Tutorial: Usar o Cache Redis do Azure como um cache semântico
Neste tutorial, você usa o Cache Redis do Azure como um cache semântico com um LLM (modelo de linguagem grande) baseado em IA. Você usa o Serviço OpenAI do Azure para gerar respostas LLM para consultas e armazenar em cache essas respostas usando o Cache do Azure para Redis, fornecendo respostas mais rápidas e reduzindo custos.
Como o Cache Redis do Azure oferece recursos internos de pesquisa vetorial, você também pode executar cache semântico. Você pode retornar respostas armazenadas em cache para consultas idênticas e também para consultas com significado semelhante, mesmo que o texto não seja o mesmo.
Neste tutorial, irá aprender a:
- Criar uma instância do Cache do Azure para Redis configurada para cache semântico
- Use LangChain outras bibliotecas Python populares.
- Use o serviço Azure OpenAI para gerar texto a partir de modelos de IA e resultados de cache.
- Veja os ganhos de desempenho do uso de cache com LLMs.
Importante
Este tutorial orienta você na criação de um Jupyter Notebook. Você pode seguir este tutorial com um arquivo de código Python (.py) e obter resultados semelhantes , mas você precisa adicionar todos os blocos de código neste tutorial no arquivo e executar uma vez para ver os .py resultados. Em outras palavras, o Jupyter Notebooks fornece resultados intermediários à medida que você executa células, mas esse não é um comportamento que você deve esperar ao trabalhar em um arquivo de código Python.
Importante
Se você quiser acompanhar em um bloco de anotações Jupyter concluído, baixe o arquivo do bloco de anotações Jupyter chamado semanticcache.ipynb e salve-o na nova pasta semanticcache .
Pré-requisitos
Uma assinatura do Azure - Crie uma gratuitamente
Acesso concedido ao Azure OpenAI na assinatura desejada do Azure Atualmente, você deve solicitar acesso ao Azure OpenAI. Você pode solicitar acesso ao Azure OpenAI preenchendo o formulário em https://aka.ms/oai/access.
Cadernos Jupyter (opcional)
Um recurso OpenAI do Azure com os modelos text-embedding-ada-002 (Versão 2) e gpt-35-turbo-instruct implantados. Atualmente, estes modelos só estão disponíveis em determinadas regiões. Consulte o guia de implantação de recursos para obter instruções sobre como implantar os modelos.
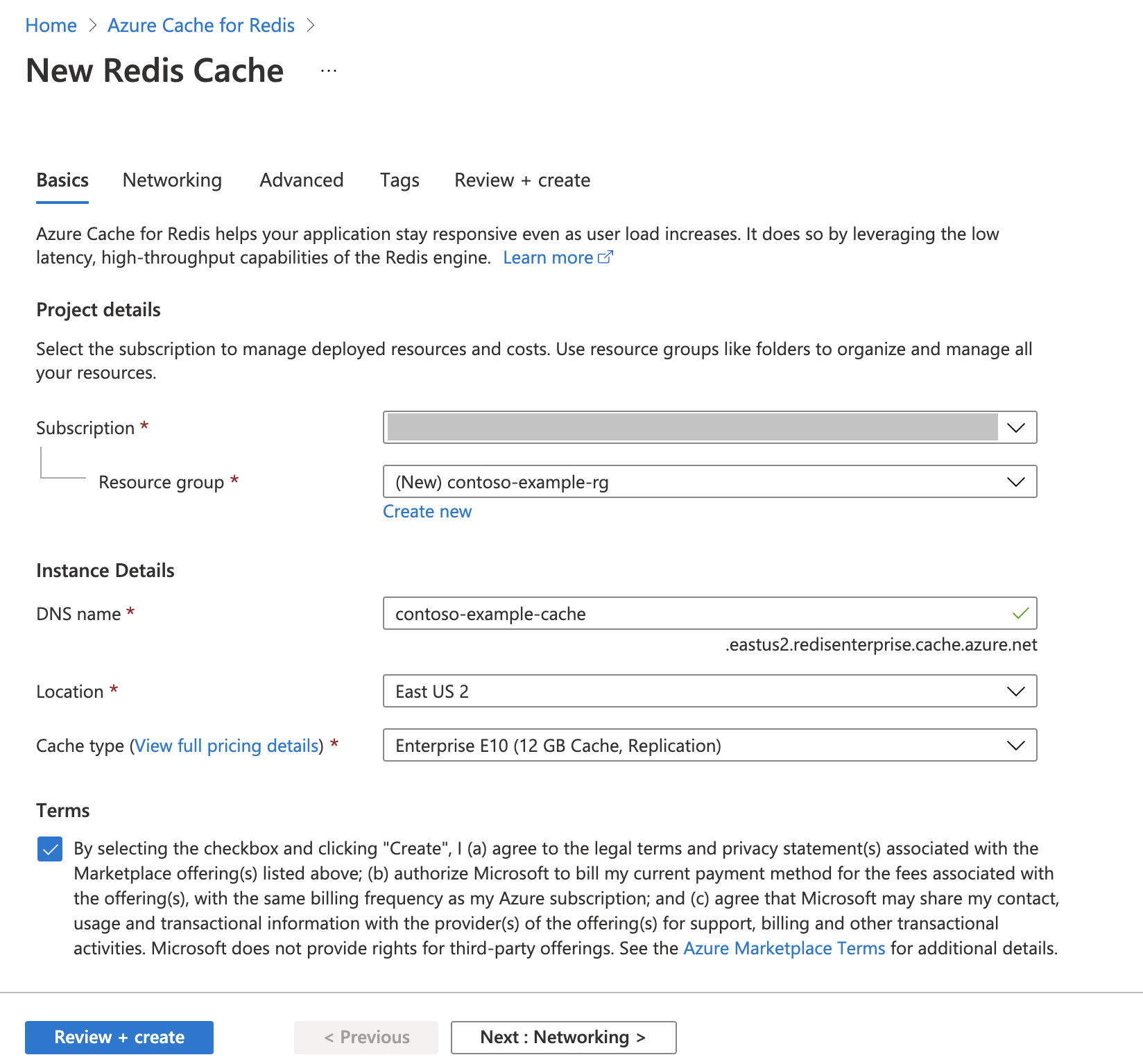
Criar uma instância do Cache do Azure para Redis
Siga o Guia de início rápido: criar um guia de cache do Redis Enterprise. Na página Avançado, certifique-se de que adicionou o módulo RediSearch e escolheu a Política de Cluster Empresarial. Todas as outras configurações podem corresponder ao padrão descrito no início rápido.
Leva alguns minutos para o cache ser criado. Enquanto isso, você pode passar para a próxima etapa.
Configurar o ambiente de desenvolvimento
Crie uma pasta no computador local chamada semanticcache no local onde você normalmente salva seus projetos.
Crie um novo arquivo python (tutorial.py) ou um bloco de anotações Jupyter (tutorial.ipynb) na pasta.
Instale os pacotes Python necessários:
pip install openai langchain redis tiktoken
Criar modelos do Azure OpenAI
Verifique se você tem dois modelos implantados em seu recurso do Azure OpenAI:
Um LLM que fornece respostas de texto. Usamos o modelo GPT-3.5-turbo-instruct para este tutorial.
Um modelo de incorporação que converte consultas em vetores para permitir que elas sejam comparadas com consultas anteriores. Usamos o modelo text-embedding-ada-002 (Versão 2) para este tutorial.
Consulte Implantar um modelo para obter instruções mais detalhadas. Registre o nome escolhido para cada implantação de modelo.
Importar bibliotecas e configurar informações de conexão
Para fazer uma chamada com êxito no Azure OpenAI, você precisa de um ponto de extremidade e uma chave. Você também precisa de um ponto de extremidade e uma chave para se conectar ao Cache do Azure para Redis.
Vá para o seu recurso do Azure OpenAI no portal do Azure.
Localize Ponto de Extremidade e Chaves na seção Gerenciamento de Recursos do seu recurso do Azure OpenAI. Copie seu ponto de extremidade e chave de acesso porque você precisa de ambos para autenticar suas chamadas de API. Um exemplo de ponto de extremidade é:
https://docs-test-001.openai.azure.com. Pode utilizarKEY1ouKEY2.Vá para a página Visão geral do seu recurso Cache do Azure para Redis no portal do Azure. Copie seu ponto de extremidade.
Localize as teclas de acesso na seção Configurações . Copie a sua chave de acesso. Pode utilizar
PrimaryouSecondary.Adicione o seguinte código a uma nova célula de código:
# Code cell 2 import openai import redis import os import langchain from langchain.llms import AzureOpenAI from langchain.embeddings import AzureOpenAIEmbeddings from langchain.globals import set_llm_cache from langchain.cache import RedisSemanticCache import time AZURE_ENDPOINT=<your-openai-endpoint> API_KEY=<your-openai-key> API_VERSION="2023-05-15" LLM_DEPLOYMENT_NAME=<your-llm-model-name> LLM_MODEL_NAME="gpt-35-turbo-instruct" EMBEDDINGS_DEPLOYMENT_NAME=<your-embeddings-model-name> EMBEDDINGS_MODEL_NAME="text-embedding-ada-002" REDIS_ENDPOINT = <your-redis-endpoint> REDIS_PASSWORD = <your-redis-password>Atualize o valor de e
RESOURCE_ENDPOINTcom os valores deAPI_KEYchave e ponto de extremidade de sua implantação do Azure OpenAI.Defina
LLM_DEPLOYMENT_NAMEeEMBEDDINGS_DEPLOYMENT_NAMEpara o nome de seus dois modelos implantados no Serviço OpenAI do Azure.Atualize
REDIS_ENDPOINTeREDIS_PASSWORDcom o ponto de extremidade e o valor da chave da sua instância do Cache do Azure para Redis.Importante
É altamente recomendável usar variáveis ambientais ou um gerenciador secreto como o Azure Key Vault para passar as informações de chave de API, ponto de extremidade e nome de implantação. Essas variáveis são definidas em texto simples aqui por uma questão de simplicidade.
Execute a célula de código 2.
Inicializar modelos de IA
Em seguida, inicialize os modelos LLM e incorpora
Adicione o seguinte código a uma nova célula de código:
# Code cell 3 llm = AzureOpenAI( deployment_name=LLM_DEPLOYMENT_NAME, model_name="gpt-35-turbo-instruct", openai_api_key=API_KEY, azure_endpoint=AZURE_ENDPOINT, openai_api_version=API_VERSION, ) embeddings = AzureOpenAIEmbeddings( azure_deployment=EMBEDDINGS_DEPLOYMENT_NAME, model="text-embedding-ada-002", openai_api_key=API_KEY, azure_endpoint=AZURE_ENDPOINT, openai_api_version=API_VERSION )Execute a célula de código 3.
Configurar o Redis como um cache semântico
Em seguida, especifique Redis como um cache semântico para seu LLM.
Adicione o seguinte código a uma nova célula de código:
# Code cell 4 redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT set_llm_cache(RedisSemanticCache(redis_url = redis_url, embedding=embeddings, score_threshold=0.05))Importante
O valor do
score_thresholdparâmetro determina como duas consultas precisam ser semelhantes para retornar um resultado armazenado em cache. Quanto menor o número, mais semelhantes as consultas precisam ser. Você pode brincar com esse valor para ajustá-lo ao seu aplicativo.Execute a célula de código 4.
Consultar e obter respostas do LLM
Por fim, consulte o LLM para obter uma resposta gerada por IA. Se você estiver usando um bloco de anotações Jupyter, poderá adicionar %%time na parte superior da célula a quantidade de tempo necessária para executar o código.
Adicione o seguinte código a uma nova célula de código e execute-o:
# Code cell 5 %%time response = llm("Please write a poem about cute kittens.") print(response)Você deve ver uma saída semelhante a esta:
Fluffy balls of fur, With eyes so bright and pure, Kittens are a true delight, Bringing joy into our sight. With tiny paws and playful hearts, They chase and pounce, a work of art, Their innocence and curiosity, Fills our hearts with such serenity. Their soft meows and gentle purrs, Are like music to our ears, They curl up in our laps, And take the stress away in a snap. Their whiskers twitch, they're always ready, To explore and be adventurous and steady, With their tails held high, They're a sight to make us sigh. Their tiny faces, oh so sweet, With button noses and paw-sized feet, They're the epitome of cuteness, ... Cute kittens, a true blessing, In our hearts, they'll always be reigning. CPU times: total: 0 ns Wall time: 2.67 sO
Wall timemostra um valor de 2,67 segundos. Esse é o tempo que o mundo real levou para consultar o LLM e para o LLM gerar uma resposta.Execute a célula 5 novamente. Você deve ver exatamente a mesma saída, mas com um tempo de parede menor:
Fluffy balls of fur, With eyes so bright and pure, Kittens are a true delight, Bringing joy into our sight. With tiny paws and playful hearts, They chase and pounce, a work of art, Their innocence and curiosity, Fills our hearts with such serenity. Their soft meows and gentle purrs, Are like music to our ears, They curl up in our laps, And take the stress away in a snap. Their whiskers twitch, they're always ready, To explore and be adventurous and steady, With their tails held high, They're a sight to make us sigh. Their tiny faces, oh so sweet, With button noses and paw-sized feet, They're the epitome of cuteness, ... Cute kittens, a true blessing, In our hearts, they'll always be reigning. CPU times: total: 0 ns Wall time: 575 msO tempo de parede parece encurtar por um fator de cinco - até 575 milissegundos.
Altere a consulta de
Please write a poem about cute kittensparaWrite a poem about cute kittense execute a célula 5 novamente. Você deve ver exatamente a mesma saída e um tempo de parede mais baixo do que a consulta original. Embora a consulta tenha sido alterada, o significado semântico da consulta permaneceu o mesmo, de modo que a mesma saída em cache foi retornada. Esta é a vantagem do cache semântico!
Alterar o limiar de semelhança
Tente executar uma consulta semelhante com um significado diferente, como
Please write a poem about cute puppies. Observe que o resultado armazenado em cache também é retornado aqui. O significado semântico da palavrapuppiesé próximo o suficiente da palavrakittenspara que o resultado armazenado em cache seja retornado.O limite de semelhança pode ser modificado para determinar quando o cache semântico deve retornar um resultado armazenado em cache e quando ele deve retornar uma nova saída do LLM. Na célula de código 4, mude
score_thresholdde0.05para0.01:# Code cell 4 redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT set_llm_cache(RedisSemanticCache(redis_url = redis_url, embedding=embeddings, score_threshold=0.01))Tente a consulta
Please write a poem about cute puppiesnovamente. Você deve receber uma nova saída específica para cachorros:Oh, little balls of fluff and fur With wagging tails and tiny paws Puppies, oh puppies, so pure The epitome of cuteness, no flaws With big round eyes that melt our hearts And floppy ears that bounce with glee Their playful antics, like works of art They bring joy to all they see Their soft, warm bodies, so cuddly As they curl up in our laps Their gentle kisses, so lovingly Like tiny, wet, puppy taps Their clumsy steps and wobbly walks As they explore the world anew Their curiosity, like a ticking clock Always eager to learn and pursue Their little barks and yips so sweet Fill our days with endless delight Their unconditional love, so complete ... For they bring us love and laughter, year after year Our cute little pups, in every way. CPU times: total: 15.6 ms Wall time: 4.3 sVocê provavelmente precisará ajustar o limite de semelhança com base em seu aplicativo para garantir que a sensibilidade certa seja usada ao determinar quais consultas armazenar em cache.
Clean up resources (Limpar recursos)
Se quiser continuar a usar os recursos criados neste artigo, mantenha o grupo de recursos.
Caso contrário, para evitar cobranças relacionadas aos recursos, se você terminar de usá-los, poderá excluir o grupo de recursos do Azure que você criou.
Aviso
A eliminação de um grupo de recursos é irreversível. Quando você exclui um grupo de recursos, todos os recursos no grupo de recursos são excluídos permanentemente. Confirme que não elimina acidentalmente o grupo de recursos ou recursos errados. Se você criou os recursos dentro de um grupo de recursos existente que tem recursos que deseja manter, você pode excluir cada recurso individualmente em vez de excluir o grupo de recursos.
Eliminar um grupo de recursos
Inicie sessão no Portal do Azure e selecione Grupos de recursos.
Selecione o grupo de recursos a ser excluído.
Se houver muitos grupos de recursos, em Filtrar para qualquer campo, insira o nome do grupo de recursos criado para concluir este artigo. Na lista de resultados da pesquisa, selecione o grupo de recursos.
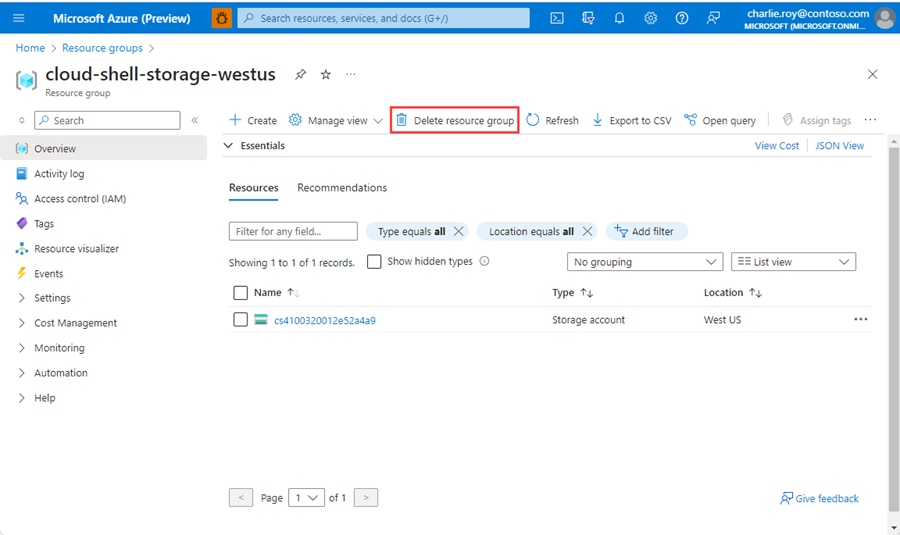
Selecione Eliminar grupo de recursos.
No painel Eliminar um grupo de recursos, introduza o nome do grupo de recursos a confirmar e, em seguida, selecione Eliminar.
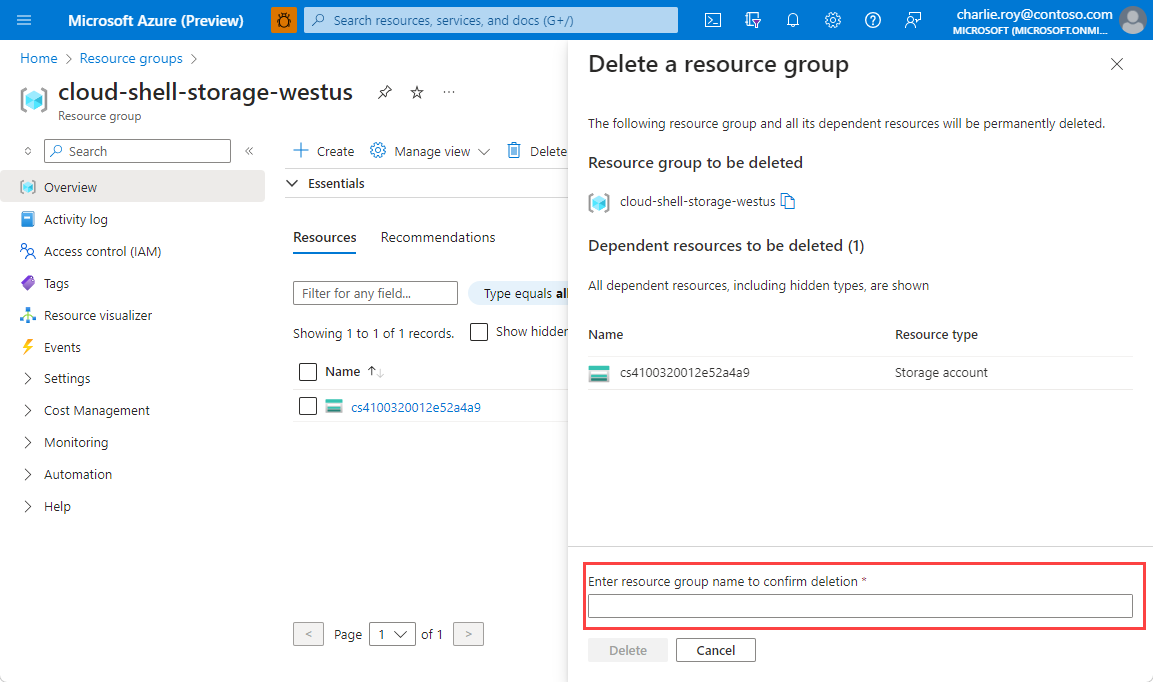
Dentro de alguns momentos, o grupo de recursos e todos os seus recursos são excluídos.
Conteúdos relacionados
- Saiba mais sobre a Cache do Azure para Redis
- Saiba mais sobre os recursos de pesquisa vetorial do Cache do Azure para Redis
- Tutorial: usar a pesquisa de semelhança vetorial no Cache Redis do Azure
- Leia como criar um aplicativo alimentado por IA com OpenAI e Redis
- Crie um aplicativo de perguntas e respostas com respostas semânticas