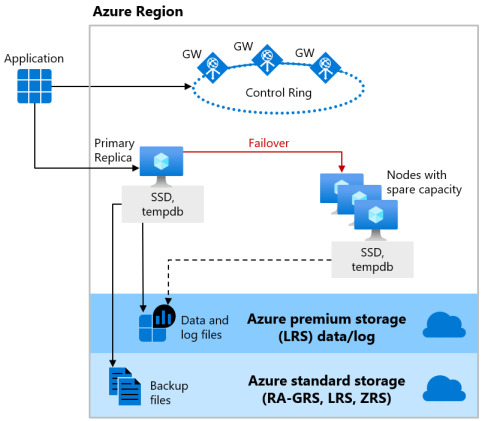
Camada de serviço Premium e Comercialmente Crítico
A camada de serviço Premium do Modelo de compra baseado em DTU e a camada de serviço Comercialmente Crítico do Modelo de compra baseado em vCore usam o modelo de disponibilidade de armazenamento local, que integra os recursos de computação (processo do mecanismo de banco de dados) e o armazenamento (SSD anexado localmente) em um nó individual. A alta disponibilidade é obtida com a replicação da computação e do armazenamento para nós adicionais.
Os arquivos de banco de dados subjacentes (.mdf/.ldf) são colocados no armazenamento SSD anexado para fornecer uma E/S de latência muito baixa para sua carga de trabalho. A alta disponibilidade é implementada usando tecnologia semelhante ao SQL Server Grupos de Disponibilidade AlwaysOn. O cluster inclui uma única réplica primária que é acessível para cargas de trabalho de leitura/gravação do cliente e até três réplicas secundárias (computação e armazenamento) que contêm cópias de dados. A réplica primária envia constantemente alterações para as réplicas secundárias em ordem e garante que os dados sejam persistidos em um número suficiente de réplicas secundárias antes de confirmar cada transação. Esse processo garante que, se a réplica primária ou uma réplica secundária para leitura falhar por qualquer motivo, sempre haverá uma réplica totalmente sincronizada para realizar o failover. O failover é iniciado pelo Azure Service Fabric. Depois que a réplica secundária se torna a nova réplica primária, outra réplica secundária é criada para garantir que o cluster tenha o número suficiente de réplicas para manter o quorum. Depois que um failover for concluído, as conexões do SQL do Azure serão redirecionadas automaticamente para a nova réplica primária ou réplica secundária legível.
Como um benefício extra, o modelo de disponibilidade armazenamento local inclui a capacidade de redirecionar conexões SQL do Azure somente leitura para uma das réplicas secundárias. Esse recurso é chamado de Expansão de Leitura. Ele fornece uma capacidade de computação adicional de 100%, sem custo adicional, para operações somente leitura fora do carregamento, como cargas de trabalho analíticas, da réplica primária.
Camada de serviço Hiperescala
A arquitetura da camada de serviço de Hiperescala é descrita na arquitetura de funções distribuídas, que tem um diagrama detalhado.
O modelo de disponibilidade em Hiperescala inclui quatro camadas:
Uma camada de computação sem estado que executa os processos do mecanismo de banco de dados e que contém somente dados transitórios e armazenados em cache, como o cache RBPEX sem cobertura, os bancos de dados
tempdbemodeletc. no SSD anexado, e cache de planos, pool de buffers e pool columnstore na memória. Essa camada sem estado inclui a réplica de computação primária e, opcionalmente, algumas réplicas de computação secundárias que podem servir como destinos de failover.Uma camada de armazenamento sem estado formada por servidores de página. Essa camada é o mecanismo de armazenamento distribuído para os processos do mecanismo de banco de dados em execução nas réplicas de computação. Cada servidor de página contém apenas dados transitórios e em cache, como o cache RBPEX com cobertura no SSD anexado, e páginas de dados armazenadas em cache na memória. Cada servidor de página tem um servidor de páginas emparelhado em uma configuração ativo-ativo para fornecer balanceamento de carga, redundância e alta disponibilidade.
Uma camada de armazenamento do log de transações com estado formada pelo nó de computação que executa o processo do serviço de log, a zona de destino do log de transações e o armazenamento de longo prazo do log de transações. A zona de destino e o armazenamento de longo prazo usam o Armazenamento do Azure, que fornece disponibilidade e redundância para o log de transações, garantindo a durabilidade dos dados para as transações confirmadas.
Uma camada de armazenamento de dados com estado nos arquivos de banco de dados (.mdf/.ndf) armazenados no Armazenamento do Azure e atualizados por servidores de página. Essa camada usa recursos de redundância e disponibilidade de dados do Armazenamento do Azure. Ele garante que todas as páginas em um arquivo de dados sejam preservadas, mesmo se os processos em outras camadas de falha de arquitetura de Hiperescala ou os nós de computação falharem.
Os nós de computação em todas as camadas de Hiperescala são executados no Azure Service Fabric, que controla a integridade de cada nó e executa failovers para nós íntegros disponíveis, conforme necessário.
Para obter mais informações sobre alta disponibilidade em Hiperescala, consulte Alta Disponibilidade do Banco de Dados em Hiperescala.
Alta disponibilidade por meio de redundância de zona
Para implantações com redundância de zona, o Banco de Dados SQL do Azure usa o número de zonas de disponibilidade do Azure em uma determinada região, duas ou mais comumente três. Os componentes de computação e armazenamento abrangem duas ou três zonas, conforme selecionado pelo SQL do Azure para resiliência ideal, em locais físicos separados com energia, resfriamento e rede independentes. O SQL do Azure seleciona automaticamente o número de zonas com base na disponibilidade regional e na otimização do serviço. Sua implantação não usará menos zonas do que o necessário para resiliência.
A disponibilidade com redundância de zona pode ser usada nos bancos de dados nas camadas de serviço Uso Geral, Comercialmente Crítico e Hiperescala do Modelo de compra baseado em vCore, e somente a camada de serviço Premium do Modelo de compra baseado em DTU. As camadas de serviço Básica e Standard não são compatíveis com a redundância de zona.
Embora cada camada de serviço implemente redundância de zona de forma diferente, todas as implementações garantem um RPO (Objetivo de Ponto de Recuperação) sem perda de dados confirmados durante o failover se uma única zona de disponibilidade dentro de uma região do Azure ficar indisponível.
O SQL do Azure otimiza automaticamente o posicionamento de zona para sua implantação. Todas as configurações de zona de disponibilidade, usando duas ou três zonas, fornecem as mesmas garantias de resiliência e SLA de alta disponibilidade.
Camada de serviço Uso Geral
A configuração com redundância de zona para a camada de serviço Uso Geral é oferecida para a computação sem servidor e provisionada para banco de dados no modelo de compra vCore. Essa configuração utiliza Zonas de Disponibilidade do Azure para replicar bancos de dados em vários locais físicos em uma região do Azure. Ao selecionar a redundância de zona, você pode tornar os pools elásticos e os bancos de dados individuais de uso geral sem servidor e provisionados novos e existentes resilientes a um conjunto muito maior de falhas, como interrupções catastróficas do datacenter, sem nenhuma alteração na lógica de aplicativo.
A configuração com redundância de zona da camada de serviço Uso Geral tem duas camadas:
- Uma camada de dados com estado com os arquivos de banco de dados (.mdf/.ldf) armazenados no ZRS (armazenamento com redundância de zona). Usando o ZRS, os arquivos de dados e de log são copiados de forma síncrona em várias zonas de disponibilidade do Azure na região primária. Isso ocorre em duas ou três zonas, conforme selecionado pelo SQL do Azure para obter a resiliência ideal.
- Uma camada de computação sem estado que executa o processo sqlservr.exe e contém apenas dados transitórios e em cache, como os bancos de dado
tempdbemodelno SSD anexado e cache de planos, pool de buffers e pool columnstore na memória. Este nó sem estado é operado pelo Microsoft Azure Service Fabric, que inicializa sqlservr.exe, controla a integridade do nó e executa o failover para outro nó, se necessário. Para bancos de dados de Uso Geral sem servidor e provisionado com redundância de zona, os nós com capacidade sobressalente estão prontamente disponíveis em outras zonas de disponibilidade para failover.
A versão com redundância de zona da arquitetura de alta disponibilidade para a camada de serviço de Uso Geral é ilustrada pelos seguintes diagramas, em uma região de duas ou três zonas:
| Região de duas zonas | Região de três zonas |
|---|---|

|

|
Quando a computação é provisionada em duas zonas de disponibilidade:
- O backup e o armazenamento ainda são sincronizados em três zonas de disponibilidade na região.
- O armazenamento com redundância de zona, como sempre, é sincronizado em três zonas de disponibilidade.
Quando a computação é provisionada em três zonas de disponibilidade:
- O backup e o armazenamento são sincronizados em três zonas de disponibilidade na região.
Todas as regiões do Azure que têm zona de disponibilidade dão suporte a bancos de dados gerais com redundância de zona.
Para a disponibilidade redundante de zona, a escolha de uma janela de manutenção diferente do padrão está atualmente disponível em regiões selecionadas. Para obter mais informações, consulte a disponibilidade da janela de manutenção por região para o Banco de Dados SQL do Azure.
A redundância de zona não está disponível para as camadas de serviço Básica e Standard no modelo de compra de DTU.
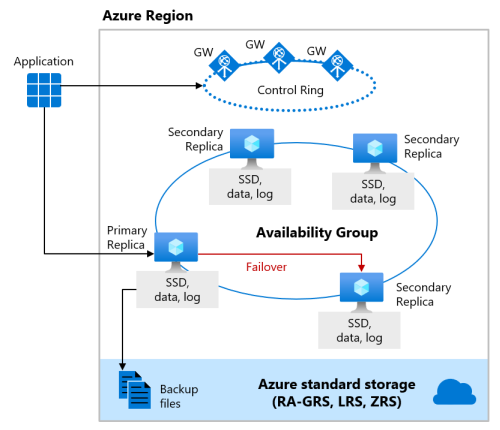
Camadas de serviço Premium e Comercialmente Crítico
Quando a Redundância de Zona está habilitada para a camada de serviço Premium ou Comercialmente Crítico, as réplicas são colocadas em zonas de disponibilidade diferentes na mesma região. Para eliminar um ponto único de falha, o anel de controle também é duplicado entre várias zonas como três GW (anéis de gateway). O roteamento para um anel de gateway específico é controlado pelo Gerenciador de Tráfego do Azure. Como a configuração de zona redundante nas camadas de serviço Premium ou Comercialmente Crítico usa suas réplicas existentes para colocar em diferentes zonas de disponibilidade, você pode habilitá-la sem custo adicional. Ao selecionar uma configuração com redundância de zona, você pode tornar os pools elásticos e os bancos de dados Premium ou Comercialmente Crítico resilientes a um conjunto muito maior de falhas, incluindo interrupções catastróficas do datacenter, sem nenhuma alteração na lógica de aplicativo. Além disso, é possível converter quaisquer pools elásticos ou bancos de dados Premium ou Comercialmente Crítico existentes para a configuração com redundância de zona.
A versão com redundância de zona da arquitetura de alta disponibilidade para a camada de serviço Comercialmente Crítico é ilustrada pelos seguintes diagramas, em uma região de duas ou três zonas:
| Região de duas zonas | Região de três zonas |
|---|---|

|

|
Quando a computação é provisionada em duas zonas de disponibilidade:
- Para o armazenamento Comercialmente Crítico, o armazenamento de disponibilidade com redundância local para arquivos de log e dados é sincronizado em duas zonas de disponibilidade.
- Para outras camadas, o backup e o armazenamento são sincronizados em três zonas de disponibilidade na região.
- O armazenamento com redundância de zona, como sempre, é sincronizado em três zonas de disponibilidade.
Quando a computação é provisionada em três zonas de disponibilidade:
- Para o armazenamento Comercialmente Crítico, o armazenamento de disponibilidade com redundância local para arquivos de log e dados é sincronizado em três zonas de disponibilidade.
- Para outras camadas, o backup e o armazenamento são sincronizados em três zonas de disponibilidade na região.
Considere o seguinte ao configurar os bancos de dados Premium ou Comercialmente Crítico com redundância de zona:
- Todas as regiões do Azure que têm zona de disponibilidade dão suporte a bancos de dados Premium e Comercialmente Críticos com redundância de zona.
- Para a disponibilidade redundante de zona, a escolha de uma janela de manutenção diferente do padrão está atualmente disponível em regiões selecionadas. Para obter mais informações, consulte a disponibilidade da janela de manutenção por região para o Banco de Dados SQL do Azure.
Camada de serviço Hiperescala
É possível configurar a redundância de zona para bancos de dados na camada de serviço Hiperescala. Para saber mais, examine Criar um banco de dados Hiperescala redundante por zona.
A habilitação dessa configuração garante a resiliência no nível da zona por meio da replicação Zonas de Disponibilidade para todas as camadas de Hiperescala. Ao selecionar a redundância de zona, é possível tornar seus bancos de dados de Hiperescala resilientes a um conjunto muito maior de falhas, como interrupções catastróficas do datacenter, sem nenhuma alteração na lógica de aplicativo.
A disponibilidade com redundância de zona é suportada em bancos de dados autônomos de Hiperescala e pools elásticos de Hiperescala. Para obter mais informações, consulte a visão geral dos pools elásticos da Hiperescala no Banco de Dados SQL do Azure.
Os diagramas a seguir demonstram a arquitetura subjacente para bancos de dados de Hiperescala com redundância de zona, em uma região de duas ou três zonas:
| Região de duas zonas | Região de três zonas |
|---|---|

|

|
Quando a computação é provisionada em duas zonas de disponibilidade:
- O backup e o armazenamento são sincronizados em três zonas de disponibilidade na região.
- O armazenamento com redundância de zona, como sempre, é sincronizado em três zonas de disponibilidade.
Quando a computação é provisionada em três zonas de disponibilidade:
- O backup e o armazenamento são sincronizados em três zonas de disponibilidade na região.
Considere as seguintes limitações:
Todas as regiões do Azure que têm zona de disponibilidade dão suporte ao banco de dados de hiperescala com redundância de zona.
- Para hardware das séries premium e premium otimizadas para memória da Hyperscale, a redundância de zona está disponível em determinadas regiões. Para obter mais informações, consulte a disponibilidade da série premium da Hiperescala por região para o Banco de Dados SQL do Azure.
A configuração com redundância de zona só pode ser especificada durante a criação do banco de dados. Essa configuração não pode ser modificada depois que o recurso é provisionado. Use Cópia de banco de dados, restauração ponto a ponto ou crie uma réplica geográfica para atualizar a configuração com redundância de zona para um banco de dados de Hiperescala existente. Ao usar uma dessas opções de atualização, se o banco de dados de destino estiver em uma região diferente da origem ou se a redundância de armazenamento de backup do banco de dados do destino for diferente do banco de dados de origem, a operação de cópia será um tamanho da operação de dados.
Para a disponibilidade redundante de zona, a escolha de uma janela de manutenção diferente do padrão está atualmente disponível em regiões selecionadas. Para obter mais informações, consulte a disponibilidade da janela de manutenção por região para o Banco de Dados SQL do Azure.
Atualmente, não há nenhuma opção para especificar a redundância de zona ao migrar um banco de dados para a Hiperescala usando o portal do Azure. Porém, a redundância de zona não pode ser especificada usando Azure PowerShell, CLI ou API REST ao migrar um banco de dados existente de outra camada de serviço do Banco de Dados SQL do Azure para a Hiperescala. Aqui está um exemplo com a CLI do Azure:
az sql db update --resource-group "myRG" --server "myServer" --name "myDB" --edition Hyperscale --zone-redundant true`Pelo menos uma réplica de computação de alta disponibilidade e o uso do armazenamento de backup com redundância de zona ou com redundância de zona geográfica são necessários para habilitar a configuração com redundância de zona para Hiperescala.
Disponibilidade com redundância de zona do banco de dados
No Banco de Dados SQL do Azure, um servidor é um constructo lógico que atua como um ponto administrativo central para uma coleção de bancos de dados. No nível do servidor, você pode administrar logons, métodos de autenticação, regras de firewall, regras de auditoria, políticas de detecção de ameaças e grupos de failover. Os dados relacionados a alguns desses recursos, como logons e regras de firewall, são armazenados no banco de dados master. Da mesma forma, os dados de algumas DMVs, por exemplo , sys.resource_stats, também são armazenados no banco de dados master.
Quando um banco de dados com uma configuração com redundância de zona é criado em um servidor lógico, o banco de dados master associado ao servidor também passa a ter redundância de zona automaticamente. Isso garante que, em uma interrupção de zona, os aplicativos que usam o banco de dados permaneçam inalterados porque os recursos dependentes do master banco de dados, como logons e regras de firewall, ainda estão disponíveis. A conversão do banco de dados master em um banco de dados com redundância de zona é um processo assíncrono e demora um pouco para ser concluído em segundo plano.
Quando nenhum dos bancos de dados em um servidor tiver redundância de zona ou quando você criar um servidor vazio, o banco de dados master associado ao servidor não terá redundância de zona. Para migrar o Banco de Dados SQL do Azure para usar a redundância de zona, siga as etapas em Migrar o Banco de Dados SQL do Azure para o suporte à zona de disponibilidade.
Para verificar a ZoneRedundant propriedade do banco de master dados, use o Azure PowerShell ou a CLI do Azure ou as etapas da API REST em Validar o status da zona de disponibilidade do Banco de Dados SQL do Azure.
Testar a resiliência de falha do aplicativo
A alta disponibilidade é uma parte fundamental da plataforma de Banco de Dados SQL que funciona de maneira transparente para o aplicativo de banco de dados. No entanto, reconhecemos que talvez você queira testar como as operações de failover automático iniciadas durante os eventos planejados ou não planejados afetariam um aplicativo antes de implantá-lo na produção. Você pode disparar um failover manualmente chamando uma API especial para reiniciar um banco de dados ou um pool elástico. No caso de um pool elástico ou um banco de dados de Uso Geral sem servidor ou provisionado com redundância de zona, a chamada à API resultará no redirecionamento das conexões de cliente para o novo primário em uma zona de disponibilidade diferente da zona de disponibilidade do primário antigo. Assim, além de testar como o failover afeta as sessões de banco de dados existentes, você também pode verificar se ele altera o desempenho de ponta a ponta devido a alterações na latência de rede. Como a operação de reinicialização é intrusiva e o excesso da mesma pode sobrecarregar a plataforma, apenas uma chamada de failover é permitida a cada 15 minutos para cada banco de dados ou pool elástico.
Para obter mais informações sobre alta disponibilidade e recuperação de desastres do Banco de Dados SQL do Azure, examine a lista de verificação de alta disponibilidade e recuperação de desastres – Banco de Dados SQL do Azure.
Um failover pode ser iniciado usando o PowerShell, a API REST ou CLI do Azure:
| Tipo de implantação | PowerShell | API REST | CLI do Azure | Portal (versão prévia) |
|---|---|---|---|---|
| Database | Invoke-AzSqlDatabaseFailover | Failover de banco de dados | az rest pode ser usado para invocar uma chamada à API REST de CLI do Azure | Reinicialização da manutenção > de configurações > |
| Pool elástico | Invoke-AzSqlElasticPoolFailover | Failover de pool elástico | az rest pode ser usado para invocar uma chamada à API REST de CLI do Azure | Reinicialização da manutenção > de configurações > |
Important
O comando failover não está disponível para réplicas secundárias legíveis de bancos de dados de Hiperescala.
Conclusion
O Banco de Dados SQL do Azure apresenta uma solução de alta disponibilidade interna, que está profundamente integrada com a plataforma Azure. Ele depende do Service Fabric para detecção de falha e recuperação, do armazenamento de Blobs do Azure para proteção de dados e de zonas de disponibilidade para maior tolerância a falhas. Além disso, o Banco de Dados SQL usa a tecnologia de grupo de disponibilidade Always On do SQL Server para sincronização de dados e failover. A combinação dessas tecnologias permite que os aplicativos percebam em sua totalidade os benefícios de um modelo de armazenamento misto e deem suporte aos SLAs mais exigentes.