Novo DBA na nuvem – Gerenciando o Banco de Dados SQL do Azure após a migração
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Mudar do ambiente tradicional autogerenciado e autocontrolado para um ambiente PaaS pode parecer um pouco esmagador no início. Como desenvolvedor de aplicativos ou DBA, você gostaria de saber os principais recursos da plataforma que o ajudariam a manter seu aplicativo disponível, com desempenho, seguro e resiliente - sempre. Este artigo pretende fazer exatamente isso. O artigo organiza sucintamente os recursos e fornece algumas orientações sobre como usar melhor os principais recursos do Banco de Dados SQL do Azure com bancos de dados únicos e agrupados para gerenciar e manter seu aplicativo funcionando de forma eficiente e alcançar resultados ideais na nuvem. Público típico para este artigo seria aqueles que:
- Estão avaliando a migração do(s) seu(s) aplicativo(s) para o Banco de Dados SQL do Azure – Modernizando sua(s) aplicação(ões).
- Estão no processo de migração da(s) sua(s) aplicação(ões) – Cenário de migração em curso.
- Ter concluído recentemente a migração para o Banco de Dados SQL do Azure – Novo DBA na nuvem.
Este artigo discute algumas das principais características do Banco de Dados SQL do Azure como uma plataforma que você pode aproveitar prontamente ao trabalhar com bancos de dados únicos e bancos de dados agrupados em pools elásticos. São eles:
- Monitorizar bases de dados com o portal do Azure
- Continuidade de negócio e recuperação após desastre (BCDR)
- Segurança e conformidade
- Monitoramento e manutenção inteligentes de banco de dados
- Movimento de dados
Nota
Microsoft Entra ID é o novo nome para o Azure Ative Directory (Azure AD). Estamos atualizando a documentação neste momento.
Monitorizar bases de dados com o portal do Azure
No portal do Azure, você pode monitorar a utilização de um banco de dados individual selecionando seu banco de dados e clicando no gráfico de monitoramento. É apresentada a janela Métricas que pode alterar ao clicar no botão Editar gráfico. Adicione as métricas seguintes:
- Percentagem de CPU
- Percentagem de DTU
- Percentagem de ES de Dados
- Percentagem de tamanho da Base de Dados
Depois de adicionar essas métricas, você pode continuar a visualizá-las no gráfico de monitoramento com mais informações na janela Métrica . As quatro métricas mostram a percentagem de utilização média relativa à DTU da base de dados. Consulte os artigos Modelo de compra baseado em DTU e Modelo de compra baseado em vCore para obter mais informações sobre camadas de serviço.
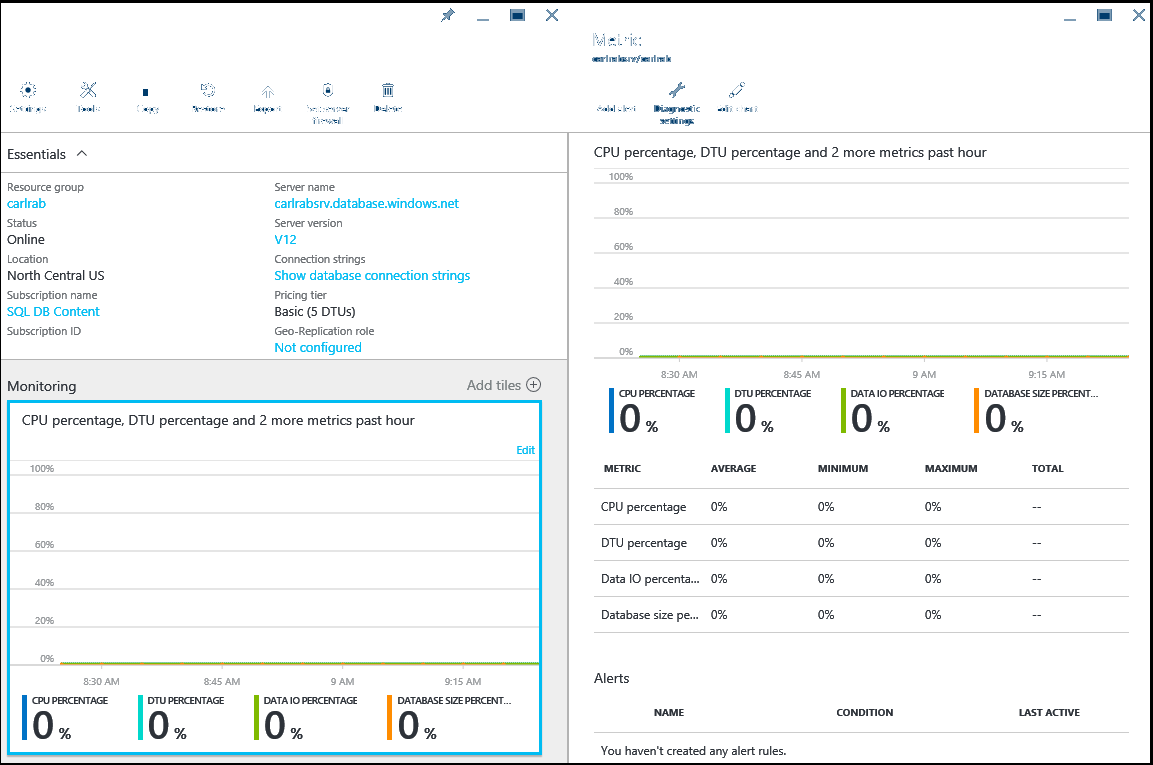
Também pode configurar alertas para as métricas de desempenho. Selecione o botão Adicionar alerta na janela Métrica . Siga o assistente para configurar o alerta. Tem a opção de alertar se as métricas excederem um determinado limiar ou se a métrica descer abaixo de um determinado limiar.
Por exemplo, se espera que a carga de trabalho na sua base de dados aumente, pode optar por configurar um alerta por e-mail sempre que a base de dados atingir 80% em qualquer uma das métricas de desempenho. Você pode usar isso como um aviso antecipado para descobrir quando você pode ter que mudar para o próximo tamanho de computação mais alto.
As métricas de desempenho também podem ajudá-lo a determinar se você pode fazer downgrade para um tamanho de computação mais baixo. Parta do princípio de que está a utilizar uma base de dados Standard S2 e que todas as métricas de desempenho mostram que, em média, a base de dados não utiliza mais de 10% em qualquer momento. É provável que a base de dados funcione corretamente no Standard S1. No entanto, esteja ciente das cargas de trabalho que aumentam ou flutuam antes de tomar a decisão de mudar para um tamanho de computação mais baixo.
Continuidade de negócio e recuperação após desastre (BCDR)
As capacidades de continuidade de negócios e recuperação de desastres permitem que você continue seus negócios, como de costume, em caso de desastre. O desastre pode ser um evento no nível do banco de dados (por exemplo, alguém deixa cair por engano uma tabela crucial) ou um evento no nível do data center (catástrofe regional, por exemplo, um tsunami).
Como faço para criar e gerenciar backups no Banco de dados SQL
Você não cria backups no Banco de Dados SQL do Azure e isso ocorre porque não é necessário. O Banco de dados SQL faz backup automático de bancos de dados para você, portanto, você não precisa mais se preocupar com agendamento, recebimento e gerenciamento de backups. A plataforma faz um backup completo a cada semana, um backup diferencial a cada poucas horas e um backup de log a cada 5 minutos para garantir que a recuperação de desastres seja eficiente e a perda de dados mínima. O primeiro backup completo acontece assim que você cria um banco de dados. Esses backups ficam disponíveis para você por um determinado período chamado "Período de retenção" e variam de acordo com a camada de serviço escolhida. O Banco de dados SQL oferece a capacidade de restaurar para qualquer point-in-time dentro desse período de retenção usando a recuperação point-in-time (PITR).
| Escalão de serviço | Período de retenção em dias |
|---|---|
| Básica | 7 |
| Standard | 35 |
| Premium | 35 |
Além disso, o recurso de retenção de longo prazo (LTR) permite que você mantenha seus arquivos de backup por um período muito mais longo, especificamente, por até 10 anos, e restaure os dados desses backups a qualquer momento dentro desse período. Além disso, os backups de banco de dados são mantidos em armazenamento replicado geograficamente para garantir resiliência contra catástrofes regionais. Você também pode restaurar esses backups em qualquer região do Azure a qualquer momento dentro do período de retenção. Consulte Visão geral da continuidade de negócios para saber mais.
Como garanto a continuidade dos negócios em caso de desastre no nível do datacenter ou catástrofe regional
Seus backups de banco de dados são armazenados em armazenamento replicado geograficamente para garantir que, durante um desastre regional, você possa restaurar o backup para outra região do Azure. Isso é chamado de restauração geográfica. O RPO (Recovery Point Objetive) para restauração geográfica é geralmente < de 1 hora e o ERT (Estimated Recovery Time) – alguns minutos a horas.
Para bancos de dados de missão crítica, o Banco de Dados SQL do Azure oferece replicação geográfica ativa, que cria uma cópia secundária replicada geograficamente do seu banco de dados original em outra região. Por exemplo, se o seu banco de dados estiver inicialmente hospedado na região Oeste dos EUA do Azure e você quiser resiliência a desastres regionais, crie uma réplica geográfica ativa do banco de dados do Oeste dos EUA para o Leste dos EUA. Quando a calamidade atinge o oeste dos EUA, você pode passar para a região leste dos EUA.
Além da replicação geográfica ativa, os grupos de failover fornecem uma maneira conveniente de gerenciar a replicação e o failover de um grupo de bancos de dados. Você pode criar um grupo de failover que contenha vários bancos de dados na mesma região ou em regiões diferentes. Em seguida, você pode iniciar um failover de todos os bancos de dados no grupo de failover para a região secundária. Para obter mais informações, consulte Grupos de failover.
Para obter resiliência para falhas de datacenter ou zona de disponibilidade, verifique se a redundância de zona está habilitada para o banco de dados ou pool elástico.
Monitore ativamente seu aplicativo em busca de um desastre e inicie um failover para o secundário. Você pode criar até 4 réplicas geográficas ativas em diferentes regiões do Azure. Fica ainda melhor. Você também pode acessar essas réplicas geográficas ativas secundárias para acesso somente leitura. Isso é muito útil para reduzir a latência de um cenário de aplicativo distribuído geograficamente.
Como é a recuperação de desastres com o Banco de dados SQL
A configuração e o gerenciamento da recuperação de desastres podem ser feitos com apenas alguns cliques no Banco de Dados SQL do Azure quando você usa grupos ativos de replicação geográfica ou failover. Você ainda precisa monitorar o aplicativo e seu banco de dados para qualquer desastre regional e fazer failover para a região secundária para restaurar a continuidade dos negócios.
Para saber mais, consulte Azure SQL Database Disaster Recovery 101.
Segurança e conformidade
O Banco de Dados SQL leva a segurança e a privacidade muito a sério. A segurança no Banco de dados SQL está disponível no nível do banco de dados e no nível da plataforma e é melhor compreendida quando categorizada em várias camadas. Em cada camada, você controla e fornece a segurança ideal para sua aplicação. As camadas são:
- Identidade e autenticação (autenticação SQL e autenticação com ID do Microsoft Entra (anteriormente Azure Ative Directory).
- Atividade de monitorização (Auditoria e deteção de ameaças).
- Proteção de dados reais (Transparent Data Encryption [TDE] e Always Encrypted [AE]).
- Controlando o acesso a dados sensíveis e privilegiados (segurança em nível de linha e mascaramento dinâmico de dados).
O Microsoft Defender for Cloud oferece gerenciamento de segurança centralizado em cargas de trabalho executadas no Azure, no local e em outras nuvens. Você pode ver se a proteção essencial do Banco de dados SQL, como auditoria e criptografia de dados transparente [TDE], está configurada em todos os recursos e criar políticas com base em seus próprios requisitos.
Quais métodos de autenticação de usuário são oferecidos no Banco de dados SQL
Há dois métodos de autenticação oferecidos no Banco de dados SQL:
A autenticação do Windows não é suportada. O Microsoft Entra ID é um serviço centralizado de gerenciamento de identidade e acesso. Com isso, você pode muito convenientemente fornecer acesso de logon único (SSO) para o pessoal em sua organização. Isso significa que as credenciais são compartilhadas entre os serviços do Azure para uma autenticação mais simples.
O Microsoft Entra ID suporta autenticação multifator e pode ser facilmente integrado ao Ative Directory do Windows Server. Isso também permite que o Banco de Dados SQL e o Azure Synapse Analytics ofereçam autenticação multifator e contas de usuário convidado em um domínio do Microsoft Entra. Se você já tiver um Ative Directory local, poderá federar o diretório com a ID do Microsoft Entra para estender seu diretório para o Azure.
A autenticação SQL suporta apenas nome de usuário e senha para autenticar usuários em qualquer banco de dados em um determinado servidor.
| Se você... | Banco de Dados SQL / Azure Synapse Analytics |
|---|---|
| Prefira não usar o Microsoft Entra ID no Azure | Usar autenticação SQL |
| AD usado no SQL Server local | Federar o AD com o Microsoft Entra ID e usar a autenticação do Microsoft Entra. Com isso, você pode usar o logon único. |
| Necessidade de impor a autenticação multifator | Exija a autenticação multifator como uma política por meio do Microsoft Conditional Access e use a autenticação multifator do Microsoft Entra. |
| Ter contas de convidado de contas Microsoft (live.com, outlook.com) ou outros domínios (gmail.com) | Use a autenticação universal do Microsoft Entra no Banco de dados SQL ou no pool SQL dedicado, que aproveita a colaboração B2B do Microsoft Entra. |
| Estão conectados ao Windows usando suas credenciais do Microsoft Entra de um domínio federado | Use a autenticação integrada do Microsoft Entra. |
| Estão conectados ao Windows usando credenciais de um domínio não federado com o Azure | Use a autenticação integrada do Microsoft Entra. |
| Ter serviços de camada intermediária que precisam se conectar ao Banco de Dados SQL ou ao Azure Synapse Analytics | Use a autenticação integrada do Microsoft Entra. |
Como faço para limitar ou controlar o acesso de conectividade ao meu banco de dados
Há várias técnicas à sua disposição que você pode usar para obter a organização de conectividade ideal para seu aplicativo.
- Regras da Firewall
- Pontos Finais de Serviço da VNet
- IPs Reservados
Firewall
Uma firewall impede o acesso ao servidor a partir de uma entidade externa, permitindo que apenas entidades específicas acedam ao servidor. Por padrão, todas as conexões com bancos de dados dentro do servidor não são permitidas, exceto (opcionalmente7) conexões provenientes de outros Serviços do Azure. Com uma regra de firewall, você pode abrir o acesso ao seu servidor apenas para entidades (por exemplo, uma máquina de desenvolvedor) que você aprovar, permitindo o endereço IP desse computador através do firewall. Ele também permite que você especifique um intervalo de IPs que você gostaria de permitir o acesso ao servidor. Por exemplo, os endereços IP da máquina do desenvolvedor em sua organização podem ser adicionados de uma só vez especificando um intervalo na página Configurações do firewall.
Você pode criar regras de firewall no nível do servidor ou no nível do banco de dados. As regras de firewall IP no nível do servidor podem ser criadas usando o portal do Azure ou com o SSMS. Para saber mais sobre como definir uma regra de firewall no nível do servidor e no nível do banco de dados, consulte: Criar regras de firewall IP no Banco de dados SQL.
Pontos finais de serviço
Por padrão, seu banco de dados está configurado para "Permitir que os serviços do Azure acessem o servidor" – o que significa que qualquer Máquina Virtual no Azure pode tentar se conectar ao seu banco de dados. Essas tentativas ainda precisam ser autenticadas. No entanto, se você não quiser que seu banco de dados seja acessível por nenhum IP do Azure, você pode desabilitar "Permitir que os serviços do Azure acessem o servidor". Além disso, você pode configurar pontos de extremidade de serviço VNet.
Os pontos de extremidade de serviço (SE) permitem que você exponha seus recursos críticos do Azure apenas à sua própria rede virtual privada no Azure. Ao fazer isso, você essencialmente elimina o acesso público aos seus recursos. O tráfego entre a sua rede virtual para o Azure permanece na rede de backbone do Azure. Sem SE, você obtém roteamento de pacotes de encapsulamento forçado. Sua rede virtual força o tráfego da Internet para sua organização e o tráfego do Serviço do Azure a percorrer a mesma rota. Com os Pontos de Extremidade de Serviço, você pode otimizar isso, uma vez que os pacotes fluem diretamente da sua rede virtual para o serviço na rede de backbone do Azure.

IPs Reservados
Outra opção é provisionar IPs reservados para suas VMs e adicionar esses endereços IP específicos da VM nas configurações do firewall do servidor. Ao atribuir IPs reservados, você evita o trabalho de ter que atualizar as regras de firewall com a alteração de endereços IP.
Em que porta me conecto ao Banco de dados SQL
Porta 1433. O Banco de dados SQL se comunica por essa porta. Para se conectar de dentro de uma rede corporativa, você precisa adicionar uma regra de saída nas configurações de firewall da sua organização. Como diretriz, evite expor a porta 1433 fora do limite do Azure.
Como posso monitorar e regular a atividade no meu servidor e banco de dados no Banco de dados SQL
Auditoria da Base de Dados SQL
Com o Banco de dados SQL, você pode ativar a auditoria para controlar eventos do banco de dados. A Auditoria do Banco de Dados SQL registra eventos de banco de dados e os grava em um arquivo de log de auditoria em sua Conta de Armazenamento do Azure. A auditoria é especialmente útil se você pretende obter informações sobre possíveis violações de segurança e políticas, manter a conformidade regulamentar, etc. Ele permite que você defina e configure certas categorias de eventos que você acha que precisam de auditoria e, com base nisso, você pode obter relatórios pré-configurados e um painel para obter uma visão geral dos eventos que ocorrem em seu banco de dados. Você pode aplicar essas políticas de auditoria no nível do banco de dados ou no nível do servidor. Um guia sobre como ativar a auditoria para seu servidor/banco de dados, consulte: Habilitar auditoria do banco de dados SQL.
Deteção de ameaças
Com a deteção de ameaças, você tem a capacidade de agir sobre violações de segurança ou políticas descobertas pela auditoria com muita facilidade. Você não precisa ser um especialista em segurança para lidar com possíveis ameaças ou violações em seu sistema. A deteção de ameaças também tem alguns recursos internos, como a deteção de injeção de SQL. SQL Injection é uma tentativa de alterar ou comprometer os dados e uma maneira bastante comum de atacar um aplicativo de banco de dados em geral. A deteção de ameaças executa vários conjuntos de algoritmos que detetam vulnerabilidades potenciais e ataques de injeção de SQL, bem como padrões anômalos de acesso ao banco de dados (como acesso de um local incomum ou por uma entidade desconhecida). Os agentes de segurança ou outros administradores designados recebem uma notificação por e-mail se uma ameaça for detetada no banco de dados. Cada notificação fornece detalhes da atividade suspeita e recomendações sobre como investigar e mitigar a ameaça. Para saber como ativar a Deteção de ameaças, consulte: Ativar deteção de ameaças.
Como faço para proteger meus dados em geral no Banco de dados SQL
A criptografia fornece um mecanismo forte para proteger e proteger seus dados confidenciais contra intrusos. Os seus dados encriptados não têm qualquer utilidade para o intruso sem a chave de desencriptação. Assim, ele adiciona uma camada extra de proteção sobre as camadas existentes de segurança incorporadas no Banco de dados SQL. Há dois aspetos para proteger seus dados no Banco de dados SQL:
- Seus dados que estão em repouso nos arquivos de dados e log
- Os seus dados que estão a bordo
No Banco de dados SQL, por padrão, seus dados em repouso nos arquivos de dados e log no subsistema de armazenamento são completa e sempre criptografados por meio da Criptografia de Dados Transparente [TDE]. As suas cópias de segurança também são encriptadas. Com a TDE não são necessárias alterações no lado da sua aplicação que está a aceder a estes dados. A encriptação e desencriptação acontecem de forma transparente; daí o nome. Para proteger seus dados confidenciais em voo e em repouso, o Banco de dados SQL fornece um recurso chamado Always Encrypted (AE). AE é uma forma de criptografia do lado do cliente que criptografa colunas confidenciais em seu banco de dados (para que elas estejam em texto cifrado para administradores de banco de dados e usuários não autorizados). O servidor recebe os dados criptografados para começar. A chave para Always Encrypted também é armazenada no lado do cliente, para que apenas clientes autorizados possam desencriptar as colunas confidenciais. O servidor e os administradores de dados não podem ver os dados confidenciais, uma vez que as chaves de criptografia são armazenadas no cliente. O AE criptografa colunas confidenciais na tabela de ponta a ponta, de clientes não autorizados para o disco físico. O AE oferece suporte a comparações de igualdade atualmente, para que os DBAs possam continuar a consultar colunas criptografadas como parte de seus comandos SQL. O Always Encrypted pode ser usado com uma variedade de opções de armazenamento de chaves, como o Cofre de Chaves do Azure, o armazenamento de certificados do Windows e módulos de segurança de hardware locais.
| Caraterísticas | Always Encrypted | Encriptação de Dados Transparente |
|---|---|---|
| Extensão de criptografia | De ponta a ponta | Dados em repouso |
| O servidor pode acessar dados confidenciais | Não | Sim, uma vez que a encriptação é para os dados em repouso |
| Operações T-SQL permitidas | Comparação da igualdade | Toda a área de superfície do T-SQL está disponível |
| Alterações no aplicativo necessárias para usar o recurso | Mínimo | Muito mínimo |
| Granularidade de criptografia | Nível da coluna | Nível do banco de dados |
Como posso limitar o acesso a dados confidenciais na minha base de dados
Cada aplicativo tem um certo pedaço de dados confidenciais no banco de dados que precisa ser protegido de ser visível para todos. Certos funcionários dentro da organização precisam visualizar esses dados, no entanto, outros não devem ser capazes de visualizar esses dados. Um exemplo são os salários dos empregados. Um gerente precisaria ter acesso às informações salariais para seus subordinados diretos, no entanto, os membros individuais da equipe não deveriam ter acesso às informações salariais de seus pares. Outro cenário são desenvolvedores de dados que podem estar interagindo com dados confidenciais durante estágios de desenvolvimento ou testes, por exemplo, SSNs de clientes. Essas informações novamente não precisam ser expostas ao desenvolvedor. Nesses casos, seus dados confidenciais precisam ser mascarados ou não devem ser expostos. O Banco de dados SQL oferece duas dessas abordagens para impedir que usuários não autorizados possam exibir dados confidenciais:
O mascaramento dinâmico de dados é um recurso de mascaramento de dados que permite limitar a exposição de dados confidenciais mascarando-os para usuários sem privilégios na camada de aplicativo. Você define uma regra de mascaramento que pode criar um padrão de mascaramento (por exemplo, para mostrar apenas os últimos quatro dígitos de um ID SSN NACIONAL: XXX-XX-0000 e marcar a maior parte dele como Xs) e identificar quais usuários devem ser excluídos da regra de mascaramento. O mascaramento acontece em tempo real e existem várias funções de mascaramento disponíveis para várias categorias de dados. O mascaramento dinâmico de dados permite que você detete automaticamente dados confidenciais em seu banco de dados e aplique mascaramento a eles.
A segurança em nível de linha permite controlar o acesso no nível da linha. Ou seja, certas linhas em uma tabela de banco de dados com base no usuário que executa a consulta (associação ao grupo ou contexto de execução) estão ocultas. A restrição de acesso é feita na camada de banco de dados em vez de em uma camada de aplicativo, para simplificar a lógica do aplicativo. Você começa criando um predicado de filtro, filtrando as linhas que não são expostas e a política de segurança em seguida definindo quem tem acesso a essas linhas. Finalmente, o usuário final executa sua consulta e, dependendo do privilégio do usuário, ele visualiza essas linhas restritas ou não consegue vê-las.
Como faço para gerenciar chaves de criptografia na nuvem
Há opções de gerenciamento de chaves para Always Encrypted (criptografia do lado do cliente) e Transparent Data Encryption (criptografia em repouso). É recomendável girar regularmente as chaves de criptografia. A frequência de rotação deve estar alinhada com os regulamentos internos da organização e com os requisitos de conformidade.
Encriptação de Dados Transparente (TDE)
Há uma hierarquia de duas chaves no TDE – os dados em cada banco de dados de usuário são criptografados por uma chave de criptografia de banco de dados (DEK) simétrica AES-256, que por sua vez é criptografada por uma chave mestra assimétrica RSA 2048 exclusiva do servidor. A chave mestra pode ser gerenciada:
- Automaticamente pela plataforma - Banco de Dados SQL.
- Ou usando o Azure Key Vault como o armazenamento de chaves.
Por padrão, a chave mestra para Criptografia de Dados Transparente é gerenciada pelo serviço Banco de dados SQL por conveniência. Se sua organização quiser ter controle sobre a chave mestra, há uma opção para usar o Azure Key Vault](always-encrypted-azure-key-vault-configure.md) como o armazenamento de chaves. Ao usar o Cofre de Chaves do Azure, sua organização assume o controle sobre o provisionamento de chaves, rotação e controles de permissão. A rotação ou comutação do tipo de uma chave mestra TDE é rápida, pois apenas criptografa novamente a DEK. Para organizações com separação de funções entre segurança e gerenciamento de dados, um administrador de segurança pode provisionar o material de chave para a chave mestra TDE no Cofre de Chaves do Azure e fornecer um identificador de chave do Cofre de Chaves do Azure ao administrador do banco de dados para usar para criptografia em repouso em um servidor. O Cofre da Chave foi concebido de forma a que a Microsoft não veja nem extraia quaisquer chaves de encriptação. Você também obtém um gerenciamento centralizado de chaves para sua organização.
Always Encrypted
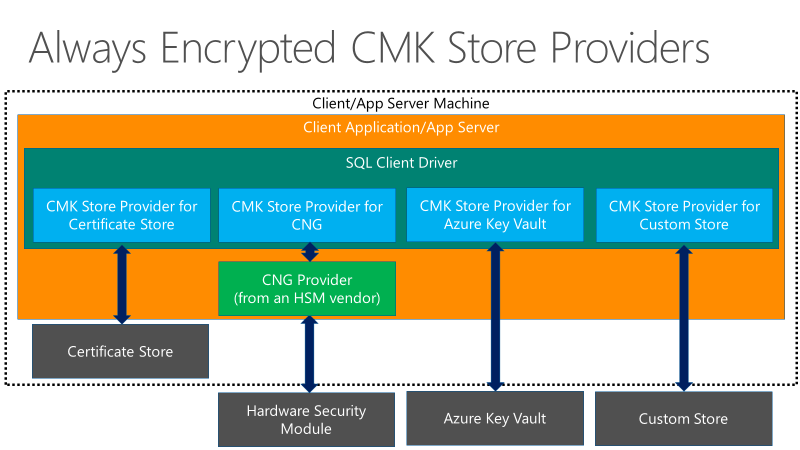
Há também uma hierarquia de duas chaves em Always Encrypted - uma coluna de dados confidenciais é criptografada por uma chave de criptografia AES de 256 colunas (CEK), que por sua vez é criptografada por uma chave mestra de coluna (CMK). Os drivers de cliente fornecidos para Always Encrypted não têm limitações no comprimento das CMKs. O valor criptografado do CEK é armazenado no banco de dados e a CMK é armazenada em um armazenamento de chaves confiável, como o Repositório de Certificados do Windows, o Cofre de Chaves do Azure ou um módulo de segurança de hardware.
- Tanto o CEK como o CMK podem ser rotacionados.
- A rotação CEK é um tamanho de operação de dados e pode ser demorada, dependendo do tamanho das tabelas que contêm as colunas criptografadas. Por conseguinte, é prudente planear as rotações CEK em conformidade.
- A rotação CMK, no entanto, não interfere no desempenho do banco de dados e pode ser feita com funções separadas.
O diagrama a seguir mostra as opções de armazenamento de chaves para as chaves mestras de coluna em Sempre Criptografado
Como posso otimizar e proteger o tráfego entre a minha organização e a Base de Dados SQL
O tráfego de rede entre sua organização e o Banco de dados SQL geralmente é roteado pela rede pública. No entanto, se você optar por otimizar esse caminho e torná-lo mais seguro, poderá examinar a Rota Expressa do Azure. O ExpressRoute essencialmente permite que você estenda sua rede corporativa para a plataforma do Azure por meio de uma conexão privada. Ao fazê-lo, não passa pela Internet pública. Você também obtém maior segurança, confiabilidade e otimização de roteamento que se traduz em latências de rede mais baixas e velocidades muito mais rápidas do que normalmente experimentaria usando a Internet pública. Se você estiver planejando transferir uma parte significativa de dados entre sua organização e o Azure, usar a Rota Expressa pode gerar benefícios de custo. Você pode escolher entre três modelos de conectividade diferentes para a conexão de sua organização com o Azure:
O ExpressRoute também permite que você aumente até 2x o limite de largura de banda que você compra sem custo adicional. Também é possível configurar a conectividade entre regiões usando a Rota Expressa. Para ver uma lista de provedores de conectividade de Rota Expressa, consulte: Parceiros de Rota Expressa e Locais de Emparelhamento. Os seguintes artigos descrevem a Rota Expressa com mais detalhes:
O Banco de Dados SQL é compatível com quaisquer requisitos normativos e como isso ajuda na conformidade da minha própria organização
O Banco de dados SQL é compatível com uma série de conformidades regulamentares. Para exibir o conjunto mais recente de conformidades que foram atendidas pelo Banco de Dados SQL, visite a Central de Confiabilidade da Microsoft e faça uma busca detalhada nas conformidades que são importantes para sua organização para ver se o Banco de Dados SQL está incluído nos serviços compatíveis do Azure. É importante observar que, embora o Banco de Dados SQL possa ser certificado como um serviço compatível, ele ajuda na conformidade do serviço da sua organização, mas não o garante automaticamente.
Monitoramento e manutenção inteligentes do banco de dados após a migração
Depois de migrar seu banco de dados para o Banco de dados SQL, você vai querer monitorar seu banco de dados (por exemplo, verificar como é a utilização de recursos ou verificações DBCC) e executar manutenção regular (por exemplo, reconstruir ou reorganizar índices, estatísticas, etc.). Felizmente, o Banco de dados SQL é inteligente no sentido de que usa as tendências históricas e métricas e estatísticas registradas para ajudá-lo proativamente a monitorar e manter seu banco de dados, para que seu aplicativo seja executado de forma otimizada sempre. Em alguns casos, o Banco de Dados SQL do Azure pode executar automaticamente tarefas de manutenção dependendo da sua configuração de configuração. Há três facetas para monitorar seu banco de dados no Banco de dados SQL:
- Monitorização e otimização do desempenho.
- Otimização da segurança.
- Otimização de custos.
Monitorização e otimização do desempenho
Com o Query Performance Insights, você pode obter recomendações personalizadas para sua carga de trabalho de banco de dados para que seus aplicativos possam continuar sendo executados em um nível ideal - sempre. Você também pode configurá-lo para que essas recomendações sejam aplicadas automaticamente e você não precise se preocupar em executar tarefas de manutenção. Com o SQL Database Advisor, você pode implementar automaticamente recomendações de índice com base em sua carga de trabalho - isso é chamado de ajuste automático. As recomendações evoluem à medida que a carga de trabalho do aplicativo muda para fornecer as sugestões mais relevantes. Você também tem a opção de revisar manualmente essas recomendações e aplicá-las a seu critério.
Otimização da segurança
O Banco de dados SQL fornece recomendações de segurança acionáveis para ajudá-lo a proteger seus dados e a deteção de ameaças para identificar e investigar atividades suspeitas do banco de dados que possam representar um thread potencial para o banco de dados. A avaliação de vulnerabilidades é um serviço de verificação e relatório de banco de dados que permite monitorar o estado de segurança de seus bancos de dados em escala e identificar riscos de segurança e desvio de uma linha de base de segurança definida por você. Após cada verificação, uma lista personalizada de etapas acionáveis e scripts de correção é fornecida, bem como um relatório de avaliação que pode ser usado para ajudar a atender aos requisitos de conformidade.
Com o Microsoft Defender for Cloud, você identifica as recomendações de segurança em todos os aspetos e as aplica rapidamente.
Otimização de custos
A plataforma SQL do Azure analisa o histórico de utilização nos bancos de dados em um servidor para avaliar e recomendar opções de otimização de custos para você. Essa análise geralmente leva quinze dias para analisar e construir recomendações acionáveis. A piscina elástica é uma dessas opções. A recomendação aparece no portal como um banner:
Você também pode visualizar essa análise na seção "Orientador":

Como faço para monitorar o desempenho e a utilização de recursos no Banco de dados SQL
No Banco de dados SQL, você pode aproveitar os insights inteligentes da plataforma para monitorar o desempenho e ajustar de acordo. Você pode monitorar o desempenho e a utilização de recursos no Banco de dados SQL usando os seguintes métodos:
Portal do Azure
O portal do Azure mostra a utilização de um banco de dados selecionando o banco de dados e clicando no gráfico no painel Visão geral. Você pode modificar o gráfico para mostrar várias métricas, incluindo porcentagem de CPU, porcentagem de DTU, porcentagem de E/S de dados, porcentagem de sessões e porcentagem de tamanho do banco de dados.
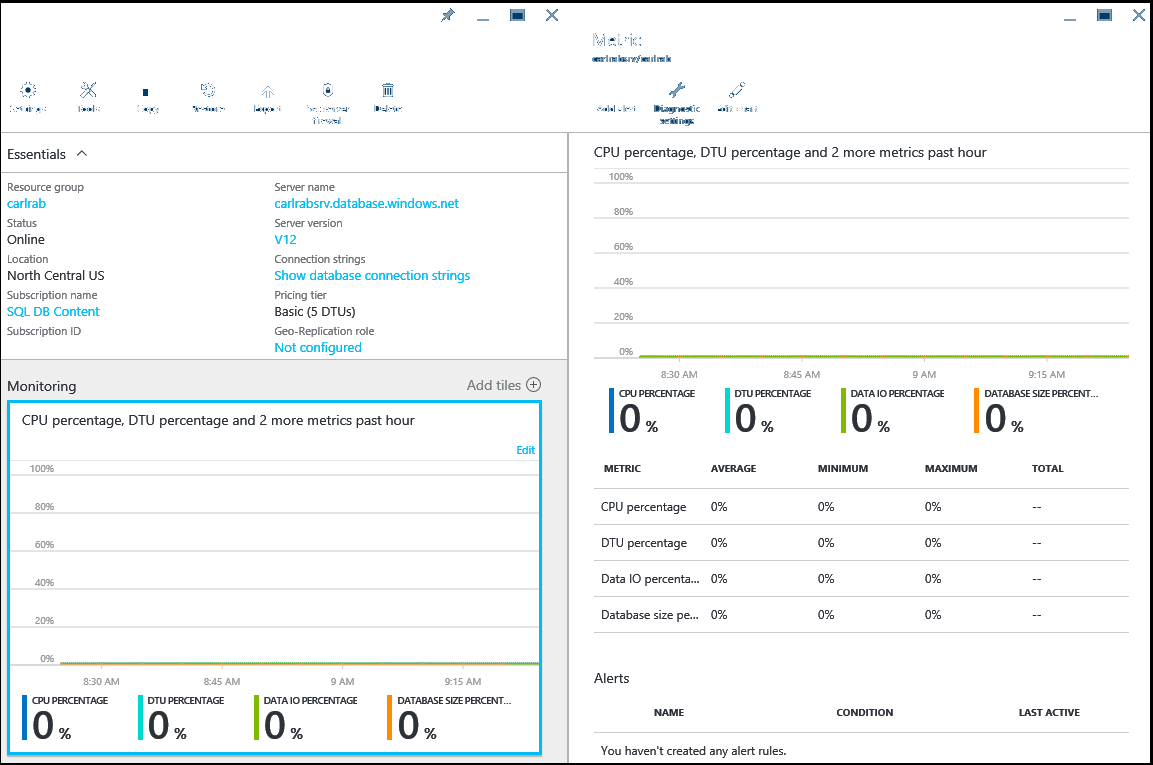
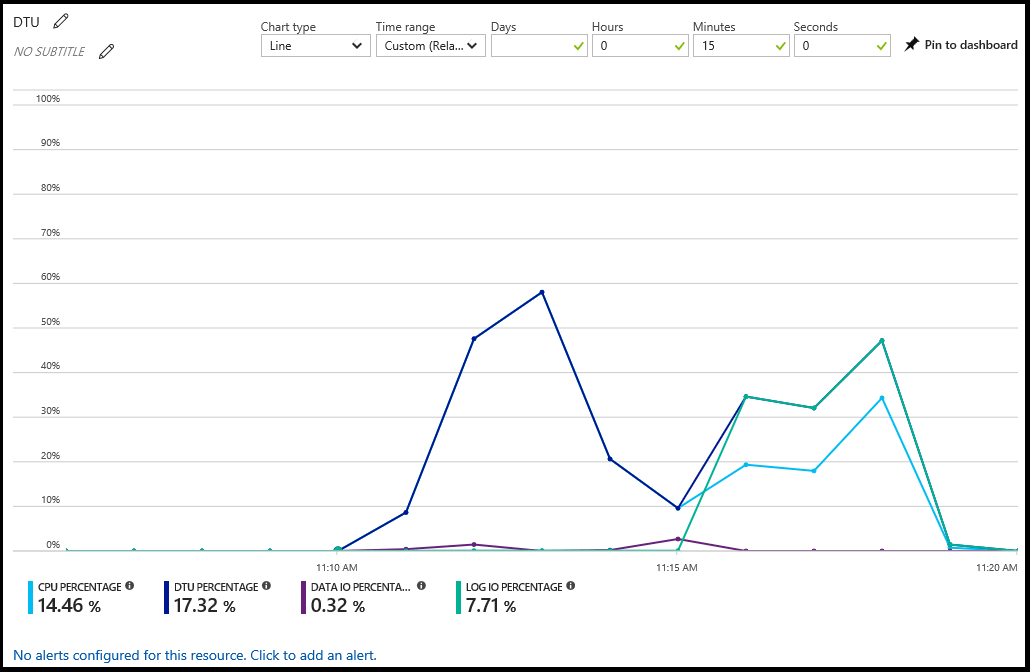
Neste gráfico, você também pode configurar alertas por recurso. Esses alertas permitem que você responda às condições do recurso com um e-mail, escreva em um ponto de extremidade HTTPS/HTTP ou execute uma ação. Para obter mais informações, veja Criar alertas.
Vistas de gestão dinâmicas (DMV)
Você pode consultar a exibição de gerenciamento dinâmico sys.dm_db_resource_stats para retornar o histórico de estatísticas de consumo de recursos da última hora e a exibição de catálogo do sistema sys.resource_stats para retornar o histórico dos últimos 14 dias.
Query Performance Insight
O Query Performance Insight permite que você veja um histórico das principais consultas que consomem recursos e das consultas de longa execução para um banco de dados específico. Você pode identificar rapidamente consultas TOP por utilização de recursos, duração e frequência de execução. Você pode rastrear consultas e detetar regressão. Esse recurso requer que o Repositório de Consultas esteja habilitado e ativo para o banco de dados.

Azure SQL Analytics (Pré-visualização) nos registos do Azure Monitor
Os logs do Azure Monitor permitem coletar e visualizar as principais métricas de desempenho do Banco de Dados SQL do Azure, oferecendo suporte a até 150.000 bancos de dados e 5.000 pools elásticos SQL por espaço de trabalho. Você pode usá-lo para monitorar e receber notificações. Você pode monitorar o Banco de Dados SQL e as métricas do pool elástico em várias assinaturas do Azure e pools elásticos e pode ser usado para identificar problemas em cada camada de uma pilha de aplicativos.
Estou percebendo problemas de desempenho: como minha metodologia de solução de problemas do Banco de dados SQL difere do SQL Server
Uma grande parte das técnicas de solução de problemas que você usaria para diagnosticar problemas de desempenho de consulta e banco de dados permanece a mesma. Afinal, o mesmo mecanismo de banco de dados alimenta a nuvem. No entanto, a plataforma - Banco de Dados SQL do Azure incorporou 'inteligência'. Ele pode ajudá-lo a solucionar e diagnosticar problemas de desempenho ainda mais facilmente. Ele também pode executar algumas dessas ações corretivas em seu nome e, em alguns casos, corrigi-las proativamente - automaticamente.
Sua abordagem para solucionar problemas de desempenho pode se beneficiar significativamente usando recursos inteligentes, como o Query Performance Insight (QPI) e o Database Advisor em conjunto, e, portanto, a diferença na metodologia difere nesse aspeto – você não precisa mais fazer o trabalho manual de triturar os detalhes essenciais que podem ajudá-lo a solucionar o problema em questão. A plataforma faz o trabalho duro para você. Um exemplo disso é o QPI. Com o QPI, você pode detalhar até o nível de consulta e examinar as tendências históricas e descobrir quando exatamente a consulta regrediu. O Supervisor de Banco de Dados fornece recomendações sobre coisas que podem ajudá-lo a melhorar seu desempenho geral em geral, como índices ausentes, queda de índices, parametrização de consultas, etc.
Com a solução de problemas de desempenho, é importante identificar se é apenas o aplicativo ou o banco de dados que o apoia, que está afetando o desempenho do aplicativo. Muitas vezes, o problema de desempenho está na camada de aplicação. Pode ser a arquitetura ou o padrão de acesso aos dados. Por exemplo, considere que você tem um aplicativo tagarela que é sensível à latência da rede. Neste caso, seu aplicativo sofre porque haveria muitas solicitações curtas indo e voltando ("tagarelas") entre o aplicativo e o servidor e, em uma rede congestionada, essas viagens de ida e volta se somam rapidamente. Para melhorar o desempenho nesse caso, você pode usar consultas em lote. O uso de lotes ajuda tremendamente porque agora suas solicitações são processadas em lote; assim, ajudando você a reduzir a latência de ida e volta e melhorar o desempenho do seu aplicativo.
Além disso, se você notar uma degradação no desempenho geral do banco de dados, poderá monitorar as exibições de gerenciamento dinâmico sys.dm_db_resource_stats e sys.resource_stats para entender o consumo de CPU, E/S e memória. Seu desempenho pode ser afetado porque seu banco de dados está carente de recursos. Pode ser que você precise alterar o tamanho da computação e/ou a camada de serviço com base nas crescentes e reduzidas demandas de carga de trabalho.
Para obter um conjunto abrangente de recomendações para ajustar problemas de desempenho, consulte: Ajustar seu banco de dados.
Como posso garantir que estou usando a camada de serviço e o tamanho de computação apropriados
O Banco de dados SQL oferece várias camadas de serviço Basic, Standard e Premium. A cada camada de serviço você obtém um desempenho previsível garantido vinculado a essa camada de serviço. Dependendo da sua carga de trabalho, você pode ter picos de atividade em que a utilização de recursos pode atingir o limite do tamanho de computação atual em que você está. Nesses casos, é útil começar por avaliar se algum ajuste pode ajudar (por exemplo, adicionar ou alterar um índice, etc.). Se você ainda encontrar problemas de limite, considere mudar para uma camada de serviço ou tamanho de computação mais alto.
| Escalão de serviço | Cenários de casos de uso comuns |
|---|---|
| Básica | Aplicativos com poucos usuários e um banco de dados que não tem altos requisitos de simultaneidade, escala e desempenho. |
| Standard | Aplicativos com requisitos consideráveis de simultaneidade, escala e desempenho, juntamente com demandas de E/S baixas a médias. |
| Premium | Aplicativos com muitos usuários simultâneos, alta CPU/memória e altas demandas de E/S. Aplicativos de alta simultaneidade, alta taxa de transferência e latência podem aproveitar o nível Premium. |
Para ter certeza de que você está no tamanho de computação correto, você pode monitorar sua consulta e o consumo de recursos do banco de dados por meio de uma das maneiras mencionadas acima em "Como monitorar o desempenho e a utilização de recursos no Banco de dados SQL". Se você achar que suas consultas/bancos de dados estão consistentemente funcionando quente em CPU/Memória, etc., você pode considerar o dimensionamento para um tamanho de computação mais alto. Da mesma forma, se você notar que, mesmo durante o horário de pico, você não parece usar tanto os recursos; Considere reduzir a partir do tamanho de computação atual.
Se você tiver um padrão de aplicativo SaaS ou um cenário de consolidação de banco de dados, considere usar um pool elástico para otimização de custos. O pool elástico é uma ótima maneira de obter consolidação de banco de dados e otimização de custos. Para ler mais sobre como gerenciar vários bancos de dados usando pool elástico, consulte: Gerenciar pools e bancos de dados.
Com que frequência preciso executar verificações de integridade do banco de dados para meu banco de dados
O Banco de dados SQL usa algumas técnicas inteligentes que permitem lidar com certas classes de corrupção de dados automaticamente e sem qualquer perda de dados. Essas técnicas são incorporadas ao serviço e são aproveitadas pelo serviço quando necessário. Regularmente, os backups de banco de dados em todo o serviço são testados restaurando-os e executando DBCC CHECKDB nele. Se houver problemas, o Banco de dados SQL os abordará proativamente. O reparo automático de páginas é aproveitado para corrigir páginas corrompidas ou com problemas de integridade de dados. As páginas do banco de dados são sempre verificadas com a configuração CHECKSUM padrão que verifica a integridade da página. O Banco de dados SQL monitora e revisa proativamente a integridade dos dados do seu banco de dados e, se surgirem problemas, os aborda com a mais alta prioridade. Além destes, você pode optar por executar opcionalmente suas próprias verificações de integridade à sua vontade. Para obter mais informações, consulte Integridade de dados no Banco de dados SQL
Movimentação de dados após a migração
Como exportar e importar dados como arquivos BACPAC do Banco de Dados SQL usando o portal do Azure
Exportar: você pode exportar seu banco de dados no Banco de Dados SQL do Azure como um arquivo BACPAC do portal do Azure
Importar: você também pode importar dados como um arquivo BACPAC para seu banco de dados no Banco de Dados SQL do Azure usando o portal do Azure.

Como sincronizar dados entre o Banco de dados SQL e o SQL Server
Você tem várias maneiras de conseguir isso:
- Sincronização de dados – esse recurso ajuda a sincronizar dados bidirecionalmente entre vários bancos de dados do SQL Server e o Banco de dados SQL. Para sincronizar com bancos de dados do SQL Server, você precisa instalar e configurar o agente de sincronização em um computador local ou em uma máquina virtual e abrir a porta TCP de saída 1433.
- Replicação de transações – Com a replicação de transações, você pode sincronizar seus dados de um banco de dados do SQL Server para o Banco de Dados SQL do Azure, com a instância do SQL Server sendo o editor e o Banco de Dados SQL do Azure sendo o assinante. Por enquanto, apenas esta configuração é suportada. Para obter mais informações sobre como migrar seus dados de um banco de dados do SQL Server para o SQL do Azure com o mínimo de tempo de inatividade, consulte: Usar replicação de transações
Próximos passos
Saiba mais sobre o Banco de Dados SQL.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários