Migrar cluster do HDInsight para uma nova versão
Para aproveitar os novos recursos do HDInsight, é recomendável que os clusters do HDInsight sejam atualizados frequentemente para a versão mais recente. O HDInsight não oferece suporte a atualizações in-loco em que um cluster existente é atualizado para uma versão de componente mais recente. Para usar o novo cluster, é necessário criar um novo cluster com o componente e a versão de plataforma desejados e, em seguida, migrar os aplicativos. Siga as diretrizes abaixo para migrar as versões do cluster do HDInsight.
Observação
Se você estiver criando um cluster Hive com um contêiner de armazenamento primário, copie-o de um cluster HDInsight existente. Não copie todo o conteúdo. Copie somente as pastas de dados configuradas.
Tarefas de migração
O fluxo de trabalho para atualizar o cluster HDInsight serão apresentadas a seguir.
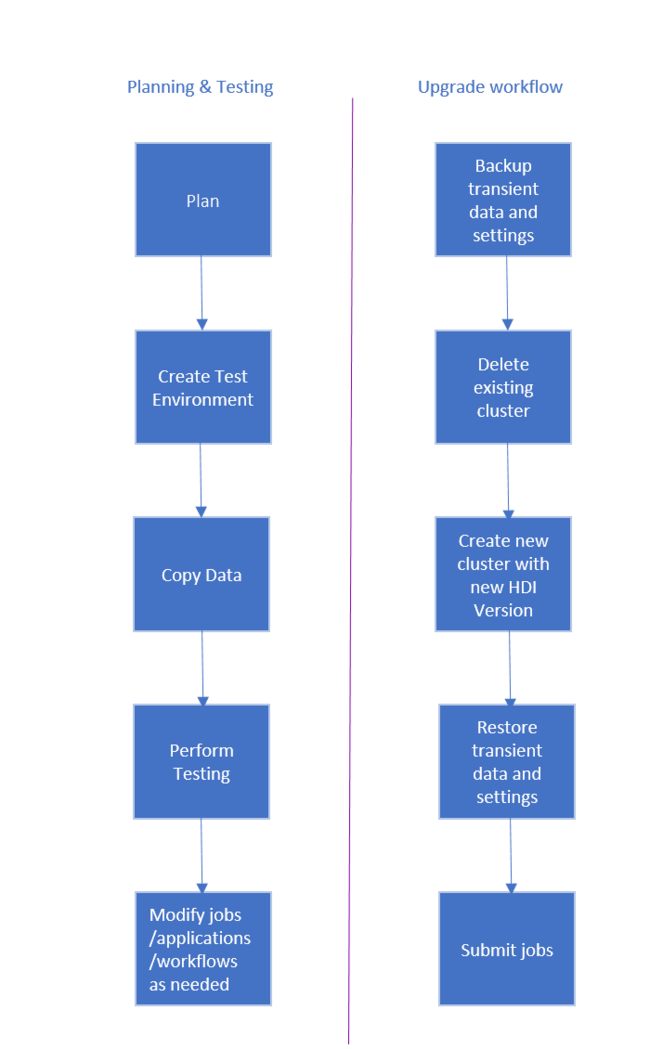
- Leia cada seção deste documento para entender as alterações que podem ser necessárias ao atualizar o cluster HDInsight.
- Crie um cluster como um ambiente de teste/garantia de qualidade. Para saber mais sobre como criar um cluster, consulte Saiba como criar clusters HDInsight baseados em Linux
- Copie trabalhos, fontes de dados e coletores existentes para o novo ambiente.
- Execute testes de validação para garantir que os trabalhos funcionem conforme o esperado no novo cluster.
Depois de verificar se tudo está funcionando conforme o esperado, agende o tempo de inatividade para a migração. Durante esse tempo de inatividade, execute as tarefas a seguir:
- Faça backup de dados transitórios armazenados localmente em nós do cluster. Por exemplo, se você tiver dados armazenados diretamente em um nó principal.
- Exclua o cluster existente.
- Crie um cluster na mesma sub-rede VNET com a versão do HDI mais recente (ou com suporte) que usa o mesmo armazenamento de dados padrão utilizado pelo cluster anterior. Isso permite que o novo cluster continue trabalhando nos dados de produção existentes.
- Importe o backup de todos os dados transitórios.
- Inicie os trabalhos/continue processando usando o novo cluster.
Diretrizes específicas da carga de trabalho
Os documentos a seguir fornecem diretrizes sobre como migrar cargas de trabalho específicas:
Fazer backup e restaurar
Para obter mais informações sobre backup e restauração de banco de dados, consulte Recuperar um banco de dados no banco de dados SQL do Azure usando backups de banco de dados automáticos.
Cenários de atualização
Conforme mencionado acima, a Microsoft recomenda que os clusters HDInsight sejam migrados regularmente para a versão mais recente para aproveitar novos recursos e correções. Confira a lista de motivos a seguir para solicitar que um cluster seja excluído e reimplantado:
- A versão do cluster foi desativada ou se você estiver tendo um problema de cluster que seria resolvido com uma versão mais recente.
- A causa raiz de um problema de cluster é determinada como relacionada a uma VM subdimensionada. Veja a configuração de nó recomendada da Microsoft.
- Um cliente abre um caso de suporte e a equipe de engenharia da Microsoft determina que o problema já foi corrigido em uma versão mais recente do cluster.
- Um banco de dados metastore padrão (Ambari, Hive, Oozie, Ranger) atingiu seu limite de utilização. A Microsoft solicita que você recrie o cluster usando um banco de dados do metastore personalizado.
- A causa raiz de um problema de cluster é devido a uma operação sem suporte. Aqui estão algumas das operações comuns sem suporte:
- Mover ou adicionar um serviço no Ambari. Veja nas informações sobre o serviço de cluster no Ambari que uma das ações disponíveis no menu de Ações do serviço é Mover o [Nome do serviço]. Outra ação é Adicionar [Nome do Serviço] . Não há suporte para ambas as opções.
- Corrupção de pacote do Python. Os clusters HDInsight dependem dos ambientes internos do Python, tanto Python 2.7 quanto Python 3.5. A instalação direta de pacotes personalizados nesses ambientes internos padrão pode causar alterações inesperadas na versão da biblioteca e interromper o cluster. Saiba como instalar com segurança pacotes externos do Python personalizados para seus aplicativos Spark.
- Software de terceiros. Os clientes têm a capacidade de instalar software de terceiros em seus clusters HDInsight, mas recomendamos recriar o cluster se ele interromper a funcionalidade existente.
- Várias cargas de trabalho no mesmo cluster. No HDInsight 4.0, o Hive Warehouse Connector precisa de clusters separados para cargas de trabalho do Spark e do Interactive Query. Siga estas etapas para configurar ambos os clusters no Azure HDInsight. Da mesma forma, a integração do Spark ao HBASE requer dois clusters diferentes.
- A senha personalizada do Ambari DB foi alterada. A senha do Ambari DB é definida durante a criação do cluster e não há nenhum mecanismo atual para atualizá-la. Se um cliente implantar o cluster com um BD Ambari personalizado, ele poderá alterar a senha do banco de dados no banco de dados SQL; no entanto, não há como atualizar essa senha em um cluster HDInsight em execução.
- Modificando balanceadores de carga do HDInsight. Os balanceadores de carga do HDInsight que são implantados automaticamente para acesso do Ambari e SSH não devem ser modificados ou excluídos. Se você modificar os balanceadores de carga do HDInsight e isso interromper a funcionalidade do cluster, você será aconselhado a reimplantar o cluster.