Segurança, acesso e operações para migrações do Netezza
Este artigo é a terceira parte de uma série de sete partes que oferece diretrizes para fazer a migração do Netezza para o Azure Synapse Analytics. O foco deste artigo é descrever as melhores práticas para operações de acesso à segurança.
Considerações de segurança
Este artigo aborda os métodos de conexão para ambientes herdados do Netezza e como eles podem ser migrados para o Azure Synapse Analytics com impacto para o usuário e risco mínimos.
Este artigo presume que haja o requisito de migrar os métodos de conexão existentes e a estrutura de usuários/funções/permissões como estão. Caso contrário, use o portal do Azure para criar e gerenciar um novo regime de segurança.
Para obter mais informações sobre as opções de Segurança do Azure Synapse, consulte o Whitepaper de segurança.
Conexão e autenticação
Dica
A autenticação no Netezza e no Azure Synapse pode ocorrer "no banco de dados" ou por meio de métodos externos.
Opções de autorização do Netezza
O sistema IBM Netezza oferece vários métodos de autenticação para usuários de banco de dados do Netezza:
Autenticação local: os administradores do Netezza definem os usuários do banco de dados e as respectivas senhas usando o comando
CREATE USERou por meio de interfaces administrativas do Netezza. Na autenticação local, use o sistema Netezza para gerenciar contas e senhas de banco de dados e adicionar e remover usuários do banco de dados do sistema. Esse é o método de autenticação padrão.Autenticação LDAP: use um servidor de nomes LDAP para autenticar usuários do banco de dados e gerenciar senhas, ativar e desativar contas de banco de dados. O sistema Netezza usa um PAM (Módulo de Autenticação Conectável) para autenticar usuários no servidor de nomes LDAP. O Microsoft Active Directory está em conformidade com o protocolo LDAP e, portanto, pode ser tratado como um servidor LDAP para fins de autenticação LDAP.
Autenticação Kerberos: use um servidor de distribuição Kerberos para autenticar usuários do banco de dados e gerenciar senhas, ativar e desativar contas de banco de dados.
A autenticação é uma configuração de todo o sistema. Os usuários devem ser autenticados localmente ou autenticados usando o método LDAP ou Kerberos. Se você optar pela autenticação LDAP ou Kerberos, crie usuários com autenticação local por usuário. O LDAP e o Kerberos não podem ser usados ao mesmo tempo para autenticar usuários. O host do Netezza dá suporte à autenticação LDAP ou Kerberos somente para logons de usuário de banco de dados, não para logons do sistema operacional no host.
Opções de autorização do Azure Synapse
O Azure Synapse dá suporte a duas opções básicas de conexão e autorização:
Autenticação SQL: a autenticação SQL ocorre por meio de uma conexão de banco de dados que inclui um identificador de banco de dados, uma ID de usuário e uma senha, além de outros parâmetros opcionais. Funcionalmente, isso é equivalente a conexões locais do Netezza.
Autenticação do Microsoft Entra: com a autenticação do Microsoft Entra, você pode gerenciar centralmente as identidades dos usuários de banco de dados e outros serviços da Microsoft em um local central. O gerenciamento central de IDs fornece um único local para gerenciar os usuários do Azure Synapse e simplifica o gerenciamento de permissões. A ID Microsoft Entra também pode oferecer suporte às conexões com os serviços LDAP e Kerberos - por exemplo, a ID do Microsoft Entra pode ser usada para se conectar aos diretórios LDAP existentes, caso eles devam permanecer no local após a migração do banco de dados.
Usuários, funções e permissões
Visão geral
Dica
O planejamento de alto nível é essencial para um projeto de migração bem-sucedido.
Tanto o Netezza quanto o Azure Synapse implementam o controle de acesso ao banco de dados por meio de uma combinação de usuários, funções (grupos no Netezza) e permissões. Use instruções CREATE USER e CREATE ROLE/GROUP padrão do SQL para definir usuários e funções, e instruções GRANT e REVOKE para atribuir ou remover permissões para esses usuários e/ou funções.
Dica
A automação de processos de migração é recomendada para reduzir o tempo decorrido e o escopo dos erros.
Conceitualmente, os dois bancos de dados são semelhantes e pode ser possível automatizar a migração de IDs, grupos e permissões de usuário existentes até certo ponto. Migre esses dados extraindo o usuário herdado e as informações de grupo das tabelas de catálogo do sistema Netezza e gerando instruções CREATE USER e CREATE ROLE equivalentes a serem executadas no Azure Synapse para recriar a mesma hierarquia de usuário/função.
Após a extração de dados, use as tabelas de catálogo do sistema Netezza para gerar instruções GRANT equivalentes para atribuir permissões (quando existe uma equivalente). O diagrama a seguir mostra como usar metadados existentes para gerar o SQL necessário.
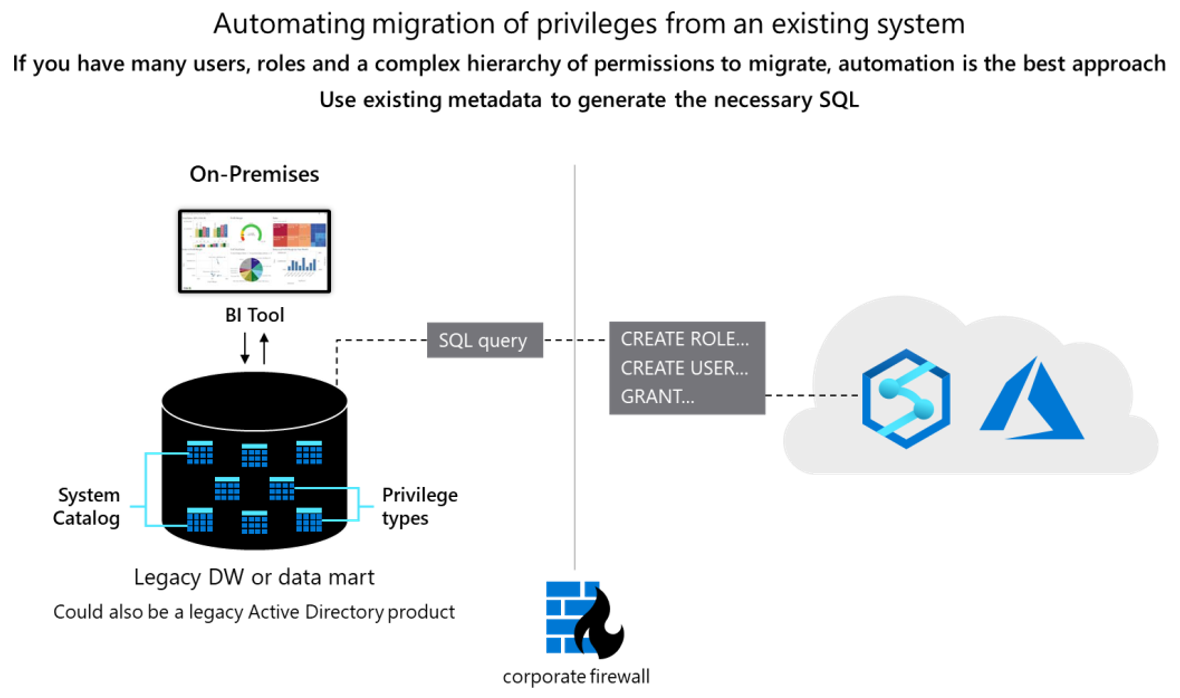
Confira as seções a seguir para obter mais detalhes.
Usuários e funções
Dica
A migração de um data warehouse requer mais do que apenas tabelas, exibições e instruções SQL.
As informações sobre os usuários e grupos atuais em um sistema Netezza são mantidas nas exibições do catálogo do sistema _v_users e _v_groupusers. Use o utilitário nzsql ou ferramentas como Netezza Performance, NzAdmin ou scripts do utilitário Netezza para listar os privilégios de usuário. Por exemplo, use os comandos dpu e dpgu no nzsql para exibir usuários ou grupos com as respectivas permissões.
Use ou edite os scripts de utilitário nz_get_users e nz_get_user_groups para recuperar as mesmas informações no formato necessário.
Consulte as exibições do catálogo do sistema diretamente (se o usuário tiver o acesso SELECT a essas exibições) para obter listas atuais de usuários e funções definidas no sistema. Veja exemplos de como listar usuários, grupos ou usuários e os grupos associados a eles:
-- List of users
SELECT USERNAME FROM _V_USER;
--List of groups
SELECT DISTINCT(GROUPNAME) FROM _V_USERGROUPS;
--List of users and their associated groups
SELECT USERNAME, GROUPNAME FROM _V_GROUPUSERS;
Modifique a instrução SELECT de exemplo para produzir um conjunto de resultados que é uma série de instruções CREATE USER e CREATE GROUP, incluindo o texto apropriado como um literal dentro da instrução SELECT.
Não há como recuperar senhas existentes, portanto, você precisa implementar um esquema para alocar novas senhas iniciais no Azure Synapse.
Permissões
Dica
Há permissões equivalentes do Azure Synapse para operações básicas de banco de dados, como DML e DDL.
Em um sistema Netezza, a tabela do sistema _t_usrobj_priv contém os direitos de acesso para usuários e funções. Consulte essas tabelas (se o usuário tiver acesso SELECT a elas) para obter listas atuais dos direitos de acesso definidos dentro do sistema.
No Netezza, as permissões individuais são representadas como bits individuais dentro de privilégios de campo ou g_privileges. Veja a SQL instrução de exemplo em permissões de grupo de usuários
A maneira mais simples de obter um script DDL que contém os comandos GRANT para replicar os privilégios atuais para usuários e grupos é usar os scripts de utilitário do Netezza apropriados:
--List of group privileges
nz_ddl_grant_group -usrobj dbname > output_file_dbname;
--List of user privileges
nz_ddl_grant_user -usrobj dbname > output_file_dbname;
O arquivo de saída pode ser modificado para produzir um script que é uma série de instruções GRANT para o Azure Synapse.
O Netezza dá suporte a duas classes de direitos de acesso, Administrador e Objeto. Consulte as tabelas a seguir para obter uma lista de direitos de acesso do Netezza e seu equivalente no Azure Synapse.
| Privilégio de Administrador | Descrição | Equivalente no Azure Synapse |
|---|---|---|
| Backup | Permite que o usuário crie backups. O usuário pode executar backups. O usuário pode executar o comando nzbackup. |
1 |
| [Create] Aggregate | Permite que o usuário crie UDAs (agregações definidas pelo usuário). A permissão para operar UDAs existentes é controlada por privilégios de objeto. | CREATE FUNCTION 3 |
| [Create] Database | Permite que o usuário crie bancos de dados. A permissão para operar bancos de dados existentes é controlada por privilégios de objeto. | CREATE DATABASE |
| [Create] External Table | Permite que o usuário crie tabelas externas. A permissão para operar tabelas existentes é controlada por privilégios de objeto. | CREATE TABLE |
| [Create] Function | Permite que o usuário crie UDFs (funções definidas pelo usuário). A permissão para operar UDFs existentes é controlada por privilégios de objeto. | CREATE FUNCTION |
| [Create] Group | Permite que o usuário crie grupos. A permissão para operar grupos existentes é controlada por privilégios de objeto. | CREATE ROLE |
| [Create] Index | Somente para uso do sistema. Os usuários não podem criar índices. | CREATE INDEX |
| [Create] Library | Permite que o usuário crie bibliotecas compartilhadas. A permissão para operar bibliotecas compartilhadas existentes é controlada por privilégios de objeto. | 1 |
| [Create] Materialized View | Permite que o usuário crie exibições materializadas. | CREATE VIEW |
| [Create] Procedure | Permite que o usuário crie procedimentos armazenados. A permissão para operar procedimentos armazenados existentes é controlada por privilégios de objeto. | CREATE PROCEDURE |
| [Create] Schema | Permite que o usuário crie esquemas. A permissão para operar esquemas existentes é controlada por privilégios de objeto. | CREATE SCHEMA |
| [Create] Sequence | Permite que o usuário crie sequências de bancos de dados. | 1 |
| [Create] Synonym | Permite que o usuário crie sinônimos. | CREATE SYNONYM |
| [Create] Table | Permite que o usuário crie tabelas. A permissão para operar tabelas existentes é controlada por privilégios de objeto. | CREATE TABLE |
| [Create] Temp Table | Permite que o usuário crie tabelas temporárias. A permissão para operar tabelas existentes é controlada por privilégios de objeto. | CREATE TABLE |
| [Create] User | Permite que o usuário crie usuários. A permissão para operar usuários existentes é controlada por privilégios de objeto. | CREATE USER |
| [Create] View | Permite que o usuário crie exibições. A permissão para operar exibições existentes é controlada por privilégios de objeto. | CREATE VIEW |
| [Manage Hardware | Permite que o usuário faça as seguintes operações relacionadas ao hardware: exibir o status do hardware, gerenciar SPUs, gerenciar a topologia e o espelhamento e executar testes de diagnóstico. O usuário pode executar estes comandos: nzhw e nzds. | 4 |
| [Manage Security | Permite que o usuário execute comandos e operações relacionados às seguintes opções de segurança avançadas: gerenciar e configurar bancos de dados de histórico, gerenciar objetos de segurança de vários níveis, especificar a segurança para usuários e grupos, gerenciar repositórios de chaves e chaves de banco de dados e gerenciar repositórios de chaves para assinatura digital de dados de auditoria. | 4 |
| [Manage System | Permite que o usuário execute as seguintes operações de gerenciamento: iniciar/parar/pausar/retomar o sistema, anular sessões e exibir o mapa de distribuição, estatísticas do sistema e logs. O usuário pode usar estes comandos: nzsystem, nzstate, nzstats e nzsession. | 4 |
| Restaurar | Permite que o usuário restaure o sistema. O usuário pode executar o comando nzrestore. | 2 |
| Unfence | Permite que o usuário crie ou altere uma função ou agregação definida pelo usuário para ser executada no modo não isolado. | 1 |
| Privilégio do objeto Abort | Descrição | Equivalente no Azure Synapse |
|---|---|---|
| Anular | Permite que o usuário anule sessões. Aplica-se a grupos e usuários. | KILL DATABASE CONNECTION |
| Alterar | Permite que o usuário modifique atributos de objeto. Aplica-se a todos os objetos. | ALTER |
| Excluir | Permite que o usuário exclua linhas de tabela. Aplica-se apenas a tabelas. | Delete (excluir) |
| Remover | Permite que o usuário remova objetos. Aplica-se a todos os tipos de objeto. | DROP |
| Execute (executar) | Permite que o usuário execute funções definidas pelo usuário, agregações definidas pelo usuário ou procedimentos armazenados. | Execute |
| GenStats | Permite que o usuário gere estatísticas com base em tabelas ou bancos de dados. O usuário pode executar o comando GENERATE STATISTICS. | 2 |
| Groom | Permite que o usuário recupere espaço em disco referente a linhas excluídas ou desatualizadas e reorganize uma tabela organizando as chaves, ou migre dados para tabelas que têm várias versões armazenadas. | 2 |
| Inserir | Permite que o usuário insira linhas em uma tabela. Aplica-se apenas a tabelas. | INSERT |
| Lista | Permite que o usuário exiba um nome de objeto, seja em uma lista ou de outra maneira. Aplica-se a todos os objetos. | LISTA |
| Selecionar | Permite que o usuário selecione (ou consulte) linhas em uma tabela. Aplica-se a tabelas e exibições. | SELECT |
| Truncate | Permite que o usuário exclua todas as linhas de uma tabela. Aplica-se apenas a tabelas. | TRUNCATE |
| Atualizar | Permite que o usuário modifique linhas de tabela. Aplica-se apenas a tabelas. | UPDATE |
Observações da tabela :
Não há um equivalente direto para essa função no Azure Synapse.
Essas funções do Netezza são tratadas automaticamente no Azure Synapse.
O recurso
CREATE FUNCTIONdo Azure Synapse incorpora a funcionalidade de agregação do Netezza.Esses recursos são gerenciados automaticamente pelo sistema ou por meio do portal do Azure no Azure Synapse. Consulte a próxima seção sobre considerações operacionais.
Consulte as permissões de segurança do Azure Synapse Analytics.
Considerações operacionais
Dica
Tarefas operacionais são necessárias para manter qualquer data warehouse operando com eficiência.
Esta seção descreve como implementar tarefas operacionais típicas do Netezza no Azure Synapse com o mínimo de risco e impacto para os usuários.
Assim como acontece com todos os produtos de data warehouse, uma vez em produção, há tarefas de gerenciamento contínuas que são necessárias para manter o sistema em execução com eficiência e fornecer dados para monitoramento e auditoria. A utilização de recursos e o planejamento de capacidade para crescimento futuro também se enquadram nessa categoria, assim como o backup/restauração de dados.
As tarefas de administração do Netezza normalmente se enquadram em duas categorias:
Administração do sistema, que é o gerenciamento do hardware, das configurações, do status do sistema, do acesso, do espaço em disco, do uso, das atualizações e de outras tarefas.
Administração do banco de dados, que consiste em gerenciar bancos de dados de usuário e seu conteúdo, carregar dados, fazer backup de dados, restaurar dados e controlar o acesso a dados e permissões.
O IBM Netezza oferece várias maneiras ou interfaces que você pode usar para executar tarefas de gerenciamento de sistema e de banco de dados:
Os comandos do Netezza (comandos
nz*) são instalados no diretório/nz/kit/binno host do Netezza. Para muitos dos comandosnz*, você precisa entrar no sistema Netezza para acessar e executá-los. Na maioria dos casos, os usuários entram como a conta de usuário padrão donz, mas você pode criar outras contas de usuário Linux no sistema. Alguns comandos exigem que você especifique uma conta de usuário de banco de dados, senha e banco de dados para garantir que tenha permissão para fazer a tarefa.Os kits de cliente da CLI do Netezza empacotam um subconjunto dos comandos
nz*que podem ser executados nos sistemas cliente Windows e UNIX. Os comandos do cliente também podem exigir que você especifique uma conta de usuário de banco de dados, senha e banco de dados para garantir que tenha permissões administrativas e de objeto do banco de dados para executar a tarefa.Os comandos SQL dão suporte a tarefas de administração e consultas em uma sessão do banco de dados SQL. Você pode executar os comandos SQL no interpretador de comandos nzsql do Netezza ou por meio de APIs SQL como ODBC, JDBC e o Provedor do OLE DB. Você precisa ter uma conta de usuário de banco de dados para executar os comandos SQL com as permissões adequadas para as consultas e tarefas executadas.
A ferramenta NzAdmin é uma interface do Netezza executada em estações de trabalho do cliente Windows para gerenciar sistemas Netezza.
Embora conceitualmente as tarefas de gerenciamento e operações para diferentes data warehouses sejam semelhantes, as implementações individuais podem ser diferentes. Em geral, produtos modernos baseados em nuvem como o Azure Synapse tendem a incorporar uma abordagem mais automatizada e "gerenciada pelo sistema" (em vez da abordagem mais "manual" de data warehouses herdados como o Netezza).
As seções a seguir comparam as opções do Netezza e do Azure Synapse para várias tarefas operacionais.
Tarefas de manutenção
Dica
As tarefas de manutenção mantêm um warehouse de produção operando com eficiência e otimizam o uso de recursos como armazenamento.
Na maioria dos ambientes de data warehouse herdados, tarefas regulares de "manutenção" são demoradas. Recupere o espaço de armazenamento em disco removendo versões antigas de linhas atualizadas ou excluídas ou reorganizando dados, arquivos de log ou blocos de índice para aumentar a eficiência (GROOM e VACUUM no Netezza). Coletar estatísticas também é uma tarefa potencialmente demorada, necessária após uma ingestão de dados em massa para fornecer ao otimizador de consulta dados atualizados nos quais os planos de execução de consulta serão baseados.
O Netezza recomenda coletar estatísticas da seguinte maneira:
Colete estatísticas em tabelas não preenchidas para configurar o histograma de intervalo usado no processamento interno. Essa coleta inicial torna as coletas de estatísticas posteriores mais rápidas. Lembre-se de coletar estatísticas novamente depois que dados forem adicionados.
Coletar estatísticas de fase de protótipo para tabelas recém-preenchidas.
Coletar dados estatísticos da fase de produção, após uma porcentagem significativa de alterações na tabela ou partição (cerca de 10% das linhas). Para grandes volumes de valores não exclusivos, como datas ou carimbos de data/hora, pode ser vantajoso repetir a coleta em 7%.
Colete estatísticas da fase de produção depois de criar usuários e aplicar cargas de consulta do mundo real ao banco de dados (até cerca de três meses de consulta).
Colete estatísticas nas primeiras semanas após uma atualização ou migração durante períodos de baixa utilização da CPU.
O banco de dados Netezza contém muitas tabelas de log no dicionário de dados que acumulam dados, automaticamente ou depois que determinados recursos são habilitados. Como os dados de log crescem ao longo do tempo, limpe informações mais antigas para evitar o uso de espaço permanente. Há opções para automatizar a manutenção desses logs.
Dica
Automatize e monitore as tarefas de manutenção no Azure.
O Azure Synapse tem a opção de criar estatísticas automaticamente para que elas possam ser usadas conforme necessário. Execute a desfragmentação de índices e blocos de dados manualmente, de maneira agendada ou automática. Aproveitar os recursos nativos internos do Azure pode reduzir o esforço necessário em um exercício de migração.
Monitoramento e auditoria
Dica
O Portal de Desempenho do Netezza é o método recomendado de monitoramento e registro em log para sistemas Netezza.
A Netezza fornece o Portal de Desempenho do Netezza para monitorar vários aspectos de um ou mais sistemas Netezza, incluindo atividade, desempenho, filas e utilização de recursos. O Portal de Desempenho do Netezza é uma GUI interativa que permite que os usuários analisem detalhes de baixo nível de qualquer gráfico.
Dica
O portal do Azure fornece uma GUI para gerenciar tarefas de monitoramento e auditoria para todos os dados e processos do Azure.
De maneira semelhante, o Azure Synapse oferece uma rica experiência de monitoramento no portal do Azure para fornecer insights sobre sua carga de trabalho de data warehouse. O portal do Azure é a ferramenta recomendada ao monitorar seu data warehouse, pois ele fornece períodos de retenção configuráveis, alertas, recomendações e gráficos e painéis personalizáveis para métricas e logs.
O portal também permite a integração com outros serviços de monitoramento do Azure, como o OMS (Operations Management Suite) e o Azure Monitor (logs) para fornecer uma experiência de monitoramento holística não apenas para o data warehouse, mas também para toda a plataforma de análise do Azure para uma experiência de monitoramento integrada.
Dica
Métricas de baixo nível de todo o sistema são registradas automaticamente no Azure Synapse.
Estatísticas de utilização de recursos do Azure Synapse são registradas automaticamente no sistema. As métricas de cada consulta incluem estatísticas de uso de CPU, memória, cache, E/S e workspace temporário, bem como informações de conectividade, como tentativas de conexão com falha.
O Azure Synapse fornece um conjunto de DMVs (Exibições de Gerenciamento Dinâmico). Essas exibições são úteis ao ativamente resolver problemas e identificar gargalos de desempenho com sua carga de trabalho.
Para obter mais informações, consulte Operações e opções de gerenciamento do Azure Synapse.
HA (alta disponibilidade) e DR (recuperação de desastre)
Os dispositivos Netezza são sistemas redundantes e tolerantes a falhas e há diversas opções em um sistema Netezza para habilitar a alta disponibilidade e a recuperação de desastre.
Adicionar o IBM Netezza Replication Services para recuperação de desastre aumenta a tolerância a falhas estendendo a redundância entre redes locais e de longa distância.
O IBM Netezza Replication Services protege contra perda de dados sincronizando dados em um sistema primário (o nó primário) a dados em um ou mais nós de destino (subordinados). Esses nós compõem um conjunto de replicação.
O Linux de alta disponibilidade (também chamado de Linux-HA) fornece os recursos de failover de um host primário ou ativo do Netezza para um host secundário ou em espera do Netezza. O daemon de gerenciamento do cluster principal na solução Linux-HA é chamado de Heartbeat. O Heartbeat inspeciona os hosts e gerencia a comunicação e as verificações de status dos serviços.
Cada serviço é um recurso.
O Netezza agrupa serviços específicos do Netezza no grupo de recursos nps. Quando o Heartbeat detecta problemas que implicam uma condição de falha de host ou perda de serviço para usuários do Netezza, ele pode iniciar um failover para o host em espera.
O DRBD (Distributed Replicated Block Device) é um driver de dispositivo de bloco que espelha o conteúdo de dispositivos de bloco (discos rígidos, partições e volumes lógicos) entre os hosts. O Netezza usa a replicação do DRBD somente nas partições /nz e /export/home. À medida que novos dados são gravados nas partições /nz e /export/home no host primário, o software DRBD faz automaticamente as mesmas alterações nas partições /nz e /export/home do host em espera.
Dica
O Azure Synapse cria instantâneos automaticamente para garantir tempos de recuperação rápidos.
O Azure Synapse usa instantâneos de banco de dados para fornecer alta disponibilidade do warehouse. Um instantâneo de data warehouse cria um ponto de restauração que pode ser usado para recuperar ou copiar seu data warehouse para um estado anterior. Como o Azure Synapse é um sistema distribuído, um instantâneo de data warehouse consiste em vários arquivos no Armazenamento do Azure. Os instantâneos capturam as alterações incrementais dos dados armazenados no data warehouse.
Dica
Use instantâneos definidos pelo usuário para definir um ponto de recuperação antes das atualizações de chave.
Dica
O Microsoft Azure fornece backups automáticos para uma localização geográfica separada para habilitar a DR.
O Azure Synapse faz instantâneos automaticamente ao longo do dia, criando pontos de restauração que ficam disponíveis por sete dias. Não é possível alterar esse período de retenção. O Azure Synapse dá suporte a um RPO (objetivo de ponto de recuperação) de oito horas. Um data warehouse pode ser restaurado na região primária com base em qualquer um dos instantâneos tirados nos sete dias anteriores.
Também há suporte para pontos de restauração definidos pelo usuário, permitindo que o disparo manual de instantâneos crie pontos de restauração de um data warehouse antes e depois de grandes modificações. Isso garante que os pontos de restauração sejam logicamente consistentes, o que oferece proteção de dados adicional em caso de interrupções da carga de trabalho ou de erros do usuário, para um RPO de menos de oito horas.
Além dos instantâneos descritos, o Azure Synapse também executa como padrão um backup geográfico uma vez por dia para um data center emparelhado. O RPO de uma restauração geográfica é de 24 horas. Você pode restaurar o backup geográfico para um servidor em qualquer outra região em que o Azure Synapse tem suporte. O backup geográfico garante que um data warehouse possa ser restaurado caso os pontos de restauração na região primária não estejam disponíveis.
Gerenciamento de carga de trabalho
Dica
Em um data warehouse de produção, normalmente há cargas de trabalho misturadas com diferentes características de uso de recursos em execução simultaneamente.
O Netezza incorpora vários recursos para gerenciar cargas de trabalho:
| Técnica | Descrição |
|---|---|
| Regras do agendador | As regras do agendador influenciam o agendamento de planos. Cada regra do agendador especifica uma condição ou um conjunto de condições. Cada vez que recebe um plano, o agendador avalia todas as regras modificadoras do agendador e executa as ações apropriadas. Cada vez que seleciona um plano para execução, o agendador avalia todas as regras limitadoras do agendador. O plano será executado apenas se fazer isso não exceder um limite imposto por uma regra limitadora do agendador. Caso contrário, o plano aguardará. Isso proporciona uma maneira de classificar e manipular planos de uma forma que influencie as outras técnicas de WLM (SQB, GRA e PQE). |
| GRA (alocação de recurso garantida) | Você pode atribuir uma parcela mínima e um percentual máximo dos recursos totais do sistema a entidades chamadas grupos de recursos. O agendador garante que cada grupo de recursos receba recursos do sistema proporcionalmente à sua parcela mínima. Um grupo de recursos recebe uma parcela maior de recursos quando outros grupos de recursos estão ociosos, mas nunca recebe mais do que o percentual máximo configurado. Cada plano está associado a um grupo de recursos, e as configurações desse grupo de recursos determinam qual fração dos recursos de sistema disponíveis deve ser disponibilizada para processar o plano. |
| SQB (viés de consulta curta) | Os recursos (ou seja, slots de agendamento, memória e enfileiramento preferencial) são reservados para consultas curtas. Uma consulta curta é uma consulta cuja estimativa de custo é menor que um valor máximo especificado (o padrão é dois segundos). Com o SQB, consultas curtas podem ser executadas mesmo quando o sistema está ocupado processando outras consultas mais longas. |
| PQE (execução de consulta priorizada) | Com base nas configurações, o sistema atribui uma prioridade — crítica, alta, normal ou baixa — a cada consulta. A prioridade depende de fatores como o usuário, o grupo ou a sessão associada à consulta. Em seguida, o sistema pode usar a prioridade como base para alocar recursos. |
O Azure Synapse registra automaticamente as estatísticas de utilização de recursos. As métricas incluem estatísticas de uso para CPU, memória, cache, E/S e workspace temporário para cada consulta. O Azure Synapse também registra informações de conectividade, como tentativas de conexão com falha.
Dica
As métricas de baixo nível de todo o sistema são registradas automaticamente no Azure.
No Azure Synapse, as classes de recursos são limites de recursos predeterminados que controlam recursos de computação e simultaneidade para execução da consulta. Classes de recursos podem ajudar a gerenciar a carga de trabalho, definindo limites no número de consultas executadas simultaneamente e nos recursos de computação atribuídos a cada consulta. Há um equilíbrio entre a memória e simultaneidade.
O Azure Synapse dá suporte a esses conceitos básicos de gerenciamento de carga de trabalho:
Classificação da carga de trabalho: você pode atribuir uma solicitação a um grupo de carga de trabalho para definir níveis de importância.
Importância da carga de trabalho: você pode influenciar a ordem em que uma solicitação obtém acesso aos recursos. Por padrão, as consultas são liberadas da fila no esquema primeiro a entrar, primeiro a sair, à medida que os recursos são disponibilizados. A importância da carga de trabalho permite que consultas de prioridade mais alta recebam recursos imediatamente, independentemente da fila.
Isolamento da carga de trabalho: você pode reservar recursos para um grupo de carga de trabalho, atribuir usos máximo e mínimo para recursos variados, limitar os recursos que um grupo de solicitações pode consumir e definir um valor de tempo limite para encerrar automaticamente as consultas descontroladas.
A execução de cargas de trabalho mistas pode representar desafios de recursos em sistemas ocupados. Um esquema de gerenciamento de carga de trabalho bem-sucedido gerencia efetivamente os recursos, garante uma utilização de recursos altamente eficiente e maximiza o ROI (retorno sobre o investimento). A classificação da carga de trabalho, a importância da carga de trabalho e o isolamento da carga de trabalho dão mais controle sobre como a carga de trabalho utiliza os recursos do sistema.
O guia de gerenciamento de carga de trabalho descreve as técnicas para analisar a carga de trabalho, gerenciar e monitorar a importância da carga de trabalho importance (../../sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md) e as etapas para converter uma classe de recurso em um grupo de carga de trabalho. Use o portal do Azure e as consultas T-SQL em DMVs para monitorar a carga de trabalho para garantir que os recursos aplicáveis sejam utilizados com eficiência. O Azure Synapse fornece um conjunto de DMVs (Exibições de Gerenciamento Dinâmico) para monitorar todos os aspectos do gerenciamento de carga de trabalho. Essas exibições são úteis para resolver problemas ativamente e identificar gargalos de desempenho com sua carga de trabalho.
Essas informações também podem ser usadas para planejamento de capacidade, determinando os recursos necessários para usuários ou cargas de trabalho adicionais do aplicativo. Isso também se aplica ao planejamento de reduções de escala/escala vertical de recursos de computação para suporte econômico de cargas de trabalho "com picos", como cargas de trabalho com intermitências temporárias e intensas de atividades cercadas por períodos de atividade pouco frequente.
Para obter mais informações sobre o gerenciamento de carga de trabalho no Azure Synapse, consulte Gerenciamento de carga de trabalho com classes de recursos.
Escalar recursos de computação
Dica
Um grande benefício do Azure é a capacidade de escalar e reduzir verticalmente sem depender de recursos de computação sob demanda para lidar de maneira econômica com cargas de trabalho de pico.
A arquitetura do Azure Synapse separa armazenamento e computação, permitindo que cada um seja dimensionado independentemente. Como resultado, os recursos de computação podem ser dimensionados para atender às demandas de desempenho independentemente do armazenamento de dados. Além disso, você também pode pausar e retomar os recursos de computação. Um benefício natural dessa arquitetura é que a cobrança pela computação e pelo armazenamento é separada. Se um data warehouse não estiver em uso, você pode economizar os custos de computação pausando a computação.
Os recursos de computação podem ser escalados ou reduzidos verticalmente ajustando a configuração de unidades do data warehouse. O desempenho de consultas e carregamento aumentará linearmente na medida em que você adicionar mais unidades de data warehouse.
Adicionar mais nós de computação adiciona mais poder de computação e a capacidade de aproveitar mais processamento paralelo. À medida que o número de nós de computação aumenta, o número de distribuições por nó de computação diminui, proporcionando mais potência de computação e processamento paralelo para as consultas. Da mesma forma, diminuir as unidades de data warehouse reduz o número de nós de computação, o que reduz os recursos de computação para consultas.
Próximas etapas
Para saber mais sobre visualização e relatórios, confira o próximo artigo desta série: Visualização e relatórios para migrações do Netezza.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de