O Hadoop Distributed File System (HDFS) é um sistema de arquivos distribuído baseado em Java que fornece armazenamento de dados confiável e escalável que pode abranger grandes clusters de servidores de mercadoria. Este artigo fornece uma visão geral do HDFS e um guia para migrá-lo para o Azure.
Apache, Apache Spark®, Apache Hadoop®, Apache Hive e o logotipo flame são marcas registradas ou marcas comerciais da Apache Software Foundation nos Estados Unidos e/ou em outros países.® Nenhum endosso da Apache Software Foundation está implícito no uso dessas marcas.
Arquitetura e componentes do HDFS
O HDFS tem um design primário/secundário. No diagrama a seguir, NameNode é o primário e os DataNodes são os secundários.
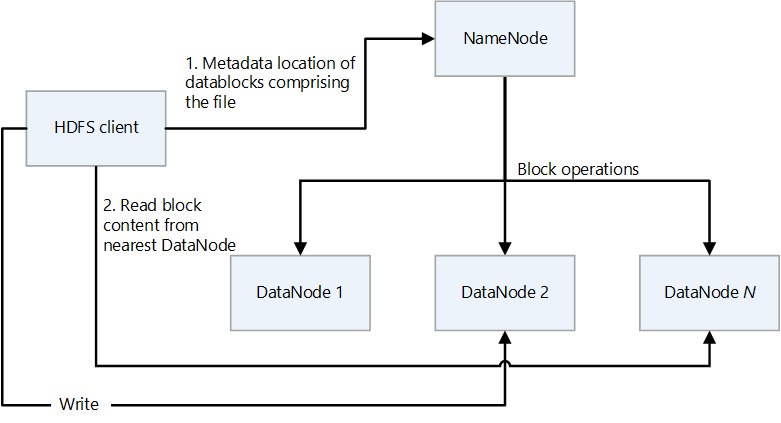
- NameNode gerencia o acesso a arquivos e ao namespace do sistema de arquivos, que é uma hierarquia de diretórios.
- Arquivos e diretórios são nós em NameNode. Eles têm atributos como permissões, tempos de modificação e acesso e cotas de tamanho para namespace e espaço em disco.
- Um arquivo é composto por vários blocos. O tamanho padrão do bloco é de 128 megabytes. Um tamanho de bloco não padrão pode ser definido para um cluster modificando o arquivo hdfs-site.xml.
- Cada bloco do arquivo é replicado independentemente em vários DataNodes. O valor padrão para o fator de replicação é três, mas cada cluster pode ter seu próprio valor não padrão. O fator de replicação pode ser alterado a qualquer momento. Uma alteração causa um reequilíbrio de cluster.
- NameNode mantém a árvore de namespace e o mapeamento de blocos de arquivo para DataNodes (os locais físicos dos dados de arquivo).
- Quando um cliente HDFS lê um ficheiro:
- Ele entra em contato com o NameNode para os locais dos blocos de dados do arquivo.
- Ele lê o conteúdo do bloco do DataNode mais próximo.
- O HDFS mantém todo o namespace na RAM.
- DataNodes são os nós secundários que executam operações de leitura e gravação no sistema de arquivos e executam operações de bloco, como criação, replicação e exclusão.
- Um DataNode contém arquivos de metadados que contêm as somas de verificação dos arquivos armazenados. Para cada réplica de bloco hospedada por um DataNode, há um arquivo de metadados correspondente que contém metadados sobre a réplica, incluindo suas informações de soma de verificação. O arquivo de metadados tem o mesmo nome base que o arquivo de bloco e extensão .meta.
- O DataNode contém o arquivo de dados que contém os dados do bloco.
- Quando um DataNode lê um arquivo, ele busca os locais de bloco e os locais de réplica do NameNode e tenta ler no local mais próximo.
- Um cluster HDFS pode ter milhares de DataNodes e dezenas de milhares de clientes HDFS por cluster. Cada DataNode pode executar várias tarefas de aplicativo simultaneamente.
- Um cálculo de soma de verificação de ponta a ponta é executado como parte do pipeline de gravação do HDFS quando um bloco é gravado em DataNodes.
- O Cliente HDFS é o cliente que os aplicativos usam para acessar arquivos.
- É uma biblioteca de códigos que exporta a interface do sistema de arquivos HDFS.
- Ele suporta operações para ler, gravar e excluir arquivos, e operações para criar e excluir diretórios.
- Ele executa as seguintes etapas quando um aplicativo lê um arquivo:
- Ele obtém do NameNode uma lista de DataNodes e locais que contêm os blocos de arquivo. A lista inclui as réplicas.
- Ele usa a lista para obter os blocos solicitados dos DataNodes.
- O HDFS fornece uma API que expõe os locais dos blocos de arquivos. Isso permite que aplicativos como a estrutura MapReduce programem uma tarefa para ser executada onde os dados estão, a fim de otimizar o desempenho de leitura.
Mapa de recursos
O driver do Sistema de Arquivos de Blob do Azure (ABFS) fornece uma interface que possibilita que o Armazenamento Azure Data Lake atue como um sistema de arquivos HDFS. A tabela a seguir compara a funcionalidade principal do driver ABFS e do armazenamento Data Lake com a do HDFS.
| Funcionalidade | O driver ABFS e o armazenamento Data Lake | HDFS |
|---|---|---|
| Acesso compatível com o Hadoop | Pode gerir e aceder aos dados tal como faria com o HDFS. O driver ABFS está disponível em todos os ambientes Apache Hadoop, incluindo o Azure HDInsight e o Azure Databricks. | Um cluster MapR pode acessar um cluster HDFS externo com os protocolos hdfs:// ou webhdfs:// |
| Permissões POSIX | O modelo de segurança do Data Lake Gen2 suporta permissões de lista de controle de acesso (ACL) e POSIX, juntamente com alguma granularidade extra específica do Data Lake Storage Gen2. As configurações podem ser configuradas usando ferramentas de administração ou estruturas como Apache Hive e Apache Spark. | Trabalhos que exigem recursos do sistema de arquivos, como renomeações estritamente atômicas de diretórios, permissões refinadas do HDFS ou links simbólicos do HDFS, só podem funcionar no HDFS. |
| Relação custo-eficácia | O Data Lake Storage oferece capacidade de armazenamento e transações de baixo custo. Os ciclos de vida do Armazenamento de Blobs do Azure ajudam a reduzir os custos ajustando as taxas de cobrança à medida que os dados se movem ao longo do seu ciclo de vida. | |
| Driver otimizado | O driver ABFS é otimizado para análise de big data. As APIs REST correspondentes são fornecidas através do ponto de extremidade do sistema de arquivos distribuídos (DFS), dfs.core.windows.net. |
|
| Tamanho do bloco | Blocks é equivalente a uma única invocação Append API (a Append API cria um novo bloco) e é limitado a 100 MB por invocação. No entanto, o padrão de gravação suporta chamar Append muitas vezes por arquivo (mesmo em paralelo) para um máximo de 50.000 e, em seguida, chamar Flush (equivalente a PutBlockList). Esta é a forma como o tamanho máximo dos ficheiros de 4,75 TB é alcançado. | O HDFS armazena os dados num bloco de dados. Você define o tamanho do bloco definindo um valor no arquivo hdfs-site.xml no diretório Hadoop. O tamanho padrão é 128 MB. |
| ACLS padrão | Os arquivos não têm ACLs padrão e não são habilitados por padrão. | Os arquivos não têm ACLs padrão. |
| Arquivos binários | Os arquivos binários podem ser movidos para o Armazenamento de Blobs do Azure em um namespace não hierárquico. Os objetos no Armazenamento de Blob podem ser acessados por meio da API REST do Armazenamento do Azure, do Azure PowerShell, da CLI do Azure ou de uma biblioteca de cliente do Armazenamento do Azure. As bibliotecas de cliente estão disponíveis para diferentes linguagens, incluindo .NET, Java, Node.js, Python, Go, PHP e Ruby | O Hadoop oferece a capacidade de ler e gravar arquivos binários. SequenceFile é um arquivo simples que consiste em uma chave binária e pares de valor. O SequenceFile fornece classes Writer, Reader e Sorter para escrita, leitura e classificação. Converta o arquivo de imagem ou vídeo em um SequenceFile e armazene-o no HDFS. Em seguida, use os métodos HDFS SequenceFileReader/Writer ou o comando put: bin/hadoop fs -put /src_image_file /dst_image_file |
| Herança de permissão | O Armazenamento Data Lake usa o modelo no estilo POSIX e se comporta da mesma forma que o Hadoop se as ACLs controlarem o acesso a um objeto. Para obter mais informações, consulte Listas de controle de acesso (ACLs) no Data Lake Storage Gen2. | As permissões para um item são armazenadas no próprio item, não herdadas depois que o item existe. As permissões só são herdadas se as permissões padrão forem definidas no item pai antes que o item filho seja criado. |
| Replicação de dados | Os dados em uma conta de Armazenamento do Azure são replicados três vezes na região primária. O armazenamento com redundância de zona é a opção de replicação recomendada. Ele replica de forma síncrona em três zonas de disponibilidade do Azure na região primária. | Por padrão, o fator de replicação de um arquivo é três. Para arquivos críticos ou arquivos acessados com frequência, um fator de replicação mais alto melhora a tolerância a falhas e aumenta a largura de banda de leitura. |
| Bit pegajoso | No contexto do armazenamento Data Lake, é improvável que o bit adesivo seja necessário. Resumidamente, se o bit adesivo estiver habilitado em um diretório, um item filho só poderá ser excluído ou renomeado pelo usuário proprietário do item filho. O bit adesivo não é mostrado no portal do Azure. | O bit adesivo pode ser definido em diretórios para impedir que qualquer pessoa, exceto o superusuário, proprietário do diretório ou proprietário do arquivo, exclua ou mova arquivos dentro do diretório. Definir o bit adesivo para um arquivo não tem efeito. |
Desafios comuns de um HDFS local
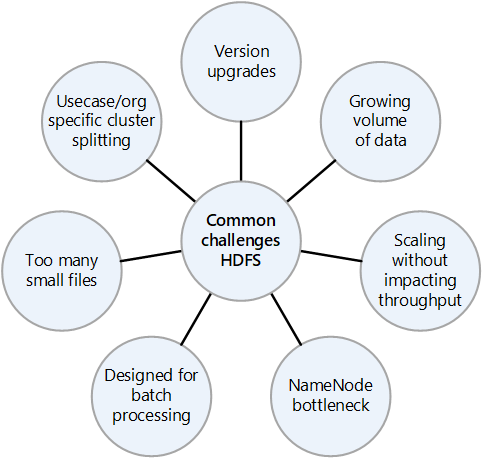
Os muitos desafios apresentados por uma implementação HDFS local podem ser motivos para considerar as vantagens da migração para a nuvem:
- Atualizações frequentes da versão do HDFS
- Quantidades crescentes de dados
- Ter muitos arquivos pequenos que aumentam a pressão sobre o NameNode, que controla os metadados de todos os arquivos no cluster. Mais arquivos geralmente significam mais tráfego de leitura no NameNode quando os clientes leem os arquivos e mais chamadas quando os clientes estão escrevendo.
- Se várias equipes na organização exigirem conjuntos de dados diferentes, não é possível dividir os clusters HDFS por caso de uso ou organização. O resultado é que a duplicação de dados aumenta, o que aumenta os custos e reduz a eficiência.
- O NameNode pode se tornar um gargalo de desempenho à medida que o cluster HDFS é ampliado ou reduzido.
- Antes do Hadoop 2.0, todas as solicitações de cliente para um cluster HDFS passam primeiro pelo NameNode, porque todos os metadados são armazenados em um único NameNode. Esse design torna o NameNode um possível gargalo e ponto único de falha. Se o NameNode falhar, o cluster não estará disponível.
Migration considerations (Considerações sobre a migração)
Aqui estão algumas coisas que são importantes considerar ao planejar uma migração do HDFS para o Data Lake Storage:
- Considere agregar dados que estão em arquivos pequenos em um único arquivo no Data Lake Storage.
- Liste todas as estruturas de diretório no HDFS e replique zoneamento semelhante no Armazenamento Data Lake. Você pode obter a estrutura de diretórios do HDFS usando o
hdfs -lscomando. - Liste todas as funções definidas no cluster HDFS para que você possa replicá-las no ambiente de destino.
- Observe a política de ciclo de vida de dados dos arquivos armazenados no HDFS.
- Lembre-se de que alguns recursos do sistema do HDFS não estão disponíveis no Armazenamento Data Lake, incluindo:
- Renomeação estritamente atômica de diretórios
- Permissões refinadas do HDFS
- Links simbólicos HDFS
- O Armazenamento do Azure tem replicação com redundância geográfica, mas nem sempre é aconselhável usá-la. Ele fornece redundância de dados e recuperação geográfica, mas um failover para um local mais distante pode degradar gravemente o desempenho e incorrer em custos adicionais. Considere se a maior disponibilidade dos dados vale a pena.
- Se os ficheiros tiverem nomes com os mesmos prefixos, o HDFS trata-os como uma única partição. Portanto, se você usar o Azure Data Factory, todas as unidades de movimentação de dados (DMUs) gravam em uma única partição.

- Se você usar o Data factory para transferência de dados, verifique cada diretório, excluindo instantâneos, e verifique o tamanho do diretório usando o
hdfs ducomando. Se houver vários subdiretórios e grandes quantidades de dados, inicie várias atividades de cópia no Data Factory. Por exemplo, use uma cópia por subdiretório em vez de transferir o diretório inteiro usando uma única atividade de cópia.

- As plataformas de dados são frequentemente utilizadas para a retenção a longo prazo de informações que podem ter sido removidas dos sistemas de registo. Você deve planejar a criação de backups em fita ou instantâneos dos dados arquivados. Considere replicar as informações para um local de recuperação. Normalmente, os dados são arquivados para fins de conformidade ou para fins de dados históricos. Antes de arquivar dados, você deve ter um motivo claro para mantê-los. Além disso, decida quando os dados arquivados devem ser removidos e estabeleça processos para removê-los naquele momento.
- O baixo custo do nível de acesso ao Arquivo do Data Lake Storage o torna uma opção atraente para o arquivamento de dados. Para obter mais informações, consulte Camada de acesso ao arquivo.
- Quando um cliente HDFS usa o driver ABFS para acessar o Armazenamento de Blob, pode haver instâncias em que o método usado pelo cliente não é suportado e o AzureNativeFileSystem lança um UnsupportedOperationException. Por exemplo,
append(Path f, int bufferSize, Progressable progress)não é suportado atualmente. Para verificar problemas relacionados ao driver ABFS, consulte Recursos e correções do Hadoop. - Há uma versão backport do driver ABFS para uso em clusters Hadoop mais antigos. Para obter mais informações, consulte Backport for ABFS Driver.
- Em um ambiente de rede virtual do Azure, a ferramenta DistCp não oferece suporte ao emparelhamento privado do Azure ExpressRoute com um ponto de extremidade de rede virtual do Armazenamento do Azure. Para obter mais informações, consulte Usar o Azure Data Factory para migrar dados de um cluster Hadoop local para o Armazenamento do Azure.
Abordagem da migração
A abordagem típica para migrar o HDFS para o armazenamento Data Lake usa estas etapas:

Avaliação HDFS
Os scripts de avaliação local fornecem informações que ajudam a determinar quais cargas de trabalho podem ser migradas para o Azure e se os dados devem ser migrados todos de uma vez ou uma parte de cada vez. Ferramentas de terceiros como o Unravel podem fornecer métricas e dar suporte à avaliação automática do HDFS local. Alguns fatores importantes a considerar ao planejar incluem:
- Volume de dados
- Impacto comercial
- Propriedade dos dados
- Complexidade de processamento
- Complexidade de extração, transferência e carga (ETL)
- Informações de identificação pessoal (PII) e outros dados confidenciais
Com base nesses fatores, você pode formular um plano para mover dados para o Azure que minimize o tempo de inatividade e a interrupção dos negócios. Talvez os dados confidenciais possam permanecer no local. Os dados históricos podem ser movidos e testados antes de mover uma carga incremental.
O fluxo de decisão a seguir ajuda a decidir os critérios e comandos a serem executados para obter as informações certas.

Os comandos do HDFS para obter métricas de avaliação do HDFS incluem:
Liste todos os diretórios em um local:
hdfs dfs -ls booksListe recursivamente todos os arquivos em um local:
hdfs dfs -ls -R booksObtenha o tamanho do diretório e dos arquivos HDFS:
hadoop fs -du -s -h commandO
hadoop fs -du -s -hcomando exibe o tamanho dos arquivos e do diretório HDFS. Como o sistema de arquivos Hadoop replica todos os arquivos, o tamanho físico real do arquivo é o número de réplicas multiplicado pelo tamanho de uma réplica.Determine se as ACLs estão habilitadas. Para fazer isso, obtenha o valor de
dfs.namenode.acls.enabledin Hdfs-site.xml. Conhecer o valor ajuda a planejar o controle de acesso na conta de Armazenamento do Azure. Para obter informações sobre o conteúdo desse arquivo, consulte Configurações de arquivo padrão.
Ferramentas de parceiros, como o Unravel, fornecem relatórios de avaliação para o planejamento da migração de dados. As ferramentas devem ser executadas no ambiente local ou conectar-se ao cluster Hadoop para gerar relatórios.
O seguinte relatório Unravel fornece estatísticas, por diretório, sobre os pequenos arquivos no diretório:

O relatório a seguir fornece estatísticas, por diretório, sobre os arquivos no diretório:

Transferir dados
Os dados devem ser transferidos para o Azure conforme descrito no seu plano de migração. A transferência requer as seguintes atividades:
Identifique todos os pontos de ingestão.
Se, devido a requisitos de segurança, os dados não puderem ser enviados diretamente para a nuvem, o local poderá servir como uma zona de aterrissagem intermediária. Você pode criar pipelines no Data Factory para extrair os dados de sistemas locais ou usar scripts AZCopy para enviar os dados por push para a conta de Armazenamento do Azure.
As fontes de ingestão comuns incluem:
- Servidor SFTP
- Ingestão de ficheiros
- Ingestão de bases de dados
- Despejo de banco de dados
- Captura de dados de alteração
- Ingestão em transmissão em fluxo
Planeje o número de contas de armazenamento necessárias.
Para planejar o número de contas de armazenamento necessárias, entenda a carga total no HDFS atual. Você pode usar a métrica TotalLoad, que é o número atual de acessos simultâneos a arquivos em todos os DataNodes. Defina o limite da conta de armazenamento na região de acordo com o valor TotalLoad local e o crescimento esperado no Azure. Se for possível aumentar o limite, uma única conta de armazenamento pode ser suficiente. No entanto, para um data lake, é melhor manter uma conta de armazenamento separada para cada zona, para se preparar para o crescimento futuro do volume de dados. Outros motivos para manter uma conta de armazenamento separada incluem:
- Controlo de acesso
- Requisitos de resiliência
- Requisitos de replicação de dados
- Expondo os dados para uso público
Quando você habilita um namespace hierárquico em uma conta de armazenamento, não pode alterá-lo de volta para um namespace simples. Cargas de trabalho, como backups e arquivos de imagem de VM, não obtêm nenhum benefício de um namespace hierárquico.

Para obter informações sobre como proteger o tráfego entre sua rede virtual e a conta de armazenamento por meio de um link privado, consulte Protegendo contas de armazenamento.
Para obter informações sobre limites padrão para contas de Armazenamento do Azure, consulte Metas de escalabilidade e desempenho para contas de armazenamento padrão. O limite de entrada aplica-se aos dados enviados para uma conta de armazenamento. O limite de saída aplica-se aos dados recebidos de uma conta de armazenamento
Decida sobre os requisitos de disponibilidade.
Você pode especificar o fator de replicação para plataformas Hadoop em hdfs-site.xml ou especificá-lo por arquivo. Você pode configurar a replicação no Armazenamento Data Lake de acordo com a natureza dos dados. Se um aplicativo exigir que os dados sejam reconstruídos em caso de perda, o armazenamento com redundância de zona (ZRS) é uma opção. No Data Lake Storage ZRS, os dados são copiados de forma síncrona em três zonas de disponibilidade na região primária. Para aplicativos que exigem alta disponibilidade e que podem ser executados em mais de uma região, copie os dados para uma região secundária. Trata-se de replicação com redundância geográfica.

Verifique se há blocos corrompidos ou ausentes.
Verifique se há blocos corrompidos ou ausentes no relatório do scanner de blocos. Se houver, aguarde até que o arquivo seja restaurado antes de transferi-lo.

Verifique se o NFS está habilitado.
Verifique se o NFS está habilitado na plataforma Hadoop local verificando o arquivo core-site.xml. Ele tem as propriedades nfsserver.groups e nfsserver.hosts.
O recurso NFS 3.0 está em visualização no Armazenamento Data Lake. Alguns recursos podem não ser suportados ainda. Para obter mais informações, consulte Suporte ao protocolo NFS (Network File System) 3.0 para o Armazenamento de Blobs do Azure.

Verifique os formatos de arquivo do Hadoop.
Use o fluxograma de decisão a seguir para obter orientação sobre como lidar com formatos de arquivo.

Escolha uma solução do Azure para transferência de dados.
A transferência de dados pode ser on-line pela rede ou off-line usando dispositivos físicos. O método a utilizar depende do volume de dados, da largura de banda da rede e da frequência da transferência de dados. Os dados históricos têm de ser transferidos apenas uma vez. Cargas incrementais exigem transferências contínuas repetidas.
Os métodos de transferência de dados são discutidos na lista a seguir. Para obter mais informações sobre como escolher tipos de transferência de dados, consulte Escolher uma solução do Azure para transferência de dados.
Azcopy
Azcopy é um utilitário de linha de comando que pode copiar arquivos do HDFS para uma conta de armazenamento. Esta é uma opção para transferências de alta largura de banda (mais de 1 GBPS).
Aqui está um comando de exemplo para mover um diretório HDFS:
*azcopy copy "C:\local\path" "https://account.blob.core.windows.net/mycontainer1/?sv=2018-03-28&ss=bjqt&srt=sco&sp=rwddgcup&se=2019-05-01T05:01:17Z&st=2019-04-30T21:01:17Z&spr=https&sig=MGCXiyEzbtttkr3ewJIh2AR8KrghSy1DGM9ovN734bQF4%3D" --recursive=true*DistCp
DistCp é um utilitário de linha de comando no Hadoop que pode fazer operações de cópia distribuída em um cluster Hadoop. O DistCp cria várias tarefas de mapa no cluster Hadoop para copiar dados da origem para o coletor. Essa abordagem de push é boa quando há largura de banda de rede adequada e não requer recursos de computação extras a serem provisionados para migração de dados. No entanto, se o cluster HDFS de origem já estiver ficando sem capacidade e não for possível adicionar computação adicional, considere usar o Data Factory com a atividade de cópia DistCp para extrair em vez de enviar os arquivos.
*hadoop distcp -D fs.azure.account.key.<account name>.blob.core.windows.net=<Key> wasb://<container>@<account>.blob.core.windows.net<path to wasb file> hdfs://<hdfs path>*Azure Data Box para transferências de dados grandes
O Azure Data Box é um dispositivo físico encomendado à Microsoft. Ele fornece transferências de dados em grande escala e é uma opção de transferência de dados offline quando a largura de banda da rede é limitada e o volume de dados é alto (por exemplo, quando o volume está entre alguns terabytes e um petabyte).
Você conecta um Data Box à LAN para transferir dados para ela. Em seguida, você o envia de volta para o data center da Microsoft, onde os dados são transferidos pelos engenheiros da Microsoft para a conta de armazenamento configurada.
Há várias opções de Data Box que diferem pelos volumes de dados que eles podem manipular. Para obter mais informações sobre a abordagem Data Box, consulte Documentação do Azure Data Box - Transferência offline.
Data Factory
O Data Factory é um serviço de integração de dados que ajuda a criar fluxos de trabalho orientados por dados que orquestram e automatizam a movimentação e a transformação de dados. Você pode usá-lo quando houver largura de banda de rede suficiente disponível e houver um requisito para orquestrar e monitorar a migração de dados. Você pode usar o Data Factory para carregamentos incrementais regulares de dados quando os dados incrementais chegam ao sistema local como um primeiro salto e não podem ser transferidos diretamente para a conta de armazenamento do Azure devido a restrições de segurança.
Para obter mais informações sobre as várias abordagens de transferência, consulte Transferência de dados para grandes conjuntos de dados com largura de banda de rede moderada a alta.
Para obter informações sobre como usar o Data Factory para copiar dados do HDFS, consulte Copiar dados do servidor HDFS usando o Azure Data Factory ou o Synapse Analytics
Soluções de parceiros, como migração WANdisco LiveData
A plataforma WANdisco LiveData para Azure é uma das soluções preferidas da Microsoft para migrações do Hadoop para o Azure. Você acessa seus recursos usando o portal do Azure e a CLI do Azure. Para obter mais informações, consulte Migrar seus data lakes Hadoop com o WANdisco LiveData Platform for Azure.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Principais autores:
- Namrata Maheshwary - Brasil | Arquiteto de Soluções Cloud Sênior
- Raja N - Brasil | Diretor, Customer Success
- Hideo Takagi - Brasil | Arquiteto de Soluções Cloud
- Ram Yerrabotu - Brasil | Arquiteto de Soluções Cloud Sênior
Outros contribuidores:
- Ram Baskaran - Brasil | Arquiteto de Soluções Cloud Sênior
- Jason Bouska - Brasil | Engenheiro de Software Sênior
- Eugene Chung - Brasil | Arquiteto de Soluções Cloud Sênior
- Pawan Hosatti - Brasil | Arquiteto de Soluções Cloud Sênior - Engenharia
- Daman Kaur - Brasil | Arquiteto de Soluções Cloud
- Danny Liu - Brasil | Arquiteto de Soluções Cloud Sênior - Engenharia
- Jose Mendez Arquiteto Sênior de Soluções Cloud
- Ben Sadeghi - Brasil | Especialista Sénior
- Sunil Sattiraju - Brasil | Arquiteto de Soluções Cloud Sênior
- Amanjeet Singh - Brasil | Gerente de Programa Principal
- Nagaraj Seeplapudur Venkatesan - Brasil | Arquiteto de Soluções Cloud Sênior - Engenharia
Para ver perfis não públicos do LinkedIn, inicie sessão no LinkedIn.
Próximos passos
Introduções de produtos do Azure
- Introdução ao Azure Data Lake Storage Gen2
- O que é Apache Spark em Azure HDInsight
- O que é o Apache Hadoop no Azure HDInsight?
- O que é o Apache HBase no Azure HDInsight
- O que é o Apache Kafka no Azure HDInsight
Referência do produto Azure
- Documentação do Microsoft Entra
- Documentação do Azure Cosmos DB
- Documentação do Azure Data Factory
- Documentação do Azure Databricks
- Documentação dos Hubs de Eventos do Azure
- Documentação das Funções do Azure
- Documentação do Azure HDInsight
- Documentação de governança de dados do Microsoft Purview
- Documentação do Azure Stream Analytics
- Azure Synapse Analytics
Outro
- Pacote de Segurança Empresarial para Azure HDInsight
- Desenvolver programas Java MapReduce para Apache Hadoop no HDInsight
- Utilizar o Apache Sqoop com o Hadoop no HDInsight
- Visão geral do Apache Spark Streaming
- Tutorial do Structured Streaming
- Usar Hubs de Eventos do Azure a partir de aplicativos Apache Kafka