Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Replicar seu espaço de trabalho do Log Analytics entre regiões aumenta a resiliência, permitindo que você alterne para o espaço de trabalho replicado e continue as operações se houver uma falha regional. Este artigo explica como funciona a replicação do espaço de trabalho do Log Analytics, como replicar seu espaço de trabalho, como alternar entre os espaços de trabalho replicados e como decidir quando alternar entre os espaços de trabalho replicados.
Veja um vídeo que fornece uma visão geral rápida de como funciona a replicação do espaço de trabalho do Log Analytics:
Importante
Embora às vezes usemos o termo failover, por exemplo, na chamada de API, o failover também é comumente usado para descrever um processo automático. Portanto, este artigo usa o termo "switchover" para enfatizar que a mudança para o espaço de trabalho replicado é uma ação que você inicia manualmente.
Como funciona a replicação do espaço de trabalho do Log Analytics
O espaço de trabalho e a região originais são chamados de principais. O espaço de trabalho replicado e a região alternativa são chamados de secundários.
O processo de replicação do espaço de trabalho cria uma instância do seu espaço de trabalho na região secundária. O processo cria o espaço de trabalho secundário com a mesma configuração do espaço de trabalho principal, e o Azure Monitor atualiza automaticamente o espaço de trabalho secundário com quaisquer alterações futuras feitas na configuração do espaço de trabalho principal.
O espaço de trabalho secundário é um espaço de trabalho "sombra" apenas para fins de resiliência. Você não pode ver o espaço de trabalho secundário no portal do Azure e não pode gerenciá-lo ou acessá-lo diretamente.
Quando você habilita a replicação do espaço de trabalho, o Azure Monitor envia novos logs ingeridos ao seu espaço de trabalho primário para sua região secundária também. Os logs que você ingere no espaço de trabalho antes de habilitar a replicação do espaço de trabalho não são copiados.
Nota
A replicação do espaço de trabalho replica totalmente todos os esquemas de tabela, mas envia apenas novos logs ingeridos desde que a replicação foi ativada. Os logs ingeridos no espaço de trabalho antes de ativar a replicação não serão copiados.
Se uma interrupção afetar sua região primária, você poderá alternar e redirecionar todas as solicitações de ingestão e consulta para sua região secundária. Depois que o Azure atenuar a interrupção e seu espaço de trabalho principal estiver íntegro novamente, você poderá alternar novamente para sua região principal.
Ao alternar entre os espaços de trabalho, o espaço de trabalho secundário torna-se ativo e o espaço de trabalho principal torna-se inativo. Em seguida, o Azure Monitor ingere novos dados por meio do pipeline de ingestão em sua região secundária, em vez da região primária. Quando você alterna para sua região secundária, o Azure Monitor replica todos os dados que você ingere da região secundária para a região primária. O processo é assíncrono e não afeta a latência de ingestão.
Nota
Depois de alternar para a região secundária, se a região primária não puder processar dados de log de entrada, o Azure Monitor armazenará os dados em buffer na região secundária por até 11 dias. Durante os primeiros quatro dias, o Azure Monitor tenta replicar os dados periodicamente.

Proteção contra perda de dados em trânsito durante uma falha regional
O Azure Monitor tem vários mecanismos para garantir que os dados em trânsito não sejam perdidos quando há uma falha na região primária.
O Azure Monitor protege os dados que chegam ao ponto final de ingestão na região primária quando o pipeline da região primária não está disponível para processar os dados. Quando o pipeline se torna disponível, ele continua a processar os dados em trânsito, e o Azure Monitor ingere e replica estes dados na região secundária.
Se o ponto de extremidade de ingestão da região primária não estiver disponível, o Agente do Azure Monitor repetirá regularmente o envio de dados de log para o ponto de extremidade. O endpoint de ingestão de dados na região secundária começa a receber dados dos agentes alguns minutos após o início da alternância.
Ao criares um cliente próprio para enviar dados de registo para o teu espaço de trabalho do Log Analytics, assegura que o cliente consiga lidar com solicitações de ingestão falhadas.
Considerações sobre implementação
Nota
Atualmente, a replicação de espaços de trabalho não oferece suporte à replicação de tabelas Auxiliares e não deve ser habilitada em espaços de trabalho que incluam tabelas Auxiliares. As tabelas auxiliares não são replicadas e, portanto, não são protegidas contra perda de dados no caso de uma falha regional e não estão disponíveis quando você alterna para o espaço de trabalho secundário.
As operações de gerenciamento de espaço de trabalho não podem ser iniciadas durante a transição, incluindo:
- Alteração da retenção do espaço de trabalho, escalão de preços, limite diário e assim por diante
- Alteração das configurações de rede
- Alteração de esquema por meio de novos logs personalizados ou conexão de logs de plataforma de novos provedores de recursos, como o envio de logs de diagnóstico de um novo tipo de recurso
O processo de failover atualiza seus registros DNS (Sistema de Nomes de Domínio) para redirecionar todas as solicitações de ingestão para sua região secundária para processamento. Alguns clientes HTTP têm "conexões adesivas" e podem levar mais tempo para receber atualizações de DNS. Durante a mudança, esses clientes podem tentar ingerir logs através da região primária durante algum tempo. Você pode estar ingerindo registos no seu espaço de trabalho principal usando vários clientes, incluindo o Log Analytics Agent legado, o Azure Monitor Agent, código (usando a API de Ingestão de Registos ou a API de coleção de dados HTTP legada) e outros serviços, como o Microsoft Sentinel.
Importante
As regras de alerta de pesquisa de log continuam a funcionar quando você alterna entre regiões, a menos que o serviço Alertas na região ativa não esteja funcionando corretamente ou as regras de alerta não estejam disponíveis. Isso pode acontecer, por exemplo, se a região na qual as regras de alerta foram criadas estiver totalmente inativa. A replicação de regras de alerta entre regiões não é feita automaticamente como parte da replicação do espaço de trabalho, mas pode ser feita pelo usuário (por exemplo, exportando da região primária e importando para a secundária).
A operação de limpeza, que exclui registros de um espaço de trabalho, remove os registros relevantes dos espaços de trabalho primário e secundário. Se uma das instâncias do espaço de trabalho não estiver disponível, a operação de limpeza falhará.
O Microsoft Sentinel atualiza os registos nas tabelas Lista de Vigilância e Inteligência de Ameaças a cada 12 dias. Portanto, como apenas novos logs são ingeridos no espaço de trabalho replicado, pode levar até 12 dias para replicar totalmente os dados da Lista de Vigilância e da Inteligência de Ameaças para o local secundário.
O recurso de direcionamento de solução do agente herdado do Log Analytics não é suportado durante a transição. Durante a transição, os dados da solução são ingeridos de todos os agentes.
Estes recursos não são suportados atualmente ou apenas parcialmente suportados:
Caraterística Suporte Planos de mesas auxiliares Não suportado. O Azure Monitor não replica dados em tabelas com o plano de log auxiliar para o espaço de trabalho secundário. Portanto, esses dados não são protegidos contra perda de dados no caso de uma falha regional e não estão disponíveis quando você alterna para o espaço de trabalho secundário. Pesquisar Empregos, Restaurar Parcialmente suportado - As tarefas de pesquisa e as operações de restauração criam tabelas e preenchem-nas com dados restaurados ou resultados de pesquisa. Depois de habilitar a replicação do espaço de trabalho, as novas tabelas criadas para essas operações serão replicadas para o espaço de trabalho secundário. As tabelas preenchidas antes de habilitar a replicação não são replicadas. Se estas operações estiverem em andamento quando altera de função, o resultado será inesperado. Poderá ser concluído com sucesso, mas não ser replicado, ou poderá falhar, dependendo da integridade do seu espaço de trabalho e da temporização exata. Application Insights nos espaços de trabalho do Log Analytics Não suportado Análises de VM Não suportado Informações sobre Contêineres Não suportado Ligações privadas Não suportado durante o processo de recuperação
Regiões suportadas
Atualmente, há suporte para replicação de espaços de trabalho em espaços de trabalho em um conjunto limitado de regiões, organizadas por grupos de regiões (grupos de regiões geograficamente adjacentes). Ao habilitar a replicação, selecione um local secundário na lista de regiões suportadas no mesmo grupo de regiões que o local principal do espaço de trabalho. Por exemplo, um espaço de trabalho na Europa Ocidental pode ser replicado no Norte da Europa, mas não no Oeste dos EUA 2, uma vez que essas regiões estão em grupos de regiões diferentes.
Estes grupos de regiões e regiões têm atualmente suporte:
| Grupo de Regiões | Regiões primárias | Regiões secundárias (locais de replicação) |
|---|---|---|
| América do Norte | Canadá Central Leste do Canadá EUA centrais Leste dos EUA* Leste dos EUA 2* Centro-Norte dos EUA Centro-Sul dos EUA* Centro-Oeste dos EUA Oeste dos EUA Oeste dos EUA 2 O Oeste dos EUA 3 |
Canadá Central EUA centrais Leste dos EUA* Leste dos EUA 2* Oeste dos EUA E.U.A. Oeste 2 |
| América do Sul | Brasil Sul Brasil Sudeste |
Brasil Sul Brasil Sudeste |
| Europa | França Central França Sul Alemanha Norte Alemanha Centro-Oeste Itália Norte Norte da Europa Leste da Noruega Noruega Oeste Polónia Central Sul do Reino Unido Espanha Central Suécia Central Suécia Sul Suíça Norte Suíça Oeste Europa Ocidental Oeste do Reino Unido |
França Central Norte da Europa Sul do Reino Unido Europa Ocidental |
| Médio Oriente | Catar Central Centro dos Emirados Árabes Unidos Emirados Árabes Unidos Norte |
Catar Central Centro dos Emirados Árabes Unidos Emirados Árabes Unidos Norte |
| Índia | Índia Central Sul da Índia |
Índia Central Sul da Índia |
| Ásia-Pacífico | Ásia Oriental Leste do Japão Oeste do Japão Coreia Central Coreia do Sul Sudeste Asiático |
Ásia Oriental Leste do Japão Coreia Central |
| Oceânia | Austrália Central Austrália Central 2 Leste da Austrália Austrália Sudeste |
Austrália Central Leste da Austrália Austrália Sudeste |
| África | África do Sul Norte África do Sul Ocidental |
África do Sul Norte África do Sul Ocidental |
Nota
Os espaços de trabalho localizados no Leste dos EUA, Leste dos EUA 2 e Centro-Sul dos EUA só podem ser replicados para regiões secundárias fora desse conjunto de três. Selecione outro local secundário do grupo de regiões da América do Norte.
Requisitos de residência de dados
Clientes diferentes têm requisitos de residência de dados diferentes, por isso é importante que você controle onde seus dados são armazenados. O Azure Monitor processa e armazena logs nas regiões primária e secundária que você escolher. Para obter mais informações, consulte Regiões suportadas.
Suporte para Microsoft Sentinel e outros serviços
Vários serviços e recursos que usam espaços de trabalho do Log Analytics são compatíveis com a replicação e a alternância do espaço de trabalho. Esses serviços e recursos continuam a funcionar quando você alterna para o espaço de trabalho secundário.
Por exemplo, problemas de rede regional que causam latência de ingestão de log podem afetar os clientes do Microsoft Sentinel. Os clientes que usam espaços de trabalho replicados podem alternar para a região secundária para continuar trabalhando com o espaço de trabalho do Log Analytics e o Sentinel. No entanto, se o problema de rede afetar a integridade do serviço Sentinel, mudar para outra região não atenuará o problema.
Algumas experiências do Azure Monitor, incluindo o Application Insights e o VM Insights, são atualmente apenas parcialmente compatíveis com a replicação e a alternância do espaço de trabalho. Para obter a lista completa, consulte Considerações sobre implantação.
Modelo de preços
Ao habilitar a replicação do espaço de trabalho, você será cobrado pela replicação de todos os dados ingeridos no espaço de trabalho.
Importante
Se você enviar dados para seu espaço de trabalho usando o Agente do Azure Monitor, a API de Ingestão de Logs, Hubs de Eventos do Azure ou outras fontes de dados que usam regras de coleta de dados, certifique-se de associar suas regras de coleta de dados ao ponto de extremidade de coleta de dados do seu espaço de trabalho. Essa associação garante que os dados ingeridos sejam replicados para o espaço de trabalho secundário. Se não associares as tuas regras de recolha de dados ao ponto final de recolha de dados do espaço de trabalho, serás cobrado por todos os dados ingeridos no espaço de trabalho, mesmo que os dados não sejam replicados.
Permissões necessárias
| Ação | Permissões necessárias |
|---|---|
| Habilitar replicação de espaço de trabalho |
Microsoft.OperationalInsights/workspaces/write e Microsoft.Insights/dataCollectionEndpoints/write permissões, conforme fornecido pela função interna do Colaborador de Monitoramento, por exemplo |
| Alternar e voltar (iniciar failover e failback) |
Microsoft.OperationalInsights/locations/workspaces/failover, Microsoft.OperationalInsights/workspaces/failback, Microsoft.Insights/dataCollectionEndpoints/triggerFailover/action e Microsoft.Insights/dataCollectionEndpoints/triggerFailback/action permissões, conforme fornecido pela função interna Colaborador de Monitoramento, por exemplo |
| Verificar o estado do espaço de trabalho |
Microsoft.OperationalInsights/workspaces/readpermissões para o espaço de trabalho do Log Analytics, conforme fornecido pela função interna Colaborador de Monitorização, por exemplo |
Habilitar e desabilitar a replicação do espaço de trabalho
Você habilita e desabilita a replicação do espaço de trabalho usando um comando REST. O comando dispara uma operação de longa duração, o que significa que pode levar alguns minutos para que as novas configurações sejam aplicadas. Depois de habilitar a replicação, pode levar até uma hora para que todas as tabelas (tipos de dados) comecem a replicar, e alguns tipos de dados podem começar a replicar antes de outros. As alterações feitas nos esquemas de tabela depois de habilitar a replicação do espaço de trabalho - por exemplo, novas tabelas de log personalizadas ou campos personalizados criados ou logs de diagnóstico configurados para novos tipos de recursos - podem levar até uma hora para começar a replicar.
Usando um cluster dedicado?
Se o espaço de trabalho estiver vinculado a um cluster dedicado, você deverá primeiro habilitar a replicação no cluster e só depois no espaço de trabalho. Essa operação cria um segundo cluster em sua região secundária (sem custo extra além das taxas de replicação), para permitir que seu espaço de trabalho continue usando um cluster dedicado mesmo se você fizer failover. Isso também significa que recursos como chaves gerenciadas por cluster (CMK) continuam a funcionar (com a mesma chave) durante o failover. Quando a replicação entre regiões estiver habilitada, prossiga para habilitar a replicação para um ou mais espaços de trabalho vinculados a esse cluster.
Importante
Depois que a replicação em cluster estiver habilitada, alterar o destino da replicação requer desabilitar a replicação e reativá-la em um local diferente.
Para habilitar a replicação em seu cluster dedicado, use o seguinte comando PUT. Esta chamada devolve 202. É uma operação de longa execução que pode levar tempo para ser concluída, e você pode acompanhar seu estado exato conforme explicado em Verificar estado de provisionamento do cluster.
Para habilitar a replicação de cluster, use este PUT comando:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/clusters/<cluster_name>?api-version=2025-02-01
body:
{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}
Onde:
-
<subscription_id>: O ID de subscrição relacionado com o seu cluster -
<resourcegroup_name>: o grupo de recursos que contém o recurso de cluster do Log Analytics -
<cluster_name>: O nome do cluster dedicado -
<primary_region>: A região principal do cluster dedicado do Log Analytics -
<secondary_region>: A região na qual o Azure Monitor cria o cluster dedicado secundário
Verificar o estado de provisionamento do cluster
Para verificar o estado de provisionamento do cluster, execute este GET comando:
GET
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/clusters/<cluster_name>?api-version=2025-02-01
Onde:
-
<subscription_id>: O ID de subscrição relacionado com o seu cluster -
<resourcegroup_name>: o grupo de recursos que contém o recurso de cluster do Log Analytics -
<cluster_name>: O nome do cluster do Log Analytics
Use o GET comando para verificar se o estado de provisionamento do cluster muda de Updating para Succeeded, e se a região secundária está definida conforme o esperado.
Nota
Quando você habilita a replicação de cluster, um novo cluster está sendo provisionado no local secundário. Este processo pode levar de 1 a 2 horas.
Habilitar replicação de espaço de trabalho
Para habilitar a replicação no espaço de trabalho do Log Analytics, use este PUT comando:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2025-02-01
body:
{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}
Onde:
-
<subscription_id>: O ID de subscrição associado à sua área de trabalho -
<resourcegroup_name>: o grupo de recursos que contém o recurso de espaço de trabalho do Log Analytics -
<workspace_name>: O nome do seu espaço de trabalho -
<primary_region>: a região principal do espaço de trabalho do Log Analytics -
<secondary_region>: A região na qual o Azure Monitor cria o espaço de trabalho secundário
Para obter os valores suportados location , consulte Regiões suportadas.
O PUT comando é uma operação de longa duração que pode levar algum tempo para ser concluída. Uma chamada bem-sucedida retorna um código de 200 status. Você pode acompanhar o estado de provisionamento da sua solicitação, conforme descrito em Verificar estado de provisionamento do espaço de trabalho.
Importante
Se o espaço de trabalho estiver vinculado a um cluster dedicado, primeiro habilite a replicação no cluster. Observe também que o local secundário do seu espaço de trabalho deve ser idêntico ao local secundário do cluster dedicado.
Verificar o estado de provisionamento do espaço de trabalho
Para verificar o estado de provisionamento do seu espaço de trabalho, execute este GET comando:
GET
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>?api-version=2025-02-01
Onde:
-
<subscription_id>: O identificador da subscrição relacionado com a sua área de trabalho. -
<resourcegroup_name>: o grupo de recursos que contém o recurso de espaço de trabalho do Log Analytics. -
<workspace_name>: O nome do seu espaço de trabalho do Log Analytics.
Use o GET comando para verificar se o estado de provisionamento do espaço de trabalho muda de Updating para Succeeded, e se a região secundária está definida conforme o esperado.
Nota
Quando você habilita a replicação para espaços de trabalho que interagem com o Sentinel, pode levar até 12 dias para replicar totalmente os dados da Lista de observação e do Threat Intelligence para o espaço de trabalho secundário.
Verificar se a replicação está habilitada em um espaço de trabalho
Para verificar se e onde a replicação do espaço de trabalho está habilitada, revise essas configurações.
No portal do Azure, selecione Visão geral do espaço de trabalho>.
Se a replicação estiver habilitada, a seção Essentials exibirá o local Secundário, indicando a região do espaço de trabalho replicado.

A mesma seção Essentials tem uma exibição JSON que exibe os detalhes da replicação como um objeto JSON, que também está disponível via REST/CLI.

Associar regras de recolha de dados ao endpoint de recolha de dados no espaço de trabalho
O Agente de Monitor do Azure, a API de Ingestão de Logs e os Hubs de Eventos do Azure coletam dados e os enviam para o destino especificado com base em como você configura suas regras de coleta de dados (DCR).
Se você tiver regras de coleta de dados que enviam dados para seu espaço de trabalho principal, precisará associá-las a um ponto de extremidade de coleta de dados do sistema (DCE), que o Azure Monitor cria quando você habilita a replicação de espaço de trabalho. O ID do seu espaço de trabalho é idêntico ao nome do endpoint de coleta de dados do espaço de trabalho. Somente as regras de coleta de dados que associar ao endpoint de coleta de dados do espaço de trabalho permitem a replicação e a alternância. Esse comportamento permite especificar o conjunto de fluxos de log a serem replicados, o que ajuda a controlar os custos de replicação.
Para replicar dados coletados usando regras de coleta de dados, associe suas regras de coleta de dados ao ponto de extremidade de coleta de dados do espaço de trabalho:
No portal do Azure, selecione Regras de coleta de dados.
Na tela Regras de coleta de dados, selecione uma regra de coleta de dados que envie dados para seu espaço de trabalho principal do Log Analytics.
Na página Visão geral da regra de coleta de dados, selecione Configurar DCE e escolha o endpoint de coleta de dados do espaço de trabalho na lista disponível:
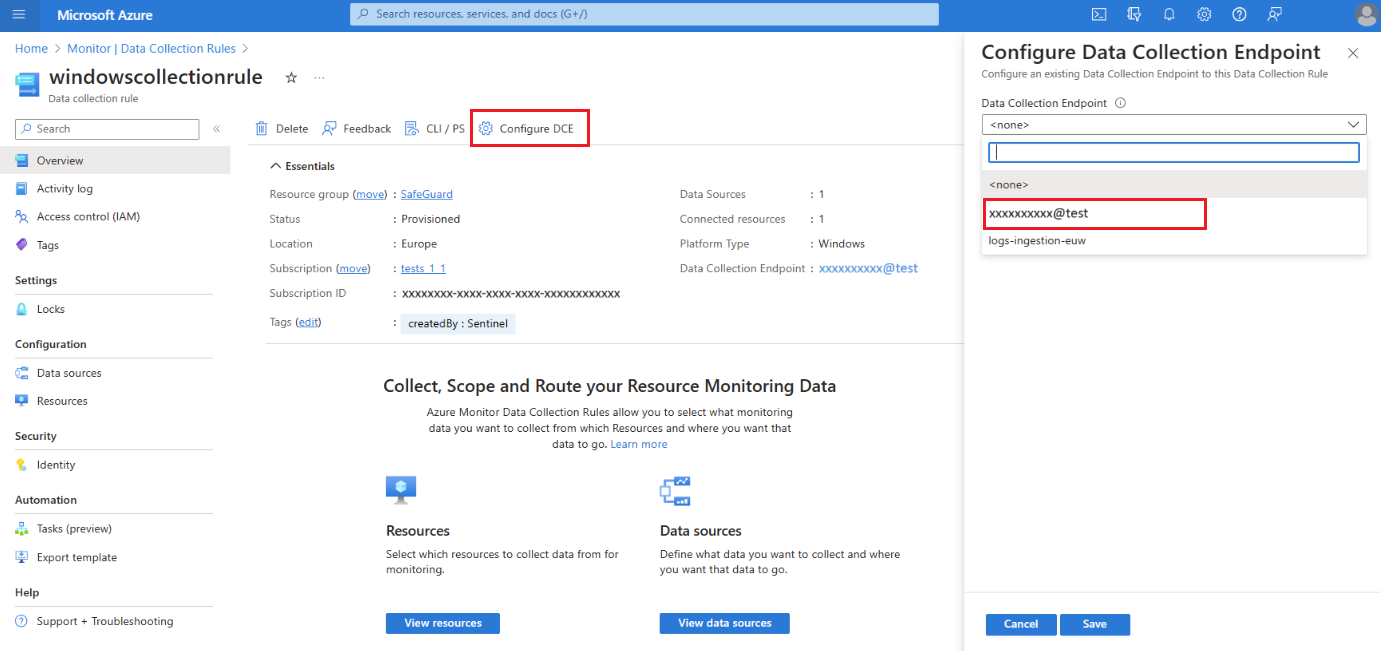
Para obter detalhes sobre o DCE do sistema, verifique as propriedades do objeto do espaço de trabalho.

Importante
As regras de coleta de dados conectadas a um ponto de extremidade de coleta de dados da área de trabalho podem ter como alvo apenas essa área de trabalho específica. As regras de coleta de dados não devem ter como destino outros destinos, como outros espaços de trabalho ou contas de Armazenamento do Azure.
O que verificar se a replicação do espaço de trabalho falhar
- O espaço de trabalho está vinculado a um cluster dedicado?
- A replicação deve ser habilitada no cluster antes de poder ser habilitada no espaço de trabalho.
- A replicação de cluster e de espaço de trabalho deve ser definida para a mesma localização secundária. Por exemplo, se o cluster for replicado para o Norte da Europa, os espaços de trabalho vinculados a ele só poderão ser replicados para o Norte da Europa também.
- Você usou a API REST para habilitar a replicação?
- Verifique se você usou a API versão 2025-02-01 ou posterior.
- O espaço de trabalho principal está localizado no Leste dos EUA, Leste dos EUA 2 ou Centro-Sul dos EUA?
- As regiões Leste dos EUA, Leste dos EUA 2 e Centro-Sul dos EUA não conseguem replicar dados entre si.
- Onde está localizado o espaço de trabalho principal e onde está o secundário? Ambos os locais devem estar no mesmo grupo de regiões. Por exemplo, espaços de trabalho localizados em regiões dos EUA não podem ter uma replicação (região secundária) na Europa e vice-versa. Para obter a lista de grupos de regiões, consulte Regiões suportadas.
- Você tem as permissões necessárias?
- Você deu tempo suficiente para que a operação de replicação fosse concluída? A replicação é uma operação de longa duração. Monitore o estado da operação conforme explicado em Verificar estado de provisionamento do espaço de trabalho.
- Você tentou reativar a replicação para alterar o local secundário do espaço de trabalho? Para alterar o local do espaço de trabalho secundário, você deve primeiro desabilitar a replicação do espaço de trabalho, permitir que a operação seja concluída e, só então, habilitar a replicação para outro local secundário.
O que verificar se a replicação do espaço de trabalho está configurada, mas os logs não são replicados?
- A replicação pode levar até uma hora para começar a ser aplicada, e alguns tipos de dados podem começar a ser replicados antes de outros.
- Os logs ingeridos no espaço de trabalho antes da replicação ser ativada não são copiados para o espaço de trabalho secundário. Somente os logs ingeridos após a ativação da replicação são replicados.
- Se alguns logs forem replicados e outros não, verifique se todas as DCRs (regras de coleta de dados) que transmitem logs para o espaço de trabalho estão configuradas corretamente. Para revisar os DCRs direccionados ao espaço de trabalho, consulte o separador Recolha de Dados do Log Analytics Workspace Insights no portal do Azure.
Desabilitar a replicação do espaço de trabalho
Para desabilitar a replicação de um espaço de trabalho, use este PUT comando:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2025-02-01
body:
{
"properties": {
"replication": {
"enabled": false
}
},
"location": "<primary_region>"
}
Onde:
-
<subscription_id>: O identificador da subscrição relacionado com a sua área de trabalho. -
<resourcegroup_name>: O grupo de recursos que contém os recursos do espaço de trabalho. -
<workspace_name>: O nome do seu espaço de trabalho. -
<primary_region>: A região principal do seu espaço de trabalho.
O PUT comando é uma operação de longa duração que pode levar algum tempo para ser concluída. Uma chamada bem-sucedida retorna um código de 200 status. Você pode acompanhar o estado de provisionamento da sua solicitação, conforme descrito em Verificar estado de provisionamento do espaço de trabalho.
Importante
Se estiveres a usar um cluster dedicado, deves desativar a replicação do cluster depois de desativares a replicação para cada espaço de trabalho ligado a este cluster.
Desabilitar a replicação de cluster
A desativação da replicação de cluster pode ser feita somente depois de desabilitar a replicação para todos os espaços de trabalho vinculados a esse cluster (se habilitado anteriormente).
Para desabilitar a replicação de um espaço de trabalho, use este PUT comando:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/clusters/<cluster_name>?api-version=2025-02-01
body:
{
"properties": {
"replication": {
"enabled": false
}
},
"location": "<primary_region>"
}
Onde:
-
<subscription_id>: A ID da subscrição relacionada ao seu cluster. -
<resourcegroup_name>: O grupo de recursos que contém o recurso de cluster. -
<workspace_name>: O nome do seu cluster. -
<primary_region>: A região primária do cluster.
O PUT comando é uma operação de longa duração que pode levar algum tempo para ser concluída. Uma chamada bem-sucedida retorna um código de 200 status. Você pode acompanhar o estado de provisionamento da sua solicitação, conforme descrito em Verificar estado de provisionamento do espaço de trabalho.
Nota
Depois que a replicação é desabilitada e o cluster replicado é limpo, os logs replicados são excluídos e não podem ser acessados novamente. A cópia original deles na sua localização principal não é alterada neste processo.
Importante
O processo de remoção da replicação de cluster leva 14 dias. Se você precisar que esse processo seja concluído mais rapidamente, crie uma solicitação de suporte do Azure.
Monitorizar a integridade do espaço de trabalho e do serviço
Latência de ingestão ou falhas de consulta são exemplos de problemas que muitas vezes podem ser resolvidos ao comutar para a sua região secundária. Esses problemas podem ser detetados usando notificações de integridade do serviço e consultas de registo.
As notificações de Integridade do Serviço são úteis para problemas relacionados com o serviço. Para identificar problemas que afetam seu espaço de trabalho específico (e possivelmente não todo o serviço), você pode usar outras medidas:
Crie alertas com base na saúde dos recursos do espaço de trabalho
Defina os seus próprios limites para métricas de integridade do espaço de trabalho
Crie suas próprias consultas de monitoramento para servir como indicadores de integridade personalizados para seu espaço de trabalho, conforme descrito em Monitorar o desempenho do espaço de trabalho usando consultas, para:
- Medir a latência de ingestão por tabela
- Identificar se a fonte da latência são os agentes de recolha ou o pipeline de ingestão
- Monitorar anomalias no volume de ingestão por tabela e recurso
- Monitorar a taxa de sucesso da consulta por tabela, usuário ou recurso
- Crie alertas com base nas suas consultas
Nota
Você também pode usar consultas de log para monitorar seu espaço de trabalho secundário, mas lembre-se de que a replicação de logs é feita em operações em lote. A latência medida pode flutuar e não indica nenhum problema de saúde com o seu espaço de trabalho secundário. Para obter mais informações, consulte Auditar o espaço de trabalho inativo.
Mude para a área de trabalho secundária
Durante a transição, a maioria das operações funciona da mesma forma que quando se utiliza o espaço de trabalho e a região principais. No entanto, algumas operações têm um comportamento ligeiramente diferente ou são bloqueadas. Para obter mais informações, consulte Considerações sobre implantação.
Quando devo mudar?
Você decide quando alternar para o espaço de trabalho secundário e voltar para o espaço de trabalho principal com base no monitoramento contínuo de desempenho e integridade e nos padrões e requisitos do sistema.
Há vários pontos a considerar no seu plano de transição, conforme descrito nas subsecções seguintes.
Tipo de problema e âmbito
O processo de alternância roteia solicitações de ingestão e consulta para sua região secundária, que geralmente ignora qualquer componente defeituoso que esteja causando latência ou falha na sua região primária. Como resultado, a transição provavelmente não ajudará se:
- Há um problema inter-regional com um recurso subjacente. Por exemplo, se os mesmos tipos de recursos falharem nas regiões primária e secundária.
- Você encontra um problema relacionado ao gerenciamento do espaço de trabalho, como alterar a política de retenção do espaço de trabalho. As operações de gestão de espaço de trabalho são sempre tratadas na sua região principal. Durante a transição, as operações de gerenciamento do espaço de trabalho são bloqueadas.
Duração do problema
A transição não é instantânea. O processo de reencaminhamento de pedidos depende de atualizações de DNS, que alguns clientes captam em poucos minutos, enquanto outros podem demorar mais tempo. Portanto, é útil entender se o problema pode ser resolvido em poucos minutos. Se o problema observado for consistente ou contínuo, não espere para fazer a mudança. Seguem-se alguns exemplos:
Ingestão: Problemas com o pipeline de ingestão na região principal podem impactar a replicação de dados no espaço de trabalho secundário. Durante a transição, os logs são enviados, em vez disso, para o pipeline de ingestão na região secundária.
Consulta: Se as consultas no ambiente de trabalho principal falharem ou expirarem, os alertas de pesquisa de log poderão ser afetados. Nesse cenário, alterne para o espaço de trabalho secundário para garantir que todos os alertas sejam acionados corretamente.
Dados do espaço de trabalho secundário
Os logs ingeridos no espaço de trabalho principal antes de habilitar a replicação não são copiados para o espaço de trabalho secundário. Se você habilitou a replicação do espaço de trabalho há três horas e agora alterna para o espaço de trabalho secundário, suas consultas só poderão retornar dados das últimas três horas.
Antes de mudar regiões durante a mudança, o espaço de trabalho secundário precisa conter um número suficiente de logs. Recomendamos aguardar pelo menos uma semana após ativar a replicação antes de iniciar a alternância. Os sete dias permitem que dados suficientes estejam disponíveis na sua região secundária.
Iniciar troca automática
Antes de alternar, confirme se a operação de replicação do espaço de trabalho foi concluída com êxito. A mudança só é bem-sucedida quando o espaço de trabalho secundário está configurado corretamente.
Para alternar para o espaço de trabalho secundário, use este POST comando:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/locations/<secondary_region>/workspaces/<workspace_name>/failover?api-version=2025-02-01
Onde:
-
<subscription_id>: O identificador da subscrição relacionado com a sua área de trabalho. -
<resourcegroup_name>: O grupo de recursos que contém os recursos do espaço de trabalho. -
<secondary_region>: A região para a qual mudar durante a transição. -
<workspace_name>: O nome do espaço de trabalho para o qual alternar durante a mudança.
O POST comando é uma operação de longa duração que pode levar algum tempo para ser concluída. Uma chamada bem-sucedida retorna um código de 202 status. Você pode acompanhar o estado de provisionamento da sua solicitação, conforme descrito em Verificar estado de provisionamento do espaço de trabalho.
O que verificar se a transição (failover) falhar
- Você usou a API REST para acionar a mudança (failover)?
- Verifique se você usou a API versão 2025-02-01 ou posterior.
- Verifique se o local secundário fornecido no comando failover é o local secundário definido para este espaço de trabalho. Essas informações estão disponíveis na visualização do portal do Azure do espaço de trabalho e através da API.
- A alternância de regiões requer uma função de Colaborador do Log Analytics no grupo de recursos do espaço de trabalho, e não apenas no espaço de trabalho em si.
Voltar ao espaço de trabalho principal
O processo de reversão cancela o redirecionamento de consultas e solicitações de ingestão de registos para o espaço de trabalho secundário. Quando mudar de volta, o Azure Monitor volta a encaminhar consultas e solicitações de ingestão de logs para o seu espaço de trabalho principal.
Quando muda para a sua região secundária, o Azure Monitor replica os logs do espaço de trabalho secundário para o espaço de trabalho principal. Se uma interrupção afetar o processo de ingestão de logs na região primária, pode levar tempo para que o Azure Monitor conclua a ingestão dos logs replicados em seu espaço de trabalho principal.
Quando devo voltar atrás?
Há vários pontos a considerar no plano de retorno, conforme descrito nas subseções a seguir.
Estado de replicação do log
Antes de voltar, verifique se o Azure Monitor concluiu a replicação de todos os logs ingeridos durante a transição para a região primária. Se regressar antes que todos os registos sejam replicados para o workspace principal, as suas consultas poderão retornar resultados parciais até que a ingestão de registos seja concluída.
Você pode consultar seu espaço de trabalho principal no portal do Azure para a região inativa, conforme descrito em Auditar o espaço de trabalho inativo.
Integridade do espaço de trabalho primário
Há dois itens de saúde importantes para verificar na preparação para o regresso ao seu espaço de trabalho principal.
- Confirme se não há notificações pendentes de Saúde do Serviço para o espaço de trabalho e a região principais.
- Confirme se seu espaço de trabalho principal está ingerindo logs e processando consultas conforme o esperado.
Para obter exemplos de como consultar o espaço de trabalho principal quando o espaço de trabalho secundário estiver ativo e ignorar o redirecionamento de solicitações para o espaço de trabalho secundário, consulte Auditar o espaço de trabalho inativo.
Acionamento de reversão
Antes de voltar atrás, confirme a integridade do espaço de trabalho primário e conclua a replicação dos logs.
O processo de switchback atualiza seus registros DNS. Após a atualização dos registros DNS, pode levar tempo para que todos os clientes recebam as configurações de DNS atualizadas e retomem o roteamento para o espaço de trabalho principal.
Para voltar ao espaço de trabalho principal, use este POST comando:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>/failback?api-version=2025-02-01
Onde:
-
<subscription_id>: O identificador da subscrição relacionado com a sua área de trabalho. -
<resourcegroup_name>: O grupo de recursos que contém os recursos do espaço de trabalho. -
<workspace_name>: O nome do espaço de trabalho para o qual mudar durante o retorno.
O POST comando é uma operação de longa duração que pode levar algum tempo para ser concluída. Uma chamada bem-sucedida retorna um código de 202 status. Você pode acompanhar o estado de provisionamento da sua solicitação, conforme descrito em Verificar estado de provisionamento do espaço de trabalho.
Auditar o espaço de trabalho inativo
Por padrão, a região ativa do seu espaço de trabalho é a região onde você cria o espaço de trabalho e a região inativa é a região secundária, onde o Azure Monitor cria o espaço de trabalho replicado.
Quando você aciona o failover, isso muda – a região secundária é ativada e a região primária fica inativa. Dizemos que ele está inativo porque não é o alvo direto da ingestão de logs e solicitações de consulta.
É útil consultar a região inativa antes de alternar entre regiões para verificar se o espaço de trabalho na região inativa tem os logs que você espera ver lá.
Consultar região inativa
Para consultar dados de log na região inativa, use este comando GET:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=<query>×pan=<timespan-in-ISO8601-format>&overrideWorkspaceRegion=<primary|secondary>
Por exemplo, para executar uma consulta curta como Perf | count a do dia anterior na sua região secundária, use:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=Perf%20|%20count×pan=P1D&overrideWorkspaceRegion=secondary
Você pode confirmar se o Azure Monitor executa sua consulta na região pretendida verificando estes campos na tabela, que é criada quando você habilita a LAQueryLogs auditoria de consulta em seu espaço de trabalho do Log Analytics:
-
isWorkspaceInFailover: Indica se o espaço de trabalho estava no modo de transferência durante a consulta. O tipo de dados é booleano (True, False). -
workspaceRegion: A região do espaço de trabalho alvo da consulta. O tipo de dados é String.
Monitorar o desempenho do espaço de trabalho usando consultas
Recomendamos usar as consultas nesta seção para criar regras de alerta que o notifiquem sobre possíveis problemas de integridade ou desempenho do espaço de trabalho. No entanto, a decisão de mudar requer uma consideração cuidadosa e não deve ser tomada automaticamente.
Na regra de consulta, você pode definir uma condição para alternar para o espaço de trabalho secundário após um número especificado de violações. Para obter mais informações, consulte Criar ou editar uma regra de alerta de pesquisa de log.
Duas medições significativas do desempenho do espaço de trabalho incluem latência de ingestão e volume de ingestão. As seções a seguir exploram essas opções de monitoramento.
Monitore a latência de ingestão de ponta a ponta
A latência de processamento mede o tempo necessário para processar os logs no espaço de trabalho. A medição de tempo começa quando o evento inicial registrado ocorre e termina quando o log é armazenado em seu espaço de trabalho. A latência total de ingestão é composta por duas partes:
- Latência do agente: o tempo necessário pelo agente para relatar um evento.
- Latência do pipeline de ingestão (back-end): o tempo necessário para o pipeline de ingestão processar os logs e escrevê-los no seu espaço de trabalho.
Diferentes tipos de dados têm latência de ingestão diferente. Você pode medir a ingestão para cada tipo de dados separadamente ou criar uma consulta genérica para todos os tipos e uma consulta mais refinada para tipos específicos que são de maior importância para você. Sugerimos que meça o percentil 90 da latência de ingestão, que é mais sensível à mudança do que a média ou o percentil 50 (mediana).
As secções seguintes mostram como usar consultas para verificar a latência de ingestão do seu espaço de trabalho.
Avaliar a latência de ingestão basal de tabelas específicas
Comece determinando a latência da linha de base de tabelas específicas ao longo de vários dias.
Esta consulta de exemplo cria um gráfico do 90º percentil da latência de ingestão na tabela Perf.
// Assess the ingestion latency baseline for a specific data type
Perf
| where TimeGenerated > ago(3d)
| project TimeGenerated,
IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize LatencyIngestion90Percentile=percentile(IngestionDurationSeconds, 90) by bin(TimeGenerated, 1h)
| render timechart
Depois de executar a consulta, revise os resultados e o gráfico renderizado para determinar a latência esperada para essa tabela.
Monitorizar e alertar sobre a latência de ingestão atual
Depois de estabelecer a latência de ingestão da linha de base para uma tabela específica, crie uma regra de alerta de pesquisa de log para a tabela com base em alterações na latência durante um curto período de tempo.
Esta consulta calcula a latência de ingestão nos últimos 20 minutos:
// Track the recent ingestion latency (in seconds) of a specific table
Perf
| where TimeGenerated > ago(20m)
| extend IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize Ingestion90Percent_seconds=percentile(IngestionDurationSeconds, 90)
Como você pode esperar algumas flutuações, crie uma condição de regra de alerta para verificar se a consulta retorna um valor significativamente maior do que a linha de base.
Determinar a origem da latência de ingestão
Quando der conta de que a latência total de ingestão está a aumentar, poderá usar consultas para determinar se a origem da latência são os agentes ou o pipeline de ingestão.
Esta consulta mapeia a latência no 90.º percentil dos agentes e do pipeline, separadamente.
// Assess agent and pipeline (backend) latency
Perf
| where TimeGenerated > ago(1h)
| extend AgentLatencySeconds = (_TimeReceived-TimeGenerated)/1s,
PipelineLatencySeconds=(ingestion_time()-_TimeReceived)/1s
| summarize percentile(AgentLatencySeconds,90), percentile(PipelineLatencySeconds,90) by bin(TimeGenerated,5m)
| render columnchart
Nota
Embora o gráfico exiba os dados do percentil 90 como colunas empilhadas, a soma dos dados nos dois gráficos não é igual ao percentil 90 da ingestão total .
Monitorizar o volume de ingestão
As medições do volume de ingestão podem ajudar a identificar alterações inesperadas no volume de ingestão total ou específico da tabela para o seu espaço de trabalho. As medições de volume de consulta podem ajudá-lo a identificar problemas de desempenho com a ingestão de logs. Algumas medições de volume úteis incluem:
- Volume total de ingestão por tabela
- Volume de ingestão constante (paragem)
- Anomalias de ingestão - picos e quedas no volume de ingestão
As seções a seguir demonstram como usar consultas para verificar o volume de ingestão para o seu espaço de trabalho.
Monitorizar o volume total de ingestão por tabela
Você pode definir uma consulta para monitorizar o volume de ingestão por tabela na sua área de trabalho. A consulta pode incluir um alerta que verifica se há alterações inesperadas nos volumes totais ou específicos da tabela.
Esta consulta calcula o volume total de ingestão na última hora por tabela em megabytes por segundo (MBs):
// Calculate total ingestion volume over the past hour per table
Usage
| where TimeGenerated > ago(1h)
| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated,1h), DataType
Verificar se há interrupção na ingestão
Se ingerires logs através de agentes, podes usar o "heartbeat" do agente para detetar a conectividade. Um batimento cardíaco parado pode revelar uma interrupção na ingestão de logs no seu espaço de trabalho. Quando os dados da consulta revelam uma paralisação de ingestão, você pode definir uma condição para disparar uma resposta desejada.
A consulta a seguir verifica a pulsação do agente para detetar problemas de conectividade:
// Count agent heartbeats in the last ten minutes
Heartbeat
| where TimeGenerated>ago(10m)
| count
Monitorizar anomalias de ingestão
Pode identificar picos e quedas no volume de dados ingeridos do seu espaço de trabalho de várias maneiras. Utilize a função series_decompose_anomalies() para extrair anomalias dos volumes de ingestão que o utilizador monitora no seu espaço de trabalho, ou crie o seu próprio detetor de anomalias para suportar os cenários exclusivos do espaço de trabalho.
Identificar anomalias usando series_decompose_anomalies
A series_decompose_anomalies() função identifica anomalias em uma série de valores de dados. Essa consulta calcula o volume de ingestão por hora de cada tabela no espaço de trabalho do Log Analytics e usa series_decompose_anomalies() para identificar anomalias:
// Calculate hourly ingestion volume per table and identify anomalies
Usage
| where TimeGenerated > ago(24h)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| summarize
Timestamp=make_list(TimeGenerated),
IngestionVolumeMB=make_list(IngestionVolumeMB)
by DataType
| extend series_decompose_anomalies(IngestionVolumeMB)
| mv-expand
Timestamp,
IngestionVolumeMB,
series_decompose_anomalies_IngestionVolumeMB_ad_flag,
series_decompose_anomalies_IngestionVolumeMB_ad_score,
series_decompose_anomalies_IngestionVolumeMB_baseline
| where series_decompose_anomalies_IngestionVolumeMB_ad_flag != 0
Para obter mais informações sobre como usar series_decompose_anomalies() para detetar anomalias em dados de log, consulte Detetar e analisar anomalias usando recursos de aprendizado de máquina KQL no Azure Monitor.
Crie o seu próprio detetor de anomalias
Você pode criar um detetor de anomalias personalizado para dar suporte aos requisitos de cenário para a configuração do espaço de trabalho. Esta seção fornece um exemplo para demonstrar o processo.
A consulta a seguir calcula:
- Volume de ingestão esperado: Por hora, por tabela (com base na mediana das medianas, mas você pode personalizar a lógica)
- Volume de ingestão real: Por hora, por tabela
Para filtrar diferenças insignificantes entre o volume de ingestão esperado e real, a consulta aplica dois filtros:
- Taxa de variação: Mais de 150% ou menos de 66% do volume esperado, por tabela
- Volume de variação: indica se o volume aumentado ou diminuído é superior a 0,1% do volume mensal desse quadro
// Calculate expected vs actual hourly ingestion per table
let TimeRange=24h;
let MonthlyIngestionByType=
Usage
| where TimeGenerated > ago(30d)
| summarize MonthlyIngestionMB=sum(Quantity) by DataType;
// Calculate the expected ingestion volume by median of hourly medians
let ExpectedIngestionVolumeByType=
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionMedian=percentile(Quantity, 50) by bin(TimeGenerated, 1h), DataType
| summarize ExpectedIngestionVolumeMB=percentile(IngestionMedian, 50) by DataType;
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| join kind=inner (ExpectedIngestionVolumeByType) on DataType
| extend GapVolumeMB = round(IngestionVolumeMB-ExpectedIngestionVolumeMB,2)
| where GapVolumeMB != 0
| extend Trend=iff(GapVolumeMB > 0, "Up", "Down")
| extend IngestedVsExpectedAsPercent = round(IngestionVolumeMB * 100 / ExpectedIngestionVolumeMB, 2)
| join kind=inner (MonthlyIngestionByType) on DataType
| extend GapAsPercentOfMonthlyIngestion = round(abs(GapVolumeMB) * 100 / MonthlyIngestionMB, 2)
| project-away DataType1, DataType2
// Determine whether the spike/deep is substantial: over 150% or under 66% of the expected volume for this data type
| where IngestedVsExpectedAsPercent > 150 or IngestedVsExpectedAsPercent < 66
// Determine whether the gap volume is significant: over 0.1% of the total monthly ingestion volume to this workspace
| where GapAsPercentOfMonthlyIngestion > 0.1
| project
Timestamp=format_datetime(todatetime(TimeGenerated), 'yyyy-MM-dd HH:mm:ss'),
Trend,
IngestionVolumeMB,
ExpectedIngestionVolumeMB,
IngestedVsExpectedAsPercent,
GapAsPercentOfMonthlyIngestion
Monitorar o sucesso e a falha da consulta
Cada consulta retorna um código de resposta que indica sucesso ou falha. Quando a consulta falha, a resposta também inclui os tipos de erro. Uma alta onda de erros pode indicar um problema com a disponibilidade do espaço de trabalho ou o desempenho do serviço.
Esta consulta conta quantas consultas retornaram um código de erro do servidor:
// Count query errors
LAQueryLogs
| where ResponseCode>=500 and ResponseCode<600
| count