IA e aprendizado de máquina no Databricks
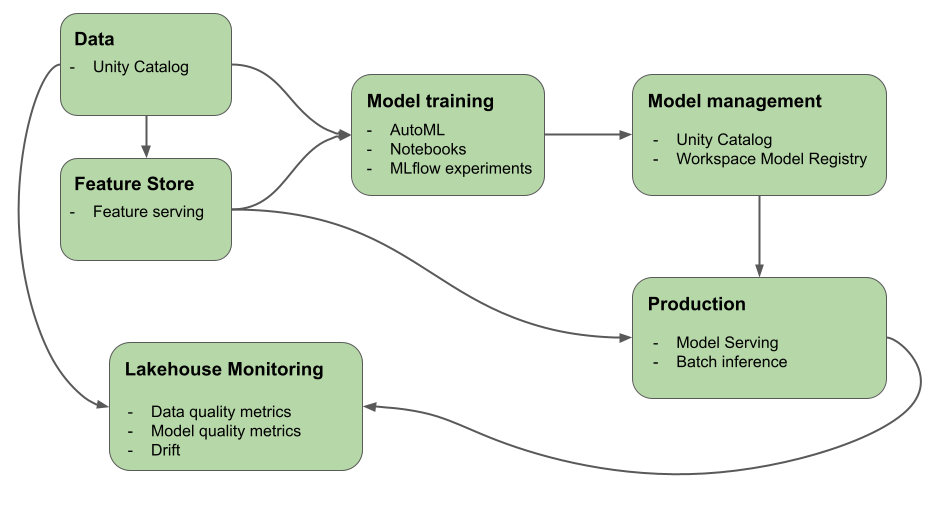
Este artigo descreve as ferramentas que o Mosaic AI (anteriormente Databricks Machine Learning) fornece para ajudar você a criar sistemas de IA e de ML. O diagrama mostra como vários produtos na plataforma Databricks ajudam você a implementar seus fluxos de trabalho de ponta a ponta para criar e implantar sistemas de IA e de ML
IA generativa no Databricks
A Ia do Mosaic unifica o ciclo de vida de IA da coleta e da preparação de dados ao desenvolvimento de modelos, ao LLMOps, ao serviço e ao monitoramento. Os seguintes recursos são especificamente otimizados para facilitar o desenvolvimento de aplicativos de IA generativa:
- Catálogo do Unity para governança, descoberta, controle de versão e controle de acesso para dados, recursos, modelos e funções.
- MLflow para acompanhamento de desenvolvimento de modelo.
- Gateway de IA do Mosaic para controlar e monitorar o acesso a modelos de IA generativos compatíveis e os respectivos pontos de extremidade de serviço de modelos associados.
- Mosaic AI Model Serving para a implantação de LLMs. Você pode configurar um ponto de extremidade de serviço de modelo especificamente para acessar modelos de IA generativos:
- LLMs abertos de última geração usando APIs Foundation Model.
- Modelos de terceiros hospedados fora da Databricks. Consulte Modelos externos no Mosaic AI Model Serving.
- O Mosaic AI Vector Search fornece um banco de dados de vetores consultável que armazena vetores de inserção e pode ser configurado para sincronização automática com sua base de conhecimento.
- Monitoramento do Lakehouse para monitorar dados e rastrear a qualidade e o descompasso de dados das previsões do modelo usando o registro automático de carga útil com tabelas de inferência.
- AI Playground para testar modelos de IA generativos do workspace do Databricks. Você pode solicitar, comparar e ajustar configurações como parâmetros de inferência e de prompt do sistema.
- Ajuste fino do modelo de base (agora parte do Mosaic AI Model Training) para personalizar um modelo de base usando seus próprios dados para otimizar seu desempenho para seu aplicativo específico.
- Estrutura de Agente IA Mosaic para criar e implantar agentes de qualidade de produção, como aplicativos RAG (geração aumentada de recuperação).
- Avaliação do Agente de IA Mosaic para avaliar a qualidade, o custo e a latência dos aplicativos de IA generativa, incluindo aplicativos e cadeias com RAG.
O que é a IA generativa?
A IA generativa é um tipo de inteligência artificial focada na capacidade dos computadores de usar modelos para criar conteúdo como imagens, texto, código e dados sintéticos.
Os aplicativos de IA generativos são criados com base em modelos de IA generativos: LLMs (modelos de linguagem grandes) e modelos de base.
- LLMs são modelos de aprendizagem profunda que consomem e treinam conjuntos de dados massivos para se destacarem em tarefas de processamento de linguagem. Eles criam novas combinações de texto que imitam a linguagem natural com base nos seus dados de treinamento.
- Modelos de IA generativa ou modelos de base são grandes modelos de ML pré-treinados com a intenção de serem ajustados para tarefas de compreensão e geração de linguagem mais específicas. Esses modelos são usados para discernir padrões dentro dos dados de entrada.
Depois que esses modelos concluírem seus processos de aprendizagem, juntos eles geram resultados estatisticamente prováveis quando solicitados e podem ser empregados para realizar várias tarefas, incluindo:
- Geração de imagens com base nas existentes ou utilizando o estilo de uma imagem para modificar ou criar uma nova.
- Tarefas de fala como transcrição, tradução, geração de perguntas/respostas e interpretação da intenção ou significado do texto.
Importante
Embora muitos LLMs ou outros modelos de IA generativos tenham proteções, eles ainda podem gerar informações prejudiciais ou imprecisas.
A IA Generativa tem os seguintes padrões de design:
- Engenharia de prompt: criar prompts especializados para orientar o comportamento de LLM
- RAG (Geração Aumentada de Recuperação): combinar um LLM com recuperação de conhecimento externo
- Ajuste fino: adaptar um LLM pré-treinado a conjuntos de dados específicos de domínios
- Pré-treinamento: treinar um LLM do zero
Suporte para modelos de IA de geração multimodal
Modelos de IA multimodais processam e geram resultados em vários tipos de dados, como texto, imagens, áudio e vídeo. O Azure Databricks dá suporte a uma variedade de modelos de IA de geração multimodal que podem ser implantados por meio da API ou no modo de lote, garantindo flexibilidade e escalabilidade em todos os cenários de implantação:
- Modelos multimodais: Use modelos multimodais hospedados, como o Llama 3.2 e modelos externos, como o GPT-4o. Confira Modelos de base com suporte no Serviço de Modelo de IA do Mosaic.
- Modelos ajustados e personalizados: Ajuste modelos para otimização em casos de uso específicos. Confira Ajuste fino do modelo de base.
Aprendizado de máquina no Databricks
Com a IA do Mosaic, uma única plataforma atende a todas as etapas do desenvolvimento e da implantação de ML, de dados brutos a tabelas de inferência que salvam todas as solicitações e respostas de um modelo servido. Cientistas de dados, engenheiros de dados, engenheiros de ML e DevOps podem fazer seu trabalho usando o mesmo conjunto de ferramentas e uma única fonte de verdade para os dados.
O Mosaic IA unifica a camada de dados e a plataforma de ML. Todos os ativos e artefatos de dados, como modelos e funções, podem ser descobertos e controlados em um único catálogo. O uso de uma única plataforma para dados e modelos possibilita o acompanhamento da linhagem, desde os dados brutos até o modelo de produção. O monitoramento integrado de dados e modelos salva métricas de qualidade em tabelas que também são armazenadas na plataforma, facilitando a identificação da causa raiz dos problemas de desempenho do modelo. Para obter mais informações sobre como o Databricks oferece suporte a todo o ciclo de vida de ML e MLOps, consulte Fluxos de trabalho de MLOps no Azure Databricks e MLOps Stacks: processo de desenvolvimento de modelos como código.
Alguns dos principais componentes da plataforma de inteligência de dados são:
| Tarefas | Componente |
|---|---|
| Administrar e gerenciar dados, recursos, modelos e funções. Além disso, descoberta, controle de versão e linhagem. | Catálogo do Unity |
| Rastrear alterações nos dados, na qualidade dos dados e na qualidade da previsão do modelo | Monitoramento do Lakehouse, Tabelas de inferência para modelos personalizados |
| Desenvolvimento e gerenciamento de recursos | Engenharia de recursos e serviço. |
| Treinar modelos | AutoML, notebooks do Databricks |
| Acompanhar o desenvolvimento de modelos | Acompanhamento do MLflow |
| Servir modelos personalizados | Serviço de Modelos de IA do Mosaic. |
| Crie fluxos de trabalho automatizados e pipelines ETL prontos para produção | Trabalhos do Databricks |
| Integração do Git | Pastas Git do Databricks |
Aprendizado profundo no Databricks
Configurar a infraestrutura para aplicativos de aprendizado profundo pode ser difícil. O Databricks Runtime para aprendizado de máquina cuida disso para você, com clusters que têm versões internas compatíveis das bibliotecas de aprendizado profundo mais comuns, como TensorFlow, PyTorch e Keras.
Os clusters de ML do Databricks Runtime também incluem suporte de GPU pré-configurado com drivers e bibliotecas de suporte. Ele também oferece suporte a bibliotecas, como Ray, para paralelizar o processamento de computação para dimensionar fluxos de trabalho e aplicativos de ML.
Os clusters de ML do Databricks Runtime também incluem suporte de GPU pré-configurado com drivers e bibliotecas de suporte. O Serviço de Modelo do Mosaic AI permite a criação de pontos de extremidade de GPU escalonáveis para modelos de aprendizado profundo sem nenhuma configuração extra.
Para aplicativos de aprendizado de máquina, a recomendação do Databricks é usar um cluster que execute o Databricks Runtime para Machine Learning. Confira Criar um cluster usando o Databricks Runtime ML.
Para começar a usar o aprendizado profundo no Databricks, confira:
- Melhores práticas de aprendizado profundo no Azure Databricks
- Aprendizado profundo no Databricks
- Soluções de referência para aprendizado profundo
Próximas etapas
Para começar. confira:
Para obter um fluxo de trabalho de MLOps recomendado no Databricks Mosaic AI, confira:
Para saber mais sobre os principais recursos do Databricks Mosaic AI, confira: