Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo tem como destino profissionais de TI e gerentes de TI. Você aprenderá sobre a arquitetura da solução de BI no COE e as diferentes tecnologias empregadas. As tecnologias incluem Azure, Power BI e Excel. Juntos, eles podem ser aproveitados para fornecer uma plataforma de BI de nuvem escalonável e controlada por dados.
Projetar uma plataforma de BI robusta é um pouco como construir uma ponte; uma ponte que conecta dados de origem transformados e enriquecidos aos consumidores de dados. O design de uma estrutura tão complexa requer uma mentalidade de engenharia, embora possa ser uma das arquiteturas de TI mais criativas e gratificantes que você poderia projetar. Em uma organização grande, uma arquitetura de solução de BI pode consistir em:
- Fontes de dados
- Ingestão de dados
- Preparação de Dados/Big Data
- Armazém de Dados
- Modelos semânticos de BI
- Relatórios
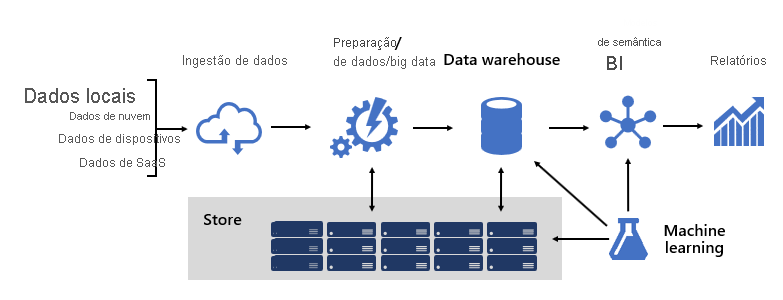
A plataforma deve dar suporte a demandas específicas. Especificamente, ele deve ser dimensionado e executado para atender às expectativas de serviços empresariais e consumidores de dados. Ao mesmo tempo, deve estar seguro desde o início. E, ele deve ser suficientemente resiliente para se adaptar às mudanças, pois é uma certeza de que, com o tempo, novos dados e áreas de assunto devem ser colocados online.
Estruturas
Na Microsoft, desde o início adotamos uma abordagem semelhante a sistemas investindo no desenvolvimento de estruturas. As estruturas técnicas e de processo empresarial aumentam a reutilização do design e da lógica e fornecem um resultado consistente. Eles também oferecem flexibilidade na arquitetura aproveitando muitas tecnologias e simplificam e reduzem a sobrecarga de engenharia por meio de processos repetíveis.
Aprendemos que estruturas bem projetadas aumentam a visibilidade da linhagem de dados, análise de impacto, manutenção da lógica de negócios, gerenciamento de taxonomia e simplificação da governança. Além disso, o desenvolvimento tornou-se mais rápido e a colaboração entre grandes equipes tornou-se mais responsiva e eficaz.
Descreveremos várias de nossas estruturas neste artigo.
Modelos de dados
Os modelos de dados fornecem controle sobre como os dados são estruturados e acessados. Para os consumidores de dados e serviços de negócios, os modelos de dados são sua interface com a plataforma de BI.
Uma plataforma de BI pode fornecer três tipos diferentes de modelos:
- Modelos empresariais
- Modelos semânticos de BI
- Modelos de ML (Machine Learning)
Modelos empresariais
Os modelos empresariais são criados e mantidos por arquitetos de TI. Às vezes, eles são chamados de modelos dimensionais ou data marts. Normalmente, os dados são armazenados em formato relacional como tabelas de dimensão e fatos. Essas tabelas armazenam dados limpos e enriquecidos consolidados de muitos sistemas e representam uma fonte autoritativa para relatórios e análises.
Os modelos empresariais fornecem uma fonte de dados consistente e única para relatórios e BI. Eles são construídos uma vez e compartilhados como um padrão corporativo. As políticas de governança garantem que os dados sejam seguros, portanto, o acesso a conjuntos de dados confidenciais, como informações do cliente ou finanças, é restrito de acordo com as necessidades. Eles adotam convenções de nomenclatura garantindo consistência, estabelecendo ainda mais a credibilidade dos dados e da qualidade.
Em uma plataforma de BI na nuvem, os modelos empresariais podem ser implantados em um pool de SQL do Synapse no Azure Synapse. O pool de SQL do Synapse se torna a única versão da verdade com a qual a organização pode contar para insights rápidos e robustos.
Modelos semânticos de BI
Modelos semânticos de BI representam uma camada semântica sobre modelos empresariais. Eles são criados e mantidos por desenvolvedores de BI e usuários empresariais. Os desenvolvedores de BI criam modelos semânticos de BI principais que geram dados de modelos empresariais. Os usuários empresariais podem criar modelos independentes de menor escala ou estender modelos semânticos de BI principais com fontes departamentais ou externas. Os modelos semânticos de BI geralmente se concentram em uma única área de assunto e geralmente são amplamente compartilhados.
Os recursos de negócios são habilitados não apenas por dados, mas por modelos semânticos de BI que descrevem conceitos, relações, regras e padrões. Dessa forma, elas representam estruturas intuitivas e fáceis de entender que definem relações de dados e encapsulam regras de negócios como cálculos. Eles também podem impor permissões de dados refinadas, garantindo que as pessoas certas tenham acesso aos dados certos. É importante ressaltar que eles aceleram o desempenho da consulta, fornecendo análises interativas extremamente responsivas, mesmo sobre terabytes de dados. Assim como os modelos empresariais, os modelos semânticos de BI adotam convenções de nomenclatura garantindo consistência.
Em uma plataforma de BI na nuvem, os desenvolvedores de BI podem implantar modelos semânticos de BI no Azure Analysis Services, capacidades do Power BI Premium ou capacidades do Microsoft Fabric.
Importante
Este artigo refere-se ao Power BI Premium ou suas assinaturas de capacidade (SKUs P). Atualmente, a Microsoft está consolidando as opções de compra e desativando os SKUs do Power BI Premium por capacidade. Clientes novos e existentes devem considerar a compra de SKUs F (assinaturas de capacidade do Fabric).
Para obter mais informações, consulte Atualização importante sobre o licenciamento do Power BI Premium e Perguntas frequentes do Power BI Premium.
Recomendamos implantar no Power BI quando ele é usado como camada de relatórios e análises. Esses produtos dão suporte a diferentes modos de armazenamento, permitindo que tabelas de modelo de dados armazenem seus dados em cache ou usem o DirectQuery, que é uma tecnologia que passa consultas para a fonte de dados subjacente. O DirectQuery é um modo de armazenamento ideal quando as tabelas de modelo representam grandes volumes de dados ou há a necessidade de fornecer resultados quase em tempo real. Os dois modos de armazenamento podem ser combinados: modelos compostos combinam tabelas que usam modos de armazenamento diferentes em um único modelo.
Para modelos altamente consultados, o Azure Load Balancer pode ser usado para distribuir uniformemente a carga de consulta entre réplicas de modelo. Ele também permite dimensionar seus aplicativos e criar modelos semânticos de BI altamente disponíveis.
Modelos de Machine Learning
Os modelos de ML (Machine Learning) são criados e mantidos por cientistas de dados. Eles são desenvolvidos principalmente a partir de fontes brutas no data lake.
Modelos de ML treinados podem revelar padrões em seus dados. Em muitas circunstâncias, esses padrões podem ser usados para fazer previsões que podem ser usadas para enriquecer dados. Por exemplo, o comportamento de compra pode ser usado para prever a rotatividade do cliente ou clientes do segmento. Os resultados da previsão podem ser adicionados aos modelos empresariais para permitir a análise por segmento do cliente.
Em uma plataforma de BI na nuvem, você pode usar o Azure Machine Learning para treinar, implantar, automatizar, gerenciar e acompanhar modelos de ML.
Armazém de Dados
Sentado no centro de uma plataforma de BI está o data warehouse, que hospeda seus modelos empresariais. É uma fonte de dados sancionados, funcionando como um sistema de registro e um hub, atendendo modelos empresariais para relatórios, BI e ciência de dados.
Muitos serviços empresariais, incluindo aplicativos LOB (linha de negócios), podem contar com o data warehouse como uma fonte confiável e governada de conhecimento corporativo.
Na Microsoft, nosso data warehouse é hospedado no Azure Data Lake Storage Gen2 (ADLS Gen2) e no Azure Synapse Analytics.
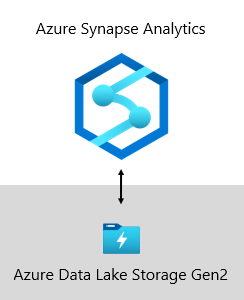
- O ADLS Gen2 transforma o Armazenamento do Azure na base para construção de data lakes corporativos no Azure. Ele foi projetado para atender a vários petabytes de informações e, ao mesmo tempo, manter centenas de gigabits de taxa de transferência. Além disso, ele oferece transações e capacidade de armazenamento de baixo custo. Além disso, ele dá suporte ao acesso compatível com Hadoop, que permite que você gerencie e acesse dados da mesma forma que faria com um HDFS (Sistema de Arquivos Distribuído hadoop). Na verdade, o Azure HDInsight, o Azure Databricks e o Azure Synapse Analytics podem acessar todos os dados armazenados no ADLS Gen2. Portanto, em uma plataforma de BI, é uma boa opção armazenar dados brutos de origem, dados semiprocessados ou preparados e dados prontos para produção. Usamos para armazenar todos os nossos dados comerciais.
- O Azure Synapse Analytics é um serviço de análise que reúne data warehouse corporativo e análise de Big Data. Ele oferece a liberdade de consultar dados em seus termos, usando recursos sob demanda sem servidor ou provisionados, em escala. O Synapse SQL, um componente do Azure Synapse Analytics, dá suporte à análise completa baseada em T-SQL, portanto, é ideal hospedar modelos empresariais que compõem suas tabelas de dimensão e fatos. As tabelas podem ser carregadas com eficiência do ADLS Gen2 usando consultas T-SQL simples do Polybase . Em seguida, você tem o poder do MPP para executar análises de alto desempenho.
Estrutura do Mecanismo de Regras de Negócios
Desenvolvemos uma estrutura bre ( mecanismo de regras de negócios ) para catalogar qualquer lógica de negócios que possa ser implementada na camada de data warehouse. Uma BRE pode significar muitas coisas, mas no contexto de um data warehouse é útil para criar colunas calculadas em tabelas relacionais. Essas colunas calculadas geralmente são representadas como cálculos matemáticos ou expressões usando instruções condicionais.
A intenção é dividir a lógica de negócios do código de BI principal. Tradicionalmente, as regras de negócios são codificadas em procedimentos armazenados do SQL, portanto, geralmente resulta em muito esforço para mantê-las quando as necessidades de negócios são alteradas. Em uma BRE, as regras de negócios são definidas uma vez e usadas várias vezes quando aplicadas a diferentes entidades de data warehouse. Se a lógica de cálculo precisar mudar, ela só precisará ser atualizada em um só lugar e não em vários procedimentos armazenados. Há um benefício paralelo também: uma estrutura BRE impulsiona a transparência e a visibilidade da lógica de negócios implementada, que pode ser exposta por meio de um conjunto de relatórios que criam documentação que se autoatualiza.
Fontes de dados
Um data warehouse pode consolidar dados de praticamente qualquer fonte de dados. É construído principalmente sobre fontes de dados de Linha de Negócio (LOB), que geralmente são bancos de dados relacionais armazenando dados específicos para vendas, marketing, finanças, etc. Esses bancos de dados podem ser hospedados na nuvem ou podem residir localmente. Outras fontes de dados podem ser baseadas em arquivo, especialmente logs da Web ou dados IOT provenientes de dispositivos. Além disso, os dados podem ser provenientes de fornecedores saaS (software como serviço).
Na Microsoft, alguns de nossos sistemas internos geram dados operacionais diretos para o ADLS Gen2 usando formatos de arquivo brutos. Além do data lake, outros sistemas de origem incluem aplicativos LOB relacionais, pastas de trabalho do Excel, outras fontes baseadas em arquivo e MDM (Master Data Management) e repositórios de dados personalizados. Os repositórios de MDM nos permitem gerenciar nossos dados mestres para garantir versões autoritativas, padronizadas e validadas de dados.
Ingestão de dados
Periodicamente, e de acordo com os ritmos da empresa, os dados são ingeridos de sistemas de origem e carregados no data warehouse. Pode ser uma vez por dia ou em intervalos mais frequentes. A ingestão de dados se preocupa em extrair, transformar e carregar dados. Ou talvez o contrário: extraindo, carregando e transformando dados. A diferença se resume ao local em que a transformação ocorre. As transformações são aplicadas à limpeza, conformidade, integração e padronização de dados. Para obter mais informações, consulte Extrair, transformar e carregar (ETL).
Em última análise, o objetivo é carregar os dados certos em seu modelo empresarial da maneira mais rápida e eficiente possível.
Na Microsoft, usamos o ADF (Azure Data Factory ). Os serviços são usados para agendar e orquestrar validações de dados, transformações e carregamentos em massa de sistemas de origem externos em nosso data lake. Ele é gerenciado por estruturas personalizadas para processar dados em paralelo e em escala. Além disso, o registro em log abrangente é realizado para dar suporte à solução de problemas, ao monitoramento de desempenho e a disparar notificações de alerta quando condições específicas forem atendidas.
Enquanto isso, o Azure Databricks , uma plataforma de análise baseada no Apache Spark otimizada para a plataforma de serviços de nuvem do Azure, realiza transformações especificamente para ciência de dados. Ele também cria e executa modelos de ML usando notebooks Python. As pontuações desses modelos de ML são carregadas no data warehouse para integrar previsões a aplicativos empresariais e relatórios. Como o Azure Databricks acessa diretamente os arquivos do data lake, ele elimina ou minimiza a necessidade de copiar ou adquirir dados.
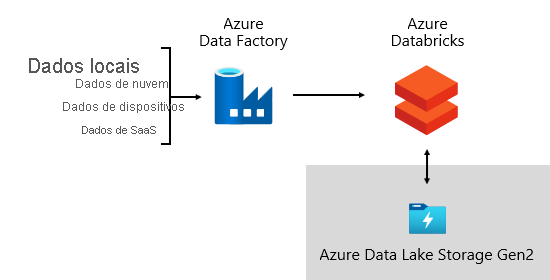
Estrutura de ingestão
Desenvolvemos uma estrutura de ingestão como um conjunto de tabelas e procedimentos de configuração. Ele dá suporte a uma abordagem controlada por dados para adquirir grandes volumes de dados em alta velocidade e com código mínimo. Em suma, essa estrutura simplifica o processo de aquisição de dados para carregar o data warehouse.
A estrutura depende de tabelas de configuração que armazenam informações relacionadas à fonte de dados e ao destino de dados, como tipo de origem, servidor, banco de dados, esquema e detalhes relacionados à tabela. Essa abordagem de design significa que não precisamos desenvolver pipelines específicos do ADF ou pacotes do SSIS (SQL Server Integration Services ). Em vez disso, os procedimentos são escritos na linguagem de nossa escolha para criar pipelines do ADF que são gerados e executados dinamicamente em tempo de execução. Portanto, a aquisição de dados torna-se um exercício de configuração que é facilmente operacionalizado. Tradicionalmente, isso exigiria recursos de desenvolvimento extensivos para criar pacotes ADF ou SSIS codificados.
A estrutura de ingestão foi projetada para simplificar o processo de tratamento de alterações no esquema de origem das fontes de dados, também. É fácil atualizar dados de configuração, manual ou automaticamente, quando são detectadas alterações de esquema para adquirir atributos recém-adicionados no sistema de origem.
Estrutura de orquestração
Desenvolvemos uma estrutura de orquestração para operacionalizar e orquestrar nossos pipelines de dados. A estrutura de orquestração usa um design controlado por dados que depende de um conjunto de tabelas de configuração. Essas tabelas armazenam metadados que descrevem dependências de pipeline e como mapear dados de origem para estruturas de dados de destino. Desde então, o investimento no desenvolvimento dessa estrutura adaptável foi pago por si só; não há mais um requisito para codificar cada movimentação de dados.
Armazenamento de dados
Um data lake pode armazenar grandes volumes de dados brutos para uso futuro, além de preparar as transformações de dados.
Na Microsoft, usamos o ADLS Gen2 como nossa única fonte de verdade. Ele armazena dados brutos junto com dados preparados e dados prontos para produção. Ele fornece uma solução data lake altamente escalonável e econômica para análise de Big Data. Combinando o poder de um sistema de arquivos de alto desempenho com grande escala, ele é otimizado para cargas de trabalho de análise de dados, acelerando a obtenção de insights.
O ADLS Gen2 fornece o melhor de dois mundos: é um armazenamento BLOB e um namespace de sistema de arquivos de alto desempenho, que configuramos com permissões de acesso refinadas.
Os dados refinados são armazenados em um banco de dados relacional para fornecer um armazenamento de dados altamente escalonável e de alto desempenho para modelos empresariais, com segurança, governança e capacidade de gerenciamento. Os data marts temáticos são armazenados no Azure Synapse Analytics e são carregados por meio do Azure Databricks ou de consultas T-SQL do Polybase.
Consumo de dados
Na camada de relatórios, os serviços empresariais consomem dados corporativos provenientes do data warehouse. Eles também acessam dados diretamente no data lake para análise ad hoc ou tarefas de ciência de dados.
As permissões refinadas são impostas em todas as camadas: no data lake, nos modelos empresariais e nos modelos semânticos de BI. As permissões garantem que os consumidores de dados só possam ver os dados que têm direitos de acesso.
Na Microsoft, usamos relatórios e dashboards do Power BI e relatórios paginados do Power BI. Alguns relatórios e análises ad hoc são feitos no Excel, especialmente para relatórios financeiros.
Publicamos dicionários de dados, que fornecem informações de referência sobre nossos modelos de dados. Eles são disponibilizados para nossos usuários para que possam descobrir informações sobre nossa plataforma de BI. Os dicionários documentam designs de modelos, fornecendo descrições sobre entidades, formatos, estrutura, linhagem de dados, relações e cálculos. Usamos o Catálogo de Dados do Azure para tornar nossas fontes de dados facilmente detectáveis e compreensíveis.
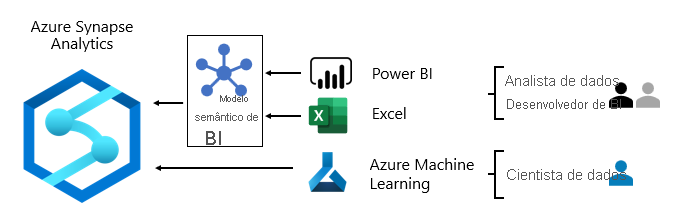
Normalmente, os padrões de consumo de dados diferem com base na função:
- Os analistas de dados se conectam diretamente aos principais modelos semânticos de BI. Quando os principais modelos semânticos de BI contêm todos os dados e lógica necessários, eles usam conexões dinâmicas para criar relatórios e dashboards do Power BI. Quando eles precisam estender os modelos com dados departamentais, eles criam modelos compostos do Power BI. Se houver a necessidade de relatórios no estilo de planilha, eles usarão o Excel para produzir relatórios com base em modelos semânticos de BI principais ou modelos semânticos de BI departamentais.
- Desenvolvedores de BI e autores de relatórios operacionais conectam-se diretamente a modelos empresariais. Eles usam o Power BI Desktop para criar relatórios de análise de conexão dinâmica. Eles também podem criar relatórios de BI do tipo operacional como relatórios paginados do Power BI, escrevendo consultas SQL nativas para acessar dados dos modelos empresariais do Azure Synapse Analytics usando t-SQL ou modelos semânticos do Power BI usando DAX ou MDX.
- Os cientistas de dados se conectam diretamente aos dados no data lake. Eles usam notebooks do Azure Databricks e python para desenvolver modelos de ML, que geralmente são experimentais e exigem habilidades especiais para uso em produção.
Conteúdo relacionado
Para obter mais informações sobre este artigo, confira os seguintes recursos:
- Roteiro de adoção do Fabric: Centro de Excelência
- BI corporativo no Azure com o Azure Synapse Analytics
- Perguntas? Tente perguntar na Comunidade Fabric
- Sugestões? Contribua com ideias para melhorar o Fabric
Serviços profissionais
Os parceiros certificados do Power BI estão disponíveis para ajudar sua organização a ter êxito ao configurar um COE. Eles podem fornecer treinamento econômico ou uma auditoria de seus dados. Para encontrar um parceiro do Power BI, visite o portal de parceiros do Microsoft Power BI.
Você também pode se envolver com parceiros de consultoria experientes. Eles podem ajudá-lo a avaliar, avaliar ou implementar o Power BI.