Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo descreve o objeto de sincronização do limite da GPU que pode ser usado na sincronização verdadeira de GPU para GPU no estágio 2 de agendamento de hardware de GPU. Esse recurso é suportado a partir do Windows 11, versão 24H2 (WDDM 3.2). Os desenvolvedores de drivers gráficos devem estar familiarizados com o WDDM 2.0 e o estágio 1 de agendamento de hardware da GPU.
Objeto de sincronização de limite monitorado do WDDM 2.x
O objeto de sincronização de limite monitorado do WDDM 2.x oferece suporte às seguintes operações:
- A CPU aguarda um valor de limite monitorado, por:
- Sondar usando um endereço virtual de CPU (VA).
- Enfileirar uma espera de bloqueio dentro de Dxgkrnl, que é sinalizada quando a CPU observa o novo valor de limite monitorado.
- Sinal da CPU de um valor monitorado.
- Sinal de GPU de um valor monitorado ao gravar no VA da GPU de limite monitorado, e aumentar um limite monitorado sinalizou interrupção para notificar a CPU da atualização de valor.
O que não tinha suporte era uma espera nativa na GPU por um valor de limite monitorado. Em vez disso, o sistema operacional continha o trabalho da GPU que depende do valor esperado na CPU. Ele só liberou esse trabalho para a GPU quando o valor é sinalizado.
Adicionado objeto de sincronização de cerca nativa da GPU
A partir do WDDM 3.2, o objeto fence monitorado foi estendido para dar suporte aos seguintes recursos adicionados:
- A GPU aguarda um valor de limite monitorado, o que permite a sincronização de mecanismo para mecanismo de alto desempenho sem exigir viagens de ida e volta da CPU.
- Notificação de interrupção condicional apenas para sinais de limite de GPU que tenham esperas de CPU. Esse recurso permite uma economia de energia substancial, permitindo que a CPU entre em um estado de baixo consumo de energia quando todo o trabalho da GPU estiver na fila.
- Armazenamento de valor de limite na memória local da GPU (em oposição à memória do sistema).
Design de objeto de sincronização de limite nativo da GPU
O diagrama a seguir ilustra a arquitetura básica de um objeto de limite nativo da GPU, com foco no estado do objeto de sincronização compartilhado entre a CPU e a GPU.
: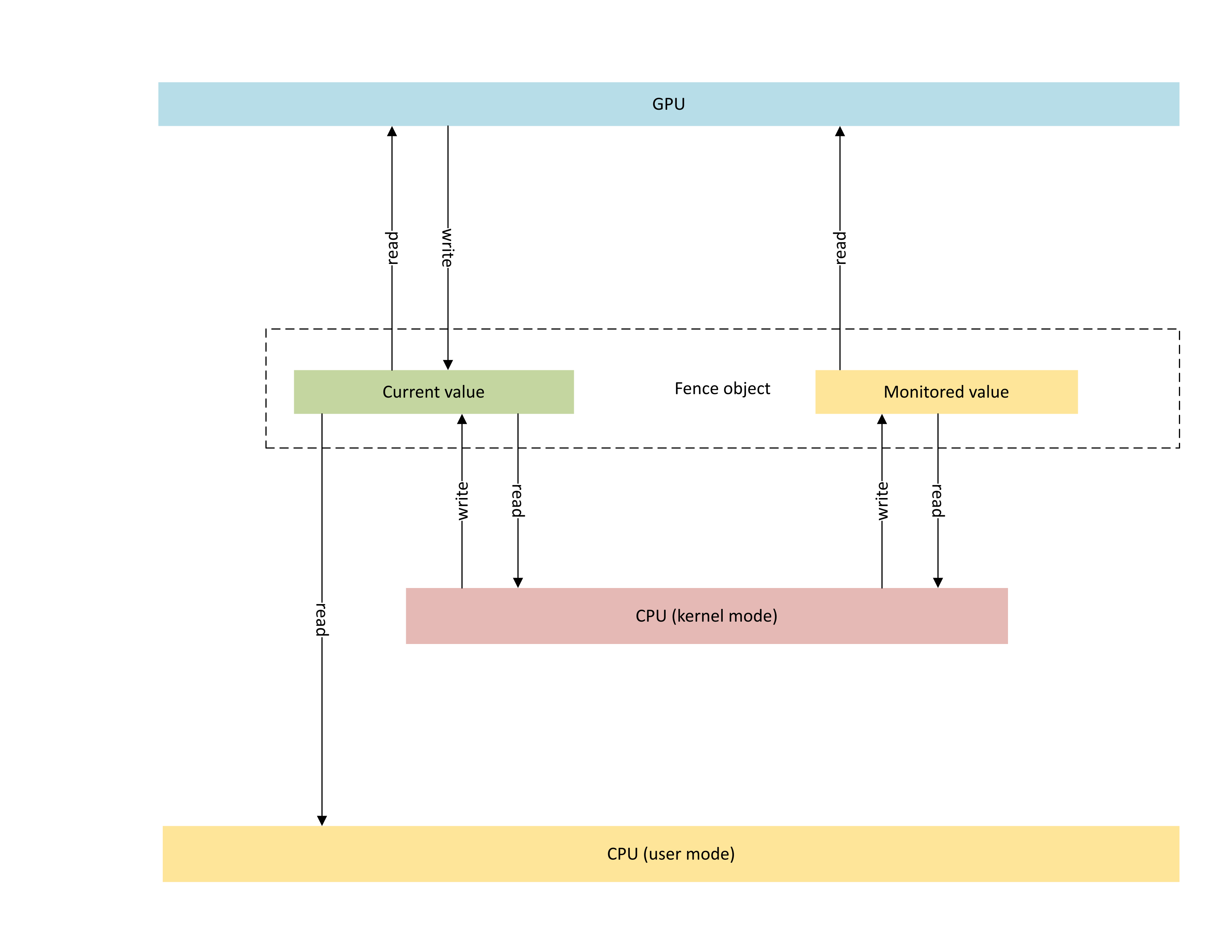
O diagrama inclui dois componentes principais:
Valor atual (referido como CurrentValue neste artigo). Esse local de memória contém o valor de limite de 64 bits sinalizado no momento. CurrentValue é mapeado e fica acessível tanto para a CPU (gravável a partir do modo kernel, legível a partir do modo de usuário e kernel) quanto para a GPU (legível e gravável usando o endereço virtual da GPU). CurrentValue requer que as gravações de 64 bits sejam atômicas do ponto de vista da CPU e da GPU. Ou seja, as atualizações para os 32 bits altos e baixos não podem ser interrompidas e devem ficar visíveis ao mesmo tempo. Esse conceito já está presente no objeto de limite monitorado atual.
Valor monitorado (referido como MonitoredValue neste artigo). Esse local de memória contém o valor menos esperado no momento pela CPU subtraído por um (1). MonitoredValue é mapeado e fica acessível tanto para a CPU (legível e gravável a partir do modo kernel, sem acesso ao modo de usuário) quanto para a GPU (legível usando GPU VA, sem acesso de gravação). O sistema operacional mantém a lista de esperas de CPU pendentes para um determinado objeto de limite e atualiza MonitoredValue à medida que as esperas são adicionadas e removidas. Quando não há esperas pendentes, o valor é definido como UINT64_MAX. Esse conceito é novo para o objeto de sincronização de limite nativo da GPU.
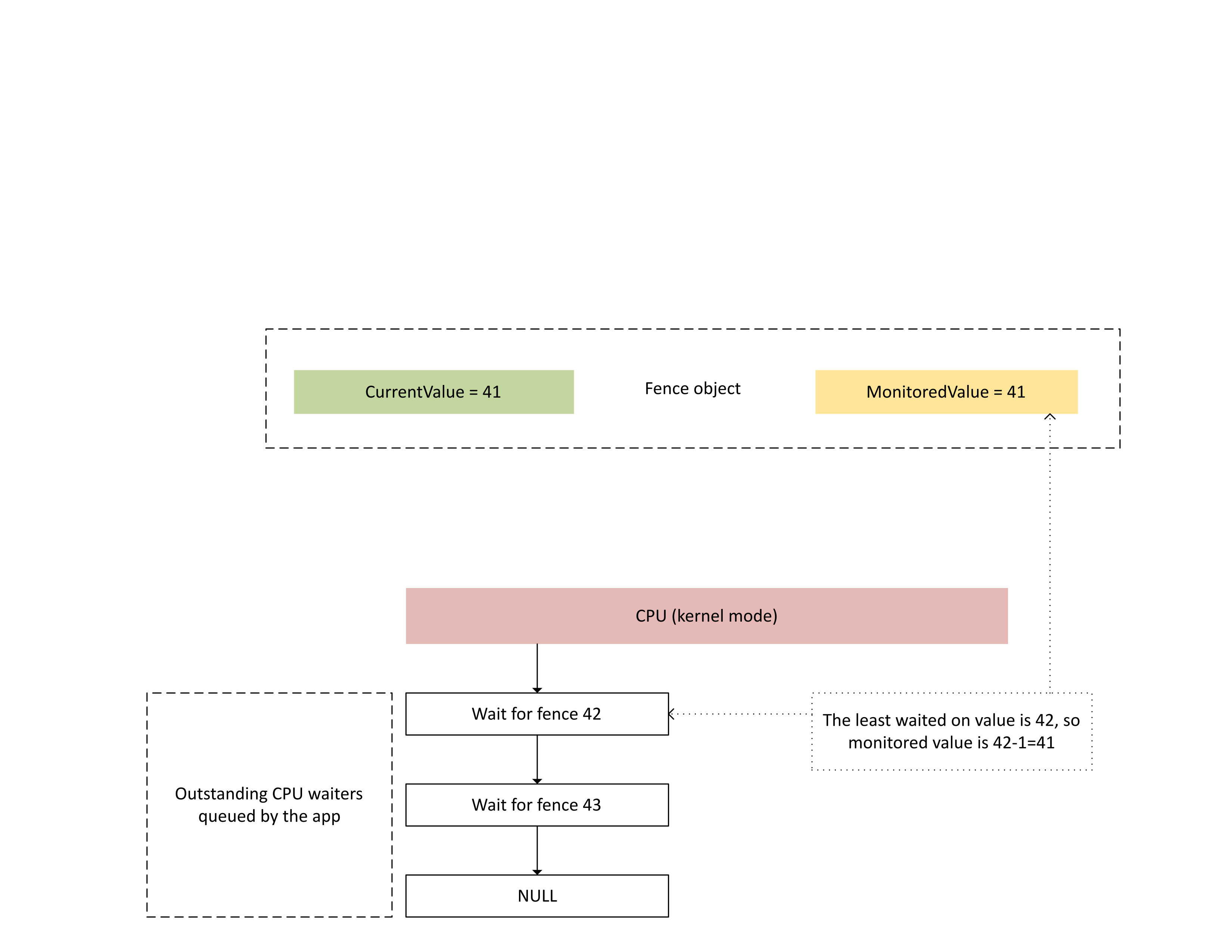
O próximo diagrama ilustra como o Dxgkrnl rastreia esperas de CPU pendentes por um valor específico de limite monitorado. Ele também mostra o valor do limite monitorado definido em um determinado ponto no tempo. CurrentValue e MonitoredValue são ambos 41, o que significa que:
- A GPU completou todas as tarefas até o valor de limite de 41.
- A CPU não está aguardando nenhum valor de limite menor ou igual a 41.
:
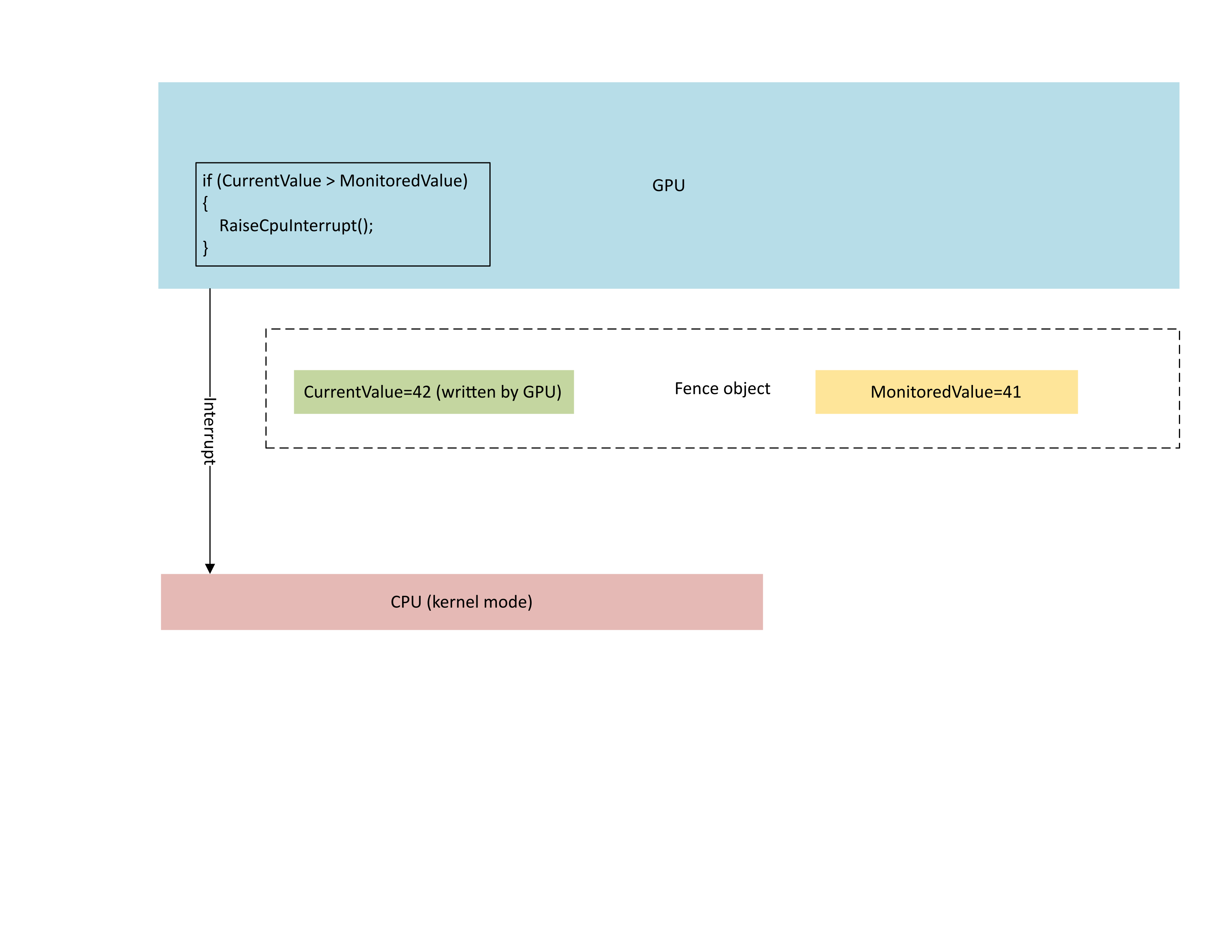
O diagrama a seguir ilustra que o processador de gerenciamento de contexto (CMP) da GPU gera condicionalmente uma interrupção de CPU somente se o novo valor de limite for maior que o valor monitorado. Tal interrupção significa que há esperas de CPU pendentes que podem ser satisfeitas com o valor recém-gravado.
:
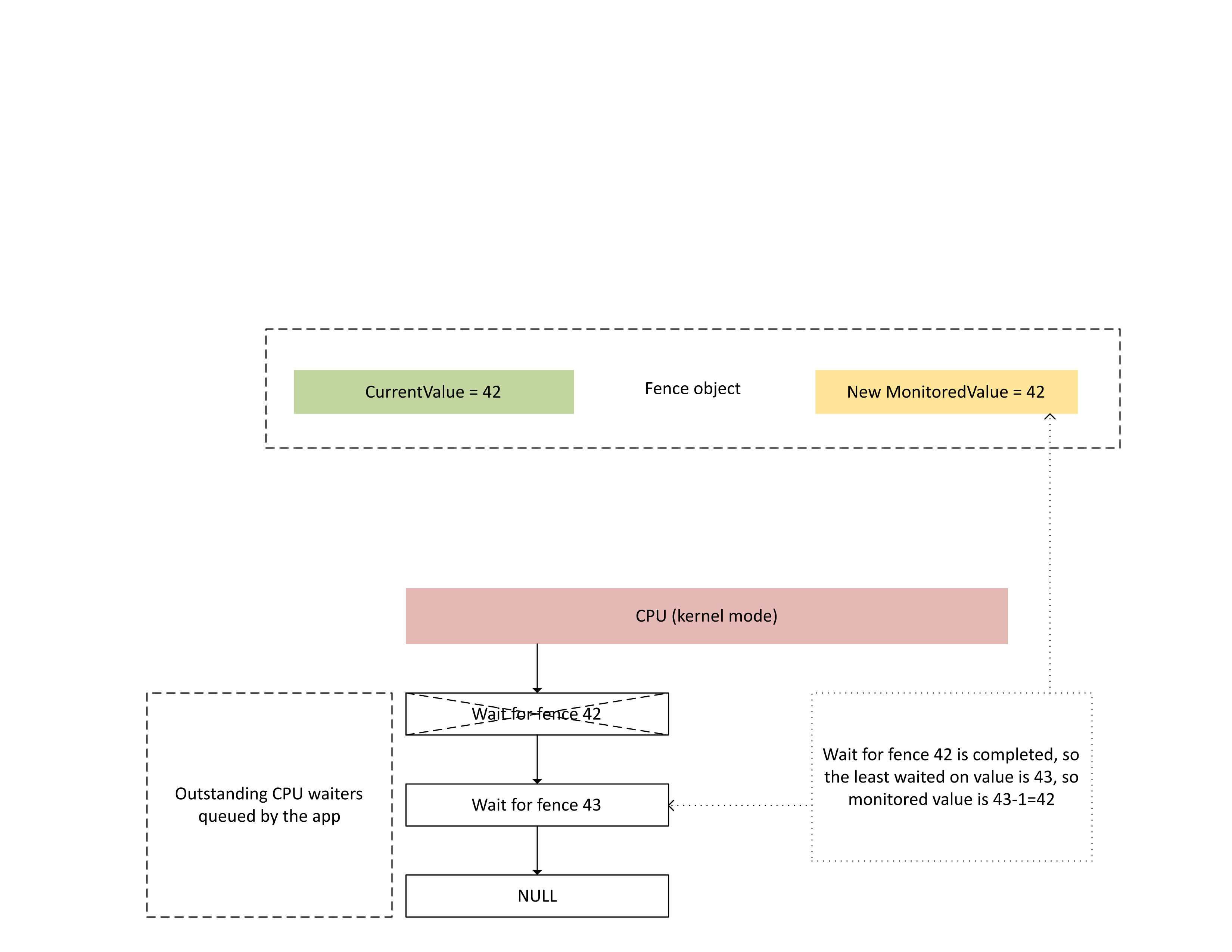
Quando a CPU processa essa interrupção, Dxgkrnl executa as seguintes ações, conforme ilustrado no diagrama a seguir:
- Ele desbloqueia esperas da CPU que ficaram satisfeitas com o limite recém-gravado.
- Ele adianta o valor monitorado para corresponder ao valor menos pendente aguardado subtraído por 1.
:
Armazenamento de memória física para valores de limite atuais e monitorados
Para um determinado objeto de limite, CurrentValue e MonitoredValue são armazenados em locais separados.
Os objetos de limite que não podem ser compartilhados têm armazenamento de valor de limite para objetos de limite diferentes dentro do mesmo processo empacotados na mesma página de memória. Os valores são empacotados de acordo com os valores de stride especificados nos limites do KMD de limite nativo descritos posteriormente neste artigo.
Os objetos de limite que podem ser compartilhados têm seus valores atuais e monitorados colocados em páginas de memória que não são compartilhadas com outros objetos de limite.
Valor atual
O valor atual pode residir na memória do sistema ou na memória local da GPU, dependendo do tipo de limite especificado pelo D3DDDI_NATIVEFENCE_TYPE.
O valor atual para cercas de adaptador cruzado está sempre na memória do sistema.
Quando o valor atual é armazenado na memória do sistema, o armazenamento é alocado do pool de memória interno do sistema.
Quando o valor atual é armazenado na memória local, o armazenamento é alocado de segmentos de memória especificados pelo driver em D3DKMDT_FENCESTORAGESURFACEDATA.
Valor monitorado
O valor monitorado também pode residir na memória local do sistema ou da GPU, dependendo D3DDDI_NATIVEFENCE_TYPE.
Quando o valor monitorado é armazenado na memória do sistema, o sistema operacional aloca o armazenamento do pool de memória interno do sistema.
Quando o valor monitorado é armazenado na memória local, o sistema operacional aloca armazenamento de segmentos de memória que o driver especificou em D3DKMDT_FENCESTORAGESURFACEDATA.
Quando as condições de espera da CPU do sistema operacional são alteradas , ele chama o retorno de chamada DxgkDdiUpdateMonitoredValues do KMD para instruir o KMD a atualizar o valor monitorado para um valor especificado.
Problemas de sincronização
O mecanismo descrito anteriormente tem uma condição de corrida inerente entre a CPU e a GPU, que lê e grava o valor atual e o valor monitorado. Se não forem tomados cuidados especiais, poderão ocorrer os seguintes problemas:
- A GPU poderia ler um MonitoredValue obsoleto e não gerar uma interrupção como esperado pela CPU.
- Um mecanismo de GPU pode gravar um CurrentValue mais recente enquanto o CMP está no meio da decisão da condição de interrupção. Esse CurrentValue mais recente pode não gerar a interrupção conforme esperado ou pode não ficar visível para a CPU à medida que busca o valor atual.
Sincronização dentro da GPU entre o mecanismo e o CMP
Para maior eficiência, muitas GPUs discretas implementam a semântica de sinal de cerca monitorada usando o estado de sombra que reside na memória local da GPU entre:
O mecanismo da GPU, que executa o fluxo de buffer de comando e condicionalmente eleva um sinal de hardware para o CMP.
O CMP da GPU que decide se uma interrupção da CPU deve ser gerada.
Nesse caso, o CMP precisa sincronizar o acesso à memória com o mecanismo da GPU que executa a gravação de memória no valor de limite. Em particular, a operação de atualização de um MonitoredValue de sombra deve ser ordenada do ponto de vista do CMP:
- Escreva um novo MonitoredValue (armazenamento de GPU de sombra).
- Execute uma barreira de memória para sincronizar o acesso à memória com o mecanismo da GPU.
- Ler CurrentValue:
- Se CurrentValue>MonitoredValue, gere uma interrupção de CPU.
- Se CurrentValue<= MonitoredValue, não gere a interrupção da CPU.
Para que essa condição de corrida seja resolvida corretamente, é imprescindível que a barreira de memória na etapa 2 funcione corretamente. Não deve haver uma operação de gravação de memória pendente para CurrentValue na etapa 3 que se originou de um comando que não viu a atualização de MonitoredValue na etapa 1. Essa situação geraria uma interrupção se a cerca escrita na etapa 3 fosse maior que o valor atualizado na etapa 1.
Sincronização entre a GPU e a CPU
A CPU tem que executar atualizações de MonitoredValue e leituras de CurrentValue de uma forma que não perca a notificação de interrupção para sinais em andamento.
- O sistema operacional precisa modificar MonitoredValue quando uma nova espera de CPU é adicionada ao sistema ou se uma espera de CPU existente é desativada.
- O sistema operacional chama DxgkDdiUpdateMonitoredValues para notificar a GPU de um novo valor monitorado.
- DxgkDdiUpdateMonitoredValue é executado no nível de interrupção do dispositivo e, portanto, é sincronizado com a rotina de serviço de interrupção (ISR) sinalizada do limite monitorado.
- DxgkDdiUpdateMonitoredValue deve garantir que, depois de retornar, CurrentValue lido por qualquer núcleo de processador foi gravado pelo CMP da GPU depois de ter observado o novo MonitoredValue.
- Após o retorno de DxgkDdiUpdateMonitoredValue, o sistema operacional redefine a amostra de CurrentValue e satisfaz todas as esperas que foram desbloqueadas pelo novo CurrentValue.
É perfeitamente aceitável que a CPU observe um CurrentValue mais recente do que o usado pela GPU para decidir se a interrupção será gerada. Essa situação ocasionalmente resultaria em uma notificação de interrupção que não desbloqueia nenhuma espera. O que não é aceitável é que a CPU não receba uma notificação de interrupção para a atualização de CurrentValue mais recente que foi monitorada (ou seja, CurrentValue>MonitoredValue).
Consultar a ativação do recurso de limite nativo no sistema operacional
Os drivers devem consultar se o recurso de limite nativo está habilitado no sistema operacional durante a inicialização do driver. A partir do WDDM 3.2, o sistema operacional usa a interface IsFeatureEnabled adicionada para controlar se determinados recursos estão habilitados, incluindo o recurso de limite nativo.
Como resultado, o KMD deve implementar a interface IsFeatureEnabled . A implementação do KMD deve consultar se o sistema operacional habilitou o recurso DXGK_FEATURE_NATIVE_FENCE antes de anunciar o suporte ao limite nativo no DXGK_VIDSCHCAPS. O sistema operacional falhará na inicialização do adaptador se o KMD anunciar suporte de limite nativo quando o sistema operacional não tiver habilitado o recurso.
Para obter mais informações sobre a interface de habilitação de recursos, consulte Consultando o suporte e a habilitação de recursos do WDDM.
DDIs para consultar a ativação de recursos de limite nativo
As seguintes interfaces são introduzidas para um KMD para consultar se o sistema operacional habilitou o recurso de limite nativo:
- DXGKCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKCBINT_FEATURE_NATIVEFENCE_1
O sistema operacional implementa a tabela de interface DXGKCB_FEATURE_NATIVEFENCE_CAPS_1 adicionada dedicada à versão 1 de DXGK_FEATURE_NATIVE_FENCE. O KMD deve consultar essa tabela de interface de recursos para determinar as funcionalidades do sistema operacional. Em versões futuras do sistema operacional, ele pode introduzir novas versões dessa tabela de interface, detalhando o suporte para novos recursos.
Código de driver de amostra para suporte a consultas
O código de exemplo a seguir mostra como os drivers devem usar o recurso DXGK_FEATURE_NATIVE_FENCE na interface DXGK_FEATURE_INTERFACE para consultar o suporte.
DXGK_FEATURE_INTERFACE FeatureInterface;
struct FEATURE_RESULT
{
bool Enabled;
DXGK_FEATURE_VERSION Version;
};
// Driver internal cache for state & version of queried features
struct FEATURE_STATE
{
struct
{
UINT NativeFenceEnabled : 1;
};
DXGK_FEATURE_VERSION NativeFenceVersion = 0;
// Interfaces
DXGKCBINT_FEATURE_NATIVEFENCE_1 NativeFenceInterface = {};
// Interface queried values
DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1 NativeFenceOSCaps1 = {};
};
// Helper function to query OS's feature enabled interface
FEATURE_RESULT IsFeatureEnabled(
DXGK_FEATURE_ID FeatureId
)
{
FEATURE_RESULT Result = {};
//
// If the feature interface functionality is available (e.g. supported by the OS)
//
DXGKARGCB_ISFEATUREENABLED2 Args = {};
Args.FeatureId = FeatureId;
if(NT_SUCCESS(FeatureInterface.IsFeatureEnabled(DxgkInterface.DeviceHandle, &Args)))
{
Result.Enabled = Args.Result.Enabled;
Result.Version = Args.Result.Version;
}
return Result;
}
// Actual code to query whether OS has enabled Native Fence support and corresponding OS caps
FEATURE_RESULT FeatureResult = IsFeatureEnabled(DXGK_FEATURE_NATIVE_FENCE);
FEATURE_STATE FeatureState = {};
FeatureState.NativeFenceEnabled = !!FeatureResult.Enabled;
if (FeatureResult.Enabled)
{
// Query OS caps for native fence feature, using the feature interface
DXGKARGCB_QUERYFEATUREINTERFACE QFIArgs = {};
QFIArgs.FeatureId = DXGK_FEATURE_NATIVE_FENCE;
QFIArgs.Interface = &FeatureState.NativeFenceInterface;
QFIArgs.InterfaceSize = sizeof(FeatureState.NativeFenceInterface);
QFIArgs.Version = FeatureResult.Version;
Status = FeatureInterface.QueryFeatureInterface(DxgkInterface.DeviceHandle, &QFIArgs);
if(NT_SUCCESS(Status))
{
FeatureState.NativeFenceVersion = FeatureResult.Version;
Status = FeatureState.NativeFenceInterface.GetOSCaps(&FeatureState.NativeFenceOSCaps1);
NT_ASSERT(NT_SUCCESS(Status));
}
else
{
// We should always succeed getting an interface from a successfully
// negotiated feature + version.
NT_ASSERT(FALSE);
}
}
Recursos nativos de limite
As seguintes interfaces são atualizadas ou introduzidas para consultar recursos nativos de limite:
O campo NativeGpuFence é adicionado a DXGK_VIDSCHCAPS. Se o sistema operacional tiver ativado o recurso DXGK_FEATURE_NATIVE_FENCE, o driver poderá declarar suporte para a funcionalidade de limite de GPU nativa durante a inicialização do adaptador definindo o bit do DXGK_VIDSCHCAPS::NativeGpuFence como 1.
O DXGKQAITYPE_NATIVE_FENCE_CAPS é adicionado a DXGK_QUERYADAPTERINFOTYPE.
O Dxgkrnl expõe esse recurso ao modo de usuário por meio da estrutura/bit correspondente D3DKMT_WDDM_3_1_CAPS::NativeGpuFenceSupported adicionada.
O KMTQAITYPE_WDDM_3_1_CAPS é adicionado ao KMTQUERYADAPTERINFOTYPE.
As entidades a seguir são adicionadas a um KMD para indicar seus recursos de suporte ao recurso de limite de GPU nativa.
A estrutura DXGK_NATIVE_FENCE_CAPS descreve os recursos de limite nativos da GPU. Quando o KMD define o bit do MapToGpuSystemProcess dessa estrutura, ele está instruindo o sistema operacional a reservar um espaço de endereço virtual da GPU do processo do sistema para uso do CMP e a criar mapeamentos VA da GPU nesse espaço de endereço para o limite nativo de CurrentValue e MonitoredValue. Esses VAs de GPU são posteriormente passados para o retorno de chamada de criação de limite do KMD como DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa e MonitoredValueSystemProcessGpuVa.
O KMD retorna sua estrutura de DXGK_NATIVE_FENCE_CAPS preenchida quando sua função DxgkDdiQueryAdapterInfo é chamada com o tipo de informações do adaptador de consulta DXGKQAITYPE_NATIVE_FENCE_CAPS adicionado.
DDIs d0 KMD para criar, abrir, fechar e destruir um objeto de limite nativo
As seguintes DDIs implementadas por KMD são introduzidas para criar, abrir, fechar e destruir um objeto de limite nativo. O Dxgkrnl chama essas DDIs em nome de componentes de modo de usuário. O Dxgkrnl os chama somente se o sistema operacional ativou o recurso DXGK_FEATURE_NATIVE_FENCE.
- DxgkDdiCreateNativeFence/DXGKARG_CREATENATIVEFENCE
- DxgkDdiOpenNativeFence/DXGKARG_OPENNATIVEFENCE
- DxgkDdiCloseNativeFence/DXGKARG_CLOSENATIVEFENCE
- DxgkDdiDestroyNativeFence/DXGKARG_DESTROYNATIVEFENCE
As seguintes DDIs foram atualizadas para oferecer suporte a objetos de limite nativos:
Os seguintes membros foram adicionados a DRIVER_INITIALIZATION_DATA. Os drivers que suportam objetos de limite de GPU nativos devem implementar as funções e fornecer Dxgkrnl com ponteiros para eles por meio dessa estrutura.
- PDXGKDDI_CREATENATIVEFENCE DxgkDdiCreateNativeFence (adicionado ao WDDM 3.1)
- PDXGKDDI_DESTROYNATIVEFENCE DxgkDdiDestroyNativeFence (adicionado ao WDDM 3.1)
- PDXGKDDI_OPENNATIVEFENCE DxgkDdiCreateNativeFence (adicionado ao WDDM 3.2)
- PDXGKDDI_CLOSENATIVEFENCE DxgkDdiCloseNativeFence (adicionado ao WDDM 3.2)
- PDXGKDDI_SETNATIVEFENCELOGBUFFER DxgkDdiSetNativeFenceLogBuffer (adicionado ao WDDM 3.2)
- PDXGKDDI_UPDATENATIVEFENCELOGS DxgkDdiUpdateNativeFenceLogs (adicionado ao WDDM 3.2)
Identificadores globais e locais para limites compartilhados
Imagine que o processo A cria um limite nativo compartilhado e o processo B depois abre essa limite.
Quando o processo A cria o limite nativo compartilhado, o Dxgkrnl chama DxgkDdiCreateNativeFence com o identificador do driver do adaptador no qual esse limite é criado. O identificador de limite criado e retornado em hGlobalNativeFence é o identificador de limite global.
Posteriormente, o Dxgkrnl segue com uma chamada para DxgkDdiOpenNativeFence para abrir o identificador local específico de um processo A (hLocalNativeFenceA).
Quando o processo B abre o mesmo limite nativo compartilhado, o Dxgkrnl chama DxgkDdiOpenNativeFence para abrir um identificador local específico do processo B (hLocalNativeFenceB).
Se o processo A destruir sua instância de cerca nativa compartilhada, o Dxgkrnl verá que ainda há uma referência pendente a esse limite global, então chama apenas DxgkDdiCloseNativeFence(hLocalNativeFenceA) para que o driver limpe estruturas específicas do processo A. O identificador hGlobalNativeFence ainda existe.
Quando o processo B destrói sua instância de limite, Dxgkrnl chama DxgkDdiCloseNativeFence (hLocalNativeFenceB) e, em seguida, DxgkDdiDestroyNativeFence(hGlobalNativeFence) para permitir que o KMD destrua seus dados de limite global.
Mapeamentos do VA da GPU no espaço de endereço do processo de paginação para uso do CMP
O KMD define o limite DXGK_NATIVE_FENCE_CAPS::MapToGpuSystemProcess no hardware que requer que os VAs da GPU de limite nativo também sejam mapeados no espaço de endereço do processo de paginação da GPU. Um bit MapToGpuSystemProcess definido instrui o sistema operacional a criar mapeamentos do VA da GPU no espaço de endereço do processo de paginação para CurrentValue e MonitoredValue do limite nativo para uso pelo CMP. Esses VAs da GPU são posteriormente passados para DxgkDdiCreateNativeFence como DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa e MonitoredValueSystemProcessGpuVa.
APIs de kernel D3DKMT para criar, abrir e destruir cercas nativas
As seguintes APIs de modo kernel D3DKMT são introduzidas para criar e abrir um objeto de limite nativo.
- D3DKMTCreateNativeFence / D3DKMT_CREATENATIVEFENCE
- D3DKMTOpenNativeFenceFromNTHandle / D3DKMT_OPENNATIVEFENCEFROMNTHANDLE
Dxgkrnl chama a função D3DKMTDestroySynchronizationObject existente para fechar e destruir (liberar) um objeto de limite nativo existente.
As estruturas de suporte e as enumerações que são introduzidas ou atualizadas incluem:
- D3DDDI_NATIVEFENCEINFO
- D3DDDI_NATIVEFENCE_TYPE
- D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS
- D3DDDI_NATIVEFENCE_MAPPING
DDI para dar suporte à colocação de valores de limite nativos na memória local
Os seguintes DDIs foram adicionados ou alterados para dar suporte ao posicionamento de valores de limite nativos na memória local:
A estrutura D3DKMDT_FENCESTORAGESURFACEDATA é adicionada.
O fence nativo MonitoredValue e o CurrentValue do tipo de fence nativo D3DDDI_NATIVEFENCE_TYPE_INTRA_GPU podem ser colocados na memória do dispositivo local. Para fazer isso, o sistema operacional solicitará que o driver especifique segmentos de memória nos quais o armazenamento fence deve ser colocado. DxgkDdiGetStandardAllocation é estendido para fornecer essas informações.
D3DKMDT_STANDARDALLOCATION_FENCESTORAGE é adicionado a DXGKARG_GETSTANDARDALLOCATIONDRIVERDATA.
Indicando uma cerca de progresso nativa para filas de hardware
A atualização a seguir é introduzida para indicar um objeto de limite de progresso da fila de hardware nativo:
Um sinalizador NativeProgressFence é adicionado para chamadas para DxgkDdiCreateHwQueue.
- Em sistemas compatíveis, o sistema operacional atualiza o limite de progresso da fila de hardware para um limite nativo. Quando o sistema operacional define NativeProgressFence, ele indica ao KMD que o identificador DXGKARG_CREATEHWQUEUE::hHwQueueProgressFence aponta para o identificador do driver de um objeto de limite de GPU nativo criado anteriormente usando DxgkDdiCreateNativeFence.
Interrupção sinalizada de limite nativo
As seguintes alterações são feitas no mecanismo de interrupção para dar suporte a uma interrupção sinalizada de limite nativo
A enumeração DXGK_INTERRUPT_TYPE é atualizada para ter um tipo de interrupção DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED.
A estrutura DXGKARGCB_NOTIFY_INTERRUPT_DATA é atualizada para incluir uma estrutura NativeFenceSignaled para denotar uma interrupção sinalizada de cerca nativa
A NativeFenceSignaled é usada para informar ao sistema operacional que um conjunto de objetos de GPU de limite nativo monitorados pela CPU foram sinalizados em um mecanismo de GPU. Se a GPU for capaz de determinar o subconjunto exato de objetos com esperas de CPU ativas, ela passará esse subconjunto via pSignaledNativeFenceArray. Os identificadores nessa matriz devem ser identificadores hGlobalNativeFence válidos que o Dxgkrnl passou ao KMD em DxgkDdiCreateNativeFence. Passar um identificador para um objeto de limite nativo destruído gera uma verificação de bug.
A estrutura DXGKCB_NOTIFY_INTERRUPT_DATA_FLAGS é atualizada para incluir um membro EvaluateLegacyMonitoredFences.
A GPU pode passar um pSignaledNativeFenceArray NULL sob as seguintes condições:
- A GPU não consegue determinar o subconjunto exato de objetos com esperas de CPU ativas.
- Várias interrupções sinalizadas são recolhidas juntas, tornando difícil determinar o conjunto sinalizado com esperas ativas.
Um valor NULL instrui o sistema operacional a verificar todas as esperas de objeto de limite de GPU nativo pendentes.
O contrato entre o sistema operacional e o driver é: se o sistema operacional tiver uma espera de CPU ativa (conforme expresso por MonitoredValue) e o mecanismo de GPU sinalizou o objeto para o valor que requer uma interrupção de CPU, a GPU deve executar uma das seguintes ações:
- Inclua esse identificador de limite nativo no pSignaledNativeFenceArray.
- Inicie uma interrupção NativeFenceSignaled com um pSignaledNativeFenceArray NULL.
Por padrão, quando o KMD gera essa interrupção com um pSignaledNativeFenceArray NULL, o Dxgkrnl verifica apenas todas as esperas de limite nativo pendentes e não as esperas de limite monitorado herdadas. Em um hardware que não pode distinguir entre DXGK_INTERRUPT_MONITORED_FENCE_SIGNALED herdado e DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED, o KMD sempre pode gerar apenas a interrupção de DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED introduzida com pSignaledNativeFenceArray = NULL e EvaluateLegacyMonitoredFences = 1, que indica ao sistema operacional para verificar todas as esperas (espera de limite monitorado herdada & esperas de limite nativo).
Instruindo o KMD a atualizar lotes de valores
As interfaces a seguir são introduzidas para instruir o KMD a atualizar um lote de valores atuais ou monitorados:
DxgkDdiUpdateCurrentValuesFromCpu / DXGKARG_UPDATECURRENTVALUESFROMCPU
DxgkDdiUpdateMonitoredValues / DXGKARG_UPDATEMONITOREDVALUES
Limites nativos de adaptador cruzado
O sistema operacional deve oferecer suporte à criação de limites nativos de adaptador cruzado porque os aplicativos DX12 existentes criam e usam limites monitorados de adaptador cruzado. Se as filas subjacentes e o agendamento desses aplicativos forem alternados para o envio no modo de usuário, seus limites monitorados também deverão ser alternados para limites nativos (as filas de modo de usuário não podem oferecer suporte a limites monitorados).
Um limite de adaptador cruzado deve ser criado com o tipo D3DDDI_NATIVEFENCE_TYPE_DEFAULT. Caso contrário, o D3DKMTCreateNativeFence falhará.
Todas as GPUs compartilham a mesma cópia do armazenamento de CurrentValue, que é sempre alocado na memória do sistema. Quando o tempo de execução cria um limite nativo de adaptador cruzado na GPU1 e a abre na GPU2, os mapeamentos VA da GPU em ambas as GPUs apontam para o mesmo armazenamento físico de CurrentValue.
Cada GPU recebe sua própria cópia do MonitoredValue. Assim, o armazenamento MonitoredValue pode ser alocado na memória do sistema ou local.
Os limites nativos de adaptador cruzado devem resolver a condição em que a GPU1 está aguardando em um limite nativo que a GPU2 sinalizou. Hoje, não há nenhum conceito de sinais GPU-to-GPU, portanto, o sistema operacional resolve explicitamente essa condição sinalizando a GPU1 da CPU. Essa sinalização é feita definindo o MonitoredValue para o limite de adaptador cruzado como 0 para sua vida útil. Em seguida, quando a GPU2 sinaliza o limite nativo, ela também gera uma interrupção da CPU, permitindo que o Dxgkrnl atualize o CurrentValue na GPU1 (usando DxgkDdiUpdateCurrentValuesFromCpu com o sinalizador NotificationOnly definido como TRUE) e desbloqueie todas as esperas de CPU/GPU pendentes dessa GPU.
Embora o MonitoredValue seja sempre 0 para limites nativos de adaptador cruzado, a espera e os sinais enviados na mesma GPU ainda se beneficiam da sincronização mais rápida da GPU. No entanto, o benefício de energia das interrupções de CPU reduzidas é perdido, pois as interrupções de CPU serão aumentadas incondicionalmente, mesmo se não houvesse esperas da CPU ou na outra GPU. Essa compensação é feita para manter o custo de projeto e implementação do limite nativo de adaptador cruzado simples.
O sistema operacional suporta o cenário em que um objeto de limite nativo é criado na GPU1 e aberto na GPU2, onde a GPU1 suporta o recurso e a GPU2 não. O objeto de limite é aberto como um MonitoredFence regular na GPU2.
O sistema operacional suporta o cenário em que um objeto de limite monitorado regular é criado na GPU1 e aberto como um limite nativo na GPU2, que suporta o recurso. O objeto de limite é aberto como um limite nativo na GPU2.
Combinações de espera/sinal de adaptador cruzado
As tabelas nas subseções a seguir mostram um exemplo de um sistema iGPU e dGPU e listam as várias configurações possíveis para espera/sinal de limite nativo da CPU/GPU. São considerados os dois casos seguintes:
- Ambas as GPUs suportam limites nativos.
- A iGPU não suporta limites nativos, mas a dGPU sim.
O segundo cenário também é semelhante ao caso em que ambas as GPUs suportam limites nativos, mas a espera/sinal de limite nativo é submetida a uma fila de modo kernel na iGPU.
As tabelas devem ser lidas selecionando um par de espera e sinal das colunas, por exemplo, WaitFromGPU - SignalFromGPU ou WaitFromGPU - SignalFromCPU etc.
Cenário 1
No cenário 1, tanto a dGPU quanto a iGPU oferecem suporte a limites nativos.
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalizarDoCpu(hFence, 10) |
|---|---|---|---|
| O UMD insere uma espera para a instrução hfence CurrentValue == 10 no buffer de comando | Chamadas de tempo de execução D3DKMTWaitForSynchronizationObjectFromCpu | ||
| O VidSch rastreia esse objeto de sincronização em sua lista de esperas da CPU de limite nativo | |||
| O UMD insere uma instrução de sinal hFence CurrentValue = 10 no buffer de comando | Chamadas de tempo de execução D3DKMTSignalSynchronizationObjectFromCpu | ||
| O VidSch recebe um limite nativo sinalizado ISR quando o CurrentValue é gravado (porque MonitoredValue == 0 sempre) | O VidSch chama DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| O VidSch propaga o sinal (hFence, 10) para a iGPU | O VidSch propaga o sinal (hFence, 10) para a iGPU | ||
| O VidSch recebe o sinal propagado e chama DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | O VidSch recebe o sinal propagado e chama DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| O KMD verifica novamente a lista de execução para desbloquear o canal HW que estava aguardando no hFence | O VidSch desbloqueia a condição de espera da CPU sinalizando o KEVENT |
Cenário 2a
No cenário 2a, a iGPU não suporta limites nativos, mas a dGPU sim. Uma espera é enviada na iGPU e um sinal é enviado na dGPU.
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| Chamadas de tempo de execução D3DKMTWaitForSynchronizationObjectFromGpu | Chamadas de tempo de execução D3DKMTWaitForSynchronizationObjectFromCpu | ||
| O VidSch rastreia esse objeto de sincronização em sua lista de espera de limite monitorado | O VidSch rastreia esse objeto de sincronização na sua lista de espera da CPU de limite monitorado | ||
| O UMD insere uma instrução de sinal hFence CurrentValue = 10 no buffer de comando | Chamadas de tempo de execução D3DKMTSignalSynchronizationObjectFromCpu | ||
| O VidSch recebe NativeFenceSignaledISR quando o CurrentValue é gravado (porque MV == 0 sempre) | O VidSch chama DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| O VidSch propaga o sinal (hFence, 10) para a iGPU | O VidSch propaga o sinal (hFence, 10) para a iGPU | ||
| O VidSch recebe o sinal propagado e observa novo valor de limite | O VidSch recebe o sinal propagado e observa novo valor de limite | ||
| O VidSch verifica sua lista de espera de limite monitorado e desbloqueia contextos de software | O VidSch verifica sua lista de espera da CPU de limite monitorado e desbloqueia a espera da CPU sinalizando o KEVENT |
Cenário 2b
No cenário 2b, o suporte a limite nativo permanece o mesmo (iGPU não suporta, dGPU suporta). Nesse caso, um sinal é enviado na iGPU e uma espera é enviada na dGPU.
| iGPU SignalFromGPU (hFence, 10) | iGPU SignalFromCPU (hFence, 10) | dGPU WaitFromGpu (hFence, 10) | dGPU WaitFromCpu(hFence, 10) |
|---|---|---|---|
| O UMD insere uma espera para a instrução hfence CurrentValue == 10 no buffer de comando | Chamadas de tempo de execução D3DKMTWaitForSynchronizationObjectFromCpu | ||
| O VidSch rastreia esse objeto de sincronização em sua lista de esperas da CPU de limite nativo | |||
| O UMD chama D3DKMTSignalSynchronizationObjectFromGpu | O UMD chama D3DKMTSignalSynchronizationObjectFromCpu | ||
| Quando o pacote está à frente do contexto do software, o VidSch atualiza o valor do limite diretamente da CPU | O VidSch atualiza o valor do limite diretamente da CPU | ||
| O VidSch propaga o sinal (hFence, 10) para a dGPU | O VidSch propaga o sinal (hFence, 10) para a dGPU | ||
| O VidSch recebe o sinal propagado e chama DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | O VidSch recebe o sinal propagado e chama DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| O KMD verifica novamente a lista de execução para desbloquear o canal HW que estava aguardando no hFence | O VidSch desbloqueia a condição de espera da CPU sinalizando o KEVENT |
Futuro sinal de adaptador cruzado da GPU para a GPU
Conforme descrito em Problemas de sincronização, para limites nativos de adaptador cruzado, perdemos economia de energia porque uma interrupção da CPU é gerada incondicionalmente.
Em uma versão futura, o sistema operacional desenvolverá uma infraestrutura para permitir que um sinal de GPU em uma GPU interrompa outras GPUs gravando em uma memória de campainha comum, permitindo que outras GPUs acordem, processem sua lista de execução e desbloqueiem filas HW prontas.
O desafio deste trabalho é projetar:
- A memória comum da campainha.
- Um conteúdo ou identificador inteligente que uma GPU possa gravar na campainha, permitindo que outras GPUs determinem qual limite foi sinalizado para que só possa escanear um subconjunto de HWQueues.
Com esse sinal de adaptador cruzado, pode até ser possível que as GPUs compartilhem a mesma cópia do armazenamento de limite nativo (uma alocação de adaptador cruzado de formato linear, semelhante às alocações de verificação em adaptador cruzado) a partir da qual todas as GPUs leem e gravam.
Design de buffer de log de limite nativo
Com limites nativos e envio no modo de usuário, o Dxgkrnl não tem visibilidade de quando as esperas da GPU nativas e os sinais enfileirados do UMD são desbloqueados na GPU para um HWQueue específico. Com limites nativos, uma interrupção sinalizada de limite monitorado poderia ser suprimida para um determinado limite.
:
Uma maneira de recriar as operações de limite, como mostrado nesta imagem de GPUView, é necessária. As caixas rosa escuro são sinais e as caixas rosa claro são esperas. Cada caixa começa quando a operação for enviada na CPU para o Dxgkrnl e termina quando o Dxgkrnl concluir a operação na CPU. Dessa forma, podemos estudar toda a vida útil de um comando.
Assim, em um nível alto, as condições por HWQueue necessárias para serem registradas são:
| Condição | Significado |
|---|---|
| FENCE_WAIT_QUEUED | Carimbo de data/hora da CPU de quando o UMD insere uma instrução de uma espera da GPU na fila de comandos |
| FENCE_SIGNAL_QUEUED | Carimbo de data/hora da CPU de quando o UMD insere uma instrução de um sinal da GPU na fila de comandos |
| FENCE_SIGNAL_EXECUTED | Carimbo de data/hora da GPU de quando um comando de sinal é executado na GPU para um HWQueue |
| FENCE_WAIT_UNBLOCKED | Carimbo de data/hora da GPU de quando uma condição de espera é satisfeita na GPU e o HWQueue é desbloqueado |
DDIs de buffer de log de limite nativo
As seguintes DDI, estruturas e enumerações são introduzidas para oferecer suporte a buffers de log de limite nativo:
- DxgkDdiSetNativeFenceLogBuffer / DXGKARG_SETNATIVEFENCELOGBUFFER
- DxgkDdiUpdateNativeFenceLogs / DXGKARG_UPDATENATIVEFENCELOGS
- Um buffer de log que contém um cabeçalho e uma matriz de entradas de log. O cabeçalho identifica se as entradas são para uma espera ou um sinal e cada entrada identifica o tipo de operação (executada ou desbloqueada):
O design do buffer de log destina-se a filas de envio de cerca nativa e modo de usuário em que a carga do buffer de log é gravada pelo mecanismo de GPU/CMP, sem envolvimento de Dxgkrnl ou KMD. Portanto, o UMD inserirá uma instrução enquanto gera o buffer de comando wait/signal, programando a GPU para gravar a carga útil do buffer de log na entrada do buffer de log na execução. Para envio de modo não usuário (ou seja, filas no modo kernel), a espera e os sinais são comandos de software dentro do Dxgkrnl, portanto, já sabemos os carimbos de data/hora e outros detalhes dessas operações e não exigimos hardware/KMD para atualizar o buffer de log. Para essas filas do modo kernel, Dxgkrnl não criará um buffer de log.
Mecanismo de buffer de log
O Dxgkrnl aloca dois buffers de log dedicados de 4 KB por HWQueue.
- Um para registrar esperas.
- Um para registrar sinais.
Esses buffers de log têm mapeamentos para a VA da CPU no modo kernel (LogBufferCpuVa), uma VA da GPU no espaço de endereço do processo (LogBufferGpuVa) e a VA do CMP (LogBufferSystemProcessGpuVa), para que possam ser lidas/gravadas no KMD, no mecanismo da GPU e no CMP. O Dxgkrnl chama DxgkDdiSetNativeFenceLogBuffer duas vezes: uma para definir o buffer de log de registro de esperas e outra para definir o buffer de log de registro de sinais.
Imediatamente após o UMD inserir uma instrução de espera ou sinal de limite nativo na lista de comandos, ele também insere um comando instruindo a GPU a gravar uma carga útil em uma entrada específica no buffer de log.
Depois que o mecanismo da GPU executa a operação de limite, ele vê a instrução do UMD para gravar uma carga útil em uma determinada entrada no buffer de log. Além disso, a GPU também grava o FenceEndGpuTimestamp atual nessa entrada do buffer de log.
Embora o UMD não possa acessar o buffer de log acessível pela GPU, ele controla a progressão do buffer de log. Ou seja, o UMD determina a próxima entrada gratuita para gravar, se houver, e programa a GPU com essas informações. Quando a GPU grava no buffer de log, ela incrementa o valor de FirstFreeEntryIndex no cabeçalho do log. O UMD deve garantir que as gravações nas entradas de log estejam aumentando monotonicamente.
Considere o cenário a seguir.
- Existem dois HWQueues, HWQueueA e HWQueueB, com buffers de log de limite correspondentes com VAs de GPU de FenceLogA e FenceLogB. O HWQueueA está associado ao buffer de log para registrar esperas e o HWQueueB está associado ao buffer de log para registrar sinais.
- Há um objeto de limite nativo com um D3DKMT_HANDLE de modo de usuário do FenceF.
- Uma espera da GPU no FenceF para o valor V1 é enfileirada para HWQueueA no momento CPUT1. Quando o UMD cria o buffer de comandos, ele insere um comando instruindo a GPU a registrar o conteúdo: LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED).
- Um sinal da GPU para FenceF com valor V1 é enfileirado para HWQueueB no momento CPUT2. Quando o UMD cria o buffer de comandos, ele insere um comando instruindo a GPU a registrar o conteúdo: LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED).
Depois que o agendador da GPU executa o sinal da GPU em HWQueueB no momento da GPU GPUT1, ele lê o conteúdo do UMD e registra o evento no log de limite fornecido pelo sistema operacional para HWQueueB:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED;
LogEntry.FenceEndGpuTimestamp = GPUT1; // Time when UMD submits a command to the GPU
Depois que o agendador da GPU observa que o HWQueueA é desbloqueado no momento da GPU GPUT2, ele lê o conteúdo do UMD e registra o evento no log de limite fornecido pelo sistema operacional para HWQueueA:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED;
LogEntry.FenceObservedGpuTimestamp = GPUTo; // Time that GPU acknowledged UMD's submitted command and queued the fence wait on HW
LogEntry.FenceEndGpuTimestamp = GPUT2;
O Dxgkrnl pode destruir e recriar um buffer de log. Cada vez que isso acontece, ele chama DxgkDdiSetNativeFenceLogBuffer para informar o KMD sobre o novo local.
Carimbos de data/hora da CPU de operações de limite enfileiradas
Há pouco benefício em fazer com que o UMD registre esses carimbos de data/hora da CPU, dado que:
- Uma lista de comandos pode ser gravada vários minutos antes da execução da GPU de um buffer de comandos que inclui a lista de comandos.
- Esses vários minutos podem estar fora de ordem com outros objetos de sincronização que estão no mesmo buffer de comando.
Há um custo para incluir os carimbos de data/hora da CPU nas instruções do UMD para o buffer de log gravado pela GPU, para que os carimbos de data/hora da CPU não sejam incluídos no conteúdo de entrada do log.
Em vez disso, o tempo de execução ou o UMD pode emitir um evento ETW de limite nativo enfileirado com o carimbo de data/hora da CPU no momento em que uma lista de comandos está sendo gravada. As ferramentas podem, portanto, criar uma linha do tempo de eventos enfileirados e concluídos, combinando o carimbo de data/hora da CPU desse novo evento e o carimbo de data/hora da GPU da entrada do buffer de log.
Ordem das operações na GPU ao sinalizar ou desbloquear um limite
O UMD deve garantir que ele mantenha a seguinte ordem quando cria uma lista de comandos instruindo a GPU a sinalizar/desbloquear um limite:
- Escreva o novo valor de limite para limitar a o VA da GPU/do CMP.
- Grave o conteúdo do log no buffer de log correspondente do VA da GPU/do CMP.
- Se necessário, gere uma interrupção sinalizada de limite nativo.
Essa ordem de operações garante que o Dxgkrnl veja as entradas de log mais recentes quando a interrupção é gerada no sistema operacional.
A saturação do buffer de log é permitida
A GPU pode saturar o buffer de log substituindo entradas ainda não vistas pelo sistema operacional. Ela faz isso incrementando o WraparoundCount..
Quando o sistema operacional eventualmente lê o log, ele pode detectar que ocorreu uma saturação comparando o novo valor de WraparoundCount no cabeçalho do log com seu valor armazenado em cache. Se ocorreu uma saturação, o sistema operacional tem as seguintes opções de fallback:
- Para desbloquear limites quando ocorre uma saturação, o sistema operacional verifica todos os limites e determina quais esperas foram desbloqueadas.
- Se o rastreamento estiver habilitado, o sistema operacional poderá emitir um sinalizador no rastreamento para notificar um usuário de que os eventos foram perdidos. Além disso, quando o rastreamento está habilitado, o sistema operacional primeiro aumenta o tamanho do buffer de log para evitar saturações.
Não é necessário que o UMD implemente o suporte à pressão de retorno durante o progresso das entradas do buffer de log.
Carimbos de data/hora do buffer de log vazios ou repetidos
Em casos comuns, o Dxgkrnl espera que os carimbos de data/hora em entradas de log estejam aumentando monotonicamente. No entanto, há cenários em que os carimbos de data/hora das entradas de log subsequentes são zero ou iguais às entradas de log anteriores.
Por exemplo, em um cenário com adaptadores de vídeo vinculados, um dos adaptadores encadeados no LDA pode ignorar a operação de gravação de limite. Nesse caso, sua entrada de buffer de log tem um carimbo de data/hora igual a zero. O Dxgkrnl lida com esse caso. Dito isso, o Dxgkrnl nunca espera que o carimbo de data/hora de uma determinada entrada de log seja menor do que o da entrada de log anterior, ou seja, os carimbos de data/hora nunca podem retroceder.
Atualizando de forma síncrona o log de limite nativo
As gravações da GPU para atualizar o valor do limite e o buffer de log correspondente devem garantir que as gravações sejam totalmente propagadas antes da leitura da CPU. Esse requisito requer o uso de barreiras de memória. Por exemplo:
- Sinalizar limite (N): grava N como um novo valor atual
- Gravar entrada de LOG, incluindo carimbo de data/hora da GPU
- MemoryBarrier
- Incremento FirstFreeEntryIndex
- MemoryBarrier
- Interrupção de limite monitorado (N): lê o endereço "M" e compara o valor com N para decidir sobre a entrega da interrupção da CPU
É muito caro inserir duas barreiras em cada sinal da GPU, especialmente quando é provável que a verificação de interrupção condicional não seja satisfeita e nenhuma interrupção da CPU seja necessária. Como resultado, o design move o custo de inserção de uma das barreiras de memória da GPU (produtora) para a CPU (consumidora). O Dxgkrnl chama a função DxgkDdiUpdateNativeFenceLogs introduzida para fazer com que o KMD libere de forma síncrona as gravações de log de limite nativo pendentes sob demanda (semelhante a como o DxgkddiUpdateflipqueuelog foi introduzido para a liberação de log de fila de inversão de HW).
Para operações de GPU:
- Sinalizar limite (N): grava N como um novo valor atual
- Gravar entrada de LOG, incluindo o carimbo de data/hora da GPU
- Incremento FirstFreeEntryIndex
- MemoryBarrier => garante que o FirstFreeEntryIndex seja totalmente propagado
- Interrupção de limite monitorado (N): lê o endereço "M" e compara o valor com N para decidir sobre a entrega da interrupção
Para operações de CPU:
No identificador da interrupção sinalizada de limite nativo do Dxgkrnl (DISPATCH_IRQL):
- Para cada log HWQueue: lê FirstFreeEntryIndex e determina se novas entradas são gravadas.
- Para cada log HWQueue com novas entradas: chama DxgkDdiUpdateNativeFenceLogs e fornece os identificadores do kernel para esses HWQueues. Nessa DDI, o KMD insere uma barreira de memória para cada HWQueue determinado, garantindo que todas as gravações de entrada de log sejam confirmadas.
- O Dxgkrnl lê entradas de log para extrair o conteúdo de carimbo de data/hora.
Assim, desde que o hardware insira uma barreira de memória após as gravações no FirstFreeEntryIndex, o Dxgkrnl sempre chama o DDI do KMD, permitindo que ele insira uma barreira de memória antes que o Dxgkrnl leia qualquer entrada de log.
Requisitos de hardware futuros
A maioria dos hardwares da geração atual pode suportar apenas a gravação do identificador do kernel do objeto de limite sinalizado na interrupção sinalizada de limite nativo. Esse design é descrito anteriormente em Interrupção sinalizada de limite nativo. Nesse caso, o Dxgkrnl identifica o conteúdo da interrupção da seguinte maneira:
- O sistema operacional executa uma leitura (potencialmente através de PCI) do valor do limite.
- Sabendo qual limite foi sinalizado e o valor do limite, o sistema operacional ativa as esperas da CPU que estão aguardando nesse limite/valor.
- Separadamente, para o dispositivo pai desse limite, o sistema operacional verifica os buffers de log de todos os seus HWQueues. O sistema operacional, em seguida, lê as últimas entradas de buffer de log gravadas para determinar qual HWQueue fez o sinal e extrai a carga de carimbo de data/hora correspondente. Essa abordagem pode ler redundantemente alguns valores de limite no PCI.
Em plataformas futuras, o Dxgkrnl prefere obter uma matriz de identificadores HwQueue do kernel na interrupção sinalizada de limite nativo. Essa abordagem permite que o sistema operacional:
- Leia as entradas de buffer de log mais recentes para esse HwQueue. O dispositivo do usuário não é conhecido pelo identificador de interrupção, portanto, esse identificador HwQueue precisa ser um identificador de kernel.
- Verifique o buffer de log em busca de entradas de log que indiquem quais limites foram sinalizados e para quais valores. A leitura somente do buffer de log garante uma única leitura sobre o PCI em vez de ter que ler redundantemente os valores de limite e o buffer de log. Essa otimização será bem-sucedida desde que o buffer de log não tenha sido saturado (descartando as entradas que o Dxgkrnl nunca leu).
- Se o sistema operacional detectar que o buffer de log foi saturado, ele retornará ao caminho não otimizado que lê o valor ativo de cada limite do mesmo dispositivo. O desempenho é proporcional ao número de limites do dispositivo. Se o valor do limite estiver na memória de vídeo, essas leituras serão coerentes com o cache em todo o PCI.
- Sabendo quais limites foram sinalizados e os valores do limite, o sistema operacional ativa as esperas da CPU que estão esperando nesses limites/valores.
Interrupção sinalizada de limite nativo otimizada
Além das alterações descritas em Interrupção sinalizada de limite nativo, a seguinte alteração também é feita para dar suporte à abordagem otimizada:
- O limite OptimizedNativeFenceSignaledInterrupt é adicionado ao DXGK_VIDSCHCAPS.
Se suportado pelo hardware, em vez de preencher uma matriz de identificadores de limites que foram sinalizados, a GPU deve mencionar apenas o identificador do KMD do HWQueue que estava em execução quando a interrupção foi gerada. O Dxgkrnl verifica o buffer de log de limite para este HWQueue e lê todas as operações de limites que foram concluídas pela GPU desde a última atualização e desbloqueia todas as esperas da CPU correspondente. Se a GPU não puder determinar qual subconjunto de limites foi sinalizado, ela deverá especificar um identificador HWQueue NULL. Quando o Dxgkrnl vê um identificador HWQueue NULL, ele volta a verificar o buffer de log de todos os HWQueues nesse mecanismo para determinar quais limites foram sinalizados.
O suporte para essa otimização é opcional. O KMD deve definir o limite DXGK_VIDSCHCAPS:OptimizedNativeFenceSignaledInterrupt se ele for suportado pelo hardware. Se o limite OptimizedNativeFenceSignaledInterrupt não estiver definido, a GPU/ o KMD deverá seguir o comportamento descrito em Interrupção sinalizada de limite nativo.
Exemplo de interrupção sinalizada de limite nativo otimizada
HWQueueA: a GPU sinaliza para o limite F1, Valor V1,> grava na entrada de buffer de log E1 -> nenhuma interrupção necessária
HWQueueA: a GPU sinaliza para o limite F1, Valor V2,> grava na entrada de buffer de log E2 -> nenhuma interrupção necessária
HWQueueA: a GPU sinaliza para o limite F2, Valor V3,> grava na entrada de buffer de log E3 -> nenhuma interrupção necessária
HWQueueA: a GPU sinaliza para o limite F2, Valor V3,> grava na entrada de buffer de log E4 -> interrupção gerada
DXGKARGCB_NOTIFY_INTERRUPT_DATA FenceSignalISR = {}; FenceSignalISR.NodeOrdinal = 0; FenceSignalISR.EngineOrdinal = 0; FenceSignalISR.hHWQueue = A;O Dxgkrnl lê o buffer de log para HWQueueA. Ele lê as entradas de buffer de log E1, E2, E3, e E4 para observar os limites sinalizados F1 @ Valor V1, F1 @ Valor V2, F2 @ Valor V3, e F2 @ Valor V3, e desbloqueia todas as esperas que aguardam nesses limites e valores
Registro opcional e obrigatório
O suporte para log de limite nativo para DXGK_NATIVE_FENCE_LOG_TYPE_WAITS e DXGK_NATIVE_FENCE_LOG_TYPE_SIGNALS é obrigatório.
No futuro, outros tipos de log podem ser adicionados somente quando ferramentas como GPUView habilitam o log detalhado de ETW no sistema operacional. O sistema operacional deve informar o UMD e o KMD de quando o log detalhado está habilitado e desabilitado para que o log desses eventos detalhados seja habilitado seletivamente.