O Apache HBase é um aplicativo distribuído de armazenamento de colunas NoSQL baseado em Java, construído sobre o Hadoop Distributed File System (HDFS). Ele segue o modelo do Bigtable do Google e traz a maioria dos recursos do Bigtable para o ecossistema Hadoop.
O HBase é um sistema distribuído. De uma perspetiva do teorema CAP, ele é projetado para consistência e particionamento. Em termos de perfil de carga de trabalho, ele foi projetado para servir como um armazenamento de dados para aplicativos com uso intensivo de dados que exigem leituras e gravações aleatórias de baixa latência e quase em tempo real.
Este artigo discute componentes e princípios que desempenham um papel no planejamento e na criação de um cluster HBase no Azure para uma migração. O debate é especialmente pertinente para estes objetivos de migração:
- Apache HBase no Azure HDInsight
- IaaS do Azure fazendo um lift and shift para máquinas virtuais (VMs)
- Azure Cosmos DB.
Apache, Apache Spark®, Apache Hadoop®, Apache HBase, Apache Ranger®, Apache ZooKeeper®, Apache Sqoop®, Apache Kafka® e o logotipo flame são marcas registradas ou marcas comerciais da Apache Software Foundation nos Estados Unidos e/ou em outros países. Nenhum endosso da Apache Software Foundation está implícito no uso dessas marcas.
Componentes, conceitos principais e arquitetura do HBase
O HBase segue um modelo de líder/seguidor. Esta seção discute os componentes e nós que estão em uma implantação do HBase.
Componentes
Os principais componentes do HBase são o servidor Master, os nós do ZooKeeper e os RegionServers.
Servidor mestre
O servidor mestre é responsável por todas as operações de metadados para um cluster HBase. Isso inclui criação e exclusão de objetos, monitoramento de RegionServers e outras operações. Normalmente, há dois servidores Master implantados para alta disponibilidade.
Nós do ZooKeeper
O ZooKeeper é um serviço centralizado para manter informações de configuração, nomear, fornecer sincronização distribuída e fornecer serviços de grupo. Esses recursos são necessários para a coordenação em um ambiente de aplicativo distribuído, como o HBase.
RegiãoServidores
RegionServers é responsável por servir e gerenciar regiões ou partições. Um RegionServer faz a maior parte do processamento de uma solicitação de leitura ou gravação do cliente. Em uma implantação distribuída do HBase, um RegionServer é executado em um HDFS DataNode.
Conceitos-chave
É importante que você compreenda os principais conceitos da arquitetura e do modelo de dados do HBase para otimizar uma implantação do HBase.
Modelo de dados
- Namespace: um agrupamento lógico de tabelas, como um banco de dados em um sistema de banco de dados relacional. Os namespaces possibilitam vários recursos relacionados à multilocação.
- Tabela: um agrupamento ou coleção de linhas. As tabelas são armazenadas em regiões ou partições espalhadas por RegionServers.
- Linha: uma linha consiste em uma chave de linha e um agrupamento de colunas chamado família de colunas. As linhas são classificadas e armazenadas com base na chave de linha.
- Família de colunas: um agrupamento de colunas que têm o mesmo prefixo.
- Célula: um local de dados identificado exclusivamente por uma tupla {linha, coluna, versão}.
- Operações de modelo de dados: há quatro operações de modelo de dados principais:
- Obter retorna atributos para uma linha especificada.
- Colocar adiciona novas linhas a uma tabela ou atualiza linhas existentes.
- A verificação permite a iteração em várias linhas para atributos especificados.
- Excluir remove uma linha de uma tabela. Um marcador, chamado lápide, é colocado nos registros para marcá-los para exclusão. As lápides e linhas excluídas são removidas durante as principais compactações.
O diagrama a seguir ilustra esses conceitos.

Caminho de escrita
O HBase usa uma combinação de estruturas de dados que residem na memória e no armazenamento persistente para fornecer gravações rápidas. Quando ocorre uma gravação, os dados são gravados primeiro em um log write-ahead (WAL), que é uma estrutura de dados armazenada no armazenamento persistente. A função da WAL é controlar as alterações para que os logs possam ser repetidos em caso de falha do servidor. O WAL é usado apenas para resiliência. Depois que os dados são confirmados com a WAL, eles são gravados no MemStore, que é uma estrutura de dados na memória. Nesta fase, uma escrita está completa.
Para persistência de dados de longo prazo, o HBase usa uma estrutura de dados chamada arquivo HBase (HFile). Um HFile é armazenado no HDFS. Dependendo do tamanho do MemStore e do intervalo de liberação de dados, os dados do MemStore são gravados em um HFile. Para obter informações sobre o formato de um HFile, consulte o Apêndice G: formato HFile.
O diagrama a seguir mostra as etapas de uma operação de gravação.

Para resumir, os componentes no caminho de gravação são:
- A WAL é uma estrutura de dados armazenada em armazenamento persistente.
- MemStore é uma estrutura de dados na memória, on-heap.
- HFile é um arquivo HBase que é armazenado no HDFS e usado para persistência de dados.
Ler caminho
O HBase usa várias estruturas de dados para fornecer leituras aleatórias e sequenciais rápidas. O HBase tenta atender às solicitações de leitura dos dados armazenados em cache no BlockCache e, na falta disso, do MemStore. Ambos são armazenados em heap. Se os dados não estiverem disponíveis no cache, eles serão buscados em um HFile e armazenados em cache no BlockCache.
O diagrama a seguir mostra as etapas de uma operação de leitura.

Nota
Para situações que exigem baixa latência de leitura, há uma opção para armazenar dados em cache no BucketCache, que é uma estrutura de dados na memória e geralmente está desmontada. Os dados armazenados no BucketCache não precisam ser armazenados no BlockCache, portanto, a atividade de heap é reduzida e as leituras são mais rápidas. Para obter mais informações, consulte BucketCache.
Caminhos de leitura e gravação fora da pilha
Para reduzir as latências de leitura e gravação, as versões 2.x e posteriores do HBase têm um pool de buffers off-heap usados para gravação e leitura. O fluxo de trabalho para gravar e ler dados faz o seu melhor para evitar alocações de memória no heap para reduzir a quantidade de trabalho que a coleta de lixo deve fazer para concluir leituras e gravações. Os buffers devem ser otimizados, pois seu uso depende muito de fatores como o número de regiões e RegionServers, o tamanho da memória e o armazenamento premium conectado ao cluster HBase no Azure. Esses parâmetros não são necessariamente os mesmos no sistema migrado e no sistema de origem.
Desafios de executar o HBase no local
Esses desafios comuns das implantações locais do HBase podem ser motivos para querer ou precisar migrar o HBase para a nuvem:
- Alcançar escalabilidade, o que pode ser difícil dependendo do hardware e da capacidade do data center.
- Ter que substituir hardware ou migrar aplicativos devido ao fim do suporte para infraestrutura envelhecida.
- Alcançar alta disponibilidade e recuperação de desastres, por motivos como:
- Falta de sites de datacenter
- Falha do cluster HBase quando o Master, um único ponto de falha, falha.
- Alcançar alta produtividade, porque um ecossistema Hadoop local é complexo, difícil de gerenciar e propenso a falhas.
- A falta de ferramentas nativas para:
- Transparência de custos
- Monitorização
- DevOps
- Automatização
Considerações para uma migração do HBase
- Se a migração de infraestrutura como serviço (IaaS) do HBase for sua primeira carga de trabalho no Azure, recomendamos que você invista o tempo e o esforço necessários para criar uma base sólida para hospedar cargas de trabalho no Azure. Para fazer isso, use as diretrizes de zona de aterrissagem em escala empresarial do Cloud Adoption Framework. A escala empresarial é uma abordagem arquitetónica e uma implementação de referência que torna possível construir e operacionalizar eficazmente zonas de aterragem no Azure, em escala. Para obter mais informações, consulte O que é uma zona de aterrissagem do Azure?.
- É altamente recomendável que todas as cargas de trabalho executadas no Azure sejam projetadas e implantadas de acordo com o Well-Architected Framework, que é um conjunto de princípios orientadores que você pode usar para melhorar a qualidade de uma carga de trabalho. A estrutura consiste em cinco pilares de excelência em arquitetura: Otimização de Custos, Excelência Operacional, Eficiência de Desempenho, Confiabilidade e Segurança.
- Ao projetar e escolher a computação e o armazenamento do Azure, considere os limites de serviço. A computação e o armazenamento têm limites que podem afetar o dimensionamento da infraestrutura para um aplicativo com uso intensivo de dados, como o HBase. Para obter mais informações, veja Subscrição do Azure e limites, quotas e restrições do serviço.
- Uma assinatura deve ser usada como uma unidade de escala. Você adiciona mais instâncias de um serviço para expandir conforme necessário. Partindo dos princípios de design em escala empresarial do Cloud Adoption Framework, use a assinatura como uma unidade de gerenciamento e escala. Alinhe as assinaturas às necessidades e prioridades de negócios e apoie as áreas de negócios e os proprietários de portfólio para incentivar a migração de aplicativos atuais e o desenvolvimento de novos.
- Uma implantação do HBase no Azure pode usar vários tipos de armazenamento para cache e armazenamento persistente. Avalie as opções ao implantar soluções HBase no Azure.
- Depois de migrar para a IaaS do Azure, você precisa otimizar o desempenho e dimensionar corretamente a infraestrutura. Há muitos fatores que afetam o desempenho, incluindo o tamanho da infraestrutura, os tipos de armazenamento e a distribuição das regiões. Mesmo que você minimize as alterações de aplicativos ao migrar, um ambiente do Azure é fundamentalmente diferente de um ambiente local. Há recursos e limites do Azure a serem considerados para atender aos requisitos de desempenho.
Abordagens migratórias
O Azure tem vários destinos de aterrissagem para o Apache HBase. Dependendo dos requisitos e dos recursos do produto, você pode escolher entre IaaS do Azure (lift and shift para VMs), HBase no HDInsight e Azure Cosmos DB (API NoSQL).
Aqui está um fluxograma de decisão para selecionar um ambiente de destino:

Essas metas são discutidas nas seguintes seções:
- Migrar para IaaS do Azure
- Migrar para o HBase no HDInsight
- Migrar para o Azure Cosmos DB (API NoSQL)
Migrar para IaaS do Azure
A migração do HBase para o Azure IaaS requer as seguintes atividades:
- Avaliar a implantação existente e decidir sobre os requisitos
- Considere as opções de VM
- Considere as opções de armazenamento
- Migrar dados
- Estabeleça segurança
- Monitorar a implantação do HBase
Avaliar a implantação existente e decidir sobre os requisitos
A tabela a seguir fornece orientações sobre como avaliar a implantação existente do HBase e estabelecer um conjunto de requisitos para uma migração do HBase para o Azure.
| Camada | Characteristic | Fundo |
|---|---|---|
| Infraestruturas | Número de servidores para cada tipo de função: HBase Master, RegionServer, nó ZooKeeper |
Entenda a escala e o design da solução existente. |
| Número de núcleos por servidor | Use o lscpu comando ou cat /proc/cpuinfo para listar núcleos por servidor. |
|
| Memória por servidor | No Linux, use free -mg ou cat /proc/meminfo para relatar a memória em cada servidor. |
|
| O ambiente existente é virtualizado ou implantado em servidores bare-metal? | Essas informações são usadas para dimensionar e entender as características de desempenho do ambiente HBase local. | |
| Configuração de rede | Entenda a largura de banda de rede que cada VM pode suportar e se uma configuração de NIC especial é usada para suportar alta largura de banda entre servidores HBase. Use os seguintes comandos para extrair detalhes da configuração de rede VM: ifconfig -a ou ethtool <name of the interface>. |
|
| Configuração do armazenamento | Qual é o tamanho total dos dados, incluindo réplicas? Normalmente, a configuração padrão do HDFS replica dados três vezes. A CLI HDFS pode ser usada para extrair o tamanho total dos dados persistentes pelo HBase: hdfs dfs -du -h hdfs://<data node address>/HBaseAlém disso, estabeleça metas de desempenho de armazenamento (IOPS e taxa de transferência). Essas informações são usadas para provisionar armazenamento e entender o nível de taxa de transferência necessário para dar suporte à implantação do Azure. |
|
| Sistema Operativo | Versão e tipo de distribuição | O comando a seguir imprime detalhes da distribuição e versão do Linux:uname -a |
| Parâmetros do kernel | Veja a nota que segue esta tabela. | |
| Aplicação | As versões das distribuições HBase e Hadoop, como Hortonworks e Cloudera, que estão em uso | A distribuição é geralmente uma das seguintes: HortonWorks, Cloudera, MapR ou uma versão de código aberto do Hadoop e HBase. Para descobrir as versões do HBase e do Hadoop, use os seguintes comandos: hbase version e hdfs version. |
| Informações específicas do HBase: o número de tabelas, os metadados de cada tabela (regiões, família de colunas) | Você pode extrair informações relacionadas à implantação do HBase usando a interface do usuário do Ambari. Se isso não estiver disponível, você pode usar a CLI:scan 'hbase:meta' {FILTER=>"PrefixFilter('tableName')", COLUMNS=>['info:regioninfo']}}Para listar todas as regiões associadas a uma determinada tabela, use: list_regions '<table name>' |
|
| Versão JAVA (JDK) | java -version} |
|
| Configuração da coleta de lixo do HBase | Qual estratégia de coleta de lixo é usada? Os mais comuns são varredura de marcas simultânea (CMS) e lixo primeiro (G1). A estratégia é especificada no arquivo de hbase-env.sh configuração. Pesquisas recentes mostram que o G1 é mais eficiente para grandes tamanhos de heap. |
|
| Segurança e administração | As formas como o HBase é acessado | Como os usuários acessam os dados no HBase? É usando APIs ou diretamente usando o shell do HBase? Como os aplicativos consomem dados? Como os dados são gravados no HBase e a que distância está o HBase? Está no mesmo data center? |
| Aprovisionamento de utilizadores | Como os usuários são autenticados e autorizados? As possibilidades incluem: • Ranger • Botão • Kerberos |
|
| Encriptação | Existe algum requisito para criptografar dados? Nos transportes? Em repouso? Que soluções de encriptação são utilizadas? | |
| Tokenização | Existe um requisito para tokenizar dados? Se sim, como? Os aplicativos de tokenização populares incluem Protegrity e Vormetric. | |
| Conformidade | Existem requisitos regulatórios especiais aplicáveis às cargas de trabalho do HBase, como CI-DSS ou HIPAA? | |
| Políticas de gerenciamento para chaves, certificados e segredos | Quais políticas e ferramentas são usadas para gerenciar segredos? | |
| Recuperação de elevada disponibilidade e após desastre | O que é o contrato de nível de serviço (SLA) e quais são os objetivos de ponto de recuperação (RPO) e os objetivos de tempo de recuperação (RTO) da implantação do HBase de origem? | As respostas afetam o design da implantação de destino no Azure. Por exemplo, deve haver um hot standby ou uma implantação regional ativa-ativa? |
| Quais são as estratégias de continuidade de negócios (BC) e recuperação de dados (DR) para cargas de trabalho do HBase? | Descreva as estratégias de BC e DR e o impacto se o HBase não estiver disponível. | |
| Dados | Tamanho e crescimento dos dados | Quantos dados são migrados para o HBase inicialmente? Qual é o crescimento esperado após 6, 12 e 18 meses? Essas informações são usadas para o planejamento de capacidade e para dimensionar o cluster. Eventualmente, ele também é usado para otimizar os custos de implantação. |
| Ingestão | Como os dados são gravados no HBase? | |
| Consumo | Como são utilizados os dados da HBase? É usando APIs ou por um mecanismo de computação como o HDInsight Spark ou o Databricks Spark? | |
| Padrão de acesso | O tráfego no HBase é pesado em leitura ou gravação? Isso afeta o ajuste fino dos parâmetros de configuração do HBase definidos nos hbase-site.xml arquivos e hdfs-site.xml . |
Nota
Parâmetros no nível do kernel podem ter sido aplicados para melhorar o desempenho do HBase no sistema de origem. Como as características de desempenho do sistema migrado não são as mesmas, recomendamos não alterar os parâmetros padrão para corresponder ao sistema de origem, exceto seguir as recomendações do fornecedor do sistema operacional ou do aplicativo. Na maioria dos casos, é melhor ajustar os parâmetros do kernel durante a fase de otimização de desempenho da migração.
Parâmetros de memória e dispositivo de bloco Linuxcat /sys/kernel/mm/transparent_hugepage/enabledcat /sys/kernel/mm/transparent_hugepage/defragcat /sys/block/sda/queue/schedulercat /sys/class/block/sda/queue/rotationalcat /sys/class/block/sda/queue/read_ahead_kbcat /proc/sys/vm/zone_reclaim_mode
Parâmetros da pilha de rede Linuxsudo sysctl -a \ grep -i "net.core.rmem_max\|net.core.wmem_max\|net.core.rmem_default\|net.core.wmem_default\|net.core.optmem_max\|net.ipv4.tcp_rmem\|net.ipv4.tcp_wmem"|
Existem várias soluções de parceiros que podem ajudar na avaliação. O Unravel tem soluções que podem ajudá-lo a acelerar a avaliação de migrações de dados para o Azure.
Considere as opções de VM
As Máquinas Virtuais do Azure são um dos vários tipos de recursos de computação escaláveis e sob demanda que o Azure oferece. Normalmente, você escolhe uma VM quando precisa de mais controle sobre o ambiente de computação do que outras opções oferecem.
Ao projetar sua migração e selecionar VMs, considere o seguinte:
- Os nomes dos recursos da aplicação
- A localização onde os recursos são armazenados
- O tamanho da VM
- O número máximo de VMs que podem ser criadas
- O sistema operativo que a VM executa
- A configuração da VM depois de iniciar
- Os recursos relacionados que a VM precisa
Para obter mais informações, consulte O que preciso pensar antes de criar uma VM?.
As famílias de VMs do Azure são otimizadas para atender a diferentes casos de uso e fornecer um equilíbrio de computação (núcleos virtuais) e memória.
| Type | Tamanho | Description |
|---|---|---|
| Nível de Entrada | A, Av2 | As VMs da série A têm desempenho de CPU e configurações de memória que são mais adequadas para cargas de trabalho de nível de entrada, como desenvolvimento e teste. Eles são uma opção de baixo custo para começar a usar o Azure. |
| Fins Gerais | D, DSv2, Dv2 | Essas VMs têm relações CPU-memória balanceadas. Eles são ideais para testes e desenvolvimento, para bancos de dados pequenos e médios e para servidores Web com tráfego baixo a médio. |
| Computação otimizada | F | Essas VMs têm uma alta relação CPU/memória. Eles são bons para servidores Web de tráfego médio, dispositivos de rede, processos em lote e servidores de aplicativos. |
| Memória otimizada | Esv3, Ev3 | Essas VMs têm uma alta relação memória/CPU. Eles são bons para servidores de banco de dados relacionais, caches médios a grandes e análises na memória. |
Para obter mais informações, consulte Máquinas virtuais no Azure.
O HBase foi projetado para usar memória e armazenamento premium (como SSDs) para otimizar o desempenho do banco de dados.
- Ele vem com recursos como o BucketCache, que pode melhorar significativamente o desempenho de leitura. O BucketCache é armazenado fora da pilha, por isso recomendamos VMs com maiores proporções de memória para CPU.
- O caminho de gravação do HBase grava alterações em um WAL, que é uma estrutura de dados que persiste em uma mídia de armazenamento. Armazenar a WAL num meio de armazenamento rápido, como SSDs, melhora o desempenho de gravação.
- O HBase foi projetado para ser dimensionado à medida que os requisitos de desempenho e armazenamento aumentam.
Para obter mais informações sobre como dimensionar VMs do Azure, consulte Tamanhos para máquinas virtuais no Azure.
Com base em considerações sobre as necessidades de computação e memória, recomendamos o uso dos seguintes tipos de família de computação do Azure para os vários tipos de nó HBase:
- HBase Master – Para implantações corporativas, recomendamos pelo menos dois Masters para alta disponibilidade. Para um cluster HBase grande, uma VM DS5_v2 Azure com 16 CPUs virtuais (vCPUs) e 56 GiB de memória deve ser suficiente para a maioria das implantações. Para clusters de tamanho médio, recomendamos pelo menos 8 vCPUs e 20 a 30 GiB de memória.
- HDFS NameNode – Recomendamos hospedar HDFS NameNodes em VMs diferentes daquelas que os Masters usam. Dois NameNodes devem ser implantados para alta disponibilidade. Para os Masters, recomendamos DS5_v2 VMs para grandes clusters de nível de produção.
- HBase RegionServer – Recomendamos o uso de VMs do Azure com uma alta relação memória/CPU. O HBase tem vários recursos que usam memória para melhorar os tempos de leitura e gravação. VMs como DS14_v2 ou DS15_v2 são bons pontos de partida. O HBase foi projetado para expandir adicionando RegionServers para melhorar o desempenho.
- ZooKeeper – O HBase conta com o ZooKeeper para as operações. Uma VM do Azure com 4 a 8 vCPUs e memória de 4 a 8 GiB é um bom ponto de partida. Verifique se há armazenamento local disponível. Os nós do ZooKeeper devem ser implantados em seu próprio conjunto de VMs.
Considere as opções de armazenamento
O Azure oferece várias opções de armazenamento que são adequadas para hospedar uma implantação IaaS do HBase. O fluxograma a seguir usa recursos de várias opções para selecionar uma opção de armazenamento. Cada opção de armazenamento no Azure tem desempenho, disponibilidade e metas de custo diferentes.

Consulte estes artigos para obter informações adicionais:
Em um modelo de armazenamento híbrido, usamos uma combinação de armazenamento local e armazenamento remoto para encontrar um equilíbrio entre desempenho e custo. O padrão mais comum é colocar o HBase WAL, que está no caminho de gravação, no Disco Gerenciado do SSD Premium do Azure conectado localmente. Os dados de longo prazo ou HFiles são armazenados em SSD Premium ou SSD padrão, dependendo dos objetivos de custo e desempenho.
Nota
A versão de código aberto do Apache Ranger não pode aplicar políticas e controle de acesso no nível de arquivo para o Armazenamento do Azure (Armazenamento de Blob do Azure ou Armazenamento do Azure Data Lake). Esta capacidade é suportada pela versão Ranger que acompanha a Cloudera Data Platform (CDP).
Há dois fatores-chave que influenciam o dimensionamento do armazenamento do HBase: volume de dados e taxa de transferência de leituras e gravações. Esses fatores também afetam a escolha do tamanho e dos números da VM do Azure e do Armazenamento do Azure (Managed Disk ou Data Lake Storage).
Volume de dados
Estes são os dados que devem ser persistidos na HBase. Os dados são mantidos no armazenamento subjacente. Quando nos referimos ao volume de dados, para fins de dimensionamento e planejamento, o volume inclui os dados brutos e a replicação 3x. O tamanho total do armazenamento é a métrica que usamos para gerar volume.
Taxa de transferência de leituras e gravações
Esta é a taxa na qual o HBase grava e lê dados. IOPS e tamanho de E/S são as duas métricas que impulsionam isso.
Se você estiver planejando uma implantação greenfield do HBase em IaaS do Azure e não houver nenhum ponto de referência em termos de implantações existentes, nossa recomendação é seguir o seguinte dimensionamento e, em seguida, adicionar RegionServers à medida que o volume de dados ou a necessidade de uma taxa de transferência mais alta cresce. As VMs das séries D e Es são adequadas para um HBase RegionServer. Para os nós HBase Master e ZooKeeper, recomendamos o uso de VMs menores da série Ds.
Para uma melhor precisão de dimensionamento e para estabelecer uma linha de base de desempenho, recomendamos que você execute testes no Azure IaaS usando o conjunto de dados, o modelo e o padrão de carga de trabalho do HBase. Se não for possível mover os dados, recomendamos o uso de ferramentas de benchmarking, como o Yahoo! Cloud Serving Benchmark (YCSB) para gerar dados sintéticos e simular tráfego de E/S sequencial e aleatório. A intenção deste exercício é obter uma compreensão do nível de desempenho esperado usando uma combinação de computação do Azure e SSD Premium. Os testes devem incluir padrões de carga de trabalho diária e casos especiais, como cargas de trabalho que podem causar um pico no uso de recursos, como atividades de fim de mês e fim de ano. Por exemplo, um varejista que usa o HBase observa picos no uso de recursos durante períodos de férias, enquanto um provedor de serviços financeiros observa picos durante os principais períodos financeiros.
As entradas de atividades de avaliação e linhas de base de desempenho devem fornecer uma visão bastante precisa do dimensionamento na IaaS do Azure. Devido à natureza das cargas de trabalho, há espaço para otimizar as operações dimensionando ou dimensionando clusters após a entrada em operação. Recomendamos que você se familiarize com várias técnicas de otimização de custos para otimizar custos e operações.
Migrar os dados
Nota
Recomendamos não copiar diretamente HFiles para migrar arquivos de dados de uma implantação do HBase para outra. Em vez disso, use um dos recursos prontos para uso do HBase.
A tabela a seguir mostra abordagens de migração de dados para várias situações.
| Padrão | Abordagem da migração | Considerações |
|---|---|---|
| Cenários de carregamento em massa em que os dados de origem não estão sendo lidos de uma instância do HBase. Por exemplo, os dados de origem estão em um formato de arquivo, como CSV, TSV ou Parquet, ou estão em um banco de dados ou formato proprietário. |
Crie um pipeline usando ferramentas como WANDisco e Databricks para ler os dados de origem e gravá-los no HBase. Se os dados estiverem em um sistema de arquivos ou no HDFS, use ferramentas como WANDisco, HDInsight Spark ou Databricks Spark para ler da origem e gravar no HBase no Azure. Em um alto nível, pipelines de migração podem ser criados — um por tabela de destino no HBase — que extraem dados da origem e os gravam primeiro no Azure HDFS. Em seguida, um pipeline separado pode ser criado para ler do Azure HDFS e gravar no Azure HBase. |
Necessidade de infraestrutura separada para o tempo de execução da ferramenta de migração. Tratamento de requisitos de criptografia e tokenização durante a migração de dados. Latência de rede entre origem e destino (Azure HBase). |
| A origem é uma instância do HBase, mas não é a mesma versão do HBase do HBase de destino do Azure. | Como a origem também é um armazenamento de dados do HBase, considere opções diretas de migração de dados de cluster para cluster do HBase, como: • HBase CopyTable • Faísca no HDInsight ou Databricks Spark • Utilitário de exportação HBase e utilitário de importação HBase • A ferramenta HashTable/SyncTable Nota - CopyTable suporta recursos de cópia de tabela delta e completa. |
As mesmas considerações que para cargas em massa, além de algumas relacionadas a ferramentas de migrações específicas. Para o HBase CopyTable, considere as versões do HBase nas implantações de origem e de destino. Os clusters devem estar online tanto para a origem quanto para o destino. Recursos adicionais são necessários no lado da origem para dar suporte ao tráfego de leitura adicional na instância do HBase de origem. O recurso CopyTable, por padrão, copia apenas a versão mais recente de uma célula de linha. Ele também copia todas as células dentro de um intervalo de tempo especificado. Pode haver alterações no HBase de origem enquanto o CopyTable é executado. Quando isso acontece, as alterações são completamente copiadas ou completamente ignoradas. O Spark no HDInsight e o Databricks Spark exigem recursos adicionais ou um cluster separado para migrar dados, mas é uma abordagem testada e comprovada. O Utilitário de Exportação do HBase, por padrão, sempre copia a versão mais recente de uma célula para o destino do HBbase. HashTable/SyncTable é mais eficiente do que o recurso CopyTable. |
| A origem é um banco de dados do HBase com a mesma versão do HBase do destino do HBase. | As mesmas opções que são usadas quando as versões diferem HBase Snapshots |
As considerações que já foram mencionadas para o caso em que as versões diferem. Para HBase Snapshots, as considerações são as seguintes. • Snapshots não cria uma cópia dos dados, mas cria uma referência de volta ao HFiles. Os HFiles referenciados são arquivados separadamente caso a compactação seja acionada na tabela pai referenciada em um instantâneo. • A pegada nos HBases de origem e de destino quando uma restauração de snapshot é acionada. • Manter a fonte de dados e os HBases de destino sincronizados durante a migração e, em seguida, planejar a substituição final. • Latência de rede entre a origem e o destino. |
Aqui está um fluxograma de decisão para ajudá-lo a escolher técnicas de migração de dados ao migrar o HBase para o Azure:

Outras leituras:
- Carregamento em massa (Apache HBase Reference Guide)
- Importar (Apache HBase Reference Guide)
- CopyTable (Guia de Referência do Apache HBase)
- HashTable/SyncTable (Guia de Referência do Apache HBase)
- HBase Snapshots (Apache HBase Reference Guide)
- Core (SQL) API
- Tutorial: Usar a ferramenta de migração de dados para migrar seus dados para o Azure Cosmos DB
- Copiar dados do HBase usando o Azure Data Factory ou o Synapse Analytics
Estabeleça segurança
Para que um cluster HBase funcione, ele deve ser capaz de se comunicar com outras VMs no cluster. Isso inclui VMs que hospedam Master, RegionServers e ZooKeeper.
Há várias maneiras de tornar possível que os servidores se autentiquem uns aos outros sem problemas. Os padrões mais comuns são:
- Servidores Linux Kerberizados que ingressaram no domínio em um controlador de domínio do Windows
- Um ambiente Linux Kerberizado que usa os Serviços de Domínio Microsoft Entra (Serviços de Domínio Microsoft Entra)
- Um controlador de domínio MIT Kerberos autônomo
- Autorização usando o Apache Ranger
Servidores Linux Kerberizados associados a um controlador de domínio do Windows
Os servidores Linux que hospedam o Apache Hadoop são associados a um domínio do Ative Directory. Nesta configuração, vemos que não há necessidade de ter um Kerberos hospedado separadamente, pois esse recurso fica dentro de um controlador de domínio do Windows.
Considerações:
- Localização do controlador de domínio.
- Funções atribuídas ao controlador de domínio.
Se o controlador de domínio estiver localizado no local ou fora de uma região do Azure ou em uma nuvem que não seja do Azure, a latência deve ser considerada para operações que exigem interação com o controlador de domínio. Uma opção é hospedar um segundo controlador de domínio no Azure. O controlador de domínio baseado no Azure é usado para todos os cenários de autenticação e autorização para cargas de trabalho executadas no Azure. Recomendamos não atribuir funções de mestres de operações aos controladores de domínio implantados no Azure. Nesse cenário, o controlador de domínio primário é hospedado localmente.
Um ambiente Linux Kerberizado que usa os Serviços de Domínio Microsoft Entra (Serviços de Domínio Microsoft Entra)
Os Serviços de Domínio Microsoft Entra fornecem serviços de domínio gerenciados, como ingresso no domínio, política de grupo, protocolo LDAP (lightweight directory access protocol) e autenticação Kerberos e NTLM. Você pode usar os Serviços de Domínio Microsoft Entra sem a necessidade de implantar, gerenciar e corrigir controladores de domínio na nuvem.
Considerações:
- Disponibilidade regional dos Serviços de Domínio Microsoft Entra
- Requisitos de rede para os Serviços de Domínio Microsoft Entra
- SLA de alta disponibilidade, recuperação de desastres e tempo de atividade para os Serviços de Domínio Microsoft Entra
Um controlador de domínio MIT Kerberos autônomo
Há algumas implantações do Hadoop que usam um controlador de domínio Kerberos autônomo, como o controlador de domínio MIT Kerberos, que é implantado em um conjunto separado de VMs do Azure para alta disponibilidade. Para obter informações sobre a implantação em servidores Linux, consulte Instalando KDCs.
Considerações para a implantação de um controlador de domínio MIT Kerberos:
- Gerenciando o controlador
- Recuperação de elevada disponibilidade e após desastre
- Diretrizes do Well-Architected Framework
Autorização usando o Apache Ranger
O Apache Ranger oferece segurança abrangente em todo o ecossistema Apache Hadoop. No contexto do Apache HBase, o Ranger é usado para criar e implantar a autorização baseada em políticas.
Monitorar a implantação do HBase
Para uma migração de elevação e mudança para IaaS do Azure, você pode usar as mesmas técnicas de monitoramento usadas no sistema de origem. Para outras migrações, há várias opções disponíveis para monitorar uma pilha completa do HBase na IaaS do Azure:
- Apache Ambari para monitorar a pilha Hadoop e HBase
- Monitoramento de Java Management Extensions (JMX) e Azure Monitor
- Registro e métricas de infraestrutura (VM, discos de armazenamento e rede)
Apache Ambari para monitorar a pilha Hadoop e HBase
Apache Ambari é um projeto para gerenciar aplicativos distribuídos, como Hadoop e HBase. Ele usa o Ambari Metrics System para fornecer métricas em clusters gerenciados pela Ambari. O Ambari pode relatar métricas específicas do HBase, como carga de cluster, uso de rede, uso de memória e heap do HBase Master. Os clusters gerenciados pelo Ambari são fornecidos com painéis para monitorar clusters.
Para obter mais informações, consulte Apache Ambari. Para obter orientações detalhadas sobre a implantação de clusters Hadoop e HBase gerenciados pelo Ambari, consulte 3. Opções de instalação.
Monitoramento de Java Management Extensions (JMX) e Azure Monitor
Os processos HBase e Hadoop são executados em uma máquina virtual Java (JVM). Uma JVM tem instrumentação integrada para fornecer dados de monitoramento por meio da API Java Management Extensions (JMX). Você pode instrumentar aplicativos para fornecer dados por meio da API JMX.
Além de exportar métricas do HBase para as opções de saída padrão suportadas pelo pacote de métricas do Hadoop, você também pode exportar por meio da API JMX. Isso torna possível visualizar estatísticas do HBase no JConsole e em outros clientes JMX.
Você pode usar um agente do Log Analytics para capturar fontes de dados JSON personalizadas e armazenar a saída no Log Analytics para relatórios pelo Azure Monitor:
- Após a implantação dos servidores Linux, é possível instalar e configurar o agente do Log Analytics para Linux. Para obter mais informações, consulte Monitorar máquinas virtuais com o Azure Monitor.
- Configure o agente do Log Analytics para coletar dados JSON personalizados. Muitos endpoints JMX fornecem JSON que pode ser coletado e analisado usando vários plug-ins FluentD.
- Aqui está um exemplo de como configurar plug-ins de entrada e saída para coletar métricas para gravar em WALs do HBase RegionServer.
<source>
type exec
command 'curl -XGET http://<regionServerName>:16030/jmx?qry=Hadoop:service=hbase,name=RegionServer,sub=WAL'
format json
tag oms.api.metrics_regionserver
run_interval 1m
</source>
<filter oms.api.metrics_regionserver>
type filter_flatten
select record['beans'][0]
</filter>
<match oms.api.metrics*>
type out_oms_api
log_level info
buffer_chunk_limit 5m
buffer_type file
buffer_path /var/opt/microsoft/omsagent/state/out_oms_api*.buffer
buffer_queue_limit 10
flush_interval 20s
retry_limit 10
retry_wait 5s
max_retry_wait 5m
compress true
</match>
Usando o exemplo acima, você pode criar plugins de entrada e saída para a lista abaixo. A lista contém pontos de extremidade JMX que você pode consultar para extrair métricas para HBase Master e RegionServer.
curl -XGET http://<region_server>:16030/jmx?qry=Hadoop:service=hbase,name=RegionServer,sub=Server
curl -XGET http://<region_server>:16030/jmx?qry=Hadoop:service=hbase,name=RegionServer,sub=Replication
curl -XGET http://<rest_server>:8085/jmx?qry=Hadoop:service=hbase,name=REST
curl -XGET http://<rest_server>:8085/jmx?qry=Hadoop:service=hbase,name=JvmMetrics
curl -XGET http://<region_server>:16030/jmx?qry=Hadoop:service=hbase,name=RegionServer,sub=WAL
curl -XGET http://<region_server>:16030/jmx?qry=Hadoop:service=hbase,name=RegionServer,sub=IPC
curl -XGET http://<region_server>:16030/jmx?qry=Hadoop:service=hbase,name=JvmMetrics
curl -XGET http://<region_server>:16030/jmx?qry=java.lang:type=OperatingSystem
curl -XGET http://<HBase_master>:16010/jmx?qry=Hadoop:service=hbase,name=Master,sub=AssignmentManger
curl -XGET http://<HBase_master>:16010/jmx?qry=Hadoop:service=hbase,name=Master,sub=IPC
curl -XGET http://<HBase_master>:16010/jmx?qry=java.lang:type=OperatingSystem
curl -XGET http://<HBase_master>:16010/jmx?qry=Hadoop:service=hbase,name=Master,sub=Balancer
curl -XGET http://<HBase_master>:16010/jmx?qry=Hadoop:service=hbase,name=JvmMetrics
curl -XGET http://<HBase_master>:16010/jmx?qry=Hadoop:service=hbase,name=Master,sub=Server
curl -XGET http://<HBase_master>:16010/jmx?qry=Hadoop:service=hbase,name=Master,sub=FileSystem
Depois de configurada, uma fonte aparece na folha Logs personalizados. No trecho acima, usamos o nome oms.api.metrics_regionservers para a entrada. O Log Analytics usa o seguinte formato para exibir o nome da tabela personalizada com um suffix_CL.
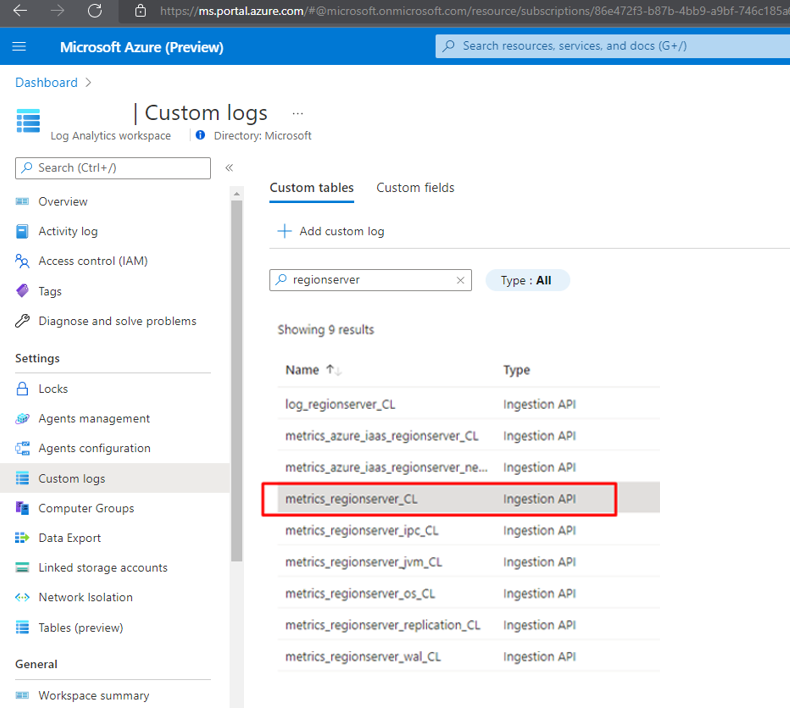
Registro e métricas de infraestrutura (VM, discos de armazenamento e rede)
Nota
Para uma migração do HBase de uma implantação de nuvem que não seja do Azure que usa uma solução de monitoramento nativa, recomendamos usar a solução de monitoramento nativa do Azure no novo ambiente. O monitoramento de aplicativos e infraestrutura juntos fornece um quadro completo.
As distribuições Linux são fornecidas com várias ferramentas, como sar, para capturar e gerar relatórios sobre métricas. Embora eles sejam bons para monitorar a integridade de uma VM individual, você não pode confiar neles para uma grande implantação de nível empresarial do Apache HBase. Recomendamos que você use o Azure Monitor em vez disso. Ele fornece painéis para monitorar todas as VMs.
O Azure Monitor depende de agentes do Log Analytics. Deve haver um agente em cada VM. O agente captura os dados gravados no Syslog e os dados de desempenho de VMs individuais. Ele envia os dados para o Azure Log Analytics para armazenamento e indexação. Em seguida, os painéis do Azure Monitor extraem dados de um Espaço de Trabalho do Log Analytics configurado e apresentam aos administradores uma exibição da integridade geral de todas as VMs. Esta é uma opção nativa que pode ser habilitada perfeitamente para VMs do Azure baseadas em Linux.
Para obter instruções sobre como configurar o Azure Monitor para coletar dados do Linux, consulte Monitorar máquinas virtuais com o Azure Monitor. Depois que os dados forem gravados no Log Analytics, você poderá usar o Kusto para analisá-los. Para obter mais informações, consulte o tutorial do Log Analytics.
Migrar para o HBase no HDInsight
Você pode baixar um guia detalhado para migrar o HBase para um cluster HBase HDInsight. A página de download é Guia para migrar cargas de trabalho de Big Data para o Azure HDInsight.
Migrar para o Azure Cosmos DB (API NoSQL)
O guia para migrar para a API do Azure Cosmos NoSQL é Migrar dados do Apache HBase para a conta da API NoSQL do Azure Cosmos DB.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Principais autores:
- Namrata Maheshwary - Brasil | Arquiteto de Soluções Cloud Sênior
- Raja N - Brasil | Diretor, Customer Success
- Hideo Takagi - Brasil | Arquiteto de Soluções Cloud
- Ram Yerrabotu - Brasil | Arquiteto de Soluções Cloud Sênior
Outros contribuidores:
- Ram Baskaran - Brasil | Arquiteto de Soluções Cloud Sênior
- Jason Bouska - Brasil | Engenheiro de Software Sênior
- Eugene Chung - Brasil | Arquiteto de Soluções Cloud Sênior
- Pawan Hosatti - Brasil | Arquiteto de Soluções Cloud Sênior - Engenharia
- Daman Kaur - Brasil | Arquiteto de Soluções Cloud
- Danny Liu - Brasil | Arquiteto de Soluções Cloud Sênior - Engenharia
- Jose Mendez Arquiteto Sênior de Soluções Cloud
- Ben Sadeghi - Brasil | Especialista Sénior
- Sunil Sattiraju - Brasil | Arquiteto de Soluções Cloud Sênior
- Amanjeet Singh - Brasil | Gerente de Programa Principal
- Nagaraj Seeplapudur Venkatesan - Brasil | Arquiteto de Soluções Cloud Sênior - Engenharia
Para ver perfis não públicos do LinkedIn, inicie sessão no LinkedIn.
Próximos passos
Introduções de produtos do Azure
- Introdução ao Azure Data Lake Storage Gen2
- O que é Apache Spark em Azure HDInsight
- O que é o Apache Hadoop no Azure HDInsight?
- O que é o Apache HBase no Azure HDInsight
- O que é o Apache Kafka no Azure HDInsight
Referência do produto Azure
- Documentação do Microsoft Entra
- Documentação do Azure Cosmos DB
- Documentação do Azure Data Factory
- Documentação do Azure Databricks
- Documentação dos Hubs de Eventos do Azure
- Documentação das Funções do Azure
- Documentação do Azure HDInsight
- Documentação de governança de dados do Microsoft Purview
- Documentação do Azure Stream Analytics
- Azure Synapse Analytics
Outro
- Pacote de Segurança Empresarial para Azure HDInsight
- Desenvolver programas Java MapReduce para Apache Hadoop no HDInsight
- Utilizar o Apache Sqoop com o Hadoop no HDInsight
- Visão geral do Apache Spark Streaming
- Tutorial do Structured Streaming
- Usar Hubs de Eventos do Azure a partir de aplicativos Apache Kafka