Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Importante
Este não é o SDK Java mais recente para o Azure Cosmos DB! Deves atualizar o teu projeto para o Azure Cosmos DB Java SDK v4 e depois ler o guia de dicas de desempenho do Azure Cosmos DB Java SDK v4. Siga as instruções no guia Migrate to Azure Cosmos DB Java SDK v4 e no guia Reactor vs RxJava para atualizar.
As dicas de desempenho neste artigo são apenas para o Azure Cosmos DB Async Java SDK v2. Consulte as notas de atualização do Azure Cosmos DB Async Java SDK v2, o repositório Maven e o guia de resolução de problemas do Azure Cosmos DB Async Java SDK v2 para mais informações.
Importante
A 31 de agosto de 2024, o Azure Cosmos DB Async Java SDK v2.x será retirado; o SDK e todas as aplicações que utilizam o SDK continuarão a funcionar; O Azure Cosmos DB simplesmente deixará de fornecer manutenção e suporte adicionais para este SDK. Recomendamos seguir as instruções acima para migrar para o SDK Java v4 do Azure Cosmos DB.
O Azure Cosmos DB é uma base de dados distribuída rápida e flexível que escala de forma fluida, com latência e rendimento garantidos. Não é necessário fazer grandes alterações na arquitetura ou escrever código complexo para dimensionar seu banco de dados com o Azure Cosmos DB. Escalar para cima e para baixo é tão fácil quanto fazer uma única chamada de API ou chamada de método SDK. No entanto, como o Azure Cosmos DB é acedido através de chamadas de rede, existem otimizações do lado do cliente que pode fazer para alcançar o desempenho máximo ao usar o Azure Cosmos DB Async Java SDK v2.
Portanto, se você estiver perguntando "Como posso melhorar o desempenho do meu banco de dados?", considere as seguintes opções:
Rede
Modo de ligação: Usar modo Direto
A forma como um cliente se liga ao Azure Cosmos DB tem implicações importantes no desempenho, especialmente em termos de latência do lado do cliente. O ConnectionMode é uma definição chave disponível para configurar a ConnectionPolicy do cliente. Para o Azure Cosmos DB Async Java SDK v2, os dois ConnectionModes disponíveis são:
O modo gateway é suportado em todas as plataformas SDK e é a opção configurada por defeito. Se as suas aplicações correrem numa rede corporativa com restrições rigorosas de firewall, o modo Gateway é a melhor escolha, pois utiliza a porta HTTPS padrão e um único endpoint. A desvantagem de desempenho, no entanto, é que o modo Gateway envolve um salto adicional de rede sempre que dados são lidos ou escritos no Azure Cosmos DB. Por isso, o modo Direto oferece melhor desempenho devido a menos saltos na rede.
O ConnectionMode é configurado durante a construção da instância DocumentClient com o parâmetro ConnectionPolicy .
Async Java SDK v2 (Maven com.microsoft.azure::azure-cosmosdb)
public ConnectionPolicy getConnectionPolicy() {
ConnectionPolicy policy = new ConnectionPolicy();
policy.setConnectionMode(ConnectionMode.Direct);
policy.setMaxPoolSize(1000);
return policy;
}
ConnectionPolicy connectionPolicy = new ConnectionPolicy();
DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);
Coloque clientes na mesma região do Azure para desempenho
Quando possível, coloque todos os aplicativos que chamam o Azure Cosmos DB na mesma região do banco de dados do Azure Cosmos DB. Para uma comparação aproximada, as chamadas para o Azure Cosmos DB dentro da mesma região são concluídas dentro de 1 a 2 ms, mas a latência entre a costa oeste e leste dos EUA é >de 50 ms. Essa latência provavelmente pode variar de solicitação para solicitação, dependendo da rota tomada pela solicitação à medida que ela passa do cliente para o limite do datacenter do Azure. A menor latência possível é alcançada garantindo que a aplicação que realiza a chamada esteja localizada na mesma região do Azure que o endpoint provisionado do Azure Cosmos DB. Para obter uma lista de regiões disponíveis, consulte Regiões do Azure.
Utilização do SDK
Instalar o SDK mais recente
Os SDKs do Azure Cosmos DB estão sendo constantemente aprimorados para fornecer o melhor desempenho. Consulte as páginas de Notas de Lançamento do Azure Cosmos DB Async Java SDK v2 para determinar o SDK mais recente e rever melhorias.
Use um cliente singleton do Azure Cosmos DB durante o tempo de vida da sua aplicação
Cada instância AsyncDocumentClient é segura contra threads e realiza uma gestão eficiente de ligações e cache de endereços. Para permitir uma gestão eficiente da ligação e um melhor desempenho pelo AsyncDocumentClient, recomenda-se usar uma única instância de AsyncDocumentClient por AppDomain durante toda a vida útil da aplicação.
Otimização de ConnectionPolicy
Por padrão, os pedidos do Azure Cosmos DB no modo Direto são feitos via TCP quando se utiliza o Azure Cosmos DB Async Java SDK v2. Internamente, o SDK utiliza uma arquitetura especial em modo Direto para gerir dinamicamente os recursos da rede e obter o melhor desempenho.
No Azure Cosmos DB Async Java SDK v2, o modo Direct é a melhor escolha para melhorar o desempenho da base de dados com a maioria das cargas de trabalho.
- Visão geral do modo Direto
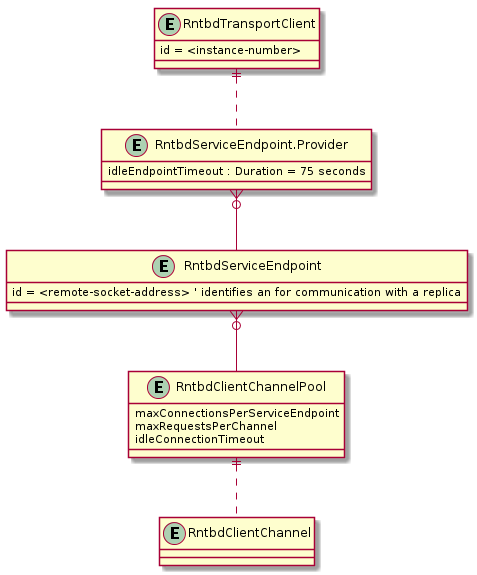
A arquitetura do lado do cliente empregue no modo Direto permite a utilização previsível da rede e o acesso multiplexado às réplicas do Azure Cosmos DB. O diagrama acima mostra como o modo Direto encaminha pedidos de clientes para réplicas no backend do Azure Cosmos DB. A arquitetura do modo Direto aloca até 10 canais no lado do cliente por réplica da base de dados. Um Canal é uma ligação TCP precedida por um buffer de pedidos, com uma profundidade de 30 pedidos. Os Canais pertencentes a uma réplica são alocados dinamicamente conforme necessário pelo Endpoint de Serviço da réplica. Quando o utilizador emite um pedido em modo Direto, o TransportClient encaminha o pedido para o endpoint de serviço adequado com base na chave de partição. A Fila de Pedidos armazena os pedidos antes do Endpoint de Serviço.
Opções de configuração ConnectionPolicy para modo Direto
Como primeiro passo, utilize as seguintes definições de configuração recomendadas abaixo. Contacte a equipa do Azure Cosmos DB se tiver problemas neste tema em particular.
Se estiver a usar o Azure Cosmos DB como base de dados de referência (ou seja, a base de dados é usada para muitas operações de leitura de pontos e poucas operações de escrita), pode ser aceitável definir o idleEndpointTimeout a 0 (ou seja, sem timeout).
Opção de configuração Predefinição bufferPageSize 8192 connectionTimeout "PT1M" tempo de inatividade do canal "PT0S" idleEndpointTimeout "PT1M10S" CapacidadeMáximaDoBuffer 8388608 maxCanaisPorEndpoint 10 máximoDePedidosPorCanal 30 receberTempoDeteçãoHang "PT1M5S" requestExpiryInterval "PT5S" requestTimeout "PT1M" requestTimerResolution "PT0.5S" enviarTempoDeteçãoSuspensão "PT10S" EncerramentoTempo de Expiração "PT15S"
Dicas de programação para o modo Direto
Consulte o artigo de resolução de problemas do Azure Cosmos DB Async Java SDK v2 como base para resolver quaisquer problemas de SDK.
Algumas dicas importantes de programação ao usar o modo Direto:
Utilize multithreading na sua aplicação para uma transferência eficiente de dados TCP - Após efetuar um pedido, a sua aplicação deve subscrever para receber dados noutra thread. Não fazê-lo força a operação 'half-duplex' não intencional e os pedidos subsequentes são bloqueados aguardando a resposta do pedido anterior.
Realizar cargas de trabalho intensivas em computação numa thread dedicada - Por razões semelhantes à dica anterior, operações como o processamento complexo de dados são melhor colocadas numa thread separada. Um pedido que puxe dados de outro armazenamento de dados (por exemplo, se o thread utiliza simultaneamente os repositórios de dados Azure Cosmos e Spark) pode experienciar maior latência e recomenda-se gerar um thread adicional que aguarde resposta do outro armazenamento de dados.
- A IO de rede subjacente no Azure Cosmos DB Async Java SDK v2 é gerida pela Netty. Veja estas dicas para evitar padrões de codificação que bloqueiam threads Netty IO.
Modelação de dados - O SLA do Azure Cosmos DB assume que o tamanho do documento é inferior a 1 KB. Otimizar o seu modelo de dados e programação para favorecer um tamanho de documento mais pequeno geralmente leva a uma menor latência. Se vais precisar de armazenamento e recuperação de documentos maiores que 1 KB, a abordagem recomendada é que os documentos se liguem a dados no Armazenamento de Blobs do Azure.
Ajuste de consultas paralelas para coleções particionadas
O Azure Cosmos DB Async Java SDK v2 suporta consultas paralelas, que permitem consultar uma coleção particionada em paralelo. Para mais informações, consulte exemplos de código relacionados com o trabalho com SDKs. As consultas paralelas são concebidas para melhorar a latência e a taxa de transferência das consultas em relação à sua contraparte serial.
Conjunto de afinaçãoMaxDegreeOfParallelism:
As consultas paralelas funcionam consultando várias partições em paralelo. No entanto, os dados de uma coleção particionada individual são obtidos em série relativamente à consulta. Assim, use setMaxDegreeOfParallelism para definir o número de partições que tem a maior probabilidade de proporcionar uma consulta de maior desempenho, desde que todas as outras condições do sistema permaneçam iguais. Se não souberes o número de partições, podes usar setMaxDegreeOfParallelism para definir um número elevado, e o sistema escolhe o mínimo (número de partições, entrada fornecida pelo utilizador) como o grau máximo de paralelismo.
É importante notar que as consultas paralelas produzem os melhores benefícios se os dados estiverem distribuídos uniformemente por todas as partições relativamente à consulta. Se a coleção particionada for particionada de tal forma que todos ou a maior parte dos dados devolvidos por uma consulta estejam concentrados em poucas partições (uma partição no pior dos casos), então o desempenho da consulta ficaria limitado por essas partições.
Otimização de setMaxBufferedItemCount:
A consulta paralela é projetada para pré-buscar resultados enquanto o lote atual de resultados está sendo processado pelo cliente. A pré-busca ajuda na melhoria geral da latência de uma consulta. setMaxBufferedItemCount limita o número de resultados pré-buscados. Definir setMaxBufferedItemCount para o número esperado de resultados devolvidos (ou um número superior) permite que a consulta receba o máximo benefício da pré-busca.
O pré-carregamento funciona da mesma maneira, independentemente do MaxDegreeOfParallelism, e existe um único buffer para os dados de todas as partições.
Implementar o backoff em intervalos de getRetryAfterInMilliseconds
Durante os testes de desempenho, deve-se aumentar a carga até que uma pequena taxa de pedidos seja controlada. Se for limitado, a aplicação cliente deve recuar para o intervalo de retentativa especificado pelo servidor. Respeitar o mecanismo de backoff garante que você passe o mínimo tempo possível a aguardar entre tentativas.
Dimensione a carga de trabalho do cliente
Se estiver a testar a níveis elevados de taxa de transferência (>50.000 RU/s), a aplicação cliente poderá ser o gargalo devido aos limites de utilização da CPU ou da rede pela máquina. Se você chegar a esse ponto, poderá continuar a expandir a conta do Azure Cosmos DB ao distribuir seus aplicativos cliente por vários servidores.
Use endereçamento baseado no nome
Use endereçamento baseado no nome, onde as ligações têm o formato
dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentId, em vez de SelfLinks (_self), que têm o formatodbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>para evitar recuperar ResourceIds de todos os recursos usados para construir a ligação. Além disso, à medida que estes recursos são recriados (possivelmente com o mesmo nome), armazená-los em cache pode não ajudar.Ajuste o tamanho da página para consultas/feeds de leitura para melhor desempenho
Ao realizar uma leitura em massa de documentos utilizando funcionalidades de feed de leitura (por exemplo, readDocuments) ou ao emitir uma consulta SQL, os resultados são devolvidos de forma segmentada se o conjunto de resultados for demasiado grande. Por defeito, os resultados são devolvidos em blocos de 100 itens ou 1 MB, consoante o limite atingido primeiro.
Para reduzir o número de idas e voltas de rede necessárias para obter todos os resultados aplicáveis, pode aumentar o tamanho da página usando o cabeçalho de pedido x-ms-max-item-count até 1000. Nos casos em que precisar de mostrar apenas alguns resultados, como quando a sua interface de utilizador ou API de aplicação retorna apenas 10 resultados de cada vez, pode também reduzir o tamanho da página para 10 para diminuir a largura de banda consumida por leituras e consultas.
Também pode definir o tamanho da página usando o método setMaxItemCount.
Use o Agendador Apropriado (Evite roubar threads do Event loop IO Netty)
O Azure Cosmos DB Async Java SDK v2 usa netty para IO não bloqueante. O SDK utiliza um número fixo de threads de ciclo de eventos IO Netty (equivalente ao número de núcleos da CPU da sua máquina) para executar operações de E/S. O Observable devolvido pela API emite o resultado numa das threads Netty do loop de eventos IO partilhado. Assim, é importante não bloquear as linhas de execução do Netty no ciclo de eventos de E/S partilhados. Fazer trabalho intensivo de CPU ou bloquear operações no thread Netty do ciclo de eventos de E/S pode causar deadlock ou reduzir significativamente o throughput do SDK.
Por exemplo, o seguinte código executa um trabalho intensivo de CPU no thread nety do ciclo de eventos IO:
Async Java SDK v2 (Maven com.microsoft.azure::azure-cosmosdb)
Observable<ResourceResponse<Document>> createDocObs = asyncDocumentClient.createDocument( collectionLink, document, null, true); createDocObs.subscribe( resourceResponse -> { //this is executed on eventloop IO netty thread. //the eventloop thread is shared and is meant to return back quickly. // // DON'T do this on eventloop IO netty thread. veryCpuIntensiveWork(); });Depois de receberes o resultado, se quiseres realizar um trabalho intensivo de CPU sobre esse resultado, deves evitar fazê-lo na thread de IO do ciclo de eventos do Netty. Pode, em vez disso, fornecer o seu próprio Scheduler para fornecer o seu próprio tópico para executar o seu trabalho.
Async Java SDK v2 (Maven com.microsoft.azure::azure-cosmosdb)
import rx.schedulers; Observable<ResourceResponse<Document>> createDocObs = asyncDocumentClient.createDocument( collectionLink, document, null, true); createDocObs.subscribeOn(Schedulers.computation()) subscribe( resourceResponse -> { // this is executed on threads provided by Scheduler.computation() // Schedulers.computation() should be used only when: // 1. The work is cpu intensive // 2. You are not doing blocking IO, thread sleep, etc. in this thread against other resources. veryCpuIntensiveWork(); });Com base no tipo do seu trabalho, deve usar o RxJava Scheduler existente apropriado para o seu trabalho. Leia aqui
Schedulers.Para mais informações, consulte a página do GitHub para o Azure Cosmos DB Async Java SDK v2.
Desativar o registo da Netty
O registo das bibliotecas Netty é conversivo e precisa de ser desligado (suprimir o sinal na configuração pode não ser suficiente) para evitar custos adicionais de CPU. Se não estiver no modo de depuração, desative completamente o registo do Netty. Portanto, se estiveres a usar o log4j para remover os custos adicionais de CPU causados
org.apache.log4j.Category.callAppenders()pelo nety, adiciona a seguinte linha à tua base de código:org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);Limite de recursos de arquivos abertos do sistema operativo
Alguns sistemas Linux (como o Red Hat) têm um limite superior no número de arquivos abertos e, portanto, no número total de conexões. Execute o seguinte para exibir os limites atuais:
ulimit -aO número de ficheiros abertos (nofile) tem de ser suficientemente grande para ter espaço suficiente para o tamanho do pool de ligação configurado e outros ficheiros abertos pelo sistema operativo. Ele pode ser modificado para permitir um tamanho maior do pool de conexões.
Abra o arquivo limits.conf:
vim /etc/security/limits.confAdicione/modifique as seguintes linhas:
* - nofile 100000
Política de Indexação
Excluir os caminhos não utilizados da indexação para assegurar escritas mais rápidas
A política de indexação do Azure Cosmos DB permite especificar quais caminhos de documento devem ser incluídos ou excluídos da indexação usando Caminhos de Indexação (setIncludedPaths e setExcludedPaths). O uso de caminhos de indexação pode oferecer melhor desempenho de gravação e menor armazenamento de índice para cenários nos quais os padrões de consulta são conhecidos de antemão, já que os custos de indexação estão diretamente correlacionados ao número de caminhos exclusivos indexados. Por exemplo, o código seguinte mostra como excluir uma secção inteira dos documentos (também conhecida como subárvore) da indexação usando o curinga "*".
Async Java SDK v2 (Maven com.microsoft.azure::azure-cosmosdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);Para obter mais informações, consulte Políticas de indexação do Azure Cosmos DB.
Capacidade de processamento
Meça e ajuste para reduzir o uso de unidades de requisição por segundo
O Azure Cosmos DB oferece um conjunto avançado de operações de banco de dados, incluindo consultas relacionais e hierárquicas com UDFs, procedimentos armazenados e gatilhos, todos operando nos documentos de uma coleção de banco de dados. O custo associado a cada uma destas operações varia com base na CPU, E/S e memória necessárias para concluir a operação. Em vez de pensar e gerenciar recursos de hardware, você pode pensar em uma unidade de solicitação (RU) como uma única medida para os recursos necessários para executar várias operações de banco de dados e atender a uma solicitação de aplicativo.
A taxa de transferência é provisionada com base no número de unidades de solicitação definidas para cada contentor. O consumo unitário de solicitação é avaliado como uma taxa por segundo. Os aplicativos que excedem a taxa unitária de solicitação provisionada para seu contêiner são limitados até que a taxa caia abaixo do nível provisionado para o contêiner. Se seu aplicativo exigir um nível mais alto de taxa de transferência, você poderá aumentar sua taxa de transferência provisionando unidades de solicitação adicionais.
A complexidade de uma consulta afeta quantas unidades de solicitação são consumidas para uma operação. O número de predicados, a natureza dos predicados, o número de UDFs e o tamanho do conjunto de dados de origem influenciam o custo das operações de consulta.
Para medir a sobrecarga de qualquer operação (criar, atualizar ou excluir), inspecione o cabeçalho x-ms-request-charge para medir o número de unidades de solicitação consumidas por essas operações. Você também pode examinar a propriedade RequestCharge equivalente em ResourceResponse<T> ou FeedResponse<T>.
Async Java SDK v2 (Maven com.microsoft.azure::azure-cosmosdb)
ResourceResponse<Document> response = asyncClient.createDocument(collectionLink, documentDefinition, null, false).toBlocking.single(); response.getRequestCharge();O custo de solicitação retornado neste cabeçalho é uma fração da taxa de transferência provisionada. Por exemplo, se tiver 2000 RU/s provisionadas, e se a consulta anterior devolver 1.000 documentos de 1 KB, o custo da operação é 1000. Como tal, dentro de um segundo, o servidor honra apenas duas dessas solicitações antes de limitar as solicitações subsequentes. Para obter mais informações, consulte Unidades de Solicitação e a Calculadora de Unidades de Solicitação.
Lidar com limitação de taxa / taxa de solicitação muito grande
Quando um cliente tenta exceder a taxa de transferência reservada para uma conta, não há degradação de desempenho no servidor e nenhum uso da capacidade de taxa de transferência além do nível reservado. O servidor terminará preventivamente a solicitação com RequestRateTooLarge (código de status HTTP 429) e retornará o cabeçalho x-ms-retry-after-ms indicando a quantidade de tempo, em milissegundos, que o usuário deve aguardar antes de tentar novamente a solicitação.
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100Todos os SDKs capturam implicitamente essa resposta, respeitam o cabeçalho retry-after especificado pelo servidor e tentam novamente a solicitação. A menos que sua conta esteja sendo acessada simultaneamente por vários clientes, a próxima tentativa será bem-sucedida.
Se tiver mais do que um cliente a operar de forma cumulativa acima da taxa de pedidos, a contagem de retentativas padrão atualmente definida internamente para 9 pelo cliente pode não ser suficiente; nessa situação, o cliente lança uma DocumentClientException com o código de estado 429 para a aplicação. A contagem padrão de tentativas pode ser alterada usando setRetryOptions na instância ConnectionPolicy. Por padrão, o DocumentClientException com o código de estado 429 é retornado após um tempo de espera acumulado de 30 segundos se o pedido continuar a operar acima da taxa de solicitações. Isso ocorre mesmo quando a contagem de tentativas atual é menor do que a contagem máxima de tentativas, seja o padrão de 9 ou um valor definido pelo usuário.
Embora o comportamento de repetição automatizada ajude a melhorar a resiliência e a usabilidade para a maioria dos aplicativos, ele pode entrar em desacordo ao fazer benchmarks de desempenho, especialmente ao medir a latência. A latência observada pelo cliente aumentará se o experimento atingir o limite do servidor e fizer com que o SDK do cliente tente novamente de forma silenciosa. Para evitar picos de latência durante experimentos de desempenho, meça a carga retornada por cada operação e verifique se as solicitações estão operando abaixo da taxa de solicitação reservada. Para obter mais informações, consulte Unidades de solicitação.
Design de documentos menores para maior eficiência
A taxa de solicitação (o custo de processamento da solicitação) de uma determinada operação está diretamente correlacionada com o tamanho do documento. As operações em documentos grandes custam mais do que as operações em documentos pequenos.
Passos seguintes
Para saber mais sobre como desenhar a sua aplicação para escala e alto desempenho, consulte Particionamento e escalonamento em Azure Cosmos DB.