Desenvolver um aplicativo Kubernetes para o Banco de Dados SQL do Azure
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Neste tutorial, saiba como desenvolver um aplicativo moderno usando Python, Docker Containers, Kubernetes e Banco de Dados SQL do Azure.
O desenvolvimento de aplicações modernas tem vários desafios. Desde a seleção de uma "pilha" de front-end, passando pelo armazenamento e processamento de dados de vários padrões concorrentes, até a garantia dos mais altos níveis de segurança e desempenho, os desenvolvedores são obrigados a garantir que o aplicativo seja dimensionado e tenha um bom desempenho e seja compatível em várias plataformas. Para esse último requisito, agrupar o aplicativo em tecnologias de contêiner, como o Docker, e implantar vários contêineres na plataforma Kubernetes é agora essencial para o desenvolvimento de aplicativos.
Neste exemplo, exploramos o uso de Python, Docker Containers e Kubernetes - todos em execução na plataforma Microsoft Azure. Usar o Kubernetes significa que você também tem a flexibilidade de usar ambientes locais ou até mesmo outras nuvens para uma implantação contínua e consistente de seu aplicativo, e permite implantações multicloud para resiliência ainda maior. Também usaremos o Banco de Dados SQL do Microsoft Azure para um ambiente baseado em serviços, escalável, altamente resiliente e seguro para o armazenamento e processamento de dados. Na verdade, em muitos casos, outros aplicativos já estão usando o Banco de dados SQL do Microsoft Azure, e esse aplicativo de exemplo pode ser usado para usar e enriquecer ainda mais esses dados.
Este exemplo é bastante abrangente em escopo, mas usa o aplicativo, o banco de dados e a implantação mais simples para ilustrar o processo. Você pode adaptar essa amostra para ser muito mais robusta, inclusive usando as tecnologias mais recentes para os dados retornados. É uma ferramenta de aprendizagem útil para criar um padrão para outras aplicações.
Use Python, Docker Containers, Kubernetes e o banco de dados de exemplo AdventureWorksLT em um exemplo prático
A empresa AdventureWorks (fictícia) utiliza uma base de dados que armazena dados sobre Vendas e Marketing, Produtos, Clientes e Fabrico. Ele também contém exibições e procedimentos armazenados que unem informações sobre os produtos, como o nome do produto, categoria, preço e uma breve descrição.
A equipe de desenvolvimento do AdventureWorks deseja criar uma prova de conceito (PoC) que retorna dados de uma exibição no AdventureWorksLT banco de dados e disponibilizá-los como uma API REST. Usando esta PoC, a equipe de desenvolvimento criará um aplicativo mais escalável e pronto para multicloud para a equipe de vendas. Eles selecionaram a plataforma Microsoft Azure para todos os aspetos da implantação. A PoC está usando os seguintes elementos:
- Um aplicativo Python usando o pacote Flask para implantação web headless.
- Docker Containers para código e isolamento de ambiente, armazenados em um registro privado para que toda a empresa possa reutilizar os contêineres do aplicativo em projetos futuros, economizando tempo e dinheiro.
- Kubernetes para facilitar a implantação e escalar e para evitar o bloqueio da plataforma.
- Banco de dados SQL do Microsoft Azure para seleção de tamanho, desempenho, escala, gerenciamento automático e backup, além de armazenamento e processamento de dados relacionais no mais alto nível de segurança.
Neste artigo, explicamos o processo de criação de todo o projeto de prova de conceito. As etapas gerais para criar o aplicativo são:
- Configurar pré-requisitos
- Criar o aplicativo
- Criar um contêiner do Docker para implantar o aplicativo e testar
- Criar um Registro do Serviço de Contêiner do Azure (ACS) e carregar o Contêiner no Registro do ACS
- Criar o ambiente do Serviço Kubernetes do Azure (AKS)
- Implantar o contêiner de aplicativos do Registro ACS no AKS
- Testar a aplicação
- Limpeza
Pré-requisitos
Ao longo deste artigo, existem vários valores que deve substituir. Certifique-se de substituir consistentemente esses valores para cada etapa. Talvez você queira abrir um editor de texto e soltar esses valores para definir os valores corretos enquanto trabalha no projeto de prova de conceito:
ReplaceWith_AzureSubscriptionName: Substitua esse valor pelo nome da assinatura do Azure que você tem.ReplaceWith_PoCResourceGroupName: Substitua esse valor pelo nome do grupo de recursos que você deseja criar.ReplaceWith_AzureSQLDBServerName: Substitua esse valor pelo nome do servidor lógico do Banco de Dados SQL do Azure que você cria usando o portal do Azure.ReplaceWith_AzureSQLDBSQLServerLoginName: Substitua esse valor pelo valor do nome de usuário do SQL Server criado no portal do Azure.ReplaceWith_AzureSQLDBSQLServerLoginPassword: Substitua esse valor pelo valor da senha de usuário do SQL Server criada no portal do Azure.ReplaceWith_AzureSQLDBDatabaseName: Substitua esse valor pelo nome do Banco de Dados SQL do Azure que você cria usando o portal do Azure.ReplaceWith_AzureContainerRegistryName: Substitua esse valor pelo nome do Registro de Contêiner do Azure que você gostaria de criar.ReplaceWith_AzureKubernetesServiceName: Substitua esse valor pelo nome do Serviço Kubernetes do Azure que você gostaria de criar.
Os desenvolvedores da AdventureWorks usam uma mistura de sistemas Windows, Linux e Apple para desenvolvimento, então eles estão usando o Visual Studio Code como seu ambiente e git para o controle do código-fonte, ambos executados entre plataformas.
Para o PoC, a equipe requer os seguintes pré-requisitos:
Python, pip e pacotes - A equipe de desenvolvimento escolhe a linguagem de programação Python como o padrão para esta aplicação baseada na web. Atualmente eles estão usando a versão 3.9, mas qualquer versão que suporte os pacotes necessários PoC é aceitável.
- Você pode baixar Python versão 3.9 do python.org.
A equipe está usando o pacote para acesso ao
pyodbcbanco de dados.- Você pode instalar o pacote pyodbc com comandos pip.
- Você também pode precisar do software Microsoft ODBC Driver se ainda não o tiver instalado.
A equipe está usando o
ConfigParserpacote para controlar e definir variáveis de configuração.- Você pode instalar o pacote configparser com comandos pip.
A equipe está usando o pacote Flask para uma interface web para o aplicativo.
- Você pode instalar a versão Python da biblioteca Flask.
Em seguida, a equipe instalou a ferramenta CLI do Azure, facilmente identificada com
aza sintaxe. Essa ferramenta multiplataforma permite uma abordagem de linha de comando e script para a PoC, para que eles possam repetir as etapas à medida que fazem alterações e melhorias.- Você pode baixar e instalar a ferramenta CLI do Azure.
Com a CLI do Azure configurada, a equipa inicia sessão na respetiva subscrição do Azure e define o nome da subscrição que utilizou para a PoC. Em seguida, eles garantiram que o servidor e o banco de dados do Banco de Dados SQL do Azure estivessem acessíveis à assinatura:
az login az account set --name "ReplaceWith_AzureSubscriptionName" az sql server list az sql db list ReplaceWith_AzureSQLDBDatabaseNameUm Grupo de Recursos do Microsoft Azure é um contêiner lógico que contém recursos relacionados para uma solução do Azure. Geralmente, os recursos que compartilham o mesmo ciclo de vida são adicionados ao mesmo grupo de recursos para que você possa implantá-los, atualizá-los e excluí-los facilmente como um grupo. O grupo de recursos armazena metadados sobre os recursos e você pode especificar um local para o grupo de recursos.
Os grupos de recursos podem ser criados e gerenciados usando o portal do Azure ou a CLI do Azure. Eles também podem ser usados para agrupar recursos relacionados para um aplicativo e dividi-los em grupos para produção e não produção, ou qualquer outra estrutura organizacional de sua preferência.
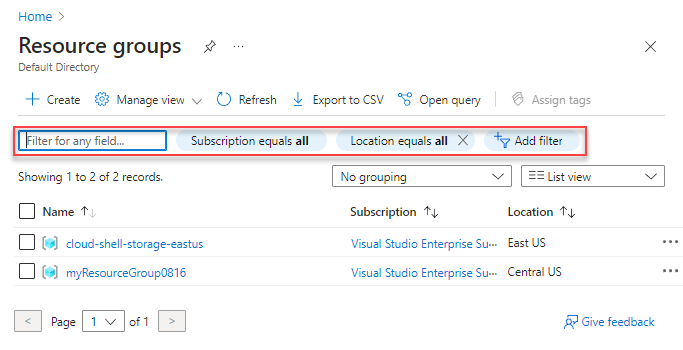
No trecho de código a seguir, você pode ver o
azcomando usado para criar um grupo de recursos. Em nosso exemplo, usamos a região eastusdo Azure.az group create --name ReplaceWith_PoCResourceGroupName --location eastusA equipe de desenvolvimento cria um Banco de Dados SQL do Azure com o
AdventureWorksLTbanco de dados de exemplo instalado, usando um logon autenticado SQL.A AdventureWorks padronizou a plataforma Microsoft SQL Server Relational Database Management System, e a equipe de desenvolvimento deseja usar um serviço gerenciado para o banco de dados em vez de instalar localmente. O uso do Banco de Dados SQL do Azure permite que esse serviço gerenciado seja completamente compatível com código onde quer que eles executem o mecanismo do SQL Server: localmente, em um contêiner, no Linux ou no Windows, ou até mesmo em um ambiente de Internet das Coisas (IoT).
Durante a criação, eles usaram o Portal de Gerenciamento do Azure para definir o Firewall do aplicativo para a máquina de desenvolvimento local e alteraram o padrão que você vê aqui para habilitar Permitir todos os Serviços do Azure e também recuperaram as credenciais de conexão.
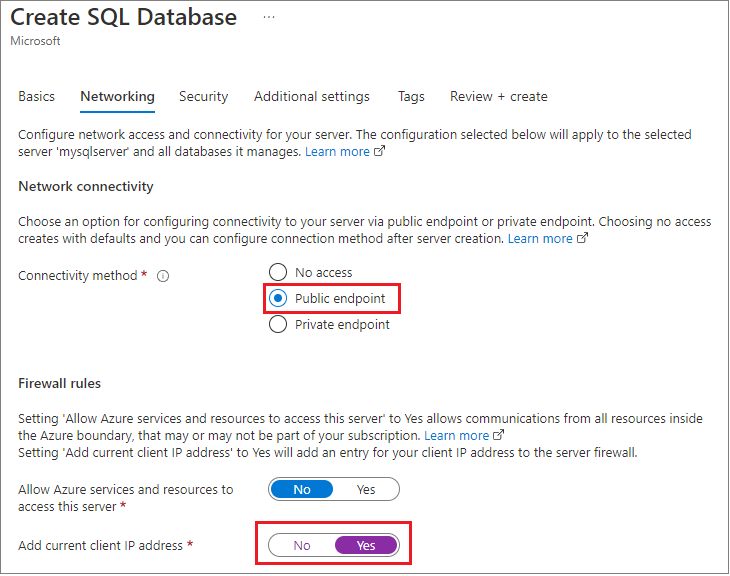
Com essa abordagem, o banco de dados poderia ser acessível em outra região ou até mesmo em uma assinatura diferente.
A equipe configurou um logon autenticado SQL para teste, mas revisitará essa decisão em uma revisão de segurança.
A equipe usou o banco de dados de exemplo
AdventureWorksLTpara a PoC usando o mesmo grupo de recursos da PoC. Não se preocupe, no final deste tutorial, limparemos todos os recursos deste novo grupo de recursos PoC.Você pode usar o portal do Azure para implantar o Banco de Dados SQL do Azure. Ao criar o Banco de Dados SQL do Azure, na guia Configurações adicionais, para a opção Usar dados existentes, selecione Exemplo.

Finalmente, na guia Tags do novo Banco de Dados SQL do Azure, a equipe de desenvolvimento forneceu metadados de tags para esse recurso do Azure, como Owner ou ServiceClass ou WorkloadName.

Criar a aplicação
Em seguida, a equipe de desenvolvimento criou um aplicativo Python simples que abre uma conexão com o Banco de Dados SQL do Azure e retorna uma lista de produtos. Esse código será substituído por funções mais complexas e também pode incluir mais de um aplicativo implantado nos Kubernetes Pods em produção para uma abordagem robusta e orientada por manifesto para soluções de aplicativos.
A equipe criou um arquivo de texto simples chamado
.envpara armazenar variáveis para as conexões do servidor e outras informações. Usando apython-dotenvbiblioteca, eles podem separar as variáveis do código Python. Esta é uma abordagem comum para manter segredos e outras informações fora do próprio código.SQL_SERVER_ENDPOINT = ReplaceWith_AzureSQLDBServerName SQL_SERVER_USERNAME = ReplaceWith_AzureSQLDBSQLServerLoginName SQL_SERVER_PASSWORD = ReplaceWith_AzureSQLDBSQLServerLoginPassword SQL_SERVER_DATABASE = ReplaceWith_AzureSQLDBDatabaseNameAtenção
Para maior clareza e simplicidade, este aplicativo está usando um arquivo de configuração que é lido do Python. Como o código será implantado com o contêiner, as informações de conexão poderão derivar do conteúdo. Você deve considerar cuidadosamente os vários métodos de trabalho com segurança, conexões e segredos e determinar o melhor nível e mecanismo que você deve usar para o nosso aplicativo. Escolha sempre o mais alto nível de segurança e até mesmo vários níveis para garantir que seu aplicativo esteja seguro. Você tem várias opções de trabalhar com informações secretas, como cadeias de conexão e similares, e a lista a seguir mostra algumas dessas opções.
Para obter mais informações, consulte Segurança do Banco de Dados SQL do Azure.
- Outro método para trabalhar com segredos em Python é usar a biblioteca python-secrets.
- Analise a segurança e os segredos do Docker.
- Reveja os segredos do Kubernetes.
- Você também pode saber mais sobre a autenticação do Microsoft Entra (anteriormente Azure Ative Directory).
Em seguida, a equipe escreveu o aplicativo PoC e o
app.pychamou de .O script a seguir realiza estas etapas:
- Configure as bibliotecas para as interfaces Web de configuração e base.
- Carregue as variáveis do
.envarquivo. - Crie o aplicativo Flask-RESTful.
- Obtenha informações de conexão do Banco de Dados SQL do Azure usando os valores de
config.iniarquivo. - Crie conexão com o Banco de Dados SQL do Azure usando os valores de
config.iniarquivo. - Conecte-se ao Banco de Dados SQL do Azure usando o
pyodbcpacote. - Crie a consulta SQL para ser executada no banco de dados.
- Crie a classe que será usada para retornar os dados da API.
- Defina o ponto de extremidade da API para a
Productsclasse. - Finalmente, inicie o aplicativo na porta padrão Flask 5000.
# Set up the libraries for the configuration and base web interfaces from dotenv import load_dotenv from flask import Flask from flask_restful import Resource, Api import pyodbc # Load the variables from the .env file load_dotenv() # Create the Flask-RESTful Application app = Flask(__name__) api = Api(app) # Get to Azure SQL Database connection information using the config.ini file values server_name = os.getenv('SQL_SERVER_ENDPOINT') database_name = os.getenv('SQL_SERVER_DATABASE') user_name = os.getenv('SQL_SERVER_USERNAME') password = os.getenv('SQL_SERVER_PASSWORD') # Create connection to Azure SQL Database using the config.ini file values ServerName = config.get('Connection', 'SQL_SERVER_ENDPOINT') DatabaseName = config.get('Connection', 'SQL_SERVER_DATABASE') UserName = config.get('Connection', 'SQL_SERVER_USERNAME') PasswordValue = config.get('Connection', 'SQL_SERVER_PASSWORD') # Connect to Azure SQL Database using the pyodbc package # Note: You may need to install the ODBC driver if it is not already there. You can find that at: # https://learn.microsoft.com/sql/connect/odbc/download-odbc-driver-for-sql-server connection = pyodbc.connect(f'Driver=ODBC Driver 17 for SQL Server;Server={ServerName};Database={DatabaseName};uid={UserName};pwd={PasswordValue}') # Create the SQL query to run against the database def query_db(): cursor = connection.cursor() cursor.execute("SELECT TOP (10) [ProductID], [Name], [Description] FROM [SalesLT].[vProductAndDescription] WHERE Culture = 'EN' FOR JSON AUTO;") result = cursor.fetchone() cursor.close() return result # Create the class that will be used to return the data from the API class Products(Resource): def get(self): result = query_db() json_result = {} if (result == None) else json.loads(result[0]) return json_result, 200 # Set the API endpoint to the Products class api.add_resource(Products, '/products') # Start App on default Flask port 5000 if __name__ == "__main__": app.run(debug=True)Eles verificaram se esse aplicativo é executado localmente e retorna uma página para
http://localhost:5000/products.
Importante
Ao criar aplicativos de produção, não use a conta de administrador para acessar o banco de dados. Para obter mais informações, leia mais sobre como configurar uma conta para seu aplicativo. O código neste artigo é simplificado para que você possa começar rapidamente com aplicativos que usam Python e Kubernetes no Azure.
De forma mais realista, você poderia usar um usuário de banco de dados contido com permissões somente leitura ou um usuário de banco de dados contido ou de login conectado a uma identidade gerenciada atribuída pelo usuário com permissões somente leitura.
Para obter mais informações, revise um exemplo completo sobre como criar API com Python e Banco de Dados SQL do Azure.

Implantar o aplicativo em um contêiner do Docker
Um contêiner é um espaço reservado e protegido em um sistema de computação que fornece isolamento e encapsulamento. Para criar um contêiner, use um arquivo de manifesto, que é simplesmente um arquivo de texto descrevendo os binários e o código que você deseja conter. Usando um Container Runtime (como o Docker), você pode criar uma imagem binária com todos os arquivos que deseja executar e referenciar. A partir daí, você pode "executar" a imagem binária, e isso é chamado de Container, que você pode referenciar como se fosse um sistema de computação completo. É uma maneira menor e mais simples de abstrair os tempos de execução e o ambiente do aplicativo do que usar uma máquina virtual completa. Para obter mais informações, consulte Contêineres e Docker.
A equipe começou com um DockerFile (o Manifesto) que coloca em camadas os elementos do que a equipe deseja usar. Eles começam com uma imagem Python base que já tem as pyodbc bibliotecas instaladas e, em seguida, executam todos os comandos necessários para conter o programa e o arquivo de configuração na etapa anterior.
O Dockerfile a seguir tem as seguintes etapas:
- Comece com um binário de contêiner que já tenha Python e
pyodbcinstalado. - Crie um diretório de trabalho para o aplicativo.
- Copie todo o código do diretório atual para o
WORKDIR. - Instale as bibliotecas necessárias.
- Quando o contêiner for iniciado, execute o aplicativo e abra todas as portas TCP/IP.
# syntax=docker/dockerfile:1
# Start with a Container binary that already has Python and pyodbc installed
FROM laudio/pyodbc
# Create a Working directory for the application
WORKDIR /flask2sql
# Copy all of the code from the current directory into the WORKDIR
COPY . .
# Install the libraries that are required
RUN pip install -r ./requirements.txt
# Once the container starts, run the application, and open all TCP/IP ports
CMD ["python3", "-m" , "flask", "run", "--host=0.0.0.0"]
Com esse arquivo no lugar, a equipe caiu para um prompt de comando no diretório de codificação e executou o seguinte código para criar a imagem binária a partir do manifesto e, em seguida, outro comando para iniciar o contêiner:
docker build -t flask2sql .
docker run -d -p 5000:5000 -t flask2sql
Mais uma vez, a equipe testa o link para garantir que o contêiner possa acessar o banco de dados e vê o http://localhost:5000/products seguinte retorno:

Implantar a imagem em um registro do Docker
O contêiner agora está funcionando, mas só está disponível na máquina do desenvolvedor. A equipe de desenvolvimento gostaria de disponibilizar essa imagem de aplicativo para o resto da empresa e, em seguida, para o Kubernetes para implantação de produção.
A área de armazenamento para Imagens de Contêiner é chamada de repositório, e pode haver repositórios públicos e privados para Imagens de Contêiner. Na verdade, o AdvenureWorks usou uma imagem pública para o ambiente Python em seu Dockerfile.
A equipe gostaria de controlar o acesso à Imagem e, em vez de colocá-la na Web, eles decidem que gostariam de hospedá-la por conta própria, mas no Microsoft Azure, onde têm controle total sobre a segurança e o acesso. Você pode ler mais sobre o Registro de Contêiner do Microsoft Azure aqui.
Voltando à linha de comando, a equipe de desenvolvimento usa az CLI para adicionar um serviço de registro de contêiner, habilitar uma conta de administração, defini-la como "pulls" anônimos durante a fase de teste e definir um contexto de login para o registro:
az acr create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureContainerRegistryName --sku Standard
az acr update -n ReplaceWith_AzureContainerRegistryName --admin-enabled true
az acr update --name ReplaceWith_AzureContainerRegistryName --anonymous-pull-enabled
az acr login --name ReplaceWith_AzureContainerRegistryName
Este contexto será utilizado nas etapas seguintes.
Marque a imagem local do Docker para prepará-la para upload
A próxima etapa é enviar a Imagem de Contêiner do aplicativo local para o serviço Azure Container Registry (ACR) para que ela esteja disponível na nuvem.
- No script de exemplo a seguir, a equipe usa os comandos do Docker para listar as imagens na máquina.
- Eles usam o
az CLIutilitário para listar as imagens no serviço ACR. - Eles usam o comando Docker para "marcar" a imagem com o nome de destino do ACR que criaram na etapa anterior e para definir um número de versão para o DevOps adequado.
- Finalmente, eles listam as informações da imagem local novamente para garantir que a tag seja aplicada corretamente.
docker images
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
docker tag flask2sql ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
docker images
Com o código escrito e testado, o Dockerfile, a imagem e o contêiner executados e testados, o serviço ACR configurado e todas as tags aplicadas, a equipe pode carregar a imagem para o serviço ACR.
Eles usam o comando "push" do Docker para enviar o arquivo e, em seguida, o az CLI utilitário para garantir que a imagem foi carregada:
docker push ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
az acr repository list --name ReplaceWith_AzureContainerRegistryName --output table
Implementar no Kubernetes
A equipe poderia simplesmente executar contêineres e implantar o aplicativo em ambientes locais e na nuvem. No entanto, eles gostariam de adicionar várias cópias do aplicativo para escala e disponibilidade, adicionar outros contêineres executando tarefas diferentes e adicionar monitoramento e instrumentação a toda a solução.
Para agrupar contêineres em uma solução completa, a equipe decidiu usar o Kubernetes. O Kubernetes é executado no local e em todas as principais plataformas de nuvem. O Microsoft Azure tem um ambiente gerenciado completo para o Kubernetes, chamado Serviço Kubernetes do Azure (AKS). Saiba mais sobre o AKS com o caminho de treinamento Introdução ao Kubernetes no Azure.
Usando o az CLI utilitário, a equipe adiciona AKS ao mesmo grupo de recursos que criou anteriormente. Com um único az comando, a equipe de desenvolvimento realiza as seguintes etapas:
- Adicione dois "nós" ou ambientes de computação para resiliência na fase de teste
- Gere automaticamente chaves SSH para acesso ao ambiente
- Anexe o serviço ACR criado nas etapas anteriores para que o cluster AKS possa localizar as imagens que deseja usar para a implantação
az aks create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName --node-count 2 --generate-ssh-keys --attach-acr ReplaceWith_AzureContainerRegistryName
O Kubernetes usa uma ferramenta de linha de comando para acessar e controlar um cluster, chamada kubectl. A equipe usa o az CLI utilitário para baixar a kubectl ferramenta e instalá-la:
az aks install-cli
Como eles têm uma conexão com o AKS no momento, eles podem pedir que ele envie as chaves SSH para conexão a ser usada quando executarem o kubectl utilitário:
az aks get-credentials --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName
Essas chaves são armazenadas em um arquivo chamado .config no diretório do usuário. Com esse conjunto de contexto de segurança, a equipe usa kubectl get nodes para mostrar os nós no cluster:
kubectl get nodes
Agora a equipe usa a az CLI ferramenta para listar as imagens no serviço ACR:
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
Agora eles podem criar o manifesto que o Kubernetes usa para controlar a implantação. Este é um arquivo de texto armazenado em um formato yaml . Aqui está o texto anotado flask2sql.yaml no arquivo:
apiVersion: apps/v1
# The type of commands that will be sent, along with the name of the deployment
kind: Deployment
metadata:
name: flask2sql
# This section sets the general specifications for the application
spec:
replicas: 1
selector:
matchLabels:
app: flask2sql
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
minReadySeconds: 5
template:
metadata:
labels:
app: flask2sql
spec:
nodeSelector:
"kubernetes.io/os": linux
# This section sets the location of the Image(s) in the deployment, and where to find them
containers:
- name: flask2sql
image: bwoodyflask2sqlacr.azurecr.io/azure-flask2sql:v1
# Recall that the Flask application uses (by default) TCIP/IP port 5000 for access. This line tells Kubernetes that this "pod" uses that address.
ports:
- containerPort: 5000
---
apiVersion: v1
# This is the front-end of the application access, called a "Load Balancer"
kind: Service
metadata:
name: flask2sql
spec:
type: LoadBalancer
# this final step then sets the outside exposed port of the service to TCP/IP port 80, but maps it internally to the app's port of 5000
ports:
- protocol: TCP
port: 80
targetPort: 5000
selector:
app: flask2sql
Com o arquivo definido, a equipe pode implantar o flask2sql.yaml aplicativo no cluster AKS em execução. Isso é feito com o comando, que, como você se lembra, ainda tem um contexto de segurança para o kubectl apply cluster. Em seguida, o comando é enviado para observar o kubectl get service cluster enquanto ele está sendo construído.
kubectl apply -f flask2sql.yaml
kubectl get service flask2sql --watch
Após alguns momentos, o comando "watch" retornará um endereço IP externo. Nesse ponto, a equipe pressiona CTRL-C para quebrar o comando watch e registra o endereço IP externo do balanceador de carga.
Testar a aplicação
Usando o endereço IP (Endpoint) obtido na última etapa, a equipe verifica se há a mesma saída que o aplicativo local e o contêiner do Docker:
Limpeza
Com a aplicação criada, editada, documentada e testada, a equipa pode agora "derrubar" a aplicação. Ao manter tudo em um único grupo de recursos no Microsoft Azure, é uma simples questão de excluir o grupo de recursos PoC usando o az CLI utilitário:
az group delete -n ReplaceWith_PoCResourceGroupName -y
Nota
Se você criou seu Banco de Dados SQL do Azure em outro grupo de recursos e não precisa mais dele, poderá usar o portal do Azure para excluí-lo.
O membro da equipe que lidera o projeto PoC usa o Microsoft Windows como estação de trabalho e deseja manter o arquivo secretos do Kubernetes, mas removê-lo do sistema como o local ativo. Eles podem simplesmente copiar o arquivo para um arquivo de config.old texto e, em seguida, excluí-lo:
copy c:\users\ReplaceWith_YourUserName\.kube\config c:\users\ReplaceWith_YourUserName\.kube\config.old
del c:\users\ReplaceWith_YourUserName\.kube\config
Conteúdos relacionados
- Visão geral do desenvolvimento de aplicativos - Banco de dados SQL & Instância gerenciada SQL
- Conectar-se e consultar o Banco de Dados SQL do Azure usando Python e o driver pyodbc
- Publicar um projeto de banco de dados para o Banco de Dados SQL do Azure no emulador local
- Procurar exemplos de código para o Banco de Dados SQL do Azure