Apache Spark MLlib e acompanhamento de MLflow automatizado
Observação
O rastreamento de MLflow automatizado da MLlib foi descontinuado em clusters que executam o Databricks Runtime 10.1 ML e superiores e está desabilitado por padrão em clusters que executam o Databricks Runtime 10.2 ML e superiores. Em seu lugar, use o registro em log automático PySpark ML do MLflowchamando mlflow.pyspark.ml.autolog(), habilitado por padrão com o Databricks Autologging.
Para usar o antigo acompanhamento de MLflow automatizado da MLlib no Databricks Runtime 10.2 ML ou superiores, habilite-o definindo as configurações do Spark spark.databricks.mlflow.trackMLlib.enabled true e spark.databricks.mlflow.autologging.enabled false.
O MLflow é uma plataforma de fonte aberta para gerenciar o ciclo de vida de machine learning de ponta a ponta. O MLflow oferece suporte ao acompanhamento para ajuste de modelo de aprendizado de máquina no Python, R e Scala. Somente para notebooks Python, as versões e compatibilidade de notas sobre a versão do Databricks Runtime e o Databricks Runtime para Aprendizado de máquina oferecem suporte ao controle automatizado de Acompanhamento do MLflow para o ajuste de modelo MLlib do Apache Spark.
Com o acompanhamento de MLflow automatizado da MLlib, quando você executa o código de ajuste que use CrossValidatorou TrainValidationSplit, os hiperparâmetros e as métricas de avaliação são registrados automaticamente no MLflow. Sem o acompanhamento de MLflow automatizado, você deve fazer chamadas explícitas de API para registro no MLflow.
Gerenciar as execuções do MLflow
Resultados de ajuste de log CrossValidator ou TrainValidationSplit com as execuções aninhadas do MLflow:
- Execução principal ou pai: as informações de
CrossValidatorouTrainValidationSplitsão registradas na execução principal. Se já houver uma execução ativa, as informações serão registradas nessa execução, que não será interrompida. Se não houver execução ativa, o MLflow criará uma nova, fará o registro nela e encerrará a execução antes de retornar. - Execuções filhas: cada configuração de hiperparâmetro testada e a métrica de avaliação correspondente são registradas em uma execução filha na execução principal.
Ao chamar fit(), o Azure Databricks recomenda o gerenciamento de execução do MLflow ativo, ou seja, encapsule a chamada para fit() em uma instrução “with mlflow.start_run():”.
Isso garante que as informações sejam registradas em sua própria execução principal do MLflow e facilita o registro de marcas, parâmetros ou métricas adicionais nessa operação.
Observação
Quando fit() é chamado várias vezes na mesma execução ativa do MLflow, ele registra essas várias execuções na mesma execução principal. Para resolver conflitos de nome para parâmetros e marcas do MLflow, ele anexa um UUID aos nomes com conflitos.
O notebook Python a seguir demonstra o acompanhamento de MLflow automatizado.
Acompanhamento de MLflow automatizado
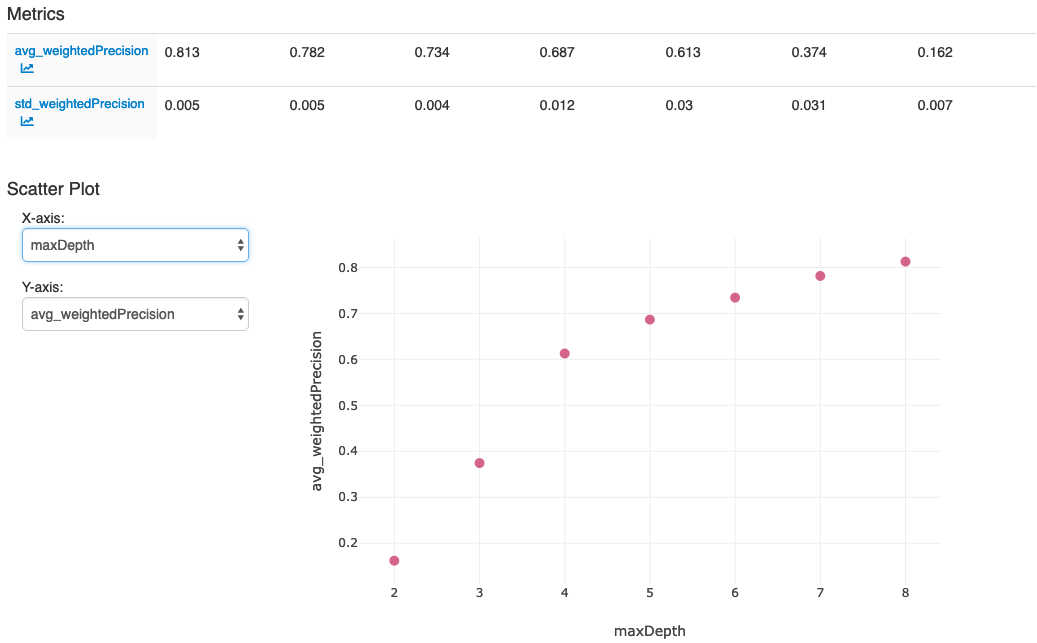
Após a execução das ações na última célula do notebook, sua interface do usuário do MLflow deverá exibir:
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de