Usar Jupyter Notebooks no Azure Data Studio
Importante
O Azure Data Studio será desativado em 28 de fevereiro de 2026. Recomendamos que você use Visual Studio Code. Para obter mais informações sobre como migrar para o Visual Studio Code, visite O que está acontecendo com o Azure Data Studio?
Aplica-se a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
O Jupyter Notebook é um aplicativo Web de código-fonte aberto que permite que criar e compartilhar documentos que contêm código ao vivo, equações, visualizações e texto narrativo. O uso inclui limpeza de dados e transformação, simulação numérica, modelagem estatística, visualização de dados e aprendizado de máquina.
Este artigo descreve como criar um notebook na versão mais recente do Azure Data Studio e como começar a criar seus próprios notebooks usando diferentes kernels.
Assista a este vídeo breve de 5 minutos para ver uma introdução sobre notebooks no Azure Data Studio:
Criar um notebook
Há várias maneiras de criar um notebook. Em todos os casos, um novo arquivo chamado Notebook-1.ipynb é aberto.
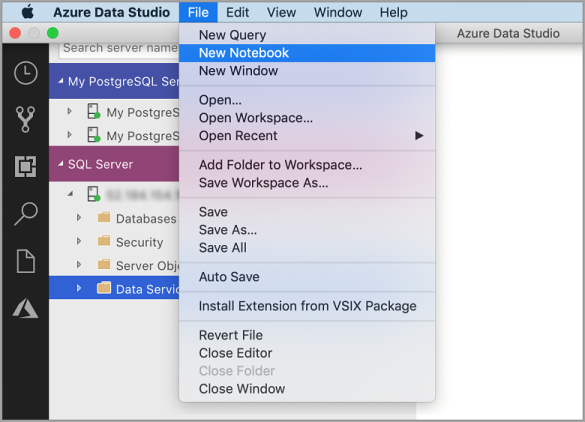
Acesse o Menu Arquivo no Azure Data Studio e selecione Novo Notebook.
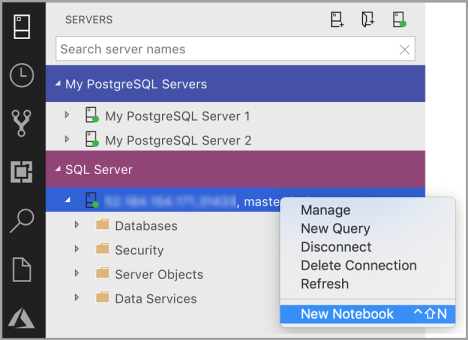
Clique com o botão direito do mouse na conexão SQL Server e selecione Novo Notebook.
Abra a paleta de comandos (Ctrl + Shift + P), digite "novo notebook" e selecione o comando Novo Notebook.

Conectar-se a um kernel
Os notebooks do Azure Data Studio dão suporte a vários kernels diferentes, incluindo SQL Server, Python, PySpark e outros. Cada kernel dá suporte a uma linguagem diferente nas células de código do notebook. Por exemplo, quando conectado ao kernel do SQL Server, você pode inserir e executar instruções T-SQL em uma célula de código do notebook.
Anexar a fornece o contexto do kernel. Por exemplo, se estiver usando o Kernel do SQL, você poderá usar anexar a qualquer uma de suas instâncias do SQL Server. Se estiver usando o Kernel do Python3, anexe a localhost e você poderá usar esse kernel para desenvolvimento de Python local.
O Kernel do SQL também pode ser usado para se conectar a instâncias do servidor PostgreSQL. Se você for um desenvolvedor de PostgreSQL e quiser conectar os notebooks ao Servidor PostgreSQL, baixe a extensão do PostgreSQL no Marketplace de extensões do Azure Data Studio e se conecte ao servidor PostgreSQL.
Se você estiver conectado ao cluster de Big Data do SQL Server 2019, o valor padrão de Anexar a será o ponto de extremidade do cluster. Você pode enviar o código Python, Scala e R usando a computação de Spark do cluster.
| Kernel | Descrição |
|---|---|
| Kernel do SQL | Escreva o código SQL direcionado ao seu banco de dados relacional. |
| Kernel PySpark3 e PySpark | Escreva o código Python usando a computação do Spark do cluster. |
| Kernel do Spark | Escreva o código Scala e R usando a computação do Spark do cluster. |
| Kernel do Python | Escreva o código Python para desenvolvimento local. |
Para obter mais informações sobre kernels específicos, confira:
- Criar e executar um notebook do SQL Server
- Criar e executar um notebook do Python
- Extensão Kqlmagic no Azure Data Studio – estende os recursos do kernel de Python
Adicionar uma célula de código
As células de código permitem executar código interativamente no notebook.
Adicione uma nova célula de código clicando no comando +Célula na barra de ferramentas e selecionando Célula de código. Uma nova célula de código é adicionada após a célula selecionada.
Insira o código na célula para o kernel selecionado. Por exemplo, se estiver usando o kernel do SQL, você poderá inserir comandos T-SQL na célula de código.
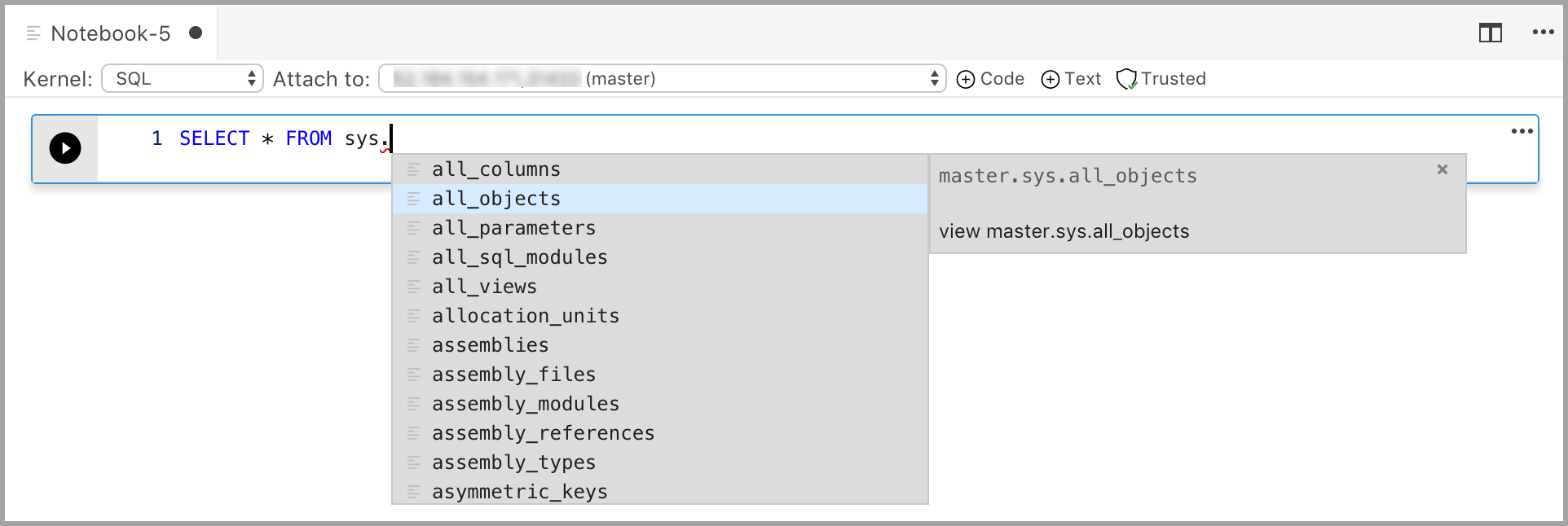
Inserir código com o kernel do SQL é semelhante a um editor de consultas SQL. A célula de código dá suporte a uma experiência moderna de codificação em SQL com recursos internos como um editor SQL avançado, o IntelliSense e trechos de código internos. Os snippets de código permitem que você gere a sintaxe SQL correta para criar bancos de dados, tabelas, exibições, procedimentos armazenados e atualizar objetos de banco de dados existentes. Use snippets de código para criar rapidamente cópias de seu banco de dados para fins de desenvolvimento ou teste e para gerar e executar scripts.
Adicionar uma célula de texto
As células de texto permitem que você documente seu código adicionando blocos de texto de Markdown entre as células de código.
Adicione uma nova célula de texto clicando no comando +Célula na barra de ferramentas e selecionando Célula de texto.
A célula é iniciada no modo de edição, no qual você pode digitar o texto de Markdown. Conforme você digita, uma visualização é mostrada abaixo.
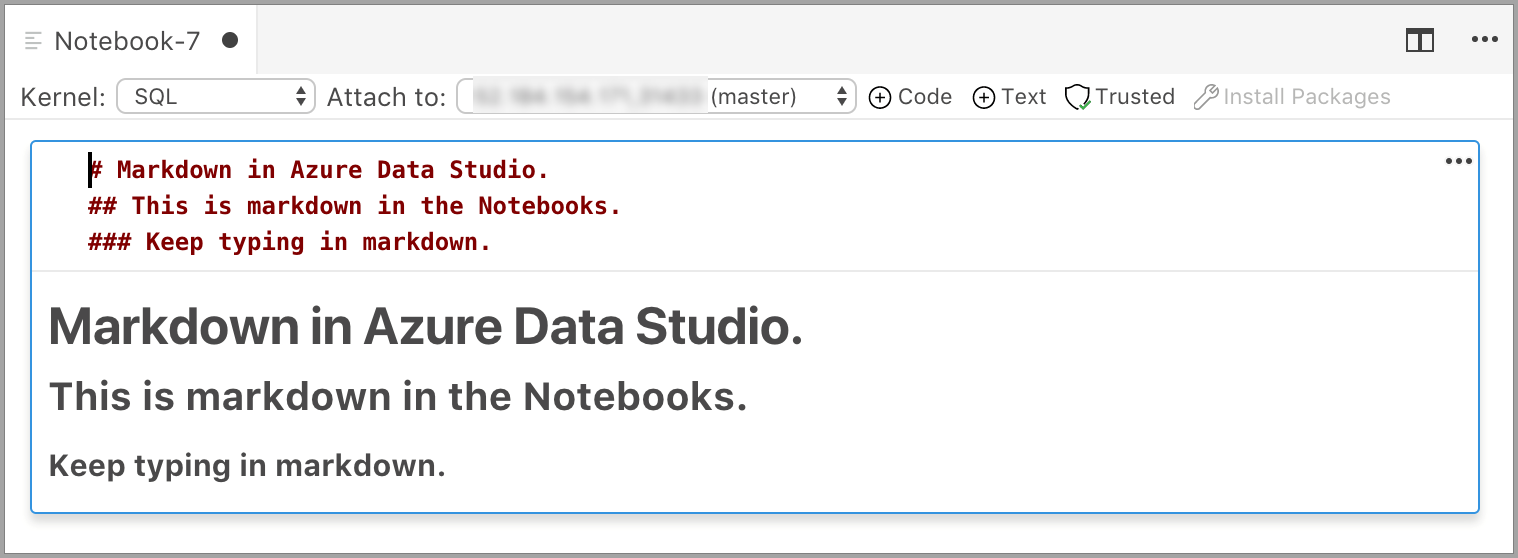
Selecionar fora da célula de texto mostra o texto de Markdown.
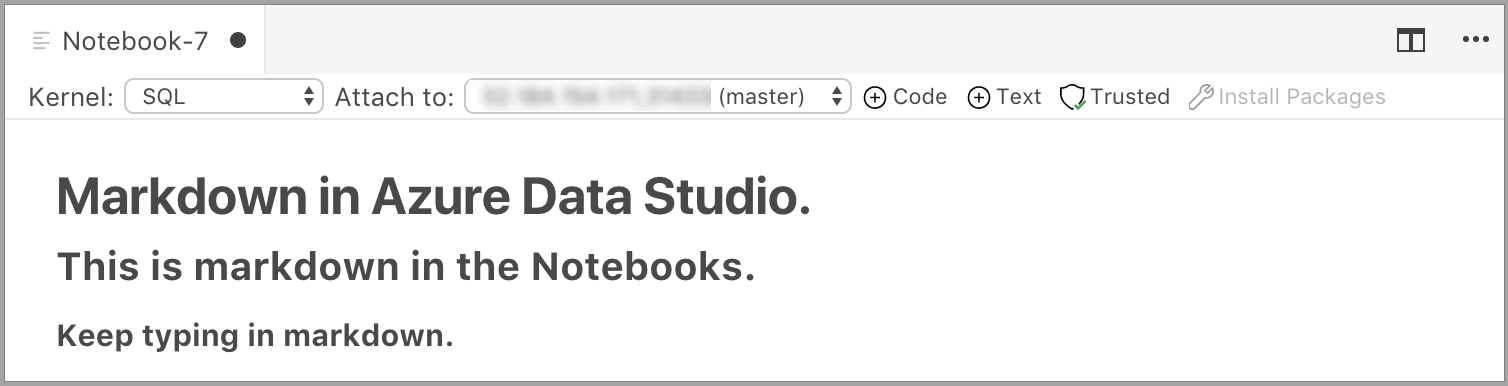
Se você clicar na célula de texto novamente, ela será alterada para o modo de edição.
Executar uma célula
Para executar apenas uma célula, clique em Executar célula (a seta preta arredondada) à esquerda da célula ou selecione a célula e pressione F5. Você pode executar todas as células no notebook clicando em Executar tudo na barra de ferramentas. As células são executadas uma por vez e a execução é interrompida quando um erro é encontrado em uma célula.
Os resultados da célula são mostrados abaixo dela. Você pode limpar os resultados de todas as células executadas no notebook selecionando o botão Limpar Resultados na barra de ferramentas.
Salvar um notebook
Para salvar um notebook, realize um dos procedimentos a seguir.
- Digite Ctrl+S
- Selecione Salvar no menu Arquivo
- Selecione Salvar como... no menu Arquivo
- Selecione Salvar todos no menu Arquivo, o que salva todos os notebooks abertos
- Na paleta de comandos, insira Arquivo: Salvar
Os notebooks são salvos como arquivos .ipynb.
Confiável e não confiável
Os notebooks abertos no Azure Data Studio são Confiáveis por padrão.
Se você abrir um notebook de outra fonte, ele será aberto no modo Não Confiável e poderá ser configurado como Confiável.
Exemplos
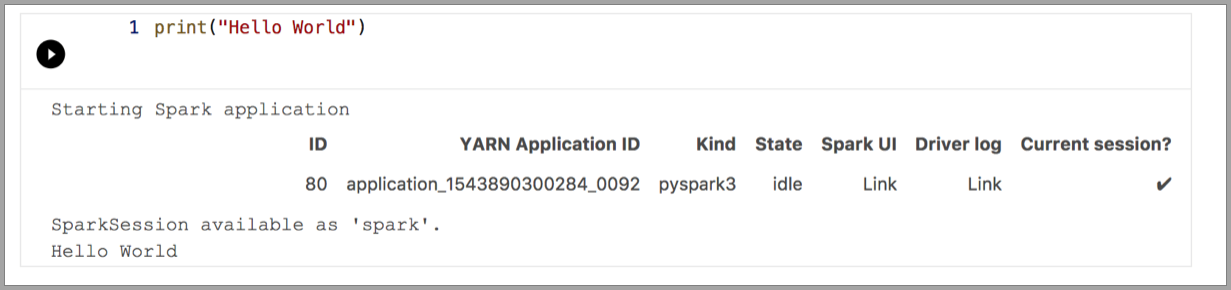
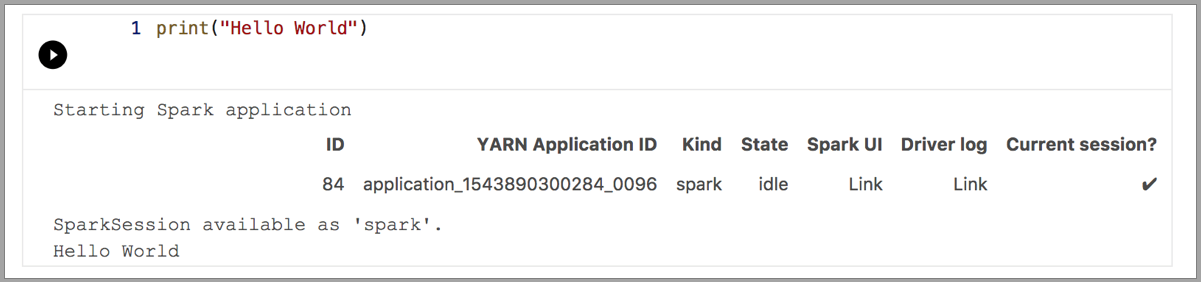
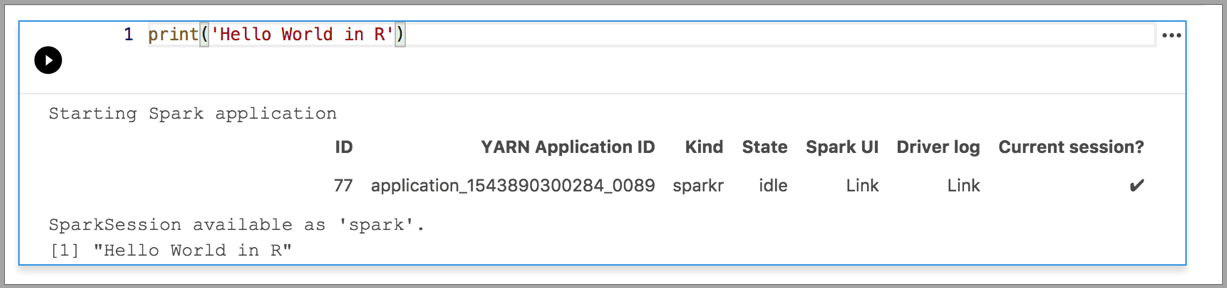
Os exemplos a seguir demonstram o uso de kernels diferentes para executar um comando "Olá, Mundo" simples. Selecione o kernel, insira o código de exemplo em uma célula e clique em Executar célula.
Pyspark
Spark | Linguagem Scala
Spark | Linguagem R
Python 3

Próximas etapas
- Criar e executar um notebook do SQL Server.
- Criar e executar um notebook do Python
- Execute scripts Python e R em notebooks no Azure Data Studio com os Serviços de Machine Learning do SQL Server.
- Implantar um cluster de Big Data do SQL Server com o notebook do Azure Data Studio.
- Gerenciar Clusters de Big Data do SQL Server com notebooks do Azure Data Studio.
- Executar um notebook de exemplo usando o Spark.