Camada de serviços do Hyperscale
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
O Banco de Dados SQL do Azure é baseado na arquitetura do Mecanismo de Banco de Dados do SQL Server que é ajustada para o ambiente de nuvem para garantir alta disponibilidade mesmo em casos de falhas de infraestrutura. Há três opções de camada de serviço no modelo de compra vCore para o Banco de Dados SQL do Azure:
- Fins Gerais
- Crítico para a Empresa
- Hyperscale
A camada de serviço Hyperscale é adequada para todos os tipos de carga de trabalho. Sua arquitetura nativa da nuvem fornece computação e armazenamento escaláveis de forma independente para suportar a maior variedade de aplicativos tradicionais e modernos. Os recursos de computação e armazenamento em Hyperscale excedem substancialmente os recursos disponíveis nas camadas de uso geral e crítica para os negócios.
Nota
- Para obter detalhes sobre as camadas de serviço de uso geral e críticas para os negócios no modelo de compra baseado em vCore, consulte Camadas de serviço de uso geral e críticas para os negócios. Para obter uma comparação do modelo de compra baseado em vCore com o modelo de compra baseado em DTU, consulte Comparar modelos de compra baseados em vCore e DTU do Banco de Dados SQL do Azure.
- Atualmente, a camada de serviço Hyperscale está disponível apenas para o Banco de Dados SQL do Azure e não para a Instância Gerenciada SQL do Azure.
Quais são os recursos de hiperescala
A camada de serviço Hyperscale no Banco de Dados SQL do Azure fornece os seguintes recursos adicionais:
- Escalonamento rápido - você pode, em tempo constante, escalar seus recursos de computação para acomodar cargas de trabalho pesadas quando necessário e, em seguida, dimensionar os recursos de computação novamente quando não for necessário.
- Expansão rápida - você pode provisionar uma ou mais réplicas somente leitura para descarregar sua carga de trabalho de leitura e para uso como hot standbys .
- Escalonamento, redução e cobrança automáticos para computação com base no uso com computação sem servidor.
- Preço/desempenho otimizado para um grupo de bancos de dados Hyperscale com demandas de recursos variáveis com pools elásticos (em visualização).
- Armazenamento de dimensionamento automático com suporte para até 100 TB de tamanho de banco de dados ou pool elástico.
- Maior desempenho geral devido à maior taxa de transferência do log de transações e tempos de confirmação de transações mais rápidos, independentemente dos volumes de dados.
- Backups rápidos de banco de dados (com base em instantâneos de arquivos), independentemente do tamanho, sem impacto de E/S nos recursos de computação.
- O banco de dados rápido restaura ou copia (com base em instantâneos de arquivos) em minutos, em vez de horas ou dias.
A camada de serviço Hyperscale remove muitos dos limites práticos tradicionalmente vistos em bancos de dados em nuvem. Onde a maioria dos outros bancos de dados é limitada pelos recursos disponíveis em um único nó, os bancos de dados na camada de serviço Hyperscale não têm esses limites. Com sua arquitetura de armazenamento flexível, o armazenamento cresce conforme necessário. Na verdade, os bancos de dados Hyperscale não são criados com um tamanho máximo definido. Um banco de dados Hyperscale cresce conforme necessário - e você é cobrado apenas pela capacidade de armazenamento alocada. Para cargas de trabalho de leitura intensiva, a camada de serviço Hyperscale fornece escalabilidade horizontal rápida provisionando réplicas adicionais conforme necessário para descarregar cargas de trabalho de leitura.
Além disso, o tempo necessário para criar backups de banco de dados ou para aumentar ou diminuir a escala não está mais vinculado ao volume de dados no banco de dados. O backup dos bancos de dados de hiperescala é praticamente instantâneo. Você também pode dimensionar um banco de dados em dezenas de terabytes para cima ou para baixo em poucos minutos na camada de computação provisionada ou usar serverless para dimensionar a computação automaticamente. Esta funcionalidade liberta-o de preocupações sobre ser encaixotado pelas suas escolhas de configuração iniciais.
Para obter mais informações sobre os tamanhos de computação para a camada de serviço Hyperscale, consulte Características da camada de serviço.
Quem deve considerar a camada de serviço Hyperscale
A camada de serviço Hyperscale destina-se a todos os clientes que precisam de maior desempenho e disponibilidade, backup e restauração rápidos e/ou escalabilidade rápida de armazenamento e computação. Isso inclui clientes que estão migrando para a nuvem para modernizar seus aplicativos, bem como clientes que já estão usando outras camadas de serviço no Banco de Dados SQL do Azure. A camada de serviço Hyperscale suporta uma ampla gama de cargas de trabalho de banco de dados, de OLTP puro a análise pura. Ele é otimizado para OLTP e cargas de trabalho de transação híbrida e processamento analítico (HTAP).
Nota
Os pools elásticos para Hyperscale estão atualmente em visualização.
Modelo de preços de hiperescala
Nota
Os preços simplificados para o Azure SQL Database Hyperscale chegaram! Reveja o novo escalão de preços para o anúncio do Azure SQL Database Hyperscale e, para obter detalhes sobre a alteração de preços, consulte Azure SQL Database Hyperscale – preços mais baixos e simplificados!.
A camada de serviço de hiperescala só está disponível no modelo vCore. Para se alinhar com a nova arquitetura, o modelo de preços é ligeiramente diferente dos níveis de serviço de uso geral ou críticos para os negócios:
Computação provisionada:
O preço da unidade de computação do Hyperscale é por réplica. Os utilizadores podem ajustar o número total de réplicas secundárias de alta disponibilidade entre 0 e 4, dependendo dos requisitos de disponibilidade e escalabilidade e criar até 30 réplicas nomeadas para suportar diversas cargas de trabalho de escalamento horizontal de leituras.
Computação sem servidor:
A cobrança de computação sem servidor é baseada no uso. Para obter mais informações, consulte Camada de computação sem servidor para o Banco de Dados SQL do Azure.
Armazenamento:
Não precisa de especificar o tamanho máximo dos dados ao configurar uma base de dados Hyperscale. No escalão Hyperscale, é-lhe faturado o armazenamento da base de dados com base na alocação real. O armazenamento é alocado automaticamente entre 10 GB e 100 TB e cresce em incrementos de 10 GB conforme necessário.
Para obter mais informações sobre preços de hiperescala, consulte Preços do Banco de Dados SQL do Azure
Comparar limites de recursos
Os níveis de serviço baseados em vCore são diferenciados com base na disponibilidade do banco de dados, no tipo de armazenamento, no desempenho e no tamanho máximo do armazenamento. Essas diferenças são descritas na tabela a seguir:
| ㅤ | Fins Gerais | Negócios Críticos | Hyperscale |
|---|---|---|---|
| Melhor para | Oferece opções de computação e armazenamento equilibradas orientadas para o orçamento. | Aplicações OLTP com alta taxa de transação e baixa latência de E/S. Oferece alta resiliência a falhas e failovers rápidos usando várias réplicas em espera ativa. | A maior variedade de cargas de trabalho. Dimensionamento automático do tamanho de armazenamento de até 100 TB, rápido dimensionamento de computação vertical e horizontal, restauração rápida do banco de dados. |
| Tamanho de computação | 2 a 128 vCores | 2 a 128 vCores | 2 a 128 vCores 1 |
| Tipo de armazenamento | Armazenamento remoto premium (por instância) | Armazenamento SSD local super-rápido (por instância) | Armazenamento desacoplado com cache SSD local (por réplica de computação) |
| Tamanhode armazenamento 1 | 1 GB – 4 TB | 1 GB – 4 TB | 10 GB – 100 TB |
| IOPS | 320 IOPS por vCore com 16.000 IOPS máximas | 4.000 IOPS por vCore com 327.680 IOPS máximas | 327.680 IOPS com SSD local máximo A hiperescala é uma arquitetura multicamadas com cache em vários níveis. IOPS eficazes dependerão da carga de trabalho. |
| Memória/vCore | 5,1 GB | 5,1 GB | 5,1 GB ou 10,2 GB |
| Disponibilidade | Uma réplica, sem expansão de leitura, HA com redundância de zona | Três réplicas, uma leitura de scale-out, HA com redundância de zona | Várias réplicas, até quatro leituras escalonadas, HA com redundância de zona |
| Cópias de segurança | Uma opção de armazenamento com redundância local (LRS), com redundância de zona (ZRS) ou com redundância geográfica (GRS) Retenção de 1 a 35 dias (sete dias por padrão), com até 10 anos de retenção de longo prazo disponíveis |
Uma opção de armazenamento com redundância local (LRS), com redundância de zona (ZRS) ou com redundância geográfica (GRS) Retenção de 1 a 35 dias (sete dias por padrão), com até 10 anos de retenção de longo prazo disponíveis |
Uma opção de armazenamento com redundância local (LRS), com redundância de zona (ZRS) ou com redundância geográfica (GRS) Retenção de 1 a 35 dias (sete dias por padrão), com até 10 anos de retenção de longo prazo disponíveis |
| Preços/faturação | vCore, armazenamento reservado e armazenamento de backup são cobrados. As IOPS não são cobradas. |
vCore, armazenamento reservado e armazenamento de backup são cobrados. As IOPS não são cobradas. |
O vCore para cada réplica, o armazenamento de dados alocado e o armazenamento de backup são cobrados. As IOPS não são cobradas. |
| Modelos de desconto | Instâncias reservadas Benefício Híbrido do Azure (não disponível em subscrições de desenvolvimento/teste) Subscrições de desenvolvimento/teste Enterprise e Pay-As-You-Go |
Instâncias reservadas Benefício Híbrido do Azure (não disponível em subscrições de desenvolvimento/teste) Subscrições de desenvolvimento/teste Enterprise e Pay-As-You-Go |
Instâncias reservadas Benefício Híbrido do Azure (não disponível em subscrições de desenvolvimento/teste) 2 Subscrições de desenvolvimento/teste Enterprise e Pay-As-You-Go |
1 A visão geral dos pools elásticos de hiperescala no Banco de Dados SQL do Azure está atualmente em visualização.
2 Preços simplificados para o SQL Database Hyperscale em breve. Consulte o blog de preços do Hyperscale para obter detalhes.
Recursos de computação
| Configuração do hardware | CPU | Memória |
|---|---|---|
| Série padrão (Gen5) | Computação provisionada - Processadores Intel E5-2673 v4 (Broadwell) de 2,3 GHz, Intel SP-8160 (Skylake)1, Intel 8272CL (Cascade Lake) 2,5 GHz 1, Intel®®®® Xeon Platinum 8370C (Ice Lake)1, AMD EPYC 7763v (Milão) - Provisão de até 80 vCores (hyper-threaded) Computação sem servidor - Processadores Intel E5-2673 v4 (Broadwell) de 2,3 GHz, Intel SP-8160 (Skylake)1, Intel 8272CL (Cascade Lake) 2,5 GHz 1, Intel®®® Xeon® Platinum 8370C (Ice Lake)1, AMD EPYC 7763v (Milão) - Autoscale até 80 vCores (hyper-threaded) - A relação memória/vCore adapta-se dinamicamente à memória e ao uso da CPU com base na demanda de carga de trabalho e pode chegar a 24 GB por vCore. Por exemplo, em um determinado momento, uma carga de trabalho pode usar e ser cobrada por 240 GB de memória e apenas 10 vCores. |
Computação provisionada - 5,1 GB por vCore - Provisionamento de até 625 GB Computação sem servidor - Dimensionamento automático de até 24 GB por vCore - Dimensionamento automático até 240 GB no máximo |
| Série premium | - Processadores Intel® Xeon Platinum 8370C (Ice Lake), AMD EPYC 7763v (Milão) - Provisão de até 128 vCores (hyper-threaded) |
- 5,1 GB por vCore |
| Memória de série premium otimizada | - Processadores Intel® Xeon Platinum 8370C (Ice Lake), AMD EPYC 7763v (Milão) - Provisão de até 80 vCores (hyper-threaded) |
- 10,2 GB por vCore |
1 Na visualização sys.dm_user_db_resource_governance gerenciamento dinâmico, a geração de hardware para bancos de dados usando processadores Intel SP-8160 (Skylake) aparece como Gen6, a geração de hardware para bancos de dados usando Intel 8272CL (Cascade Lake) aparece como Gen7 e a geração de hardware para bancos de dados usando Intel®® Xeon® Platinum 8370C (Ice Lake) ou AMD® EPYC® 7763v (Milão) aparece como Gen8. Para um determinado tamanho de computação e configuração de hardware, os limites de recursos são os mesmos, independentemente do tipo de CPU. Para obter mais informações, consulte Limites de recursos para bancos de dados únicos e pools elásticos.
O Serverless só é suportado em hardware da série Standard (Gen5).
Arquitetura de funções distribuídas
O Hyperscale separa o mecanismo de processamento de consultas dos componentes que fornecem armazenamento de longo prazo e durabilidade para os dados. Essa arquitetura permite dimensionar suavemente a capacidade de armazenamento na medida do necessário (o destino inicial é de 100 TB) e a capacidade de dimensionar recursos de computação rapidamente.
O diagrama a seguir ilustra a arquitetura funcional de hiperescala:
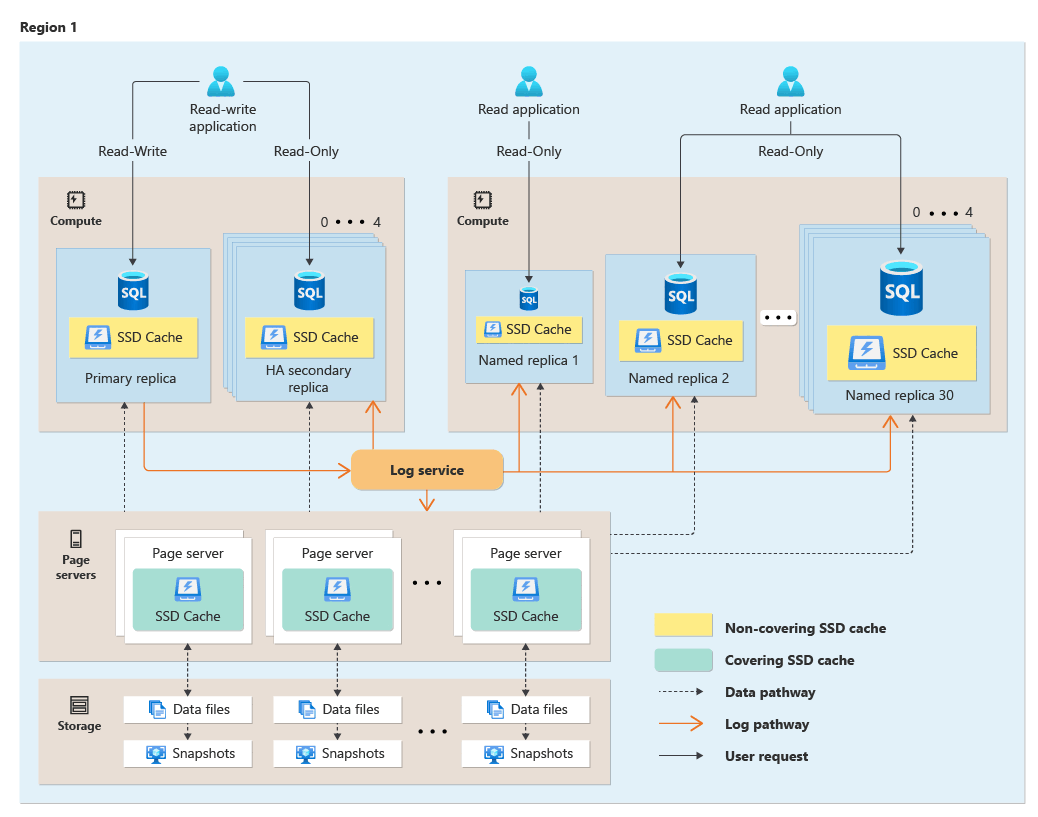
Saiba mais sobre a arquitetura de funções distribuídas Hyperscale.
Vantagens de escala e desempenho
Com a capacidade de girar rapidamente para cima/para baixo nós de computação somente leitura adicionais, a arquitetura Hyperscale permite recursos significativos de escala de leitura e também pode liberar o nó de computação primário para atender mais solicitações de gravação. Além disso, os nós de computação podem ser dimensionados para cima/para baixo rapidamente devido à arquitetura de armazenamento compartilhado da arquitetura Hyperscale. Os nós de computação somente leitura no Hyperscale também estão disponíveis na camada de computação sem servidor, que dimensiona automaticamente a computação com base na demanda de carga de trabalho.
Criar e gerenciar bancos de dados Hyperscale
Você pode criar e gerenciar bancos de dados Hyperscale usando o portal do Azure, Transact-SQL, PowerShell e a CLI do Azure. Para obter mais informações, consulte Guia de início rápido: criar um banco de dados Hyperscale.
| Operação | Detalhes | Mais informações |
|---|---|---|
| Criar um banco de dados Hyperscale | Os bancos de dados de hiperescala estão disponíveis apenas usando o modelo de compra baseado em vCore. | Encontre exemplos para criar um banco de dados Hyperscale em Guia de início rápido: crie um banco de dados Hyperscale no Banco de Dados SQL do Azure. |
| Atualizar um banco de dados existente para o Hyperscale | A migração de um banco de dados existente no Banco de Dados SQL do Azure para a camada de Hiperescala é um tamanho de operação de dados. | Saiba como migrar um banco de dados existente para o Hyperscale. |
| Reverter a migração de um banco de dados Hyperscale para a camada de serviço de uso geral | Se você migrou anteriormente um Banco de Dados SQL do Azure existente para a camada de serviço Hyperscale, poderá reverter a migração do banco de dados para a camada de serviço de Propósito Geral dentro de 45 dias da migração original para Hyperscale. Se desejar migrar o banco de dados para outra camada de serviço, como Business Critical, primeiro faça a migração reversa para a camada de serviço de uso geral e, em seguida, altere a camada de serviço. |
Saiba como reverter a migração do Hyperscale, incluindo as limitações da migração reversa. |
Alta disponibilidade do banco de dados em Hyperscale
Como em todas as outras camadas de serviço, o Hyperscale garante a durabilidade dos dados para transações confirmadas, independentemente da disponibilidade da réplica de computação. A extensão do tempo de inatividade devido à indisponibilidade da réplica principal depende do tipo de failover (planejado versus não planejado), se a redundância de zona está configurada e da presença de pelo menos uma réplica de alta disponibilidade. Em um failover planejado (como um evento de manutenção), o sistema cria a nova réplica primária antes de iniciar um failover ou usa uma réplica de alta disponibilidade existente como destino de failover. Em um failover não planejado (como uma falha de hardware na réplica primária), o sistema usa uma réplica de alta disponibilidade como destino de failover, se existir, ou cria uma nova réplica primária a partir do pool de capacidade de computação disponível. Neste último caso, a duração do tempo de inatividade é maior devido às etapas adicionais necessárias para criar a nova réplica primária.
Você pode escolher uma janela de manutenção que permita tornar os eventos de manutenção impactantes previsíveis e menos perturbadores para sua carga de trabalho.
Para SLA de hiperescala, consulte SLA para Banco de Dados SQL do Azure.
Cópia de segurança e restauro
As operações de backup e restauração para bancos de dados Hyperscale são baseadas em instantâneo de arquivo. Isso permite que essas operações sejam quase instantâneas. Como a arquitetura Hyperscale utiliza a camada de armazenamento para backup e restauração, a carga de processamento e o impacto no desempenho das réplicas de computação são significativamente reduzidos. Saiba mais em Backups em hiperescala e redundância de armazenamento.
Recuperação de desastres para bancos de dados Hyperscale
Se você precisar restaurar um banco de dados Hyperscale no Banco de Dados SQL do Azure para uma região diferente daquela em que ele está hospedado no momento, como parte de uma operação de recuperação de desastres ou drill, realocação ou qualquer outro motivo, o método principal é fazer uma restauração geográfica do banco de dados. A restauração geográfica só está disponível quando o armazenamento com redundância geográfica (RA-GRS) foi escolhido para redundância de armazenamento.
Saiba mais em Restaurar um banco de dados Hyperscale para uma região diferente.
Limitações conhecidas
Estas são as limitações atuais da camada de serviço Hyperscale. Estamos trabalhando ativamente para remover o maior número possível dessas limitações.
| Problema | Description |
|---|---|
| Restaurar banco de dados de outras camadas de serviço | Um banco de dados não Hyperscale não pode ser restaurado como um banco de dados Hyperscale e um banco de dados Hyperscale não pode ser restaurado como um banco de dados não-Hyperscale. Para bancos de dados migrados para Hyperscale de outras camadas de serviço do Banco de Dados SQL do Azure, os backups pré-migração são mantidos durante o período de retenção de backup do banco de dados de origem, incluindo políticas de retenção de longo prazo. A restauração de um backup pré-migração dentro do período de retenção de backup do banco de dados é suportada por meio da linha de comando. Você pode restaurar esses backups para qualquer camada de serviço que não seja de hiperescala. |
| Conjuntos Elásticos | As piscinas elásticas estão agora em pré-visualização. |
| Migração de bancos de dados com objetos OLTP In-Memory | O Hyperscale suporta um subconjunto de objetos OLTP In-Memory, incluindo tipos de tabela com otimização de memória, variáveis de tabela e módulos compilados nativamente. No entanto, quando quaisquer objetos OLTP In-Memory estão presentes no banco de dados que está sendo migrado, a migração das camadas de serviço Premium e Business Critical para Hyperscale não é suportada. Para migrar esse banco de dados para o Hyperscale, todos os objetos OLTP na memória e suas dependências devem ser descartados. Depois que o banco de dados é migrado, esses objetos podem ser recriados. Tabelas com otimização de memória durável e não durável não são suportadas atualmente no Hyperscale e devem ser alteradas para tabelas de disco. |
| Reduzir banco de dados | DBCC SHRINKDATABASE, DBCC SHRINKFILE ou definir AUTO_SHRINK como ON no nível do banco de dados não são suportados atualmente para bancos de dados Hyperscale. |
| Verificação da integridade do banco de dados | DBCC CHECKDB não é suportado atualmente para bancos de dados Hyperscale. DBCC CHECKTABLE ('TableName') COM TABLOCK e DBCC CHECKFILEGROUP WITH TABLOCK pode ser usado como uma solução alternativa. Consulte Integridade de Dados no Banco de Dados SQL do Azure para obter detalhes sobre o gerenciamento de integridade de dados no Banco de Dados SQL do Azure. |
| Tarefas Elásticas | Não há suporte para o uso de um banco de dados Hyperscale como o banco de dados Job. No entanto, os trabalhos elásticos podem direcionar bancos de dados Hyperscale da mesma maneira que qualquer outro banco de dados no Banco de Dados SQL do Azure. |
| Sincronização de Dados | Não há suporte para o uso de um banco de dados Hyperscale como um banco de dados de Metadados de Hub ou Sincronização. No entanto, uma base de dados Hyperscale pode ser uma base de dados membro numa topologia de Sincronização de Dados. |
| Hardware da série premium da camada de serviço de hiperescala | Atualmente, o hardware da série premium e otimizado para memória não suporta: - Redundância de zona - Nível de computação sem servidor. |
| Disponibilidade regional | O hardware otimizado para memória da série premium e da camada de serviço de hiperescala está disponível em regiões limitadas do Azure. Para obter uma lista, consulte Disponibilidade da série premium Hyperscale. |
Conteúdos relacionados
- Perguntas frequentes sobre o Hyperscale
- Comparar modelos de compra baseados em vCore e DTU do Banco de Dados SQL do Azure
- Gestão de recursos na Base de Dados SQL do Azure
- Limites de recursos das bases de dados individuais com o modelo de compra baseado em vCore
- Comparação de recursos: Banco de Dados SQL do Azure e Instância Gerenciada SQL do Azure
- Arquitetura de funções distribuídas em hiperescala
- Como gerenciar um banco de dados Hyperscale