Solucionar problemas de desempenho com o Intelligent Insights: Banco de Dados SQL do Azure e Instância Gerenciada de SQL do Azure
Aplica-se a: ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
Esta página fornece informações sobre Banco de Dados SQL do Azure e Instância Gerenciada de SQL do Azure de desempenho detectados por meio do log Intelligent Insights de recursos. Os logs de métricas e recursos podem ser enviados para o Azure Monitor logs, Hubs de Eventos do Azure, Armazenamento do Azure ou uma solução de terceiros para recursos personalizados de alertas e relatórios de DevOps.
Observação
Para obter um guia rápido de solução de problemas de desempenho usando o Intelligent Insights, confira o fluxograma Fluxo recomendado para solução de problemas neste documento.
O Intelligent Insights é uma versão prévia do recurso e não está disponível nas seguintes regiões: Oeste da Europa, Norte da Europa, Oeste dos EUA 1 e Leste dos EUA 1.
Padrões detectáveis de desempenho do banco de dados
O Intelligent Insights detecta automaticamente os problemas de desempenho com base em tempos de espera de execução de consulta, erros ou tempos limite. Intelligent Insights saídas detectadas padrões de desempenho para o log de recursos. Padrões de desempenho detectáveis estão resumidos na tabela a seguir.
| Padrões de desempenho detectáveis | Banco de Dados SQL do Azure | Instância Gerenciada do SQL do Azure |
|---|---|---|
| Atingindo os limites do recurso | O consumo de recursos disponíveis (DTUs), threads de trabalho do banco de dados ou sessões de logon de banco de dados disponíveis na assinatura monitorada atingiram os limites de seus recursos. Isso está afetando o desempenho. | O consumo de recursos de CPU está atingindo os limites do recurso. Isso está afetando o desempenho do banco de dados. |
| Aumento da carga de trabalho | Foi detectado aumento da carga de trabalho ou acumulação contínua de carga de trabalho no banco de dados. Isso está afetando o desempenho. | Foi detectado um aumento da carga de trabalho. Isso está afetando o desempenho do banco de dados. |
| Demanda de memória | Os trabalhadores que solicitaram concessões de memória têm que aguardar alocações de memória por quantidades estatisticamente significativas de tempo, ou existe um acúmulo maior de trabalhadores que solicitaram concessões de memória. Isso está afetando o desempenho. | Os operadores que solicitaram concessões de memória estão esperando alocações de memória para quantidades de tempo estatisticamente significativas. Isso está afetando o desempenho do banco de dados. |
| Bloqueio | Bloqueio de banco de dados excessivo foi detectado, afetando o desempenho. | Bloqueio de banco de dados excessivo foi detectado, afetando o desempenho do banco de dados. |
| Aumento de MAXDOP | A opção de grau máximo de paralelismo (MAXDOP) foi alterada, afetando a eficiência da execução da consulta. Isso está afetando o desempenho. | A opção de grau máximo de paralelismo (MAXDOP) foi alterada, afetando a eficiência da execução da consulta. Isso está afetando o desempenho. |
| Contenção de pagelatch | Vários threads estão tentando, simultaneamente, acessar as mesmas páginas de buffer de dados na memória, resultando em maior tempo de espera, causando contenção de pagelatch. Isso está afetando o desempenho. | Vários threads estão tentando, simultaneamente, acessar as mesmas páginas de buffer de dados na memória, resultando em maior tempo de espera, causando contenção de pagelatch. Isso está afetando o desempenho do banco de dados. |
| Índice Ausente | Foi detectada a ausência do índice, afetando o desempenho. | Foi detectada a ausência do índice, afetando o desempenho do banco de dados. |
| Nova Consulta | Foi detectada nova consulta que afeta o desempenho geral. | Foi detectada nova consulta que afeta o desempenho geral do banco de dados. |
| Aumento da Estatística de Espera | Foi detectado um aumento dos tempos de espera, afetando o desempenho. | Foi detectado um aumento dos tempos de espera, afetando o desempenho do banco de dados. |
| Contenção de TempDB | Vários threads estão tentando acessar os mesmos recursos de tempdb, provocando um gargalo. Isso está afetando o desempenho. |
Vários threads estão tentando acessar os mesmos recursos de tempdb, provocando um gargalo. Isso está afetando o desempenho do banco de dados. |
| Insuficiência de DTU no pool elástico | A insuficiência de eDTUs no pool elástico está afetando o desempenho. | Não disponível para Instância Gerenciada de SQL do Azure, pois ele usa o modelo vCore. |
| Regressão de Plano | Foi detectado um novo plano ou uma alteração na carga de trabalho de um plano existente. Isso está afetando o desempenho. | Foi detectado um novo plano ou uma alteração na carga de trabalho de um plano existente. Isso está afetando o desempenho do banco de dados. |
| Alteração do valor de configuração no escopo do banco de dados | Foi detectada uma alteração de configuração no banco de dados que está afetando seu desempenho. | Foi detectada uma alteração de configuração no banco de dados que está afetando seu desempenho. |
| Cliente lento | O cliente de aplicativo lento não pode consumir a saída do banco de dados rápido o suficiente. Isso está afetando o desempenho. | O cliente de aplicativo lento não pode consumir a saída do banco de dados rápido o suficiente. Isso está afetando o desempenho do banco de dados. |
| Downgrade de tipo de preço | A ação de downgrade do tipo de preço diminuiu os recursos disponíveis. Isso está afetando o desempenho. | A ação de downgrade do tipo de preço diminuiu os recursos disponíveis. Isso está afetando o desempenho do banco de dados. |
Dica
Para otimização contínua do desempenho do banco de dados, habilite Ajuste automático. Esse recurso de inteligência interna monitora continuamente seu banco de dados, ajusta de modo automático os índices e aplica correções de plano de execução de consulta.
A seção a seguir descreve os padrões de desempenho detectáveis com mais detalhes.
Atingindo os limites do recurso
O que está acontecendo
Esse padrão de desempenho detectável combina problemas de desempenho relacionados a alcançar os limites de recurso, limites de trabalho e limites de sessão disponíveis. Depois que esse problema de desempenho é detectado, um campo de descrição do log de diagnóstico indica se o problema de desempenho está relacionado a limites de recurso, trabalho ou sessão.
Os recursos Banco de Dados SQL do Azure são normalmente chamados de recursos de DTU ou vCore e os recursos Instância Gerenciada de SQL do Azure são chamados de recursos de vCore. O padrão de alcance dos de limites do recurso é reconhecido quando uma degradação de desempenho de consulta detectada é causada por qualquer um dos limites de recurso medidos.
O recurso de limites de sessão denota o número de logons simultâneos disponíveis para o banco de dados. Esse padrão de desempenho é reconhecido quando aplicativos que estão se conectando aos bancos de dados atingem o número de logons simultâneos disponíveis para o banco de dados. Se aplicativos tentarem usar mais sessões do que as disponíveis em um banco de dados, o desempenho da consulta será afetado.
O alcance dos limites de trabalho é um caso específico de atingir os limites do recurso, pois trabalhadores disponíveis não são contados no uso de DTU ou vCore. O alcance dos limites de trabalho em um banco de dados pode causar o surgimento de tempos de espera específicos do recurso, o que resulta em uma degradação no desempenho da consulta.
Solução de problemas
O log de diagnóstico gera hashes de consulta das consultas que afetaram o desempenho e as porcentagens de consumo do recurso. Use estas informações como ponto de partida para otimizar a carga de trabalho do banco de dados. Em particular, você pode otimizar as consultas que afetam a degradação do desempenho adicionando índices. Ou você pode otimizar aplicativos com uma distribuição de carga de trabalho mais uniforme. Se não for possível reduzir as cargas de trabalho ou fazer otimizações, considere aumentar o tipo de preço da sua assinatura do banco de dados para aumentar a quantidade de recursos disponíveis.
Se você tiver atingido os limites de sessão disponíveis, poderá otimizar seus aplicativos reduzindo o número de logons feitos no banco de dados. Se não for possível reduzir o número de logons de seus aplicativos para o banco de dados, considere aumentar o tipo de preço da assinatura do banco de dados. Ou você pode dividir e mover o banco de dados em vários bancos de dados para uma distribuição mais balanceada de carga de trabalho.
Para mais sugestões sobre como resolver limites de sessão, consulte Como lidar com os limites máximos de logons no banco de dados. Consulte Visão geral dos limites de recursos em um servidor para obter informações sobre limites nos níveis de servidor e assinatura.
Aumento da carga de trabalho
O que está acontecendo
Esse padrão de desempenho identifica problemas causados por aumento da carga de trabalho ou sua forma mais grave, empilhamento de carga de trabalho.
Essa detecção é feita por uma combinação de várias métricas. A métrica básica medida está detectando um aumento na carga de trabalho em comparação com a linha de base de carga de trabalho anterior. A outra forma de detecção baseia-se em avaliar um grande aumento nos threads de trabalho ativos, grande o suficiente para afetar o desempenho da consulta.
Em sua forma mais grave, a carga de trabalho pode ser continuamente empilhada devido à incapacidade do banco de dados de processar a carga de trabalho. O resultado é o aumento contínuo do tamanho da carga de trabalho, que é a condição de empilhamento da carga de trabalho. Devido a essa condição, o tempo que a carga de trabalho espera para execução aumenta. Essa condição representa um dos mais graves problemas de desempenho do banco de dados. Esse problema é detectado por meio de monitoramento de aumento no número de threads de trabalho anulados.
Solução de problemas
O log de diagnóstico gera o número de consultas cuja execução aumentou e o hash de consulta da consulta que mais contribuiu para o aumento da carga de trabalho. Use estas informações como ponto de partida para otimizar a carga de trabalho. A consulta identificada como principal colaboradora do aumento da carga de trabalho é especialmente útil como ponto de partida.
Considere também distribuir as cargas de trabalho de maneira mais uniforme para o banco de dados. Considere otimizar a consulta que está afetando o desempenho adicionando índices. Você também pode distribuir sua carga de trabalho entre vários bancos de dados. Se essas soluções não forem possíveis, considere aumentar o tipo de preço da sua assinatura do banco de dados para aumentar a quantidade de recursos disponíveis.
Demanda de memória
O que está acontecendo
Esse padrão de desempenho indica degradação no desempenho do banco de dados atual devido à pressão de memória ou, em sua forma mais grave, uma condição de empilhamento de memória, em comparação com a linha de base de desempenho dos últimos sete dias.
Demanda de memória indica uma condição de desempenho em que há um grande número de threads de trabalho solicitando concessões de memória. Alto volume provoca uma condição de utilização de memória alta na qual o banco de dados não consegue alocar memória com eficiência para todos os trabalhos que a solicitam. Um dos motivos mais comuns para esse problema está relacionado à quantidade de memória disponível ao banco de dados por um lado. Por outro lado, um aumento na carga de trabalho provoca o aumento nos threads de trabalho e na pressão de memória.
A forma mais grave de pressão de memória é a condição de empilhamento de memória. Essa condição indica que há um número maior de threads de trabalho solicitando concessões de memória do que o número de consultas que estão liberando a memória. Esse número de threads de trabalho que solicita concessões de memória também pode estar aumentando continuamente (empilhando-se), uma vez que o mecanismo de banco de dados não consegue alocar memória com eficiência suficiente para atender à demanda. A condição de empilhamento de memória representa um dos mais graves problemas de desempenho do banco de dados.
Solução de problemas
O log de diagnóstico gera os detalhes de repositório do objeto na memória, com o administrador (ou seja, o thread de trabalho) marcado como o motivo principal de alto uso de memória e os carimbos de data/hora relevantes. Você pode usar essa informação como a base para a solução de problemas.
Você pode otimizar ou remover consultas relacionadas aos administradores com o uso de memória mais alto. Você também pode garantir que não esteja consultando dados que você não planeje usar. A prática recomendada é sempre usar uma cláusula WHERE em suas consultas. Além disso, é recomendável criar índices não clusterizados para buscar os dados, em vez de examiná-lo.
Você também pode reduzir a carga de trabalho otimizando-a ou distribuindo-a em vários bancos de dados. Ou você pode distribuir sua carga de trabalho entre vários bancos de dados. Se essas soluções não forem possíveis, considere aumentar o tipo de preço do banco de dados para aumentar a quantidade de recursos de memória disponíveis ao banco de dados.
Para sugestões adicionais de solução de problemas, consulte Reflexão sobre concessões de memória: o misterioso consumidor de memória do SQL Server com vários nomes. Para obter mais informações sobre erros de memória no Banco de Dados SQL do Azure, confira Solucionar problemas de erros de memória com o Banco de Dados SQL do Azure.
Bloqueio
O que está acontecendo
Esse padrão de desempenho indica degradação no desempenho do banco de dados atual em que foi detectado bloqueio excessivo do banco de dados em comparação com a linha de base de desempenho dos últimos sete dias.
Em RDBMS modernos, o bloqueio é essencial para a implementação de sistemas multithread em que o desempenho é maximizado por meio da execução simultânea de várias transações paralelas de banco de dados e trabalho, quando possível. O bloqueio, neste contexto, refere-se ao mecanismo de acesso interno no qual apenas uma única transação pode acessar com exclusividade linhas, páginas, tabelas e arquivos necessários e não competir com outra transação por recursos. Quando a transação que bloqueou os recursos para uso termina de usá-los, o bloqueio desses recursos é liberado, o que permite que outras transações acessem os recursos necessários. Para obter mais informações sobre bloqueio, consulte Bloqueio no mecanismo de banco de dados.
Se as transações executadas pelo SQL Engine estiverem aguardando por longos períodos para acessar recursos bloqueados para uso, esse tempo de espera afetará o desempenho de execução da carga de trabalho.
Solução de problemas
O log de diagnóstico gera detalhes de bloqueio que você pode usar como base para solução de problemas. Você pode analisar as consultas de bloqueio relatadas, ou seja, as consultas que apresentam a degradação de desempenho de bloqueio e removê-las. Em alguns casos, talvez a otimização de consultas de bloqueio seja bem-sucedida.
A maneira mais simples e segura de atenuar o problema é manter as transações curtas e reduzir a superfície de bloqueio das consultas mais caras. Você pode dividir um lote grande de operações em operações menores. Uma melhor prática é reduzir a superfície de bloqueio de consulta, tornando a consulta o mais eficiente possível. Reduza verificações grandes, pois elas aumentam as chances de deadlocks e afetam negativamente o desempenho geral do banco de dados. Para consultas identificadas que causam o bloqueio, você pode criar novos índices ou adicionar colunas ao índice existente para evitar as verificações de tabela.
Para obter mais sugestões, consulte:
- Entender e resolver problemas de bloqueio do SQL do Azure
- Como resolver problemas de bloqueio causados por escalonamento de bloqueios no SQL Server
Aumento de MAXDOP
O que está acontecendo
Esse padrão de desempenho detectável indica uma condição em que um plano de execução de consulta escolhido foi paralelizado mais do que devia ter sido. O otimizador de consulta pode melhorar o desempenho da carga de trabalho executando consultas em paralelo para acelerar a execução sempre que possível. Em alguns casos, trabalhadores paralelos que processam uma consulta gastam mais tempo aguardando uns aos outros para sincronizar e mesclar os resultados em comparação a executar a mesma consulta com menos trabalhadores paralelos ou, até mesmo, em alguns casos, em comparação a um único thread de trabalho.
O sistema especialista analisa o desempenho de banco de dados atual em comparação ao período de linha de base. Ele determina se uma consulta em execução anteriormente está sendo executada de modo mais lento que antes porque o plano de execução de consulta está mais paralelizado que deveria estar.
A opção de configuração do servidor MAXDOP é usada para controlar o número de núcleos de CPU que podem ser usados para executar a mesma consulta em paralelo.
Solução de problemas
O log de diagnóstico produz hashes de consulta relacionados a consultas para as quais a duração da execução é aumentada porque eles foram paralelizados mais do que deveriam ter sido. O log também gera tempos de espera CXP. Esse tempo representa o tempo que um thread único de coordenador/organizador (thread 0) aguarda a conclusão de todos os outros threads antes de mesclar os resultados e seguir adiante. Além disso, o log de diagnóstico gera os tempos de espera em que as consultas de baixo desempenho estavam aguardando em execução no geral. Você pode usar essa informação como a base para a solução de problemas.
Primeiro, otimize ou simplifique consultas complexas. Uma prática recomendada é dividir trabalhos em lote grandes em partes menores. Além disso, crie índices para dar suporte às suas consultas. Você pode impor manualmente o grau máximo de paralelismo (MAXDOP) para uma consulta sinalizada como de baixo desempenho. Para configurar essa operação usando T-SQL, consulte Configurar a opção de configuração de servidor MAXDOP.
A definição da opção de configuração do servidor MAXDOP como zero (0) como um valor padrão denota que o Banco de Dados pode usar todos os núcleos de CPU disponíveis para paralelizar threads executando uma única consulta. Configuração MAXDOP como um (1) indica que apenas um núcleo pode ser usado para uma única execução de consulta. Em termos práticos, isso significa que o paralelismo está desativado. Dependendo do caso, dos núcleos disponíveis para o banco de dados e das informações do log de diagnóstico, ajuste a opção MAXDOP para o número de núcleos de execução paralela da consulta que pode resolver o problema no seu caso.
Contenção de pagelatch
O que está acontecendo
Esse padrão de desempenho indica degradação atual de desempenho da carga de trabalho do banco de dados devido à contenção de pagelatch em comparação com a linha de base da carga de trabalho dos últimos sete dias.
Travas são mecanismos de sincronização leves usados para habilitar multithreading. Elas garantem a consistência de estruturas em memória que incluem índices, páginas de dados e outras estruturas internas.
Há muitos tipos de travas disponíveis. Para fins de simplicidade, travas de buffer são usadas para proteger as páginas em memória no pool de buffers. Travas de E/S são usadas para proteger as páginas que ainda não foram carregadas no pool de buffers. Sempre que os dados são gravados ou lidos de uma página no pool de buffers, um thread de trabalho precisa adquirir uma trava de buffer para a página primeiro. Sempre que um thread de trabalho tenta acessar uma página que ainda não está disponível no pool de buffers em memória, é feita uma solicitação de E/S ao carregar as informações necessárias do armazenamento. Esta sequência de eventos indica uma forma mais grave de degradação do desempenho.
Contenção de travas na página ocorre quando vários threads tentam ao mesmo tempo adquirir travas na mesma estrutura da memória, o que introduz um tempo de espera maior para a execução da consulta. No caso de contenção de E/S pagelatch, quando os dados precisam ser acessados do armazenamento, esse tempo de espera é ainda maior. Isso pode afetar consideravelmente o desempenho da carga de trabalho. Contenção de pagelatch é o cenário mais comum de threads aguardando entre si e competindo por recursos em vários sistemas de CPU.
Solução de problemas
O log de diagnóstico gera detalhes de contenção pagelatch. Você pode usar essa informação como a base para a solução de problemas.
Como um pagelatch é um mecanismo de controle interno, ele determina automaticamente quando usá-los. Decisões do aplicativo, incluindo design de esquema, podem afetar o comportamento de pagelatch devido ao comportamento determinista das travas.
Um método de lidar com contenção de trava é substituir uma chave de índice sequencial por uma não sequencial para distribuir uniformemente as inserções em um intervalo de índice. Normalmente, uma coluna à esquerda no índice distribui a carga de trabalho proporcionalmente. Outro método a considerar é o particionamento de tabela. Uma abordagem comum para reduzir a contenção excessiva de travas é criar um esquema de particionamento de hash com uma coluna computada em uma tabela particionada. No caso de contenção de E/S pagelatch, introduzir índices ajuda a reduzir esse problema de desempenho.
Para obter mais informações, consulte Diagnosticar e resolver contenção de trava no SQL Server (download do PDF).
Índice ausente
O que está acontecendo
Esse padrão de desempenho indica degradação atual de desempenho da carga de trabalho do banco de dados em comparação com a linha de base dos últimos sete dias devido a um índice ausente.
Um índice é usado para acelerar o desempenho das consultas. Ele fornece acesso rápido aos dados da tabela com a redução do número de páginas de conjunto de dados que precisam ser visitadas ou examinadas.
Consultas específicas que provocam degradação de desempenho são identificadas por meio dessa detecção, para as quais a criação de índices seria benéfica ao desempenho.
Solução de problemas
O log de diagnóstico gera hashes de consulta para as consultas que foram identificadas como afetando o desempenho da carga de trabalho. Você pode criar índices para essas consultas. Você também pode otimizar ou remover essas consultas se elas não forem necessárias. Uma boa prática de desempenho é evitar a consulta de dados que você não usa.
Dica
Você sabia que a inteligência interna pode gerenciar automaticamente os melhores índices de desempenho para seus bancos de dados?
Para otimizar o desempenho contínuo, é recomendável habilitar o ajuste automático. Esse recurso exclusivo de inteligência interna monitora continuamente o banco de dados e ajusta e cria de modo automático índices para os bancos de dados.
Nova Consulta
O que está acontecendo
Esse padrão de desempenho indica que uma nova consulta de baixo desempenho foi detectada e está afetando o desempenho da carga de trabalho em comparação à linha de base de desempenho de sete dias.
Escrever uma consulta de bom desempenho pode, às vezes, ser uma tarefa desafiadora. Para obter mais informações sobre como escrever consultas, consulte Escrever consultas SQL. Para otimizar o desempenho de consulta existente, consulte Ajuste de consulta.
Solução de problemas
O log de diagnóstico gera informações para até duas novas consultas que mais consomem CPU, incluindo seus hashes de consulta. Como a consulta detectada afeta o desempenho da carga de trabalho, você pode otimizar sua consulta. É uma boa prática recuperar apenas os dados que você precisa usar. Também é recomendável usar consultas com uma cláusula WHERE. Também recomendamos que você simplifique as consultas complexas e dividi-as em consultas menores. Outra boa prática é dividir as consultas de lote grande em consultas de lote menor. A introdução de índices em novas consultas geralmente é uma boa prática para atenuar esse problema de desempenho.
No Banco de Dados SQL do Azure, considere o uso da Análise de Desempenho de Consultas.
Aumento da Estatística de Espera
O que está acontecendo
Esse padrão de desempenho detectável indica uma degradação de desempenho da carga de trabalho no qual o baixo desempenho de consultas é identificado em comparação com a linha de base da carga de trabalho dos últimos sete dias.
Nesse caso, o sistema não pode classificar as consultas com baixo desempenho em outras categorias de desempenho detectáveis padrão, mas ele detectou a estatística de espera responsável pela regressão. Portanto, ela as considera consultas com estatísticas de espera elevadas, em que a estatística de espera responsável pela regressão também é exposta.
Solução de problemas
O log de diagnóstico gera informações sobre detalhes de tempo de espera elevadas, hashes de consulta das consultas afetadas.
Como o sistema não conseguiu identificar com sucesso a causa raiz das consultas de baixo desempenho, as informações de diagnóstico são um bom ponto de partida para solução de problemas manual. Você pode otimizar o desempenho das consultas. É uma boa prática buscar apenas os dados que você precisa usar e simplificar e dividir consultas complexas em partes menores.
Para obter mais informações sobre como otimizar o desempenho da consulta, confira Ajuste de consulta.
Contenção de TempDB
O que está acontecendo
Esse padrão de desempenho detectável indica uma condição de desempenho do banco de dados na qual existe um gargalo de threads que tentam acessar recursos de tempdb. (Esta condição não está relacionada a IO.) O cenário típico para esse problema de desempenho são centenas de consultas simultâneas que criam, usam e, em seguida, soltam pequenas tabelas de tempdb. O sistema detectou que o número de consultas simultâneas que usam as mesmas tabelas de tempdb aumentou com significância estatística suficiente para afetar o desempenho do banco de dados em comparação com a linha de base de desempenho dos últimos sete dias.
Solução de problemas
O log de diagnóstico gera detalhes de contenção de tempdb. Você pode usar as informações como o ponto de partida para solução de problemas. Há duas medidas que você pode adotar para aliviar esse tipo de contenção e aumentar a taxa de transferência da carga de trabalho geral: você pode parar de usar as tabelas temporárias. Você também pode usar tabelas de otimização de memória.
Para obter mais informações, consulte Introdução às tabelas com otimização de memória.
Insuficiência de DTU no pool elástico
O que está acontecendo
Esse padrão de desempenho detectável indica uma degradação no desempenho de carga de trabalho de banco de dados atual em comparação à linha de base dos últimos sete dias. É devido à falta de DTUs disponíveis no pool elástico de sua assinatura.
Recursos de pool elástico do Azure são usados como um pool de recursos disponíveis de compartilhados entre vários bancos de dados para fins de dimensionamento. Quando os recursos de eDTU disponíveis em seu pool elástico não forem suficientemente grandes para dar suporte a todos os bancos de dados no pool, um problema de desempenho de insuficiência de DTU no pool elástico será detectado pelo sistema.
Solução de problemas
O log de diagnóstico gera informações sobre o pool elástico, lista os principais bancos de dados que consomem DTU e fornece um percentual de DTU do pool usada pelo banco de dados que mais consome.
Uma vez que essa condição de desempenho está relacionada a vários bancos de dados que usam o mesmo pool de eDTUs no pool elástico, as etapas de solução de problemas concentram-se nos bancos de dados que mais consomem DTU. Você pode reduzir a carga de trabalho nos bancos de dados de maior consumo, o que inclui a otimização das consultas de maior consumo nesses bancos de dados. Você também pode garantir que consulte dados que você não usa. Outra abordagem é otimizar aplicativos usando os bancos de dados que mais consomem DTU e redistribuir a carga de trabalho entre vários bancos de dados de consumo.
Se não for possível reduzir e otimizar a carga de trabalho atual em seus bancos de dados que mais consomem DTU, considere aumentar o tipo de preço do pool elástico. Esse aumento resulta no aumento de DTUs disponíveis no pool elástico.
Regressão de plano
O que está acontecendo
Esse padrão de desempenho detectável denota uma condição em que o banco de dados utiliza um plano de execução de consulta não ideal. O planos não ideal geralmente causa maior execução de consulta, levando a tempos de espera mais longos para a consulta atual e outras consultas.
O mecanismo de banco de dados determina o plano de execução da consulta com o menor custo para uma execução de consulta. À medida que o tipo de consultas e cargas de trabalho mudam, às vezes os planos existentes não são mais eficientes, ou talvez o mecanismo de banco de dados não fez uma boa avaliação. Como uma questão de correção, planos de execução de consulta podem ser forçados manualmente.
Esse padrão de desempenho detectável combina três casos diferentes de regressão de plano: regressão de plano novo, regressão de plano antigo e planos existentes com carga de trabalho alterada. O tipo específico de regressão de plano que ocorreu é apresentado na propriedade detalhes no log de diagnóstico.
A nova condição de regressão do plano refere-se a um estado no qual o mecanismo de banco de dados começa a executar um novo plano de execução de consulta que não é tão eficiente quanto o plano antigo. A condição de regressão do plano antigo refere-se a um estado em que o mecanismo de banco de dados troca o plano novo, mais eficiente, pelo plano antigo, que não é tão eficiente quanto o novo. A regressão de carga de trabalho alterada dos planos existentes refere-se ao estado em que os planos antigo e novo alternam-se continuamente, com o saldo indo mais para o plano de baixo desempenho.
Para obter mais informações sobre regressões de plano, consulte O que é regressão de plano no SQL Server?.
Solução de problemas
O log de diagnóstico gera hashes de consulta, ID de plano bom, ID de plano ruim e IDs de consulta. Você pode usar essa informação como a base para a solução de problemas.
Você pode analisar o plano com melhor desempenho para suas consultas específicas e que você possa identificar com os hashes de consulta fornecidos. Depois de determinar o plano que funciona melhor para suas consultas, você pode forçá-lo manualmente.
Para obter mais informações, consulte Saiba como o SQL Server impede regressões de plano.
Dica
Você sabia que o recurso de inteligência interna pode gerenciar automaticamente os melhores planos de execução de consulta de desempenho para seus bancos de dados?
Para otimizar o desempenho contínuo, é recomendável habilitar o ajuste automático. Esse recurso de inteligência interna monitora continuamente o banco de dados e ajusta e cria de modo automático índices para os bancos de dados.
Alteração do valor de configuração no escopo do banco de dados
O que está acontecendo
Esse padrão de desempenho detectável indica uma condição em que uma alteração à configuração do escopo do banco de dados causa regressão do desempenho detectado em comparação ao comportamento da carga de trabalho de banco de dados nos últimos sete dias. Esse padrão denota que uma alteração recente feita à configuração no escopo do banco de dados não parece ser benéfica ao desempenho do banco de dados.
As alterações de configuração no escopo do banco de dados podem ser definidas para cada banco de dados individual. Essa configuração é usada caso a caso para otimizar o desempenho individual do seu banco de dados. As opções a seguir podem ser configuradas para cada banco de dados individual: MAXDOP, LEGACY_CARDINALITY_ESTIMATION, PARAMETER_SNIFFING, QUERY_OPTIMIZER_HOTFIXES e CLEAR PROCEDURE_CACHE.
Solução de problemas
O log de diagnóstico gera alterações de configuração no escopo do banco de dados feitas recentemente e que causaram a degradação do desempenho em comparação ao comportamento da carga de trabalho dos últimos sete dias. Você pode reverter as alterações de configuração para os valores anteriores. Você também pode ajustar valor por valor até que o nível de desempenho desejado seja atingido. Você pode copiar os valores de configuração de escopo do banco de dados de um banco de dados semelhante com um desempenho satisfatório. Se você não conseguir solucionar problemas de desempenho, reverta para os valores e tente ajustar começando com essa linha de base.
Para obter mais informações sobre como otimizar a configuração de escopo do banco de dados e a sintaxe T-SQL sobre alteração da configuração, consulte Alterar a configuração (Transact-SQL) no escopo do banco de dados.
Cliente lento
O que está acontecendo
Esse padrão de desempenho detectável indica uma condição em que o cliente que usa o banco de dados não pode consumir a saída do banco de dados tão rápido quanto o banco de dados envia os resultados. Uma vez que o Banco de Dados não está armazenando os resultados das consultas executadas em um buffer, ele desacelera e aguarda o cliente consumir as saídas da consulta transmitida antes de continuar. Essa condição também pode estar relacionada a uma rede que não é rápida o suficiente para transmitir as saídas do banco de dados para o cliente consumidor.
Essa condição será gerada apenas se uma regressão de desempenho for detectada em comparação ao comportamento da carga de trabalho do banco de dados nos últimos sete dias. Esse problema de desempenho é detectado somente se ocorrer uma degradação de desempenho estatisticamente significativa em comparação com o comportamento anterior do desempenho.
Solução de problemas
Esse padrão de desempenho detectável indica uma condição no lado do cliente. Solução de problemas é necessária no aplicativo do lado do cliente ou na rede do lado do cliente. O log de diagnóstico gera hashes de consulta e tempos de espera que parecem estar aguardando ao máximo para que o cliente os consuma dentro das duas últimas horas. Você pode usar essa informação como a base para a solução de problemas.
Você pode otimizar o desempenho do seu aplicativo para consumo dessas consultas. Você também pode considerar possíveis problemas de latência de rede. Uma vez que o problema de degradação de desempenho era baseado em alteração na última linha de base de desempenho de sete dias, você pode investigar se alterações recentes de condição de aplicativo ou de rede causaram esse evento de regressão de desempenho.
Downgrade de tipo de preço
O que está acontecendo
Esse padrão de desempenho detectável indica uma condição na qual o tipo de preço da sua assinatura do Banco de Dados sofreu downgrade. Por causa da redução de recursos (DTUs) disponíveis para o banco de dados, o sistema detectou uma queda no desempenho de banco de dados atual em comparação à linha de base de sete dias anterior.
Além disso, pode haver uma condição em que o tipo de preço da assinatura do Banco de Dados sofreu downgrade e, em seguida, recebeu upgrade para uma tipo superior em um curto período de tempo. A detecção dessa degradação de desempenho temporária é produzida na seção de detalhes do log de diagnóstico como um downgrade e uma atualização do tipo de preço.
Solução de problemas
Se você tiver reduzido seu tipo de preço e, portanto, os DTUs disponíveis e estiver satisfeito com o desempenho, não há nada que você precise fazer. Se você tiver reduzido seu tipo de preço e estiver insatisfeito com o desempenho de banco de dados, reduza suas cargas de trabalho do banco de dados ou considere aumentar o tipo de preço para um nível mais alto.
Fluxo de solução de problemas recomendado
Siga o fluxograma para uma abordagem recomendada à solução de problemas de desempenho usando o Intelligent Insights.
Acesse o Intelligent Insights por meio do portal do Azure indo para Análise de SQL do Azure. Tente localizar o alerta de desempenho de entrada e selecione-o. Identifique o que está acontecendo na página de detecções. Observe a análise da causa raiz fornecida do problema, o texto da consulta, as tendências de tempo da consulta e a evolução do incidente. Tente resolver o problema usando a recomendação Intelligent Insights para mitigar o problema de desempenho.
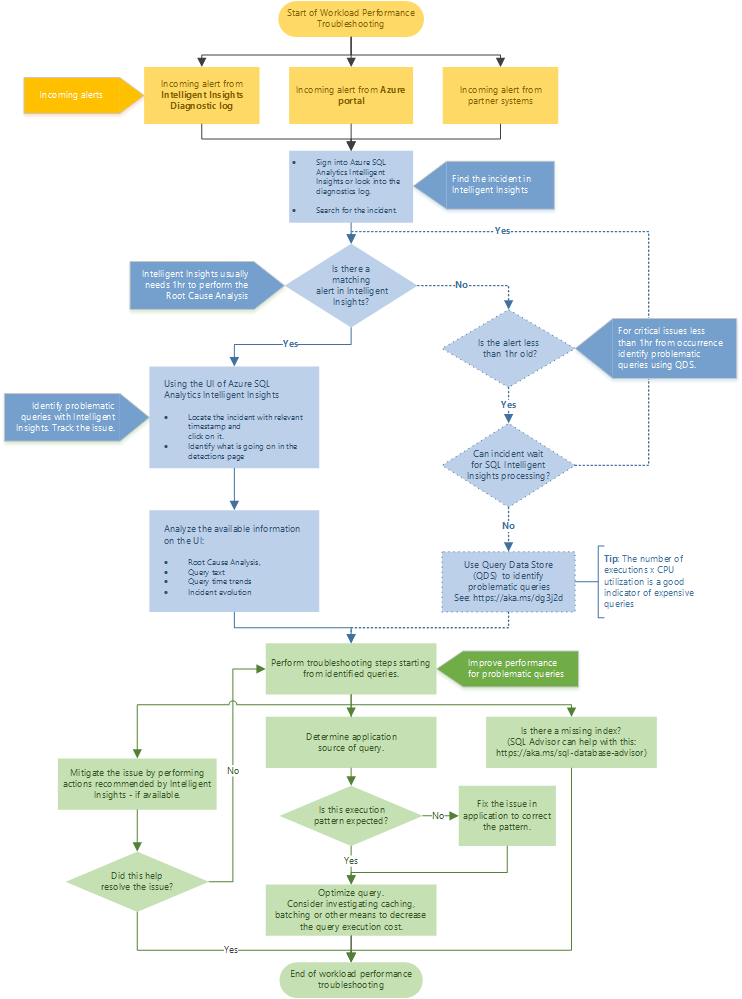
Dica
Selecione o fluxograma para baixar uma versão em PDF.
O Intelligent Insights geralmente precisa de uma hora para executar a análise da causa raiz do problema de desempenho. Se você não puder localizar o problema no Intelligent Insights e ele for crucial para você, use o Repositório de Consultas para identificar manualmente a causa raiz do problema de desempenho. (Normalmente, esses problemas têm menos de uma hora.) Para obter mais informações, consulte monitorar o desempenho usando o repositório de consultas.
Próximas etapas
- Aprenda os conceitos de Intelligent Insights.
- Use o log de diagnóstico de desempenho do Intelligent Insights.
- Monitorar usando a Análise de SQL do Azure
- Saiba como coletar e consumir dados de log dos recursos do Azure.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de