Apache Sqoop é uma ferramenta para transferir dados entre clusters Apache Hadoop e bancos de dados relacionais. Tem uma interface de linha de comando.
Você pode usar o Sqoop para importar dados para o HDFS de bancos de dados relacionais, como MySQL, PostgreSQL, Oracle e SQL Server, e para exportar dados HDFS para esses bancos de dados. O Sqoop pode usar o MapReduce e o Apache Hive para converter dados no Hadoop. Os recursos avançados incluem carregamento incremental, formatação usando SQL e atualização de conjuntos de dados. Sqoop opera em paralelo para alcançar a transferência de dados de alta velocidade.
Nota
O projeto Sqoop se aposentou. Sqoop foi transferido para o Apache Attic em junho de 2021. O site, os downloads e o rastreador de problemas permanecem abertos. Consulte Apache Sqoop no Apache Attic para obter mais informações.
Apache, Apache Spark®, Apache Hadoop®, Apache HBase, Apache Hive, Apache Ranger®, Apache Storm®, Apache Sqoop®, Apache Kafka® e o logotipo flame são marcas registradas ou marcas comerciais da Apache Software Foundation nos Estados Unidos e/ou em outros países.® Nenhum endosso da Apache Software Foundation está implícito no uso dessas marcas.
Arquitetura e componentes do Sqoop
Existem duas versões do Sqoop: Sqoop1 e Sqoop2. O Sqoop1 é uma ferramenta de cliente simples, enquanto o Sqoop2 tem uma arquitetura cliente/servidor. Eles não são compatíveis entre si e diferem no uso. O Sqoop2 não está completo e não se destina à implantação em produção.
Arquitetura Sqoop1
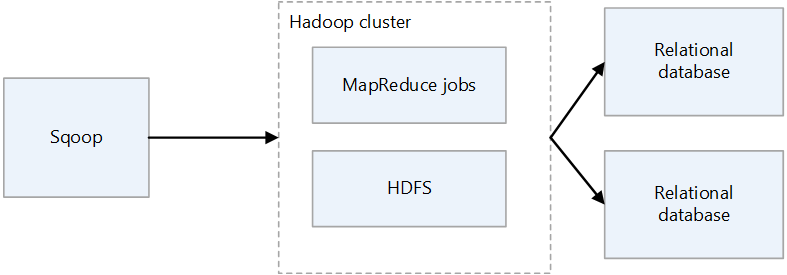
Importação e exportação Sqoop1
Importar
Lê dados de bancos de dados relacionais e produz dados para o HDFS. Cada registro na tabela de bancos de dados relacionais é gerado como uma única linha no HDFS. Text, SequenceFiles e Avro são os formatos de arquivo que podem ser gravados no HDFS.
Exportar
Lê dados do HDFS e os transfere para bancos de dados relacionais. Os bancos de dados relacionais de destino suportam inserção e atualização.
Arquitetura Sqoop2
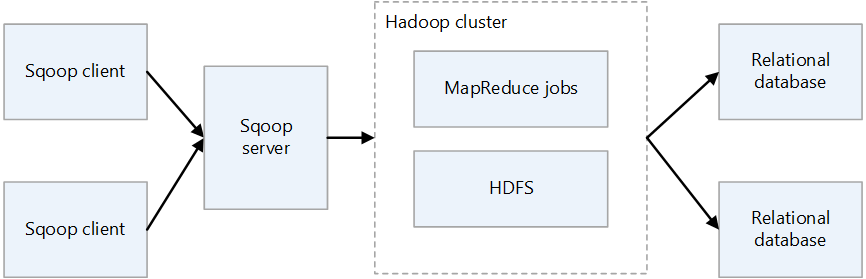
Servidor Sqoop
Fornece um ponto de entrada para clientes Sqoop.
Cliente Sqoop
Interage com o servidor Sqoop. O cliente pode estar em qualquer nó, desde que o cliente possa se comunicar com o servidor. Como o cliente precisa apenas se comunicar com o servidor, não há necessidade de fazer configurações como faria com o MapReduce.
Desafios do Sqoop local
Aqui estão alguns desafios comuns de uma implantação do Sqoop local:
- Pode ser difícil dimensionar, dependendo do hardware e da capacidade do datacenter.
- Ele não pode ser facilmente dimensionado sob demanda.
- Quando o suporte para infraestruturas envelhecidas termina, você pode ser forçado a substituir e atualizar.
- Há uma falta de ferramentas nativas para fornecer:
- Transparência de custos
- Monitorização
- DevOps
- Automatização
Considerações
- Ao migrar o Sqoop para o Azure, se sua fonte de dados permanecer local, você precisará considerar sua conectividade. Pode estabelecer uma ligação VPN através da Internet entre o Azure e a sua rede local existente ou pode utilizar o Azure ExpressRoute para estabelecer uma ligação privada.
- Ao migrar o Sqoop para o Azure HDInsight, considere sua versão do Sqoop. O HDInsight suporta apenas o Sqoop1, portanto, se você estiver usando o Sqoop2 em seu ambiente local, precisará substituí-lo pelo Sqoop1 no HDInsight ou manter o Sqoop2 independente.
- Ao migrar o Sqoop para o Azure Data Factory, você precisa considerar os formatos de arquivo de dados. O Data Factory não suporta o formato SequenceFile. A falta de suporte pode ser um problema se sua implementação do Sqoop importar dados no formato SequenceFile. Para obter mais informações, consulte Formato de arquivo.
Abordagem da migração
O Azure tem vários destinos de migração para o Apache Sqoop. Dependendo dos requisitos e recursos do produto, você pode escolher entre máquinas virtuais (VMs) IaaS do Azure, Azure HDInsight e Azure Data Factory.
Aqui está um gráfico de decisão para selecionar um destino de migração:

As metas de migração são discutidas nas seguintes seções:
Levante e mude a migração para o Azure IaaS
Se você escolher as VMs IaaS do Azure como o destino da migração para seu Sqoop local, poderá fazer uma migração de elevação e mudança. Você usa a mesma versão do Sqoop para criar um ambiente completamente controlável. Portanto, você não precisa fazer nenhuma alteração no software Sqoop. O Sqoop funciona com um cluster Hadoop e geralmente é migrado junto com um cluster Hadoop. Os artigos a seguir são guias para uma migração de elevação e deslocamento de um cluster Hadoop. Escolha o artigo que se aplica ao serviço a ser migrado.
Preparação para a migração
Para se preparar para a migração, planeje a migração e estabeleça uma conexão de rede.
Planear a migração
Reúna as seguintes informações para se preparar para a migração do seu Sqoop local. As informações ajudam a determinar o tamanho da máquina virtual de destino e a planejar os componentes de software e as configurações de rede.
| Item | Fundo |
|---|---|
| Tamanho atual do host | Obtenha informações sobre a CPU, memória, disco e outros componentes do host ou máquina virtual na qual o cliente ou servidor Sqoop está sendo executado. Você usa essas informações para estimar o tamanho base necessário para sua máquina virtual do Azure. |
| Métricas de host e aplicativo | Obtenha as informações de uso de recursos (CPU, memória, disco e outros componentes) da máquina que executa o cliente Sqoop e estime os recursos realmente usados. Se você estiver usando menos recursos do que os alocados para seu host, considere reduzir o tamanho ao migrar para o Azure. Depois de identificar a quantidade necessária de recursos, selecione o tipo de máquina virtual para a qual migrar fazendo referência ao tamanho da máquina virtual do Azure. |
| Versão Sqoop | Verifique a versão do Sqoop local para determinar qual versão do Sqoop instalar na máquina virtual do Azure. Se você estiver usando uma distribuição como Cloudera ou Hortonworks, a versão do componente depende da versão dessa distribuição. |
| Executando trabalhos e scripts | Identifique os trabalhos que executam o Sqoop e os métodos de agendamento deles. Os empregos e métodos são candidatos à migração. |
| Bancos de dados a serem conectados | Identifique os bancos de dados aos quais o Sqoop se conecta, conforme especificado pelos comandos de importação e exportação nos trabalhos do Sqoop. Depois de identificá-los, você precisa ver se pode se conectar a esses bancos de dados depois de migrar o Sqoop para suas máquinas virtuais do Azure. Se alguns dos bancos de dados aos quais você se conecta ainda estiverem no local, você precisará de uma conexão de rede entre o local e o Azure. Para obter mais informações, consulte a seção Estabelecer uma conexão de rede. |
| Plug-ins | Identifique os plug-ins do Sqoop que você usa e determine se é possível migrá-los. |
| Alta disponibilidade, continuidade de negócios, recuperação de desastres | Determine se as técnicas de solução de problemas que você usa no local podem ser usadas no Azure. Por exemplo, se você tiver uma configuração ativa/em espera em dois nós, prepare duas máquinas virtuais do Azure para clientes Sqoop que tenham a mesma configuração. O mesmo se aplica ao configurar a recuperação de desastres. |
Estabelecer uma conexão de rede
Se alguns dos bancos de dados aos quais você se conecta permanecerem locais, você precisará de uma conexão de rede entre o local e o Azure.
Há duas opções principais para conectar o local e o Azure em uma rede privada:
Gateway de VPN
Você pode usar o Gateway de VPN do Azure para enviar tráfego criptografado entre sua rede virtual do Azure e seu local local pela Internet pública. Esta técnica é barata e fácil de configurar. No entanto, devido à conexão criptografada pela internet, a largura de banda de comunicação não é garantida. Se você precisa garantir largura de banda, você deve escolher ExpressRoute, que é a segunda opção. Para obter mais informações sobre a opção VPN, consulte O que é o Gateway VPN? e Design do Gateway VPN.
ExpressRoute
O ExpressRoute pode conectar sua rede local ao Azure ou ao Microsoft 365 usando uma conexão privada fornecida por um provedor de conectividade. O ExpressRoute não passa pela internet pública, por isso é mais seguro, mais confiável e tem latências mais consistentes do que as conexões pela internet. Além disso, as opções de largura de banda da linha que você compra podem garantir latências estáveis. Para obter mais informações, consulte O que é o Azure ExpressRoute?.
Se esses métodos de conexão privada não atenderem às suas necessidades, considere o Azure Data Factory como um destino de migração. O tempo de execução de integração auto-hospedado no Data Factory possibilita que você transfira dados do local para o Azure sem precisar configurar uma rede privada.
Migrar dados e configurações
Ao migrar o Sqoop local para máquinas virtuais do Azure, inclua os seguintes dados e configurações:
Arquivos de configuração do Sqoop: Depende do seu ambiente, mas os seguintes arquivos geralmente são incluídos:
sqoop-site.xmlsqoop-env.xmlpassword-fileoraoop-site.xml, se utilizar Oraoop
Trabalhos salvos: se você salvou trabalhos no metastore do Sqoop usando o
sqoop job --createcomando, será necessário migrá-los. O destino de salvamento do metastore é definido em sqoop-site.xml. Se o metastore compartilhado não estiver definido, procure os trabalhos salvos no subdiretório .sqoop do diretório base do usuário que executa o metastore.Você pode usar os seguintes comandos para ver informações sobre os trabalhos salvos.
Obtenha a lista de empregos guardados:
sqoop job --listExibir parâmetros para trabalhos salvos
sqoop job --show <job-id>
Scripts: Se você tiver arquivos de script que executam o Sqoop, precisará migrá-los.
Agendador: Se você agendar a execução do Sqoop, precisará identificar seu agendador, como um trabalho cron Linux ou uma ferramenta de gerenciamento de trabalho. Em seguida, você precisa considerar se o agendador pode ser migrado para o Azure.
Plug-ins: Se você estiver usando plug-ins personalizados no Sqoop, por exemplo, um conector para um banco de dados externo, será necessário migrá-los. Se você criou um arquivo de patch, aplique o patch ao Sqoop migrado.
Migrar para o HDInsight
O HDInsight agrupa componentes do Apache Hadoop e a plataforma HDInsight em um pacote implantado em um cluster. Em vez de migrar o próprio Sqoop para o Azure, é mais comum executar o Sqoop em um cluster HDInsight. Para obter mais informações sobre como usar o HDInsight para executar estruturas de código aberto, como Hadoop e Spark, consulte O que é o Azure HDInsight? e Guia para migrar cargas de trabalho de Big Data para o Azure HDInsight.
Consulte os seguintes artigos para obter as versões de componentes no HDInsight.
Migrar para o Data Factory
O Azure Data Factory é um serviço de integração de dados totalmente gerenciado e sem servidor. Ele pode ser dimensionado sob demanda de acordo com fatores como o volume de dados. Ele tem uma GUI para edição e desenvolvimento intuitivos usando modelos Python, .NET e Azure Resource Manager (modelos ARM).
Ligação a fontes de dados
Consulte o artigo apropriado para obter uma lista dos conectores Sqoop padrão:
Data Factory tem um grande número de conectores. Para obter mais informações, consulte Visão geral do Azure Data Factory e do conector do Azure Synapse Analytics.
A tabela a seguir é um exemplo que mostra os conectores do Data Factory a serem usados para Sqoop1 versão 1.4.7 e Sqoop2 versão 1.99.7. Certifique-se de consultar a documentação mais recente, porque a lista de versões suportadas pode mudar.
| Sqoop1 - 1.4.7 | Sqoop2 - 1.99.7 | Data Factory | Considerações |
|---|---|---|---|
| Conector JDBC MySQL | Conector JDBC genérico | MySQL, Banco de Dados do Azure para MySQL | |
| Conector MySQL Direct | N/A | N/A | O Direct Connector usa mysqldump para dados de entrada e saída sem passar pelo JDBC. O método é diferente no Data Factory, mas o conector MySQL pode ser usado. |
| Conector Microsoft SQL | Conector JDBC genérico | SQL Server, Banco de Dados SQL do Azure, Instância Gerenciada do SQL do Azure | |
| Conector do PostgreSQL | PostgreSQL, Conector JDBC Genérico | Base de Dados do Azure para PostgreSQL | |
| Conector direto PostgreSQL | N/A | N/A | O Direct Connector não passa pelo JDBC e usa o comando COPY para dados de entrada e saída. O método é diferente no Data Factory, mas o conector PostgreSQL pode ser usado. |
| pg_bulkload conector | N/A | N/A | Carregue no PostgreSQL usando pg_bulkload. O método é diferente no Data Factory, mas o conector PostgreSQL pode ser usado. |
| Conector Netezza | Conector JDBC genérico | Netteza | |
| Conector de dados para Oracle e Hadoop | Conector JDBC genérico | Oracle | |
| N/A | Conector FTP | FTP | |
| N/A | Conector SFTP | SFTP | |
| N/A | Conector Kafka | N/A | O Data Factory não pode se conectar diretamente ao Kafka. Considere usar o Spark Streaming, como o Azure Databricks ou o HDInsight, para se conectar ao Kafka. |
| N/A | Conector Kite | N/A | O Data Factory não pode se conectar diretamente ao Kite. |
| HDFS | HDFS | HDFS | O Data Factory suporta HDFS como fonte, mas não como coletor. |
Conectar-se a bancos de dados locais
Se, depois de migrar o Sqoop para o Data Factory, você ainda precisar copiar dados entre um armazenamento de dados em sua rede local e o Azure, considere usar estes métodos:
Runtime de integração autoalojado
Se você estiver tentando integrar dados em um ambiente de rede privada onde não há um caminho de comunicação direto do ambiente de nuvem pública, você pode fazer o seguinte para melhorar a segurança:
- Instale um tempo de execução de integração auto-hospedado no ambiente local, seja no firewall interno ou na rede privada virtual.
- Faça uma conexão de saída baseada em HTTPS do tempo de execução de integração auto-hospedado para o Azure para estabelecer uma conexão para movimentação de dados.
O tempo de execução de integração auto-hospedado só é suportado no Windows. Você também pode obter escalabilidade e alta disponibilidade instalando e associando tempos de execução de integração auto-hospedados em várias máquinas. O tempo de execução de integração auto-hospedado também é responsável por despachar atividades de transformação de dados para recursos que não estão no local ou na rede virtual do Azure.
Para obter informações sobre como configurar o tempo de execução de integração auto-hospedado, consulte Criar e configurar um tempo de execução de integração auto-hospedado.
Rede virtual gerenciada usando um ponto de extremidade privado
Se você tiver uma conexão privada entre o local e o Azure (como ExpressRoute ou VPN Gateway), poderá usar a rede virtual gerenciada e o ponto de extremidade privado no Data Factory para fazer uma conexão privada com seus bancos de dados locais. Você pode usar redes virtuais para encaminhar o tráfego para seus recursos locais, conforme mostrado no diagrama a seguir, para acessar seus recursos locais sem passar pela Internet.

Transfira um ficheiro do Visio desta arquitetura.
Para obter mais informações, consulte Tutorial: Como acessar o SQL Server local a partir da VNet gerenciada do Data Factory usando o ponto de extremidade privado.
Opções de rede
O Data Factory tem duas opções de rede:
Ambos constroem uma rede privada e ajudam a proteger o processo de integração de dados. Eles podem ser usados ao mesmo tempo.
Rede virtual gerenciada
Você pode implantar o tempo de execução de integração, que é o tempo de execução do Data Factory, em uma rede virtual gerenciada. Ao implantar um ponto de extremidade privado, como um armazenamento de dados que se conecta à rede virtual gerenciada, você pode melhorar a segurança da integração de dados em uma rede privada fechada.

Transfira um ficheiro do Visio desta arquitetura.
Para obter mais informações, consulte Rede virtual gerenciada do Azure Data Factory.
Ligação privada
Você pode usar o Azure Private Link for Azure Data Factory para se conectar ao Data Factory.

Transfira um ficheiro do Visio desta arquitetura.
Para obter mais informações, consulte O que é um ponto de extremidade privado? e Documentação de link privado.
Execução da cópia de dados
O Sqoop melhora o desempenho da transferência de dados usando o MapReduce para processamento paralelo. Depois de migrar o Sqoop, o Data Factory pode ajustar o desempenho e a escalabilidade para cenários que executam migrações de dados em grande escala.
Uma unidade de integração de dados (DIU) é uma unidade de desempenho do Data Factory. É uma combinação de CPU, memória e alocação de recursos de rede. O Data Factory pode ajustar até 256 DIUs para atividades de cópia que usam o tempo de execução de integração do Azure. Para obter mais informações, consulte Unidades de integração de dados.
Se você usar o tempo de execução de integração auto-hospedado, poderá melhorar o desempenho dimensionando a máquina que hospeda o tempo de execução de integração auto-hospedado. A expansão máxima é de quatro nós.
Para obter mais informações sobre como fazer ajustes para atingir o desempenho desejado, consulte Guia de desempenho e escalabilidade da atividade de cópia.
Aplicar SQL
O Sqoop pode importar o conjunto de resultados de uma consulta SQL, conforme mostrado neste exemplo:
$ sqoop import \
--query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' \
--split-by a.id --target-dir /user/foo/joinresults
O Data Factory também pode consultar o banco de dados e copiar o conjunto de resultados:
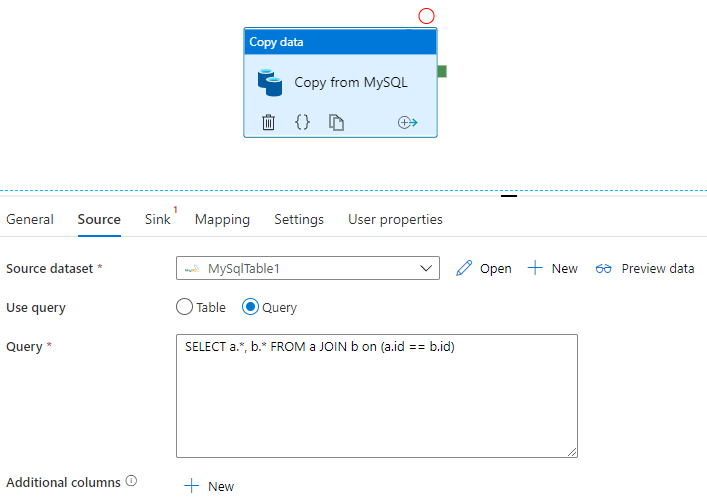
Consulte Copiar propriedades da atividade para obter um exemplo que obtém o conjunto de resultados de uma consulta em um banco de dados MySQL.
Transformação de dados
O Data Factory e o HDInsight podem executar várias atividades de transformação de dados.
Transformar dados usando atividades do Data Factory
O Data Factory pode executar uma variedade de atividades de transformação de dados, como fluxo de dados e disputa de dados. Para ambos, você define as transformações usando uma interface do usuário visual. Você também pode usar as atividades de vários componentes Hadoop do HDInsight, Databricks, procedimentos armazenados e outras atividades personalizadas. Considere usar essas atividades ao migrar o Sqoop e quiser incluir transformações de dados no processo. Consulte Transformar dados no Azure Data Factory para obter mais informações.
Transformar dados usando atividades do HDInsight
As várias atividades do HDInsight em um pipeline do Azure Data Factory, incluindo Hive, Pig, MapReduce, Streaming e Spark, podem executar programas e consultas em seu próprio cluster ou em um cluster HDInsight sob demanda. Se você migrar uma implementação do Sqoop que usa a lógica de transformação de dados do ecossistema Hadoop, será fácil migrar as transformações para as atividades do HDInsight. Para obter detalhes, consulte os seguintes artigos.
- Transformar dados usando a atividade do Hadoop Hive no Azure Data Factory ou no Synapse Analytics
- Transformar dados usando a atividade do Hadoop MapReduce no Azure Data Factory ou no Synapse Analytics
- Transforme dados usando a atividade do Hadoop Pig no Azure Data Factory ou no Synapse Analytics
- Transforme dados usando a atividade do Spark no Azure Data Factory e no Synapse Analytics
- Transformar dados usando a atividade de streaming do Hadoop no Azure Data Factory ou no Synapse Analytics
File format
O Sqoop suporta texto, SequenceFile e Avro como formatos de arquivo quando importa dados para o HDFS. O Data Factory não suporta HDFS como um coletor de dados, mas usa o Armazenamento Azure Data Lake ou o Armazenamento de Blobs do Azure como armazenamento de arquivos. Para obter mais informações sobre a migração do HDFS, consulte Migração do Apache HDFS.
Os formatos suportados para o Data Factory gravar no armazenamento de arquivos são text, binário, Avro, JSON, ORC e Parquet, mas não SequenceFile. Você pode usar uma atividade como o Spark para converter um arquivo em SequenceFile usando saveAsSequenceFile:
data.saveAsSequenceFile(<path>)
Agendamento de trabalhos
O Sqoop não fornece a funcionalidade do agendador. Se você estiver executando trabalhos do Sqoop em um agendador, precisará migrar essa funcionalidade para o Data Factory. O Data Factory pode usar gatilhos para agendar a execução do pipeline de dados. Escolha um gatilho do Data Factory de acordo com sua configuração de agendamento existente. Aqui estão os tipos de gatilhos.
- Gatilho de agenda: um gatilho de agendamento executa o pipeline em uma agenda de relógio de parede.
- Gatilho de janela de queda: um gatilho de janela de tombamento é executado periodicamente a partir de uma hora de início especificada, mantendo seu estado.
- Gatilho baseado em evento: um gatilho baseado em evento aciona o pipeline em resposta ao evento. Há dois tipos de gatilhos baseados em eventos:
- Gatilho de evento de armazenamento: um gatilho de evento de armazenamento aciona o pipeline em resposta a um evento de armazenamento, como criar, excluir ou gravar em um arquivo.
- Gatilho de evento personalizado: um gatilho de evento personalizado aciona o pipeline em resposta a um evento enviado para um tópico personalizado em uma grade de eventos. Para obter informações sobre tópicos personalizados, consulte Tópicos personalizados na Grade de Eventos do Azure.
Para obter mais informações sobre gatilhos, consulte Execução de pipeline e gatilhos no Azure Data Factory ou Azure Synapse Analytics.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Principais autores:
- Namrata Maheshwary - Brasil | Arquiteto de Soluções Cloud Sênior
- Raja N - Brasil | Diretor, Customer Success
- Hideo Takagi - Brasil | Arquiteto de Soluções Cloud
- Ram Yerrabotu - Brasil | Arquiteto de Soluções Cloud Sênior
Outros contribuidores:
- Ram Baskaran - Brasil | Arquiteto de Soluções Cloud Sênior
- Jason Bouska - Brasil | Engenheiro de Software Sênior
- Eugene Chung - Brasil | Arquiteto de Soluções Cloud Sênior
- Pawan Hosatti - Brasil | Arquiteto de Soluções Cloud Sênior - Engenharia
- Daman Kaur - Brasil | Arquiteto de Soluções Cloud
- Danny Liu - Brasil | Arquiteto de Soluções Cloud Sênior - Engenharia
- Jose Mendez Arquiteto Sênior de Soluções Cloud
- Ben Sadeghi - Brasil | Especialista Sénior
- Sunil Sattiraju - Brasil | Arquiteto de Soluções Cloud Sênior
- Amanjeet Singh - Brasil | Gerente de Programa Principal
- Nagaraj Seeplapudur Venkatesan - Brasil | Arquiteto de Soluções Cloud Sênior - Engenharia
Para ver perfis não públicos do LinkedIn, inicie sessão no LinkedIn.
Próximos passos
Introduções de produtos do Azure
- Introdução ao Azure Data Lake Storage Gen2
- O que é o Apache Spark no Azure HDInsight?
- O que é o Apache Hadoop no Azure HDInsight?
- O que é o Apache HBase no Azure HDInsight?
- O que é o Apache Kafka no Azure HDInsight?
- Visão geral da segurança corporativa no Azure HDInsight
Referência do produto Azure
- Documentação do Microsoft Entra
- Documentação do Azure Cosmos DB
- Documentação do Azure Data Factory
- Documentação do Azure Databricks
- Documentação dos Hubs de Eventos do Azure
- Documentação das Funções do Azure
- Documentação do Azure HDInsight
- Documentação de governança de dados do Microsoft Purview
- Documentação do Azure Stream Analytics
- Azure Synapse Analytics
Outro
- Pacote de Segurança Empresarial para Azure HDInsight
- Desenvolver programas Java MapReduce para Apache Hadoop no HDInsight
- Utilizar o Apache Sqoop com o Hadoop no HDInsight
- Visão geral do Apache Spark Streaming
- Tutorial do Structured Streaming
- Usar Hubs de Eventos do Azure a partir de aplicativos Apache Kafka