Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Os vetores são inserções de alta dimensão que representam texto, imagens e outros conteúdos matematicamente. O Azure AI Search armazena vetores no nível do campo, permitindo que o conteúdo de vetor e não vetor coexista no mesmo índice de pesquisa.
Um índice de pesquisa se torna um índice de vetor quando você define campos de vetor e uma configuração de vetor. Para preencher campos de vetor, você pode enviar inserções pré-computadas para eles ou usar a vetorização integrada, uma funcionalidade interna do Azure AI Search que gera inserções durante a indexação.
No momento da consulta, os campos de vetor em seu índice habilitam a pesquisa de similaridade, em que o sistema recupera documentos cujos vetores são mais semelhantes à consulta de vetor. Você pode usar a pesquisa de vetor para correspondência de similaridade sozinha ou pesquisa híbrida para uma combinação de similaridade e correspondência de palavras-chave.
Este artigo aborda os principais conceitos para criar e gerenciar um índice de vetor, incluindo:
- Padrões de recuperação de vetor
- Conteúdo (campos de vetor e configuração)
- Estrutura física de dados
- Operações básicas
Dica
Quer começar imediatamente? Consulte Criar um índice de vetor.
Padrões de recuperação de vetor
O Azure AI Search dá suporte a dois padrões para recuperação de vetor:
Pesquisa clássica. Esse padrão usa uma barra de pesquisa, entrada de consulta e resultados renderizados. Durante a execução da consulta, o mecanismo de pesquisa ou o código do aplicativo vetoriza a entrada do usuário. Em seguida, o mecanismo de pesquisa executa a pesquisa de vetor sobre os campos de vetor em seu índice e formula uma resposta que você renderiza em um aplicativo cliente.
No Azure AI Search, os resultados são retornados como um conjunto de linhas achatado e você pode escolher quais campos incluir na resposta. Embora o mecanismo de pesquisa corresponda a vetores, seu índice deve ter um conteúdo não vetor e legível para preencher os resultados da pesquisa. A pesquisa clássica dá suporte a consultas vetoriais e consultas híbridas.
Pesquisa generativa. Os modelos de linguagem usam dados do Azure AI Search para responder a consultas de usuário. Uma camada de orquestração normalmente coordena os prompts e mantém o contexto, alimentando os resultados da pesquisa em modelos de bate-papo como o GPT. Esse padrão é baseado na arquitetura RAG (geração aumentada de recuperação), em que o índice de pesquisa fornece dados de fundamentação.
Esquema de um índice de vetor
O esquema de um índice de vetor requer o seguinte:
- Nome
- Campo de chave (cadeia de caracteres)
- Um ou mais campos de vetor
- Configuração do vetor
Os campos não vetores não são necessários, mas recomendamos incluí-los para consultas híbridas ou para retornar conteúdo verbatim que não passa por um modelo de linguagem. Para obter mais informações, veja Criar um índice de vetor.
O esquema de índice deve refletir o padrão de recuperação de vetor. Esta seção aborda principalmente a composição de campo para pesquisa clássica, mas também fornece diretrizes de esquema para pesquisa gerativa.
Configuração básica do campo de vetor
Os campos de vetor têm propriedades e tipos de dados exclusivos. Veja a aparência de um campo de vetor em uma coleção de campos:
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
Somente determinados tipos de dados têm suporte para campos de vetor. O tipo mais comum é Collection(Edm.Single), mas o uso de tipos estreitos pode salvar no armazenamento.
Os campos de vetor devem ser pesquisáveis e recuperáveis, mas não podem ser filtrados, facetáveis ou classificáveis. Eles também não podem ter analisadores, normalizadores ou atribuições de mapas de sinônimos.
A dimensions propriedade deve ser definida como o número de inserções geradas pelo modelo de inserção. Por exemplo, text-embedding-ada-002 gera 1.536 inserções para cada parte do texto.
Os campos de vetor são indexados usando algoritmos especificados em um perfil de pesquisa de vetor, que é definido em outro lugar no índice e não mostrado neste exemplo. Para obter mais informações, consulte Adicionar uma configuração de pesquisa de vetor.
Coleção de campos para cargas de trabalho de vetor básicas
Os índices de vetor exigem mais do que apenas campos de vetor. Por exemplo, todos os índices devem ter um campo de chave, que está id no exemplo a seguir:
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
Outros campos, como o content campo, fornecem o equivalente legível por humanos do content_vector campo. Caso esteja usando modelos de linguagem exclusivamente para formulação de resposta, poderá omitir campos de conteúdo não vetorial, mas soluções que efetuam push dos resultados da pesquisa diretamente para aplicativos cliente, devem ter conteúdo não vetorial.
Os campos de metadados são úteis para filtros, especialmente se incluirem informações de origem sobre o documento de origem. Embora não seja possível filtrar diretamente em um campo de vetor, você pode definir os modos pré-filtro, pós-filtro ou pós-filtro estrito (versão prévia) para filtrar antes ou depois da execução da consulta de vetor.
Esquema gerado pelo assistente de importação
Recomendamos o assistente de importação de dados para avaliação e teste de prova de conceito. O assistente gera o esquema de exemplo nesta seção.
O assistente agrupa seu conteúdo em documentos de pesquisa menores, o que beneficia aplicativos RAG que usam modelos de linguagem para formular respostas. A divisão em partes ajuda você a ficar dentro dos limites de entrada dos modelos de linguagem e dos limites de token do classificador semântico. Ele também melhora a precisão na pesquisa de similaridade ao comparar consultas a partes extraídas de vários documentos de origem. Para obter mais informações, veja Dividir documentos grandes em partes para soluções de busca em vetores.
Para cada documento de pesquisa no exemplo a seguir, há uma ID de parte, ID pai, parte, título e campo vetorial. O assistente:
Preenche os campos
chunk_ideparent_idcom metadados de blob codificados em Base64 (caminho).Extrai os campos
chunkdo conteúdo do blob etitledo nome do blob, respectivamente.Cria o
vectorcampo chamando um modelo de inserção do Azure OpenAI que você fornece para vetorizar ochunkcampo. Somente o campo de vetor é totalmente gerado durante esse processo.
"name": "example-index-from-import-wizard",
"fields": [
{ "name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
Esquema para pesquisa gerativa
Se você estiver projetando o armazenamento de vetores para aplicativos no estilo RAG e chat, poderá criar dois índices:
- Um para conteúdo estático que você indexou e vetorizou.
- Um para conversas que podem ser usadas em prompt flows.
Para fins ilustrativos, esta seção usa o chat-with-your-data-solution-accelerator para criar os chat-index e conversations índices.
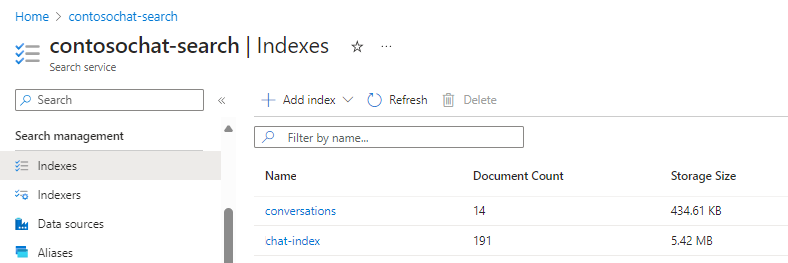
Os seguintes campos de chat-index dão suporte a experiências de pesquisa generativa:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
Os seguintes campos de conversations oferecem suporte à orquestração e ao histórico de chat:
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
A captura de tela a seguir mostra os resultados da conversations pesquisa no Gerenciador de Pesquisa:
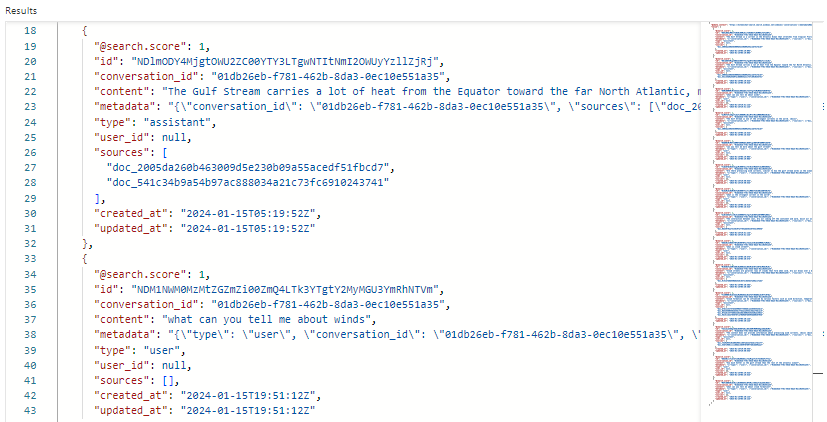
Em nosso exemplo, a pontuação de pesquisa é 1,00 porque a pesquisa não é qualificada. Vários campos dão suporte à orquestração e a prompt flows:
-
conversation_ididentifica cada sessão de chat. -
typeindica se o conteúdo é do usuário ou do assistente. -
created_ateupdated_attornam os chats do histórico obsoletos.
Estrutura física e tamanho
Na IA do Azure Search, a estrutura física de um índice é basicamente uma implementação interna. Você pode acessar seu esquema, carregar e consultar seu conteúdo, monitorar seu tamanho e gerenciar sua capacidade. No entanto, a Microsoft gerencia a infraestrutura e as estruturas de dados físicos armazenadas com seu serviço de pesquisa.
O tamanho e a substância de um índice são determinados pelo:
Quantidade e composição de seus documentos.
Pelos atributos em campos individuais. Por exemplo, mais armazenamento é necessário para campos filtrados.
Configuração de índice, incluindo a configuração de vetor que especifica como as estruturas de navegação internas são criadas. Você pode escolher HNSW ou KNN exaustivo para pesquisa de similaridade.
A Pesquisa de IA do Azure impõe limites ao armazenamento de vetores, o que ajuda a manter um sistema equilibrado e estável para todas as cargas de trabalho. Para ajudá-lo a permanecer abaixo dos limites, o uso de vetores é acompanhado e relatado separadamente no portal do Azure e programaticamente por meio de estatísticas de serviço e índice.
A captura de tela a seguir mostra um serviço S1 configurado com uma partição e uma réplica. Esse serviço tem 24 índices pequenos, cada um com uma média de um campo de vetor que consiste em 1.536 inserções. O segundo bloco mostra a cota e o uso para índices de vetor. Como um índice de vetor é uma estrutura de dados interna criada para cada campo de vetor, o armazenamento para índices vetoriais é sempre uma fração do armazenamento geral usado pelo índice. Campos não coletores e outras estruturas de dados consomem o restante.
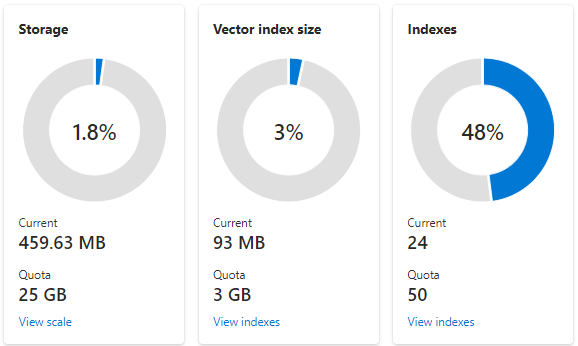
Os limites de índice vetor e as estimativas são abordados em outro artigo, mas dois pontos a serem enfatizados são que o armazenamento máximo depende da data de criação e do tipo de preço do serviço de pesquisa. Os serviços mais recentes da mesma camada têm significativamente mais capacidade para índices de vetor. Por esses motivos, você deve:
Verifique a data de criação do serviço de pesquisa. Se ele tiver sido criado antes de 3 de abril de 2024, você poderá atualizar seu serviço para maior capacidade.
Escolha uma camada escalonável se você prever flutuações nos requisitos de armazenamento de vetor. Para serviços de pesquisa mais antigos, a camada Básica é fixada em uma partição. Considere o Standard 1 (S1) e superior para obter mais flexibilidade e desempenho mais rápido. Você também pode alternar entre os níveis Básico e Standard (S1, S2 e S3).
Operações básicas e interação
Esta seção apresenta operações de tempo de execução de vetor, incluindo a conexão e a proteção de um índice individual.
Observação
Não há suporte para portal ou API para mover ou copiar um índice. Normalmente, você aponta sua implantação de aplicativo para um serviço de pesquisa diferente (usando o mesmo nome de índice) ou revisa o nome para criar uma cópia no serviço de pesquisa atual e, em seguida, compilá-la.
Isolamento de índice
No Azure AI Search, você trabalha com um índice por vez. Todas as operações relacionadas ao índice têm como destino um único índice. Não há conceitos de índices relacionados nem junção de índices independentes para indexação ou consulta.
Disponível continuamente
Um índice fica imediatamente disponível para consultas assim que o primeiro documento é indexado, mas não está totalmente operacional até que todos os documentos sejam indexados. Internamente, um índice é distribuído entre partições e executado em réplicas. O índice físico é gerenciado internamente. Você gerencia o índice lógico.
Um índice está continuamente disponível e não pode ser pausado ou colocado offline. Como ele foi projetado para operação contínua, as atualizações de seu conteúdo e adições ao próprio índice ocorrem em tempo real. Se uma solicitação coincidir com uma atualização de documento, as consultas poderão retornar temporariamente resultados incompletos.
A continuidade da consulta existe para operações de documento, como atualização ou exclusão, e para modificações que não afetam a estrutura ou a integridade existentes de um índice, como a adição de novos campos. As atualizações estruturais, como a alteração de campos existentes, normalmente são gerenciadas usando um fluxo de trabalho de drop-and-rebuild em um ambiente de desenvolvimento ou criando uma nova versão do índice no serviço de produção.
Para evitar uma reconstrução do índice, alguns clientes que estão fazendo pequenas alterações versionam um campo criando um novo que coexiste com uma versão anterior. Ao longo do tempo, isso resulta em conteúdos órfãos, por meio de campos obsoletos e definições obsoletas do analisador personalizado, especialmente em um índice de produção cuja replicação é cara. Você pode resolver esses problemas durante atualizações planejadas para o índice como parte do gerenciamento do ciclo de vida do índice.
Conexão do ponto de extremidade
Todas as solicitações de indexação de vetor e consulta têm como destino um índice. Os pontos de extremidade geralmente são um dos seguintes:
| Ponto de extremidade | Conexão e controle de acesso |
|---|---|
<your-service>.search.windows.net/indexes |
Tem como destino a coleção de índices. Usado ao criar, listar ou excluir um índice. Os direitos de administrador são necessários para essas operações e estão disponíveis por meio de chaves de API de administrador ou uma função de Colaborador de Pesquisa. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
Tem como destino a coleção de documentos de um único índice. Usado ao consultar um índice ou atualização de dados. Para consultas, os direitos de leitura são suficientes e estão disponíveis por meio de chaves de API de consulta ou uma função de leitor de dados. Para a atualização de dados, são necessários direitos de administrador. |
Como se conectar à Pesquisa de IA do Azure
Garanta ter permissões ou uma chave de acesso à API. A menos que você esteja consultando um índice existente, você precisará de direitos de administrador ou de uma atribuição de função colaborador para gerenciar e exibir conteúdo em um serviço de pesquisa.
Comece com o portal do Azure. A pessoa que criou o serviço de pesquisa pode exibi-lo e gerenciá-lo, incluindo a concessão de acesso a outras pessoas na página controle de acesso (IAM ).
Passe para outros clientes para acesso programático. Para as primeiras etapas, recomendamos o Início Rápido: Pesquisa de vetor usando REST e o repositório azure-search-vector-samples .
Gerenciar repositórios de vetores
O Azure fornece uma plataforma de monitoramento que inclui log e alertas de diagnósticos. Recomendamos que você:
Proteger o acesso aos dados de vetor
A Pesquisa de IA do Azure implementa criptografia de dados, conexões privadas para cenários sem Internet e atribuições de função para acesso seguro por meio do Microsoft Entra ID. Para obter mais informações sobre os recursos de segurança da empresa, consulte Dados, privacidade e proteções internas.