Gestão de recursos na Base de Dados SQL do Azure
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Este artigo fornece uma visão geral do gerenciamento de recursos no Banco de Dados SQL do Azure. Ele fornece informações sobre o que acontece quando os limites de recursos são atingidos e descreve os mecanismos de governança de recursos que são usados para impor esses limites.
Para limites de recursos específicos por camada de preço (também conhecido como objetivo de serviço) para bancos de dados únicos, consulte Limites de recursos de banco de dados únicos baseados em DTU ou Limites de recursos de banco de dados único baseados em vCore. Para limites de recursos do pool elástico, consulte Limites de recursos do pool elástico baseados em DTU ou Limites de recursos do pool elástico baseado em vCore. Para limites do pool SQL dedicado do Azure Synapse Analytics, consulte Limites de capacidade e limites de memória e simultaneidade.
Nota
O hardware Gen5 no modelo de compra vCore foi renomeado para série padrão (Gen5).
Gorjeta
Para limites do pool SQL dedicado do Azure Synapse Analytics, consulte Limites de capacidade e limites de memória e simultaneidade.
Limites lógicos do servidor
| Recurso | Limite |
|---|---|
| Bancos de dados por servidor lógico | 5000 |
| Número padrão de servidores lógicos por assinatura em uma região | 20 |
| Número máximo de servidores lógicos por assinatura em uma região | 250 |
| Cota DTU / eDTU 1 por servidor lógico | 54,000 |
| Cota vCore 1 por servidor lógico 2 | 540 |
| Máximo de pools elásticos por servidor lógico | Limitado pelo número de DTUs ou vCores. Por exemplo, se cada pool tiver 1000 DTUs, um servidor poderá suportar 54 pools. |
1 Os bancos de dados e pools elásticos provisionados com o modelo de compra DTU também são contados em relação à cota vCore e vice-versa. Cada vCore consumido é considerado equivalente a 100 DTUs consumidas para a cota no nível do servidor.
2 Isso inclui os vCores configurados para bancos de dados de computação provisionados/pools elásticos e os "vCores máximos" configurados para bancos de dados sem servidor.
Importante
À medida que o número de bancos de dados se aproxima do limite por servidor lógico, pode ocorrer o seguinte:
- Aumentar a
masterlatência na execução de consultas no banco de dados. Isso inclui exibições de estatísticas de utilização de recursos, comosys.resource_stats. - Aumentar a latência nas operações de gerenciamento e renderizar pontos de vista do portal que envolvem a enumeração de bancos de dados no servidor.
Nota
Para obter mais cota DTU/eDTU, cota vCore ou mais servidores lógicos do que o número padrão, envie uma nova solicitação de suporte no portal do Azure. Para obter mais informações, consulte Solicitar aumentos de cota para o Banco de Dados SQL do Azure.
O que acontece quando os limites de recursos são atingidos
CPU de computação
Quando a utilização da CPU de computação do banco de dados se torna alta, a latência da consulta aumenta e as consultas podem até atingir o tempo limite. Nessas condições, as consultas podem ser enfileiradas pelo serviço e são fornecidos recursos para execução à medida que os recursos se tornam gratuitos. Se você observar alta utilização de computação, as opções de mitigação incluem:
- Aumentar o tamanho de computação do banco de dados ou pool elástico para fornecer ao banco de dados mais recursos de computação. Consulte Dimensionar recursos de banco de dados único e Dimensionar recursos de pool elástico.
- Otimizando consultas para reduzir a utilização de recursos da CPU de cada consulta. Para obter mais informações, veja Ajuste/Sugestões de Consultas.
Armazenamento
Quando o espaço de dados usado atinge o limite máximo de tamanho de dados, seja no nível do banco de dados ou no nível do pool elástico, as inserções e atualizações que aumentam o tamanho dos dados falham e os clientes recebem uma mensagem de erro. As instruções SELECT e DELETE permanecem inalteradas.
Nos níveis de serviço Premium e Business Critical, os clientes também recebem uma mensagem de erro se o consumo combinado de armazenamento por dados, log de transações e tempdb para um único banco de dados ou pool elástico exceder o tamanho máximo de armazenamento local. Para obter mais informações, consulte Governança do espaço de armazenamento.
Se você observar uma alta utilização do espaço de armazenamento, as opções de mitigação incluem:
- Aumente o tamanho máximo de dados do banco de dados ou do pool elástico ou aumente a escala para um objetivo de serviço com um limite máximo de tamanho de dados mais alto. Consulte Dimensionar recursos de banco de dados único e Dimensionar recursos de pool elástico.
- Se o banco de dados estiver em um pool elástico, alternativamente, o banco de dados poderá ser movido para fora do pool, para que seu espaço de armazenamento não seja compartilhado com outros bancos de dados.
- Reduza um banco de dados para recuperar espaço não utilizado. Em pools elásticos, a redução de um banco de dados fornece mais armazenamento para outros bancos de dados no pool. Para obter mais informações, consulte Gerenciar espaço de arquivo no Banco de Dados SQL do Azure.
- Verifique se a alta utilização de espaço se deve a um pico no tamanho do Armazenamento de Versão Persistente (PVS). O PVS faz parte de cada banco de dados e é usado para implementar a Recuperação Acelerada de Banco de Dados. Para determinar o tamanho atual do PVS, consulte Solução de problemas do PVS. Uma razão comum para o tamanho PVS grande é uma transação que está aberta por um longo tempo (horas), impedindo a limpeza de versões mais antigas da linha no PVS.
- Para bancos de dados e pools elásticos nas camadas de serviço Premium e Business Critical que consomem grandes quantidades de armazenamento, você pode receber um erro de falta de espaço mesmo que o espaço usado no banco de dados ou no pool elástico esteja abaixo de seu limite máximo de tamanho de dados. Isso pode acontecer se
tempdbos arquivos de log de transações consumirem uma grande quantidade de armazenamento em direção ao limite máximo de armazenamento local. Faça failover do banco de dados ou do pool elástico para redefinirtempdbpara seu tamanho menor inicial ou reduza o log de transações para reduzir o consumo de armazenamento local.
Sessões, trabalhadores e solicitações
Sessões, trabalhadores e solicitações são definidos da seguinte forma:
- Uma sessão representa um processo conectado ao mecanismo de banco de dados.
- Uma solicitação é a representação lógica de uma consulta ou lote. Uma solicitação é emitida por um cliente conectado a uma sessão. Com o tempo, várias solicitações podem ser emitidas na mesma sessão.
- Um thread de trabalho, também conhecido como worker ou thread, é uma representação lógica de um thread do sistema operacional. Uma solicitação pode ter muitos trabalhadores quando executada com um plano de execução de consulta paralela ou um único trabalhador quando executada com um plano de execução serial (thread único). Os trabalhadores também são obrigados a dar suporte a atividades fora das solicitações: por exemplo, um trabalhador é obrigado a processar uma solicitação de login quando uma sessão se conecta.
Para obter mais informações sobre esses conceitos, consulte o Guia de Arquitetura de Thread e Tarefa.
O número máximo de trabalhadores é determinado pela camada de serviço e pelo tamanho do cálculo. Quando os limites de sessão ou de função de trabalho são atingidos os pedidos novos são rejeitados e os clientes recebem uma mensagem de erro. Embora o número de conexões possa ser controlado pelo aplicativo, o número de trabalhadores simultâneos é muitas vezes mais difícil de estimar e controlar. Isso é especialmente verdadeiro durante os períodos de pico de carga, quando os limites de recursos do banco de dados são atingidos e os trabalhadores se acumulam devido a consultas de execução mais longas, grandes cadeias de bloqueio ou paralelismo de consulta excessivo.
Nota
A oferta inicial do Banco de Dados SQL do Azure dava suporte apenas a consultas de thread único. Nessa altura, o número de pedidos era sempre equivalente ao número de trabalhadores. A mensagem de erro 10928 no Banco de Dados SQL do Azure contém o texto "O limite de solicitação para o banco de dados é N e foi atingido" para fins de compatibilidade com versões anteriores. O limite atingido é, na verdade, o número de funções de trabalho. Se sua configuração de grau máximo de paralelismo (MAXDOP) for igual a zero ou for maior que um, o número de trabalhadores pode ser muito maior do que o número de solicitações, e o limite pode ser atingido muito mais cedo do que quando MAXDOP é igual a um. Saiba mais sobre o erro 10928 em Erros de governança de recursos.
Você pode reduzir a aproximação ou o atingimento dos limites de trabalho ou sessão:
- Aumentar a camada de serviço ou o tamanho de computação do banco de dados ou pool elástico. Consulte Dimensionar recursos de banco de dados único e Dimensionar recursos de pool elástico.
- Otimizar consultas para reduzir a utilização de recursos se a causa do aumento de trabalhadores for a contenção de recursos de computação. Para obter mais informações, veja Ajuste/Sugestões de Consultas.
- Otimizar a carga de trabalho de consulta para reduzir o número de ocorrências e a duração do bloqueio de consulta. Para obter mais informações, consulte Compreender e resolver problemas de bloqueio do SQL do Azure.
- Reduzir a configuração MAXDOP quando apropriado.
Encontre limites de trabalho e sessão para o Banco de Dados SQL do Azure por camada de serviço e tamanho de computação:
- Limites de recursos das bases de dados individuais com o modelo de compra baseado em vCore
- Limites de recursos dos conjuntos elásticos com o modelo de compra baseado em vCore
- Limites de recursos das bases de dados individuais com o modelo de compra de DTUs
- Limites de recursos para pools elásticos usando o modelo de compra DTU
Saiba mais sobre como solucionar erros específicos para limites de sessão ou de trabalho em Erros de governança de recursos.
Ligações externas
O número de conexões simultâneas com pontos de extremidade externos feitas via sp_invoke_external_rest_endpoint é limitado a 10% dos threads de trabalho, com um limite rígido de no máximo 150 trabalhadores.
Memória
Ao contrário de outros recursos (CPU, trabalhadores, armazenamento), atingir o limite de memória não afeta negativamente o desempenho da consulta e não causa erros e falhas. Conforme descrito em detalhes no Guia de Arquitetura de Gerenciamento de Memória, o mecanismo de banco de dados geralmente usa toda a memória disponível, por design. A memória é usada principalmente para armazenar dados em cache, para evitar um acesso mais lento ao armazenamento. Assim, uma utilização mais elevada da memória geralmente melhora o desempenho da consulta devido a leituras mais rápidas da memória, em vez de leituras mais lentas do armazenamento.
Após a inicialização do mecanismo de banco de dados, à medida que a carga de trabalho começa a ler dados do armazenamento, o mecanismo de banco de dados armazena dados agressivamente em cache na memória. Após esse período inicial de aceleração, é comum e esperado ver as avg_memory_usage_percent colunas e em sys.dm_db_resource_stats e a sql_instance_memory_percent métrica do Azure Monitor estar próxima de 100%, especialmente para bancos de dados que não estão ociosos e avg_instance_memory_percent não cabem totalmente na memória.
Nota
A sql_instance_memory_percent métrica reflete o consumo total de memória pelo mecanismo de banco de dados. Essa métrica pode não chegar a 100%, mesmo quando cargas de trabalho de alta intensidade estão em execução. Isso ocorre porque uma pequena parte da memória disponível é reservada para alocações críticas de memória diferentes do cache de dados, como pilhas de threads e módulos executáveis.
Além da cache de dados, a memória é utilizada noutros componentes do motor de bases de dados. Quando há demanda por memória e toda a memória disponível foi usada pelo cache de dados, o mecanismo de banco de dados reduz o tamanho do cache de dados para disponibilizar memória para outros componentes e aumenta dinamicamente o cache de dados quando outros componentes liberam memória.
Em casos raros, uma carga de trabalho suficientemente exigente pode causar uma condição de memória insuficiente, o que leva a erros de falta de memória. Erros de falta de memória podem acontecer em qualquer nível de utilização de memória entre 0% e 100%. Erros de falta de memória são mais prováveis de ocorrer em tamanhos de computação menores que têm limites de memória proporcionalmente menores e/ou com cargas de trabalho usando mais memória para processamento de consultas, como em pools elásticos densos.
Se você receber erros de falta de memória, as opções de mitigação incluem:
- Analise os detalhes da condição OOM em sys.dm_os_out_of_memory_events.
- Aumentar a camada de serviço ou o tamanho de computação do banco de dados ou pool elástico. Consulte Dimensionar recursos de banco de dados único e Dimensionar recursos de pool elástico.
- Otimizando consultas e configurações para reduzir a utilização da memória. As soluções comuns são descritas na tabela a seguir.
| Solution | Description |
|---|---|
| Reduzir o tamanho das concessões de memória | Para obter mais informações sobre concessões de memória, consulte a postagem do blog Noções básicas sobre concessões de memória do SQL Server. Uma solução comum para evitar concessões de memória excessivamente grandes é manter as estatísticas atualizadas. Isso resulta em estimativas mais precisas do consumo de memória pelo mecanismo de consulta, evitando grandes concessões de memória. Por predefinição, nas bases de dados que utilizam o nível de compatibilidade 140 e superior, o motor de bases de dados pode ajustar automaticamente o tamanho da concessão de memória com o feedback de concessão de memória do modo Batch. Da mesma forma, em bancos de dados que usam o nível de compatibilidade 150 e superior, o mecanismo de banco de dados também usa feedback de concessão de memória no modo de linha, para consultas de modo de linha mais comuns. Esta funcionalidade integrada ajuda a evitar erros de falta de memória devido a grandes concessões de memória. |
| Reduzir o tamanho da cache do plano de consulta | O motor de bases de dados coloca os planos de consulta em cache na memória, para evitar compilar um plano de consulta para cada execução de consulta. Para evitar o inchaço do cache do plano de consulta causado por planos de cache que são usados apenas uma vez, certifique-se de usar consultas parametrizadas e considere habilitar OTIMIZE_FOR_AD_HOC_WORKLOADS configuração com escopo de banco de dados. |
| Reduzir o tamanho da memória de bloqueio | O motor de bases de dados utiliza memória para bloqueios. Sempre que possível, evite transações grandes que possam adquirir um grande número de bloqueios e causar um elevado consumo da memória de bloqueio. |
Consumo de recursos por cargas de trabalho de usuário e processos internos
O Banco de Dados SQL do Azure requer recursos de computação para implementar recursos de serviço principais, como alta disponibilidade e recuperação de desastres, backup e restauração de banco de dados, monitoramento, Repositório de Consultas, Ajuste automático, etc. O sistema reserva uma parte limitada dos recursos gerais para esses processos internos usando mecanismos de governança de recursos, disponibilizando o restante dos recursos para cargas de trabalho dos usuários. Às vezes, quando os processos internos não estão usando recursos de computação, o sistema os disponibiliza para cargas de trabalho do usuário.
O consumo total de CPU e memória por cargas de trabalho de usuário e processos internos é relatado nas visualizações sys.dm_db_resource_stats e sys.resource_stats, em avg_instance_cpu_percent e avg_instance_memory_percent colunas. Esses dados também são relatados por meio das sql_instance_cpu_percent sql_instance_memory_percent métricas e do Azure Monitor, para bancos de dados únicos e pools elásticos no nível do pool.
Nota
As métricas do Azure Monitor e do sql_instance_cpu_percent sql_instance_memory_percent Azure estão disponíveis desde julho de 2023. Eles são totalmente equivalentes às métricas e sqlserver_process_memory_percent disponíveis anteriormentesqlserver_process_core_percent, respectivamente. As duas últimas métricas permanecem disponíveis, mas serão removidas no futuro. Para evitar uma interrupção no monitoramento do banco de dados, não use as métricas mais antigas.
Essas métricas não estão disponíveis para bancos de dados que usam objetivos de serviço Basic, S1 e S2. Os mesmos dados estão disponíveis nas exibições de gerenciamento dinâmico mencionadas abaixo.
O consumo de CPU e memória por cargas de trabalho de usuário em cada banco de dados é relatado nas exibições sys.dm_db_resource_stats e sys.resource_stats, em avg_cpu_percent e avg_memory_usage_percent colunas. Para pools elásticos, o consumo de recursos no nível do pool é relatado na visualização sys.elastic_pool_resource_stats (para cenários históricos de relatórios) e em sys.dm_elastic_pool_resource_stats para monitoramento em tempo real. O consumo da CPU da carga de trabalho do usuário também é relatado por meio da métrica Azure Monitor, para bancos de dados únicos e pools elásticos no nível do cpu_percent pool.
Um detalhamento mais detalhado do consumo recente de recursos por cargas de trabalho de usuário e processos internos é relatado nas exibições sys.dm_resource_governor_resource_pools_history_ex e sys.dm_resource_governor_workload_groups_history_ex . Para obter detalhes sobre pools de recursos e grupos de carga de trabalho referenciados nessas exibições, consulte Governança de recursos. Essas exibições relatam a utilização de recursos por cargas de trabalho de usuário e processos internos específicos nos pools de recursos e grupos de carga de trabalho associados.
Gorjeta
Ao monitorar ou solucionar problemas de desempenho da carga de trabalho, é importante considerar o consumo de CPU do usuário (, ), e o consumo total de CPU por cargas de trabalho do usuário e processos internos (avg_instance_cpu_percentavg_cpu_percent,cpu_percentsql_instance_cpu_percent). O desempenho pode ser visivelmente afetado se qualquer uma dessas métricas estiver na faixa de 70-100%.
O consumo de CPU do usuário é definido como uma porcentagem em relação ao limite de CPU da carga de trabalho do usuário em cada objetivo de serviço. Da mesma forma, o consumo total de CPU é definido como a porcentagem em relação ao limite de CPU para todas as cargas de trabalho. Como os dois limites são diferentes, o usuário e o consumo total da CPU são medidos em escalas diferentes e não são diretamente comparáveis entre si.
Se o consumo de CPU do usuário atingir 100%, isso significa que a carga de trabalho do usuário está usando totalmente a capacidade de CPU disponível para ele no objetivo de serviço selecionado, mesmo que o consumo total de CPU permaneça abaixo de 100%.
Quando o consumo total de CPU atinge a faixa de 70-100%, é possível ver o nivelamento da taxa de transferência da carga de trabalho do usuário e a latência de consulta aumentando, mesmo que o consumo de CPU do usuário permaneça significativamente abaixo de 100%. É mais provável que isso ocorra ao usar objetivos de serviço menores com uma alocação moderada de recursos de computação, mas cargas de trabalho de usuário relativamente intensas, como em pools elásticos densos. Isso também pode ocorrer com objetivos de serviço menores quando os processos internos exigem temporariamente recursos adicionais, por exemplo, ao criar uma nova réplica do banco de dados ou ao fazer backup do banco de dados.
Da mesma forma, quando o consumo de CPU do usuário atingir a faixa de 70-100%, a taxa de transferência da carga de trabalho do usuário será nivelada e a latência de consulta aumentará, mesmo que o consumo total da CPU possa estar bem abaixo de seu limite.
Quando o consumo de CPU do usuário ou o consumo total de CPU é alto, as opções de mitigação são as mesmas observadas na seção CPU de computação e incluem aumento do objetivo de serviço e/ou otimização da carga de trabalho do usuário.
Nota
Mesmo em um banco de dados completamente ocioso ou pool elástico, o consumo total de CPU nunca é zero devido às atividades do mecanismo de banco de dados em segundo plano. Ele pode flutuar em uma ampla gama dependendo das atividades específicas em segundo plano, do tamanho da computação e da carga de trabalho anterior do usuário.
Gestão de recursos
Para impor limites de recursos, o Banco de Dados SQL do Azure usa uma implementação de governança de recursos baseada no Administrador de Recursos do SQL Server, modificada e estendida para ser executada na nuvem. No Banco de dados SQL, vários pools de recursos e grupos de carga de trabalho, com limites de recursos definidos nos níveis de pool e grupo, fornecem um banco de dados como serviço equilibrado. A carga de trabalho do usuário e as cargas de trabalho internas são classificadas em pools de recursos e grupos de carga de trabalho separados. A carga de trabalho do usuário nas réplicas primárias e secundárias legíveis, incluindo réplicas geográficas, é classificada SloSharedPool1 no pool de recursos e UserPrimaryGroup.DBId[N] nos grupos de carga de trabalho, onde [N] significa o valor de ID do banco de dados. Além disso, há vários pools de recursos e grupos de carga de trabalho para várias cargas de trabalho internas.
Além de usar o Administrador de Recursos para controlar recursos dentro do mecanismo de banco de dados, o Banco de Dados SQL do Azure também usa Objetos de Trabalho do Windows para governança de recursos em nível de processo e o Gerenciador de Recursos de Servidor de Arquivos do Windows (FSRM) para gerenciamento de cotas de armazenamento.
A governança de recursos do Banco de Dados SQL do Azure é hierárquica por natureza. De cima para baixo, os limites são impostos no nível do sistema operacional e no nível do volume de armazenamento usando mecanismos de governança de recursos do sistema operacional e o Administrador de Recursos, depois no nível do pool de recursos usando o Administrador de Recursos e, em seguida, no nível do grupo de carga de trabalho usando o Administrador de Recursos. Os limites de governança de recursos em vigor para o banco de dados atual ou pool elástico são relatados na exibição sys.dm_user_db_resource_governance .
Governança de E/S de dados
A governança de E/S de dados é um processo no Banco de Dados SQL do Azure usado para limitar E/S físicas de leitura e gravação em relação aos arquivos de dados de um banco de dados. Os limites de IOPS são definidos para cada nível de serviço para minimizar o efeito de "vizinho barulhento", para fornecer equidade de alocação de recursos em um serviço multilocatário e para permanecer dentro dos recursos do hardware e armazenamento subjacentes.
Para bancos de dados únicos, os limites do grupo de carga de trabalho são aplicados a todas as E/S de armazenamento em relação ao banco de dados. Para pools elásticos, os limites do grupo de carga de trabalho se aplicam a cada banco de dados no pool. Além disso, o limite do pool de recursos também se aplica à E/S cumulativa do pool elástico. Na tempdb, a E/S está sujeita a limites de grupo de carga de trabalho, exceto para a camada de serviço Básico, Padrão e de Uso Geral, onde se aplicam limites de E/S mais altos tempdb . Em geral, os limites do pool de recursos podem não ser alcançados pela carga de trabalho em um banco de dados (único ou agrupado), porque os limites do grupo de carga de trabalho são menores do que os limites do pool de recursos e limitam IOPS/taxa de transferência mais cedo. No entanto, os limites do pool podem ser atingidos pela carga de trabalho combinada em vários bancos de dados no mesmo pool.
Por exemplo, se uma consulta gerar 1000 IOPS sem qualquer governança de recursos de E/S, mas o limite máximo de IOPS do grupo de carga de trabalho estiver definido como 900 IOPS, a consulta não poderá gerar mais de 900 IOPS. No entanto, se o limite máximo de IOPS do pool de recursos for definido como 1500 IOPS e a E/S total de todos os grupos de carga de trabalho associados ao pool de recursos exceder 1500 IOPS, a E/S da mesma consulta poderá ser reduzida abaixo do limite de grupo de trabalho de 900 IOPS.
Os valores IOPS e throughput max retornados pela visualização sys.dm_user_db_resource_governance atuam como limites/limites, não como garantias. Além disso, a governança de recursos não garante nenhuma latência de armazenamento específica. A melhor latência, IOPS e taxa de transferência alcançáveis para uma determinada carga de trabalho de usuário dependem não apenas dos limites de governança de recursos de E/S, mas também da combinação de tamanhos de E/S usados e dos recursos do armazenamento subjacente. O Banco de dados SQL usa operações de E/S que variam em tamanho entre 512 bytes e 4 MB. Para fins de imposição de limites de IOPS, cada E/S é contabilizada independentemente de seu tamanho, exceto bancos de dados com arquivos de dados no Armazenamento do Azure. Nesse caso, E/S maiores que 256 KB são contabilizadas como várias E/S de 256 KB, para alinhar com a contabilidade de E/S do Armazenamento do Azure.
Para bancos de dados Básicos, Padrão e de Uso Geral, que usam arquivos de dados no Armazenamento do Azure, o primary_group_max_io valor pode não ser alcançável se um banco de dados não tiver arquivos de dados suficientes para fornecer cumulativamente esse número de IOPS, ou se os dados não forem distribuídos uniformemente entre os arquivos, ou se a camada de desempenho de blobs subjacentes limitar IOPS/taxa de transferência abaixo dos limites de governança de recursos. Da mesma forma, com pequenas operações de E/S de log geradas por confirmações frequentes de transações, o primary_max_log_rate valor pode não ser alcançável por uma carga de trabalho devido ao limite de IOPS no blob de Armazenamento do Azure subjacente. Para bancos de dados que usam o Armazenamento Premium do Azure, o Banco de Dados SQL do Azure usa blobs de armazenamento suficientemente grandes para obter IOPS/taxa de transferência necessária, independentemente do tamanho do banco de dados. Para bancos de dados maiores, vários arquivos de dados são criados para aumentar a capacidade total de IOPS/taxa de transferência.
Os valores de utilização de recursos, como e , relatados nas exibições sys.dm_db_resource_stats, sys.resource_stats, sys.dm_elastic_pool_resource_stats e avg_log_write_percentsys.elastic_pool_resource_stats, são calculados como avg_data_io_percent porcentagens dos limites máximos de governança de recursos. Portanto, quando outros fatores além da governança de recursos limitam a IOPS/taxa de transferência, é possível ver IOPS/taxa de transferência achatando e latências aumentando à medida que a carga de trabalho aumenta, mesmo que a utilização de recursos relatada permaneça abaixo de 100%.
Para monitorar o IOPS de leitura e gravação, a taxa de transferência e a latência por arquivo de banco de dados, use a função sys.dm_io_virtual_file_stats( ). Essa função apresenta todas as E/S no banco de dados, incluindo E/S em segundo plano que não é contabilizada para avg_data_io_percent, mas usa IOPS e taxa de transferência do armazenamento subjacente, e pode afetar a latência de armazenamento observada. A função relata latência adicional que pode ser introduzida io_stall_queued_read_ms pela governança de recursos de E/S para leituras e gravações, nas colunas e io_stall_queued_write_ms respectivamente.
Governança da taxa de log de transações
A governança da taxa de log de transações é um processo no Banco de Dados SQL do Azure usado para limitar altas taxas de ingestão para cargas de trabalho, como inserção em massa, SELECT INTO e compilações de índice. Esses limites são rastreados e aplicados no nível de subsegundo à taxa de geração de registros de log, limitando a taxa de transferência, independentemente de quantas E/S podem ser emitidas em relação a arquivos de dados. Atualmente, as taxas de geração de logs de transações são dimensionadas linearmente até um ponto que depende do hardware e da camada de serviço.
As taxas de log são definidas de forma que possam ser alcançadas e sustentadas em vários cenários, enquanto o sistema geral pode manter sua funcionalidade com impacto minimizado na carga do usuário. A governança da taxa de log garante que os backups de log de transações permaneçam dentro dos SLAs de capacidade de recuperação publicados. Essa governança também evita um acúmulo excessivo em réplicas secundárias que, de outra forma, poderia levar a um tempo de inatividade maior do que o esperado durante os failovers.
As E/S físicas reais para arquivos de log de transações não são controladas ou limitadas. À medida que os registros de log são gerados, cada operação é avaliada e avaliada se deve ser atrasada para manter uma taxa de log máxima desejada (MB/s por segundo). Os atrasos não são adicionados quando os registros de log são liberados para o armazenamento, em vez disso, a governança da taxa de log é aplicada durante a própria geração da taxa de log.
As taxas reais de geração de log impostas em tempo de execução também podem ser influenciadas por mecanismos de feedback, reduzindo temporariamente as taxas de log permitidas para que o sistema possa se estabilizar. O gerenciamento de espaço de arquivo de log, evitando a falta de espaço de log e os mecanismos de replicação de dados, podem diminuir temporariamente os limites gerais do sistema.
A modelagem de tráfego do regulador de taxa de log é exibida por meio dos seguintes tipos de espera (expostos nas visualizações sys.dm_exec_requests e sys.dm_os_wait_stats ):
| Tipo de espera | Notas |
|---|---|
| LOG_RATE_GOVERNOR | Limitação de banco de dados |
| POOL_LOG_RATE_GOVERNOR | Limitação da piscina |
| INSTANCE_LOG_RATE_GOVERNOR | Limitação do nível de instância |
| HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE | Controle de feedback, replicação física de grupo de disponibilidade no Premium/Business Critical não acompanhando |
| HADR_THROTTLE_LOG_RATE_LOG_SIZE | Controle de feedback, limitando as taxas para evitar uma condição de falta de espaço de log |
| HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO | Controle de feedback de replicação geográfica, limitando a taxa de log para evitar alta latência de dados e indisponibilidade de geosecundários |
Ao encontrar um limite de taxa de log que esteja dificultando a escalabilidade desejada, considere as seguintes opções:
Escale para um nível de serviço mais alto para obter a taxa máxima de log de uma camada de serviço ou mude para uma camada de serviço diferente. A camada de serviço Hyperscale fornece taxa de log de 100 MB/s por banco de dados e 125 MB/s por pool elástico, independentemente do nível de serviço escolhido.
Nota
Os pools elásticos para Hyperscale estão atualmente em visualização.
Se os dados que estão a ser carregados forem transitórios, como dados de teste num processo ETL, podem ser carregados para
tempdb(que é registado pelo mínimo).Para cenários analíticos, carregue para uma tabela columnstore em cluster ou uma tabela com índices que utilizem a compressão de dados. Isto reduz a taxa de registo necessária. Esta técnica aumenta a utilização da CPU e só é aplicável a conjuntos de dados que beneficiam de índices columnstore ou de compressão de dados.
Governança do espaço de armazenamento
Nas camadas de serviço Premium e Business Critical, os dados do cliente, incluindo arquivos de dados, arquivos de log de transações e tempdb arquivos, são armazenados no armazenamento SSD local da máquina que hospeda o banco de dados ou pool elástico. O armazenamento SSD local oferece alta IOPS e taxa de transferência, além de baixa latência de E/S. Além dos dados do cliente, o armazenamento local é usado para o sistema operacional, software de gerenciamento, dados e logs de monitoramento e outros arquivos necessários para a operação do sistema.
O tamanho do armazenamento local é finito e depende dos recursos de hardware, que determinam o limite máximo de armazenamento local, ou do armazenamento local reservado para os dados do cliente. Esse limite é definido para maximizar o armazenamento de dados do cliente, garantindo uma operação segura e confiável do sistema. Para encontrar o valor máximo de armazenamento local para cada objetivo de serviço, consulte a documentação de limites de recursos para bancos de dados únicos e pools elásticos.
Você também pode encontrar esse valor e a quantidade de armazenamento local atualmente usada por um determinado banco de dados ou pool elástico, usando a seguinte consulta:
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| Column | Description |
|---|---|
server_name |
Nome do servidor lógico |
database_name |
Nome da base de dados |
slo_name |
Nome do objetivo do serviço, incluindo geração de hardware |
user_data_directory_space_quota_mb |
Máximo de armazenamento local, em MB |
user_data_directory_space_usage_mb |
Consumo atual de armazenamento local por arquivos de dados, arquivos de log de transações e tempdb arquivos, em MB. Atualizado a cada cinco minutos. |
Essa consulta deve ser executada no banco de dados do usuário, não no master banco de dados. Para pools elásticos, a consulta pode ser executada em qualquer banco de dados do pool. Os valores relatados aplicam-se a todo o pool.
Importante
Nas camadas de serviço Premium e Business Critical, se a carga de trabalho tentar aumentar o consumo combinado de armazenamento local por arquivos de dados, arquivos de log de transações e tempdb arquivos acima do limite máximo de armazenamento local, ocorrerá um erro de falta de espaço. Isso acontecerá mesmo se o espaço usado em um arquivo de banco de dados não tiver atingido o tamanho máximo do arquivo.
O armazenamento SSD local também é usado por bancos de dados em camadas de serviço diferentes de Premium e Business Critical para o banco de dados e o tempdb cache RBPEX Hyperscale. À medida que os bancos de dados são criados, excluídos e aumentam ou diminuem de tamanho, o consumo total de armazenamento local em uma máquina flutua ao longo do tempo. Se o sistema detetar que o armazenamento local disponível em uma máquina é baixo e um banco de dados ou um pool elástico corre o risco de ficar sem espaço, ele move o banco de dados ou pool elástico para uma máquina diferente com armazenamento local suficiente disponível.
Essa movimentação ocorre de forma online, de forma semelhante a uma operação de dimensionamento de banco de dados, e tem um impacto semelhante, incluindo um failover curto (segundos) no final da operação. Esse failover encerra conexões abertas e reverte transações, potencialmente afetando os aplicativos que usam o banco de dados naquele momento.
Como todos os dados são copiados para volumes de armazenamento local em máquinas diferentes, mover bancos de dados maiores nas camadas de serviço Premium e Business Critical pode exigir uma quantidade substancial de tempo. Durante esse tempo, se o consumo de espaço local por um banco de dados ou um pool elástico, ou pelo banco de dados crescer rapidamente, o tempdb risco de ficar sem espaço aumenta. O sistema inicia a movimentação do banco de dados de forma equilibrada para minimizar erros de falta de espaço, evitando failovers desnecessários.
tempdb tamanhos
Os limites de tamanho para tempdb o Banco de Dados SQL do Azure dependem do modelo de compra e implantação.
Para saber mais, revise tempdb os limites de tamanho para:
- Modelo de compra vCore: bancos de dados únicos, bancos de dados agrupados
- Modelo de compra DTU: bancos de dados únicos, bancos de dados agrupados.
Hardware disponível anteriormente
Esta seção inclui detalhes sobre o hardware disponível anteriormente.
- O hardware Gen4 foi desativado e não está disponível para provisionamento, upscaling ou downscaling. Migre seu banco de dados para uma geração de hardware suportada para uma ampla gama de vCore e escalabilidade de armazenamento, rede acelerada, melhor desempenho de E/S e latência mínima. Para obter mais informações, consulte O suporte para hardware Gen 4 terminou no Banco de Dados SQL do Azure.
Você pode usar o Azure Resource Graph Explorer para identificar todos os recursos do Banco de Dados SQL do Azure que atualmente usam hardware Gen4 ou pode verificar o hardware usado pelos recursos para um servidor lógico específico no portal do Azure.
Você deve ter pelo menos read permissões para o objeto ou grupo de objetos do Azure para ver os resultados no Azure Resource Graph Explorer.
Para usar o Resource Graph Explorer para identificar recursos SQL do Azure que ainda estão usando hardware Gen4, siga estas etapas:
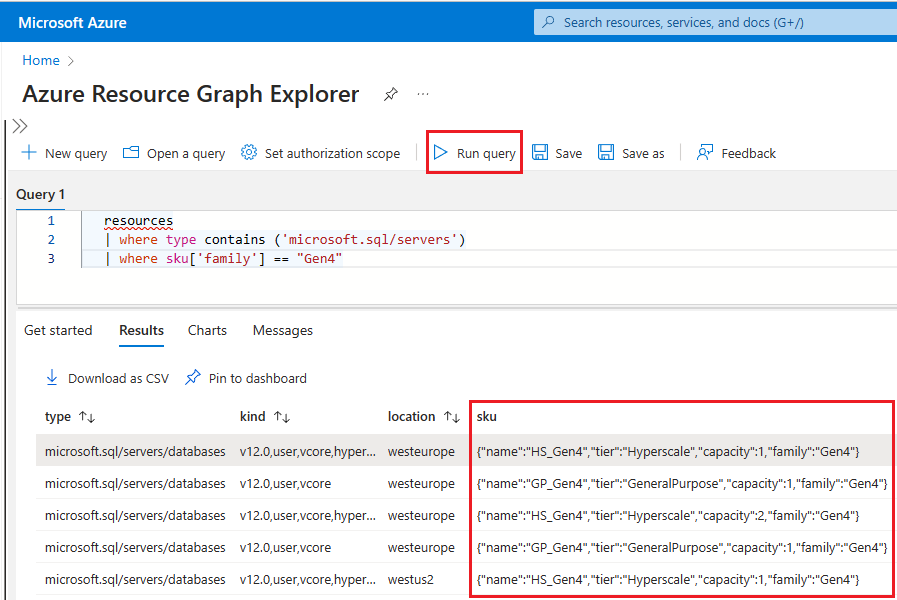
Aceda ao portal do Azure.
Pesquise
Resource graphna caixa de pesquisa e escolha o serviço Resource Graph Explorer nos resultados da pesquisa.Na janela de consulta, digite a seguinte consulta e selecione Executar consulta:
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"O painel Resultados exibe todos os recursos atualmente implantados no Azure que estão usando hardware Gen4.
Para verificar o hardware usado pelos recursos para um servidor lógico específico no Azure, siga estas etapas:
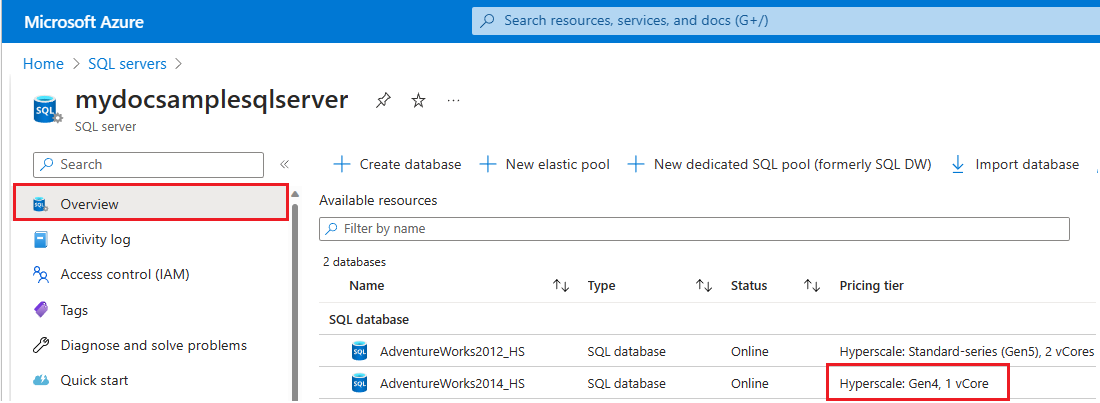
- Aceda ao portal do Azure.
- Pesquise
SQL serversna caixa de pesquisa e escolha SQL servers nos resultados da pesquisa para abrir a página SQL servers e exibir todos os servidores para a(s) assinatura(s) escolhida(s). - Selecione o servidor de interesse para abrir a página Visão geral do servidor.
- Role para baixo até os recursos disponíveis e verifique a coluna Camada de preços para recursos que estão usando hardware gen4.
Para migrar recursos para hardware de série padrão, consulte Alterar hardware.
Próximos passos
- Para obter informações sobre limites gerais do Azure, consulte Limites de assinatura e serviço, cotas e restrições do Azure.
- Para obter informações sobre DTUs e eDTUs, consulte DTUs e eDTUs.
- Para obter informações sobre
tempdblimites de tamanho, consulte bancos de dados vCore únicos, bancos de dados vCore agrupados, bancos de dados DTU únicos e bancos de dados DTU em pool.