Backups automatizados para bancos de dados Hyperscale
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Este artigo explica o recurso de backup automatizado com bancos de dados Hyperscale no Banco de Dados SQL do Azure.
Os bancos de dados de hiperescala usam uma arquitetura exclusiva com níveis de desempenho de computação e armazenamento altamente escaláveis. Os backups em hiperescala são baseados em snapshot e são quase instantâneos. Os backups de log são armazenados no armazenamento de longo prazo do Azure durante o período de retenção de backup.
Uma arquitetura Hyperscale não requer backups completos, diferenciais ou de log. Como tal, a frequência de backup, os custos de armazenamento, o agendamento, a redundância de armazenamento e os recursos de restauração diferem de outros bancos de dados no Banco de Dados SQL do Azure.
Desempenho de backup e restauração
A separação de armazenamento e computação permite que o Hyperscale empurre as operações de backup e restauração para a camada de armazenamento para eliminar o consumo de recursos em réplicas de computação. Os backups de banco de dados não afetam o desempenho de réplicas de computação primárias ou secundárias.
As operações de backup e restauração para bancos de dados Hyperscale são rápidas, independentemente do tamanho dos dados, porque usam instantâneos de armazenamento. O backup é praticamente instantâneo.
Você pode restaurar um banco de dados para qualquer point-in-time dentro de seu período de retenção de backup:
- Reverter para instantâneos de arquivo aplicáveis.
- Aplicação de logs de transações para tornar o banco de dados restaurado transacionalmente consistente.
Como tal, a restauração não é uma operação de tamanho de dados que permanece a mesma. A restauração de um banco de dados Hyperscale dentro da mesma região do Azure é concluída em minutos, em vez de horas ou dias, mesmo para bancos de dados de vários terabytes.
Alterar a redundância de armazenamento ao emitir uma restauração pode resultar em tempos de restauração mais longos, pois a restauração é o tamanho dos dados e, portanto, o tempo é proporcional ao tamanho do banco de dados.
A criação de novos bancos de dados restaurando um backup existente ou copiando o banco de dados também aproveita a separação de computação e armazenamento no Hyperscale. Você pode criar cópias para fins de desenvolvimento ou teste, mesmo de bancos de dados de vários terabytes, em minutos dentro da mesma região quando usar o mesmo tipo de armazenamento.
Retenção da cópia de segurança
A retenção padrão de curto prazo de backups para bancos de dados Hyperscale é de 7 dias.
A retenção de curto prazo de backups no intervalo de 1 a 35 dias e o recurso de retenção de backup de longo prazo (LTR) para bancos de dados Hyperscale estão geralmente disponíveis, a partir de setembro de 2023. Para obter mais informações, consulte Retenção de longo prazo - Banco de Dados SQL do Azure e Instância Gerenciada SQL do Azure.
Agendamento de backup
Não existem cópias de segurança tradicionais completas, diferenciais e de registos de transações para bases de dados Hyperscale. Em vez disso, são feitos instantâneos de armazenamento regulares dos ficheiros de dados.
Os logs de transações gerados são retidos como é para o período de retenção configurado. No momento da restauração, os registros relevantes do log de transações são aplicados ao instantâneo de armazenamento restaurado. O resultado é um banco de dados transacionalmente consistente sem qualquer perda de dados a partir do point-in-time especificado dentro do período de retenção.
Monitore o consumo de armazenamento de backup
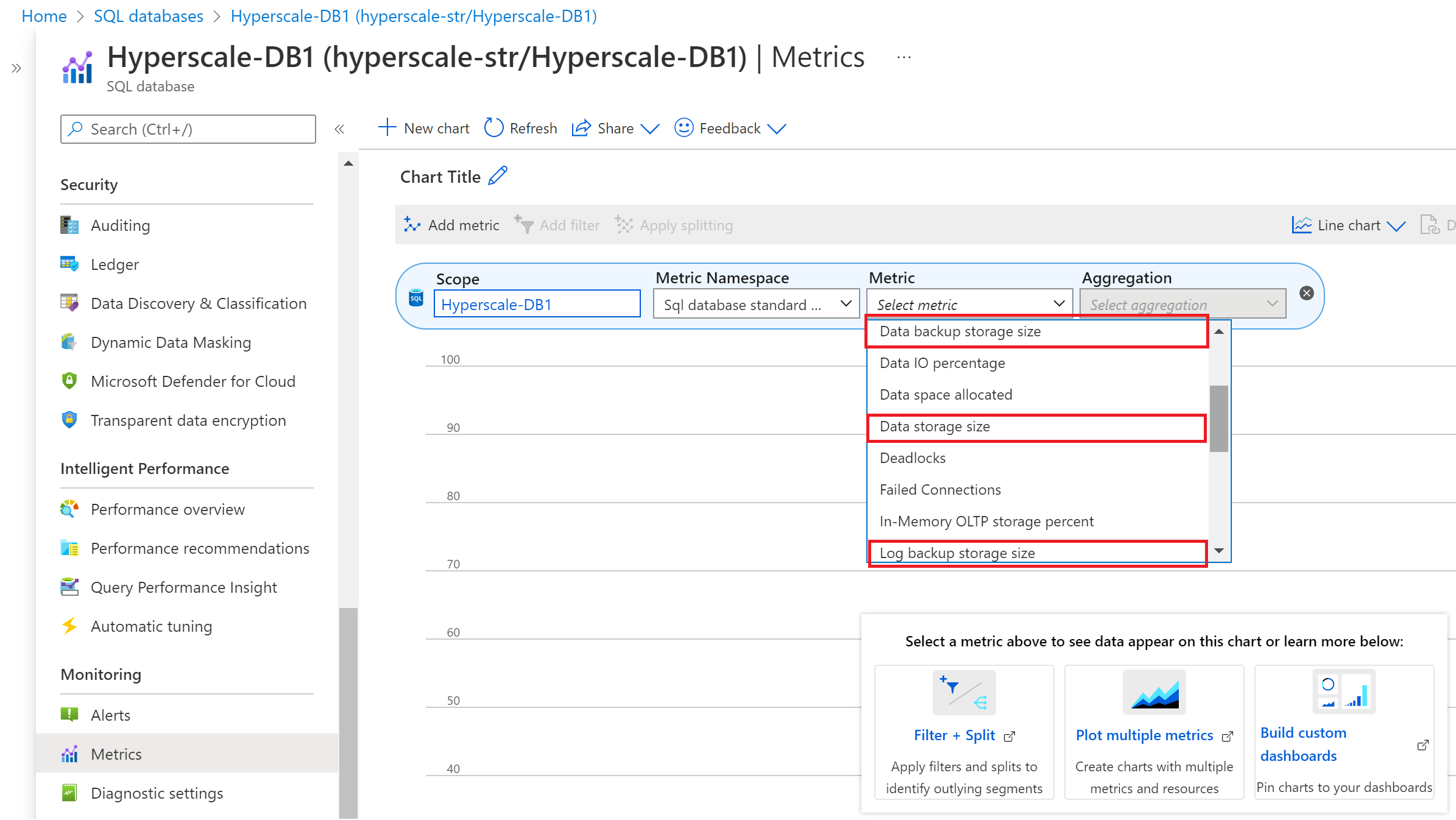
No Hyperscale, as métricas do Azure Monitor relatam as seguintes informações de consumo:
- Tamanho do armazenamento de backup de dados (tamanho do backup de snapshot)
- Tamanho do armazenamento de dados (tamanho do banco de dados alocado)
- Tamanho do armazenamento do backup de log (tamanho do backup do log de transações)
Para exibir métricas de backup e armazenamento de dados no portal do Azure, siga estas etapas:
- Vá para o banco de dados Hyperscale para o qual você deseja monitorar as métricas de backup e armazenamento de dados.
- Na seção Monitoramento, selecione a página Métricas.
- Na lista suspensa Métrica, selecione Armazenamento de backup de dados, Tamanho do armazenamento de dados e Métricas de armazenamento de backup de log com uma regra de agregação apropriada.
Reduza o consumo de armazenamento de backup
O consumo de armazenamento de backup para um banco de dados Hyperscale depende do período de retenção, da escolha da região, da redundância do armazenamento de backup e do tipo de carga de trabalho. Considere algumas das seguintes técnicas de ajuste para reduzir o consumo de armazenamento de backup para um banco de dados Hyperscale:
- Reduza o período de retenção de backup ao mínimo para suas necessidades.
- Evite fazer grandes operações de gravação, como manutenção de índice, com mais frequência do que o necessário. Para obter recomendações de manutenção de índice, consulte Otimizar a manutenção de índice para melhorar o desempenho da consulta e reduzir o consumo de recursos.
- Para grandes operações de carga de dados, considere o uso da compactação de dados quando apropriado.
- Use o
tempdbbanco de dados em vez de tabelas permanentes na lógica do aplicativo para armazenar resultados temporários e/ou dados transitórios. - Use armazenamento de backup localmente redundante ou com redundância de zona quando a capacidade de restauração geográfica for desnecessária (por exemplo, ambientes de desenvolvimento/teste).
Custos de armazenamento da cópia de segurança
O custo do armazenamento de cópias de segurança Hyperscale depende da opção da região e fa redundância do armazenamento de cópias de segurança. Também depende do tipo de carga de trabalho.
As cargas de trabalho de escrita intensiva são mais propensas a alterar páginas de dados frequentemente, o que resulta em instantâneos de armazenamento maiores. Essas cargas de trabalho também geram mais logs de transações, contribuindo para os custos gerais de backup. O armazenamento de backup é cobrado com base nos gigabytes consumidos por mês. Para obter detalhes de preços, consulte a página de preços do Banco de Dados SQL do Azure.
Para o Hyperscale, o armazenamento de backup faturável é calculado da seguinte forma:
Total billable backup storage size = (data backup storage size + log backup storage size)
O tamanho do armazenamento de dados não está incluído no backup faturável porque já é cobrado como armazenamento de banco de dados alocado.
Os bancos de dados Hyperscale excluídos incorrem em custos de backup para dar suporte à recuperação até um ponto no tempo antes da exclusão. Para um banco de dados Hyperscale excluído, o armazenamento de backup faturável é calculado da seguinte maneira:
Total billable backup storage size for deleted Hyperscale database = (data storage size + data backup size + log backup storage size) * (remaining backup retention period after deletion / configured backup retention period)
O tamanho do armazenamento de dados é incluído na fórmula porque o armazenamento de banco de dados alocado não é cobrado separadamente para um banco de dados excluído. Para um banco de dados excluído, os dados são armazenados após a exclusão para permitir a recuperação durante o período de retenção de backup configurado.
O armazenamento de backup faturável para um banco de dados excluído reduz gradualmente ao longo do tempo depois que ele é excluído. Ele se torna zero quando os backups não são mais retidos e, em seguida, a recuperação não é mais possível. Se for uma exclusão permanente e você não precisar mais de backups, poderá otimizar os custos reduzindo a retenção antes de excluir o banco de dados.
Monitore os custos de backup
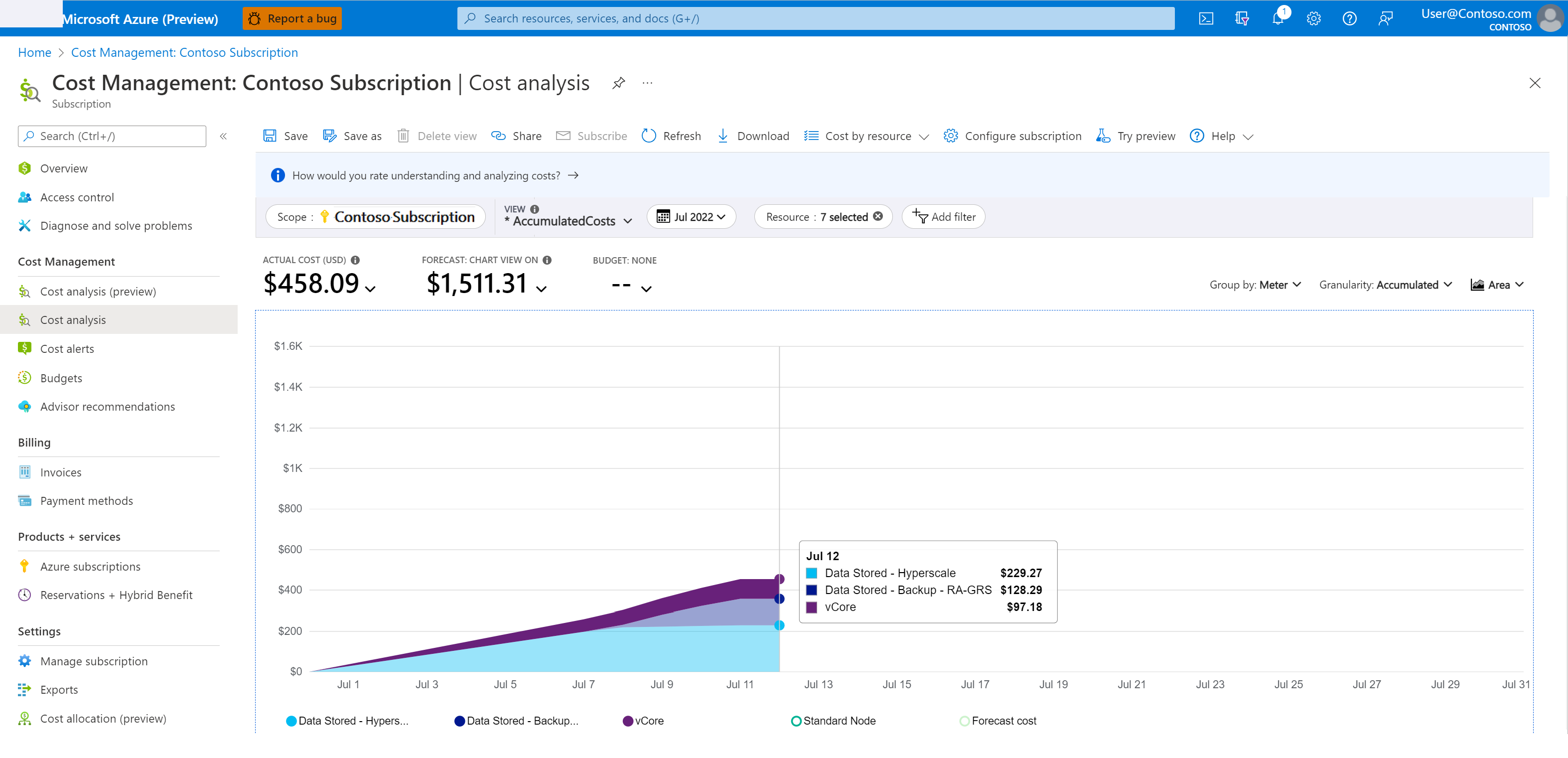
Para entender os custos de armazenamento de backup:
No portal do Azure, aceda a Cost Management + Faturação.
Selecione Análise de custos de gerenciamento de>custos.
Em Escopo, selecione a assinatura desejada.
Filtre o período de tempo e o serviço em que está interessado seguindo estes passos:
- Adicione um filtro para Nome do serviço.
- Escolha sql-database na lista suspensa.
- Adicione outro filtro para o Meter.
- Para monitorar os custos de backup para recuperação point-in-time, selecione Dados armazenados - Backup - RA na lista suspensa.
A captura de tela a seguir mostra um exemplo de análise de custo.
Redundância de armazenamento de dados e backup
O Hyperscale suporta redundância de armazenamento configurável. Ao criar um banco de dados Hyperscale, você pode escolher seu tipo de armazenamento preferido: armazenamento com redundância de zona geográfica de acesso de leitura (RA-GZRS), armazenamento com redundância geográfica de acesso de leitura (RA-GRS), armazenamento com redundância de zona (ZRS) ou armazenamento com redundância local (LRS).
- Armazenamento com redundância de zona geográfica: copia seus backups de forma síncrona em três zonas de disponibilidade do Azure na região primária. semelhante ao armazenamento com redundância de zona (ZRS). Além disso, ele copia seus dados de forma assíncrona para um único local físico na região secundária emparelhada . Atualmente está disponível apenas em determinadas regiões.
Para obter mais informações sobre como os backups são replicados para outros tipos de armazenamento, consulte Redundância de armazenamento de backup.
Como o Hyperscale usa snapshots de armazenamento para backups, os dados e backups compartilham a mesma conta de armazenamento. Como resultado, a redundância de armazenamento de backup selecionada é aplicável para dados e backups.
Nota
Considere cuidadosamente a redundância de armazenamento de backup ao criar um banco de dados Hyperscale, pois você pode defini-lo somente durante a criação do banco de dados. Não é possível modificar essa configuração depois que o recurso é provisionado.
Use a replicação geográfica ativa para atualizar as configurações de redundância de armazenamento de backup para um banco de dados Hyperscale existente com o mínimo de tempo de inatividade. Como alternativa, você pode usar a cópia do banco de dados.
Aviso
- A restauração geográfica é desabilitada assim que um banco de dados é atualizado para usar armazenamento localmente redundante ou com redundância de zona.
- Atualmente, o armazenamento com redundância de zona está disponível apenas em determinadas regiões.
- Atualmente, o armazenamento com redundância de zona geográfica está disponível apenas em determinadas regiões.
Restaurar um banco de dados Hyperscale para uma região diferente
Talvez seja necessário restaurar o banco de dados Hyperscale para uma região diferente da região atual. Os motivos comuns incluem uma operação ou exercício de recuperação de desastres ou uma realocação. O método principal é fazer uma restauração geográfica do banco de dados. Você usa as mesmas etapas que usaria para restaurar qualquer outro banco de dados no Banco de Dados SQL do Azure para uma região diferente:
- Crie um servidor na região de destino se ainda não tiver um servidor apropriado lá. Este servidor deve pertencer à mesma subscrição que o servidor original (de origem).
- Siga as instruções na seção de restauração geográfica da página sobre como restaurar um banco de dados no Banco de Dados SQL do Azure a partir de backups automáticos.
Nota
Como a origem e o destino estão em regiões separadas, o banco de dados não pode compartilhar o armazenamento de instantâneos com o banco de dados de origem como faz em restaurações não geográficas. As restaurações não geográficas são concluídas rapidamente, independentemente do tamanho do banco de dados.
Uma restauração geográfica de um banco de dados Hyperscale é uma operação de tamanho de dados, mesmo que o destino esteja na região emparelhada do armazenamento replicado geograficamente. Portanto, uma restauração geográfica levará um tempo significativamente maior em comparação com uma restauração point-in-time na mesma região.
Se o destino estiver na região emparelhada, a transferência de dados será dentro de uma região. Essa transferência será significativamente mais rápida do que uma transferência de dados entre regiões. Mas ainda será uma operação de tamanho de dados.
Se preferir, você pode copiar o banco de dados para uma região diferente. Use esse método se a restauração geográfica não estiver disponível porque não é compatível com o tipo de redundância de armazenamento selecionado. Para obter detalhes, consulte Cópia de banco de dados para Hyperscale.
Conteúdos relacionados
Os backups de banco de dados são uma parte essencial de qualquer estratégia de continuidade de negócios e recuperação de desastres, pois ajudam a proteger seus dados contra corrupção ou exclusão acidental.
- Visão geral da continuidade de negócios com o Banco de Dados SQL do Azure
- Gerenciar a retenção de backup de longo prazo do Banco de Dados SQL do Azure
- Restaurar um banco de dados a partir de um backup no Banco de Dados SQL do Azure
- Usar o PowerShell para restaurar um banco de dados para um ponto anterior no tempo
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários